https://shimo.im/docs/tRTYQWGXJWT3qddg/ 《用研相关数据分析方法》,可复制链接后用石墨文档 App 或小程序打开
文档介绍
我们为什么要分析数据,我们想要得到什么?
我们想得到一些“洞察”,一些“规律”,例如数据组是如何分布的,数据中是否有相似度很高的一部分可以组成一个类别,两种数据之间是否有关联,两组数据之间是否显著不同,某组数据的变化是否可以预测。
对于问卷来说,常用的分析方法有:对类别数据进行卡方检验,寻找类别之间的关系;对连续数据进行相关分析,寻找变量之间的关系,以及通过回归分析进行解释和预测;对不同组别的连续变量进行显著性检验,判断几组之间是否有显著差别;根据样本数据进行聚类,探索不同的用户画像。
本文将介绍这些常用的数据分析方法,包括交叉分析、t 检验、方差分析、相关性分析、线性回归分析、聚类分析。文档主要结合了邱皓政所著《量化研究与统计分析》和Dawn Griffiths的《深入浅出统计学》两本书的内容,理解本篇文档后,你将掌握这些分析方法的原理和使用条件。进行这些分析都需要使用专业统计软件,例如SPSS,JASP,本文不做具体指导,在《量化研究与统计分析》每章的范例里可以找到步骤参考。
在介绍数据分析方法之前,本文还会介绍数据的类型,描述统计的两个重要概念,以及概率分布和统计的基本概念。这些内容是理解分析方法原理的基础,有助于你真正掌握这些数据分析方法。
文档的撰写者在过去只学过简单的统计学知识,在阐述时可能存在不严谨之处,如有疑问欢迎讨论(r.kong@foxmail.com)。
对所有数据分析方法的总览可以跳转至章节【统计分析方法概览(简短实用版本)】。
数据的类型
数据作为分析对象,可以被称作“变量(variable)”。变量表示某个属性因为时间、地点、人物等等因素的不同而发生变化的内容。“变量”包含两个概念:它所指涉的属性(attribute)是什么;它的数值(value/quantities)是多少。例如“用户满意度”这个变量,所指涉的属性就是用户对某对象的满意程度,值可以是1、2、5等等。这个数值是通过测量过程以特定的量尺测量得到的。
以测量的量尺(scale)来区分,数据可以分为类别、顺序、等距和比率这四种。
- 类别(Nominal/Categorical)或名词、定类:表示某类别特质,没有任何强度、顺序、大小等数学上的意义。例如性别(男、女),婚姻状态(未婚、已婚、离婚、丧偶等)。
- 顺序(Ordinal)或有序、定序:表示存在特定大小顺序关系的类别。例如教育程度(硕士及以上、大学、高中、初中、小学及以下)。
- 等距(Interval)或间隔、定距:表示有间隔的数据。其数值不仅有分类、顺序的意义,数值大小也反映了两个观察对象的差距或相对距离。例如温度计量出的“温度”,考试决定的“学业成绩”,智力测验得到的“智商”等。它的重要特性是,其单位只有相对零点,没有绝对零点。也就是当测量值为0时,并无绝对意义,例如气温为0时,不代表没有温度,而是指就测量工具而言得到0个单位的意思。
比率(Ratio)或比例、定比:当测量尺度使用了某个标准化单位,同时又有一个绝对零点,称为比率数据。数据之间有比例关系,具有真正的零点。例如身高(厘米),年龄(岁),受教育年数(年)。
这四种数据具备的数学特性比较如下表:
| 测量层次 | 数学关系 | |||
|---|---|---|---|---|
| = 或 ≠ | >或< | +或- | ×或÷ | |
| 类别 | √ | |||
| 顺序 | √ | √ | ||
| 等距 | √ | √ | √ | |
| 比率 | √ | √ | √ | √ |
另一种划分方式是看数据是否连续:
- 离散(Discrete):指测量对象的变化是“分开来的”,例如某座城市的人口数量,一个家庭的子女数量,性别,国籍等。
连续(Continuous):指测量对象的特征可以由无限精密的数值来反映,例如身高、体重、气温等,如果技术允许,可以无限精密。
介绍了这两种分类方式,也许你已经在脑海中匹配问卷里经常用到的题型和它的数据类型了。最简单、常用的测量格式是类别性测量,多用于人口基本属性、事实性问题的测量,例如性别、通勤方式等。显然这一种测量是为了鉴别差异,确认调查对象归属的类别,对应类别数据或顺序数据。连续性测量则是对程度进行测量,用于测定某些概念、现象的强度大小,例如智商、焦虑感、自信等。一种得到广泛运用的是Likert-type(李克特格式)量表,由一组测量某一个相同特质或现象的题目组成。李克特量表对应的是等距数据。
统计分析的原理和技术
【统计分析方法概览(简短实用版本)】
表格对比
| 分析目的 | 数据类型 | 分析方法 | | | | —- | —- | —- | —- | —- | | | | 方法名称 | 统计量 | 限制条件 | | 找出几种变量之间的关联性(甚至进行预测) | 类别变量 | 卡方分析(卡方检验,交叉分析) | 令α=0.05,若χ2检验结果P值<0.05,达到显著水平,两个变量之间存在显著关联。 | 80%以上的单元格期望值要大于5 | | | 连续变量
(等距变量,比率变量) | 线性相关分析 | 皮式积差相关系数 Pearson’s r:
位于±1范围内。
r 的绝对值小于0.5,说明相关性不太强;大于0.7,相关性较强。
| \ | | | 连续变量
(等距变量,比率变量) | 线性回归分析 | 决定系数R^2:
位于0~1范围内,越接近1,表明拟合度越高。
R^2的大小可以用F检验来检验其显著性。
| 在相关分析之后的进一步分析,如果相关性不强,回归分析无意义 | | | | 多元线性回归分析 | 决定系数R^2:
位于0~1范围内,越接近1,表明拟合度越高。
R^2的大小可以用F检验来检验其显著性。 | 需要检验多重共线性 | | 检验不同组的变量平均数是否存在显著差异 | 连续变量
(等距变量,比率变量) | t 检验 | 令α=0.05,若 t 检验结果P值小于0.05,说明存在显著差异;P值大于0.05,说明无显著差异。 | 为了检验样本的变异数是否同质,也需进行Levene同质性检验,如果F检验达到显著水平,需要使用校正公式计算t值。 | | | 连续变量
(等距变量,比率变量) | 方差分析(ANOVA,方差检验,变异数分析,F检验) | 令α=0.05,若F检验结果P值小于0.05,说明总体存在显著差异。可以进行事后检验(post-hoc),找到具体存在差异的组别。 | 为了检验样本的变异数是否同质,也需进行Levene同质性检验。 | | 探索性地对数据进行分类 | 定量数据,或类别数据 | 聚类分析 | \ | \ | | 查看数据的整体分布 | 取决于使用的量数,具体参考中心趋势量数表格和变异量数表格 | 描述统计 | 平均数(均值,中位数,众数)
变异性(全距,四分差,方差,标准差) | \ |
举例阐述
卡方分析/交叉分析:类别变量,检验两个变量之间是否有关系(或者检验拟合度是否好,没有前者常用)。设定显著性水平α为0.05,若卡方检验结果的p值若大于0.05,说明未达显著水平,两个变量之间相互独立,没有显著关联。
需要有80%以上的单元格期望值要大于5,否则卡方检验的结果偏差非常明显。
例如检验学生的性别分布与居住情况(城市/乡镇)是否有关联,设定α为0.05,结果P值为0.10,说明两个变量之间没有关联。
t 检验:连续变量,检验样本平均数与总体或理论值的差异(单一样本t检验),或者不同样本的平均数差异(独立样本t检验)。比较单一样本或配对样本在两个变量的平均数,使用配对样本t检验。设定显著性水平α为0.05,若t检验结果的P值小于0.05,说明存在显著差异;P值大于0.05,说明无显著差异。为了检验样本的变异数是否同质,也需进行Levene同质性检验,如果F检验达到显著水平,需要使用校正公式计算t值。
例如检验甲、乙两个班级学生的期末成绩是否有显著差异,t检验结果P值为0.02,小于设定的显著性水平0.05,说明存在显著差异。
方差分析/ANOVA:连续变量,检验超过2个样本平均数之间的差异。使用F检验。根据实验设计、自变量个数等采用不同的ANOVA方法。显著性水平α为0.05,检验结果P值若小于0.05,说明总体存在显著差异,可以进行事后检验,找到具体存在差异的组别。和t检验一样,也需要进行同质性检验。
例如研究处于不同婚姻状态的成人的生活满意度,将婚姻状态分为四种情况A\B\C\D,每一种情况随机选取5位受访者,请他们在生活满意度问卷上作答,每个人最后的得分位于0至6之间。用单因素方差分析,Levene同质性检验不显著,表明样本的离散情形无明显差别,符合方差分析的前提假设。F检验结果P值小于0.01,说明人们的生活满意度确实会因婚姻状态的不同而有所差异。经过事后检验,发现具体是A类和D类显著低于B类和C类。
线性相关分析:连续变量,两个变量之间是否有关系。皮式积差相关系数 Pearson’s r,位于±1范围内。r 的绝对值小于0.5,可能相关性不太强。
例如计算身高数据与体重数据的积差r,值为0.8,说明有中度的相关性。
线性回归分析:连续变量,寻找能够解释和预测两个变量数值的回归方程,是在相关分析之后的进一步分析。决定系数R^2,表示回归模型的预测力、解释力。位于0~1范围内,越接近1,表明拟合度越高。R^2的大小可以用F检验来检验其显著性。
例如根据身高、体重的数据样本进行最小二乘回归分析求得y=kx+b的方程,R^2为0.8,说明预测力较好,身高与体重确实有这样的线性相关且方程能够解释、预测两者的变化。再进一步进行F检验,可以检测这个回归方程是否有统计意义。
多元线性回归分析:连续变量,寻找能够解释和预测多个解释变量和一个因变量的线性关系的回归方程。决定系数R^2,表示回归模型的预测力、解释力。位于0~1范围内,越接近1,表明拟合度越高。R^2的大小可以用F检验来检验其显著性。
例如根据企业客户经理对我方产品的总体满意度和七个分项指标的满意度评价,通过回归分析,了解什么分项指标对总体满意度有重要影响,它的改进更能提升总体满意度。将所有满意度的分项指标作为解释变量X1、X2到X7,将总体满意度作为因变量Y。输出结果R^2为0.8,说明方程的解释力较好。接着看它是否具有显著性,如果F检验结果P值显著,说明回归模型可以很好地解释数据,然后需要对回归系数进行t检验,来决定各个解释变量的解释力。如果解释变量的单位统一,可以直接比较解释变量的相关系数,如果测量尺度不统一,则需要看标准化回归系数β,从而比较各个解释变量的相关程度,也就是各个因素的重要程度。
聚类分析:通常针对定量数据,也可以对类别数据进行分类。用于对样本进行分类,通常分为3~6类。具有探索性质,常用于对用户进行分类制作用户画像。
信效度:通常针对定量数据、问卷中的量表数据。非量表数据的效度可从内容效度的角度用文字详细说明。信度表示测量的可靠程度、一致性;效度表示测量能够真正达到测量目的、了解待测对象真实情况的程度。信度分析结果常用克朗巴哈系数(Cronbach α系数)表示,高于0.7则可以接受。效度分析有多个角度。
实用工具
个人使用过的对新手友好的统计软件:JASP
某平台的数据分析在线帮助手册: https://spssau.com/front/spssau/helps/universalmethod/frequency.html
Dawn Griffiths《深入浅出统计学》:非常易读的统计学入门书籍,以故事的形式展开介绍
邱皓政《量化研究与统计分析》:比较经典的统计分析书籍,结合SPSS进行范例解读
描述统计
为了获得数据的全局印象,我们往往需要描述它的平均值和变化范围,分别对应“中心趋势量数(measures of central tendency)”和“变异量数(variance)”。中心趋势量数描述了一组数据的共同落点,变异量数描述了数据分布的广度。
进一步来看,仅仅看数值的大小并不能充分解读这个数据,我们还要了解数值的相对意义。标准分数和正态分布模型能帮助我们理解统计数据的概率变化规律。
均值
均值 (mean),也就是所有数字相加再除以数字个数。这样算出来的是算术平均数(arithmetic mean)。
均值是应用最广泛的统计量之一,于是统计师们专门给了它一个符号μ,读作“miu”。
在日常生活,我们可能会觉得均值就是平均数,但在统计学中,我们严格区分这两者,只称呼均值为均值。均值并不是唯一一种表示数据平均数的值。有时候我们要靠中位数、众数来表示数据的平均水平。这是因为一组数据有可能出现“异常值”,它会凭一己之力让数据偏斜,使我们对数据的认知产生差错(如果你只计算了均值的话)。
如果异常值特别高,它会使数据往右拉,这样均值就被抬高了,高于数据里大部分的值。
例如在一个健身俱乐部,有10个学员是20岁左右,有2个学员是80岁(他们精神奕奕)。根据均值,一个40岁的市民可能会欣然加入,然后发现自己完全受不了这里的训练强度。因为均值已经被2位80岁健身达人严重拉高了!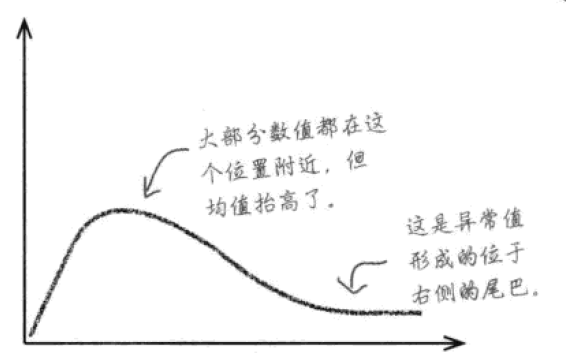
异常值特别低,会使得数据向左偏斜,均值小于大部分值。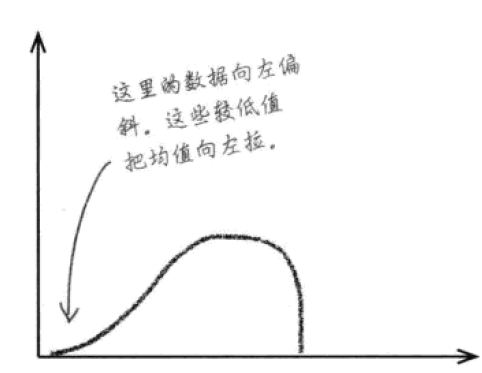
这是理想的数据分布,两边对称。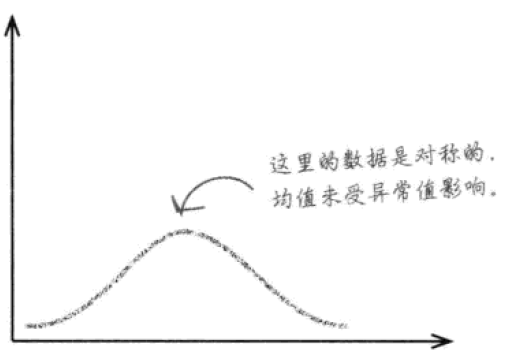
中位数
中位数 (median),永远处于中间。将所有数据从小到大或从大到小排列,最中间的那个数就是中位数(如果一共有偶数个数据,那就是中间两个数字的均值)。
当数据发生偏斜时,中位数能够恰当地体现典型值。此时均值会给出并不存在于数据集中区的数值。但这并不是说中位数比均值更好,在大多数情况下,我们还是需要使用均值,均值对于抽样数据来说更稳定。
众数
除了均值和中位数,还有第三种平均数,称为众数(mode),也就是出现次数最多的一个数字,数据中最典型的数值。
有时候数据的众数不止一个,有两个数值都具有最大频数的话,就说这种数据是双峰的。对于这种数据,均值和中位数都不能很好地反映数据情况。例如一家游泳馆,学员里有一批2岁小宝宝,还有一批32岁上班族,他们的人数都很多。众数在此时发挥作用。
众数不仅能用于数值型数据,还能用于类别数据。它是唯一能用于类别数据的平均数。
三种中心趋势量数的对比表格
| 测量层次 | 集中量数 | ||
|---|---|---|---|
| 众数 | 中位数 | 平均数 | |
| 类别 | √ | ||
| 顺序 | √ | √ | |
| 定距/定比 | √ | √ | √ |
| 优点 | 不受偏离值影响,可以反映数据的多个集中趋势 | 对数值变化不敏感,较不受极端值、异常值影响 | 测量最为精密,考虑到了每一个样本 |
| 缺点 | 测量粗糙,无法反映所有样本 | 无法反映数据的多个集中趋势,无法反映所有样本的状况 | 易受极端值、异常值影响,无法反映数据的多个集中趋势 |
平均数在寻找数据典型值方面很厉害,但平均数并不能说明一切。我们还需要知道,它可不可靠。这时候就需要分析各种“距”和“差”。
在描述统计中,中心趋势量数需要结合变异量数,才能反映一组数据的分布特征。
分散性:全距
全距 (range),也叫作极差,是数据中的最大数减去数据中的最小数。最小值称为下界,最大值称为上界。全距指出了数据的扩展范围。
全距仅仅描述了数据的宽度,并没有描述数据在上下界之间的分布形态。如果数据中包含异常值,那么全距就会极具误导性。我们需要摆脱异常值,但得用一个统一的方法——四分位数是个好主意。
分散性:四分位距和四分差
把数据按升序排列,然后分为四个相等的数据块。把数据分为4块的几个数值,就是“四分位数”。最小的四分位数Q1称为“下四分位数”或“第一四分位数”,最大的四分位数Q3称为“上四分位数”或“第三四分位数”。Q1和Q3之间的距被称为“四分位距 (IQR)”。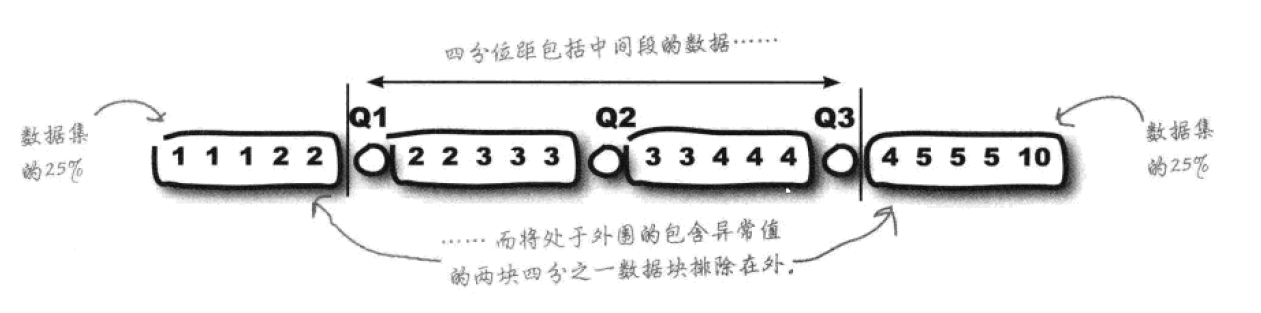
显然,四分位距比起全距,较少地受到异常值的影响。
四分差 (semi-interquartile range; QR),是四分位距的二分之一。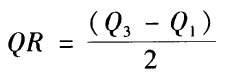
四分差越大,表明数值越分散。
全距和四分位距,都只是告诉我们分散程度,而不能告诉我们数据的稳定程度,也就是说数据以什么频率上下抖动。就像一个篮球运动员的得分,我们希望知道得到最高分或最低分的频率,以及球员们得到接近中心趋势的得分的频率。
变异性
度量数据的变异性,我们常用标准差(standard deviation)和方差(variance)。方差是标准差的平方,这两个量数都是利用离均差(deviation score)作为变异指标的计算基础的。
离均差是各个数据点与均值的距离,通常用小写的x表示。x = (X - μ)。一组数据的离均差的和总是0,于是可以取绝对值相加再除以观察值的个数,这就得到了平均差(mean diviation, MD)。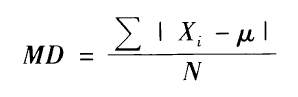
平均差虽然容易理解,但在统计学中,不常用取绝对值的方式来去除负数,而是采用平方的方式,这样对极端数据的侦测更为敏锐一些。这样就得到了离均差平方和(sum of sqaures, SS)。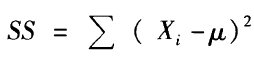
离均差平方和除以人数,就得到了方差,以 σ2或 MS (mean sqaure)表示: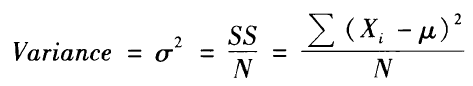
距离的平方总不如距离本身直观,为了更直观地考虑分散性,我们对方差进行简单地修正:取平方根,称为标准差,以 σ 表示。
标准差或方差越大,表明该分布的变异情形较大。
我们可以这样理解标准差:假定有一批数据的标准差为3cm,你可以简单地理解为,平均而言,这些数值与均值的距离是3cm。标准差不好说是越大越好还是越小越好,取决于具体情形。如果是生产机器零件,显然希望标准差小一些。如果是某家大公司的薪资情况,自然标准差会比较大。
在样本量小于30时,标准差可能有低估总体变异程度的情形,不是一个无偏估计数,于是会将算式的分母由N改为N-1。在统计学中,N-1称为自由度。自由度的概念在小样本时非常明显,样本量大于30时,自由度的影响几近于0。
变异量数的对比表格
| 测量层次 | 集中量数 | ||
|---|---|---|---|
| 全距 | 四分差 | 标准差/方差 | |
| 类别 | √ | ||
| 顺序 | √ | √ | |
| 定距/定比 | √ | √ | √ |
| 优点 | 不受极值外的个别分数影响,计算简便 | 对极端值不敏感,能表现顺序尺度的变异情形 | 测量最为精密,考虑到了每一个样本 |
| 缺点 | 测量粗糙,无法反映所有样本 | 无法反映所有样本的变异状况 | 易受极端值、异常值影响 |
标准分数
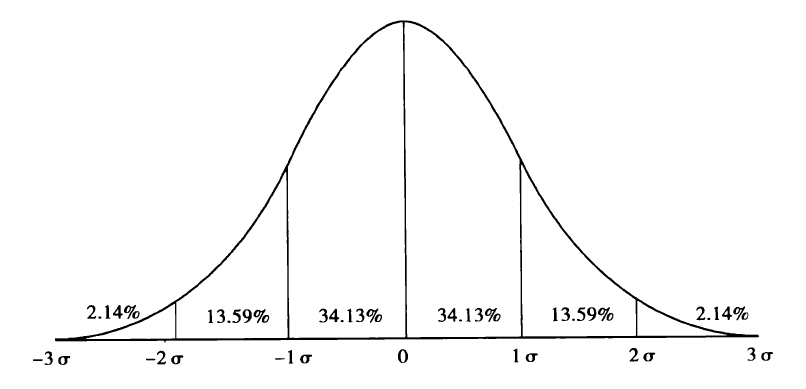
正态分布和标准分
“正态分布”是应用最为广泛的一种连续型概率分布,在了解统计抽样的概念之前,我们先来理解正态分布。
正态分布是大量连续数据分布的理想形态。也就是说,在现实生活中,你对某个数据(例如男生的身高)的收集结果“正常情况下”会呈现出这个样子: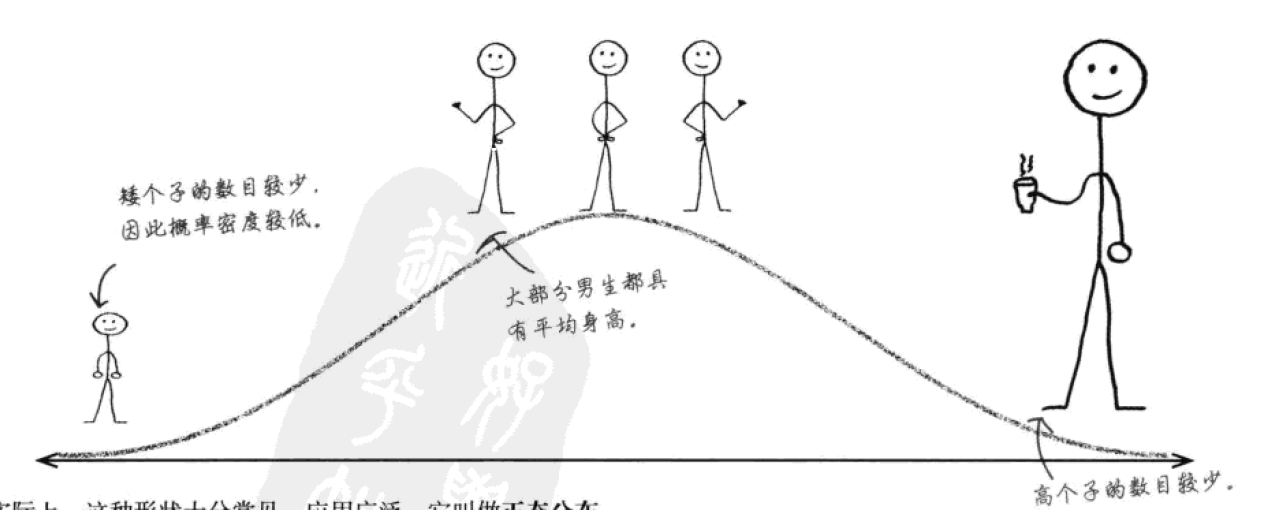
中间多,两头少,一个对称的钟形曲线。身高位于均值附近的概率高,身高远远偏离均值的概率低。
如果一个随机变量 X 满足正态分布,可以记作 X∼N(μ,σ^2)。其中μ表示平均值,σ表示标准差。μ指出了曲线的中央位置,σ指出分散性。σ^2越大,正态分布的曲线就越平、越宽。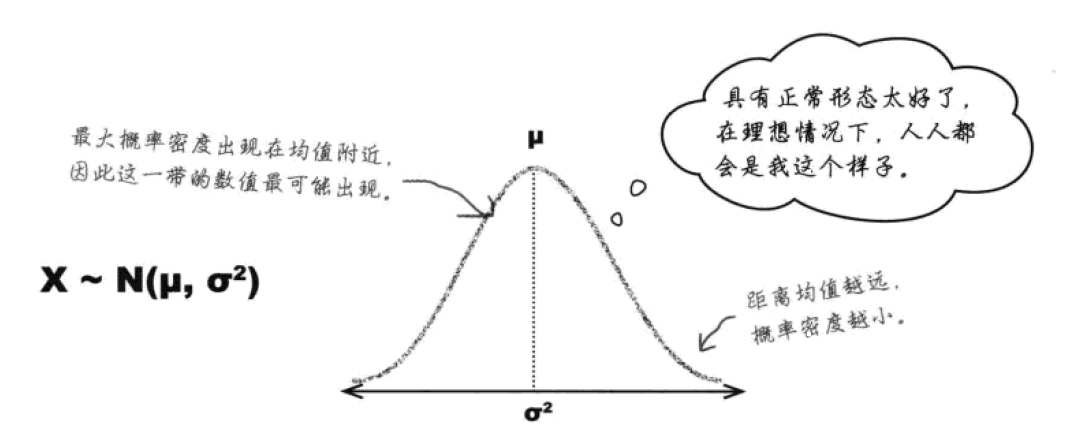

虽然在越来越远离μ的地方,概率密度曲线极度逼近0,但却永远到达不了0。这可以理解为,事件越来越不可能发生,但永远会有微小的可能性。
对于连续概率密度函数,如果要求某个事件的概率,就得求对应的曲线下方的面积。如果是“身高为180cm”的概率,数值会接近0——因为这个事件对应曲线上的一个点,一个点下方的面积是很小的,毕竟身高恰好为180.0000000……厘米的概率,确实很小。但是身高范围在179.5cm到180.5cm之间的概率,就挺可观了。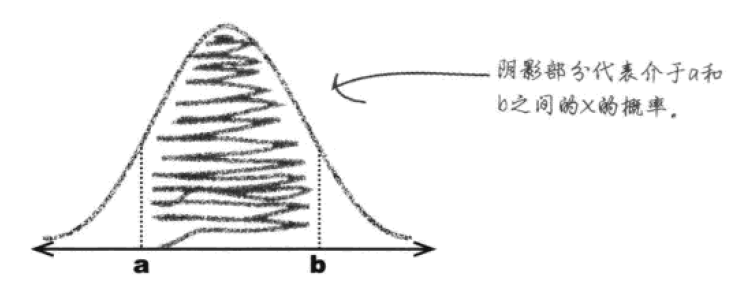
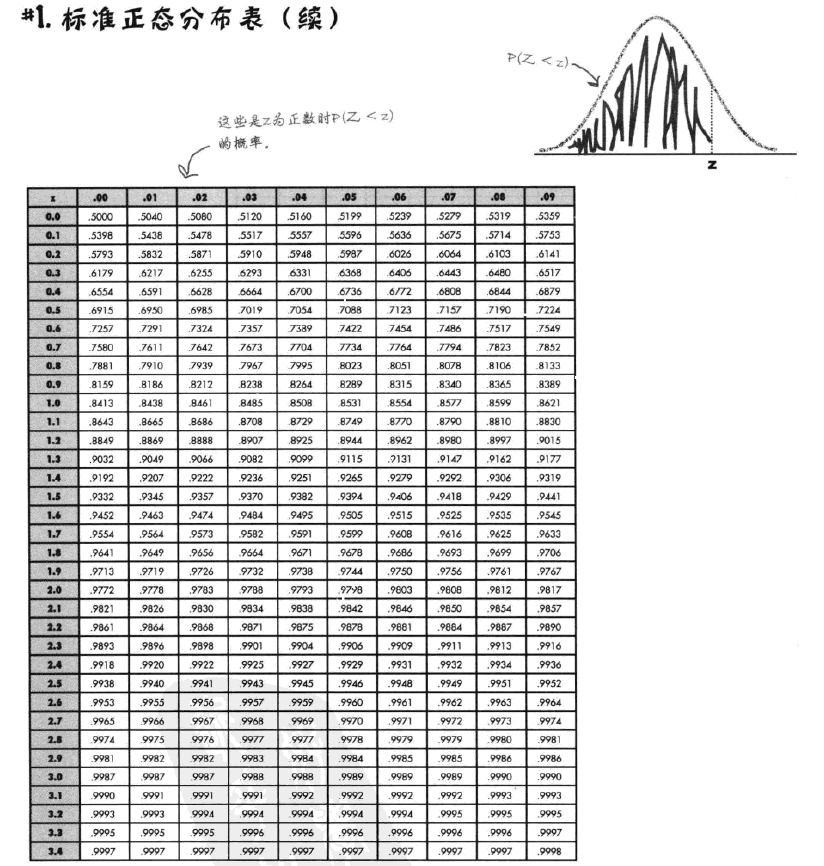
手工计算这条曲线下方的面积似乎有点难,在实际操作中,我们都是通过查表来获得结果的。
对于任意一个符合正态分布的随机变量,我们可以通过三步求得概率:
- 确定分布与范围;(求得平均值和标准差)
- 使其标准化;(把分布标准化为N(0,1),后面再介绍)
查找概率。(直接查表就能得到结果,大功告成)
第一步:确定分布与范围
例如,假设男性身高X满足N(71, 20.25)。(单位为英寸)
我们想要求得男性身高大于64英寸的概率,也就是求得曲线与横轴值64的直线之间的面积。
第二步:使其标准化
概率表只给出了N(0,1)分布的概率,因为不可能给每一条正态分布曲线制定概率表。
所以,我们要把概率分布标准化为符合N(0,1)的正态分布。
可以使用标准分完成这样的过程: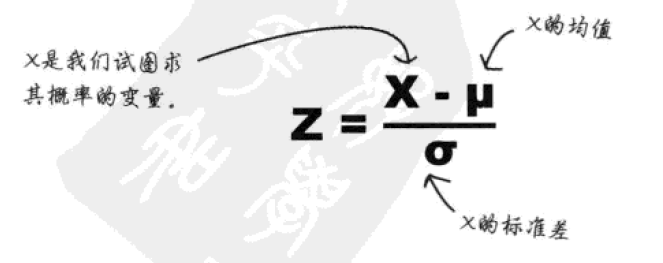
标准分非常有用,多亏了它,我们能够方便地比较各种各样的正态分布。
案例中均值为71,标准差为4.5,求得标准分Z=(X-71)/4.5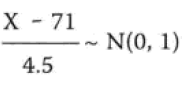

然后求得64的标准分:
然后查询概率表就可以得到结果。
我们分析问卷数据并不涉及到具体计算概率,只需要理解正态分布的求解过程,因此不需要仔细研究下表: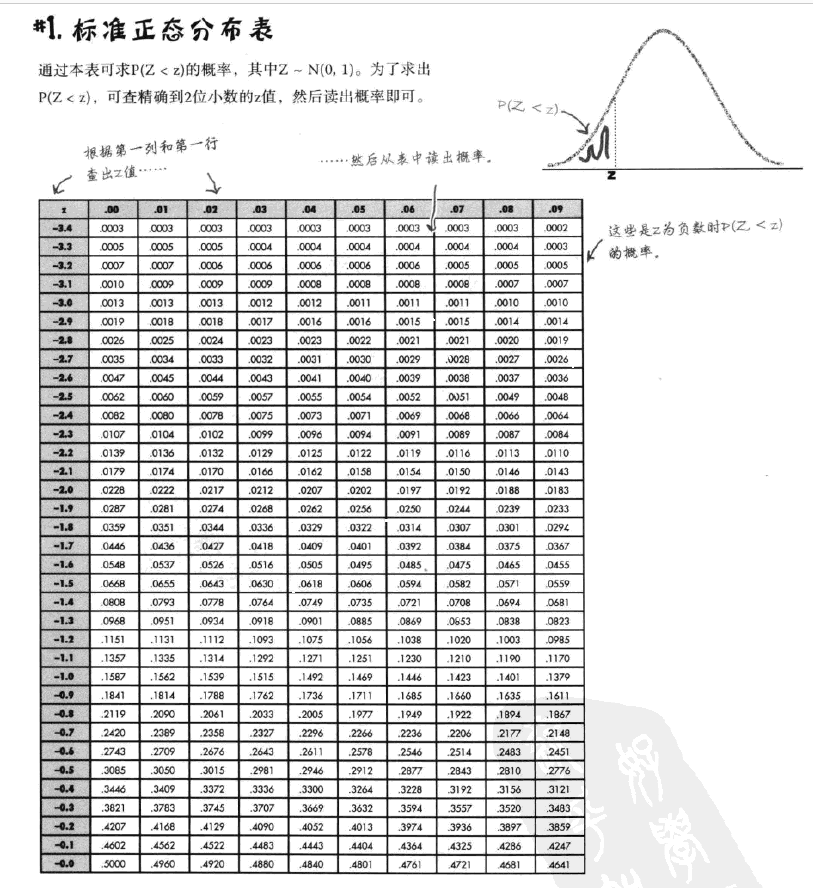
总体和样本的估计
我们想要了解的群体可能数量非常庞大,不可能收集到全部的数据。所以我们通常会选择群体中的一部分进行调查——这种选择方法也是很有讲究的。我们希望有效、正确、省时省钱地抽取样本。
设计样本时需要考虑的因素是:目标总体(正在研究的群体到底是什么样的?尽量精确),抽样单位(要抽取哪一类对象?是一颗螺丝,还是一整盒螺丝;是一个人,还是一对伴侣),抽样空间(列举总体范围内的所有抽样单位,这是进行抽样的空间。但对于数量庞大或无法溯源的总体,没法拟定抽样空间)。
建立一个好样本的关键是尽可能选择最符合整体特征的样本,这样通过从样本中获得的洞见能最好地预测出总体的情况。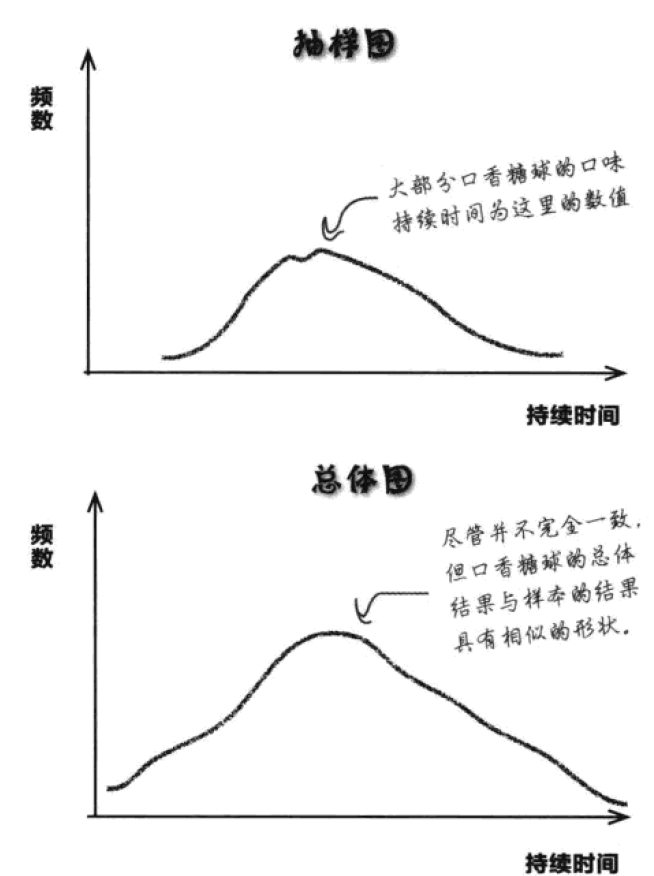
如果样本无偏,它可以代表总体,是总体的客观反映。如果抽样有误,得到了偏倚样本,那么从偏倚样本中得到的结果则可能误导我们对总体做出错误的推论。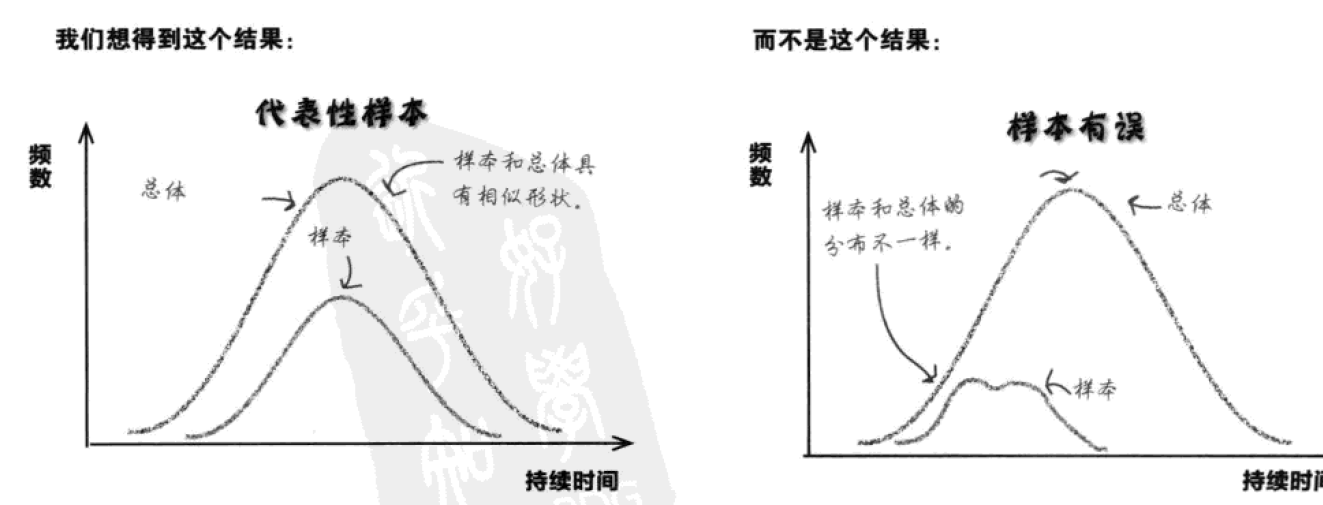
如何避免偏倚的出现?偏倚来源广泛,我们只能尽最大努力,让偏倚发生的机率尽可能降低。
这是一部分发生偏倚的原因:
- 抽样空间条目不齐全(总体中的一部分被排除在抽样空间外了。不过也并不是总能拟定抽样空间)
- 抽样单位不正确(例如应当抽取一个个家庭,却抽取了一个个单独的人)
- 为样本选取的一个个抽样单位未出现在实际样本中(不是所有被选为抽样对象的人都会填写问卷)
- 调查问卷的问题设计不当(问题具有引导性,就会导致偏倚)
样本缺乏随机性(例如在大街上发放问卷时回避行色匆匆或气势汹汹的人,他们就被排除在调查范围外了)
一个常用的样本选取方法是简单随机抽样。通过随机过程从总体N中选取n个样本,每个样本被选取的概率相同。对于大型抽样空间,可以用随机编号生成器来选取样本。
但简单随机抽样也可能有问题,可能选出的结果恰好全是总体中的一个小类别,例如抽样对象恰好全都是某某行业的人。
一个替代方案是分层抽样。把总体分为几个组,每个组内有相似的特性。例如按照学历分,按照行业分,按照年龄段分。然后对每个组分别进行简单随机抽样。为此还需了解每个组在总体中的比例,然后按照比例从层中选取样本。
如果整体中包含大量相似的群,可使用整群抽样。群与群之间性质非常相似,例如口香糖质量抽检,可选取一盒一盒而不是一颗一颗。
如果可以列出总体名单,也可以使用系统抽样,对于列表中的每k个单位进行一次调查。如果名单呈现循环重复分布的话会产生偏倚。
使用这些抽样方法无法保证不发生偏倚,但认真思考目标总体的特征、认真思考如何使样本代表总体,能够降低发生偏倚的概率。
随机选择样本,无法保证样本一定代表总体。因为“选出无法有效代表总体的样本”也纯属随机现象。还有可能,你以为自己在随机选取,实际上并不是,例如最积极参加顾客满意度调查的可能是特别满意或特别不满意的人,而总体中大部分人可能是感受不强烈、不会参加调查的人。
增大样本,可以一定程度上减小发生偏倚的概率,但同时也增加了调查成本。
接下来我们来探讨,如何通过样本了解总体。
得到样本数据后,我们可以得到样本均值,它是我们为总体做出的估计,也被称为总体均值的点估计量。我们期望样本分布与总体分布相似,这样样本均值就和总体均值大致相同。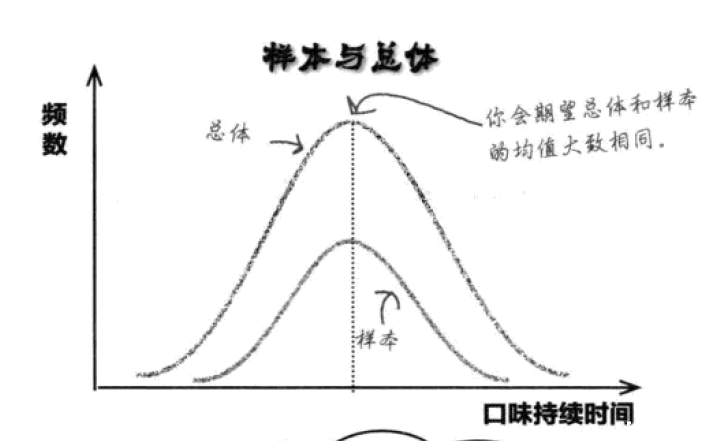
在无法得知总体参数的情形下,我们使用点估计量对总体参数做出最接近的猜测。例如对于均值这个参数,总体均值的点估计量就是对总体均值的最好猜测。可被记作μ上加一顶帽子,如下图右侧: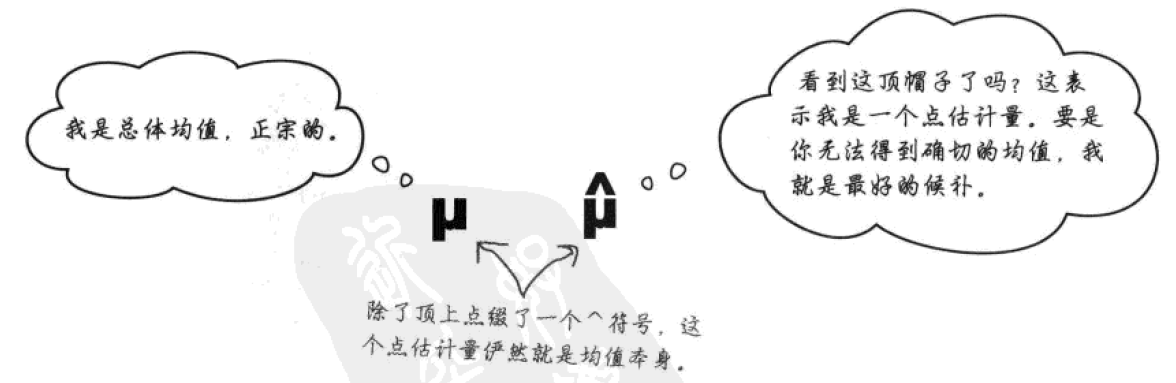
样本均值被记作X上加一顶帽子,数值上和点估计量相等。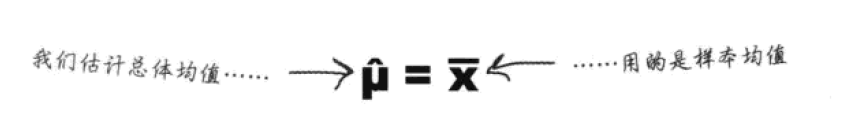

对于收集到的样本,得到的样本均值就是对总体均值的点估计量,是对总体均值μ的最佳猜测,但我们永远不知道真正的μ是什么。如果样本无偏,我们的猜测就能十分接近真值;如果样本有偏,那么我们的估计就很可能有误。
置信区间
总体均值的点估计量仅仅是一个估计值,我们没法说这个值到底可不可靠、有多大把握说真值就和这个估计值一样。于是,我们引入“置信区间”的概念,通过“不确定性”让我们的结论更加可靠。
点估计量可能是接近真值的,但是多接近才算是“够接近”?很自然地,我们可以用一个估计的区间,来替代单个精确的数值。例如一盒螺丝的重量,很难说“样本质量是300g,那么总体也就是300g”,但是我们会说“样本质量是300g,总体质量是300g±2g”。这个上下浮动的区间,就给了我们这个平均值到底有多接近真值一个范围。
回到那张正态分布函数图,我们不再只关注最高点、平均值所在的那条线,我们会在它的左右各取一个值a, b,确定一个范围。而这个范围与正态分布的概率分布函数就共同构成了真值落在区间内的概率。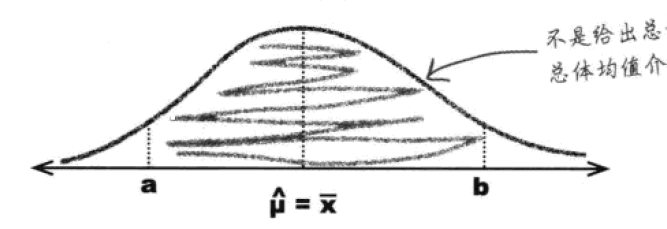
例如,如果你希望通过选择a和b,让该区间中包含总体均值的几率达到95%,那么也就是要求得到一个区间 (a,b) 使得 P(a<μ
具体求解置信区间的过程不予展示,毕竟我们不是需要考试的数理统计课程。
问题来了,置信水平取多少好呢?答案取决你需要对“区间中包含总体统计量”这一说法有多大信心。最常用的置信水平是95%,有时候你可能另有要求,取90%或99%。置信水平越高,区间越宽,置信区间包含总体统计量的几率越大。
那么置信水平往高了取不就好了?但是,一个超级高的置信水平,对应的置信区间可能会失去意义。举个夸张的例子,工厂里任意一盒螺丝的质量99.9%会落在1g至1000g之间,但是这个范围显然没有意义。所以,我们要有一个足够窄的置信区间,也要有足够高的置信水平。科研界通常会设置95%的置信水平,这样得出的置信区间范围是比较合理的。
假如我们已经求得平均值μ的95%置信区间为(61.72, 63.68),这意味着:如果你打算抽取大小相同的多个样本,然后为所有样本构建置信区间,那么这些置信区间中有95%包含着总体均值的真实值。由此可知,用这种方法构建的置信区间在95%的情况下都将包含总体均值。
另外,如果总体符合正态分布、但样本数量小于30,那么置信区间的构建应当根据 t 分布而不是正态分布。求解原理和过程则同上。
在确定问卷样本数量时,我们通过同时设定置信水平和置信区间,来计算所需的样本量。业界习惯是95%的置信水平和±3%的置信区间(或者说误差界限为3%)。
假设我们有一份问卷,希望收集用户对于产品的满意度评分(1~5分)。用户总体可能有N=1000人,我们要收集多少份回答,得到的平均分才能可靠地代表总体的满意度呢?根据样本量计算器,我们往往需要填写这些数据:总体数量,置信水平,误差界限(置信区间)。总体数量是我们对于用户总体的估计,可以写1000;置信水平可以选择最常用的95%(当然你也可以写最保守的99%);误差界限可以选择常用的3,或者再宽一些到5也是可以的,再宽可能就太不靠谱了。假设我们分别填写了1000、95%、3、50%,得到样本数量为516。最终516份问卷结果的平均分为3.5,这就意味着:用我们这种方法构建的置信区间(3.5转化为标准分后的左右3%)有95%的概率是包含总体均值的真正值的。
或者,我们已经收集了n=300份数据,样本平均分为3.5分,想看看置信区间是多少,同样可以计算出来。其中Percentage可以选择差异度最大的50%(因为我们并不知道总体的分布,选择最大的差异度意味着结果更可靠),得到置信区间为±4.74%,意味着总体的均值有95%的概率落在这个置信区间内(总体的满意度平均分落在3.5的标准分的±4.74%区间内)。
假设检验
我们对于问卷结果(或者说统计结果)可能有一些预期,一些断言。事实是不是如此?假设检验提供了一种检验方法,利用样本检验各种统计断言是不是可能属实。
假设检验有6个步骤:
- 确定要进行检验的假设(即我们要对其进行试验的断言)
- 选择检验统计量(我们需要选择能最有效地对断言进行检验的统计量)
- 确定用于做决策的拒绝域(我们需要使用某种确定性水平)
- 求出检验统计量的p值(我们需要了解在假定断言为真的情况下,我们的试验结果的可信程度)
- 查看样本结果是否位于拒绝域内(接着需要了解试验结果是否位于确定性限值范围中)
作出决策
我们想要检验的断言被称为原假设,以H0表示。如果没有足够的证据拒绝H0,我们就接受H0。
与原假设对立的断言被称为备择假设,用H1表示。如果有足够的证据拒绝H0,我们就接受H1。
假设检验无法给出绝对的证明,我们只能在假定原假设为真的前提下,通过假设检验了解观察结果到底有多可靠。如果观察结果极不可能发生,就会成为证明原假设为假的证据。
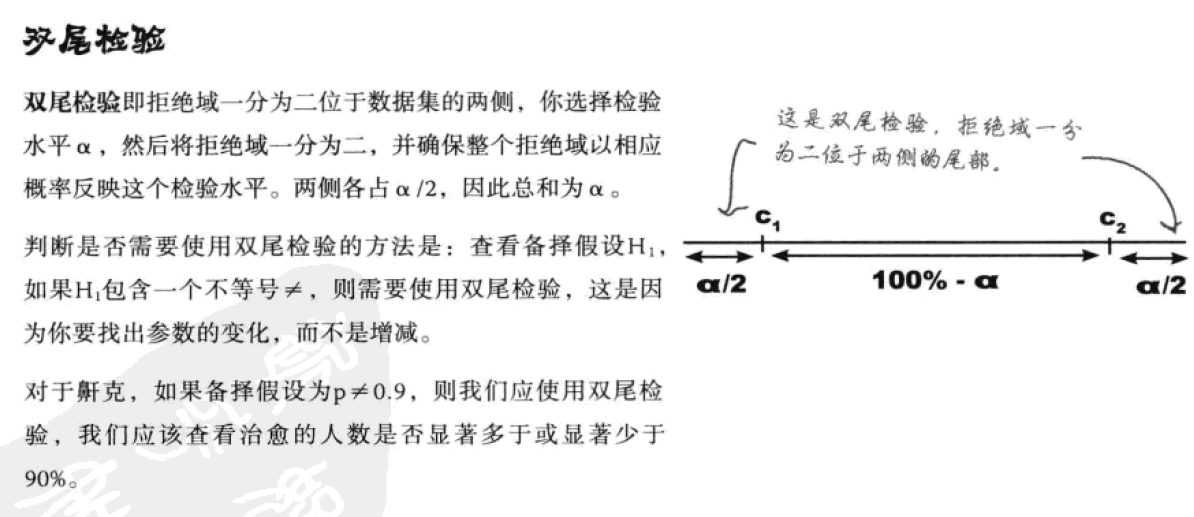
当证据的强度多大时,我们能坚决地拒绝原假设?指定一个拒绝域,就可以确定何时可以合理拒绝原假设。试验数值在拒绝域以内,我们就说有足够的证据可以反驳原假设。拒绝域的分界点被称为“c”——临界值。
而为了求得假设检验的拒绝域,首先要定下“显著性水平”。检验的显著性水平所量度的是一种愿望,即:希望在样本结果的不可能程度达到多大时,就拒绝原假设H0。和置信区间的置信水平一样,显著性水平以百分数表示。如果以5%为显著性水平检验某断言,这就说明我们选取的拒绝域应使得“断言中的对象数值小于c”的概率小于0.05。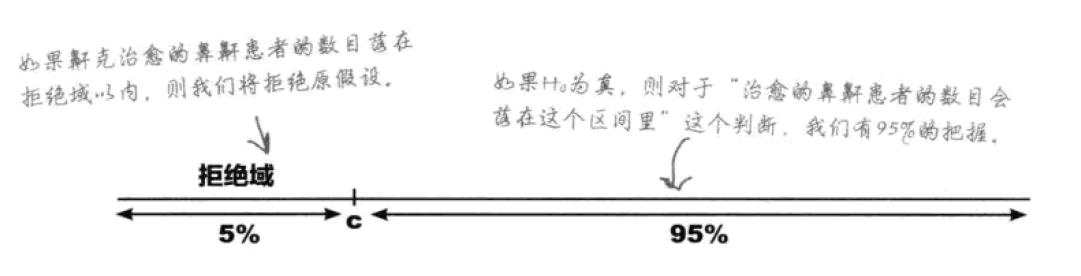
显著性水平通常用α表示。α越小,为了拒绝H0,样本结果需要达到的不可能程度越高。最常用的显著性水平为5%,不过有时也会用到1%。顺便一提,假设检验又被称作“显著性检验”,就是因为我们是按照某种显著性水平进行检验的。
构建拒绝域时,还需要明白所构建的是单尾检验还是双尾检验。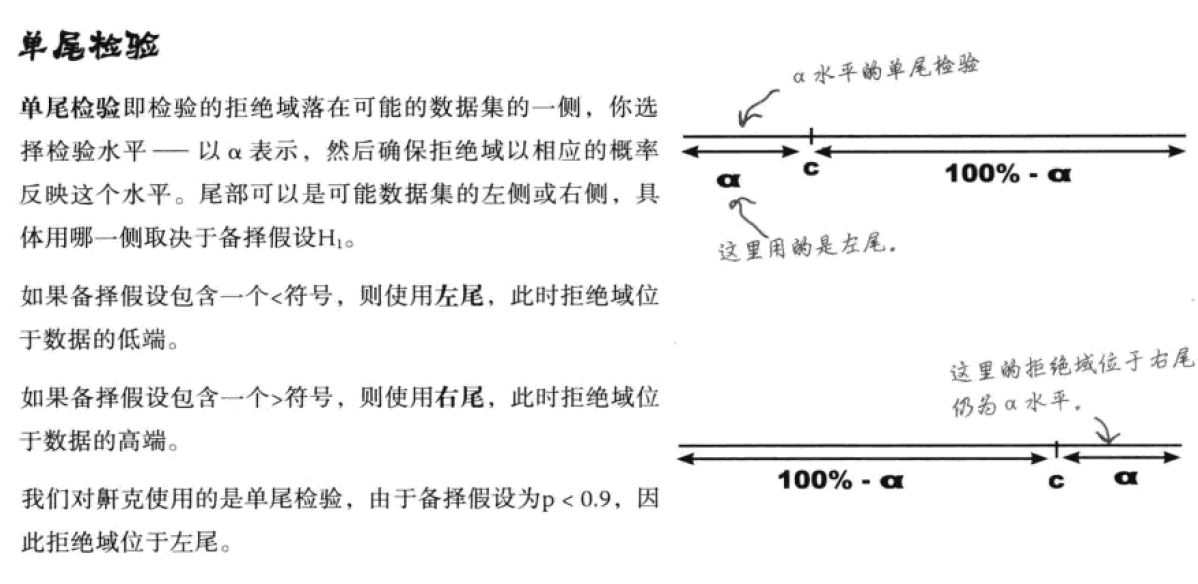
P值是某个小于或者等于拒绝域方向上的一个样本数值的概率。利用样本进行计算,然后判定样本结果是否落在假设检验的拒绝域以内。也就是说,我们通过P值确定是否拒绝原假设。
具体使用哪种方法求P值,则取决于拒绝域和检验统计量。之后我们会介绍卡方检验,t检验,方差检验。
如果P值位于拒绝域中,则有充足理由拒绝原假设;P值位于拒绝域外,则没有充足的证据。
注意,一旦确定了检验的显著性水平,就无法改变。检验必须公正,如果想先看证据是否充分,再确定检验水平,这就会影响判定,你会忍不住按照想要的结果选一个特定的检验级别,这就会令检验结果发生偏倚,于是可能做出错误决策。
当样本数量很大时,我们会选择用正态分布来近似二项分布。经过标准化,我们以Z作为检验统计量。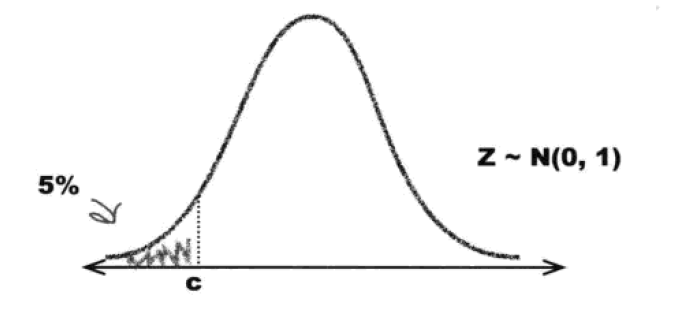
我们依照流程,利用样本结果完成了假设检验,要么拒绝了原假设,要么接受了原假设。
悲伤的是,即便我们找到了足够的证据证明断言是错误的,我们也没法保证断言是错误的。
这就像是法官审查囚犯,除非有充足的不利证据,否则法官会假定囚犯无罪。但是,即使考虑了证据,法官仍有可能误判。
统计学家给我们可能会犯的错误给了专用名称。
第一类错误:错误地拒绝真的原假设;
第二类错误:错误地接受假的原假设。
假设检验的功效即为你正确地拒绝一个假的原假设的概率。
类别数据的分析:卡方检验/交叉分析
类别尺度、顺序尺度的数据,都算是类别数据,而有时等距尺度或比率尺度所测量得到的数据,也可以通过分组处理简化为类别变量,例如将身高分为高、中、低三组。类别变量很普遍,例如性别、国籍、所在地域等。对于类别数据,我们可以用次数分布表(frequency table)和列联表(contingency table / cross tabulation)来整理、呈现数据内容,然后进一步用卡方检验(chi-square test)来进行统计检验。
类别数据的呈现
次数分布表是直接展示不同类别的名称和对应的出现次数。
列联表(又称为交叉表)是同时将两个类别变量的数据在一张表格里呈现,如下图:
列变量多以X表示,行变量多以Y表示。
一般,当行列变量没有特定因果或影响关系,则称为对称关系;当X与Y为非对称关系时,也就是某一个变量为自变量,另一个变量为因变量时,将自变量以X表示,因变量以Y表示。
列联表两侧填写总和的部分(上表的右侧及下方)称为边缘分布(marginal distribution),反映两个变量的次数分布情况,也就是两个独立的次数分布表。
类别数据的检验
卡方检验是以单元格中的次数来进行比较,以检验两个变量整体的关联性,俗称交叉分析。
这里使用到一个检验统计量χ2,描述观察频数和期望频数之间的差异。观察值与期望值的差异越大,χ2值越大,表示单元格的次数变化很特别,若超过显著水平的临界值,则接受两个变量具有特殊关系的假设。
χ2大到什么数值才算是显著?为了回答这个问题,我们需要理解卡方分布。
卡方概率分布(Χ2分布)通过一个检验统计量χ2来检查期望结果和实际结果之间何时存在显著差别。这种分布主要有两个用途。第一是用于检验拟合优度(goodness-of-fit test),也就是一组给定数据和指定分布的吻合程度;第二是用于检验两个变量的独立性(test of independence),检查两个变量之间是否存在某种关联。
卡方分布用到一个参数ν,读作niu。
当ν等于1或2: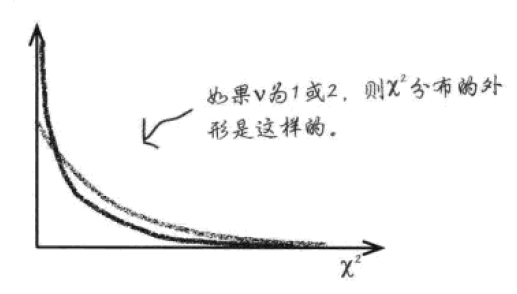
卡方分布的概率曲线先高后低。检验统计量χ2等于较小数值的概率远远高于等于较大数值的概率,也就是说,观察频数可能接近期望频数。
当ν大于2: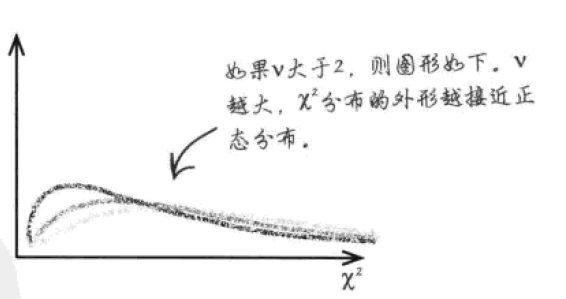
随着χ2递增,图形先低,后高,再低。当ν很大时,图形接近正态分布。
如果你正在使用具有特定参数ν的Χ2分布以及检验统计量χ2,可简单记为:
这里ν为自由度数目,即独立变量的数目。一般来说,ν=组数-限制数。
用卡方分布进行的检验为单尾检验,右尾被称为拒绝域。如果检验统计量落在了拒绝域以内,就可以判定根据期望分布得出的结果的可能性。
如果用显著性水平α进行检验,则可以写作: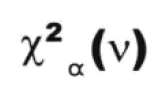
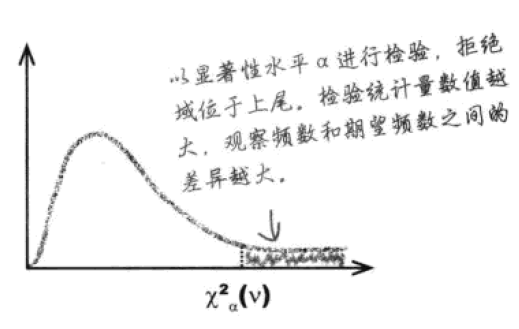
一般会设定显著性水平α为0.05。若卡方检验结果的p值若大于0.05,说明未达显著水平,两个变量之间相互独立,没有显著关联。
人工计算临界值则需要使用卡方概率表,不过我们通常会使用软件直接计算出结果。
运用卡方检验分析时,有一个特殊要求,即各单元格的期望次数(或理论次数)不能小于5。小于5时可能造成统计基本假设的违反,导致统计检验值高估。通常,需要有80%以上的单元格期望值要大于5,否则卡方检验的结果偏差非常明显。
SPSS分析范例:《量化研究与统计分析》P163 范例9.2
平均数的差异检验:t 检验
等距数据和比率数据,可以以连续变量的形式,进行较为精细的测量和检验。这种类型的数据,适合以描述统计的中心趋势量数和变异量数来描绘观察结果。这一部分先介绍平均数差异检验:t 检验,下一个部分介绍平均数的变异数分析/方差检验。
基本概念
研究时,由于总体庞大,我们多以抽样的方式,选取适当大小的样本进行测量,再借由统计推论的技术来进行总体真伪的假设检验工作。由于抽样后的样本平均数和标准差往往和总体有相当程度的差异,研究者无法得知抽样过程是不是具有偏差、是不是违反了正态分布的基本要求,所以必须通过一套以抽样分布为基础的推论统计理论,来进行统计检验与决策。
在平均数检验方法中,有Z检验和t检验,前者要求总体的标准差已知。一般来说,总体的标准差是没法知道的,所以使用Z检验的机会不多,大概只会在统计学课堂和作业中用到Z检验。并且,由于t分布随着自由度的改变而改变,当n大于30时,t分布与Z分布就十分接近了,使用t检验其实涵盖了Z检验的应用。在数据分析实践中,大多以 t 检验来进行单样本的平均数检验或平均数的差异检验。
对于单总体,不考虑其他变量的影响,只对这一个连续变量进行检验,那么进行的是单总体的平均数检验。比如总体身高的平均数。如果对总体进行分组,比如分为男生组和女生组,对两个组的身高的平均数进行比较,就牵涉到多个平均数的检验,这叫做多总体的平均数检验。
在平均数检验中,研究者的兴趣往往在于比较不同平均数的差距,而提出两个平均数大于、小于与不等于这几种形式的研究假设,形成有特定方向的检验或无方向性的检验这两种模式。如果研究者只关心单一一个方向的比较关系,例如女生的数学成绩X1是否优于男生X2,平均数的检验仅有一个拒绝域,使用单尾检验(one-tailed test)。如:
原假设H0:μ1>μ2
备择假设H1:μ1≤μ2
其中μ1表示女生的数学成绩,μ2表示男生的数学成绩。
如果研究者没有方向的设定,只对“是否相同”感兴趣,例如城市A的年均降雨量和城市B的年均降雨量是否相同,那就需要设定两个拒绝域,进行双尾检验(two-tailed test)。如:
原假设H0:μ1=μ2
备择假设H1:μ1≠μ2
如果没有支持单侧检验的证据,或变量间的关系具有明确的线索显示必须使用单侧检验,否则需要采用双侧检验来检验平均数的特性。
平均数差异检验的原理
《量化研究与统计分析》P170
正态分布 → t 分布
对于单总体:
检验一个连续变量的平均数,是否与某个理论值或总体平均数相符合。例如某大学一年级新生的平均年龄19.2岁是否与全国大一学生的平均年龄18.7岁相同。H0为μ=μ0。
总体标准差未知,使用样本标准差的无偏估计值来推估总体标准差,使用t分布来进行检验。t检验量公式如下: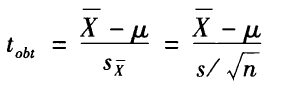
对于双总体:
检验两个总体的平均数差异是否存在。例如某大学一年级新生男生的平均年龄21.1岁,是否与女生的平均年龄19.7岁相同。H0为两个总体的平均数相同,μ1=μ2。(如果样本为相依样本,使用相依样本平均数检验。)
t检验量的公式如下: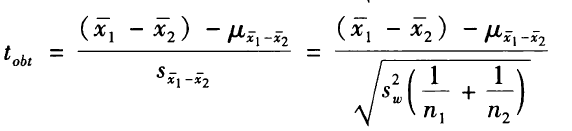
其余情况的公式略。
t检验是基于一些统计假设来进行的:
- 正态性假设(样本平均数的抽样分布符合正态分布)
变异数同质性假设(样本的离散程度具有同质性),可使用F检验来进行变异数分析
平均数的方差检验:ANOVA
如果类别变量的内容超过两种水平,统计检验的总体超过两个,此时需要能同时对两个以上的样本平均数差异进行检验的方法,称为变异数分析或方差分析(analysis of variance),简称ANOVA。方差检验也被称作F检验。
根据实验设计、自变量个数,以及变量之间的相关性,有不同的方差分析方法,可以参考以下表格。“独立样本”意味着样本之间没有关系,关联样本意味着相互关联的样本,例如同一份样本的处理前和处理后的状态。由于问卷设计通常不会涉及到复杂情形,不详细介绍每种分析方法。问卷可能会用到ONEWAY ANOVA、TWOWAY ANOVA等。
| 方差分析大类 | 研究设计形态 | 自变量个数 | 自变量关系 | 简称 |
|---|---|---|---|---|
| 单因素方差分析 | 独立样本设计(independent samples) | 1 | 独立 | ONEWAY |
| 关联样本设计(paired-samples) | 1 | 关联 | repeated measures ONEWAY | |
| 双因素方差分析 | 完全独立样本设计 | 2 | 独立 | 2-way ANOVA |
| 完全关联样本设计 | 2 | 关联 | repeated measures 2-way ANOVA | |
| 关联与独立样本混合设计 | 2 | 1个自变量独立 1个自变量关联 |
2-way ANOVA mixed design (split-plot ANOVA) |
|
| 多因素方差分析 | 完全独立或完全关联设计 | 3 | 都独立或都关联 | 3-way ANOVA |
| 关联与独立样本混合设计 | 3 | 多个自变量独立 1个自变量关联 |
3-WAY anova mixed design | |
| 共变量设计ANOCVA | 单因素共变量设计 (独立或关联样本) |
1个自变量 1个或多个共变量 |
ONEWAY ANOCVA | |
| 多因素共变量设计 (完全独立或混合设计) |
1个或多个共变量 多个自变量 |
FACTORIAL ANOCVA | ||
| 多重因变量设计MANOVA | 单因素多变量设计 (独立或关联样本) |
1 | ONEWAY MANOVA | |
| 多因素多变量 (完全独立或混合设计) |
多个 | FACTORIAL MANOVA | ||
| 单因素多变量共变设计 (独立或关联样本) |
1个自变量 1个或多个共变量 |
ONEWAY MANOVA with covariates | ||
| 多因素多变量共变设计 (完全独立或混合设计) |
多个自变量 1个或多个共变量 |
FACTORIAL MANOVA with covariates |
方差分析的目的是同时处理多个平均数的比较,主要原理是将全体样本在因变量上的数值的变异情形,分为受自变量影响的变异,和与误差有关的变异,对这两个部分分别进行计算。将总的离散量数拆解为自变量效果(组间效果)和误差效果(组内效果)两个部分。
公式推导略,检验时利用F分布来获得独立变量效果的统计显著性。
如果达到了显著水平,说明几组平均数之间有显著差异存在,但是我们不知道究竟是哪几个平均数之间显著有所不同,这就需要进行多重比较(multiple comparison)来检验。多重比较也有多种不同的方式,视不同统计条件而定,这里不详细介绍。
ANOVA也涉及到一些基本的统计假设:
- 正态性假设
- 可加性假设
变异数同质性假设
线性关系的分析:相关与回归
连续变量也是研究者经常接触到的数据,例如完成任务所花费的时间,抑郁量表分数等。单独的一个连续变量,可以用一般的次数分布表和图示法来表现数据的内容和特性,或以均值及标准差来描述数据的集中与离散情形。但研究所涉及到的问题,往往同时牵涉两个以上连续变量关系的探讨。两个连续变量的共同变化的情形,称为共变(covariance)。
在统计学上,涉及两个连续变量的关系多以线性关系的形式来进行分析。线性关系分析是将两个变量的关系以直线方程式的原理来估计关联强度。另一方面,回归分析是运用变量间的关系来进行解释与预测的统计技术。在线性关系假设成立的情况下,回归分析以直线方程式来进行统计决策与应用,又称为线性回归(linear regression)。一般来说,两个变量的关系先以相关系数去检验线性关联的强度,如果达到统计显著水平,表明线性关系有意义,便可进行回归来进行进一步的预测和解释。
借助于散点图(scatter plot),我们可以直观地看到两个变量之间的关系。如果散点图上的点几乎是呈直线分布,则相关性为线性。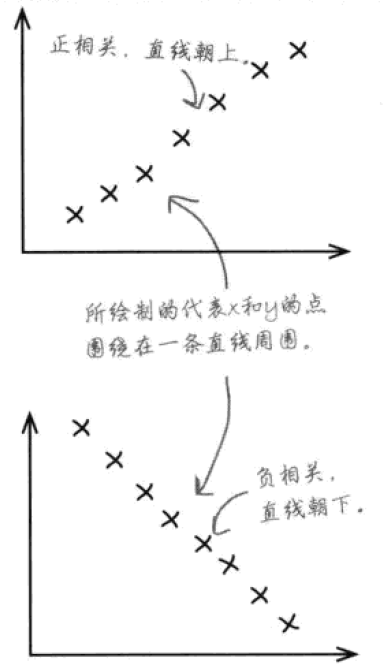
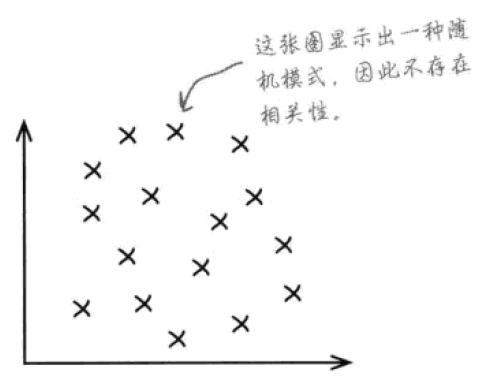
下图呈现了一种随机的、没有相关关系的模式。
积差
两个连续变量的线性关系,可以利用相关(correlation)的概念来描述。用以描述相关情形的量数,称为相关系数(coefficient of correlation)。令总体数据求得的相关系数以希腊字母ρ表示,以样本数据求得的相关系数以英文字母r表示。
数学推导过程略,可参考《量化研究与统计分析》P245。
Pearson提出了标准化关联系数,得到了去除单位的、标准化的共变数,被称为皮式积差相关系数(Pearson’s product moment correlation coefficient),简称Pearson’s r。
积差相关系数不受变量单位和集中性的影响,系数值介于±1之间。
系数数值不呈等距关系,因此只可以以顺序尺度的概念,来说明数值的相对大小。
相关系数的解释与应用,须经过显著性检验来决定系数的统计意义,一旦显著,便可解释系数的强度,给予实务意义。
在统计学上,统计意义与实务意义是两个截然不同的概念。有时,一个微弱的相关(.10),可能会因为样本数很大而达到统计的显著水平,有数学上的统计意义,然而实务意义低。一个很强的相关(.6),可能因为样本数太小而没有显著的统计意义,但实务意义很高。样本数大小是影响相关系数统计显著性的重要因素,提高样本数可以提高统计的意义,但不改变实务意义。影响实务意义大小的决定因素不是样本规模,而是变量间的实质关系。
例如,假如城市里唱片店的数量和咖啡店的数量呈现高度相关,但你很难说两者之间真的有什么关联,或者这种关联有什么意义。顺便一提,相关性也不等于因果性。假如唱片店数量增加的同时,咖啡店的数量减少,你也不能说是唱片店的增加导致了咖啡店的减少。
| 相关系数范围(绝对值) | 变量关联程度(统计意义) |
|---|---|
| 1.00 | 完全相关 |
| .70至.99 | 高度相关 |
| .40至.69 | 中度相关 |
| .10至.39 | 低度相关 |
| .10以下 | 微弱或无相关 |
回归分析
相关分析的目的在于描述两个连续变量的线性关系强度,而回归则是在此基础上,进一步探讨变量间的解释与预测关系的统计方法。
“回归”这个词起源于1855年英国学者Galton的论文,Galton分析了孩童身高与父母身高的关系,发现可以用父母的身高来预测子女的身高:当父母身高越高,子女的身高会比一般孩童高。有趣的是,当父母身高特别高或特别矮时,子女的身高不会像父母那么极端化,而是朝向平均数移动(regression toward mediocrity),这就是著名的“均值回归(regression toward the mean)”现象。自此以后,“回归”这个名词就被视为研究变量间因果或预测关系的重要同义词。
简单来说,你想在数据散点图上画一条直线,这条直线尽量接近每一个点。能最好地接近所有数据点的线,被称为最佳拟合线。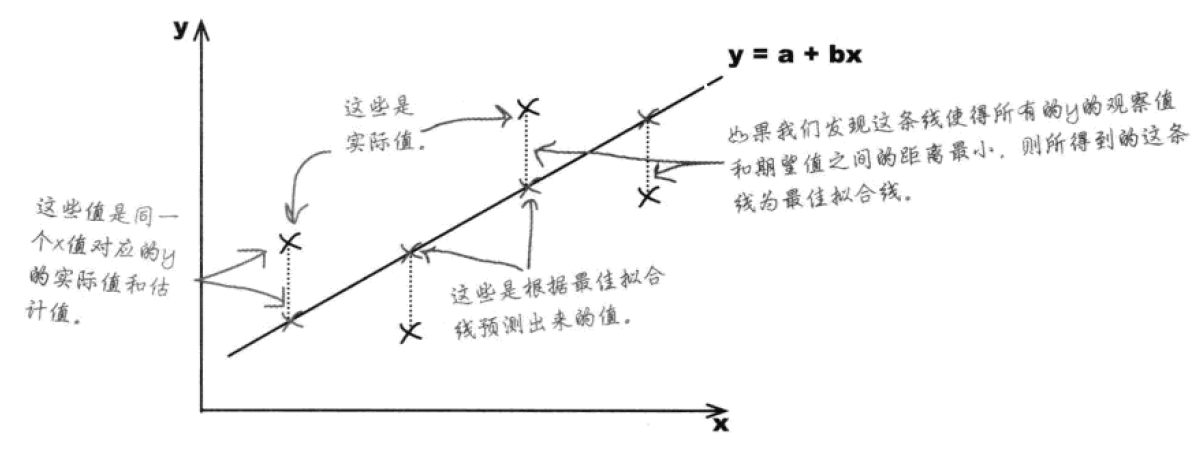
定义回归方程式为Y’=bX+a,对某一对观察值(X,Y),将X代入方程得到的数值,就是对Y变量的预测值,记为Y’,两者的差值Y-Y’为残差。和方差类似,这里会利用最小平方法求得最小化的残差平方和,从而得到最小平方回归线(least sqaure regression line)。这种分析被称为一般最小平方回归分析,简称OLS回归。
我们可以计算得到方程式的系数,以X去预测Y的回归系数byx和以Y去预测X的回归系数bxy。截距ayx则利用回归线会经过两个变量的平均配对点的原理得出。
对于一个有两个变量的回归方程式,有两个回归系数byx和bxy,但是只有一个相关系数r。三者间具有r^2=byx × bxy的关系。一般将r^2称为决定系数,因其决定了回归的预测力。
byx和bxy系数是带有单位的非标准化统计量,可以反映自变量对于因变量影响的数量,但由于存在单位的差异,无法进行相对比较。想要比较回归系数,就得对回归系数进行标准化处理。
标准化回归系数被称为Beta系数。这个系数也是将X和Y变量所有数值转换成Z分数后,所计算得到的斜率。β系数的数值类似相关系数,介于±1之间,绝对值越大,表示预测能力越强,正负方向代表X与Y变量的关系方向。在简单回归中,由于仅有一个独立变量,其值恰好等于相关系数。
对于真实的样本数据,数据点与得出的最佳回归预测线多少有一些差距,不会完全落在线上。根据方程式,代入一个值Xi,可以获得一个预测值Yi’,预测值Yi’和真实值Yi的差距就是回归无法解释的误差部分e。
由回归误差e,可以推导得到决定系数R^2(过程略,参见《量化研究与统计分析》P249),它反映了回归模型的解释力,反映了由独立变量与因变量所形成的的线性回归模式的适配度(拟合度,goodness of fit)。R^2的数值为80%,表示拟合的方程能够解释因变量80%的变化。
如果要对回归模型进行显著性检验,可以使用检验量F,配合F分布,即可进行回归模式的方差分析检验,用以检验回归模型是否具有统计的意义。
回归分析对于变量关系的探讨,是基于一些统计假设之下的。如果假设被违反,会导致偏误的发生。其中五个回归分析的重要假设如下:
- 固定独立变量假设
- 线性关系假设
- 正态性假设
- 误差独立性假设
误差等分散性假设
相关分析和回归分析的SPSS软件应用范例参见《量化研究与统计分析》P252
非线性关系的相关分析和回归分析略去。
多元回归
上一章节讨论的是用单一解释变量来预测因变量的情况,称为“简单回归”。在研究中,通常存在不止一个解释变量,就需要建立一套含有多个解释变量的多元回归模型,称为多元回归(multiple regression)。
基本概念
多元回归涉及到对多个解释变量的同时处理,所以计算过程比较复杂。尤其是解释变量之间的共变关系,这会影响回归系数的计算,需要小心处理。另一方面,多个解释变量对因变量的解释可能有次序上的先后关系,使得多元回归的运作更加复杂。
基于预测和解释两种目的,多元回归可以被分为“预测型回归”和“解释型回归”。预测型回归中,研究目的在于解决实际问题,预测或控制实际生活中的问题。解释型回归中,主要目的在于了解自变量对因变量的解释情形。两者在“分析策略”和“理论在其中所起的作用”上有所差异:分析策略的不同
预测型回归最常使用的变量选择方法是逐步回归法(stepwise regression)。逐步回归可以满足预测型回归的目的:以最少的变量来达成对因变量最大的预测力。
解释型回归的目的则在于厘清变量之间的关系,以及找出对因变量的变化具有最合理解释的回归模型。所以,在选择解释变量时非常慎重,也会慎重对待每一个解释变量和其他变量的关系。学术上通常使用的回归策略是同时回归法(simultaneous regression),即不分先后顺序,一律将解释变量纳入方程式同时分析。
- 理论所起的作用
预测型回归对于解释变量的选择,考虑的更多的是它是否有实际价值,而不是基于理论上的合适与否。理论可能会被用来说明回归模型在实际应用中的价值,以便在最低成本下获得最大的实际价值。
解释型回归则非常看重理论基础,理论不仅会决定解释变量的选择和安排,也会影响研究结果的解释。
不过,不论是哪种回归,如果解释变量具有理论上的层次关系,就必须以不同的阶段来处理不同的解释变量对因变量的解释。可以利用阶层回归分析(hierarchical regression)的区组选择程序(blockwise selection),按理论上的先后次序逐一检验解释变量对因变量的解释。
原理与特性
多元回归中,对因变量进行解释的变量不止一个,我们用“多元相关系数(multiple correlation)”来表示这一组解释变量与因变量之间的关系,或者用字母R表示。多元相关系数是因变量的回归预测值Y’与实际预测值Y的相关系数,多元相关系数的平方R^2表示Y被X解释的百分比。R = ρY’Y
在上一章讨论的简单回归中,因为解释变量只有一个,此时多元相关系数R恰好等于解释变量与因变量的积差相关系数r。
借助例子来解释如何进行多元回归分析。假设我们收集了100个企业客户经理对我方产品的总体满意度和七个分项指标的满意度评价,我们希望知道,什么分项指标对总体满意度有重要影响,它的改进更能提升总体满意度;如果建立预测模型,我们期望能从分项指标的评价预测总体满意度的数值。
将所有满意度的分项指标作为解释变量X1、X2到X7,将总体满意度作为因变量Y。打开SPSS选择回归分析,令X1到X7为自变量,令Y为因变量,选择相应的统计参数,输出结果。
首先关注R^2,它说明了方程的拟合好坏程度。接着看它是否具有显著性,如果F检验结果P值显著,说明回归模型可以很好地解释数据,然后需要对回归系数进行统计检验,来决定各个解释变量的解释力。检验原理与简单回归相同,用t 检验来检验回归系数的统计显著性。
如果解释变量的单位统一,可以直接比较解释变量的相关系数,如果测量尺度不统一,则需要看标准化回归系数β,从而比较各个解释变量的相关程度,也就是各个因素的重要程度。
R^2的数值高,说明拟合度较好,回归模型能够较好地解释数据关系。但是,也可能是存在多重共线性。
多重共线性问题
多重共线性(multilinearility)是多元回归模型产生误差的主要原因。
最单纯理想的情况是两个解释变量X1、X2相互独立,即图14.1 (b),r12为0,此时R^2就等于ry1与ry2两个相关系数的平方和,共线性为0。
在(c) (d)中,X1和X2之间具有相关性,r12≠0,计算R^2时就需要将r1y与r2y两个相关系数的平方和扣除重叠计算的区域。扣除重复面积的方法上如果有不同的处理,对于各变量的解释也会有所不同。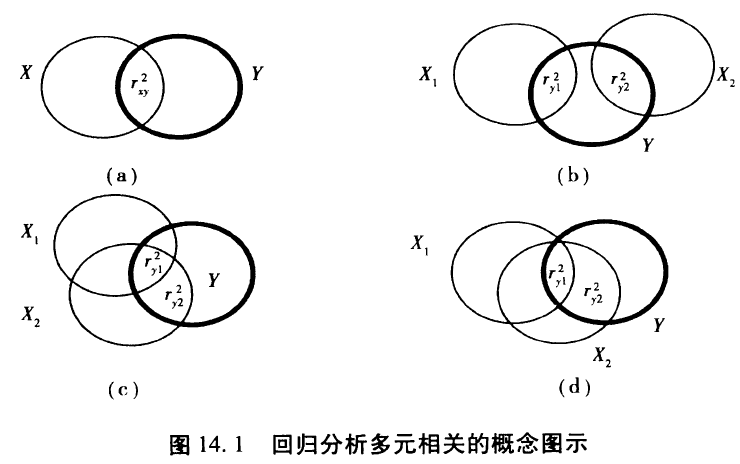
实践中,多重共线性是普遍存在的,轻微的多重共线性问题可以不采取措施。若问题严重,一般根据经验或分析回归结果发现,例如影响系数符号,重要的解释变量t值很低。如果模型仅用于实践预测,那么只要拟合程度好,也可以不处理多重共线性问题,往往不影响预测结果。
造成多重共线性的原因可能有:
- 解释变量有共同的时间趋势;
- 一个解释变量是另一个解释变量的滞后反应,二者遵循一个趋势;
- 数据收集的基础不够宽,部分解释变量会一起变动;
- 某些解释变量之间存在近似的线性关系等等。
一些判别方式:
- 发现系数估计值的符号不对;
- 部分重要的解释变量的t值很低,而R^2并不低;
- 当一个不太重要的解释变量被删除后,回归结果显著变化。
检验方式:
- VIF检验:一般统计软件会提供容忍值(tolerance)或方差膨胀因子(variance inflation factor, VIF)来评估共线性的影响。VIF越大,共线性越明显。容忍值越大越好。
- 条件系数检验:利用特征值(eigenvalue)和条件系数(conditional index, CI)来判断。特征值越小,表示解释变量之间具有共线性。CI值越高,表示共线性越严重。CI<30,表示共线性问题较缓和,CI值位于30~100之间,表明回归模型中具有中至高度共线性,100以上表示严重的共线性。
- 方差比率:当同一个线性整合的CI值中,有两个或以上的解释变量有高度方差比率时,显示它们之间具有共线性。当任意两个或多个回归系数方差在同一个CI值上的方差比率均大于50%、接近1时,表示可能存在共线性组合。
变量选择模式
在基本概念部分提到了不同的分析策略,此处结合范例进行具体解释。
从60位参与科学竞赛活动学生的信息中,希望能够对于心理与社会能力如何影响科学能力提出一套解释模型。(从《量化研究与统计分析》P262开始)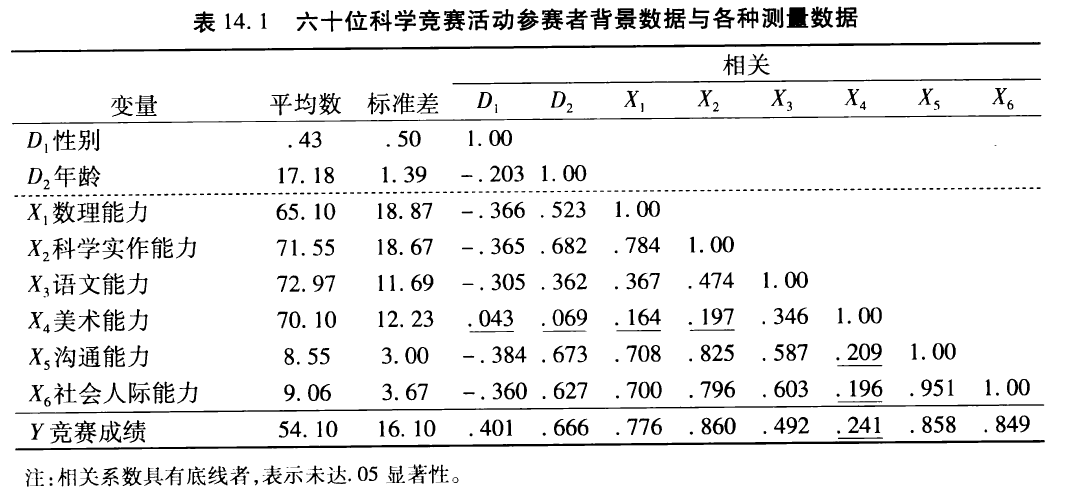
同时回归分析
最单纯的变量处理方法,将所有的解释变量同时纳入回归方程式当中,来对因变量进行影响力的估计。回归分析仅保留一个包括全体解释变量的回归模型。除非解释变量间的共线性过高,否则每一个解释变量都会一直保留在模型中,即便对于因变量的边际解释力没有达到统计水平,也不会被排除在模型之外。
以同时回归(simultaneous regression)技术进行的回归分析,又可被称为解释型回归,因为研究者的目的通常是厘清提出的解释变量能否用来解释因变量。
解释型回归的第一个工作是检视各变量的特性和相关情形。从表14.1可以看出,解释变量除了X4美术能力,都和因变量Y显著性相关。解释变量之间,也大多显著相关,这种高度重叠的多重共线性将会影响结果的解释。
第二个工作是计算回归模型的整体解释力和显著性检验。由表14.2可知,R^2高达0.841,解释力很高,表示这些能力指标和人口变量能够解释参赛者的表现。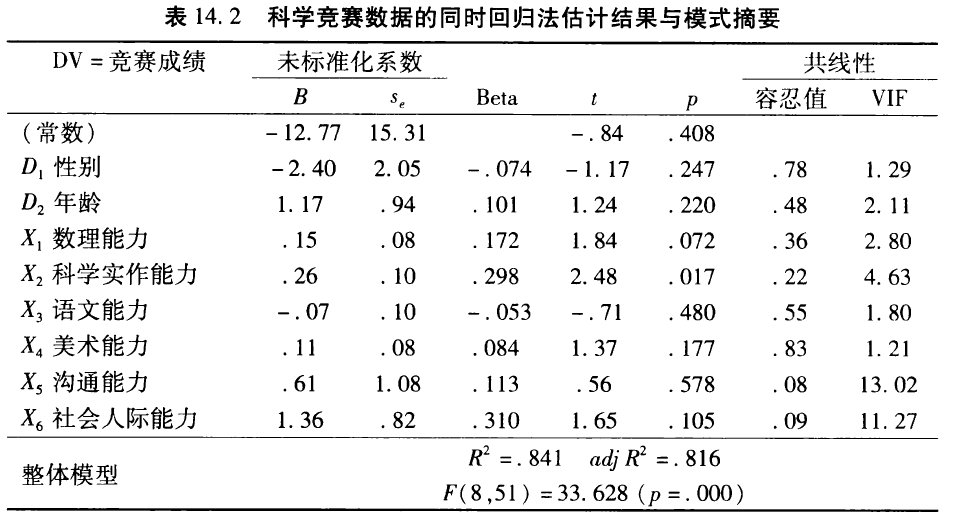
进一步检视各个变量的个别解释力,发现只有科学实作能力具有显著的解释力,Beta系数为.298,t(51)=2.48, p= .017。科学实作能力越强,参赛表现越理想,但相关强度仅有中度水平。其他各变量的解释力则未达显著。
逐步回归分析
多出现在以预测为目的的探索性研究中。一般做法是投入多个解释变量后,由各变量与因变量的相关系数的大小来决定每一个预测变量能否进入回归模式或淘汰出局,最后得到一个以最少解释变量解释做多因变量变异量的最佳回归模型。这种回归分析包括向前法、向后法、逐步法。
向前法即是先选入与因变量相关系数最高的解释变量,再选入与因变量有最大的偏相关者(能增加最多解释力R^2的预测变量)。直到模型外的变量的偏相关系数都无法达到.05的显著性,程序终止。
向后法是先将所有解释变量投入回归模型,再将最没有预测力的解释变量依次排除。
逐步法结合了两种策略,先依据向前法,再用向后法排除,直到没有变量可以被选入或排除。
阶层法
阶层回归分析也是“逐步”地纳入变量,不过是基于理论或研究需要来取舍变量。
解释变量之间可能具有特定的先后关系,需要依特定的顺序来进行分析。例如,涉及到性别、社会经济地位、自尊、焦虑感与努力程度这些解释变量,可以被分为几个区组,将性别、社会经济地位列入一个区组(人口变量,与其他相对独立),自尊感和焦虑感列入另一个区组(都是关于情绪感受的变量,可能相关)。先对第一个区组进行回归分析,再将第二个区组的变量投入回归模型,如此等等。这就是阶层分析法。
实际执行时,阶层回归分析最重要的工作是决定变量的阶层关系和进入模式,需要基于理论、现象上的合理性来考虑。
SPSS软件应用范例参见《量化研究与统计分析》P268
探索数据分类:聚类分析
聚类分析是一种探索性的数据分析方法,根据指标、变量的数据结构特征,对数据进行分类,使得类别内部的差异尽可能小,类别间的差异尽可能大。
通常认为,样本个数要大于聚类个数的平方。
如果需要聚类的数据量较少,少于100个,可以考虑使用层次聚类法、K-均值聚类法、两步聚类法。如果数据量较大,大于1000个,应考虑选择快速聚类法或两步聚类法。数据量在100到1000之间,计算条件可以满足任何聚类方法的要求,可结合实际情况选择。
如果是定量数据,按样本分类,可以使用K-means聚类法或K-prototype聚类法;按变量(标题)分类,可以使用分层聚类。如果有类别数据的参与,按照样本分可使用K-prototype聚类法。
软件输出结果中,F检验结果P值小于0.05的分析项就是不同类别之间有显著差别的项目。
测验编制的分析技术
信效度
信度是测量的可靠性,指测量结果的一致性或稳定性。
信度分析仅针对测验或量表类型的数据;仅针对定量数据。
常用克朗巴哈系数系数(Cronbach α系数)表示可信程度,若大于0.8,表明该量表的信度非常好,在0.7以上可以接受,0.6以上表示量表应进行修订但不失其价值,0.6以下需要重新设计题项。
信度与误差之间有密切关系,误差变异越大,信度越低。探讨影响信度的因素,基本上是探讨误差的来源。造成测量误差的原因可能有:
- 程序性因素
- 受试者因素(受测者的身心健康状况,动机,注意力,持久性,作答态度等)
- 主试者因素(非标准化的测验程序,主试者的偏颇与暗示,评分的主观性等)
- 测验环境因素(测验环境条件如通风,光线,声音,桌面,空间等)
- 工具本身的因素
- 测验内容因素(试题抽样不当,内部一致性低,题数过少等)
样本的异质性也会影响信度。如果接受测验的受测者的异质性越大,总分变异越大,得到的信度系数就越高。
效度是测量的正确性,指测验或其他测量工具确实能够测得其所想要测量的内容的程度。
效度分析针对定量数据,常通过因子分析进行验证。一般,效度只针对量表数据,对于非量表数据,若想分析效度,建议使用“内容效度”,即用文字详细描述问卷设计的过程,用文字描述问卷做什么、有什么用、为什么合理、且有专家认证,以此说明问卷设计合理有效。
测量的效度越高,表明测量的结果越能显现其所想要测量内容的真正特征。
效度通常用测验分数和想要测量的特质之间的相关系数来表示。
参考文献
邱皓政 《量化研究与统计分析》
Dawn Griffiths《深入浅出统计学》
Michael Milton《深入浅出数据分析》

若有收获,就点个赞吧
0 人点赞
