信息存储
:::info
存储单元
大多数计算机使用8位的块,或者字节(byte),作为最小的可寻址的内存单位,而不是访问内存中单独的位。
地址
内存的每个字节都由一个唯一的数字来标识,称为它的地址(address),所有可能地址的集合就称为虚拟地址空间(virtualaddress space)。
:::
16进制表示法

一个字节由8位组成,用二进制表示即为0000 0000-1111 1111,十进制表示为0-255.两种符号表示法对于描述位模式来说都不是非常方便。二进制表示法太冗长,而十进制表示法与位模式的互相转化很麻烦。替代的方法是,以16为基数,或者叫做十六进制(hexadecimal)数。16进制下一个字节的值域为00-FF。
字数据大小
:::warning
每台计算机都有一个字长(wordsize),指明指针数据的标称大小(nominalsize)。因为虚拟地址是以这样的一个字来编码的,所以字长决定的最重要的系统参数就是虚拟地址空间的最大大小。也就是说,对于一个字长为w位的机器而言,虚拟地址的范围为 ,程序最多访问
,程序最多访问 个字节。
:::
32位字长限制虚拟地址空间为4千兆字节(写作4GB),也就是说,刚刚超过
个字节。
:::
32位字长限制虚拟地址空间为4千兆字节(写作4GB),也就是说,刚刚超过 字节。扩展到64位字长使得虚拟地址空间为
字节。扩展到64位字长使得虚拟地址空间为16EB,大约是 字节.
字节.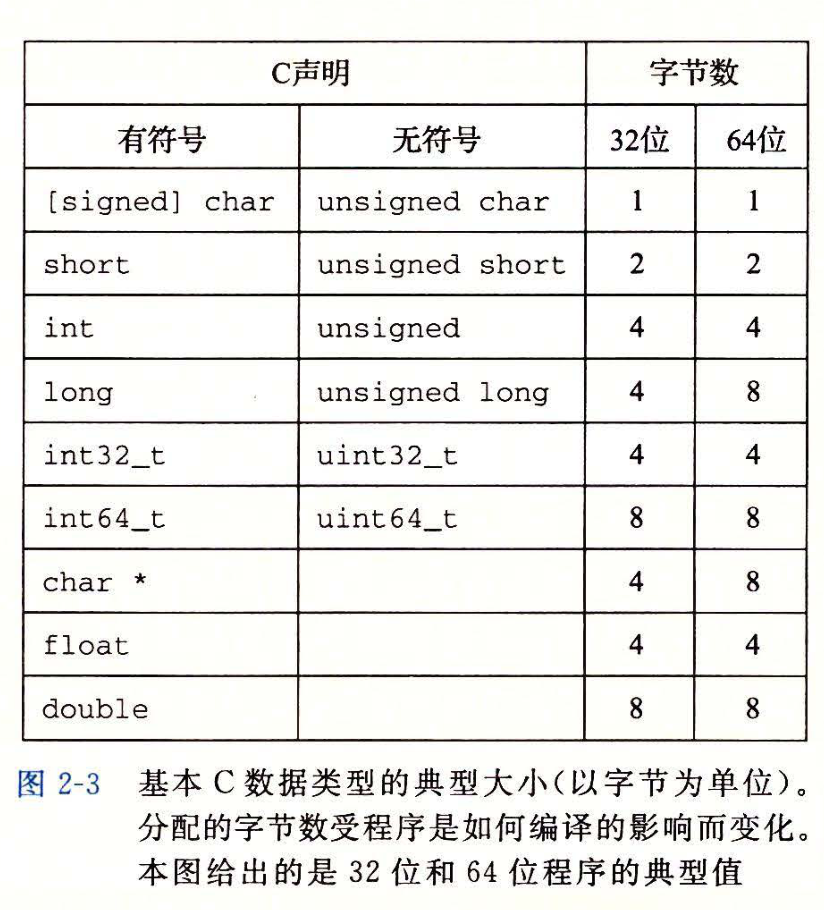
不同类型机器的字长不同,会引发一些未知的错误行为。
:::warning
为了避免由于依赖“典型”大小和不同编译器设置带来的奇怪行为,ISO C99引入了一类数据类型,其数据大小是固定的,不随编译器和机器设置而变化。其中就有数据类型int32_t和int64_t,它们分别为4个字节和8个字节
:::
寻址和字节顺序
- 大端序:一些机器则按照从最高有效字节到最低有效字节的顺序存储。这种最高有效字节在最前面的方式,称为大端法(bigendian)。
- 小端序:某些机器选择在内存中按照从最低有效字节到最高有效字节的顺序存储对象。最低有效字节在最前面的方式,称为小端法(littleendian)。
假设一个int变量,地址从0x100开始,16进制值为0x01234567,大端法和小端法的存储方式分别如下: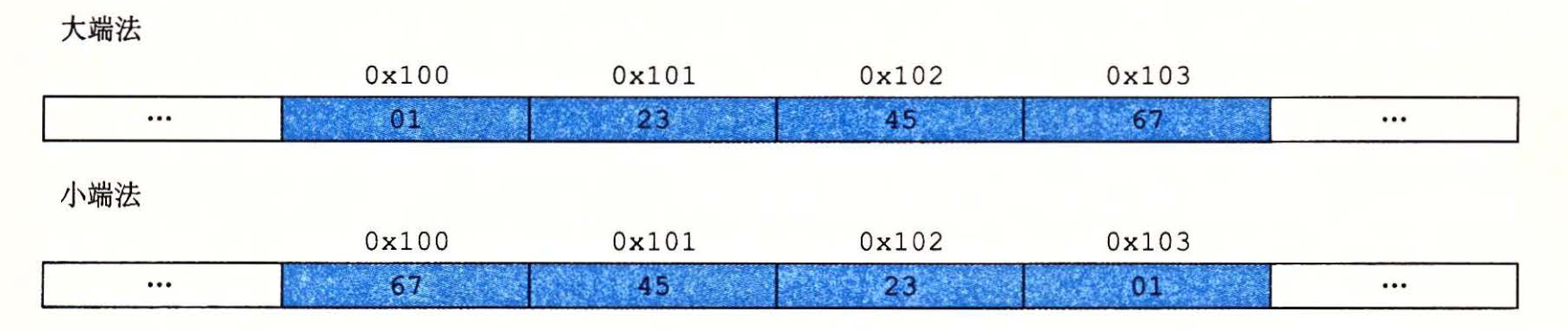
表示字符串
:::info
C语言中字符串被编码为一个以null(其值为0)字符结尾的字符数组。每个字符都由某个标准编码来表示,最常见的是ASCII字符码
:::
:::warning
关于Unicode
ASCII字符集适合于编码英语文档,但是在表达一些特殊宇符方面并没有太多办法。它完全不适合编码希腊语、俄语和中文等语言的文档。这些年,提出了很多方法来对不同语言的文字进行编码。Unicode联合会(Unicode Consortium)修订了最全面且广泛接受的文字编码标准。
基本编码,称为Unicode的“统一字符集“,使用32位来表示字符。这好像要求文本串中每个字符要占用4个字节。不过,可以有一些替代编码,常见的宇符只需要1个或2个字节,而不太常用的字符需要多一些的字节数。
:::
表示代码
实际上代码在机器中也是通过字节表示的机器代码存储的 :::info 不同的机器类型使用不同的且不兼容的指令和编码方式。即使是完全一样的进程,运行在不同的操作系统上也会有不同的编码规则,因此二进制代码是不兼容的。二进制代码很少能在不同机器和操作系统组合之间移植。 :::
运算
C语言中的位级运算
C语言支持按位的与或非操作:
小技巧之通过按位异或进行交换
void swapNum(int* x,int* y){*y=*x^*y;*x=*x^*y;*y=*x^*y;//因为 a^a=0;0^x=x}
需要注意的是要保证x和y并非指向同一个数
位运算最常见的功能就是做掩码:例如x&0xFF即求低八位的数据
逻辑运算
C语言还提供了一组逻辑运算符II、&&和!,分别对应千命题逻辑中的OR、AND和NOT运算。逻辑运算很容易和位级运算相混淆,但是它们的功能是完全不同的。逻辑运算认为所有非零的参数都表示TRUE,而参数0表示FALSE。
逻辑运算符
&&和||与它们对应的位级运算&和|之间第二个重要的区别是,如果对第一个参数求值就能确定表达式的结果,那么逻辑运算符就不会对第二个参数求值。
移位运算
C语言还提供了一组移位运算,向左或者向右移动位模式。对于一个位表示为 的操作数
的操作数 ,C表达式
,C表达式x<<k会生成一个值,其位表示为 。也就是说,
。也就是说, 向左移动k位,丢弃最高的k位,并在右端补k个0。移位量应该是一个
向左移动k位,丢弃最高的k位,并在右端补k个0。移位量应该是一个 之间的值。移位运算是从左至右可结合的,所以
之间的值。移位运算是从左至右可结合的,所以x<<j<<k等价于(x<<j)<<k。
一般而言,机器支持两种形式的右移:逻辑右移和算术右移。
- 逻辑右移在左端补k个0,
算术右移是在左端补k个最高有效位的值。它对有符号整数数据的运算非常有用。 :::tips 移位指令只考虑位移量的低
 位,因此实际上位移量就是通过计算
位,因此实际上位移量就是通过计算k mod w得到的,也就是说如果k>w,那么位移实际上是取模后的k值。 :::整数表示
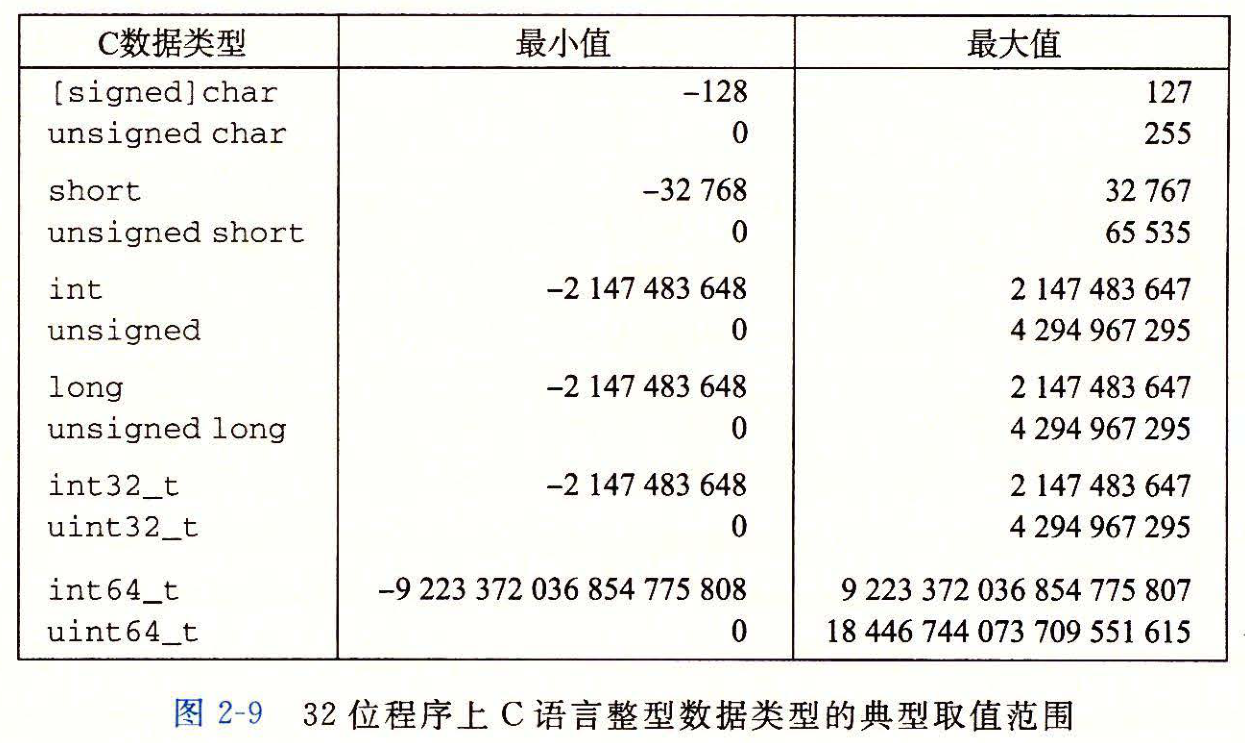 :::danger
一个很值得注意的特点是取值范围不是对称的负数的范围比整数的范围大1
:::
:::danger
一个很值得注意的特点是取值范围不是对称的负数的范围比整数的范围大1
:::
无符号数的编码
假设有一个整数数据类型有
 位。我们可以将位向量写成
位。我们可以将位向量写成 表示整个向量,或者写成
表示整个向量,或者写成 表示向量中的每一位。把
表示向量中的每一位。把 看做一个二进制表示的数
看做一个二进制表示的数
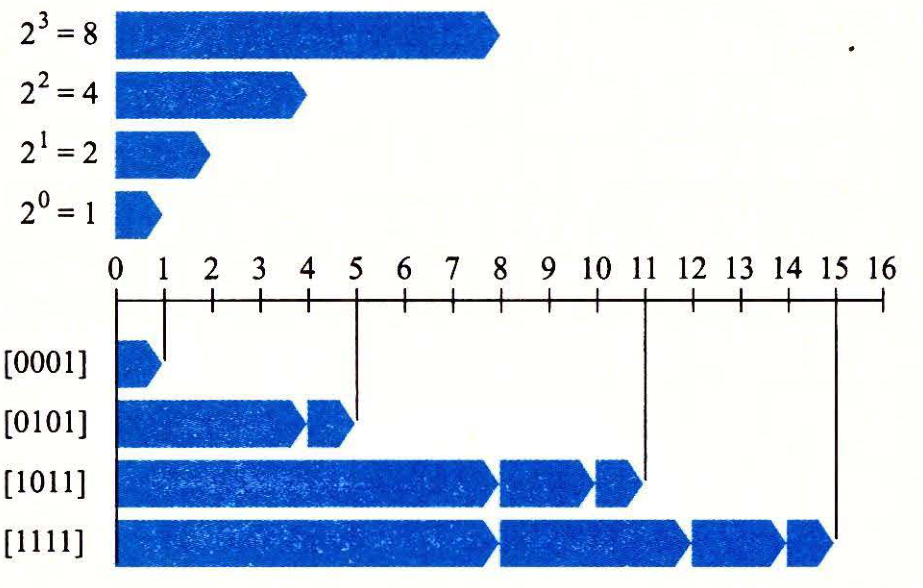
无符号数的二进制表示有一个很重要的属性,也就是每个介于 之间的数都有唯一一个w位的值编码。
之间的数都有唯一一个w位的值编码。
补码编码
对于许多应用,我们还希望表示负数值。最常见的有符号数的计算机表示方式就是补码(
two's-complement)形式。在这个定义中,将字的最高有效位解释为负权(negative weight)。
对于

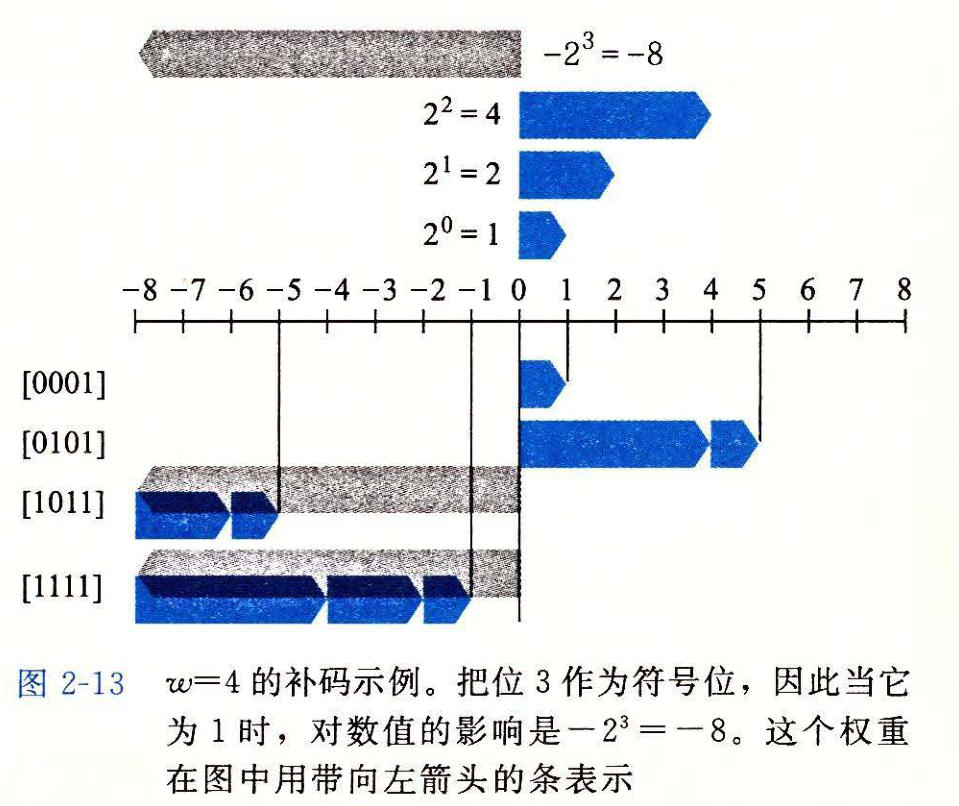
补码的范围是不对称的: 也就是说,
也就是说,TMin没有与之对应的正数。正如我们将
会看到的,这导致了补码运算的某些特殊的属性,并且容易造成程序中细微的错误。有符号数和无符号数之间的转换
:::info 强制类型转换的结果保持位值不变,只是改变了解释这些位的方式。对于大多数C语言的实现,处理同样字长的有符号数和无符号数之间相互转换的一般规则是:数值可能会改变,但是位模式不变。 :::

有符号数和无符号数
C语言支持所有整型数据类型的有符号和无符号运算。尽管C语言标准没有指定有符号数要采用某种表示,但是儿乎所有的机器都使用补码。通常,大多数数字都默认为是有符号的。例如,当声明一个像
12345或者0x1A2B这样的常量时,这个值就被认为是有符号的。要创建一个无符号常量,必须加上后缀字符'u'或者'U',例如,12345U或者0x1A2Bu。 :::success C语言允许无符号数和有符号数之间的转换。虽然C标准没有精确规定应如何进行这种转换,但大多数系统遵循的原则是底层的位表示保持不变。 :::扩展一个数字的位表示
要将一个无符号数转换为一个更大的数据类型,我们只要简单地在表示的开头添加0。这种运算被称为零扩展(zero extension)
- 要将一个补码数字转换为一个更大的数据类型,可以执行一个符号扩展(sign extension),在表示中添加最高有效位的值
输出结果如下short sx = -12345; /* -12345 */unsigned short usx = sx; /* 53191 */int x = sx; /* 12345 */unsigned ux = usx; /* 53191 */printf("sx = %d:\t", sx);show_bytes((byte_pointer) &sx, sizeof(short));printf("usx = %u:\t", usx);show_bytes((byte_pointer) &usx, sizeof(unsigned short));printf("x = %d:\t", x);show_bytes((byte_pointer) &x, sizeof(int));printf ("ux = %u: \t", ux);show_bytes((byte_pointer) &ux,sizeof(unsigned));
:::info 我们看到,尽管sx = -12345: cf c7usx = 53191: cf c7X = -12345: ff ff cf c7ux = 53191: 00 00 cf c7
-12345的补码表示和53191的无符号表示在16位字长时是相同的,但是在32位字长时却是不同的。这就是补码符号扩展的原因,why?为了保证补码的值不变 :::截断数字
:::info 当将一个w位的数 截断为一个k位数字时,我们会丢弃高w-k位,得到一个位向量
截断为一个k位数字时,我们会丢弃高w-k位,得到一个位向量 。截断一个数字可能会改变它的值溢出的一种形式。
:::
对于截断无符号数
。截断一个数字可能会改变它的值溢出的一种形式。
:::
对于截断无符号数 .该原理背后的直觉就是所有被截去的位其权重形式都为
.该原理背后的直觉就是所有被截去的位其权重形式都为 ,其中i>=k,因此,每一个权在取模操作下结果都为零。
,其中i>=k,因此,每一个权在取模操作下结果都为零。补码截断也具有相似的属性,只不过要将最高位转换为符号位.
整数运算
无符号加法
考虑两个非负整数x和y,满足 。每个数都能表示为w位无符号的数字,然而如果要计算和,至少需要w+1位(
。每个数都能表示为w位无符号的数字,然而如果要计算和,至少需要w+1位( )
)
这种持续的”字长膨胀”意味着,要想完整地表示算术运算的结果,我们不能对字长做任何限制。更常见的是,编程语言支持固定精度的运算,因此像“加法”和"乘法”这样的运算不同千它们在整数上的相应运算。
:::info
让我们为参数x和y定义运算 ,其中
,其中 ,该操作是把整数和
,该操作是把整数和 截断为w位得到的结果,再把这个结果看做是一个无符号数。
截断为w位得到的结果,再把这个结果看做是一个无符号数。
实际上加法涉及截断,或者说会考虑溢出的情况。
:::

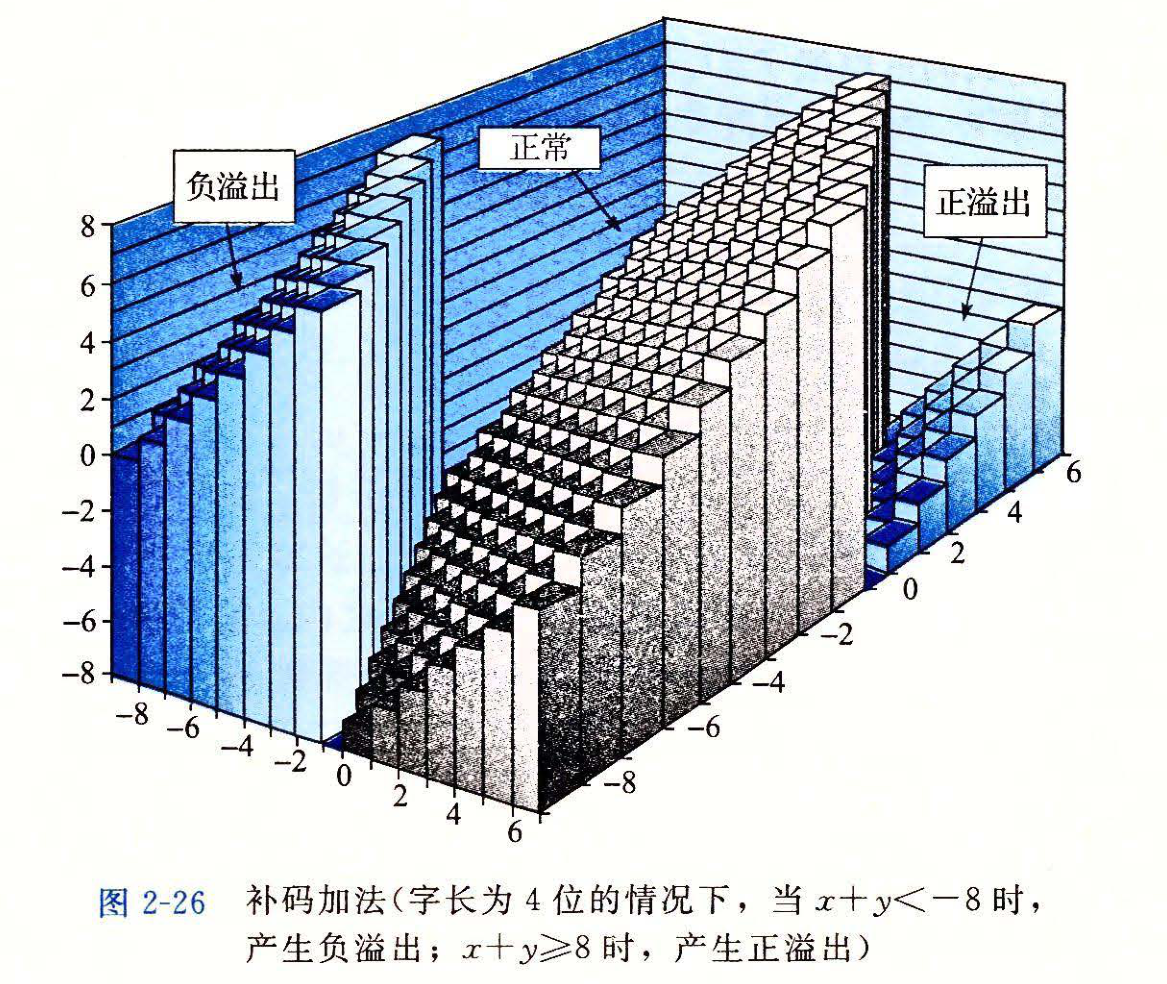
补码的加法
类似地,补码的加法也需要考虑溢出,只不过有正数的溢出和负数的溢出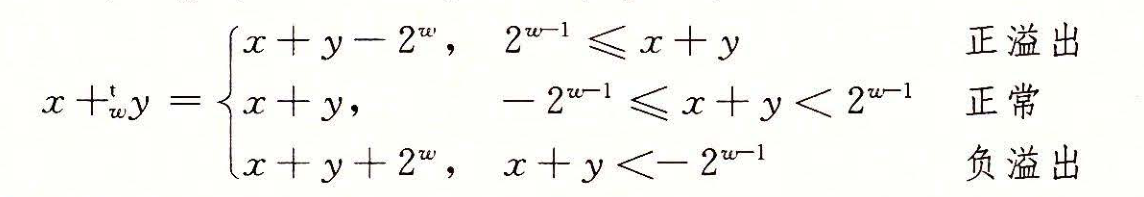
浮点数
浮点表示对形如 护的有理数进行编码。它对执行涉及非常大的数字、非常接近于0的数字,以及更普遍地作为实数运算的近似值计算。
护的有理数进行编码。它对执行涉及非常大的数字、非常接近于0的数字,以及更普遍地作为实数运算的近似值计算。
IEEE浮点表示
:::info
IEEE浮点标准用 的形式来表示一个数:
:::
的形式来表示一个数:
:::
- 尾数(significand):M是一个二进制小数,它的范围是
 ,或者是
,或者是 。
。 - 阶码(exponent):E的作用是对浮点数加权,这个权重是2的E次幕(可能是负数)。
将浮点数的位表示划分为三个字段,分别对这些值进行编码:
一个单独的符号位s直接编码符号s。
k位的阶码字段 编码阶码E。
编码阶码E。
n位小数字段 编码尾数M,但是编码出来的值也依赖于阶码字段的值是否等千0。
:::info
在单精度浮点格式(C语言中的floa七)中,s、exp和frac字段分别为1位、k=8位和n=23位,得到一个32位的表示。在双精度浮点格式(C语言中的double)中,s、exp和frac字段分别为1位、k=11位和n=52位,得到一个64位的表示。
:::
编码尾数M,但是编码出来的值也依赖于阶码字段的值是否等千0。
:::info
在单精度浮点格式(C语言中的floa七)中,s、exp和frac字段分别为1位、k=8位和n=23位,得到一个32位的表示。在双精度浮点格式(C语言中的double)中,s、exp和frac字段分别为1位、k=11位和n=52位,得到一个64位的表示。
:::


若有收获,就点个赞吧
0 人点赞
