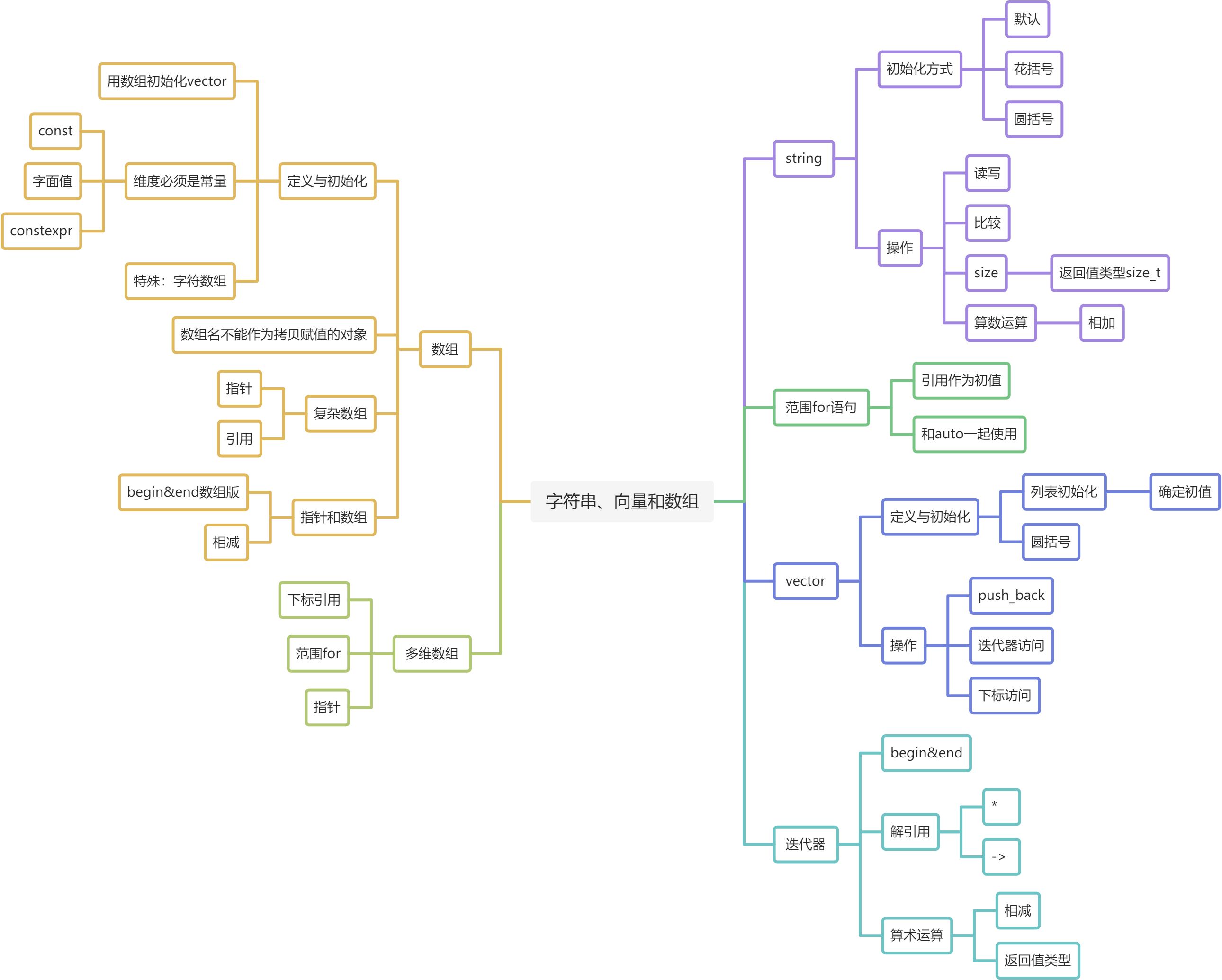
Using声明
使用using声明可以访问到特定作用域的变量,而不用复杂度一直使用::作用域运算符
位于头文件的代码一般来说不应该使用u s i n g产明。这是因为头文件的内容会拷贝到所有引用它的文件中去,如果头文件里有某个using声明,那么每个使用了该头文件的文件就都会有这个声明。
标准库类型string
标准库类型string表示可变长的字符序列,
始化string对象的方式
string s1;string s2(s1);string s2=s1; //等价于2string s3("value"); //s3是字符串常量"value"的副本string s3="value"; //等价于4方式string s4(n,'c') //n个'c'
拷贝初始化和直接初始化
如果使用等号=初始化一个变量,实际上执行的是拷贝初始化( copy initialization) ,编译器把等号右侧的初始值拷贝到新创建的对象中去(e.g. 3&5)。与之相反,如果不使用等号,则执行的是直接初始化(e.g. 2&4)
string的操作

读写string对象
- 在执行读取操作时,string对象会自动忽略开头的空白(即空格符、换行符、制表符等)并从第一个真正的字符开始读起,直到遇见下一处空白为止
- 读一行getline
getline()函数的参数是一个输入流和一个string对象,函数从给定的输入流中读入内容,直到遇到换行符为止(注意换行符也被读进来了),然后把所读的内容存入到那个string对象中去(注意不存换行符)
int main(){string line;while(getline(cin,line)){cout<<line<<endl;}return 0;}
size
但其实size函数返回的是一个string::size_type类型的值
:::info
- string类及其他大多数标准库类型都定义了几种配套的类型。这些配套类型体现了标准库类型与机器无关的特性.
- 由于
size()函数返回的是一个无符号整型数,因此切记,如果在表达式中混用了带符号数和无符号数将可能产生意想不到的结果,例如若int n=-1,那么size()<n必然恒成立; :::
String进行比较
string对象相等意味着它们的长度相同而且所包含的字符也全都相同。
- 如果两个srting对象的长度不同,而且较短string对象的每个字符都与较长string对象对应位翌上的字符相同,就说较短string对象小千较string对象。
若某些位置上符号不同,则返回string对象中第一对相异字符比较的结果。
相加
相加实际上是字符串拼接 :::info 对string对象使用加法运算符
+的结果是一个新的string对象,它所包含的字符由两部分组成:前半部分是加号左侧string对象所含的字符、后半部分是加号右侧string对象所含的字符。 :::与字面值相加:
把string对象和字符字面值及字符串字面值混在一条语句中使用时,必须确保每个加法运算符+的两侧的运算对象至少有一个是string因为某些历史原因,也为了与C兼容 ,所以C++ 语言中的字符串宇面值并不是标准库类型string的对象。切记,字符串宇面值与string是不同的类型
*范围for语句
:::info C++11提供了新语句:范围for(range for),可以遍历给定序列的所有元素 :::
for(declaration:expression)statement
expression:一个序列
- declaration:变量,用于访问序列的基础元素,每次都会访问下一个元素
string s1(10,'c');for(auto c:s1)cout<<c<<endl;
范围for改变字符串
要想改变序列中的值,必须把变量声明为引用string s("hello");for(auto &c:s)c=toupper(c);
标准库类型vector
vector是一个模板类,表示对象的集合, 其中所有对象的类型都相同。集合中的每个对象都有一个与之对应的索引,索引用于访问对象。 :::info 模板
模板本身不是类或函数,相反可以将模板看作为编译器生成类或函数编写的一份说明。编译器根据模板创建类或函数的过程称为实例化,当使用模板时,需要指出编译器应把类或函数实例化成何种类型。 :::
定义与初始化
vector的定义和初始化与string类类似
vector<T> v1;vector<T> v2(v1); //直接拷贝构造(初始化)vector<T> v2=v1; //这种方式会调用拷贝;vector<T> v3(n,val);vector<T> v4{a,b,c,};
列表初始化vector对象 :::info C++11提供的新方式:如果提供的是初始元素值的列表,则只能把初始值都放在花括号里进行列表初始化,而不能放在圆括号里 :::
值初始化问题:
可以允许只提供vector的元素数量而不去给初始值,此时库会创建一个值初始化的元素初值,将其赋给容器中所有元素,比如int型,则改值为0;
列表初始值还是元素数量?
:::tips
用花括号进行初始化,会尽可能的将花括号内的值当做元素初始值的列表来处理,只有当无法处理时,才会考虑其他的初始化方式。
:::
vector<int> v1{10}; //一个元素10vector<string> v2{10}; //10个空字符串
vector支持的操作
- 添加元素:
push_back() 使用下标访问
v[n](下标必须合法) :::warning 可以用下标访问元素,但是尽量不要用下标修改元素 :::empty……
迭代器
迭代器也提供了对对象的间接访问。就迭代器而言,其对象是容器中的元素或者string对象中的字符。使用迭代器可以访问某个元素,迭代器也能从一个元素移动到另外一个元素。迭代器有有效和无效之分,这一点和指针差不多。有效的迭代器或者指向某个元素,或者指向容器中尾元素的下一位置;其他所有情况都属于无效。
begin&end
begin():返回指向首元素的迭代器end():返回指向末尾元素后一个元素的迭代器;因此是个无效地址,无法访问解引用迭代器
解引用迭代器可获得迭代器所指的对象,如果该对象的类型恰好是类,就有可能希望进一步访问它的成员 。(*it).empty();
注意,
(*it).empty中的圆括号必不可少,该表达式的含义是先对it解引用,然后解引用的结果再执行点运算符。如果不加圆括号,点运算符将由辽来执行,而非it解引用的结果- 为了简化上述表达式,C++语言定义了箭头运算符
->。箭头运算符把解引用和成员访问两个操作结合在一起,也就是说,it->mem和(*it).mem表达的意思相同。
:::danger
某些对vector<>对象的操作会使迭代器失效:
具体而言值改变vector容量的操作都会有此风险
:::
迭代器的算术运算
迭代器与一个整数相加、相减,返回值时向前或向后移动了若干位置的迭代器。
:::info
迭代器之间可以相减
:::
difference_type
只要两个迭代器指向的是同一个容器中的元素或者尾元素的下一位置,就能将其相减,所得结果是两个迭代器的距离。所谓距离指的是右侧的迭代器向前移动多少位置就能追上左侧的迭代器,其类型是名为difference_type的带符号整型数。string和vector都定义了difference_type,因为这个距离可正可负,所以difference_type是带符号类型的。
:::danger
迭代器之间的加法并未定义!
使用mid=beg+(end-beg)/2而不是mid=(beg+end)/2;因为迭代器相加得到的是无意义的;
:::
数组
:::info 需要通过其所在位置访问。与vector不同的地方是, 数组的大小确定不变,不能随意向数组中增加元素。因为数组的大小固定,因此对某些特殊的应用来说程序的运行时性能较好,但是相应地也损失了一些灵活性。 :::
定义和初始化数组
数组是一种复合类型。数组的声明形如a[d],其中a是数组的名字,d是数组的维度。维度说明了数组中元素的个数,因此必须大千0 。数组中元素的个数也屈于数组类型的一部分,编译的时候维度应该是已知的。也就是说,维度必须是一个常量表达式
:::info
数组的大小是一个size_t类型的变量,该类型也是一个无符号类型,类似vector和string
:::
- 定义数组的时候必须指定数组的类型,不允许用
auto关键字由初始值的列表推断类型。另外和vector一样,数组的元素应为对象,因此不存在引用的数组。 - 可以对数组的元素进行列表初始化,此时允许忽略数组的维度。如果在声明时没有指明维度,编译器会根据初始值的数量计算并推测出来;相反,如果指明了维度, 那么初始值的总数不应该超出指定的大小。
Special:字符数组
char a1[]={'C','+','+'};char a2[]={'C','+','+'.'\n'};char a3[]="C++";char a4[3]="C++"\\wrong
字符数组有一种额外的初始化形式,我们可以用字符串字面值对此类数组初始化。当使用这种方式时,一定要注总字符串字面值的结尾处还有一个空字符,这个空字符也会像字符串的其他字符一样被拷贝到字符数组中去
不允许拷贝和赋值
数组名实际上是数组首地址;
不能将数组的内容拷贝给其他数组作为其初始值,也不能用数组为其他数组赋值
int a5[]=a1;//wronga5=a1;//wrong
复杂数组
int (*Parray)[10]=&arr; //指针,指向一个含有十个整数的数组
默认情况下,类型修饰符从右向左依次绑定。
:::info
就数组而言,由内向外阅读要比从右向左好多了。由内向外的顺序可帮助我们更好地理解Parray的含义:首先是圆括号括起来的部分,*Parray意味着Parray是个指针,接下来观察右边,可知道Parray是个指向大小为10的数组的指针,最后观察左边,知道数组中的元素是int
:::
指针和数组
使用数组的时候编译器一般会把它转换成指针。在大多数表达式中 ,使用数组类型的对象其实是使用一个指向该数组首元素的指针。
Begin和end函数
为了让指针的使用更简单、更安全,C++11新标准引入了两个名为begin和end的函数。这两个函数与容器中的两个同名成员功 能 类 似 ,不过数组毕竟不是类 , 因此这两个函 数不是成员函数。正确的使用形式是将数组作为它们的参数int* beg=begin(a)
指针运算
:::info
和迭代器一样, 两个指针相减的结果是它们之间的距离。参与运算的两个指针必须指向同一个数组当中的元素,如果两个指针分别指向不相关的对象,则不能比较它们
:::
指针相减的结果类似迭代器,返回的为ptrdiff_t的无符号数据类型
- 可以用数组给vector对象赋值:允许使用数组来初始化vector对象。 要实现这一目的,只要指明要拷贝区域的首元素地址和尾后地址就可以了。
- 但是不允许用vector给数组赋值
:::tips 现代的C++程序应当尽量使用vetor和迭代器, 避免使用内置数组和指针;应该尽昼使用string,避免使用C风格的基于数组的字符串。 :::
多维数组
:::info 严格来说,C++语言中没有多维数组,通常所说的多维数组其实是数组的数组。谨记这一点,对今后理解和使用多维数组大有益处。 :::
当一个数组的元素仍然是数组时, 通常使用两个维度来定义它:一个维度表示数组本身大小,另外一个维度表示其元素(也是数组)大小
int a[3][4];int a[4][10][20];int ia[3][4]={{0},{4},{8}};//初始化方式类似一维数组
下标引用
如果表达式含有的下标运算符数黛和数组的维度一样多,该表达式的结果将是给定类型的元素;反之,如果表达式含有的下标运算符数量比数组的维度小,则表达式的结果将是给定索引处的一个内层数组
int ia[2][3]=1;int (&row)[4]=ia[1] //把row绑定在ia的第二个4元素数组上
范围for语句处理多维数组
C++11新标准中新增了范围for语句,可以更方便的访问多维数组(用auto)
size_t cnt=0;for(auto &row:ia)for(auto &col :row){col=cnt;++cnt;}
:::info
为何用引用类型
这是因为,像之前一样第一个循环遍历ia的所有元素,注意这些元素实际上是大小为4的数组。因为row不是引用类型,所以编译器初始化row时会自动将这些数组形式的元素(和其他类型的数组一样)转换成指向该数组内首元素的指针。这样得到的row的类型就是int*,显然内层的循环就不合法了,编译器将试图在一个int*内遍历,这显然和程序的初衷相去甚远。
:::
:::tips
使用范围for语句处理多层数组,除了最内层外,其他所有的层都应该声明成引用.
:::
多维数组和指针
int ia[3][4];int (*p)[4]=ia;
因为多维数组实际上是数组的数组,所以由多维数组名转换得来的指针实际上是指向第一个内层数组的指针; :::tips 利用C++11中的auto,可以避免使用数组指针 :::
for(auto p=begin(ia);p!=end(ia);++p){\\pointer int (*p)[4]for(auto q=begin(*p);q!=end(*p);++q) \\ pointer int *q{cout *q;}}
:::info 此外,可以利用别名来简化 :::
using int_array=int[4];for(int_array *p=ia;p!=ia+3;++p){for(int *q=*p;q!=*p+4;q++){}}

若有收获,就点个赞吧
0 人点赞
