 09讲⽹络通信优化之序列化:避免使⽤Java序列化
09讲⽹络通信优化之序列化:避免使⽤Java序列化
你好,我是刘超。
当前⼤部分后端服务都是基于微服务架构实现的。服务按照业务划分被拆分,实现了服务的解耦,但同时也带来了新的问题, 不同业务之间通信需要通过接⼝实现调⽤。两个服务之间要共享⼀个数据对象,就需要从对象转换成⼆进制流,通过⽹络传 输,传送到对⽅服务,再转换回对象,供服务⽅法调⽤。这个编码和解码过程我们称之为序列化与反序列化。

在⼤量并发请求的情况下,如果序列化的速度慢,会导致请求响应时间增加;⽽序列化后的传输数据体积⼤,会导致⽹络吞吐量下降。所以⼀个优秀的序列化框架可以提⾼系统的整体性能。
我们知道,Java提供了RMI框架可以实现服务与服务之间的接⼝暴露和调⽤,RMI中对数据对象的序列化采⽤的是Java序列 化。⽽⽬前主流的微服务框架却⼏乎没有⽤到Java序列化,SpringCloud⽤的是Json序列化,Dubbo虽然兼容了Java序列化, 但默认使⽤的是Hessian序列化。这是为什么呢?
今天我们就来深⼊了解下Java序列化,再对⽐近两年⽐较⽕的Protobuf序列化,看看Protobuf是如何实现最优序列化的。
Java序列化
在说缺陷之前,你先得知道什么是Java序列化以及它的实现原理。
Java提供了⼀种序列化机制,这种机制能够将⼀个对象序列化为⼆进制形式(字节数组),⽤于写⼊磁盘或输出到⽹络,同时也能从⽹络或磁盘中读取字节数组,反序列化成对象,在程序中使⽤。
JDK提供的两个输⼊、输出流对象ObjectInputStream和ObjectOutputStream,它们只能对实现了Serializable接⼝的类的对象
进⾏反序列化和序列化。
ObjectOutputStream的默认序列化⽅式,仅对对象的⾮transient的实例变量进⾏序列化,⽽不会序列化对象的transient的实例变量,也不会序列化静态变量。
在实现了Serializable接⼝的类的对象中,会⽣成⼀个serialVersionUID的版本号,这个版本号有什么⽤呢?它会在反序列化过程中来验证序列化对象是否加载了反序列化的类,如果是具有相同类名的不同版本号的类,在反序列化中是⽆法获取对象的。
具体实现序列化的是writeObject和readObject,通常这两个⽅法是默认的,当然我们也可以在实现Serializable接⼝的类中对其进⾏重写,定制⼀套属于⾃⼰的序列化与反序列化机制。
另外,Java序列化的类中还定义了两个重写⽅法:writeReplace()和readResolve(),前者是⽤来在序列化之前替换序列化对象的,后者是⽤来在反序列化之后对返回对象进⾏处理的。
Java序列化的缺陷
如果你⽤过⼀些RPC通信框架,你就会发现这些框架很少使⽤JDK提供的序列化。其实不⽤和不好⽤多半是挂钩的,下⾯我们就⼀起来看看JDK默认的序列化到底存在着哪些缺陷。
1.⽆法跨语⾔
现在的系统设计越来越多元化,很多系统都使⽤了多种语⾔来编写应⽤程序。⽐如,我们公司开发的⼀些⼤型游戏就使⽤了多种语⾔,C++写游戏服务,Java/Go写周边服务,Python写⼀些监控应⽤。
⽽Java序列化⽬前只适⽤基于Java语⾔实现的框架,其它语⾔⼤部分都没有使⽤Java的序列化框架,也没有实现Java序列化 这套协议。因此,如果是两个基于不同语⾔编写的应⽤程序相互通信,则⽆法实现两个应⽤服务之间传输对象的序列化与反序列化。
2.易被攻击
Java官⽹安全编码指导⽅针中说明:“对不信任数据的反序列化,从本质上来说是危险的,应该予以避免”。可⻅Java序列化是不安全的。
我们知道对象是通过在ObjectInputStream上调⽤readObject()⽅法进⾏反序列化的,这个⽅法其实是⼀个神奇的构造器,它可以将类路径上⼏乎所有实现了Serializable接⼝的对象都实例化。
这也就意味着,在反序列化字节流的过程中,该⽅法可以执⾏任意类型的代码,这是⾮常危险的。
对于需要⻓时间进⾏反序列化的对象,不需要执⾏任何代码,也可以发起⼀次攻击。攻击者可以创建循环对象链,然后将序列化后的对象传输到程序中反序列化,这种情况会导致hashCode⽅法被调⽤次数呈次⽅爆发式增⻓, 从⽽引发栈溢出异常。例如下⾯这个案例就可以很好地说明。
Set root = new HashSet(); Set s1 = root;
Set s2 = new HashSet();
for (int i = 0; i < 100; i++) { Set t1 = new HashSet();
Set t2 = new HashSet(); t1.add(“foo”); //使t2不等于t1 s1.add(t1);
s1.add(t2);
s2.add(t1);
s2.add(t2); s1 = t1; s2 = t2;
}
2015年FoxGlove Security安全团队的breenmachine发布过⼀篇⻓博客,主要内容是:通过Apache Commons
Collections,Java反序列化漏洞可以实现攻击。⼀度横扫了WebLogic、WebSphere、JBoss、Jenkins、OpenNMS的最新版,各⼤Java Web Server纷纷躺枪。
其实,Apache Commons Collections就是⼀个第三⽅基础库,它扩展了Java标准库⾥的Collection结构,提供了很多强有⼒的数据结构类型,并且实现了各种集合⼯具类。
实现攻击的原理就是:Apache Commons Collections允许链式的任意的类函数反射调⽤,攻击者通过“实现了Java序列化协议”的端⼝,把攻击代码上传到服务器上,再由Apache Commons Collections⾥的TransformedMap来执⾏。
那么后来是如何解决这个漏洞的呢?
很多序列化协议都制定了⼀套数据结构来保存和获取对象。例如,JSON序列化、ProtocolBuf等,它们只⽀持⼀些基本类型和数组数据类型,这样可以避免反序列化创建⼀些不确定的实例。虽然它们的设计简单,但⾜以满⾜当前⼤部分系统的数据传输需求。
我们也可以通过反序列化对象⽩名单来控制反序列化对象,可以重写resolveClass⽅法,并在该⽅法中校验对象名字。代码如下所示:
@Override
protected Class resolveClass(ObjectStreamClass desc) throws IOException,ClassNotFoundException { if (!desc.getName().equals(Bicycle.class.getName())) {
throw new InvalidClassException(
“Unauthorized deserialization attempt”, desc.getName());
}
return super.resolveClass(desc);
}
3.序列化后的流太⼤
序列化后的⼆进制流⼤⼩能体现序列化的性能。序列化后的⼆进制数组越⼤,占⽤的存储空间就越多,存储硬件的成本就越
⾼。如果我们是进⾏⽹络传输,则占⽤的带宽就更多,这时就会影响到系统的吞吐量。
Java序列化中使⽤了ObjectOutputStream来实现对象转⼆进制编码,那么这种序列化机制实现的⼆进制编码完成的⼆进制数组⼤⼩,相⽐于NIO中的ByteBuffer实现的⼆进制编码完成的数组⼤⼩,有没有区别呢?
我们可以通过⼀个简单的例⼦来验证下:
User user = new User(); user.setUserName(“test”); user.setPassword(“test”);
ByteArrayOutputStream os =new ByteArrayOutputStream(); ObjectOutputStream out = new ObjectOutputStream(os); out.writeObject(user);
byte[] testByte = os.toByteArray();
System.out.print(“ObjectOutputStream 字节编码⻓度:” + testByte.length + “\n”);
ByteBuffer byteBuffer = ByteBuffer.allocate( 2048);
byte[] userName = user.getUserName().getBytes(); byte[] password = user.getPassword().getBytes(); byteBuffer.putInt(userName.length); byteBuffer.put(userName); byteBuffer.putInt(password.length); byteBuffer.put(password);
byteBuffer.flip();
byte[] bytes = new byte[byteBuffer.remaining()];
System.out.print(“ByteBuffer 字节编码⻓度:” + bytes.length+ “\n”);
运⾏结果:
ObjectOutputStream 字节编码⻓度:99
ByteBuffer 字节编码⻓度:16
这⾥我们可以清楚地看到:Java序列化实现的⼆进制编码完成的⼆进制数组⼤⼩,⽐ByteBuffer实现的⼆进制编码完成的⼆进制数组⼤⼩要⼤上⼏倍。因此,Java序列后的流会变⼤,最终会影响到系统的吞吐量。
4.序列化性能太差
序列化的速度也是体现序列化性能的重要指标,如果序列化的速度慢,就会影响⽹络通信的效率,从⽽增加系统的响应时间。
我们再来通过上⾯这个例⼦,来对⽐下Java序列化与NIO中的ByteBuffer编码的性能:
User user = new User(); user.setUserName(“test”); user.setPassword(“test”);
long startTime = System.currentTimeMillis();
for(int i=0; i<1000; i++) {
ByteArrayOutputStream os =new ByteArrayOutputStream(); ObjectOutputStream out = new ObjectOutputStream(os); out.writeObject(user);
out.flush();
out.close();
byte[] testByte = os.toByteArray(); os.close();
}
long endTime = System.currentTimeMillis();
System.out.print(“ObjectOutputStream 序列化时间:” + (endTime - startTime) + “\n”);
long startTime1 = System.currentTimeMillis(); for(int i=0; i<1000; i++) {
ByteBuffer byteBuffer = ByteBuffer.allocate( 2048);
byte[] userName = user.getUserName().getBytes(); byte[] password = user.getPassword().getBytes(); byteBuffer.putInt(userName.length); byteBuffer.put(userName); byteBuffer.putInt(password.length); byteBuffer.put(password);
byteBuffer.flip();
byte[] bytes = new byte[byteBuffer.remaining()];
}
long endTime1 = System.currentTimeMillis();
System.out.print(“ByteBuffer 序列化时间:” + (endTime1 - startTime1)+ “\n”);
运⾏结果:
ObjectOutputStream 序列化时间:29
ByteBuffer 序列化时间:6
通过以上案例,我们可以清楚地看到:Java序列化中的编码耗时要⽐ByteBuffer⻓很多。
使⽤Protobuf序列化替换Java序列化
⽬前业内优秀的序列化框架有很多,⽽且⼤部分都避免了Java默认序列化的⼀些缺陷。例如,最近⼏年⽐较流⾏的
FastJson、Kryo、Protobuf、Hessian等。我们完全可以找⼀种替换掉Java序列化,这⾥我推荐使⽤Protobuf序列化框架。
Protobuf是由Google推出且⽀持多语⾔的序列化框架,⽬前在主流⽹站上的序列化框架性能对⽐测试报告中,Protobuf⽆论是编解码耗时,还是⼆进制流压缩⼤⼩,都名列前茅。
Protobuf以⼀个 .proto 后缀的⽂件为基础,这个⽂件描述了字段以及字段类型,通过⼯具可以⽣成不同语⾔的数据结构⽂件。在序列化该数据对象的时候,Protobuf通过.proto⽂件描述来⽣成Protocol Buffers格式的编码。
这⾥拓展⼀点,我来讲下什么是Protocol Buffers存储格式以及它的实现原理。
Protocol Buffers 是⼀种轻便⾼效的结构化数据存储格式。它使⽤T-L-V(标识 - ⻓度 - 字段值)的数据格式来存储数据,T代表字段的正数序列(tag),Protocol Buffers 将对象中的每个字段和正数序列对应起来,对应关系的信息是由⽣成的代码来保证的。在序列化的时候⽤整数值来代替字段名称,于是传输流量就可以⼤幅缩减;L代表Value的字节⻓度,⼀般也只占⼀个字 节;V则代表字段值经过编码后的值。这种数据格式不需要分隔符,也不需要空格,同时减少了冗余字段名。
Protobuf定义了⼀套⾃⼰的编码⽅式,⼏乎可以映射Java/Python等语⾔的所有基础数据类型。不同的编码⽅式对应不同的数据类型,还能采⽤不同的存储格式。如下图所示: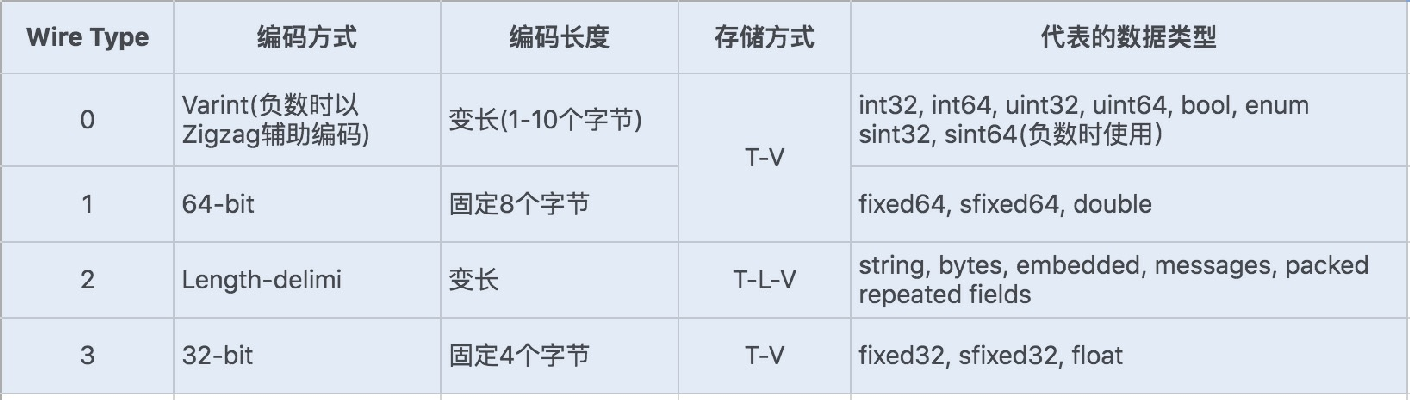
对于存储Varint编码数据,由于数据占⽤的存储空间是固定的,就不需要存储字节⻓度 Length,所以实际上Protocol Buffers的存储⽅式是 T - V,这样就⼜减少了⼀个字节的存储空间。
Protobuf定义的Varint编码⽅式是⼀种变⻓的编码⽅式,每个数据类型⼀个字节的最后⼀位是⼀个标志位(msb),⽤0和1来表示,0表示当前字节已经是最后⼀个字节,1表示这个数字后⾯还有⼀个字节。
对于int32类型数字,⼀般需要4个字节表示,若采⽤Varint编码⽅式,对于很⼩的int32类型数字,就可以⽤1个字节来表示。对于⼤部分整数类型数据来说,⼀般都是⼩于256,所以这种操作可以起到很好地压缩数据的效果。
我们知道int32代表正负数,所以⼀般最后⼀位是⽤来表示正负值,现在Varint编码⽅式将最后⼀位⽤作了标志位,那还如何去表示正负整数呢?如果使⽤int32/int64表示负数就需要多个字节来表示,在Varint编码类型中,通过Zigzag编码进⾏转换,将 负数转换成⽆符号数,再采⽤sint32/sint64来表示负数,这样就可以⼤⼤地减少编码后的字节数。
Protobuf的这种数据存储格式,不仅压缩存储数据的效果好, 在编码和解码的性能⽅⾯也很⾼效。Protobuf的编码和解码过程
结合.proto⽂件格式,加上Protocol Buffer独特的编码格式,只需要简单的数据运算以及位移等操作就可以完成编码与解码。可以说Protobuf的整体性能⾮常优秀。
总结
⽆论是⽹路传输还是磁盘持久化数据,我们都需要将数据编码成字节码,⽽我们平时在程序中使⽤的数据都是基于内存的数据类型或者对象,我们需要通过编码将这些数据转化成⼆进制字节流;如果需要接收或者再使⽤时,⼜需要通过解码将⼆进制字节流转换成内存数据。我们通常将这两个过程称为序列化与反序列化。
Java默认的序列化是通过Serializable接⼝实现的,只要类实现了该接⼝,同时⽣成⼀个默认的版本号,我们⽆需⼿动设置, 该类就会⾃动实现序列化与反序列化。
Java默认的序列化虽然实现⽅便,但却存在安全漏洞、不跨语⾔以及性能差等缺陷,所以我强烈建议你避免使⽤Java序列化。
纵观主流序列化框架,FastJson、Protobuf、Kryo是⽐较有特点的,⽽且性能以及安全⽅⾯都得到了业界的认可,我们可以结合⾃身业务来选择⼀种适合的序列化框架,来优化系统的序列化性能。
思考题
这是⼀个使⽤单例模式实现的类,如果我们将该类实现Java的Serializable接⼝,它还是单例吗?如果要你来写⼀个实现了
Java的Serializable接⼝的单例,你会怎么写呢?
public class Singleton implements Serializable{
private final static Singleton singleInstance = new Singleton();
private Singleton(){}
public static Singleton getInstance(){ return singleInstance;
}
}
期待在留⾔区看到你的⻅解。也欢迎你点击“请朋友读”,把今天的内容分享给身边的朋友,邀请他⼀起学习。
精选留⾔ <br />陆离<br />序列化会通过反射调⽤⽆参构造器返回⼀个新对象,破坏单例模式。解决⽅法是添加readResolve()⽅法,⾃定义返回对象策略。<br />2019-06-08 09:02<br />作者回复<br />回答正确<br />2019-06-08 09:22
 kevin
kevin
⽼师请教下,为什么spring cloud不使⽤protobuf, thrift等性能更⾼、⽀持跨平台的序列化⼯具,⽽且使⽤json?
2019-06-09 12:28
作者回复
springcloud是spring⽣态中的⼀部分,就⽬前spring⽣态很少引⼊⾮⽣态框架。但是我们可以⾃⼰实现springcloud兼容protobuf
序列化。
2019-06-10 21:34
 -W.LI-
-W.LI-
⽂中说Java序列化,不会序列化静态变量,这个单例的静态变量会被怎么处理啊?
2019-06-08 11:34
作者回复
是的,Java序列化会调⽤构造函数,构造出⼀个新对象
2019-06-10 21:06
 waniz
waniz
⽼师您好,Java序列化将数据转化为⼆进制字节流,json序列化将数据转化为json字符串。但是在物理层数据都是以电信号或 模拟信号传输。那么从应⽤层到物理层数据的编码状态究竟是怎么变化的?出发点不同,最后都是⼆进制传输…忘解惑
2019-07-05 19:19
作者回复
Java序列化是将Java对象转化为⼆进制流,⽽Json序列化是将Json字符串转为⼆进制的过程,只是包装的数据格式不⼀样。
2019-07-07 09:59 密码123456
密码123456
看到提问,才发现这竟然不是单例。回想内容是因为。可以把类路径上⼏乎所有实现了 Serializable 接⼝的对象都实例化。还真不知道怎么写?内部私有类实现,这种可以吗?
2019-06-08 06:46
作者回复
线上代码发⽣错位了,已修正。
导致这个问题的原因是序列化中的readObject会通过反射,调⽤没有参数的构造⽅法创建⼀个新的对象。所以我们可以在被序列化类中重写readResolve⽅法。
private Object readResolve(){ return singleInstance;
}
2019-06-08 09:21
 强哥
强哥
⾸先为什么单例要实现Serializable接⼝呢?如果本身就不合理,那直接删掉Serializable即可,没必要为了本身的不合理,添加 多余的⽅法,除⾮有特殊场景,否则这么这样的代码指定会被ugly
2019-06-19 22:42
17702158422
可以定义⼀个静态属性 boolean flag = false, 在构造函数⾥ 判断 flag是否为ture, 如果为true则抛出异常,否则将flag赋值为 true
,则可以在运⾏期防⽌反序列化时通过反射破坏单例模式
2019-06-19 14:31 草帽路⻜
草帽路⻜
⽼师,您好。Java 序列化的安全性中,序列化的时候执⾏按段循环对象链的代码为什么会导致 hashcode 成倍增⻓呀?
2019-06-19 14:08
 undifined
undifined
⽼师 我们有⼀个需求,需要将⼀些更新前的数据保存起来⽤于回滚,保存的对象有⼀个 value 属性是 Object 类型的,赋值 Big
Decimal 后使⽤ FastJson 序列化保存到数据库,回滚的时候再反序列化变成了Integer,考虑将 FastJson 改成 JDK 的序列化
,但是⼜担⼼会造成性能问题,请问⽼师有什么建议吗
2019-06-11 08:54
作者回复
请问改成JDK序列化的⽬的是什么?
2019-06-12 09:26
 DemonLee
DemonLee
图⼀中,输⼊流ObjectInputStream应该是反序列吧,输出流ObjectOutputStream应该是序列化吧,⽼师我理解错了?
2019-06-11 00:44
作者回复
是的,你理解没有错。ObjectInputStream对应readObject,ObjectOutputStream对应writeObject。
2019-06-12 10:39
 Liam
Liam
在java序列号安全性那⾥有个疑问,为什么反序列化会导致hashCode⽅法的频繁调⽤呢,反序列化时调⽤hashCode的作⽤是
2019-06-09 09:46
作者回复
这⾥不是序列化调⽤hashcode⽅法,⽽是序列化时,运⾏这段代码。
2019-06-10 21:14
 晓杰
晓杰
不是单例,因为在反序列化的时候,会调⽤ObjectInputStream的readObject⽅法,该⽅法可以对实现序列化接⼝的类进⾏实例 化,所以会破坏单例模式。
可以通过重写readResolve,返回单例对象的⽅式来避免这个问题
2019-06-08 23:02
作者回复
正确
2019-06-10 21:12
 张学磊
张学磊
上⾯说默认序列化⽅式不会序列化对象的 transient 的实例变量,也不会序列化静态变量,那这个单例的变量是静态的,是不是可以理解序列化成了⼀个空对象?
2019-06-08 12:36
 colin
colin
Protobuf的格式感觉喝字节码有点类似
2019-06-08 11:47
作者回复
这个形容⾮常到位
2019-06-10 21:12

若有收获,就点个赞吧
0 人点赞
