这是一篇比较老的文章,整理自阿里中间件团队分享的帖子。
发展到现在,尽管实现上有了很多升级,但是底层设计思想还是延续的,有相当的参考价值。
欢迎大家交流,我可以从使用层面上为大家答疑解惑。(毕竟不是大佬,设计就不谈太多了)
DRC 是什么?
DRC(Data Replication Center)是阿里技术保障-数据库技术团队自主研发的数据流产品,支持异构数据库实时同步,数据记录变更订阅服务。为跨域实时同步、实时增量分发、异地双活、分布式数据库等场景提供产品级的解决方案。DRC在阿里服务了数万个实时通道,在刚刚过去的 2015 双 11,DRC 峰值每秒解析一千万条记录,三单元同步平均延时 500ms。
DRC 今天已经是阿里巴巴的基础设施,支持电商异地多活、大数据实时抽取、搜索实时数据、蚂蚁商户账单,甚至双 11 的“酷毙了”的媒体大屏等。在云上已经有上百个外部用户通过阿里云数据传输产品 DTS 调用 DRC 建立自己的容灾体系。我认为 DRC 是阿里数据生产到数据消费的底层基础设施,就像网络一样无处不在。
DRC 是怎么做起来的?
很肯定的说,DRC 是以解决数据库的痛点为出发点的,是在一次次刚需驱动下做起来的。
大家知道 MySQL 数据库 Master 到 Slave 的同步,一直是单线程 apply。在 2011 年,淘宝的评价库作为一个写入大的应用,最早出现了主备延时,Slave 单线程 apply 很容易出现主备延时,因为主库的业务写入一直是并发的,再加上我们当时都是 SAS 硬盘(写入性能不足)。一般这种情况只能拆库,把库拆小一点,单实例写入就少一点。
另外就是淘宝一直在做单元化项目,最早叫做“走出杭州”,我们要在北方站点 A 建设一个单元来跑读流量,该项目 2009 年是冷备,2011 年开始试验流量,2012 年才有正式切读流量,2013 年实现淘宝最小单元化环境,2014 实现近距离异地双活,到今年双 11 实现远距离的异地多活,大家可能都听说过了。
2011 年站点 A 大概部署了几十台服务器,混跑全站 MySQL,远距离的单线程复制就更加不可保障延时了。技术上此时有两种解法,在 MySQL 内部做并发 apply,或者做个第三方工具模拟 Slave 拉数据再像应用一样并发写入 Slave。我们相信在内核里解一定是未来,但因为当时对 MySQL 内核把控没有足够把握,就先在外面做。
DRC 第一任开发者董开,在 MySQL 内核专家希羽的指导下,经历近半年的迭代,于 2011 年 9 月完成了第一个版本 DRC 1.0。一个进程负责实时拉取 MySQL 日志,并且并发写入 Slave,单进程干完所有的活。然后很快就发布了了 DRC v1.1,解决了过多线程重复拉 Slave 日志以及表过滤规则正则匹配。当时的架构大概是这样的[2011年10月]。
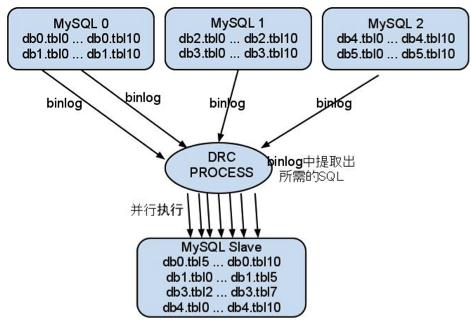
尽管理论上解决了问题,但这个版本配置复杂,易用性和稳定性很差,加上投入不足,DBA 一度质疑 DRC 的作用(当时我是 DBA,也是这么看的)。后来数据库内核专家丁奇了解了这个需求,用 MySQL 框架快速实现了一个 transfer,作为一个独立的 MySQL 进程,模拟从库拉日志,然后并发写备库。使用上相当于一个定制化的 Slave,跟 MySQL Slave 长得几乎一样,只有部署的 DBA 本人才知道那是一个 transfer。
当时 DRC 和 transfer 都在用,DBA 在实际工作中基本是遇到延时了就临时启一个,不延时就去掉,因此只有个别 DBA 会用到这两个工具。站点 A 单元本身 O 记延时就大,主要是应用和搜索测试。但是因为站点 A 没有部署完整链路,业务都是读,没有写逻辑,无法自己失效 Tair,跨域远程失效代价太大,因此需要依赖数据库日志来失效本地 Tair。DRC-Tair 版本 7 月份发布,站点 A 2011 年 8 月就已经用 DRC 来失效 Tair。
交易主库 2011 年 12 月底去 O 后,站点 A 读流量终于不依赖 O 记延时,开始规划 2012 年站点 A 正式跑生产流量,店铺、商品详情页等应用要支持 30% 的读流量,我们开始批量使用 DRC 用于杭州到站点 A 的复制。当时我们意识到这条链路是非常重要的生产依赖,开始找人才加大投入。
去 IOE 后大量使用 MySQL,DBA 开始感到不幸福了。除了运维自动化程度不够之外,还因为拆库拆表非常频繁,每次都要去通知下游,漏通知一个就会故障。而此时数据库,除了 DRC 同步站点 A 链路外,还有非常多的账号来拉取数据,搜索每天晚上全量拉数据,数仓也是按表拉全量,业务也开始使用精卫来拉数据做业务逻辑,而部分数仓实时业务也想把增量的 O 记版的 dbsync 改成 MySQL 版。这就意味着核心库除了前台业务外,还会有至少 5 个下游账号,预期还会增加。而一个业务方内部也会有很多子团队,因此拆一个库要通知十几个团队是很正常的,靠接口人发邮件,然后晚上拆库时一起熬夜改配置。上下游都很痛苦,一个漏通知就故障了。另外,数据库性能瓶颈和账号安全性也是很大问题,因为一般拉数据都是公共账号,内部多团队共用。
因此,我一直希望 DRC 把单进程的抓取和写入分开成两个进程,通过进程间通信做到一次抓取,多次分发,至少以后新接入不要再建账号拉数据了。这时,一个契机来了,搜索刚好也在做技术迭代、做实时搜索。DBA 和搜索团队达成全改增的一致目标,2012 年 1 月份基本确认需求。
当时 DRC 已经有站点A数据同步和失效 Tair 链路的业务,是一个选择,而另一个阿里内部的数据分发工具精卫正在同步给前台业务逻辑,数仓 dbsync 在同步离线抽取,但这些工具里面没有一个可以马上服务于搜索,都要经过改造。
此时 DRC 已经在考虑统一同步链路的设计,2012 年 1 月的插件化设计文档,只解决各种数据库间技术差异的问题,不解决 DRC 数据服务问题。
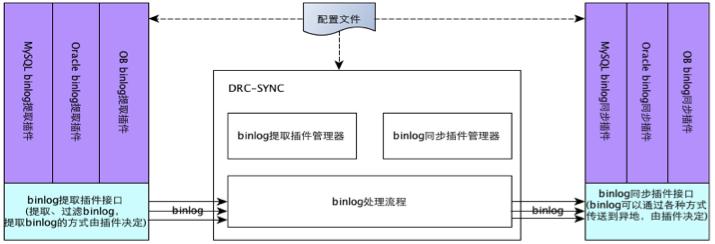
刚才提到的数据库拆库要通知下游,2012 年站点 A 的实时需求,多个账号的同时存在,都是我们必须去解决掉的。因此我们必须建设一个增量同步中心,而当时可以说没有任何工具能够同时解决这些问题,除了 DRC。
因为 DRC 从第一天设计开始,就选择了一条最难的路,保障数据库的事务一致性,包括 DDL(表结构变更)也可以进行同步或过滤。而这是其他数据同步产品第一天就想避开的,因为那样简单高效。而 DBA 天生就在这个坑里,绝对不能让主备不一致、或事务不完整,哪怕只是一条数据。而且 DBA 迫切希望以后不用通知下游了,让 DRC 自动适配主备切换或拆库。
后面的路该怎么走其实很清晰,但是我们首先要服务好搜索这个业务。杰睿、二败、赤天三个主力开发,玉龙负责测试,本空作为架构师,开始考虑抓取和写入对不同的数据源插件化,引入 zookeeper,调研 Server?Framework 做集群管理和路由。中间经历好几个版本,把各模块原型都开发完了,大概 5 月份,整体架构已经基本完成。此时主要考虑的需求有 4 个:
1. 机房容灾(站点 A 异地实时读)
2. 搜索的增量数据同步
3. 阿里云 RDS 数据库版本升级的数据迁移
4. MySQL 数据导入到 OceanBase(集团业务上 OB 迁移)
DRC 团队提出了三大技术前提:
1).强一致性;
2).实时性(<1S)
3).强鲁棒性。
全力以赴,守护这几点。
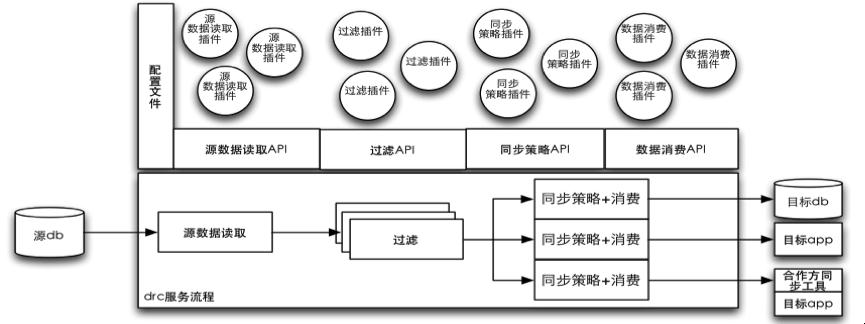
**
原架构:通过插件支持多种源和目的,单机版工作,需要较多运维配套。
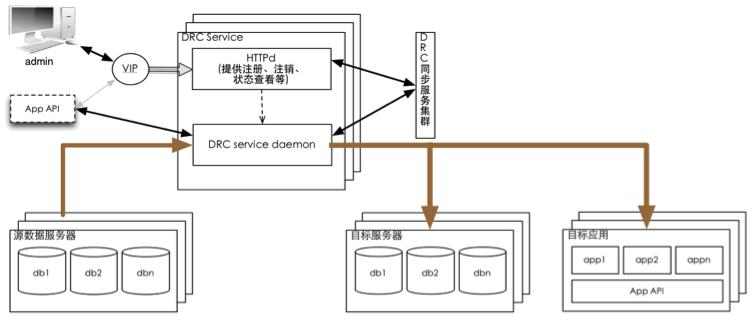
目标架构:集群管理,支持单点故障自动容灾,支持调用httpd接口创建和管理任务。
定下搜索增量服务的目标后,当时还有很多其他的需求需要经常沟通和核对,感谢玉龙记下这些珍贵的资料。
这段时间,我很少关注 DRC,但我知道在角落里,有两个人天天干到深夜。二败和杰睿为了兑现给客户的承诺,为了心中的梦想,不眠不休。这段时间,我在做 DBFree 运维平台,对 DRC 的希望是,站点 A 不要延时太大。另外生产上我让吉远做了个工具,可以在 MySQL 原生复制和 DRC 之间一键切换,我们靠这个应对了 2012 年双 11 的主备延时。
在开启高大上新篇章之前,我特别想说一下参与的同学。DRC 在 2011 年作为一个工具存在,还有很多问题很难解,董开压力巨大,走了。赤天前后脚进来,一直做失效 Tair 链路,直到 12 年 7 月离开 DRC。杰睿和二败在 12 年初进来,有了玉龙和本空协助,面临巨大的机遇和挑战。我经常说 DRC 干挂了两批人,活下来真心不容易,但有了阿里这个舞台,有了梦想的坚持,一切皆有可能。
2012 年 7 月,DRC 内部版本,实现 ClusterManager 原型,主要是路由功能和容灾守护,引入 zookeeper,已经和现在的架构非常接近,当时杰睿有个 DRC 免运维的梦想。2012 年 11 月,增量平台 v1.0 正式发布,支持自动主备切换,支持 DDL,支持库、表、列过滤。而搜索选择 DRC 的最主要原因是,DRC 提供了心跳信息,搜索一般只订阅几个表,如果这几个表没有新的业务写入,位点就会停止,搜索不知道是任务异常了还是没有数据。而 DRC 在整个库有任何写入都会推进心跳位点,搜索可以基于心跳位点做合并时间。这成为搜索选型时确定使用 DRC 的最核心因素。
此时 DRC 服务于站点 A MySQL 同步、Tair 失效、搜索和广告增量。虽然有集群管理,但依然是单进程服务架构,三个场景的进程版本不一样,使用插件式,已经支持数据库主备切换自动联动,DBA 不需要再通知上下游。
但是问题又来了,一方面,数据库已经有那么多账号各拉一份自己的数据,DBA 提出 DRC 一个账号只能来拉一次。另一方面,搜索业务已经成功上线,我们要合并版本,为马上要来的 2013 淘宝最小单元化环境准备。当时的 DBA 负责人后羿在交给我时,就已经提出了增量中心的目标,让数据库的账号安全和稳定性有保障。
我们做了两个重要业务决定,
1、做好小淘宝单元化是首要目标
2、做增量中心,收敛账号,降低实时链路维护成本(非搜索场景DBA的人工通知还在持续)。
2012 年底二败预研 LevelDB 做数据持久化,此时一个重要人物,来自华为的时勤博士加入,接手二败已经预发的版本,做 DRC Queue。2013 年 4 月年完成开发测试,DRC 具备数据持久化能力。3 月份我正式带 DRC 了,5 月延瑛加入。
我们在技术上做出两个重要技术决定,
1、抓取和写入作为两个进程分离,一次抓取,多次订阅,reader 继续插件化不变以支持多种数据源,合并 DRC 版本。
2、引入 embedded MySQL,所有的 DDL 都会内部执行一遍,为单元化架构准备,保障延时情况可复原数据格式,不丢一条,不错一条。
2013 年 7 月,DRC 单元化版本发布,同步和增量版本统一。
- Feature 持久化队列引擎
- Feature支持避免增量循环复制功能
- Feature 增量数据一对多分发
- Feature 数据事务并发复制
- Feature 增量任务自动容灾
- Feature 增量任务自动主备切换
问题来了,为什么是 DRC?
我深信只有足够艰苦的付出才能获得丰厚的回报。DRC 从第一天就选择了一条最难的路,做的是最底层,因此才能统一链路。从一开始,DRC 就是为了解决 MySQL 内核缺陷,DRC 团队找的人,全部都是数据库内核研发背景的。最最核心的是,DRC 是被 DBA 骂起来的,也是 DBA 在单元化过程中反复使用推动了迭代,没有一直在边上骂的 DBA,DRC 可能会取巧走偏,不会硬着头皮,把看似不可能变成可能。DRC 技术上最重要的三点,也是其他数据同步产品都不具备的能力。
- 保障事务的高效并发同步,DRC申请了多项事务冲突并发算法专利。其他同步产品不保障事务,保障事务是关系数据库同步的底线。
- MetaBuilder,解决回拉历史而表结构变更的问题,保障强一致。今天给你一条 binlog,你可以知道数据,但不知道格式,是 bigint 还是 varchar。如果是实时的,可以回查 DB 得到表结构 Meta,来获得格式并完成拼接,这就是取巧的做法,但如果不实时,回查 DB 时,DB 已经发生过 DDL,拉到的 Meta 不是这个日志当初产生的样子,就无解了。而 DRC 的内嵌 MySQL 会执行和同步每个 DDL,因此自己实时构造着和日志相同步调的 Meta 信息。
- DRC 的代码效率,不管是存储压缩、带宽压缩、实时性、吞吐性能,一直赶在单元化需求前面。虽然在单元化上摔过跤,但我们一直按数据库内核的质量要求保障着核心代码。
是什么成就了DRC?
如果觉得以上3点答案还不够,那么我想说我们最大的财富就是有一票 DBA 兄弟共同战斗。非常感谢最早天天梳理单元化逻辑到深夜的胜通,出故障时顶着压力的张瑞、云浩,做数据实时校验产品的千震、奚越。
当 DRC 团队在角落埋头苦干解决下面 3 个问题的时候,DBA 就在 DRC 的坑里一起扛着。我一直非常认可张瑞的一句话:没有 DBA,就没有 DRC。
- 站点 A 容灾机房,2009 年开始建。2011 年初核心去 O 后 MySQL 出现延时, DBA 经常重建 Slave。
- 2011-2013,大量的 MySQL,大量的下游公共账号,部分还非得拉主库,DBA 主备切换或拆库,要通知 10 多个团队,N 个邮件列表,大家一起熬夜变更,一旦出现漏通知故障就由 DBA 扛。
- 2013 年,淘宝最小单元化环境,数据库之间双向同步,循环复制。
2013 年除了淘宝最小单元化,搜索、数据仓库、阿里云 RDS 都已经使用 DRC 做同步或增量服务。我称之为 DRC 基础设施建设年。
2014 年,异地双活,阿里云官网上云,精卫也已经接入 DRC,我们提供了自动化接入能力。我称之为 DRC 基础设施落地年。
2015 年,也就是现在,是 DRC 的云上服务年,通过 DTS 提供数据同步服务。
DRC 作为数据库同步基础设施,功能更好,因为我们的对手是阿里数据生产到数据消费日益增长的需求和成本。DRC 要通过规模化服务能力,做好数据质量、稳定性和成本,成为网络一样无处不在的基础设施。
当我们聚焦在单元化场景时,现有架构已经可以把分发需求的服务成本边际化掉。但今天 DRC 的集群规模已经很大,线上几十个集群,最大的集群有接近 7000 个实时任务通道,目前正在进行着新一代集群架构研发,面向未来 3 年,支撑单集群 5 万个任务的管理。
最后,我想感谢一下曾经为 DRC 战斗,如今已经离开战线的老战友们。

若有收获,就点个赞吧
0 人点赞
