 17讲并发容器的使⽤:识别不同场景下最优容器
17讲并发容器的使⽤:识别不同场景下最优容器
你好,我是刘超。
在并发编程中,我们经常会⽤到容器。今天我要和你分享的话题就是:在不同场景下我们该如何选择最优容器。
 并发场景下的Map容器
并发场景下的Map容器
假设我们现在要给⼀个电商系统设计⼀个简单的统计商品销量TOP 10的功能。常规情况下,我们是⽤⼀个哈希表来存储商品和销量键值对,然后使⽤排序获得销量前⼗的商品。在这⾥,哈希表是实现该功能的关键。那么请思考⼀下,如果要你设计这个功能,你会使⽤哪个容器呢?
在07讲中,我曾详细讲过HashMap的实现原理,以及HashMap结构的各个优化细节。我说过HashMap的性能优越,经常被⽤来存储键值对。那么这⾥我们可以使⽤HashMap吗?
答案是不可以,我们切忌在并发场景下使⽤HashMap。因为在JDK1.7之前,在并发场景下使⽤HashMap会出现死循环,从⽽导致CPU使⽤率居⾼不下,⽽扩容是导致死循环的主要原因。虽然Java在JDK1.8中修复了HashMap扩容导致的死循环问题, 但在⾼并发场景下,依然会有数据丢失以及不准确的情况出现。
这时为了保证容器的线程安全,Java实现了Hashtable、ConcurrentHashMap以及ConcurrentSkipListMap等Map容器。
Hashtable、ConcurrentHashMap是基于HashMap实现的,对于⼩数据量的存取⽐较有优势。
ConcurrentSkipListMap是基于TreeMap的设计原理实现的,略有不同的是前者基于跳表实现,后者基于红⿊树实
现,ConcurrentSkipListMap的特点是存取平均时间复杂度是O(log(n)),适⽤于⼤数据量存取的场景,最常⻅的是基于跳跃表实现的数据量⽐较⼤的缓存。
回归到开始的案例再看⼀下,如果这个电商系统的商品总量不是特别⼤的话,我们可以⽤Hashtable或ConcurrentHashMap来实现哈希表的功能。
Hashtable ConcurrentHashMap
更精准的话,我们可以进⼀步对⽐看看以上两种容器。
在数据不断地写⼊和删除,且不存在数据量累积以及数据排序的场景下,我们可以选⽤Hashtable或ConcurrentHashMap。
Hashtable使⽤Synchronized同步锁修饰了put、get、remove等⽅法,因此在⾼并发场景下,读写操作都会存在⼤量锁竞争, 给系统带来性能开销。
相⽐Hashtable,ConcurrentHashMap在保证线程安全的基础上兼具了更好的并发性能。在JDK1.7中,ConcurrentHashMap 就使⽤了分段锁Segment减⼩了锁粒度,最终优化了锁的并发操作。
到了JDK1.8,ConcurrentHashMap做了⼤量的改动,摒弃了Segment的概念。由于Synchronized锁在Java6之后的性能已经得到了很⼤的提升,所以在JDK1.8中,Java重新启⽤了Synchronized同步锁,通过Synchronized实现HashEntry作为锁粒 度。这种改动将数据结构变得更加简单了,操作也更加清晰流畅。
与JDK1.7的put⽅法⼀样,JDK1.8在添加元素时,在没有哈希冲突的情况下,会使⽤CAS进⾏添加元素操作;如果有冲突,则通过Synchronized将链表锁定,再执⾏接下来的操作。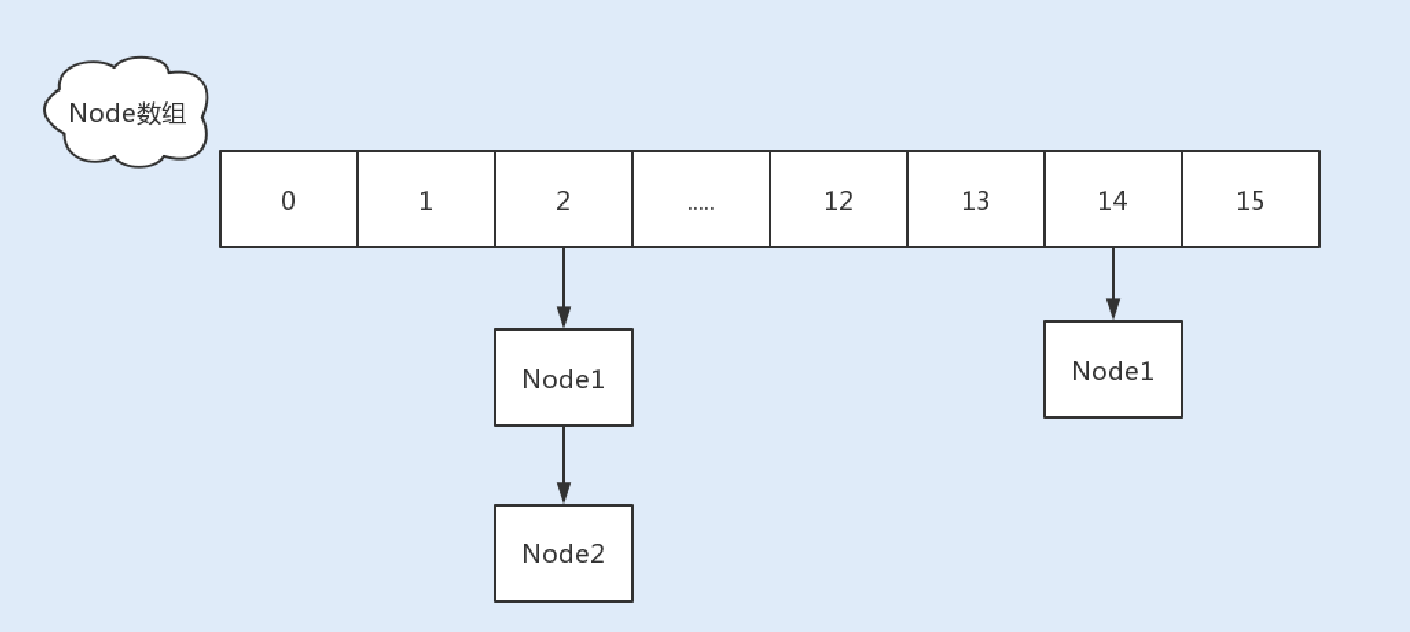
综上所述,我们在设计销量TOP10功能时,⾸选ConcurrentHashMap。
但要注意⼀点,虽然ConcurrentHashMap的整体性能要优于Hashtable,但在某些场景中,ConcurrentHashMap依然不能代替
Hashtable。例如,在强⼀致的场景中ConcurrentHashMap就不适⽤,原因是ConcurrentHashMap中的get、size等⽅法没有
⽤到锁,ConcurrentHashMap是弱⼀致性的,因此有可能会导致某次读⽆法⻢上获取到写⼊的数据。
ConcurrentHashMap ConcurrentSkipListMap
我们再看⼀个案例,我上家公司的操作系统中有这样⼀个功能,提醒⽤户⼿机卡实时流量不⾜。主要的流程是服务端先通过虚拟运营商同步⽤户实时流量,再通过⼿机端定时触发查询功能,如果流量不⾜,就弹出系统通知。
该功能的特点是⽤户量⼤,并发量⾼,写⼊多于查询操作。这时我们就需要设计⼀个缓存,⽤来存放这些⽤户以及对应的流量键值对信息。那么假设让你来实现⼀个简单的缓存,你会怎么设计呢?
你可能会考虑使⽤ConcurrentHashMap容器,但我在07讲中说过,该容器在数据量⽐较⼤的时候,链表会转换为红⿊树。红
⿊树在并发情况下,删除和插⼊过程中有个平衡的过程,会牵涉到⼤量节点,因此竞争锁资源的代价相对⽐较⾼。
⽽跳跃表的操作针对局部,需要锁住的节点少,因此在并发场景下的性能会更好⼀些。你可能会问了,在⾮线程安全的Map容
器中,我并没有看到基于跳跃表实现的SkipListMap呀?这是因为在⾮线程安全的Map容器中,基于红⿊树实现的TreeMap在单线程中的性能表现得并不⽐跳跃表差。
因此就实现了在⾮线程安全的Map容器中,⽤TreeMap容器来存取⼤数据;在线程安全的Map容器中,⽤SkipListMap容器来存取⼤数据。
那么ConcurrentSkipListMap是如何使⽤跳跃表来提升容器存取⼤数据的性能呢?我们先来了解下跳跃表的实现原理。
什么是跳跃表
跳跃表是基于链表扩展实现的⼀种特殊链表,类似于树的实现,跳跃表不仅实现了横向链表,还实现了垂直⽅向的分层索引。
⼀个跳跃表由若⼲层链表组成,每⼀层都实现了⼀个有序链表索引,只有最底层包含了所有数据,每⼀层由下往上依次通过⼀个指针指向上层相同值的元素,每层数据依次减少,等到了最顶层就只会保留部分数据了。
跳跃表的这种结构,是利⽤了空间换时间的⽅法来提⾼了查询效率。程序总是从最顶层开始查询访问,通过判断元素值来缩⼩查询范围。我们可以通过以下⼏张图来了解下跳跃表的具体实现原理。
⾸先是⼀个初始化的跳跃表: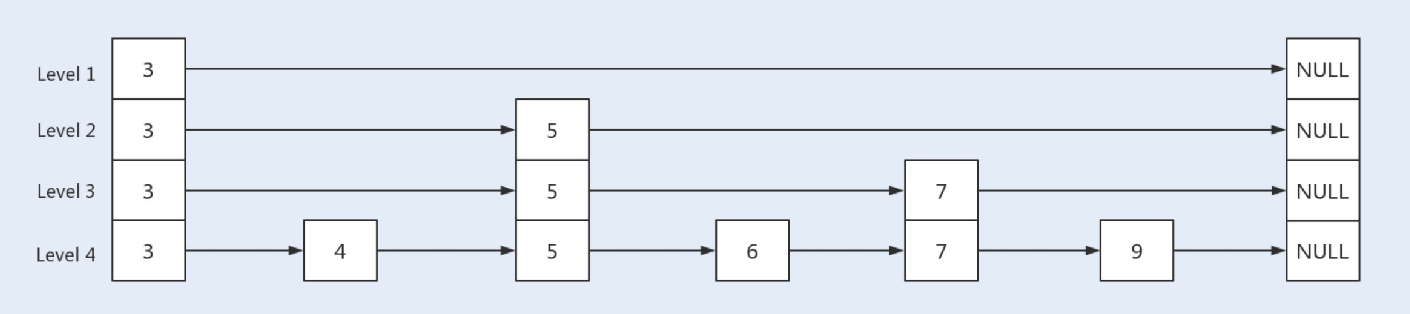
当查询key值为9的节点时,此时查询路径为: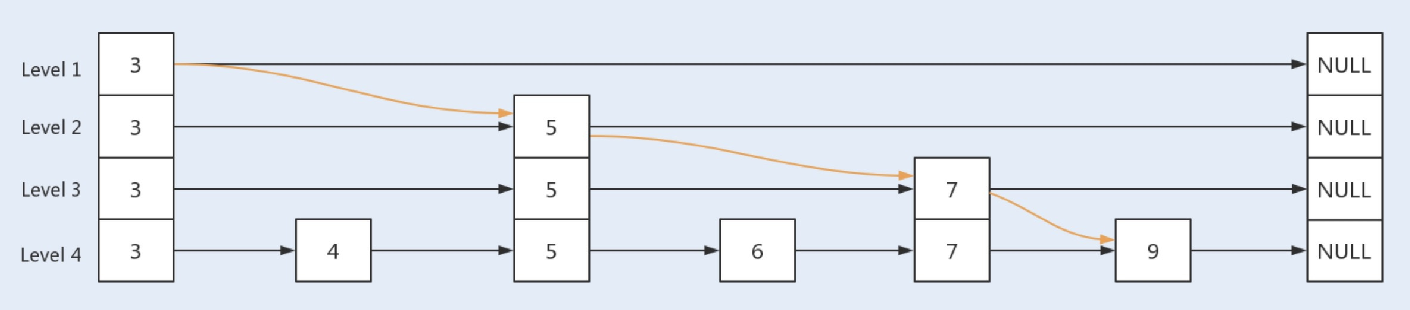
当新增⼀个key值为8的节点时,⾸先新增⼀个节点到最底层的链表中,根据概率算出level值,再根据level值新建索引层,最后链接索引层的新节点。新增节点和链接索引都是基于CAS操作实现。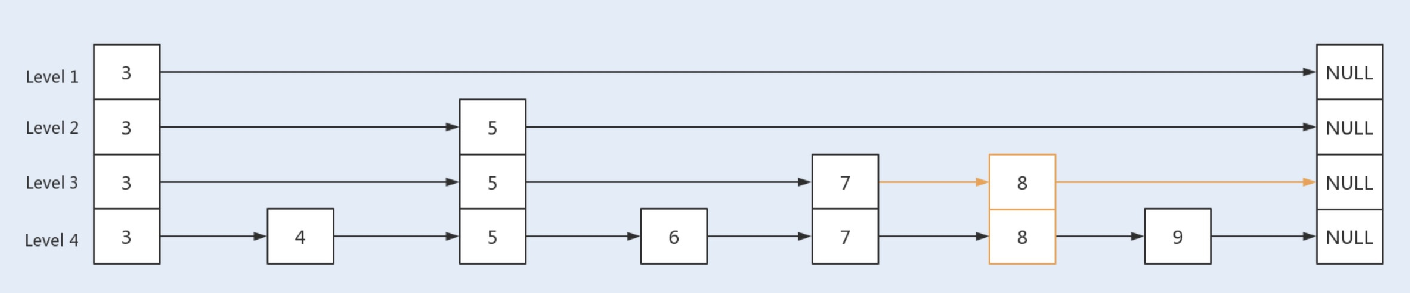
当删除⼀个key值为7的结点时,⾸先找到待删除结点,将其value值设置为null;之后再向待删除结点的next位置新增⼀个标记
结点,以便减少并发冲突;然后让待删结点的前驱节点直接越过本身指向的待删结点,直接指向后继结点,中间要被删除的结点最终将会被JVM垃圾回收处理掉;最后判断此次删除后是否导致某⼀索引层没有其它节点了,并视情况删除该层索引 。
通过以上两个案例,我想你应该清楚了Hashtable、ConcurrentHashMap以及ConcurrentSkipListMap这三种容器的适⽤场景了。
如果对数据有强⼀致要求,则需使⽤Hashtable;在⼤部分场景通常都是弱⼀致性的情况下,使⽤ConcurrentHashMap即可; 如果数据量在千万级别,且存在⼤量增删改操作,则可以考虑使⽤ConcurrentSkipListMap。
并发场景下的List容器
下⾯我们再来看⼀个实际⽣产环境中的案例。在⼤部分互联⽹产品中,都会设置⼀份⿊名单。例如,在电商系统中,系统可能会将⼀些频繁参与抢购却放弃付款的⽤户放⼊到⿊名单列表。想想这个时候你⼜会使⽤哪个容器呢?
⾸先⽤户⿊名单的数据量并不会很⼤,但在抢购中需要查询该容器,快速获取到该⽤户是否存在于⿊名单中。其次⽤户ID是整数类型,因此我们可以考虑使⽤数组来存储。那么ArrayList是否是你第⼀时间想到的呢?
我讲过ArrayList是⾮线程安全容器,在并发场景下使⽤很可能会导致线程安全问题。这时,我们就可以考虑使⽤Java在并发编程中提供的线程安全数组,包括Vector和CopyOnWriteArrayList。
Vector也是基于Synchronized同步锁实现的线程安全,Synchronized关键字⼏乎修饰了所有对外暴露的⽅法,所以在读远⼤于写的操作场景中,Vector将会发⽣⼤量锁竞争,从⽽给系统带来性能开销。
相⽐之下,CopyOnWriteArrayList是java.util.concurrent包提供的⽅法,它实现了读操作⽆锁,写操作则通过操作底层数组的新副本来实现,是⼀种读写分离的并发策略。我们可以通过以下图示来了解下CopyOnWriteArrayList的具体实现原理。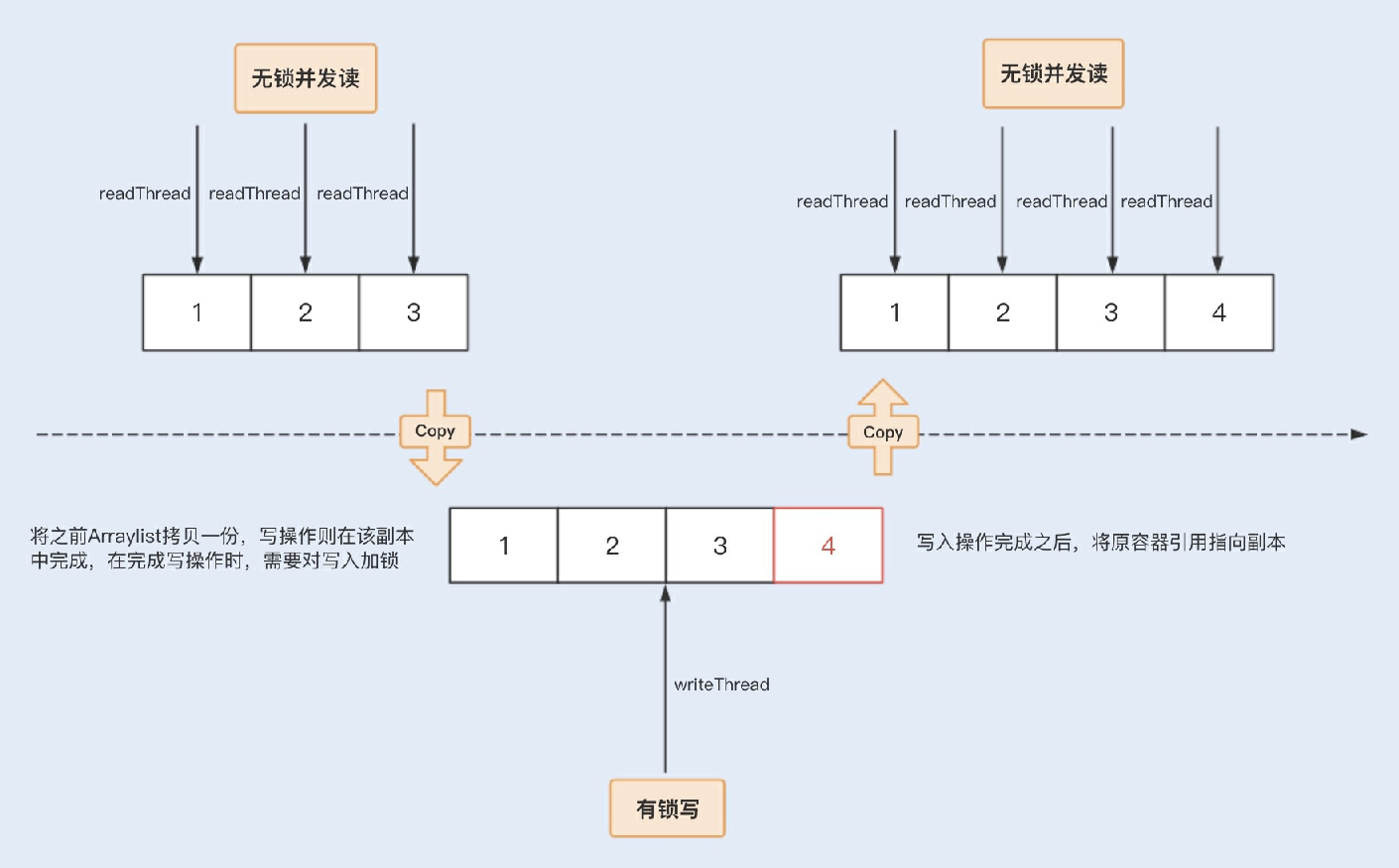
回到案例中,我们知道⿊名单是⼀个读远⼤于写的操作业务,我们可以固定在某⼀个业务⽐较空闲的时间点来更新名单。
这种场景对写⼊数据的实时获取并没有要求,因此我们只需要保证最终能获取到写⼊数组中的⽤户ID就可以了,⽽
CopyOnWriteArrayList这种并发数组容器⽆疑是最适合这类场景的了。
总结
在并发编程中,我们经常会使⽤容器来存储数据或对象。Java在JDK1.1到JDK1.8这个漫⻓的发展过程中,依据场景的变化实现了同类型的多种容器。我将今天的主要内容为你总结了⼀张表格,希望能对你有所帮助,也欢迎留⾔补充。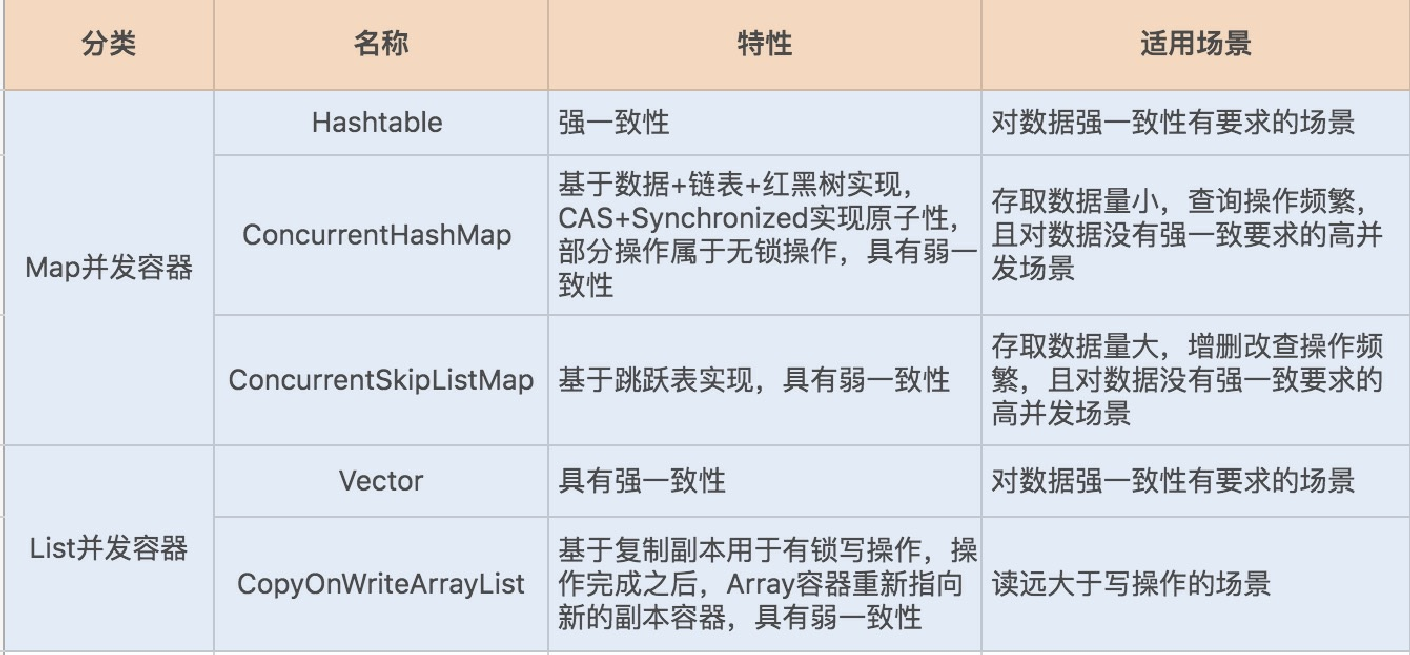
思考题 在抢购类系统中,我们经常会使⽤队列来实现抢购的排队等待,如果要你来选择或者设计⼀个队列,你会怎么考虑呢? 期待在留⾔区看到你的⻅解。也欢迎你点击“请朋友读”,把今天的内容分享给身边的朋友,邀请他⼀起学习。
在抢购类系统中,我们经常会使⽤队列来实现抢购的排队等待,如果要你来选择或者设计⼀个队列,你会怎么考虑呢? 期待在留⾔区看到你的⻅解。也欢迎你点击“请朋友读”,把今天的内容分享给身边的朋友,邀请他⼀起学习。
精选留⾔ <br />东⽅奇骥<br />如果数据变动频繁,就不建议使⽤CopyOnWriteArrayList了,因为每次写都要拷⻉⼀份,代价太⼤。⽼师,怎么直观理解强⼀ 致性和弱⼀致性?之前⼀直觉得ConcurrentHashMap就是⽤来代替HashTable的,因为HashTable并发时因为同步锁性能差。<br />2019-06-27 19:33<br />作者回复<br />对的,CopyOnWriteArrayList只适合偶尔⼀两次数据更改的操作。我们很多缓存数据往往是在深夜在没有读操作时,进⾏修改<br />。这种场景适合使⽤CopyOnWriteArrayList。
我们先来理解下happens-before规则中,对锁的规则:
⼀个unLock操作先⾏发⽣于后⾯对同⼀个锁的lock操作;
也就是说,ConcurrentHashMap中的get如果有锁操作,在put操作之后,get操作是⼀定能拿到put后的数据;⽽实际上get操作时没有锁的,也就是说下⾯这种情况:
void func(){ map.put(key1,value1); map.get(key1);
.
.
//use key1 value to do something
}
此时,get获取值的可能不是put修改的值,⽽此时get没有获取到真正要获取的值,此时就是弱⼀致了。
2019-06-28 11:30
 undifined
undifined
抢购的过程中存在并发操作,所以需要⽤线程安全的容器,同时,抢购的⽤户会很多,应当使⽤链表的数据结构,这种场景往往是写多读少,还需要排队,所以 ConcurrentLinkedQueue应该是最合适的
2019-06-27 08:22
作者回复
对的,ConcurrentLinkedQueue是基于CAS乐观锁来实现线程安全。ConcurrentLinkedQueue是⽆界的,所以使⽤的时候要特别注意内存溢出问题。
2019-06-27 09:33
 QQ怪
QQ怪
麻烦⽼师加餐出个queue并发相关的⽂章,感激不尽!!!
2019-06-27 22:00 ⼤雁⼩⻥
⼤雁⼩⻥
⽼师,ConcurrentHashMap为啥是弱⼀致性的?
2019-06-27 10:34
作者回复
因为ConcurrentHashMap有些⽅法是没有锁的,例如get ⽅法。假设A修改了数据,⽽B后于A⼀瞬间去获取数据,有可能拿到的数据是A修改之前的数据。
还有 clear foreach⽅法在操作时,都有可能存在数据不确定性。
2019-06-28 10:50
 WL
WL
请问⼀下⽼师两个问题:
- 为什么在⽆锁是红⿊树和跳表的性能差不多呢, 红⿊树再平衡的操作会不会更复杂⼀些.
- 从本篇⽂章看好像ConcurrentSkipListMap的性能⽐ConcurrentHashMap性能要好, 那为啥平时还是⽤后者的⼈更多呢, 我想很定是后者相对前者也有⼀定的优势吧, 但我⾃⼰没想出来, ⽼师能不能指点⼀下是啥优势.
2019-06-27 20:39
作者回复
1、两者的平均查询复杂度都是O(logn),所以查询性能差不多。⽽在新增和删除操作,红⿊树有平衡操作,但跳跃表也有建⽴ 索引层操作。跳跃表的结构简单易懂。
2、这⾥是基于数据量⽐较⼤(例如千万级别)且写⼊操作多的情况下,ConcurrentSkipListMap性能要⽐ConcurrentHashMap
好⼀些,并不是在任何情况下都要优于ConcurrentHashMap的。
2019-06-28 11:04
 Liam
Liam
⽼师,我有2个问题:
top 10 问题涉及到排序, 我感觉⽤优先级队列或带排序功能的ConcurrentSkipListMap更合适?ConcurrentHashMap不⽀持排序吧
CopyOnWrite的list为什么还要加锁呢,副本不是线程独享的吗?
2019-06-27 08:04
作者回复
ConcurrentSkipListMap只是key值的升排序,并没有对value进⾏排序;
CopyOnWrite在副本写时,是需要加锁的。
2019-06-28 11:37
 ⾏者
⾏者
redis中map的实现就是通过跳表来做的,简单⾼效。
2019-07-18 08:49
 Johnny
Johnny
还是不明⽩,concurrenthashmap的数组不是有volatile属性吗,就算没有锁变更了可以保证其他线程可⻅呀。happenbefore规则也是有这个的。
2019-07-17 10:07
作者回复
我已经在评论中回复相关问题了,麻烦查下。
2019-07-19 07:45
 Chaos
Chaos
⽼师,您好,如果这个业务⽤分布式锁,分布式锁是根据业务来决定锁定时间,但是如果业务没有执⾏完,但是redis释放了锁
,这时应该怎么办啊?
2019-07-08 09:34
作者回复
请问Chaos同学说的是⽤redis分布式锁实现抢购队列吗?
2019-07-08 16:35
 李
李
在⽬前线上机器都是多台部署的,想问下⽼师,如上的数据结构如何选择,或者⽤不到如上的选择,都彩⽟第3⽅存储,⽐如re
dis实现
2019-06-30 15:13
作者回复
⼀般分布式的缓存,我们都是基于redis实现存储。
2019-07-02 10:06
 WL
WL
赞成讲下那⼏个blockingQueue
2019-06-29 14:54 晓杰
晓杰
可以⽤ConcurrentLinkedQueue,优势如下:
1、抢购场景⼀般都是写多读少,该队列基于链表实现,所以新增和删除元素性能较⾼
2、写数据时通过cas操作,性能较⾼。
但是LinkedQueue有⼀个普遍存在的问题,就是该队列是⽆界的,需要控制容量,否则可能引起内存溢出
2019-06-28 11:00
作者回复
对的
2019-06-30 10:36
 nightmare
nightmare
抢购队列我觉得写⼤于读,链表⽐较合适,但是抢购数据确定,可以⽤linkedBlockQueue设置⻓度为抢购数据,就算分布式部署,为⾮也就是抢购数量乘以机器数据,ConcurentLinkedDeque⽆界队列不合适
2019-06-28 08:22 左瞳
左瞳
⿊名单查询⽤户是否存在不是应该⽤HashSet吗?
2019-06-28 07:46
作者回复
如果是单线程写⼊,可以考虑使⽤HashSet。
2019-06-28 09:12
 ….
….
元素增减对每层链表的变化是怎么样的
2019-06-28 00:06
作者回复
在新增时,是通过随机算出level值,根据level新建垂直索引链。
//获取⼀个线程⽆关的随机数,占四个字节,32 个⽐特位
int rnd = ThreadLocalRandom.nextSecondarySeed();
//和 1000 0000 0000 0000 0000 0000 0000 0001 与
//如果等于 0,说明这个随机数最⾼位和最低位都为 0,这种概率很⼤
//如果不等于 0,那么将仅仅把新节点插⼊到最底层的链表中即可,不会往上层递归
if ((rnd & 0x80000001) == 0) {
int level = 1, max;
//⽤低位连续为 1 的个数作为 level 的值,也是⼀种概率策略
while (((rnd >>>= 1) & 1) != 0)
++level;
Index
//如果概率算得的 level 在当前跳表 level 范围内
//构建⼀个从 1 到 level 的纵列 index 结点引⽤
if (level <= (max = h.level)) { for (int i = 1; i <= level; ++i)
idx = new Index
}
//否则需要新增⼀个 level 层
else {
level = max + 1;
@SuppressWarnings(“unchecked”)
Index
idxs[i] = idx = new Index
h = head;
int oldLevel = h.level;
//level 肯定是⽐ oldLevel ⼤⼀的,如果⼩了说明其他线程更新过表了
if (level <= oldLevel) break;
HeadIndex
//正常情况下,循环只会执⾏⼀次,如果由于其他线程的并发操作导致 oldLevel 的值不稳定,那么会执⾏多次循环体
for (int j = oldLevel+1; j <= level; ++j)
newh = new HeadIndex
//更新头指针
if (casHead(h, newh)) { h = newh;
idx = idxs[level = oldLevel]; break;
}
}
}
在删除时,会先删除底层的节点,最后通过扫描索引层是否失去了底层节点来回收掉索引层。
//判断此次删除后是否导致某⼀索引层没有其他节点了,并删除该层索引 if (head.right == null)
ryReduceLevel();
建议具体的可以深⼊到源码中查看。
2019-06-30 10:35
 Geek_75b4cd
Geek_75b4cd
我也没太明⽩什么叫弱⼀致性
2019-06-27 23:09
作者回复
我们先来理解下happens-before规则中,对锁的规则:
⼀个unLock操作先⾏发⽣于后⾯对同⼀个锁的lock操作;
也就是说,ConcurrentHashMap中的get如果有锁操作,在put操作之后,get操作是⼀定能拿到put后的数据;⽽实际上get操作时没有锁的,也就是说下⾯这种情况:
void func(){ map.put(key1,value1); map.get(key1);
.
.
//use key1 value to do something
}
此时,get获取值的可能不是put修改的值,⽽此时get没有获取到真正要获取的值,此时就是弱⼀致了。
2019-06-28 11:27
 QQ怪
QQ怪
我想问下⽼师,concurrentHashMap是⽆序的,我不太明⽩是如何完成Top10这个需求的,麻烦解答
2019-06-27 21:58
作者回复
我们后⾯说了,在获取排名时,需要对concurrentHashMap进⾏排序。
2019-06-28 09:14
 陆离
陆离
这⼀节要是有Queue就更好了,那⼏个blockingQueue还是很有意思的
2019-06-27 16:46
作者回复
多留⾔哦~说不定在下⼀期的加餐中就惊现福利了! ི
2019-06-27 20:25
 梁中华
梁中华
ConcurrentHashmap和ConcurrentSkipListMap在功能上的主要区别是前者不排序,后者⾃动排序。并⾮数据量上的区别吧。控制好ConcurrentHashmap⾥元素key的hashcode值,尽量减少碰撞,在数据量⽐较⼤的情况下可能⽐
ConcurrentSkipListMap的效率更好。
2019-06-27 10:43
作者回复
ConcurrentSkipListMap的key值是⼀个升序,⽽ConcurrentHashmap的默认没有排序。在查询速率来说,两者区别不⼤,区别在于存储⼤量数据情况下的写操作性能不⼀样。
2019-06-28 12:01
 -W.LI-
-W.LI-
⽼师好!为啥没有CopyOnWriteMap啊,ConpOnwriteArrayList。时间复杂度还是O(n)吧。
2019-06-27 09:26

若有收获,就点个赞吧
0 人点赞
