 32讲MySQL调优之SQL语句:如何写出⾼性能SQL语句
32讲MySQL调优之SQL语句:如何写出⾼性能SQL语句
你好,我是刘超。
 从今天开始,我将带你⼀起学习MySQL的性能调优。MySQL数据库是互联⽹公司使⽤最为频繁的数据库之⼀,不仅仅因为它开源免费,MySQL卓越的性能、稳定的服务以及活跃的社区都成就了它的核⼼竞争⼒。
从今天开始,我将带你⼀起学习MySQL的性能调优。MySQL数据库是互联⽹公司使⽤最为频繁的数据库之⼀,不仅仅因为它开源免费,MySQL卓越的性能、稳定的服务以及活跃的社区都成就了它的核⼼竞争⼒。
我们知道,应⽤服务与数据库的交互主要是通过SQL语句来实现的。在开发初期,我们更加关注的是使⽤SQL实现业务功能, 然⽽系统上线后,随着⽣产环境数据的快速增⻓,之前写的很多SQL语句就开始暴露出性能问题。
在这个阶段中,我们应该尽量避免⼀些慢SQL语句的实现。但话说回来,SQL语句慢的原因千千万,除了⼀些常规的慢SQL语句可以直接规避,其它的⼀味去规避也不是办法,我们还要学会如何去分析、定位到其根本原因,并总结⼀些常⽤的SQL调优
⽅法,以备不时之需。
那么今天我们就重点看看慢SQL语句的⼏种常⻅诱因,从这点出发,找到最佳⽅法,开启⾼性能SQL语句的⼤⻔。
慢SQL语句的⼏种常⻅诱因
⽆索引、索引失效导致慢查询
如果在⼀张⼏千万数据的表中以⼀个没有索引的列作为查询条件,⼤部分情况下查询会⾮常耗时,这种查询毫⽆疑问是⼀个慢
SQL查询。所以对于⼤数据量的查询,我们需要建⽴适合的索引来优化查询。
虽然我们很多时候建⽴了索引,但在⼀些特定的场景下,索引还有可能会失效,所以索引失效也是导致慢查询的主要原因之
⼀。针对这点的调优,我会在第34讲中详解。
锁等待
我们常⽤的存储引擎有 InnoDB 和 MyISAM,前者⽀持⾏锁和表锁,后者只⽀持表锁。
如果数据库操作是基于表锁实现的,试想下,如果⼀张订单表在更新时,需要锁住整张表,那么其它⼤量数据库操作(包括查
询)都将处于等待状态,这将严重影响到系统的并发性能。
这时,InnoDB 存储引擎⽀持的⾏锁更适合⾼并发场景。但在使⽤ InnoDB 存储引擎时,我们要特别注意⾏锁升级为表锁的可能。在批量更新操作时,⾏锁就很可能会升级为表锁。
MySQL认为如果对⼀张表使⽤⼤量⾏锁,会导致事务执⾏效率下降,从⽽可能造成其它事务⻓时间锁等待和更多的锁冲突问题发⽣,致使性能严重下降,所以MySQL会将⾏锁升级为表锁。还有,⾏锁是基于索引加的锁,如果我们在更新操作时,条件索引失效,那么⾏锁也会升级为表锁。
因此,基于表锁的数据库操作,会导致SQL阻塞等待,从⽽影响执⾏速度。在⼀些更新操作(insert\update\delete)⼤于或等于读操作的情况下,MySQL不建议使⽤MyISAM存储引擎。
除了锁升级之外,⾏锁相对表锁来说,虽然粒度更细,并发能⼒提升了,但也带来了新的问题,那就是死锁。因此,在使⽤⾏锁时,我们要注意避免死锁。关于死锁,我还会在第35讲中详解。
不恰当的SQL语句
使⽤不恰当的SQL语句也是慢SQL最常⻅的诱因之⼀。例如,习惯使⽤ SQL语句,在⼤数据表中使⽤
优化SQL语句的步骤
通常,我们在执⾏⼀条SQL语句时,要想知道这个SQL先后查询了哪些表,是否使⽤了索引,这些数据从哪⾥获取到,获取到数据遍历了多少⾏数据等等,我们可以通过EXPLAIN命令来查看这些执⾏信息。这些执⾏信息被统称为执⾏计划。
通过EXPLAIN分析SQL执⾏计划
假设现在我们使⽤EXPLAIN命令查看当前SQL是否使⽤了索引,先通过SQL EXPLAIN导出相应的执⾏计划如下:
下⾯对图示中的每⼀个字段进⾏⼀个说明,从中你也能收获到很多零散的知识点。
id:每个执⾏计划都有⼀个id,如果是⼀个联合查询,这⾥还将有多个id。
select_type:表示SELECT查询类型,常⻅的有SIMPLE(普通查询,即没有联合查询、⼦查询)、PRIMARY(主查询)、UNION(UNION中后⾯的查询)、SUBQUERY(⼦查询)等。
table:当前执⾏计划查询的表,如果给表起别名了,则显示别名信息。
partitions:访问的分区表信息。
type:表示从表中查询到⾏所执⾏的⽅式,查询⽅式是SQL优化中⼀个很重要的指标,结果值从好到差依次是:system > const > eq_ref > ref > range > index > ALL。
system/const:表中只有⼀⾏数据匹配,此时根据索引查询⼀次就能找到对应的数据。如果是B +树索引,我们知道此时索
引构造成了多个层级的树,当查询的索引在树的底层时,查询效率就越低。const表示此时索引在第⼀层,只需访问⼀层便
能得到数据。
eq_ref:使⽤唯⼀索引扫描,常⻅于多表连接中使⽤主键和唯⼀索引作为关联条件。
ref:⾮唯⼀索引扫描,还可⻅于唯⼀索引最左原则匹配扫描。
range:索引范围扫描,⽐如,<,>,between等操作。
index:索引全表扫描,此时遍历整个索引树。
ALL:表示全表扫描,需要遍历全表来找到对应的⾏。
possible_keys:可能使⽤到的索引。
key:实际使⽤到的索引。
key_len:当前使⽤的索引的⻓度。
ref:关联id等信息。
rows:查找到记录所扫描的⾏数。
filtered:查找到所需记录占总扫描记录数的⽐例。
Extra:额外的信息。
通过Show Profile分析SQL执⾏性能
上述通过 EXPLAIN 分析执⾏计划,仅仅是停留在分析SQL的外部的执⾏情况,如果我们想要深⼊到MySQL内核中,从执⾏线程的状态和时间来分析的话,这个时候我们就可以选择Profile。
Profile除了可以分析执⾏线程的状态和时间,还⽀持进⼀步选择ALL、CPU、MEMORY、BLOCK IO、CONTEXT
SWITCHES等类型来查询SQL语句在不同系统资源上所消耗的时间。以下是相关命令的注释:
SHOW PROFILE [type [, type] … ] [FOR QUERY n]
[LIMIT row_count [OFFSET offset]]
type参数:
| ALL:显示所有开销信息
| BLOCK IO:阻塞的输⼊输出次数
| CONTEXT SWITCHES:上下⽂切换相关开销信息
| CPU:显示CPU的相关开销信息
| IPC:接收和发送消息的相关开销信息
| MEMORY :显示内存相关的开销,⽬前⽆⽤
| PAGE FAULTS :显示⻚⾯错误相关开销信息
| SOURCE :列出相应操作对应的函数名及其在源码中的调⽤位置(⾏数)
| SWAPS:显示swap交换次数的相关开销信息
值得注意的是,MySQL是在5.0.37版本之后才⽀持Show Profile功能的,如果你不太确定的话,可以通过select
@@have_profiling查询是否⽀持该功能,如下图所示:
最新的MySQL版本是默认开启Show Profile功能的,但在之前的旧版本中是默认关闭该功能的,你可以通过set语句在Session
级别开启该功能:
Show Profiles只显示最近发给服务器的SQL语句,默认情况下是记录最近已执⾏的15条记录,我们可以重新设置
profiling_history_size增⼤该存储记录,最⼤值为100。
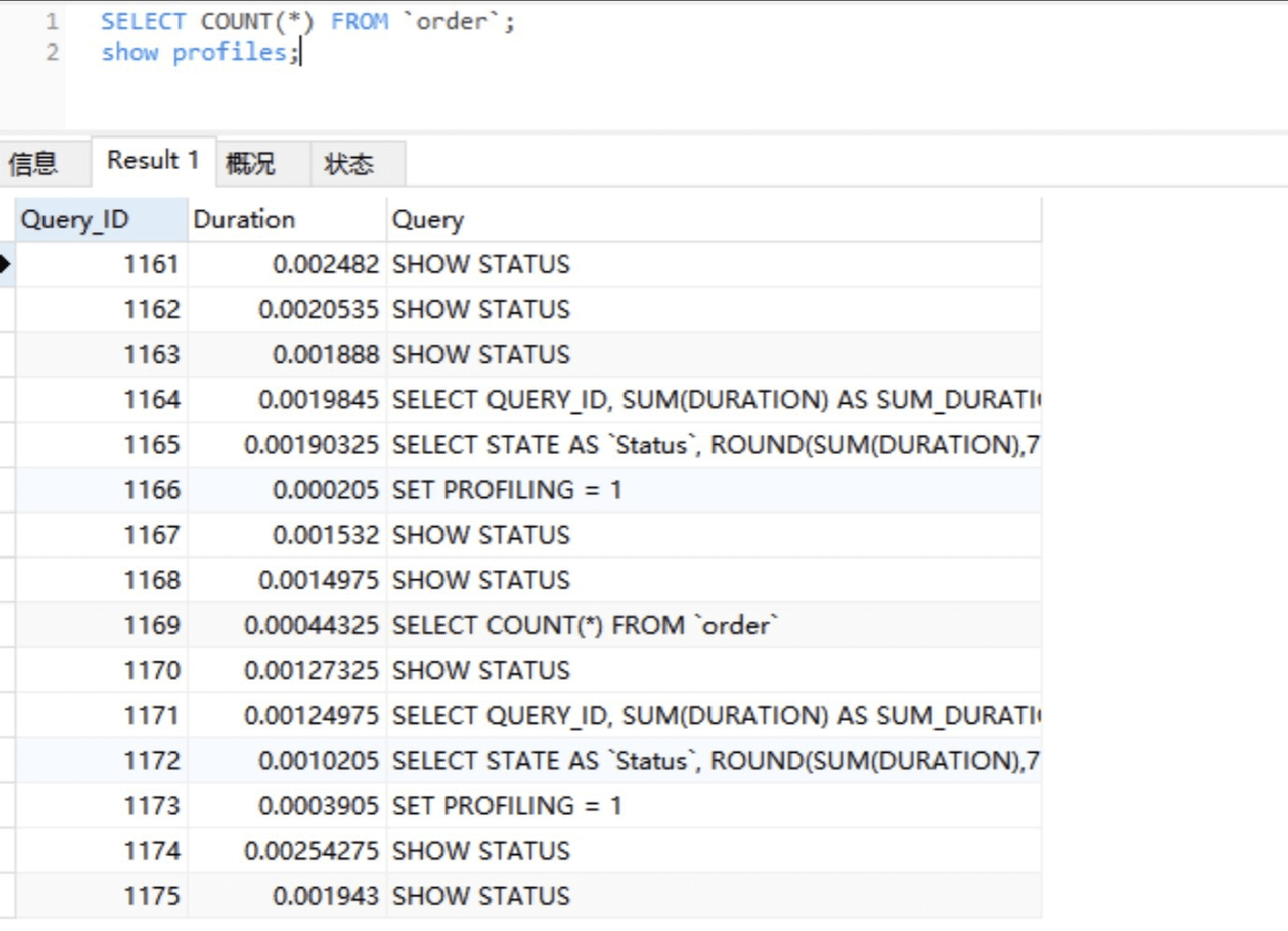
获取到Query_ID之后,我们再通过Show Profile for Query ID语句,就能够查看到对应Query_ID的SQL语句在执⾏过程中线程
的每个状态所消耗的时间了:
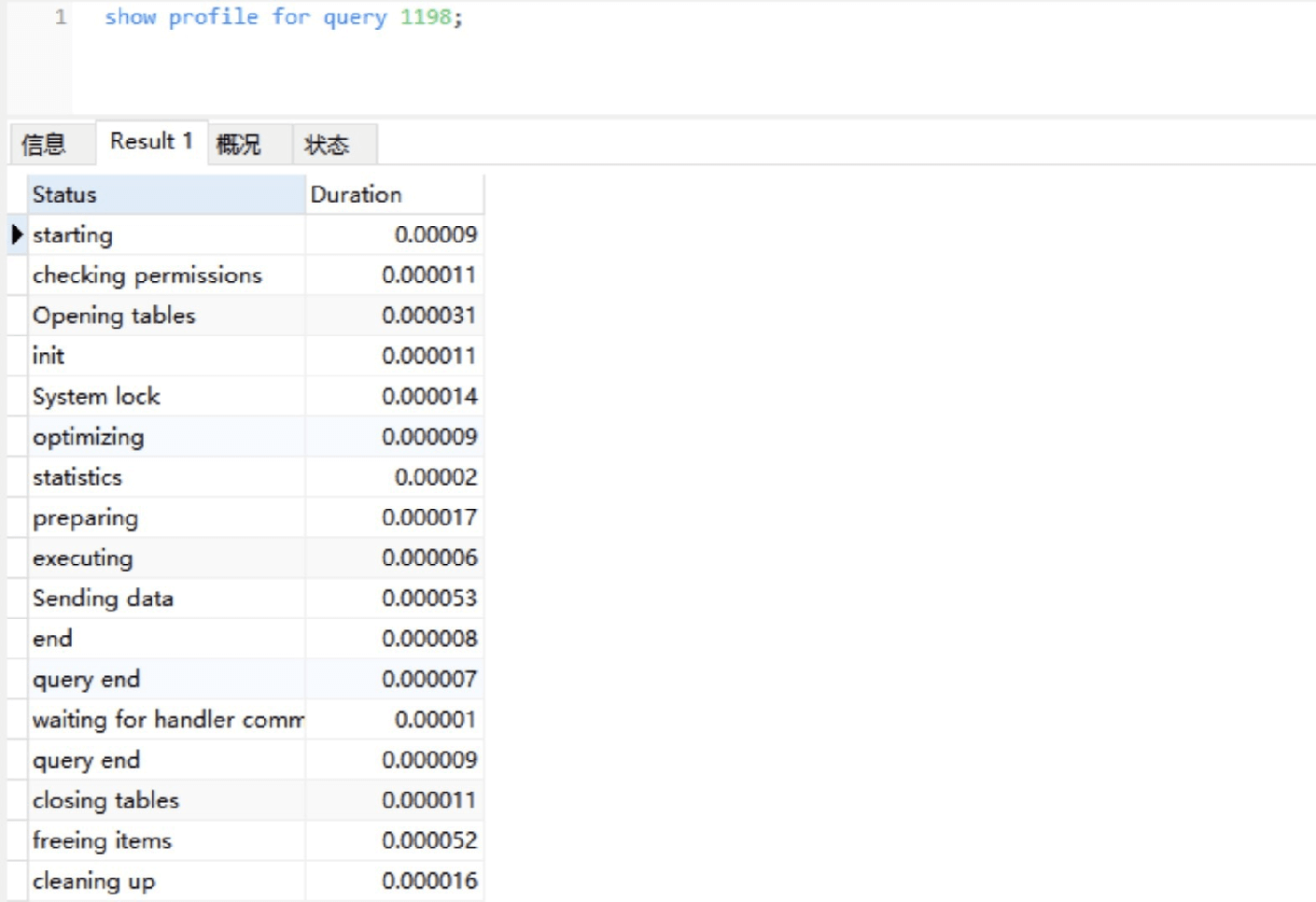
通过以上分析可知:SELECT COUNT(*) FROM order; SQL语句在Sending data状态所消耗的时间最⻓,这是因为在该状态
下,MySQL线程开始读取数据并返回到客户端,此时有⼤量磁盘I/O操作。
常⽤的SQL优化
在使⽤⼀些常规的SQL时,如果我们通过⼀些⽅法和技巧来优化这些SQL的实现,在性能上就会⽐使⽤常规通⽤的实现⽅式更加优越,甚⾄可以将SQL语句的性能提升到另⼀个数量级。
优化分⻚查询
通常我们是使⽤
这是因为我们在使⽤LIMIT的时候,偏移量M在分⻚越靠后的时候,值就越⼤,数据库检索的数据也就越多。例如 LIMIT
10000,10这样的查询,数据库需要查询10010条记录,最后返回10条记录。也就是说将会有10000条记录被查询出来没有被使
⽤到。
我们模拟⼀张10万数量级的order表,进⾏以下分⻚查询:
select * from demo.order order by order_no limit 10000, 20;
通过EXPLAIN分析可知:该查询使⽤到了索引,扫描⾏数为10020⾏,但所⽤查询时间为0.018s,相对来说时间偏⻓了。


利⽤⼦查询优化分⻚查询
以上分⻚查询的问题在于,我们查询获取的10020⾏数据结果都返回给我们了,我们能否先查询出所需要的20⾏数据中的最⼩
ID值,然后通过偏移量返回所需要的20⾏数据给我们呢?我们可以通过索引覆盖扫描,使⽤⼦查询的⽅式来实现分⻚查询:
select * from demo.order where id> (select id from demo.order order by order_no limit 10000, 1) limit |
|---|
 |
通过EXPLAIN分析可知:⼦查询遍历索引的范围跟上⼀个查询差不多,⽽主查询扫描了更多的⾏数,但执⾏时间却减少了, 只有0.004s。这就是因为返回⾏数只有20⾏了,执⾏效率得到了明显的提升。

优化SELECT COUNT(*)
COUNT()是⼀个聚合函数,主要⽤来统计⾏数,有时候也⽤来统计某⼀列的⾏数量(不统计NULL值的⾏)。我们平时最常⽤的就是COUNT(*)和COUNT(1)这两种⽅式了,其实两者没有明显的区别,在拥有主键的情况下,它们都是利⽤主键列实现了
⾏数的统计。
但COUNT()函数在MyISAM和InnoDB存储引擎所执⾏的原理是不⼀样的,通常在没有任何查询条件下的COUNT(*),MyISAM 的查询速度要明显快于InnoDB。
这是因为MyISAM存储引擎记录的是整个表的⾏数,在COUNT(*)查询操作时⽆需遍历表计算,直接获取该值即可。⽽在
InnoDB存储引擎中就需要扫描表来统计具体的⾏数。⽽当带上where条件语句之后,MyISAM跟InnoDB就没有区别了,它们都需要扫描表来进⾏⾏数的统计。
如果对⼀张⼤表经常做SELECT COUNT(*)操作,这肯定是不明智的。那么我们该如何对⼤表的COUNT()进⾏优化呢?
使⽤近似值
有时候某些业务场景并不需要返回⼀个精确的COUNT值,此时我们可以使⽤近似值来代替。我们可以使⽤EXPLAIN对表进⾏估算,要知道,执⾏EXPLAIN并不会真正去执⾏查询,⽽是返回⼀个估算的近似值。
增加汇总统计
如果需要⼀个精确的COUNT值,我们可以额外新增⼀个汇总统计表或者缓存字段来统计需要的COUNT值,这种⽅式在新增和删除时有⼀定的成本,但却可以⼤⼤提升COUNT()的性能。
优化SELECT *
我曾经看过很多同事习惯在只查询⼀两个字段时,都使⽤select * from table where xxx这样的SQL语句,这种写法在特定的环境下会存在⼀定的性能损耗。
MySQL常⽤的存储引擎有MyISAM和InnoDB,其中InnoDB在默认创建主键时会创建主键索引,⽽主键索引属于聚簇索引,即在存储数据时,索引是基于B +树构成的,具体的⾏数据则存储在叶⼦节点。
⽽MyISAM默认创建的主键索引、⼆级索引以及InnoDB的⼆级索引都属于⾮聚簇索引,即在存储数据时,索引是基于B +树构成的,⽽叶⼦节点存储的是主键值。
假设我们的订单表是基于InnoDB存储引擎创建的,且存在order_no、status两列组成的组合索引。此时,我们需要根据订单号查询⼀张订单表的status,如果我们使⽤select * from order where order_no=’xxx’来查询,则先会查询组合索引,通过组合索引获取到主键ID,再通过主键ID去主键索引中获取对应⾏所有列的值。
如果我们使⽤select order_no, status from order where order_no=’xxx’来查询,则只会查询组合索引,通过组合索引获取到对应的order_no和status的值。如果你对这些索引还不够熟悉,请重点关注之后的第34讲,那⼀讲会详述数据库索引的相关内 容。
总结
在开发中,我们要尽量写出⾼性能的SQL语句,但也⽆法避免⼀些慢SQL语句的出现,或因为疏漏,或因为实际⽣产环境与开发环境有所区别,这些都是诱因。⾯对这种情况,我们可以打开慢SQL配置项,记录下都有哪些SQL超过了预期的最⼤执⾏时间。⾸先,我们可以通过以下命令⾏查询是否开启了记录慢SQL的功能,以及最⼤的执⾏时间是多少:
Show variables like ‘slow_query%’; Show variables like ‘long_query_time’;
如果没有开启,我们可以通过以下设置来开启:
set global slow_query_log=’ON’; //开启慢SQL⽇志
set global slow_query_log_file=’/var/lib/mysql/test-slow.log’;//记录⽇志地址set global long_query_time=1;//最⼤执⾏时间
除此之外,很多数据库连接池中间件也有分析慢SQL的功能。总之,我们要在编程中避免低性能的SQL操作出现,除了要具备
⼀些常⽤的SQL优化技巧之外,还要充分利⽤⼀些SQL⼯具,实现SQL性能分析与监控。
思考题
假设有⼀张订单表order,主要包含了主键订单编码order_no、订单状态status、提交时间create_time等列,并且创建了status
列索引和create_time列索引。此时通过创建时间降序获取状态为1的订单编码,以下是具体实现代码:
select order_no from order where status =1 order by create_time desc
你知道其中的问题所在吗?我们⼜该如何优化?
期待在留⾔区看到你的答案。也欢迎你点击“请朋友读”,把今天的内容分享给身边的朋友,邀请他⼀起讨论。
精选留⾔ <br />张学磊<br />status和create_time单独建索引,在查询时只会遍历status索引对数据进⾏过滤,不会⽤到create_time列索引,将符合条件的数据返回到server层,在server对数据通过快排算法进⾏排序,Extra列会出现file sort;应该利⽤索引的有序性,在status和cre<br />ate_time列建⽴联合索引,这样根据status过滤后的数据就是按照create_time排好序的,避免在server层排序<br />2019-08-06 09:02<br />作者回复<br />⾮常准确!<br />2019-08-06 11:06
 QQ怪
QQ怪
对staus和create_time建⽴联合索引
2019-08-06 09:30
作者回复
对的,为了避免⽂件排序的发⽣。因为查询时我们只能⽤到status索引,如果要对create_time进⾏排序,则需要使⽤⽂件排序fi
lesort。
filesort是通过相应的排序算法将取得的数据在内存中进⾏排序,如果内存不够则会使⽤磁盘⽂件作为辅助。虽然在⼀些场景中
,filesort并不是特别消耗性能,但是我们可以避免filesort就尽量避免。
2019-08-06 11:05
 迎⻛劲草
迎⻛劲草
创建 status create_time order_no 联合索引,避免回表
2019-08-06 08:29
作者回复
建⽴联合索引没错,还有就是避免⽂件排序的问题。
2019-08-06 11:08
 Jian
Jian
因为好久没有做SQL相关的开发了,所以开始没有特别明⽩【利⽤⼦查询优化分⻚查询】这⾥⾯的意思。我来说下⾃⼰的想法
,请您检证。我看到您贴的截图中,优化后的sql语句,扫描的⾏数(rows列)分别是90409和10001,多余前⼀个较慢的查询
,可⻅扫描⾏数,不是这个性能的主要原因。我推测这个是由于limit [m],n的实现⽅法导致的,即MySql会把m+n的数据都取出来,然后返回n个数据给⽤户。如果⽤第⼆种SQL语句,⼦查询只是获得⼀个id,虽然扫描了很多⾏,但都是在索引上进⾏的, 切不需要回表获取内容。外查询是根据id获取数据20条内容,速度⾃然就会快了。我认为这⾥性能提⾼的原因还是居于索引的恰当使⽤。
2019-08-12 09:24
 JackJin
JackJin
感觉要建⽴联合索引,但不知具体原因
2019-08-09 10:08
作者回复
为了避免⽂件排序的发⽣。因为查询时我们只能⽤到status索引,如果要对create_time进⾏排序,则需要使⽤⽂件排序filesort
。
2019-08-12 10:00
 Geek_002ff7
Geek_002ff7
真实情况⼀般不会在status上单独建索引,因为status⼤部分都是重复值,数据库⼀般⾛全表扫描了,感觉漏讲了索引失效的情况
2019-08-09 09:30
作者回复
下⼀讲则会讲到
2019-08-12 10:02
 东⽅奇骥
东⽅奇骥
select from demo.order order by order_no limit 10000, 20;
select from demo.order where id> (select id from demo.order order by order_no limit 10000, 1) limit 20; ⽼师,感觉⾃
⼰没完全弄明⽩,就是⽤⼦查询快那么多,但是⼦查询⾥,不是也要扫描10001⾏?还是说⼦查询⾥只查了id,不需要回⾏, 所以速度快?
2019-08-08 11:22
作者回复
这个涉及到返回记录的⼤⼩,前者会返回10020条⾏记录,⽽后者只返回20条记录。
2019-08-09 09:39
 Kian.Lee
Kian.Lee
我在实际项⽬中使⽤“select order_no from order where status =1 order by id desc
” 代替此功能,id为bigint ,也少维护⼀个索引(create_time)
2019-08-08 08:07
 LW
LW
order_no创建主键,status+create_time创建联合索引
2019-08-06 10:29
作者回复
对的
2019-08-06 11:05
 撒旦的堕落
撒旦的堕落
订单状态字段的离散度很低 不适合做索引
因为离散度低 ⽽⼜没有分⻚ 所以当表数据量⼤的时候 查询出来的数量也有可能很⼤
创建时间倒序 可以换成主键倒序 去除掉时间字段的索引
根据状态查询 个⼈觉得可以从业务⼊⼿ 将相同状态的数据保存到⼀张表 想听听⽼师的意⻅
2019-08-06 09:29
作者回复
这⾥主要是filesort问题
2019-08-06 11:07
 nimil
nimil
select * from table limit 1 这种sql语句会⾛主键索引么,我看explain⾥边没有任何索引记录
2019-08-06 08:53
作者回复
不会,没有使⽤到索引。
2019-08-06 11:06
⻔窗⼩⼆
创建status,创建时间及订单号联合索引,其中创建时间制定降序,这样避免产⽣filesort及回表!不知道是否正确?
2019-08-06 08:18
作者回复
对的,赞
2019-08-06 11:15
 我知道了嗯
我知道了嗯
感觉订单状态不需要索引
2019-08-06 08:12
 Zed
Zed
这⾥感觉有俩缺陷
1、会全表排序
2、订单状态过滤效果不佳
2019-08-06 07:31

若有收获,就点个赞吧
0 人点赞
