 08讲⽹络通信优化之IO模型:如何解决⾼并发下IO瓶颈
08讲⽹络通信优化之IO模型:如何解决⾼并发下IO瓶颈
你好,我是刘超。
 提到Java I/O,相信你⼀定不陌⽣。你可能使⽤I/O操作读写⽂件,也可能使⽤它实现Socket的信息传输…这些都是我们在系统中最常遇到的和I/O有关的操作。
提到Java I/O,相信你⼀定不陌⽣。你可能使⽤I/O操作读写⽂件,也可能使⽤它实现Socket的信息传输…这些都是我们在系统中最常遇到的和I/O有关的操作。
我们都知道,I/O的速度要⽐内存速度慢,尤其是在现在这个⼤数据时代背景下,I/O的性能问题更是尤为突出,I/O读写已经成为很多应⽤场景下的系统性能瓶颈,不容我们忽视。
今天,我们就来深⼊了解下Java I/O在⾼并发、⼤数据业务场景下暴露出的性能问题,从源头⼊⼿,学习优化⽅法。
什么是I/O
I/O是机器获取和交换信息的主要渠道,⽽流是完成I/O操作的主要⽅式。
在计算机中,流是⼀种信息的转换。流是有序的,因此相对于某⼀机器或者应⽤程序⽽⾔,我们通常把机器或者应⽤程序接收外界的信息称为输⼊流(InputStream),从机器或者应⽤程序向外输出的信息称为输出流(OutputStream),合称为输⼊/输出流(I/O Streams)。
机器间或程序间在进⾏信息交换或者数据交换时,总是先将对象或数据转换为某种形式的流,再通过流的传输,到达指定机器或程序后,再将流转换为对象数据。因此,流就可以被看作是⼀种数据的载体,通过它可以实现数据交换和传输。
Java的I/O操作类在包java.io下,其中InputStream、OutputStream以及Reader、Writer类是I/O包中的4个基本类,它们分别处理字节流和字符流。如下图所示:
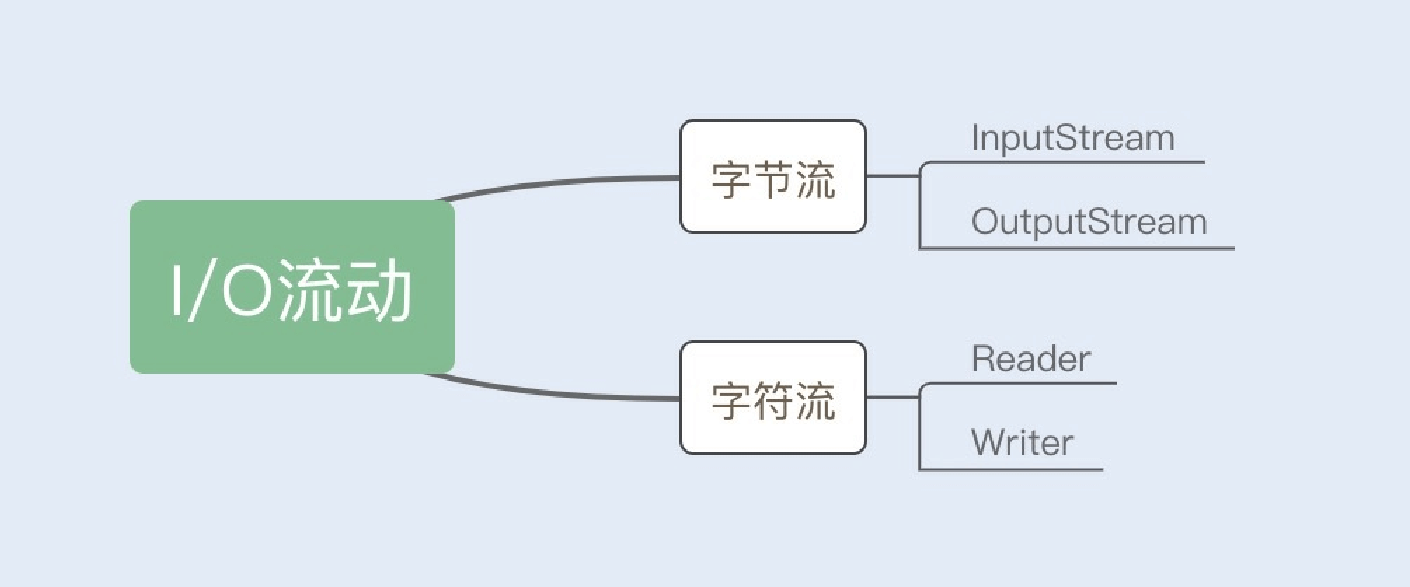
回顾我的经历,我记得在初次阅读Java I/O流⽂档的时候,我有过这样⼀个疑问,在这⾥也分享给你,那就是:“不管是⽂件读
写还是⽹络发送接收,信息的最⼩存储单元都是字节,那为什么I/O流操作要分为字节流操作和字符流操作呢?”
我们知道字符到字节必须经过转码,这个过程⾮常耗时,如果我们不知道编码类型就很容易出现乱码问题。所以I/O流提供了
⼀个直接操作字符的接⼝,⽅便我们平时对字符进⾏流操作。下⾯我们就分别了解下“字节流”和“字符流”。
1.字节流
InputStream/OutputStream是字节流的抽象类,这两个抽象类⼜派⽣出了若⼲⼦类,不同的⼦类分别处理不同的操作类型。如果是⽂件的读写操作,就使⽤FileInputStream/FileOutputStream;如果是数组的读写操作,就使⽤
ByteArrayInputStream/ByteArrayOutputStream;如果是普通字符串的读写操作,就使⽤
BufferedInputStream/BufferedOutputStream。具体内容如下图所示:
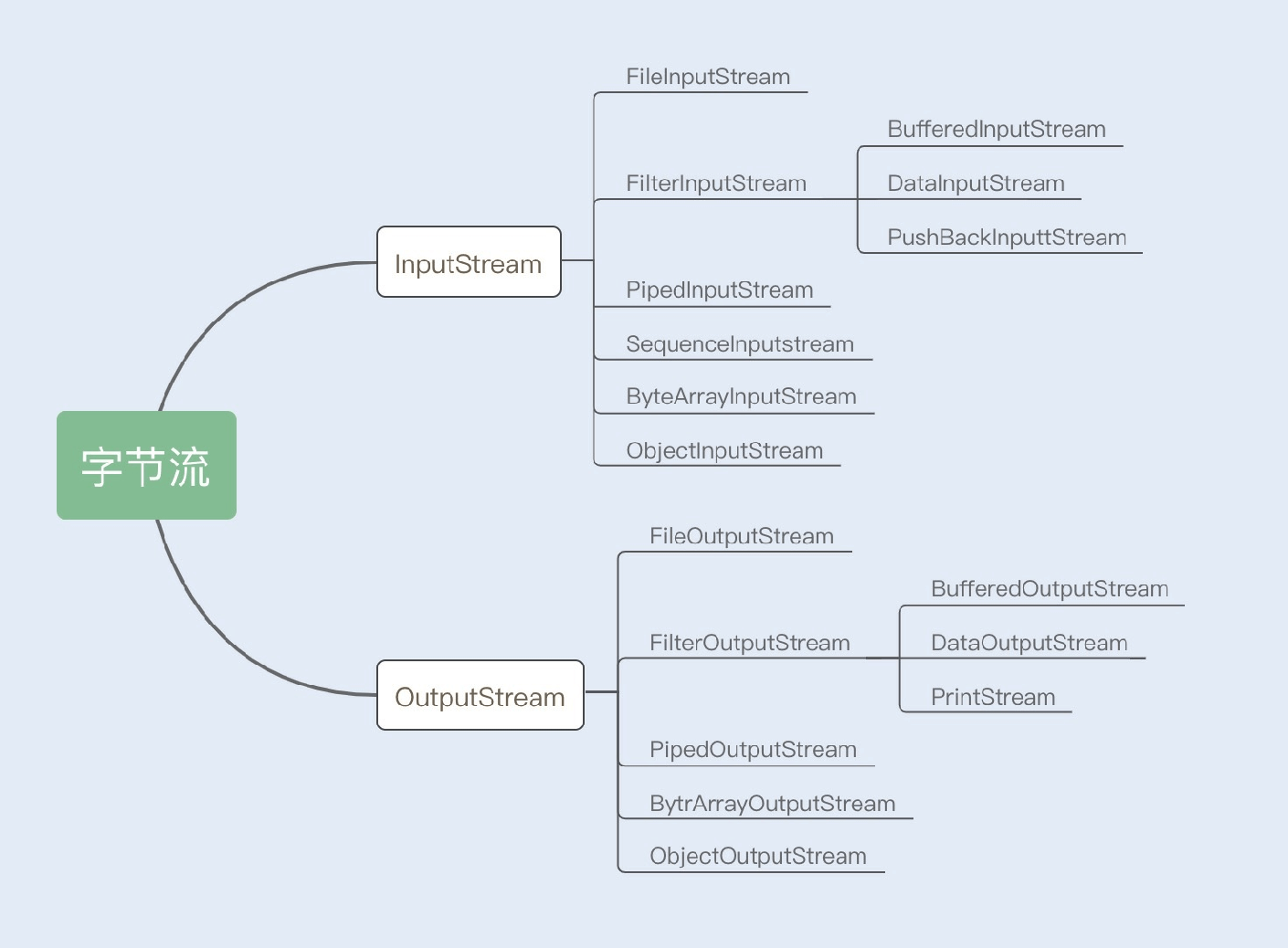
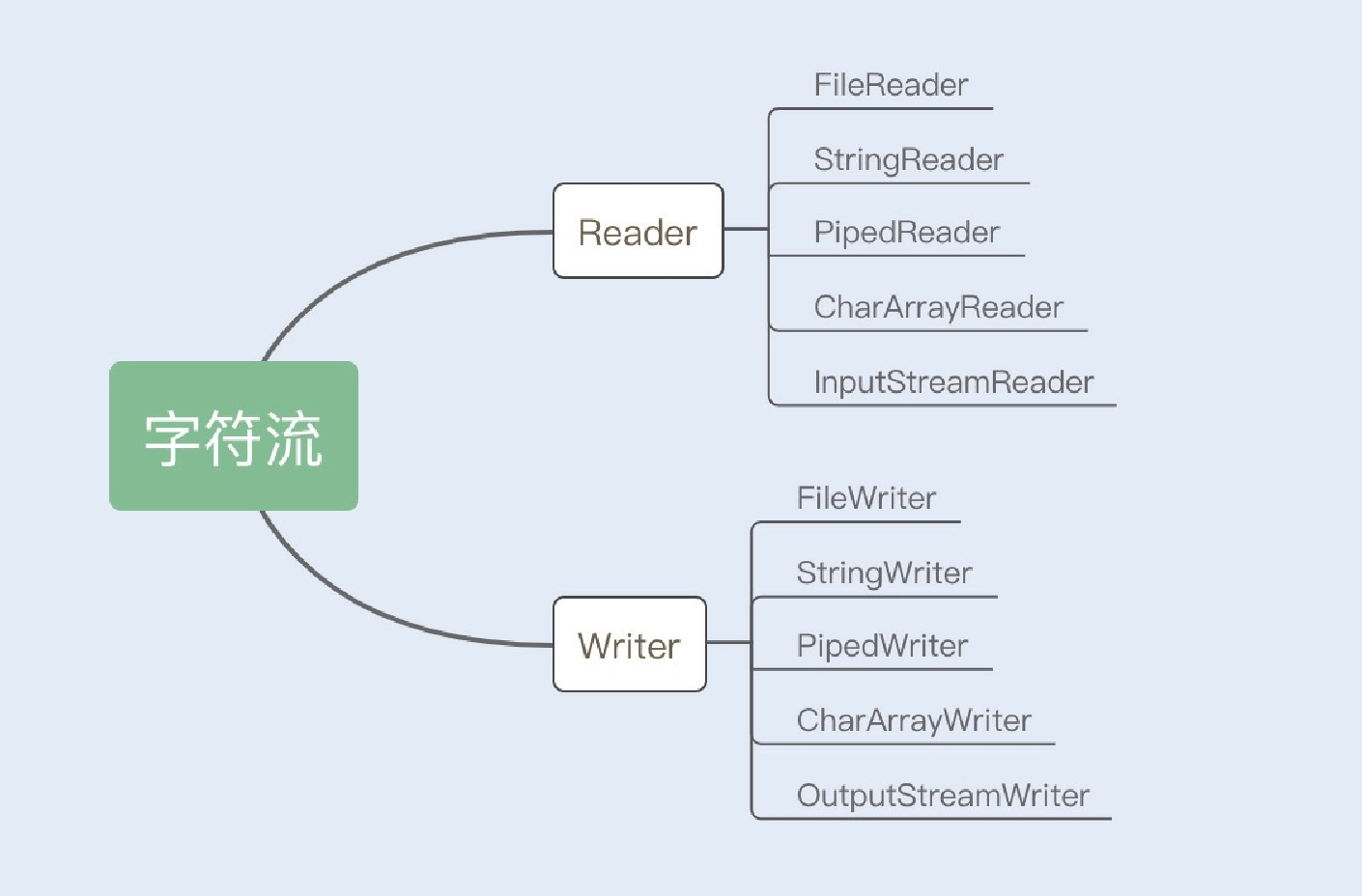
2.字符流
Reader/Writer是字符流的抽象类,这两个抽象类也派⽣出了若⼲⼦类,不同的⼦类分别处理不同的操作类型,具体内容如下图所示:
传统I/O的性能问题
我们知道,I/O操作分为磁盘I/O操作和⽹络I/O操作。前者是从磁盘中读取数据源输⼊到内存中,之后将读取的信息持久化输出在物理磁盘上;后者是从⽹络中读取信息输⼊到内存,最终将信息输出到⽹络中。但不管是磁盘I/O还是⽹络I/O,在传统I/O中都存在严重的性能问题。
1.多次内存复制
在传统I/O中,我们可以通过InputStream从源数据中读取数据流输⼊到缓冲区⾥,通过OutputStream将数据输出到外部设备
(包括磁盘、⽹络)。你可以先看下输⼊操作在操作系统中的具体流程,如下图所示: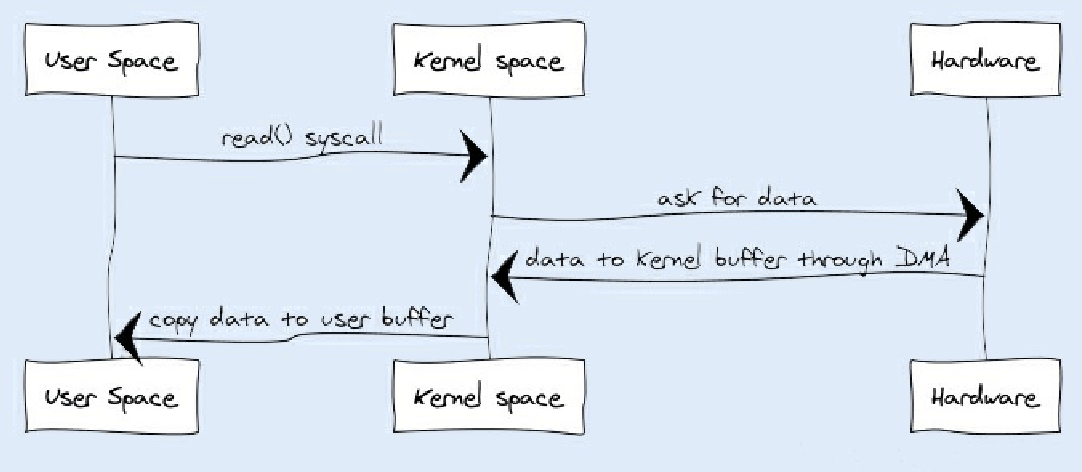
JVM会发出read()系统调⽤,并通过read系统调⽤向内核发起读请求; 内核向硬件发送读指令,并等待读就绪;
内核把将要读取的数据复制到指向的内核缓存中;
操作系统内核将数据复制到⽤户空间缓冲区,然后read系统调⽤返回。
在这个过程中,数据先从外部设备复制到内核空间,再从内核空间复制到⽤户空间,这就发⽣了两次内存复制操作。这种操作会导致不必要的数据拷⻉和上下⽂切换,从⽽降低I/O的性能。
2.阻塞
在传统I/O中,InputStream的read()是⼀个while循环操作,它会⼀直等待数据读取,直到数据就绪才会返回。这就意味着如果没有数据就绪,这个读取操作将会⼀直被挂起,⽤户线程将会处于阻塞状态。
在少量连接请求的情况下,使⽤这种⽅式没有问题,响应速度也很⾼。但在发⽣⼤量连接请求时,就需要创建⼤量监听线程, 这时如果线程没有数据就绪就会被挂起,然后进⼊阻塞状态。⼀旦发⽣线程阻塞,这些线程将会不断地抢夺CPU资源,从⽽ 导致⼤量的CPU上下⽂切换,增加系统的性能开销。
如何优化I/O操作
⾯对以上两个性能问题,不仅编程语⾔对此做了优化,各个操作系统也进⼀步优化了I/O。JDK1.4发布了java.nio包(new I/O 的缩写),NIO的发布优化了内存复制以及阻塞导致的严重性能问题。JDK1.7⼜发布了NIO2,提出了从操作系统层⾯实现的异步I/O。下⾯我们就来了解下具体的优化实现。
1.使⽤缓冲区优化读写流操作
在传统I/O中,提供了基于流的I/O实现,即InputStream和OutputStream,这种基于流的实现以字节为单位处理数据。
NIO与传统 I/O 不同,它是基于块(Block)的,它以块为基本单位处理数据。在NIO中,最为重要的两个组件是缓冲区
(Buffer)和通道(Channel)。Buffer是⼀块连续的内存块,是 NIO 读写数据的中转地。Channel表示缓冲数据的源头或者⽬的地,它⽤于读取缓冲或者写⼊数据,是访问缓冲的接⼝。
传统I/O和NIO的最⼤区别就是传统I/O是⾯向流,NIO是⾯向Buffer。Buffer可以将⽂件⼀次性读⼊内存再做后续处理,⽽传统的⽅式是边读⽂件边处理数据。虽然传统I/O后⾯也使⽤了缓冲块,例如BufferedInputStream,但仍然不能和NIO相媲美。使
⽤NIO替代传统I/O操作,可以提升系统的整体性能,效果⽴竿⻅影。
2.使⽤DirectBuffer减少内存复制
NIO的Buffer除了做了缓冲块优化之外,还提供了⼀个可以直接访问物理内存的类DirectBuffer。普通的Buffer分配的是JVM堆内存,⽽DirectBuffer是直接分配物理内存。
我们知道数据要输出到外部设备,必须先从⽤户空间复制到内核空间,再复制到输出设备,⽽DirectBuffer则是直接将步骤简化为从内核空间复制到外部设备,减少了数据拷⻉。
这⾥拓展⼀点,由于DirectBuffer申请的是⾮JVM的物理内存,所以创建和销毁的代价很⾼。DirectBuffer申请的内存并不是直接由JVM负责垃圾回收,但在DirectBuffer包装类被回收时,会通过Java Reference机制来释放该内存块。
3.避免阻塞,优化I/O操作
NIO很多⼈也称之为Non-block I/O,即⾮阻塞I/O,因为这样叫,更能体现它的特点。为什么这么说呢?
传统的I/O即使使⽤了缓冲块,依然存在阻塞问题。由于线程池线程数量有限,⼀旦发⽣⼤量并发请求,超过最⼤数量的线程 就只能等待,直到线程池中有空闲的线程可以被复⽤。⽽对Socket的输⼊流进⾏读取时,读取流会⼀直阻塞,直到发⽣以下三种情况的任意⼀种才会解除阻塞:
有数据可读;
连接释放;
空指针或I/O异常。
阻塞问题,就是传统I/O最⼤的弊端。NIO发布后,通道和多路复⽤器这两个基本组件实现了NIO的⾮阻塞,下⾯我们就⼀起来了解下这两个组件的优化原理。
通道(Channel)
前⾯我们讨论过,传统I/O的数据读取和写⼊是从⽤户空间到内核空间来回复制,⽽内核空间的数据是通过操作系统层⾯的I/O 接⼝从磁盘读取或写⼊。
最开始,在应⽤程序调⽤操作系统I/O接⼝时,是由CPU完成分配,这种⽅式最⼤的问题是“发⽣⼤量I/O请求时,⾮常消耗
CPU“;之后,操作系统引⼊了DMA(直接存储器存储),内核空间与磁盘之间的存取完全由DMA负责,但这种⽅式依然需要向CPU申请权限,且需要借助DMA总线来完成数据的复制操作,如果DMA总线过多,就会造成总线冲突。
通道的出现解决了以上问题,Channel有⾃⼰的处理器,可以完成内核空间和磁盘之间的I/O操作。在NIO中,我们读取和写⼊数据都要通过Channel,由于Channel是双向的,所以读、写可以同时进⾏。
多路复⽤器(Selector)
Selector是Java NIO编程的基础。⽤于检查⼀个或多个NIO Channel的状态是否处于可读、可写。
Selector是基于事件驱动实现的,我们可以在Selector中注册accpet、read监听事件,Selector会不断轮询注册在其上的
Channel,如果某个Channel上⾯发⽣监听事件,这个Channel就处于就绪状态,然后进⾏I/O操作。
⼀个线程使⽤⼀个Selector,通过轮询的⽅式,可以监听多个Channel上的事件。我们可以在注册Channel时设置该通道为⾮阻塞,当Channel上没有I/O操作时,该线程就不会⼀直等待了,⽽是会不断轮询所有Channel,从⽽避免发⽣阻塞。
⽬前操作系统的I/O多路复⽤机制都使⽤了epoll,相⽐传统的select机制,epoll没有最⼤连接句柄1024的限制。所以Selector 在理论上可以轮询成千上万的客户端。
下⾯我⽤⼀个⽣活化的场景来举例,看完你就更清楚Channel和Selector在⾮阻塞I/O中承担什么⻆⾊,发挥什么作⽤了。
我们可以把监听多个I/O连接请求⽐作⼀个⽕⻋站的进站⼝。以前检票只能让搭乘就近⼀趟发⻋的旅客提前进站,⽽且只有⼀个检票员,这时如果有其他⻋次的旅客要进站,就只能在站⼝排队。这就相当于最早没有实现线程池的I/O操作。
后来⽕⻋站升级了,多了⼏个检票⼊⼝,允许不同⻋次的旅客从各⾃对应的检票⼊⼝进站。这就相当于⽤多线程创建了多个监听线程,同时监听各个客户端的I/O请求。
最后⽕⻋站进⾏了升级改造,可以容纳更多旅客了,每个⻋次载客更多了,⽽且⻋次也安排合理,乘客不再扎堆排队,可以从
⼀个⼤的统⼀的检票⼝进站了,这⼀个检票⼝可以同时检票多个⻋次。这个⼤的检票⼝就相当于Selector,⻋次就相当于
Channel,旅客就相当于I/O流。
总结
Java的传统I/O开始是基于InputStream和OutputStream两个操作流实现的,这种流操作是以字节为单位,如果在⾼并发、⼤ 数据场景中,很容易导致阻塞,因此这种操作的性能是⾮常差的。还有,输出数据从⽤户空间复制到内核空间,再复制到输出设备,这样的操作会增加系统的性能开销。
传统I/O后来使⽤了Buffer优化了“阻塞”这个性能问题,以缓冲块作为最⼩单位,但相⽐整体性能来说依然不尽⼈意。
于是NIO发布,它是基于缓冲块为单位的流操作,在Buffer的基础上,新增了两个组件“管道和多路复⽤器”,实现了⾮阻塞
I/O,NIO适⽤于发⽣⼤量I/O连接请求的场景,这三个组件共同提升了I/O的整体性能。
你可以在Github上通过⼏个简单的例⼦来实践下传统IO、NIO。
思考题
在JDK1.7版本中,Java发布了NIO的升级包NIO2,也就是AIO。AIO实现了真正意义上的异步I/O,它是直接将I/O操作交给操作系统进⾏异步处理。这也是对I/O操作的⼀种优化,那为什么现在很多容器的通信框架都还是使⽤NIO呢?
期待在留⾔区看到你的⻅解。也欢迎你点击“请朋友读”,把今天的内容分享给身边的朋友,邀请他⼀起学习。
精选留⾔ <br />⽪⽪<br />⽼师,个⼈觉得本期的内容讲的稍微浅了⼀点,关于IO的⼏种常⻅模型可以配图讲⼀下的,另外就是linux下的select,poll,ep<br />oll的对⽐应⽤场景。最重要的⽬前⽤的最多的IO多路复⽤可以深⼊讲⼀下的。<br />2019-06-06 13:06<br />作者回复<br />你好,这篇I/O性能优化主要是普及NIO对I/O的性能优化。I/O这块的知识点很多,包括IO模型、事件处理模型以及操作系统层的事件驱动,如果都压缩到⼀讲,由于字数有限,很难讲完整。对于⼀些童鞋来说,也不好理解。
我将会在后⾯的⼀讲中,补充⼤家提到的⼀些内容。谢谢你的建议。
2019-06-06 20:21
 张学磊
张学磊
在Linux中,AIO并未真正使⽤操作系统所提供的异步I/O,它仍然使⽤poll或epoll,并将API封装为异步I/O的样⼦,但是其本质 仍然是同步⾮阻塞I/O,加上第三⽅产品的出现,Java⽹络编程明显落后,所以没有成为主流
2019-06-06 08:32
作者回复
对的,异步I/O模型在Linux内核中没有实现
2019-06-10 22:00
 Geek_8043c2
Geek_8043c2
很多知识linux ⽹络 I/O模型底层原理,零拷⻉技术等深⼊讲⼀下,毕竟学Java性能调优的学员都是有⼏年⼯作经验的, 希望⽼师后⾯能专⻔针对这次io 出个补充,这⼀讲⽐较不够深⼊。
2019-06-07 10:14
作者回复
这⼀讲中提到了DirectBuffer,也就是零拷⻉的实现。谢谢你的建议,后⾯我会补充下⼏种⽹络I/O模型的底层原理。
2019-06-10 21:51
 Only now
Only now
⽼师能不能讲讲DMA和Channel的区别, DMA需要占⽤总线, 那么Channel是如何跳过总线向内存传输数据的?
2019-06-06 15:19
作者回复
⼀个设备接⼝试图通过总线直接向外部设备(磁盘)传送数据时,它会先向CPU发送DMA请求信号。外部设备(磁盘)通过DMA的
⼀种专⻔接⼝电路――DMA控制器(DMAC),向CPU提出接管总线控制权的总线请求,CPU收到该信号后,在当前的总线周期结束后,会按DMA信号的优先级和提出DMA请求的先后顺序响应DMA信号。CPU对某个设备接⼝响应DMA请求时,会让出总线控制权。于是在DMA控制器的管理下,磁盘和存储器直接进⾏数据交换,⽽不需CPU⼲预。数据传送完毕后,设备接⼝会向CPU发送DMA结束信号,交还总线控制权。
⽽通道则是在DMA的基础上增加了能执⾏有限通道指令的I/O控制器,代替CPU管理控制外设。通道有⾃⼰的指令系统,是⼀个协处理器,他实质是⼀台能够执⾏有限的输⼊输出指令,并且有专⻔通讯传输的通道总线完成控制。
2019-06-07 09:48
 ZOU志伟
ZOU志伟
⽼师,为什么要字符流还是没懂
2019-06-19 18:26
 vvsuperman
vvsuperman
建议加写例⼦,⽐如tomcat⽤的io造成阻塞之类,实例分析等
2019-06-06 14:31
作者回复
感谢这位同学的建议,⽼师会在11讲中集中补充有关IO的⼀些实战内容。
2019-06-06 23:17
 相瑜以沫
相瑜以沫
⽼师,请教个问题,如果是⻓连接下,⾼并发应该怎么样设计⽅案更合理呢,谢谢
2019-07-02 23:49
 -W.LI-
-W.LI-
⽼师好!隔壁的李好双⽼师说⼀次普通IO需要要进过六次拷⻉。
⽹卡->内核->临时本地内存->堆内存->临时本地内存->内核->⽹卡。
directbfuffer下
⽹卡->内核->本地内存->内核->⽹卡
ARP下C直接调⽤
⽂件->内核->⽹卡。李⽼师说的对么?
本地内存和堆内存都是在⽤户空间的是么?
2019-06-20 08:49
 325G
325G
我们可以在注册 Channel 时设置该通道为⾮阻塞,当 Channel 上没有 I/O 操作时,该线程就不会⼀直等待了,⽽是会不断轮询所有 Channel,从⽽避免发⽣阻塞。
如果⼀个Channel上I/O耗时很⻓是不是后续的Channel就被阻塞了?
2019-06-17 12:06
作者回复
是的。如果I/O操作时间⽐较⻓,我们可以创建新的⼀个线程来执⾏I/O操作,避免阻塞Reactor从线程。
2019-06-18 09:35 ⼩荷才露尖尖⻆
⼩荷才露尖尖⻆
谢谢⽼师! 我觉得从基础讲起再深⼊挺好的 有逻辑与层次感, ⼀上来就是好⾼深的内容 就会让⼀半道⾏没够的同学放弃治疗了。
2019-06-16 14:01
 Geek_37bdff
Geek_37bdff
⽼师,您好,能通俗解释⼀下什么是同步阻塞,异步阻塞,同步⾮阻塞,异步⾮阻塞这些概念不,还有就是nio是属于同步⾮阻塞还是异步⾮阻塞,为什么
2019-06-12 10:55
作者回复
同学你好!周四即将更新的11讲答疑课堂就能解决你的问题。到时如有疑问,可以继续给⽼师留⾔。
2019-06-12 17:36
 知⾏合⼀
知⾏合⼀
思考题:是因为会很耗费cpu吗?
2019-06-10 20:41
作者回复
答案已经有同学给出了,异步I/O没有在Linux内核中实现
2019-06-10 22:01
 z.l
z.l
从⽂章的描述我猜测DirectBuffer属于内核空间的内存,但java作为⽤户进城是如何操作内核空间内存的呢?
2019-06-09 23:13
Geek_801517
⽼师,我也觉得今天的内容浅了⼀点,nio的多路复⽤也可以深⼊讲下或者netty的实现,epoll这些也是,还有其他io模型也可以对⽐下
2019-06-09 01:30
作者回复
收到~⽼师会集中⼤家的留⾔,在11讲答疑课堂中做出补充讲解。感谢你的建议!
2019-06-09 02:32
 晓杰
晓杰
⽼师,channel只是解决了内核空间和磁盘之前的io操作问题,那⽤户空间和内核空间之间的来回复制是不是依然是⼀个耗时的 操作
2019-06-07 10:52
作者回复
这讲中提到了零拷⻉,⽤DirectBuffer减少内存复制,也就是避免了⽤户空间与内核空间来回复制。
2019-06-10 21:48
 -W.LI-
-W.LI-
⽼师好!能说下哪些操作需要在⽤户态下完成么?正常的代码运⾏⽤户态就可以了是吗?
1.创建selector
2.创建serverSockekChannel
3.OP_ACCEPT事件注册到selector中
4.监听到OP_ACCEPT事件
5.创建channel
6.OP_READ事件注册到selector中
7.监听到READ事件
8.从channel中读数据
读的时候需要先切换到内核模式,复制在内核空间,然后从内核空间复制到⽤户空间。
9.处理数据
10.write:⽤户模式切换到内核模式,从⽤户空间复制到内核空间,再从内核空间发送到IO⽹络上。
1-7步⾥⾯有哪些操作需要在内核模式下执⾏的么?
第8和10我是不是理解错了?
DMA啥时候起作⽤啊?
JVM的内存属于⽤户空间是吧,directBuffer直接申请的物理内存,是属于特殊的⽤户空间么。内核模式直接往那⾥写。kafka
的0拷⻉和directbuffer⼀个意思么?╯﹏╰都不知道
2019-06-06 13:39 圣⻄罗
圣⻄罗
使⽤webflux的过程中最⼤的不⽅便是不⽀持threadlocal,导致像创建⼈修改⼈id的赋值需要明传参数
2019-06-06 09:01
胖妞
git上的测试案例有吗?想很多通过时间具体对⽐⼀下!总感觉讲的有点抽象和概念了,脑⼦⾥没有形成⼀个具体的形象!希望能给⼏个⼩demo看⼀下!麻烦了!
2019-06-06 07:47
作者回复
git上有源码,分别是io和nio的简单实现的demo。如果需要通过简单的代码测试⽐对两者的性能,可以⾃⼰尝试⼀下,有疑问可以再问⽼师。
2019-06-06 08:26

若有收获,就点个赞吧
0 人点赞
