 03讲字符串性能优化不容⼩觑,百M内存轻松存储⼏⼗G数据
03讲字符串性能优化不容⼩觑,百M内存轻松存储⼏⼗G数据
你好,我是刘超。
从第⼆个模块开始,我将带你学习Java编程的性能优化。今天我们就从最基础的String字符串优化讲起。
 String对象是我们使⽤最频繁的⼀个对象类型,但它的性能问题却是最容易被忽略的。String对象作为Java语⾔中重要的数据类型,是内存中占据空间最⼤的⼀个对象。⾼效地使⽤字符串,可以提升系统的整体性能。
String对象是我们使⽤最频繁的⼀个对象类型,但它的性能问题却是最容易被忽略的。String对象作为Java语⾔中重要的数据类型,是内存中占据空间最⼤的⼀个对象。⾼效地使⽤字符串,可以提升系统的整体性能。
接下来我们就从String对象的实现、特性以及实际使⽤中的优化这三个⽅⾯⼊⼿,深⼊了解。
在开始之前,我想先问你⼀个⼩问题,也是我在招聘时,经常会问到⾯试者的⼀道题。虽是⽼⽣常谈了,但错误率依然很⾼, 当然也有⼀些⾯试者答对了,但能解释清楚答案背后原理的⼈少之⼜少。问题如下:
通过三种不同的⽅式创建了三个对象,再依次两两匹配,每组被匹配的两个对象是否相等?代码如下:
String str1= “abc”;
String str2= new String(“abc”); String str3= str2.intern(); assertSame(str1==str2); assertSame(str2==str3); assertSame(str1==str3)
你可以先想想答案,以及这样回答的原因。希望通过今天的学习,你能拿到满分。
String对象是如何实现的?
在Java语⾔中,Sun公司的⼯程师们对String对象做了⼤量的优化,来节约内存空间,提升String对象在系统中的性能。⼀起
来看看优化过程,如下图所示: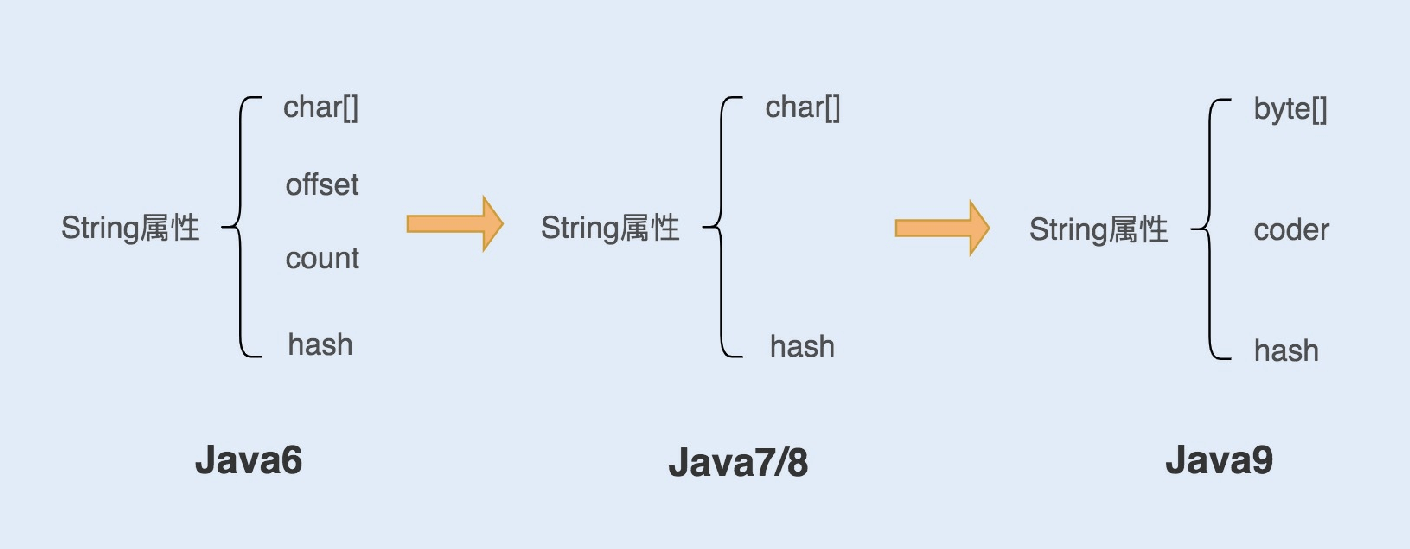
1.在Java6以及之前的版本中,String对象是对char数组进⾏了封装实现的对象,主要有四个成员变量:char数组、偏移量
offset、字符数量count、哈希值hash。
String对象是通过offset和count两个属性来定位char[]数组,获取字符串。这么做可以⾼效、快速地共享数组对象,同时节省内存空间,但这种⽅式很有可能会导致内存泄漏。
2.从Java7版本开始到Java8版本,Java对String类做了⼀些改变。String类中不再有offset和count两个变量了。这样的好处是
String对象占⽤的内存稍微少了些,同时,String.substring⽅法也不再共享char[],从⽽解决了使⽤该⽅法可能导致的内存泄漏问题。
3.从Java9版本开始,⼯程师将char[]字段改为了byte[]字段,⼜维护了⼀个新的属性coder,它是⼀个编码格式的标识。
⼯程师为什么这样修改呢?
我们知道⼀个char字符占16位,2个字节。这个情况下,存储单字节编码内的字符(占⼀个字节的字符)就显得⾮常浪费。
JDK1.9的String类为了节约内存空间,于是使⽤了占8位,1个字节的byte数组来存放字符串。
⽽新属性coder的作⽤是,在计算字符串⻓度或者使⽤indexOf()函数时,我们需要根据这个字段,判断如何计算字符串⻓ 度。coder属性默认有0和1两个值,0代表Latin-1(单字节编码),1代表UTF-16。如果String判断字符串只包含了Latin-1,则
coder属性值为0,反之则为1。
String对象的不可变性
了解了String对象的实现后,你有没有发现在实现代码中String类被final关键字修饰了,⽽且变量char数组也被final修饰了。
我们知道类被final修饰代表该类不可继承,⽽char[]被final+private修饰,代表了String对象不可被更改。Java实现的这个特性叫作String对象的不可变性,即String对象⼀旦创建成功,就不能再对它进⾏改变。
Java这样做的好处在哪⾥呢?
第⼀,保证String对象的安全性。假设String对象是可变的,那么String对象将可能被恶意修改。
第⼆,保证hash属性值不会频繁变更,确保了唯⼀性,使得类似HashMap容器才能实现相应的key-value缓存功能。
第三,可以实现字符串常量池。在Java中,通常有两种创建字符串对象的⽅式,⼀种是通过字符串常量的⽅式创建,如String
str=“abc”;另⼀种是字符串变量通过new形式的创建,如String str = new String(“abc”)。
当代码中使⽤第⼀种⽅式创建字符串对象时,JVM⾸先会检查该对象是否在字符串常量池中,如果在,就返回该对象引⽤,否则新的字符串将在常量池中被创建。这种⽅式可以减少同⼀个值的字符串对象的重复创建,节约内存。
String str = new String(“abc”)这种⽅式,⾸先在编译类⽂件时,”abc”常量字符串将会放⼊到常量结构中,在类加载
时,“abc”将会在常量池中创建;其次,在调⽤new时,JVM命令将会调⽤String的构造函数,同时引⽤常量池中的”abc” 字符串,在堆内存中创建⼀个String对象;最后,str将引⽤String对象。
这⾥附上⼀个你可能会想到的经典反例。
平常编程时,对⼀个String对象str赋值“hello”,然后⼜让str值为“world”,这个时候str的值变成了“world”。那么str值确实改变了,为什么我还说String对象不可变呢?
⾸先,我来解释下什么是对象和对象引⽤。Java初学者往往对此存在误区,特别是⼀些从PHP转Java的同学。在Java中要⽐较两个对象是否相等,往往是⽤==,⽽要判断两个对象的值是否相等,则需要⽤equals⽅法来判断。
这是因为str只是String对象的引⽤,并不是对象本身。对象在内存中是⼀块内存地址,str则是⼀个指向该内存地址的引⽤。所以在刚刚我们说的这个例⼦中,第⼀次赋值的时候,创建了⼀个“hello”对象,str引⽤指向“hello”地址;第⼆次赋值的时候,⼜重新创建了⼀个对象“world”,str引⽤指向了“world”,但“hello”对象依然存在于内存中。
也就是说str并不是对象,⽽只是⼀个对象引⽤。真正的对象依然还在内存中,没有被改变。
String对象的优化
了解了String对象的实现原理和特性,接下来我们就结合实际场景,看看如何优化String对象的使⽤,优化的过程中⼜有哪些需要注意的地⽅。
1.如何构建超⼤字符串?
编程过程中,字符串的拼接很常⻅。前⾯我讲过String对象是不可变的,如果我们使⽤String对象相加,拼接我们想要的字符串,是不是就会产⽣多个对象呢?例如以下代码:
String str= “ab” + “cd” + “ef”;
分析代码可知:⾸先会⽣成ab对象,再⽣成abcd对象,最后⽣成abcdef对象,从理论上来说,这段代码是低效的。
但实际运⾏中,我们发现只有⼀个对象⽣成,这是为什么呢?难道我们的理论判断错了?我们再来看编译后的代码,你会发现编译器⾃动优化了这⾏代码,如下:
String str= “abcdef”;
上⾯我介绍的是字符串常量的累计,我们再来看看字符串变量的累计⼜是怎样的呢?
String str = “abcdef”;
for(int i=0; i<1000; i++) { str = str + i;
}
上⾯的代码编译后,你可以看到编译器同样对这段代码进⾏了优化。不难发现,Java在进⾏字符串的拼接时,偏向使⽤
StringBuilder,这样可以提⾼程序的效率。
String str = “abcdef”;
for(int i=0; i<1000; i++) {
str = (new StringBuilder(String.valueOf(str))).append(i).toString();
}
综上已知:即使使⽤+号作为字符串的拼接,也⼀样可以被编译器优化成StringBuilder的⽅式。但再细致些,你会发现在编译器优化的代码中,每次循环都会⽣成⼀个新的StringBuilder实例,同样也会降低系统的性能。
所以平时做字符串拼接的时候,我建议你还是要显示地使⽤String Builder来提升系统性能。
如果在多线程编程中,String对象的拼接涉及到线程安全,你可以使⽤StringBuffer。但是要注意,由于StringBuffer是线程安全的,涉及到锁竞争,所以从性能上来说,要⽐StringBuilder差⼀些。
2.如何使⽤String.intern节省内存?
讲完了构建字符串,我们再来讨论下String对象的存储问题。先看⼀个案例。
Twitter每次发布消息状态的时候,都会产⽣⼀个地址信息,以当时Twitter⽤户的规模预估,服务器需要32G的内存来存储地址信息。
public class Location { private String city; private String region; private String countryCode; private double longitude; private double latitude;
}
考虑到其中有很多⽤户在地址信息上是有重合的,⽐如,国家、省份、城市等,这时就可以将这部分信息单独列出⼀个类,以减少重复,代码如下:
public class SharedLocation {
private String city; private String region; private String countryCode;
}
public class Location {
private SharedLocation sharedLocation; double longitude;
double latitude;
}
通过优化,数据存储⼤⼩减到了20G左右。但对于内存存储这个数据来说,依然很⼤,怎么办呢?
这个案例来⾃⼀位Twitter⼯程师在QCon全球软件开发⼤会上的演讲,他们想到的解决⽅法,就是使⽤String.intern来节省内存空间,从⽽优化String对象的存储。
具体做法就是,在每次赋值的时候使⽤String的intern⽅法,如果常量池中有相同值,就会重复使⽤该对象,返回对象引⽤, 这样⼀开始的对象就可以被回收掉。这种⽅式可以使重复性⾮常⾼的地址信息存储⼤⼩从20G降到⼏百兆。
SharedLocation sharedLocation = new SharedLocation(); sharedLocation.setCity(messageInfo.getCity().intern()); sharedLocation.setCountryCode(messageInfo.getRegion() sharedLocation.setRegion(messageInfo.getCountryCode().intern()); Location location = new Location(); location.set(sharedLocation); location.set(messageInfo.getLongitude()); location.set(messageInfo.getLatitude()); |
|---|
 |
为了更好地理解,我们再来通过⼀个简单的例⼦,回顾下其中的原理:
String a =new String(“abc”).intern(); String b = new String(“abc”).intern();
if(a==b) {
System.out.print(“a==b”);
}
输出结果:
a==b
在字符串常量中,默认会将对象放⼊常量池;在字符串变量中,对象是会创建在堆内存中,同时也会在常量池中创建⼀个字符串对象,引⽤赋值到堆内存对象中,并返回堆内存对象引⽤。
如果调⽤intern⽅法,会去查看字符串常量池中是否有等于该对象的字符串,如果没有,就在常量池中新增该对象,并返回该对象引⽤;如果有,就返回常量池中的字符串引⽤。堆内存中原有的对象由于没有引⽤指向它,将会通过垃圾回收器回收。
了解了原理,我们再⼀起看看上边的例⼦。
在⼀开始创建a变量时,会在堆内存中创建⼀个对象,同时会在加载类时,在常量池中创建⼀个字符串对象,在调⽤intern⽅法之后,会去常量池中查找是否有等于该字符串的对象,有就返回引⽤。
在创建b字符串变量时,也会在堆中创建⼀个对象,此时常量池中有该字符串对象,就不再创建。调⽤intern⽅法则会去常量池中判断是否有等于该字符串的对象,发现有等于”abc”字符串的对象,就直接返回引⽤。⽽在堆内存中的对象,由于没有引⽤ 指向它,将会被垃圾回收。所以a和b引⽤的是同⼀个对象。
下⾯我⽤⼀张图来总结下String字符串的创建分配内存地址情况: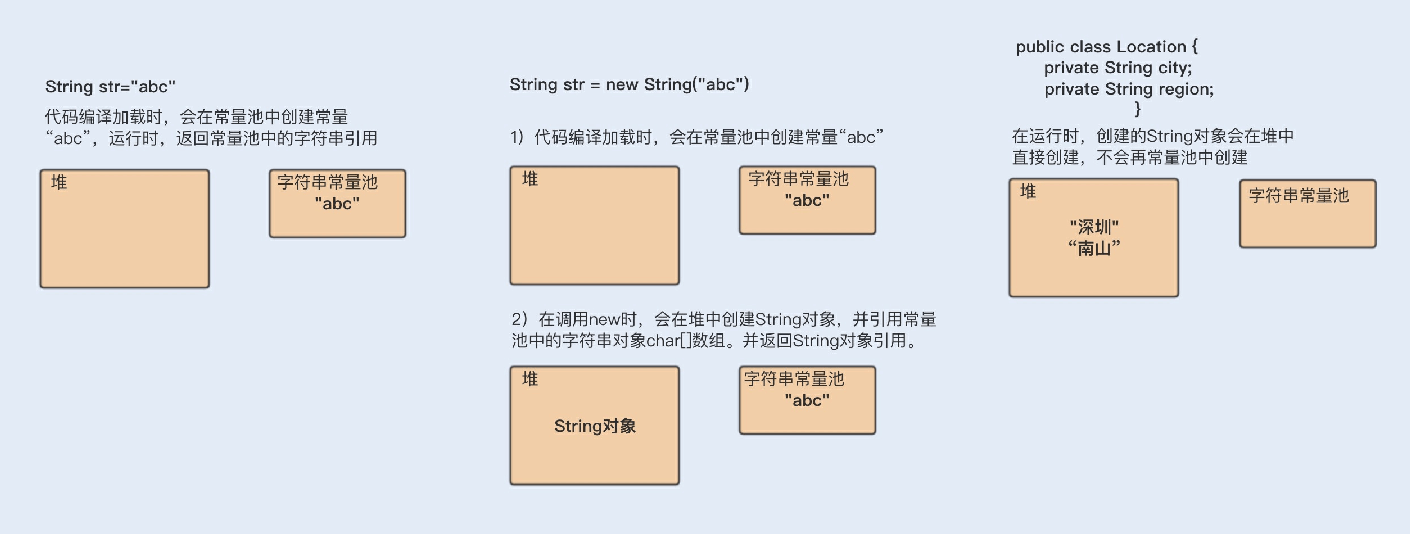
使⽤intern⽅法需要注意的⼀点是,⼀定要结合实际场景。因为常量池的实现是类似于⼀个HashTable的实现⽅式,HashTable 存储的数据越⼤,遍历的时间复杂度就会增加。如果数据过⼤,会增加整个字符串常量池的负担。
3.如何使⽤字符串的分割⽅法?
最后我想跟你聊聊字符串的分割,这种⽅法在编码中也很最常⻅。Split()⽅法使⽤了正则表达式实现了其强⼤的分割功能,⽽正则表达式的性能是⾮常不稳定的,使⽤不恰当会引起回溯问题,很可能导致CPU居⾼不下。
所以我们应该慎重使⽤Split()⽅法,我们可以⽤String.indexOf()⽅法代替Split()⽅法完成字符串的分割。如果实在⽆法满⾜需求,你就在使⽤Split()⽅法时,对回溯问题加以重视就可以了。
总结
这⼀讲中,我们认识到做好String字符串性能优化,可以提⾼系统的整体性能。在这个理论基础上,Java版本在迭代中通过不断地更改成员变量,节约内存空间,对String对象进⾏优化。
我们还特别提到了String对象的不可变性,正是这个特性实现了字符串常量池,通过减少同⼀个值的字符串对象的重复创建,
进⼀步节约内存。
但也是因为这个特性,我们在做⻓字符串拼接时,需要显示使⽤StringBuilder,以提⾼字符串的拼接性能。最后,在优化⽅
⾯,我们还可以使⽤intern⽅法,让变量字符串对象重复使⽤常量池中相同值的对象,进⽽节约内存。
最后再分享⼀个个⼈观点。那就是千⾥之堤,溃于蚁⽳。⽇常编程中,我们往往可能就是对⼀个⼩⼩的字符串了解不够深⼊, 使⽤不够恰当,从⽽引发线上事故。
⽐如,在我之前的⼯作经历中,就曾因为使⽤正则表达式对字符串进⾏匹配,导致并发瓶颈,这⾥也可以将其归纳为字符串使
⽤的性能问题。具体实战分析,我将在04讲中为你详解。
思考题
通过今天的学习,你知道⽂章开头那道⾯试题的答案了吗?背后的原理是什么?
互动时刻
今天除了思考题,我还想和你做⼀个简短的交流。
上两讲中,我收到了很多留⾔,在此⾮常感谢你的⽀持。由于前两讲是概述内容,主要是帮你建⽴对性能调优的整体认识,所以相对来说重理论、偏基础。但我发现,很多同学都有这样迫切的愿望,那就是赶紧学会使⽤排查⼯具,监测分析性能,解决当下的⼀些问题。
我这⾥特别想分享⼀点,其实性能调优不仅仅是学会使⽤排查监测⼯具,更重要的是掌握背后的调优原理,这样你不仅能够独
⽴解决同⼀类的性能问题,还能写出⾼性能代码,所以我希望给你的学习路径是:夯实基础-结合实战-实现进阶。
最后,欢迎你积极发⾔,讨论思考题或是你遇到的性能问题都可以,我会知⽆不尽。也欢迎你点击“请朋友读”,把今天的内容分享给身边的朋友,邀请他⼀起讨论。
精选留⾔
 KL3
KL3
⽼师,能解释下,
“String.substring ⽅法也不再共享 char[],从⽽解决了使⽤该⽅法可能导致的内存泄漏问题。”
共享char数组可能导致内存泄露问题?
2019-05-25 00:56
作者回复
你好 KL3,在Java6中substring⽅法会调⽤new string构造函数,此时会复⽤原来的char数组,⽽如果我们仅仅是⽤substring获取⼀⼩段字符,⽽原本string字符串⾮常⼤的情况下,substring的对象如果⼀直被引⽤,由于substring的⾥⾯的char数组仍然指向原字符串,此时string字符串也⽆法回收,从⽽导致内存泄露。
试想下,如果有⼤量这种通过substring获取超⼤字符串中⼀⼩段字符串的操作,会因为内存泄露⽽导致内存溢出。
2019-05-25 10:59
 扫地僧
扫地僧
答案是false,false,true。背后的原理是:
1、String str1 = “abc”;通过字⾯量的⽅式创建,abc存储于字符串常量池中;
2、String str2 = new String(“abc”);通过new对象的⽅式创建字符串对象,引⽤地址存放在堆内存中,abc则存放在字符串常量池中;所以str1 == str2?显然是false
3、String str3 = str2.intern();由于str2调⽤了intern()⽅法,会返回常量池中的数据,地址直接指向常量池,所以str1 == str3;
⽽str2和str3地址值不等所以也是false(str2指向堆空间,str3直接指向字符串常量池)。不知道这样理解有⽊有问题
2019-05-25 10:00
作者回复
答案⾮常正确,理解了这个题⽬基本理解了string的特性了。
2019-05-25 11:06
 失⽕的夏天
失⽕的夏天
开头题⽬答案是false false true
str1是建⽴在常量池中的“abc”,str2是new出来,在堆内存⾥的,所以str1!=str2,
str3是通过str2..intern()出来的,str1在常量池中已经建⽴了”abc”,这个时候str3是从常量池⾥取出来的,和str1指向的是同⼀个对象,⾃然也就有了st1==str3,str3!=str2了
2019-05-25 10:09
作者回复
这⾥我纠正下,str3是intern返回的引⽤,intern⽽不是创建出来的。
你的答案是正确的!
2019-05-25 11:00
 快乐的五五开
快乐的五五开
⾃学⼀年居然不知道有String.intern这个⽅法
不过从Java8开始(⼤概) String.split() 传⼊⻓度为1字符串的时候并不会使⽤正则,这种情况还是可以⽤
2019-05-25 01:36
作者回复
⾮常感谢Geek的补充,我在这⾥也再补充⼀个⼩点,split有两种情况不会使⽤正则表达式:
第⼀种为传⼊的参数⻓度为1,且不包含“.$|()[{^?*+\”regex元字符的情况下,不会使⽤正则表达式;
第⼆种为传⼊的参数⻓度为2,第⼀个字符是反斜杠,并且第⼆个字符不是ASCII数字或ASCII字⺟的情况下,不会使⽤正则表达式。
2019-05-25 11:21
 ⻛翱
⻛翱
 使⽤ intern ⽅法需要注意的⼀点是,⼀定要结合实际场景。因为常量池的实现是类似于⼀个 HashTable 的实现⽅式,HashTab
使⽤ intern ⽅法需要注意的⼀点是,⼀定要结合实际场景。因为常量池的实现是类似于⼀个 HashTable 的实现⽅式,HashTab
le 存储的数据越⼤,遍历的时间复杂度就会增加。如果数据过⼤,会增加整个字符串常量池的负担。像国家地区是有边界的。像其他情况,怎么把握这个度呢?
2019-05-25 08:03
作者回复
如果对空间要求⾼于时间要求,且存在⼤量重复字符串时,可以考虑使⽤常量池存储。
如果对查询速度要求很⾼,且存储字符串数量很⼤,重复率很低的情况下,不建议存储在常量池中。具体可以通过模拟测试⾃⼰的场景,对⽐两种存储⽅式的性能,通过数据来给⾃⼰答案。
2019-05-25 11:04
 Eric
Eric
对于您⽂中 “在⼀开始创建 a 变量时,会在堆内存中创建⼀个对象,同时在常量池中创建⼀个字符串对象” 这句话 我认为前部分没有问题 分歧点在后⾯那部分 我觉得abc常量早就在运⾏时常量池就存在了 可以理解使⽤这个类之前 就已经构造好了运⾏时常量池 ⽽运⾏时常量池中就包括“abc”常量 ⾄于使⽤new String(“abc”) 我觉得它应该只会在堆中创建String对象 并将运⾏时常量池中已经存在的“abc”常量的引⽤作为构造函数的参数⽽已
2019-05-25 18:28
作者回复
你理解的分歧点是对的,这个构造是在加载类时,就已经在常量池中构造好常量。
2019-05-26 08:27
Teanmy
⽼师好,有⼀点始终想不明⽩,请⽼师解惑,⾮常感谢!
⽼师先帮忙看看关于这两⾏代码,我的分析是否正确:
str1 = “abc”;
str2 = new String(“abc”)
str1 = “abc”;
1.str1,⾸先是在字符串常量池中寻找”abc”,找到则取其地址,找不到则创建并返回其地址
2.将该地址赋值给栈中的str1
str2 = new String(“abc”)
1.在堆中创建String对象,我查阅了String构造⽅法源码,实际值取的是”abc”的(此时”abc”已经存在字符串常量池中)引⽤, 也就是说,str2还是指向常量池,并没有创建新的”abc”。
public String(String original) { this.value = original.value; this.hash = original.hash;
}
2.堆中创建完String对象,将该对象的地址赋值给栈变量str2
疑问:
既然不管是以上哪种⽅式,最终实际引⽤的还是常量池中的”abc”,str2 = new String(“abc”)只是增加了⼀个堆中String的“空壳” 对象⽽已(因为实际上char[]指向的还是常量池中的”abc”),这个空壳对象并不会占⽤过多内存。⽽.intern的实质只是减少了这个中间的String空壳对象,那何来twitter通过.intern减少⼤量内存?
2019-06-02 19:36
作者回复
你好 teanmy。运⾏时创建的字符串对象只会在堆中创建⼀个对象。在这个前提下,如果有相同值的对象创建,使⽤intern可以减少重复字符串的创建。例如,有⼴东省/深圳市/南⼭区,如果有千万个⼈发布消息,创建了地址对象,这样导致千万个“⼴东省”对象在堆内存中创建,如果⻓时间引⽤,这些对象都没法释放,使⽤intern将“⼴东省”放到常量池中,其他对象引⽤常量池中的同⼀个“⼴东省”字符串,⽽堆中的千万个对象将被回收。
如果有疑问,请继续留⾔。
2019-06-03 09:44
 Zend
Zend
“在字符串变量中,对象是会创建在堆内存中,同时也会在常量池中创建⼀个字符串对象,复制到堆内存对象中,并返回堆内存对象引⽤。”
⽐如:
是从常量池中复制到堆内存,这时常量池中字符串与堆内存字符串是完全独⽴的,内部也不存在引⽤关系?
2019-05-26 05:44
作者回复
你好 Zend,具体的复制过程是先将常量池中的字符串压⼊栈中,在使⽤string的构造⽅法时,会拿到栈中的字符串作为构造⽅法的参数。这⾥我纠正⼀点,今天我查看了下这个构造函数,String的构造函数是⼀个char数组赋值过程,不是new char[]重新创建,所以是引⽤了常量池中的字符串对象,存在引⽤关系。
2019-05-26 08:24
 Eric
Eric
我在《Java虚拟机规范》⾥⾯看到⼀句话 这句话是当类或接⼝创建时,它的⼆进制表示中的常量池表被⽤来构造运⾏时常量池我理解的意思是 类或接⼝ 创建时就根据.class⽂件的常量池表⽣成了运⾏时常量池 执⾏new String(“abc”)这⾏代码应该只会⽣成⼀个String对象 并且调⽤它的构造函数 参数是运⾏时常量池⾥⾯”abc”字符串常量的Reference类型的数据(可以理解为指针吧)怎么会在这⾏代码执⾏的时候才会在运⾏时常量池⽣成”abc“对象呢?
2019-05-25 18:10
作者回复
如果是需要按照创建顺序来讲,常量“abc”,则会在加载编译时构造常量池时在常量池中创建“abc”字符串对象,⽽new对象的构 造函数是在运⾏时创建并复制常量池中的“abc”。还有⼀个运⾏时常量池,也就是说,在运⾏时创建的字符串对象,通过intern
⽅法会在运⾏时常量池中创建字符串对象。
2019-05-26 08:03
 Eric
Eric
String s1 = new String(“abc”).intern()
Code:
0: new #2 // class java/lang/String
3: dup
4: ldc #3 // String abc
6: invokespecial #4 // Method java/lang/String.”
9: invokevirtual #5 // Method java/lang/String.intern:()Ljava/lang/String;
12: astore_1
13: return
9:invokevirtual的时候 常量池⾥⾯应该早就有了”abc“这个字符串常量了吧 为什么⽂中说的是先去堆中创建⼀个String对象 然后再去常量池创建⼀个字符串常量? 我理解错误了吗?
2019-05-25 13:09
作者回复
我们可以看到0 new,即是⽣成了⼀个对象,这个对象是在堆内存⽤创建的,之后4 Idc则是将常量池中创建的字符串abc压⼊栈中,invokespecial调⽤构造⽅法复制abc字符串到对象中,invokevirtual调⽤intern本地⽅法,返回常量池中的对象引⽤给s1。
new String(“abc”)是会创建两个对象的,⼀个是堆对象,⼀个是常量池中的对象,intern会去判断常量池中是否有,这个时候是有的,所以不会创建,⽽是改变s1的引⽤。
不知道这样是否更好理解?
2019-05-25 15:38
 建国
建国
在实际编码中我们应该使⽤什么⽅式创建字符传呢?
A.String str= “abcdef”;
B.String str= new String(“abcdef”); C.String str= new String(“abcdef”). intern(); D.String str1=str.intern();
2019-05-25 10:45
作者回复
实际编码中,我们要结合实际场景来选择创建字符串的⽅式,例如,在创建局部变量以及常量时,我们⼀般使⽤A的这种⽅式
;如果我们要区别⼀个字符串创建两个不同的对象来使⽤时,会选择B;intern⼀般使⽤的⽐较少,例如我们平时会创建很多⼀样的字符串的对象时,且对象会保存在内存中,我们可以考虑使⽤intern⽅法来减少过多重复对象占⽤内存空间。
2019-05-25 11:32
 ° BugMaker
° BugMaker
刘⽼师您好!”使⽤ intern ⽅法需要注意的⼀点是,⼀定要结合实际场景。因为常量池的实现是类似于⼀个 HashTable 的实现⽅式,HashTable 存储的数据越⼤,遍历的时间复杂度就会增加。如果数据过⼤,会增加整个字符串常量池的负担”,那这个Twitte
r ⼯程师在 QCon 全球软件开发⼤会上的演讲的那个 intern ⽅法是如何做到遍历这么多常量池的数据,同时保证性能的呢?
2019-05-31 14:21
作者回复
你好,如果我们的数据对查询速度没有这么⾼要求,可以考虑使⽤。
2019-05-31 20:49
 Only now
Only now
看了本篇⼏乎全部留⾔, 感觉包括⽼师在内, 对于 “字符串常量池” 和 “常量池”, 这俩概念⽤的很混。
对于jdk7 以及之前的jvm版本不再去深究了, 它的字符串常量池存在于⽅法区, 但是jdk8以后, 它存在于Java堆中, 唯⼀, 且由java.
lang.String类维护, 它和类⽂件常量池, 运⾏时常量池没有半⽑钱的关系。
最后我有个疑问问⽼师, 字符串常量池中的对象, 在失去了所有外部引⽤之后, 会被gc掉吗?
2019-05-29 15:53
作者回复
⾮常感谢only now的总结,这⼀讲中没有详细去区分常量池,⽽是在强调字符串的使⽤,后⾯我们在JVM中可以再⼀起研究下常量池。
JVM⽂献中提到⽅法区是存在垃圾回收。我们可以通过intern⽅法来验证这个gc问题,通过⼤量请求请求某个接⼝,传⼊参数创建字符串对象,之后通过intern⽅法在常量池中⽣成字符串对象,之后失去引⽤,观察gc情况。
2019-05-29 21:35
 晓杰
晓杰
回答开篇的问题:
str1会在常量池中创建⼀个对象
str2⾸先会在堆内存中创建⼀个对象,然后在加载类的时候在常量池创建⼀个字符串对象,同时复制到堆内存对象中,并返回堆内存对象的引⽤
str3会先去常量池中查看存在于该字符串相等的对象,因为str1已经在常量池创建了⼀个相同的对象,所以str1和str3相等。综上:str1和str2不相等,str1和str3相等,str2和str3不相等
2019-05-26 20:51
 -W.LI-
-W.LI-
⽼师你说的对!直接把char数组做⼊参创建的String对象⾥的value数组地址是不⼀样的。调⽤intern()⽅法后就⼀样了。是我搞错 了,然后回到第⼀个问题的后半部分,我打印输出a==b是false。之前有看到char数组的地址是⼀样的。这说明new虽然在堆中
新建了⼀个String对象,但是⾥⾯的char数组是复⽤的。这样做的⽬的是为了节约char数组的内存开销,然后String本身就是不
可变对象,复⽤char数组不会带来问题。问题⼀:这个char数组是存放在哪的啊?堆还是常量池,其实我不知道常量池具体是个啥,课上⽼师说的类似hashmap,这样的话就是接近O(1)随机读取。不知道它能不能存char[]。问题⼆:复⽤char[]我猜是这么实现的new创建String时会去常量池中查找对应的String存在拿取char[]复⽤,如果这样的话其实char[]到底存放在哪不太重要。问题三:常量池的内存会回收么?突然觉得⾃⼰对常量池⼀⽆所知。。。常量池的⽣命周期⼀⽆所知。
2019-05-26 19:46
作者回复
char数组是存放在常量池中,常量是会在编译时⽣成字⾯量,在类加载时加载到常量池中。这个存放位置还是重要的,这就相当于权职划分,每个位置都有⾃⼰的功能和职责。
常量池中的垃圾回收,也是垃圾回收器完成,只要没有根引⽤的对象,包括类信息等等,都会在回收期被回收掉。常量池中的常量⼀般是固定的,不像对中的对象。
2019-05-27 09:49
 -W.LI-
-W.LI-
⽼师好!第⼀个问题没有描述清楚。String
a = ”abc”, String b =new String(“abc”),String c=new String(new char[]{‘a’,‘b’,‘c’})。创建的String对象。我debug时发现这三个
String对象的value指向的那个char数组地址值都是⼀样的。他们是复⽤了⼀个char数组么?还是⼯具显示问题?我⽤的idea。
2019-05-26 15:29
作者回复
你好 W.LI,刚我debug了下,a和b的value是同⼀个地址,因为a在常量池中创建了”abc”,⽽new String(“abc”)时,发现常量池存在”abc”字符串对象,不会创建了。这时通过构造函数String(String original)将常量池中的”abc”复制给value,这⾥的复制是引
⽤,不是创建新的char[]数组,所以是同⼀个value地址。
⽽c中的构造函数,是新开辟了⼀个char[]数组:
public String(char value[]) {
this.value = Arrays.copyOf(value, value.length);
}
所以value的地址不⼀样。可以再试试,有问题留⾔。
2019-05-26 19:13
 QQ怪
QQ怪
⽼师讲的挺到位的,挺容易理解,之前忘记的现在⼜被⽼师点出来了,⽀持⽼师
2019-05-25 12:38 纯⻛
纯⻛
你好啊 我不了解堆和栈 能不能给我说下 创建的对象在堆中,栈中放的是对象的引⽤地址吗 还有使⽤intern()⽅法 和 创建的对象放在常量池中 这两者是什么关系
2019-07-05 16:39
作者回复
你好,纯⻛。如果不了解JVM内存模型,建议可以留意21讲,这⾥会详细讲解。
2019-07-07 10:14
 benben
benben
请教最后⼀张图第三列的意思是对象成员变量是string的话不会放到常量池是吗?
2019-06-26 16:39
作者回复
是的,运⾏时动态创建是在堆内存中直接创建的,调⽤intern⽅法,会反倒常量池中。
2019-06-30 10:15
Hammy
⽼师您好,我这⾥有⼀个疑问。在听您说完,对象的string属性实质上在运⾏中是在堆内存中创建⽽不是引⽤常量池的时候如
雷贯⽿⼀般,觉得⾃⼰之前根本没思考过这个问题,完全没想过⽤intern进⾏优化。但是我做了⼀个实验,public class Person
{
public String name;
public void setName(String name) { this.name = name;
}
public String getName() { return name;
}
public static void main(String[] args) { Person person1 = new Person();
person1.setName(“张三”);
Person person2 = new Person();
person2.setName(“ 张 三 “); System.out.println(person1.name==person2.name);
}
这段代码中,我理解如果string是在运⾏过程中在堆内存⽣成对象,那么结果应该是false,但是返回的结果是true。这是我的⼀ 个疑惑,劳烦⽼师帮忙看⼀下我的测试代码哪⾥不对,还是有理解错误的地⽅。
2019-06-21 15:23

若有收获,就点个赞吧
0 人点赞
