 43讲如何使⽤缓存优化系统性能
43讲如何使⽤缓存优化系统性能
你好,我是刘超。
 缓存是我们提⾼系统性能的⼀项必不可少的技术,⽆论是前端、还是后端,都应⽤到了缓存技术。前端使⽤缓存,可以降低多次请求服务的压⼒;后端使⽤缓存,可以降低数据库操作的压⼒,提升读取数据的性能。
缓存是我们提⾼系统性能的⼀项必不可少的技术,⽆论是前端、还是后端,都应⽤到了缓存技术。前端使⽤缓存,可以降低多次请求服务的压⼒;后端使⽤缓存,可以降低数据库操作的压⼒,提升读取数据的性能。
今天我们将从前端到服务端,系统了解下各个层级的缓存实现,并分别了解下各类缓存的优缺点以及应⽤场景。
前端缓存技术
如果你是⼀位Java开发⼯程师,你可能会想,我们有必要去了解前端的技术吗?
不想当将军的⼠兵不是好⼠兵,作为⼀个技术⼈员,不想做架构师的开发不是好开发。作为架构⼯程师的话,我们就很有必要去了解前端的知识点了,这样有助于我们设计和优化系统。前端做缓存,可以缓解服务端的压⼒,减少带宽的占⽤,同时也可以提升前端的查询性能。
本地缓存
平时使⽤拦截器(例如Fiddler)或浏览器Debug时,我们经常会发现⼀些接⼝返回304状态码+ Not Modified字符串,如下图中的极客时间Web⾸⻚。
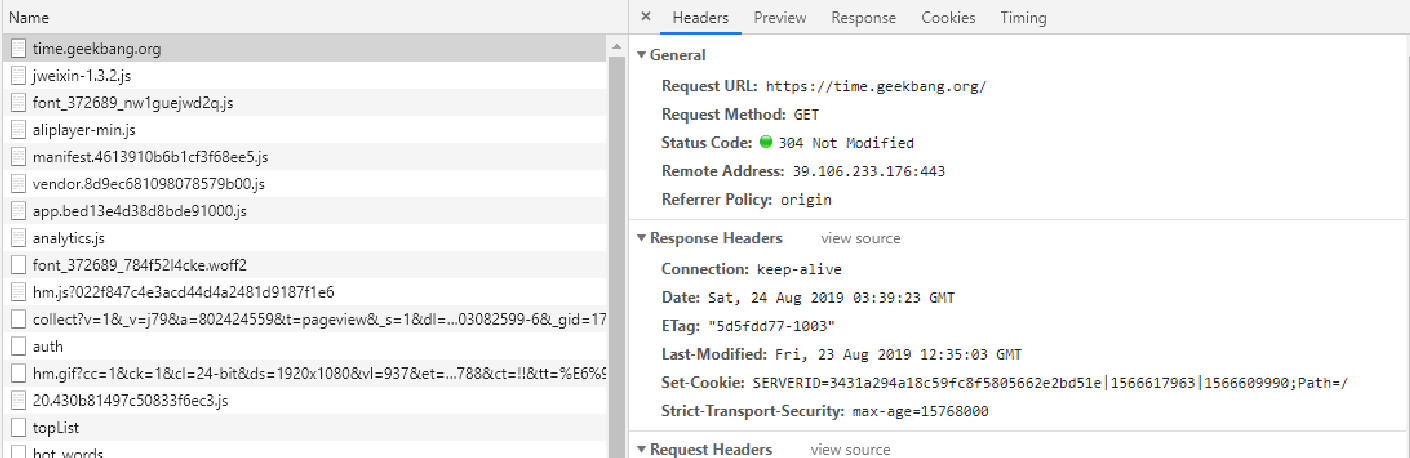
如果我们对前端缓存技术不了解,就很容易对此感到困惑。浏览器常⽤的⼀种缓存就是这种基于304响应状态实现的本地缓存
了,通常这种缓存被称为协商缓存。
协商缓存,顾名思义就是与服务端协商之后,通过协商结果来判断是否使⽤本地缓存。
⼀般协商缓存可以基于请求头部中的If-Modified-Since字段与返回头部中的Last-Modified字段实现,也可以基于请求头部中的
If-None-Match字段与返回头部中的ETag字段来实现。
两种⽅式的实现原理是⼀样的,前者是基于时间实现的,后者是基于⼀个唯⼀标识实现的,相对来说后者可以更加准确地判断
⽂件内容是否被修改,避免由于时间篡改导致的不可靠问题。下⾯我们再来了解下整个缓存的实现流程:
当浏览器第⼀次请求访问服务器资源时,服务器会在返回这个资源的同时,在Response头部加上ETag唯⼀标识,这个唯⼀
标识的值是根据当前请求的资源⽣成的;
当浏览器再次请求访问服务器中的该资源时,会在Request头部加上If-None-Match字段,该字段的值就是Response头部加上ETag唯⼀标识;
服务器再次收到请求后,会根据请求中的If-None-Match值与当前请求的资源⽣成的唯⼀标识进⾏⽐较,如果值相等,则返回304 Not Modified,如果不相等,则在Response头部加上新的ETag唯⼀标识,并返回资源;
如果浏览器收到304的请求响应状态码,则会从本地缓存中加载资源,否则更新资源。本地缓存中除了这种协商缓存,还有⼀种就是强缓存的实现。
强缓存指的是只要判断缓存没有过期,则直接使⽤浏览器的本地缓存。如下图中,返回的是200状态码,但在size项中标识的是memory cache。
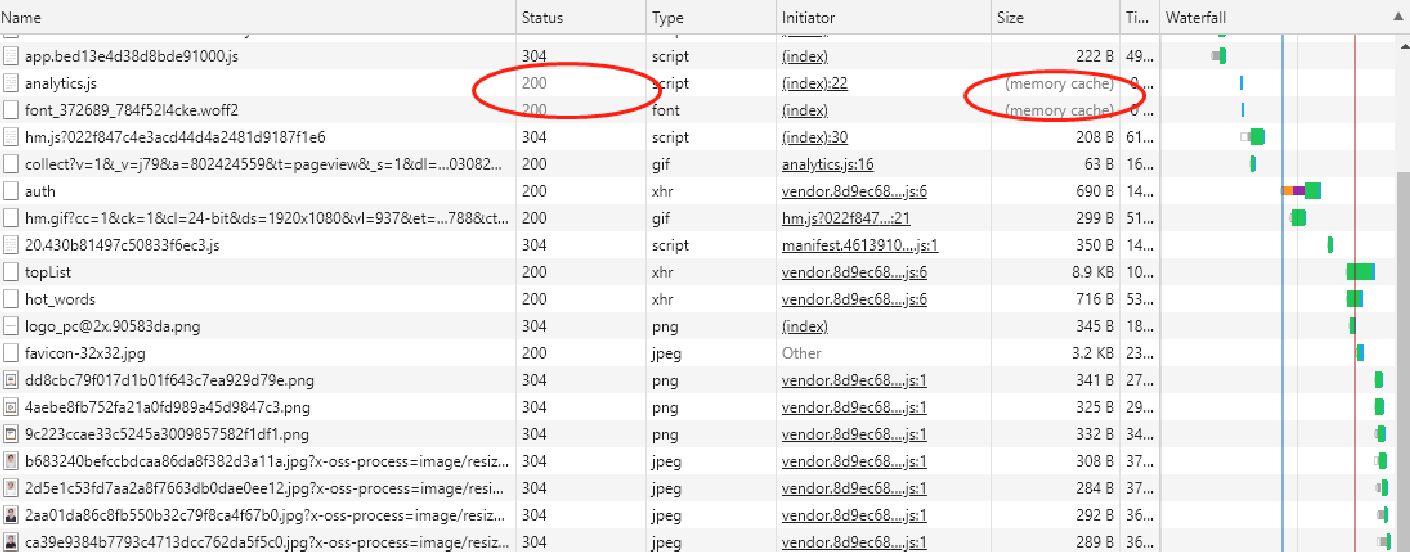
强缓存是利⽤Expires或者Cache-Control这两个HTTP Response Header实现的,它们都⽤来表示资源在客户端缓存的有效
期。
Expires是⼀个绝对时间,⽽Cache-Control是⼀个相对时间,即⼀个过期时间⼤⼩,与协商缓存⼀样,基于Expires实现的强缓存也会因为时间问题导致缓存管理出现问题。我建议使⽤Cache-Control来实现强缓存。具体的实现流程如下:
当浏览器第⼀次请求访问服务器资源时,服务器会在返回这个资源的同时,在Response头部加上Cache-Control,Cache-
Control中设置了过期时间⼤⼩;
浏览器再次请求访问服务器中的该资源时,会先通过请求资源的时间与Cache-Control中设置的过期时间⼤⼩,来计算出该资源是否过期,如果没有,则使⽤该缓存,否则请求服务器;
服务器再次收到请求后,会再次更新Response头部的Cache-Control。
⽹关缓存
除了以上本地缓存,我们还可以在⽹关中设置缓存,也就是我们熟悉的CDN。
CDN缓存是通过不同地点的缓存节点缓存资源副本,当⽤户访问相应的资源时,会调⽤最近的CDN节点返回请求资源,这种
⽅式常⽤于视频资源的缓存。
服务层缓存技术
前端缓存⼀般⽤于缓存⼀些不常修改的常量数据或⼀些资源⽂件,⼤部分接⼝请求的数据都缓存在了服务端,⽅便统⼀管理缓存数据。
服务端缓存的初衷是为了提升系统性能。例如,数据库由于并发查询压⼒过⼤,可以使⽤缓存减轻数据库压⼒;在后台管理中的⼀些报表计算类数据,每次请求都需要⼤量计算,消耗系统CPU资源,我们可以使⽤缓存来保存计算结果。
服务端的缓存也分为进程缓存和分布式缓存,在Java中进程缓存就是JVM实现的缓存,常⻅的有我们经常使⽤的容器类,ArrayList、ConcurrentHashMap等,分布式缓存则是基于Redis实现的缓存。
进程缓存
对于进程缓存,虽然数据的存取会更加⾼效,但JVM的堆内存数量是有限的,且在分布式环境下很难同步各个服务间的缓存更新,所以我们⼀般缓存⼀些数据量不⼤、更新频率较低的数据。常⻅的实现⽅式如下:
//静态常量
public final staticS String url = “https://time.geekbang.org“;
//list容器
public static List
//map容器
private static final Map
除了Java⾃带的容器可以实现进程缓存,我们还可以基于Google实现的⼀套内存缓存组件Guava Cache来实现。
Guava Cache适⽤于⾼并发的多线程缓存,它和ConcurrentHashMap⼀样,都是基于分段锁实现的并发缓存。
Guava Cache同时也实现了数据淘汰机制,当我们设置了缓存的最⼤值后,当存储的数据超过了最⼤值时,它就会使⽤LRU
算法淘汰数据。我们可以通过以下代码了解下Guava Cache的实现:
public class GuavaCacheDemo {
public static void main(String[] args) { Cache
.maximumSize(2)
.build(); cache.put(“key1”,”value1”);
cache.put(“key2”,”value2”);
cache.put(“key3”,”value3”);
System.out.println(“第⼀个值:” + cache.getIfPresent(“key1”));
System.out.println(“第⼆个值:” + cache.getIfPresent(“key2”));
System.out.println(“第三个值:” + cache.getIfPresent(“key3”));
}
}
运⾏结果:
第⼀个值:null 第⼆个值:value2第三个值:value3
那如果我们的数据量⽐较⼤,且数据更新频繁,⼜是在分布式部署的情况下,想要使⽤JVM堆内存作为缓存,这时我们⼜该如何去实现呢?
Ehcache是⼀个不错的选择,Ehcache经常在Hibernate中出现,主要⽤来缓存查询数据结果。Ehcache是Apache开源的⼀套缓存管理类库,是基于JVM堆内存实现的缓存,同时具备多种缓存失效策略,⽀持磁盘持久化以及分布式缓存机制。
分布式缓存
由于⾼并发对数据⼀致性的要求⽐较严格,我⼀般不建议使⽤Ehcache缓存有⼀致性要求的数据。对于分布式缓存,我们建议使⽤Redis来实现,Redis相当于⼀个内存数据库,由于是纯内存操作,⼜是基于单线程串⾏实现,查询性能极⾼,读速度超 过了10W次/秒。
Redis除了⾼性能的特点之外,还⽀持不同类型的数据结构,常⻅的有string、list、set、hash等,还⽀持数据淘汰策略、数据
持久化以及事务等。
两种缓存讲完了,接下来我们看看其中可能出现的问题。
数据库与缓存数据⼀致性问题
在查询缓存数据时,我们会先读取缓存,如果缓存中没有该数据,则会去数据库中查询,之后再放⼊到缓存中。
当我们的数据被缓存之后,⼀旦数据被修改(修改时也是删除缓存中的数据)或删除,我们就需要同时操作缓存和数据库。这时,就会存在⼀个数据不⼀致的问题。
例如,在并发情况下,当A操作使得数据发⽣删除变更,那么该操作会先删除缓存中的数据,之后再去删除数据库中的数据, 此时若是还没有删除成功,另外⼀个请求查询操作B进来了,发现缓存中已经没有了数据,则会去数据库中查询,此时发现有数据,B操作获取之后⼜将数据存放在了缓存中,随后数据库的数据⼜被删除了。此时就出现了数据不⼀致的情况。
那如果先删除数据库,再删除缓存呢?
我们可以试⼀试。在并发情况下,当A操作使得数据发⽣删除变更,那么该操作会先删除了数据库的操作,接下来删除缓存, 失败了,那么缓存中的数据没有被删除,⽽数据库的数据已经被删除了,同样会存在数据不⼀致的问题。
所以,我们还是需要先做缓存删除操作,再去完成数据库操作。那我们⼜该如何避免⾼并发下,数据更新删除操作所带来的数据不⼀致的问题呢?
通常的解决⽅案是,如果我们需要使⽤⼀个线程安全队列来缓存更新或删除的数据,当A操作变更数据时,会先删除⼀个缓存数据,此时通过线程安全的⽅式将缓存数据放⼊到队列中,并通过⼀个线程进⾏数据库的数据删除操作。
当有另⼀个查询请求B进来时,如果发现缓存中没有该值,则会先去队列中查看该数据是否正在被更新或删除,如果队列中有该数据,则阻塞等待,直到A操作数据库成功之后,唤醒该阻塞线程,再去数据库中查询该数据。
但其实这种实现也存在很多缺陷,例如,可能存在读请求被⻓时间阻塞,⾼并发时低吞吐量等问题。所以我们在考虑缓存时, 如果数据更新⽐较频繁且对数据有⼀定的⼀致性要求,我通常不建议使⽤缓存。
缓存穿透、缓存击穿、缓存雪崩
对于分布式缓存实现⼤数据的存储,除了数据不⼀致的问题以外,还有缓存穿透、缓存击穿、缓存雪崩等问题,我们平时实现缓存代码时,应该充分、全⾯地考虑这些问题。
缓存穿透是指⼤量查询没有命中缓存,直接去到数据库中查询,如果查询量⽐较⼤,会导致数据库的查询流量⼤,对数据库造成压⼒。
通常有两种解决⽅案,⼀种是将第⼀次查询的空值缓存起来,同时设置⼀个⽐较短的过期时间。但这种解决⽅案存在⼀个安全漏洞,就是当⿊客利⽤⼤量没有缓存的key攻击系统时,缓存的内存会被占满溢出。
另⼀种则是使⽤布隆过滤算法(BloomFilter),该算法可以⽤于检查⼀个元素是否存在,返回结果有两种:可能存在或⼀定不存在。这种情况很适合⽤来解决故意攻击系统的缓存穿透问题,在最初缓存数据时也将key值缓存在布隆过滤器的BitArray
中,当有key值查询时,对于⼀定不存在的key值,我们可以直接返回空值,对于可能存在的key值,我们会去缓存中查询,如果没有值,再去数据库中查询。
BloomFilter的实现原理与Redis中的BitMap类似,⾸先初始化⼀个m⻓度的数组,并且每个bit初始化值都是0,当插⼊⼀个元素时,会使⽤n个hash函数来计算出n个不同的值,分别代表所在数组的位置,然后再将这些位置的值设置为1。
假设我们插⼊两个key值分别为20,28的元素,通过两次哈希函数取模后的值分别为4,9以及14,19,因此4,9以及14,19都被设置
为1。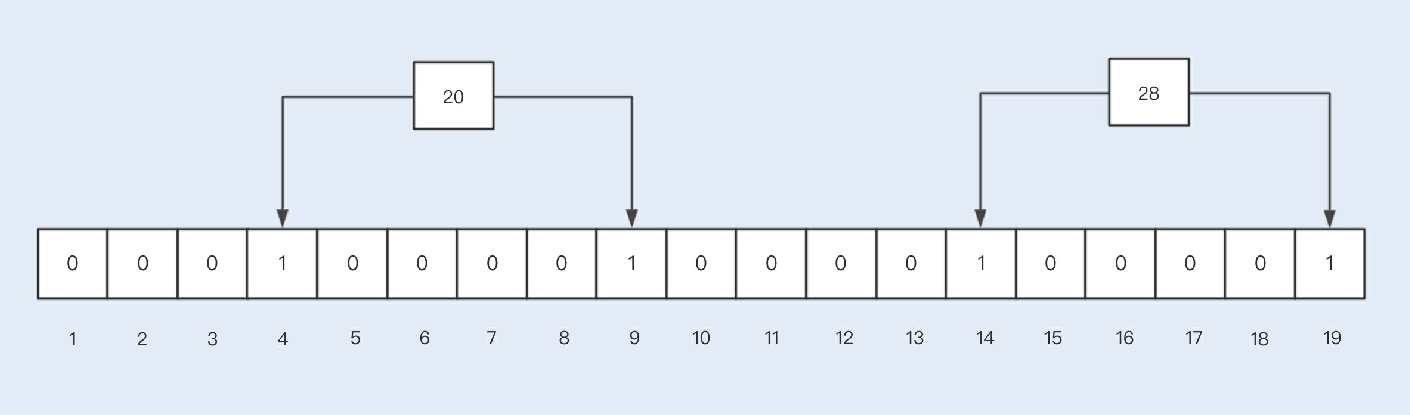
那为什么说BloomFilter返回的结果是可能存在和⼀定不存在呢?
假设我们查找⼀个元素25,通过n次哈希函数取模后的值为1,9,14。此时在BitArray中肯定是不存在的。⽽当我们查找⼀个元素
21的时候,n次哈希函数取模后的值为9,14,此时会返回可能存在的结果,但实际上是不存在的。
BloomFilter不允许删除任何元素的,为什么?假设以上20,25,28三个元素都存在于BitArray中,取模的位置值分别为4,9、
1,9,14以及14,19,如果我们要删除元素25,此时需要将1,9,14的位置都置回0,这样就影响20,28元素了。
因此,BloomFilter是不允许删除任何元素的,这样会导致已经删除的元素依然返回可能存在的结果,也会影响BloomFilter判断的准确率,解决的⽅法则是重建⼀个BitArray。
那什么缓存击穿呢?在⾼并发情况下,同时查询⼀个key时,key值由于某种原因突然失效(设置过期时间或缓存服务宕
机),就会导致同⼀时间,这些请求都去查询数据库了。这种情况经常出现在查询热点数据的场景中。通常我们会在查询数据库时,使⽤排斥锁来实现有序地请求数据库,减少数据库的并发压⼒。
缓存雪崩则与缓存击穿差不多,区别就是失效缓存的规模。雪崩⼀般是指发⽣⼤规模的缓存失效情况,例如,缓存的过期时间同⼀时间过期了,缓存服务宕机了。对于⼤量缓存的过期时间同⼀时间过期的问题,我们可以采⽤分散过期时间来解决;⽽针对缓存服务宕机的情况,我们可以采⽤分布式集群来实现缓存服务。
总结
从前端到后端,对于⼀些不常变化的数据,我们都可以将其缓存起来,这样既可以提⾼查询效率,⼜可以降低请求后端的压
⼒。对于前端来说,⼀些静态资源⽂件都是会被缓存在浏览器端,除了静态资源⽂件,我们还可以缓存⼀些常量数据,例如商品信息。
服务端的缓存,包括了JVM的堆内存作为缓存以及Redis实现的分布式缓存。如果是⼀些不常修改的数据,数据量⼩,且对缓 存数据没有严格的⼀致性要求,我们就可以使⽤堆内存缓存数据,这样既实现简单,查询也⾮常⾼效。如果数据量⽐较⼤,且是经常被修改的数据,或对缓存数据有严格的⼀致性要求,我们就可以使⽤分布式缓存来存储。
在使⽤后端缓存时,我们应该注意数据库和缓存数据的修改导致的数据不⼀致问题,如果对缓存与数据库数据有⾮常严格的⼀致性要求,我就不建议使⽤缓存了。
同时,我们应该针对⼤量请求缓存的接⼝做好预防⼯作,防⽌查询缓存的接⼝出现缓存穿透、缓存击穿和缓存雪崩等问题。
思考题
在基于Redis实现的分布式缓存中,我们更新数据时,为什么建议直接将缓存中的数据删除,⽽不是更新缓存中的数据呢?
期待在留⾔区看到你的答案。也欢迎你点击“请朋友读”,把今天的内容分享给身边的朋友,邀请他⼀起讨论。
精选留⾔ <br />QQ怪<br />学到了很多,挺收益的,思考题:更新效率太低,代价很⼤,且不⼀定被访问的频率⾼,不⾼则没必要缓存,还不如直接删掉<br />,⽽且还容易出现数据不⼀致问题<br />2019-08-29 22:36<br />作者回复<br />对的,两个并发写去更新还存在⼀致性的问题。不过,在删除缓存后,记得读取数据需要加锁或延时等待,防⽌读取脏数据。<br />2019-08-30 09:20
 yungoo
yungoo
基于redis集中缓存更新数据采⽤删除⽽不是直接更新缓存的原因之⼀:避免⼆类更新丢失问题。
分布式系统中当存在并发数据更新时,因⽆法保证更新操作顺序的时间⼀致性,从⽽导致旧值覆盖新值。如:
t1时间点,A进程发起更新key1为1的P1操作。
t1+x时间点,B进程发起更新key1为2的P2操作。其中P1 -> P2,数据库中值为2。
⽽redis收到的指令,可能因⽹络抖动或者STW,实际为P2 -> P1,缓存的值为1,造成数据不⼀致。
2019-08-29 06:58
作者回复
存在并发更新时数据不⼀致问题
2019-08-30 09:58
 Better me
Better me
布隆过滤器为什么要经过n个hash函数散列,有什么特别的考虑吗
2019-08-29 21:34
作者回复
这是为了计算不同的位置,通过不同位置置1,得出⼀个数值。
2019-08-30 09:21
 AiSmart4J
AiSmart4J
还有就是更新缓存代价⼤。如果缓存⾥的数据不是把数据库⾥的数据直接存下来,⽽是需要经过某种复杂的运算,那么这种不必要的更新会带来更⼤的浪费。
2019-08-29 07:32
作者回复
对的,这也是⼀种情况
2019-08-30 09:57
 AiSmart4J
AiSmart4J
如果是更新数据库再操作缓存的话,此时更新缓存的操作不是必须的。可能缓存⾥的数据并没有被读到,就会被下⼀次更新My
SQL操作带来Redis更新操作覆盖,那么本次更新操作就是⽆意义的。
2019-08-29 07:31
 godtrue
godtrue
我觉得看场景,我们是电商的核⼼系统,计算全部依赖缓存,我们的缓存是经过复杂计算的结构数据,每天定时任务刷新,更新是全部是先添加有效数据后删除⽆效数据。添加有效数据时,如果数据存在就是更新操作了啦!我觉得挺OK的
2019-09-12 23:14
 Liam
Liam
把数据库的数据全部加载到bitmap?
2019-09-05 09:19
作者回复
是的
2019-09-07 11:36
 Liam
Liam
bloom filter怎么初始化呢?刚开始bit array都是0吧,不可能直接拒绝掉呀?难道是把数据库的
2019-09-05 09:19
作者回复
初始化时将数据加载到bit array中
2019-09-07 11:37
 Maxwell
Maxwell
⽼师⾼并发时会不会卡?影响吞吐量,涉及到要更改公⽤数据如消费积分总量、每天的消费积分额度,现在没加锁,靠数据库的事务更新,担⼼以后qps上来了数据库扛不住
2019-08-30 23:41
作者回复
使⽤队列来异步更新数据,没有压⼒
2019-09-07 11:55
 victoriest
victoriest
只看 模块七 值回票价
2019-08-30 10:28 疯狂咸⻥
疯狂咸⻥
浏览器缓存就是常说的http缓存么?
2019-08-29 23:48
作者回复
对的
2019-08-30 10:05
 许童童
许童童
直接更新缓存中的数据,因为请求到达的顺序⽆法保证,有可能后请求的数据覆盖前请求的数据。直接将数据删除,就是⼀种幂等的操作,删除后,再去数据库拉数据,就不会有覆写的问题。
2019-08-29 14:40
作者回复
对的,如果两个并发写去更新还存在⼀致性的问题,还不如直接删除,等下次读取的时候再次写⼊缓存中。不过,在删除缓存
后,记得读取数据需要加锁或延时等待,防⽌读取脏数据。
2019-08-30 09:38
 Loubobooo
Loubobooo
课后题:原因很简单
- 很多时候,在复杂点的缓存场景,缓存不单单是数据库中直接取出来的值。⽐如可能更新了某个表的⼀个字段,然后其对应的缓存,是需要查询另外两个表的数据并进⾏运算,才能计算出缓存最新的值的。
另外更新缓存的代价有时候是很⾼的。每次修改数据库的时候,都⼀定要将其对应的缓存更新⼀份,这样做的代价较⾼。如果遇到复杂的缓存数据计算的场景,缓存频繁更新,但这个缓存到底会不会被频繁访问到?如果没有,这个缓存的效率就很低了
2019-08-29 14:19
作者回复
回答很全⾯
2019-08-30 09:40
 撒旦的堕落
撒旦的堕落
⽼师说 缓存数据库⼀致性问题时 当⼀个线程缓存删除 ⽽数据库中没有来得及删除时 另⼀个线程来请求数据 发现缓存中数据不存在去队列中判断 如果数据在更新中 则等待 然后唤醒 不过如果是不同进程中的线程呢 怎么唤醒?感觉这种⽅式要维护的数据更多了 要把删除的缓存取出来放到队列中 然后更新完成后 还要删除队列中的数据 为了应对分布式的情况 还要使⽤的是分布式队列 效率变低了 有⽊有更好的办法呢
2019-08-29 09:30
作者回复
暂时没有想到更好的
2019-08-30 10:02
 Maxwell
Maxwell
⽼师您说的:通常我们会在查询数据库时,使⽤排斥锁来实现有序地请求数据库,减少数据库的并发压⼒。这个通常哪些⽅案
?
2019-08-29 09:18
作者回复
最常⽤的就是使⽤同步锁或Lock锁实现。
2019-08-30 09:50
 -W.LI-
-W.LI-
⽼师真棒,全能。
CDN的缓存策略是copy服务端的,协商缓存和强缓存?如果有些静态资源,服务端开发没做缓存策略,CDN还会缓存么?实际 开发中⽤过⼀次CDN。是在资源路径前,拼接⼀段CDN路径。具体不知
课后习题,如果并发操作时,虽然redis是单线程的但是没法保证⽹络延时下,先更新数据库。也先更新缓存。个⼈感觉失效⼀个key⽐写⼀个key开销⼩。⽹络传输上看,update还得传⼀个value的值,redis更新还得写缓存感觉也是失效慢。并发情况写两次(除开正确性)有⼀次的写完全浪费。
2019-08-29 08:10
作者回复
通常我们是会指定⼀些静态资源⽂件上传到CDN上去,并且通过版本号来更新。例如,我们的js资源⽂件是 xxx001.js,如果我们更新了该资源⽂件,则将xxx002.js推送到CDN上,同时前端的访问路径也更新访问资源路径。
2019-08-30 09:57

若有收获,就点个赞吧
0 人点赞
