 01讲如何制定性能调优标准
01讲如何制定性能调优标准
你好,我是刘超。
 我有⼀个朋友,有⼀次他跟我说,他们公司的系统从来没有经过性能调优,功能测试完成后就上线了,线上也没有出现过什么性能问题呀,那为什么很多系统都要去做性能调优呢?
我有⼀个朋友,有⼀次他跟我说,他们公司的系统从来没有经过性能调优,功能测试完成后就上线了,线上也没有出现过什么性能问题呀,那为什么很多系统都要去做性能调优呢?
当时我就回答了他⼀句,如果你们公司做的是 12306 ⽹站,不做系统性能优化就上线,试试看会是什么情况。
如果是你,你会怎么回答呢?今天,我们就从这个话题聊起,希望能跟你⼀起弄明⽩这⼏个问题:我们为什么要做性能调优? 什么时候开始做?做性能调优是不是有标准可参考?
为什么要做性能调优?
⼀款线上产品如果没有经过性能测试,那它就好⽐是⼀颗定时炸弹,你不知道它什么时候会出现问题,你也不清楚它能承受的极限在哪⼉。
有些性能问题是时间累积慢慢产⽣的,到了⼀定时间⾃然就爆炸了;⽽更多的性能问题是由访问量的波动导致的,例如,活动或者公司产品⽤户量上升;当然也有可能是⼀款产品上线后就半死不活,⼀直没有⼤访问量,所以还没有引发这颗定时炸弹。
现在假设你的系统要做⼀次活动,产品经理或者⽼板告诉你预计有⼏⼗万的⽤户访问量,询问系统能否承受得住这次活动的压
⼒。如果你不清楚⾃⼰系统的性能情况,也只能战战兢兢地回答⽼板,有可能⼤概没问题吧。
所以,要不要做性能调优,这个问题其实很好回答。所有的系统在开发完之后,多多少少都会有性能问题,我们⾸先要做的就是想办法把问题暴露出来,例如进⾏压⼒测试、模拟可能的操作场景等等,再通过性能调优去解决这些问题。
⽐如,当你在⽤某⼀款 App 查询某⼀条信息时,需要等待⼗⼏秒钟;在抢购活动中,⽆法进⼊活动⻚⾯等等。你看,系统响应就是体现系统性能最直接的⼀个参考因素。
那如果系统在线上没有出现响应问题,我们是不是就不⽤去做性能优化了呢?再给你讲⼀个故事吧。
曾经我的前前东家系统研发部⻔来了⼀位⼤神,为什么叫他⼤神,因为在他来公司的⼀年时间⾥,他只做了⼀件事情,就是把
服务器的数量缩减到了原来的⼀半,系统的性能指标,反⽽还提升了。
好的系统性能调优不仅仅可以提⾼系统的性能,还能为公司节省资源。这也是我们做性能调优的最直接的⽬的。
什么时候开始介⼊调优?
解决了为什么要做性能优化的问题,那么新的问题就来了:如果需要对系统做⼀次全⾯的性能监测和优化,我们从什么时候开始介⼊性能调优呢?是不是越早介⼊越好?
其实,在项⽬开发的初期,我们没有必要过于在意性能优化,这样反⽽会让我们疲于性能优化,不仅不会给系统性能带来提升,还会影响到开发进度,甚⾄获得相反的效果,给系统带来新的问题。
我们只需要在代码层⾯保证有效的编码,⽐如,减少磁盘 I/O 操作、降低竞争锁的使⽤以及使⽤⾼效的算法等等。遇到⽐较复杂的业务,我们可以充分利⽤设计模式来优化业务代码。例如,设计商品价格的时候,往往会有很多折扣活动、红包活动,我们可以⽤装饰模式去设计这个业务。
在系统编码完成之后,我们就可以对系统进⾏性能测试了。这时候,产品经理⼀般会提供线上预期数据,我们在提供的参考平台上进⾏压测,通过性能分析、统计⼯具来统计各项性能指标,看是否在预期范围之内。
在项⽬成功上线后,我们还需要根据线上的实际情况,依照⽇志监控以及性能统计⽇志,来观测系统性能问题,⼀旦发现问题,就要对⽇志进⾏分析并及时修复问题。
有哪些参考因素可以体现系统的性能?
上⾯我们讲到了在项⽬研发的各个阶段性能调优是如何介⼊的,其中多次讲到了性能指标,那么性能指标到底有哪些呢? 在我们了解性能指标之前,我们先来了解下哪些计算机资源会成为系统的性能瓶颈。
CPU:有的应⽤需要⼤量计算,他们会⻓时间、不间断地占⽤ CPU 资源,导致其他资源⽆法争夺到 CPU ⽽响应缓慢,从⽽带来系统性能问题。例如,代码递归导致的⽆限循环,正则表达式引起的回溯,JVM频繁的 FULL GC,以及多线程编程造成的⼤量上下⽂切换等,这些都有可能导致 CPU 资源繁忙。
内存:Java 程序⼀般通过 JVM 对内存进⾏分配管理,主要是⽤ JVM 中的堆内存来存储 Java 创建的对象。系统堆内存的读写速度⾮常快,所以基本不存在读写性能瓶颈。但是由于内存成本要⽐磁盘⾼,相⽐磁盘,内存的存储空间⼜⾮常有限。所以当内存空间被占满,对象⽆法回收时,就会导致内存溢出、内存泄露等问题。
磁盘I/O:磁盘相⽐内存来说,存储空间要⼤很多,但磁盘 I/O 读写的速度要⽐内存慢,虽然⽬前引⼊的 SSD 固态硬盘已经有所优化,但仍然⽆法与内存的读写速度相提并论。
⽹络:⽹络对于系统性能来说,也起着⾄关重要的作⽤。如果你购买过云服务,⼀定经历过,选择⽹络带宽⼤⼩这⼀环节。带宽过低的话,对于传输数据⽐较⼤,或者是并发量⽐较⼤的系统,⽹络就很容易成为性能瓶颈。
异常:Java 应⽤中,抛出异常需要构建异常栈,对异常进⾏捕获和处理,这个过程⾮常消耗系统性能。如果在⾼并发的情况下引发异常,持续地进⾏异常处理,那么系统的性能就会明显地受到影响。
数据库:⼤部分系统都会⽤到数据库,⽽数据库的操作往往是涉及到磁盘 I/O 的读写。⼤量的数据库读写操作,会导致磁盘
I/O 性能瓶颈,进⽽导致数据库操作的延迟性。对于有⼤量数据库读写操作的系统来说,数据库的性能优化是整个系统的核
⼼。
锁竞争:在并发编程中,我们经常会需要多个线程,共享读写操作同⼀个资源,这个时候为了保持数据的原⼦性(即保证这个
共享资源在⼀个线程写的时候,不被另⼀个线程修改),我们就会⽤到锁。锁的使⽤可能会带来上下⽂切换,从⽽给系统带来
性能开销。JDK1.6 之后,Java 为了降低锁竞争带来的上下⽂切换,对 JVM 内部锁已经做了多次优化,例如,新增了偏向锁、⾃旋锁、轻量级锁、锁粗化、锁消除等。⽽如何合理地使⽤锁资源,优化锁资源,就需要你了解更多的操作系统知识、
Java 多线程编程基础,积累项⽬经验,并结合实际场景去处理相关问题。
了解了上⾯这些基本内容,我们可以得到下⾯⼏个指标,来衡量⼀般系统的性能。
响应时间
响应时间是衡量系统性能的重要指标之⼀,响应时间越短,性能越好,⼀般⼀个接⼝的响应时间是在毫秒级。在系统中,我们可以把响应时间⾃下⽽上细分为以下⼏种: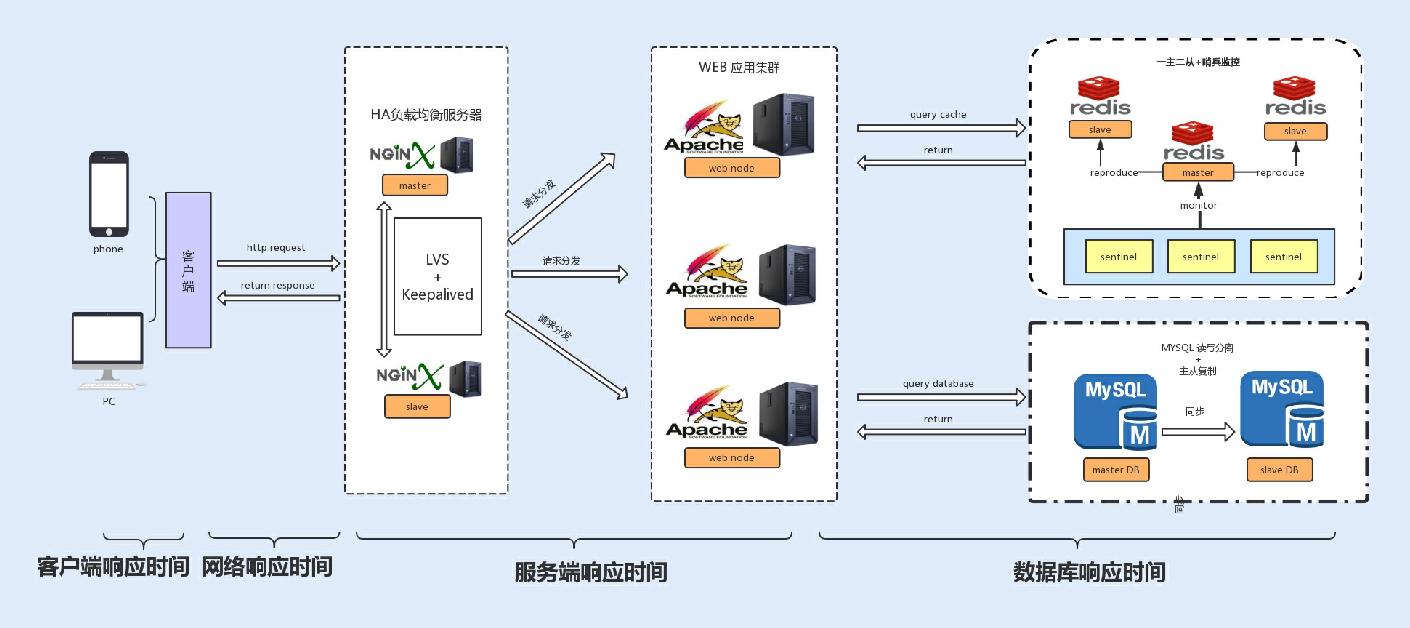
数据库响应时间:数据库操作所消耗的时间,往往是整个请求链中最耗时的;
服务端响应时间:服务端包括 Nginx 分发的请求所消耗的时间以及服务端程序执⾏所消耗的时间;
⽹络响应时间:这是⽹络传输时,⽹络硬件需要对传输的请求进⾏解析等操作所消耗的时间;
客户端响应时间:对于普通的 Web、App 客户端来说,消耗时间是可以忽略不计的,但如果你的客户端嵌⼊了⼤量的逻辑处理,消耗的时间就有可能变⻓,从⽽成为系统的瓶颈。
吞吐量
在测试中,我们往往会⽐较注重系统接⼝的 TPS(每秒事务处理量),因为 TPS 体现了接⼝的性能,TPS 越⼤,性能越好。在系统中,我们也可以把吞吐量⾃下⽽上地分为两种:磁盘吞吐量和⽹络吞吐量。
我们先来看磁盘吞吐量,磁盘性能有两个关键衡量指标。
⼀种是 IOPS(Input/Output Per Second),即每秒的输⼊输出量(或读写次数),这种是指单位时间内系统能处理的 I/O 请求数量,I/O 请求通常为读或写数据操作请求,关注的是随机读写性能。适应于随机读写频繁的应⽤,如⼩⽂件存储(图
⽚)、OLTP 数据库、邮件服务器。
另⼀种是数据吞吐量,这种是指单位时间内可以成功传输的数据量。对于⼤量顺序读写频繁的应⽤,传输⼤量连续数据,例如,电视台的视频编辑、视频点播 VOD(Video On Demand),数据吞吐量则是关键衡量指标。
接下来看⽹络吞吐量,这个是指⽹络传输时没有帧丢失的情况下,设备能够接受的最⼤数据速率。⽹络吞吐量不仅仅跟带宽有关系,还跟 CPU 的处理能⼒、⽹卡、防⽕墙、外部接⼝以及 I/O 等紧密关联。⽽吞吐量的⼤⼩主要由⽹卡的处理能⼒、内部
程序算法以及带宽⼤⼩决定。
计算机资源分配使⽤率
通常由 CPU 占⽤率、内存使⽤率、磁盘 I/O、⽹络 I/O 来表示资源使⽤率。这⼏个参数好⽐⼀个⽊桶,如果其中任何⼀块⽊板出现短板,任何⼀项分配不合理,对整个系统性能的影响都是毁灭性的。
负载承受能⼒
当系统压⼒上升时,你可以观察,系统响应时间的上升曲线是否平缓。这项指标能直观地反馈给你,系统所能承受的负载压⼒极限。例如,当你对系统进⾏压测时,系统的响应时间会随着系统并发数的增加⽽延⻓,直到系统⽆法处理这么多请求,抛出
⼤量错误时,就到了极限。
总结
通过今天的学习,我们知道性能调优可以使系统稳定,⽤户体验更佳,甚⾄在⽐较⼤的系统中,还能帮公司节约资源。
但是在项⽬的开始阶段,我们没有必要过早地介⼊性能优化,只需在编码的时候保证其优秀、⾼效,以及良好的程序设计。
在完成项⽬后,我们就可以进⾏系统测试了,我们可以将以下性能指标,作为性能调优的标准,响应时间、吞吐量、计算机资源分配使⽤率、负载承受能⼒。
回顾我⾃⼰的项⽬经验,有电商系统、⽀付系统以及游戏充值计费系统,⽤户级都是千万级别,且要承受各种⼤型抢购活动, 所以我对系统的性能要求⾮常苛刻。除了通过观察以上指标来确定系统性能的好坏,还需要在更新迭代中,充分保障系统的稳定性。
这⾥,给你延伸⼀个⽅法,就是将迭代之前版本的系统性能指标作为参考标准,通过⾃动化性能测试,校验迭代发版之后的系统性能是否出现异常,这⾥就不仅仅是⽐较吞吐量、响应时间、负载能⼒等直接指标了,还需要⽐较系统资源的 CPU 占⽤
率、内存使⽤率、磁盘 I/O、⽹络 I/O 等⼏项间接指标的变化。
思考题
除了以上这些常⻅的性能参考指标,你是否还能想到其他可以衡量系统性能的指标呢?
期待在留⾔区看到你的⻅解。也欢迎你点击“请朋友读”,把今天的内容分享给身边的朋友,邀请他⼀起讨论。
精选留⾔ <br />杨军<br />⾸先很⾼兴终于有⼈开Java性能优化的课程,我在⼯作中需要接触很多这⽅⾯的⼯作,希望通过学习这次课程能带来更多收获<br />。<br />然后我想请教⽼师⼀个问题,CPU利⽤率和系统负载这两个指标之间是什么关系?⽹上很多资料讲的不清不楚,看不明⽩。
2019-05-21 00:41
作者回复
杨军你好,系统负载代表单位时间内正在运⾏或等待的进程或线程数,代表了系统的繁忙程度,CPU利⽤率则代表单位时间内
⼀个线程或进程实时占⽤CPU的百分⽐。我们知道,⼀个进程或者线程在运⾏时,未必都在实时的利⽤CPU的。
⽐如,在CPU密集型的情况下,系统的负载未必会⾼,但CPU的利⽤率肯定会⾼,⼀个线程/进程⼀直在计算,它对CPU的实 时利⽤率是100%,⽽系统负载是0.1;
⼜⽐如,⽽对于I/O密集型的程序来说,有可能CPU的利⽤率不⾼,但系统的负载却会⾮常⾼,这是因为I/O经常引起阻塞,这 样导致很多线程/进程被处于阻塞等待状态,处于等待的线程或进程也是属于负载线程/进程的。
通过以上两个例⼦,不知道有没有让你分清楚两个指标的区别,有问题保持沟通。
2019-05-21 17:56
 QQ怪
QQ怪
我觉得还有接⼝返回200的成功率吧
2019-05-20 21:26
作者回复
晚上好 QQ怪,你说的很对。我们平时在使⽤AB进⾏压测时,会有⼀个failed requests指标,本身接⼝没有异常的情况下,压测出现了异常,也是说明这个接⼝有性能问题。还有就是percentage of the requests served within a certain time这个指标,这个指标对⾦融交易系统来说是⾮常重要的,如果有99%的请求是1ms返回,但有1%是500ms返回,这对于某些对交易时间要求极致的⾦融系统来说也是性能问题。感谢你的回答,期望我的回答能让你满意!
2019-05-20 21:56
 遇⻅阳光
遇⻅阳光
⽼师,tps qps这块还是有点不太清楚。
2019-05-21 23:17
作者回复
遇⻅阳光 你好,TPS(transaction per second)是单位时间内处理事务的数量,QPS(query per second)是单位时间内请求的数量。TPS代表⼀个事务的处理,可以包含了多次请求。很多公司⽤QPS作为接⼝吞吐量的指标,也有很多公司使⽤TPS作为标准,两者都能表现出系统的吞吐量的⼤⼩,TPS的⼀次事务代表⼀次⽤户操作到服务器返回结果,QPS的⼀次请求代表⼀个接
⼝的⼀次请求到服务器返回结果。当⼀次⽤户操作只包含⼀个请求接⼝时,TPS和QPS没有区别。当⽤户的⼀次操作包含了多个服务请求时,这个时候TPS作为这次⽤户操作的性能指标就更具有代表性了。
2019-05-22 09:26
 业余草
业余草
优化,⾸先是你要知道它是什么,⽤了什么原理,才能更深⼊的去做好优化。其实最重要的优化,是优化⾃⼰的编程思想。⾸先要排除的是,每个需求,不是功能做完了就做好了。我们要做的是把知识变成钱,⽽不是把劳动⼒变成钱,
2019-05-21 10:57
 kaixiao7
kaixiao7
⽼师,关于JVM的异常问题,您在@陆离的回答中说”平时的业务异常避免⽣成栈追踪信息,在异常中⽤字符串描述业务异常信息即可”,我通过throw new Exception(“aaa”),debug时发现还是会调⽤fillInStackTrace()⽅法。我是不是理解错了呢?具体该怎么做?感谢
2019-06-04 15:25
作者回复
可以⾃⼰实现⾃定义异常,继承RuntimeException,然后将writableStackTrace设置为false。以下是RuntimeException的构造函数:
protected RuntimeException(String message, Throwable cause, boolean enableSuppression,
boolean writableStackTrace) {
super(message, cause, enableSuppression, writableStackTrace);
}
2019-06-05 09:41
 ⼩辉辉
⼩辉辉
现在的项⽬也是没有经过压测和调优的,上线也没多久,正好跟着⽼师的专栏来试着优化⼀下性能
2019-05-20 21:27
作者回复
为你⼿动点赞
2019-05-20 22:37
 Maxwell
Maxwell
请问⽼师最近段时间遇到端⼝被CLOSE_WAIT占⽤,重启后过了半天⼜重现,以前没有出现过,⼀般如何排查
2019-06-01 11:36
作者回复
可以通过tcpdump抓包看看连接状态,分析是否是服务端的FIN packet没有发出去。
正常的关闭流程是:服务端在接收到客户端发送的关闭请求FIN后,会进⼊CLOSE_WAIT状态,同时发送ACK回去。在完成与客户端直接的通信操作之后,再向客户端发送FIN,进⼊LAST_ACK状态。
如果连接是CLOSE_WAIT状态,⽽不是LAST_ACK状态,说明还没有发FIN给Client,那么可能是在关闭连接之前还有许多数据要发送或者其他事要做,导致没有发这个FIN packet。
建议确定关闭请求的四次握⼿,哪个环节出了问题,再去排查业务代码,可能是由于超时或者异常导致没有正常关闭连接。
2019-06-02 13:14
 诸葛
诸葛
异常:Java 应⽤中,抛出异常需要构建异常栈,对异常进⾏捕获和处理,这个过程⾮常消耗系统性能。如果在⾼并发的情况下引发异常,持续地进⾏异常处理,那么系统的性能就会明显地受到影响。
⽼师好,⾼并发调⽤⽅法之后第⼀步就是检验⼀堆⼊参,如果⼊参有问题⽴即抛出异常给前端,不再处理下边的逻辑了,这样有问题吗?我看系统性能还可以啊。压⼒测试也还⾏。如果有问题的话那应该怎么做呢,检验错误后给前端放回code码然后返回空对象吗?感谢
2019-05-26 14:43
作者回复
如果没有⽣成堆栈追踪信息,不会有性能问题。⼀般业务异常避免⽣成堆栈追踪信息,我们知道这个异常是什么原因,所以直接返回字符串就好了。⽽系统异常,⼀般都会⽣成堆栈追踪信息,以便追踪源头,更好的排查问题。
2019-05-26 19:28
 劉磊
劉磊
我⽤springboot打的jar,⽤了⼗天半⽉的莫名其妙⾃⼰死了,⽇志没有啥有价值。这个有⼈遇到过吗?
2019-05-20 23:01
作者回复
刘磊 你好,请问是否打开debug⽇志模式呢,很多系统以及中间件异常需要在debug模式下才能看到异常⽇志。我们也可以提前开启JVM的gc和内存异常⽇志,可以在问题出现后,查看JVM是否存在异常⽇志。
2019-05-21 09:46
 随遇⽽安
随遇⽽安
希望这次能学到真正的东⻄
2019-05-20 22:07
作者回复
坚持就会有收获,加油!
2019-05-20 22:35
 我⾏我素
我⾏我素
并发⽤户数,⾼可⽤可扩展等⽅⾯
2019-05-20 21:47
作者回复
你好 我⾏我素,感谢你的回答。并发⽤户数代表系统同⼀时间处理事务的并发能⼒,也是体现系统性能的⼀个直接性能指标。当然,TPS也能间接的体现系统并发处理能⼒。
2019-05-21 08:53
 Phoenix
Phoenix
想请教下⽼师,使⽤MySQL经常会遇到业务需要实时导出⼤量业务数据的需求,那么如何在不影响业务和不分库的的情况满⾜业务实时导出⼤量数据的需求呢?
2019-05-20 21:17
作者回复
你好 Phoenix,切忌在主库中操作这种报表类的导出,在写⼊和查询都在⼀个主库进⾏,会造成数据库性能瓶颈,严重的会导致数据库死锁。我们可以将数据库读写分离,写业务⾛主(写)库,导出数据可以从从(读)库导出。这种实现⽅式,⾸先能提⾼数据导出的性能,其次不影响写业务。
如果你们公司有⼤数据中⼼,可以考虑将需要导出的数据实时同步到⼤数据中⼼,通过实时的流计算处理⽣成不同需求的业务数据。
希望以上的回答能让你满意,如果有问题保持沟通!
2019-05-20 22:41
 Teamillet
Teamillet
编译原理还好没忘记,少⽤正则……
2019-05-30 17:18
 Geek_ebda96
Geek_ebda96
 ⽼师你好,请问系统负载所指的正在运⾏或者等待的进程数和CPU的数⽬的百分⽐,但我⼤部分得系统来说运⾏的进程数⽬基本不会边,都是稳定的,在变的应该是应⽤程序本身的线程数,这个参数对于性能观察来说有⽤么,哪些⽅法能看到因为线程数过多或者线程的使⽤率很⾼导致性能问题,⽐如TOP查看CPU使⽤率?
⽼师你好,请问系统负载所指的正在运⾏或者等待的进程数和CPU的数⽬的百分⽐,但我⼤部分得系统来说运⾏的进程数⽬基本不会边,都是稳定的,在变的应该是应⽤程序本身的线程数,这个参数对于性能观察来说有⽤么,哪些⽅法能看到因为线程数过多或者线程的使⽤率很⾼导致性能问题,⽐如TOP查看CPU使⽤率?
2019-05-28 23:23
作者回复
进程或线程,不单单指的是进程。可⽤使⽤top指令查看整体的使⽤率以及单个进程和单个线程的使⽤率。
2019-05-29 07:57
 张⼩⼩的席⼤⼤
张⼩⼩的席⼤⼤
⽼师 您好 我想请问个问题 您说的压测⼯具ab 我⽤过 但是我们现在想要模拟完整的项⽬流程去压测(直播项⽬) 您有什么好的建议么
2019-05-28 09:10
作者回复
建议使⽤jmeter或者loadrunner,可以通过录制业务流程,⽣成jmeter脚本。近期我会讲到测试⼯具的使⽤。
2019-05-28 10:04
 ⾏者
⾏者
⽼师,我想到服务器响应时间可以进⼀步细分到服务器中位数响应时间,服务器最慢的响应时间;要尽可能让所有接⼝响应时间接近,避免⻓尾。
2019-05-22 21:01
作者回复
⾏者你好,你想到的很好,我们在做性能测试的时候有⼀个percentage of the requests served within a certain time指标,就是反应单位时间内,不同响应时间的占⽐率,例如50% 的响应时间是1ms以内,80%的响应时间是2ms以内,99%的响应时间是
5ms以内。说明有19%是在2ms~5ms以内,如果这个范围太⼤,有可能存在性能问题,具体问题具体分析。
上述我说的这个参数应该就是你现在描述的性能指标,有问题保持沟通。
2019-05-23 09:55
 tyul
tyul
⽹络吞吐量⾥⾯的字被和谐了
2019-05-22 19:32
作者回复
感谢这位热⼼同学!
2019-05-22 19:53
 庄⻛
庄⻛
希望⽼师在以后的课程中讲⼀下相关性能监测⼯具软件。我在项⽬中遇到了性能问题后,确实不知道该如何分析、监测系统状态,并进⾏相应的处理和优化。之前⼀直⽤的是Windows⾃带的性能监视器,不过并不好⽤。
2019-05-22 09:31 张德
张德
主要是纯粹的JAVA专栏 很期待很期待
2019-05-22 08:48 ⼃北纬91度灬
⼃北纬91度灬
⽼师您好,看到性能调优这块的指标内容,需要涉及到很多⽅⾯的知识,⽐如Linux操作,JVM虚拟机原理,Java源码基础知识等,这些东⻄对于⼀个刚接触后台开发的⼈来说,确实⽐较吃⼒,在学习本专栏课程的同时去学习这些东⻄,这些有优先级吗,哪些是需要先急需掌握⼀部分的
2019-05-22 01:26
作者回复
你好,在我看来Linux操作系统、JVM以及Java基础三者的学习并不会存在前后顺序,可以并⾏学习。对于Java初学者来说, 建议可以⼀边了解Java的运⾏原理(JVM)⼀边学习Java基础知识,基础打好之后,我们可以进⼊⾼级篇,⽐如Java的并发编程
,如果需要进⾏⼀些项⽬实践,我们可以学习Spring相关框架组件。Linux操作系统我们也可以在了解基础原理的前提下,先熟练掌握⼀些常⽤操作命令,再作深⼊学习。
2019-05-22 08:56

若有收获,就点个赞吧
0 人点赞
