- 文章目录
- L 1 什么是操作系统
- 学习操作系统可以有很多层次
- L4. 操作系统接口
- 什么是操作系统接口?
- L5. 系统调用的实现
- 系统调用的直观实现
- 内核(用户)态, 内核(用户)段
- 硬件提供了“主动进入内核的方法”
- 系统调用的实现
- Linux系统调用的实现细节!
- int 0x80中断的处理
- L7. 我们的任务
- L8. CPU管理的直观想法
- 使用CPU
- 看看这样做有没有问题? 提出问题
- 多道程序、交替执行,好东西啊!
- 一个CPU面对多个程序
- 不止修改寄存器PC
- 引入“进程”概念
- L9. 多进程图像
- 多进程图像从启动开始到关机结束
- 多进程的组织:PCB+状态+队列
- 交替的三个部分:队列操作+调度+切换
- 多进程如何影响
- 进程带动内存的使用
- 多进程图像:多进程如何合作
- 核心在于进程同步(合理的推进顺序)
- 总结:如何形成多进程图像?
- L10 用户级线程
- 多进程是操作系统的基本图像
- 是否可以资源不动而切换指令序列?
- 多个执行序列+一个地址空间是否实用
- 实现这个浏览器
- 将所有的东西组合在一起……
- 用户级线程和核心级线程
- L11 内核级线程
- 和用户级相比,核心级线程有什么不同?
- 用户栈和内核栈之间的关联
- 内核线程switch_to的五段论
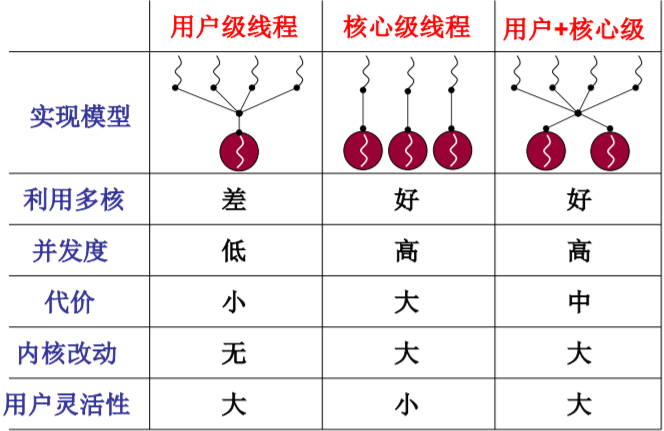
- 用户级线程、核心级线程的对比
- L12 内核级线程实现
- 核心级线程的两套栈,核心是内核栈…
- 整个故事要从进入内核开始——某个中断开始
- 切换五段论中的switch_to
- L13 操作系统的那棵“树”
- 运转CPU(种子)
- CPU没有好好运转
- 得让CPU好好运转
- 从A跳到B我们并不陌生
- 一个栈+Yield造成的混乱
- 两个栈+两个用户TCB
- 一直在用户态那怎么行?
- 引入内核栈的切换
- 到实现idea的时候了(Linux 0.01)
- L14 CPU调度策略
- 面对诸多场景,如何设计调度算法?
- 如何做到合理? 需要折中,需要综合…
- 各种CPU调度算法
- L15 一个实际的schedule函数
- Linux 0.11的调度函数schedule()
- counter的作用: 时间片
- counter的另一个作用: 优先级
- counter作用的整理
- L16 进程同步与信号量
- 从纸上到实际:生产者-消费者实例
- 只发信号还不能解决全部问题
- 从信号到信号量
- 什么是信号量? 信号量的定义…
- 用信号量解生产者-消费者问题
- L17 信号量临界区保护
- 解决竞争条件的直观想法
- 临界区(Critical Section)
- 多个进程怎么办? - 面包店算法 (软件)
- 临界区保护的另一类解法…
- 临界区保护的硬件原子指令法
- L18 信号量的代码实现
- 从Linux 0.11那里学点东西…
- L19 死锁处理
- 死锁的成因
- 死锁处理方法概述
- 死锁预防的方法例子
- 死锁避免: 判断此次请求是否引起死锁?
- 死锁检测+恢复: 发现问题再处理
- 死锁忽略的引出
- L20 内存使用与分段
- 重定位: 修改程序中的地址(是相对地址)
- 程序载入后还需要移动…
- 重定位最合适的时机 - 运行时重定位
- 程序员眼中的程序
- 不是将整个程序,是将各段分别放入内存
- L21 内存分区与分页
- 可变分区的管理过程 — 核心数据结构
- 可变分区的管理—再次申请
- 引入分页: 解决内存分区导致的内存效率问题
- 页已经载入了内存,接下来的事情…
- L22 多级页表与快表
- 页表会很大,页表放置就成了问题…
- 第一种尝试,只存放用到的页
- 第二种尝试:多级页表,即页目录表(章)+页表(节)
- 多级页表提高了空间效率,但在时间上? TLB
- TLB得以发挥作用的原因
- L23 段页结合的实际内存管理
- 段、页同时存在:段面向用户/页面向硬件
- 段、页同时存在是的重定位(地址翻译)
- 一个实际的段、页式内存管理
- 段、页式内存下程序如何载入内存?
- 故事从fork()开始
- 进程0、进程1、进程2的虚拟地址
- 接下来应该是什么了?
- 接下来干什么应该猜也猜的到…
- 程序、虚拟内存+物理内存的样子
- 第五步(总结)
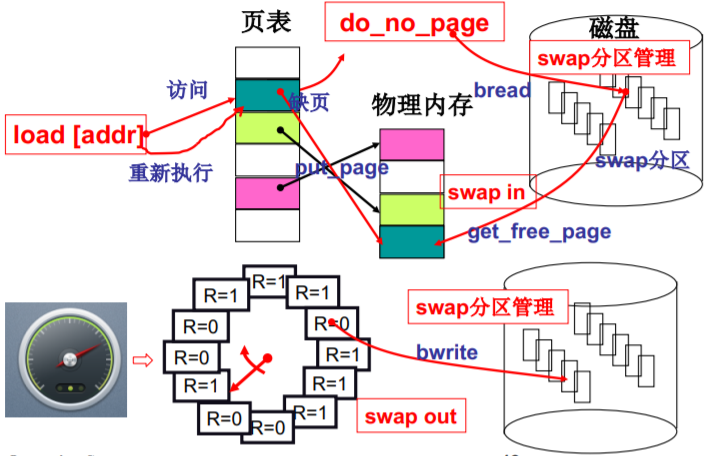
- L24 内存换入-请求调页
- 用户眼里的内存!
- 请求调页
- 一个实际系统的请求调页
- L25 内存换出
- get_free_page? 还是…
- LRU页面置换
- LRU准确实现,用页码栈
- Clock算法
- Clock算法的分析与改造
- 置换策略有了,还需要解决一个问题
- 总结(swap in swap out swap分区管理)
- L26 I/O与显示器
- 让外设工作起来
- 一段操纵外设的程序
- 一个统一的视图-文件视图
- 概念有了,开始给显示器输出…
- 只有一句话:mov pos
- printf的整个过程
- L27 键盘
- 关于键盘的故事从哪里开始?
- 键盘处理…
- 总结
- L28 生磁盘的使用
- 磁盘的I/O过程
- 通过盘块号读写磁盘(一层抽象)
- 从CHS到扇区号,从扇区到盘块
- 再接着使用磁盘:程序输出block
- 多个进程通过队列使用磁盘(第二层抽象)
- 生磁盘(raw disk)的使用整理
- L29 从生磁盘到文件
- 引入文件,对磁盘使用的第三层抽象
- 映射的作用
- 文件实现的第三种结构,索引结构
- 实际系统是多级索引
- L30 文件使用磁盘的实现
- 再一次使用磁盘,通过文件使用
- file_write的实现
- create_block算盘块,文件抽象的核心
- m_inode,设备文件的inode
- 伟大的文件视图…
- L31 目录与文件系统
- 文件系统,抽象整个磁盘(第四层抽象)
- 故事先从多个文件开始…
- 要使整个系统能自举,还需存一些信息
- “完成全部映射下”的磁盘使用
- L32 目录解析代码实现
- 就是将open弄明白…
- get_dir完成真正的目录解析
- 目录解析 — 从根目录开始
- 读取inode — iget
- 开始目录解析 — find_entry(&inode,name,…,&de)
- 操作系统全图
操作系统(哈工大李治军老师)32讲
The mind is not a vessel that needs filling, but wood that needs igniting!
文章目录
- L 1 什么是操作系统
- L4. 操作系统接口
- L5. 系统调用的实现
- L7. 我们的任务
- L8. CPU管理的直观想法
- L9. 多进程图像
- L10 用户级线程
- L11 内核级线程
- L12 内核级线程实现
- L13 操作系统的那棵“树”
- L14 CPU调度策略
- L15 一个实际的schedule函数
- L16 进程同步与信号量
- L17 信号量临界区保护
- L18 信号量的代码实现
- L19 死锁处理
- L20 内存使用与分段
- L21 内存分区与分页
- L22 多级页表与快表
- L23 段页结合的实际内存管理
- L24 内存换入-请求调页
- L25 内存换出
- L26 I/O与显示器
- L27 键盘
- L28 生磁盘的使用
- L29 从生磁盘到文件
- L30 文件使用磁盘的实现
- L31 目录与文件系统
- L32 目录解析代码实现
- 操作系统全图
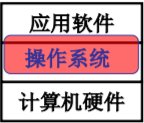
L 1 什么是操作系统
是计算机硬件和应用之间的一层软件
- 方便我们使用硬件,如使用显存…
- 高效的使用硬件,如开多个终端(窗口)
- 管理哪些硬件
- CPU管理 内存管理 终端管理 磁盘管理 文件管理 ——五基本功能(本课程重点)
- 网络管理 电源管理 多核管理
- 管理哪些硬件
学习操作系统可以有很多层次
- 从应用软件出发“探到操作系统”
- 集中在使用计算机的接口上
- 使用显示器:printf;使用CPU:fork,使用文件:open、read…

- 从应用软件出发“进入操作系统” (本课程目标)
- 一段文字是如何写到磁盘上的…
- 从硬件出发“设计并实现操作系统”
- 给你一个板子,配一个操作系统…

本课程目标
进入操作系统
- 能理解真实操作系统的运转!
- printf(hello”)到底怎么回事
- 能在真实的基本操作系统上动手实践!(能自己动手才是真正学会了…)
为什么要这样干?
- 学生:我们要成为掌握计算机关键技术的工程师
套用Stanford操作系统课程中的一句话: “Learn OS concepts by coding them!”
L4. 操作系统接口
接口(Interface)
仍然从常识开始… 日常生活中有很多接口:电源插座;汽车油门…
那什么是接口?
连接两个东西、信号转换、屏蔽细节…
什么是操作系统接口?
连接上层用户和操作系统软件

问题:操作系统直接面对用户吗? 即用户是怎么用操作系统的?..
用户如何使用计算机? 命令行 图形按钮 应用程序
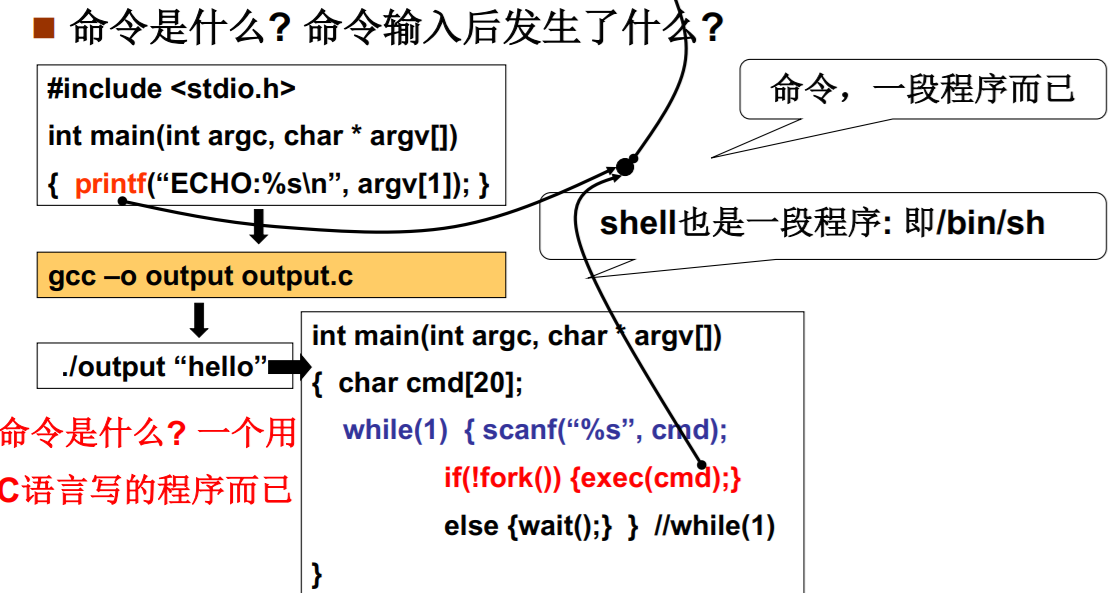
命令行是怎么回事?

图形按钮又是怎么回事?
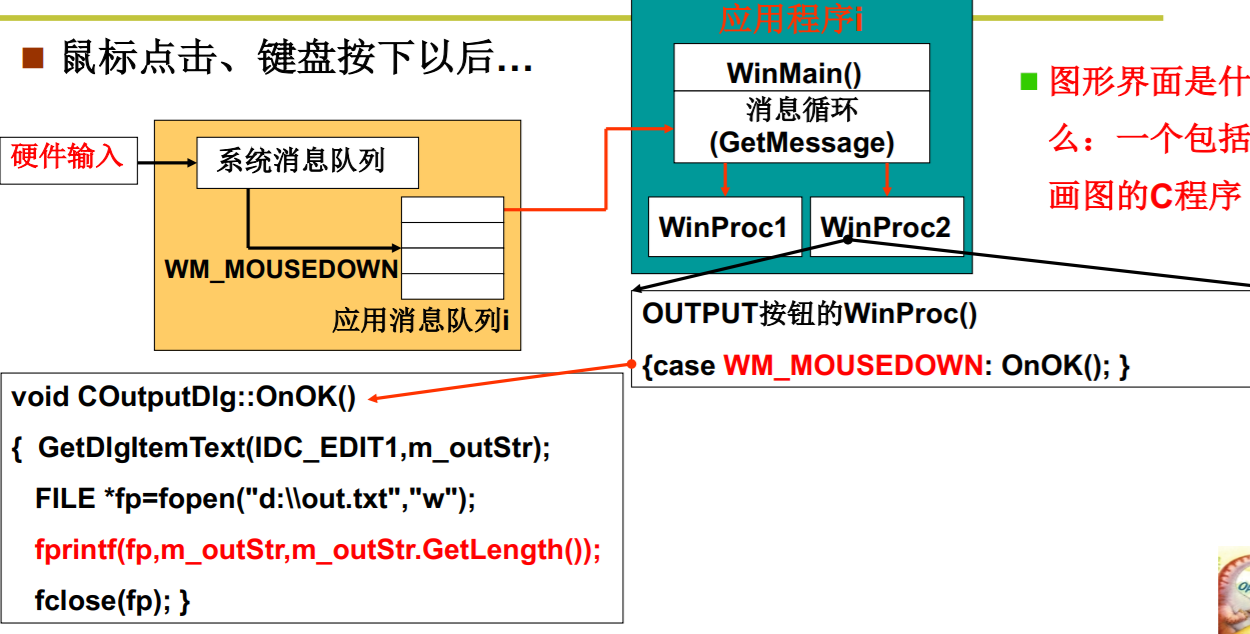
硬件驱动 + 消息机制 + 绘图机制 = 图形按钮
再回到那个问题
用户使用计算机:通过程序(应用软件)
- 命令行: 命令程序
- 图形界面:消息框架程序+消息处理程序
操作系统接口:连接谁? 连接操作系统和应用软件;如何连接? C语言程序
- 普通C代码加上一 些重要的函数
- 操作系统供这样的重要函数
这就是操作系统接口了: 接口表现为函数调 用,又由系统供,所以称为系统调用 (system call)
一个概念来回答问题
系统调用! 就好像电源插头一样…
- 先从认识“插头”开始,这是操作系统的常识
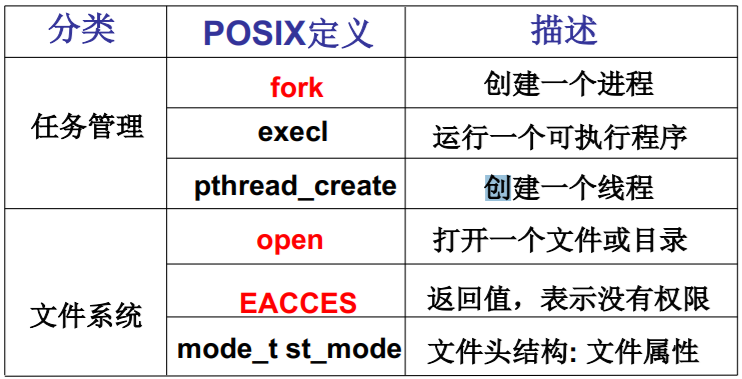
- POSIX: Portable Operating System Interface of Unix(IEEE制定的一个标准族)
L5. 系统调用的实现
系统调用的直观实现
问题+直观想法…
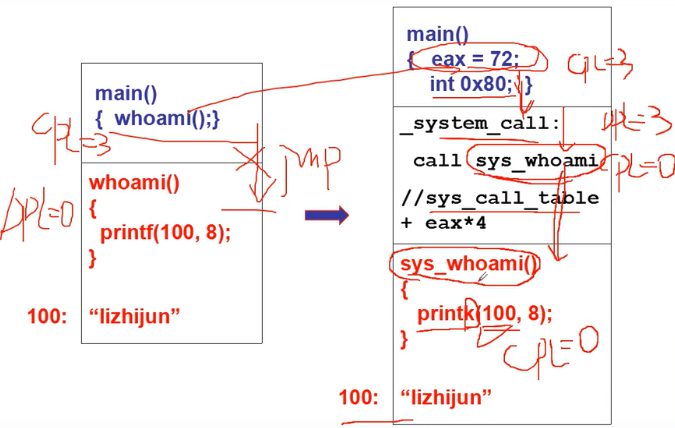
实现一个whoami系统调用
- 用户程序调用whoami, 一个字符串“lizhijun”放在操作系统中(系统引导 时载入),取出来打印
为什么不能直接访问该内存,要去操作系统中取?
100: “lizhijun” 都在内存中,这内存不都是我买的吗…
- 不能随意的调用数据, 不能随意的jmp。
- 可以看到root密码, 可以修改它…
- 可以通过显存看到别 人word里的内容…
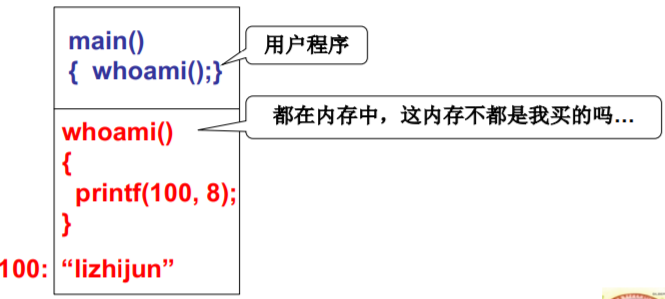
内核(用户)态, 内核(用户)段
将内核程序和用户程序隔离!!!
用户态执行在用户段下
内核态执行在内核段下
特权级:数字越大,级别越低

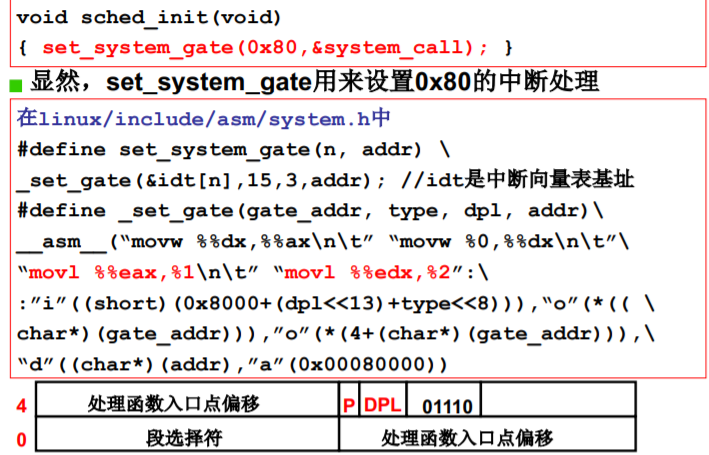
硬件提供了“主动进入内核的方法”
- 对于Intel x86,那就是中断指令
- int int指令将使CS中的CPL改成0, “进入内核”
- 这是用户程序发起的调用内核代码的唯一方式 (此时,CPL=3而 DPL=0)
- 系统调用的核心:
- (1) 用户程序中包含一段包含int指令的代码
- (2) 操作系统写中断处理,获取想调程序的编号
- (3) 操作系统根据编号执行相应代码
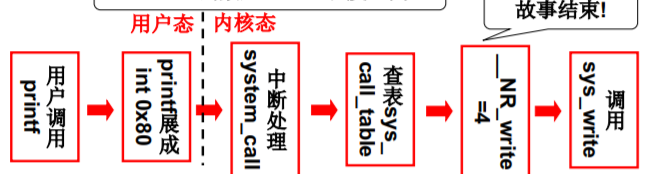
系统调用的实现
int 0x80
prinf 使用了 write
write 系统调用中 包含int指令的代码

Linux系统调用的实现细节!
将关于write的故事完整的讲完…
其系统调用从 #define _syscall3(_syscall3(int, write, int, fd, const char *buf, off_t, count)) type 继续说起

显然,__NR_write是系统调用号,放在eax中
在linux/include/unistd.h中
#define __NR_write 4 //一堆连续正整数(数组下标, 函数表索引)
同时eax也存放返回值,ebx,ecx,edx存放3个参数
int 0x80中断的处理
中断处理程序: system_call
_sys_call_table
L7. 我们的任务
我们要学什么? 再具体一些…
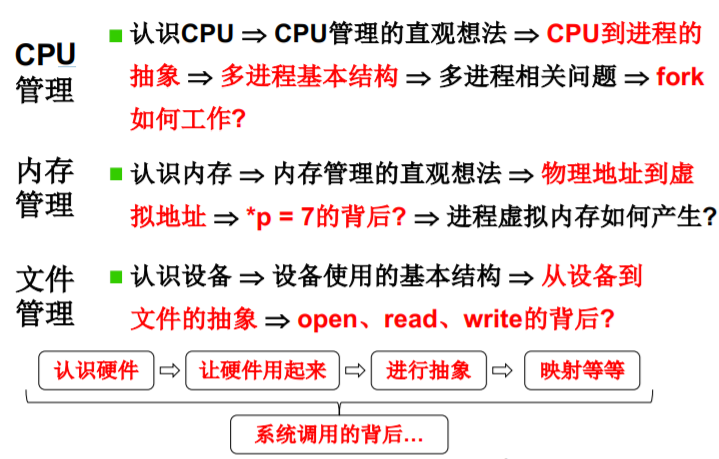
L8. CPU管理的直观想法
使用CPU
(计算机组成原理)
CPU工作原理
- CPU上电以后发生了什么? 自动的取指—执行
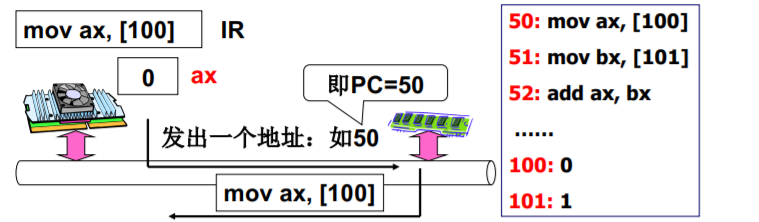
管理CPU的最直观方法 设好PC初值就完事
看看这样做有没有问题? 提出问题
int main(int argc, char* argv[]){int i , to, *fp, sum = 0;to = atoi(argv[1]);for(i=1; i<=to; i++){sum = sum + i;fprintf(fp,“%d”, sum);}}
fprintf 和 普通语句 运行时间比5.7 * 10^5 : 1 等fprintf —— 浪费时间
怎么解决?

多道程序、交替执行,好东西啊!
提高了CPU和外设的利用率
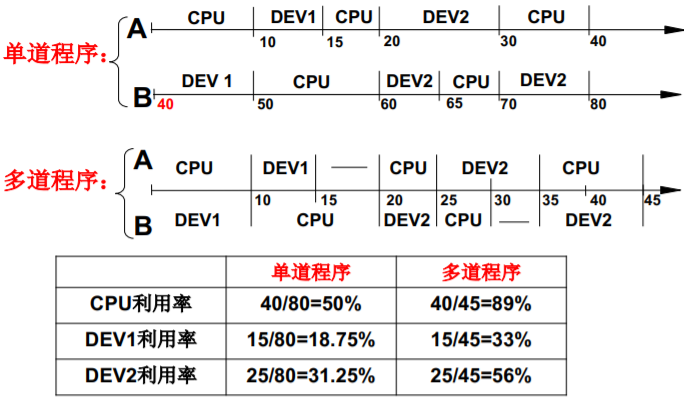
一个CPU面对多个程序
CPU实际工作的样子
一个CPU上交替的执行多个程序:并发
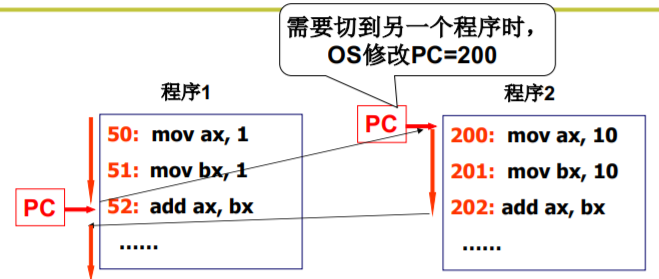
不止修改寄存器PC
运行的程序和静态 程序不一样了
要记录返回地址,要记录ax
每个程序有了一个存放信息的结构: PCB
引入“进程”概念
运行的程序和静态程序不一样!
- 需要描述这些不一样… (这些不一样就成了 进程概念的外延)
- 程序 + 所有这些不一样 -> 一个概念 (所有的不一样都表 现在PCB中…)
进程是进行(执行)中的程序
- 进程有开始、有结束,程序没有
- 进程会走走停停,走停对程序无意义
- 进程需要记录ax,bx,…,程序不用
L9. 多进程图像
多个进程使用CPU的图像
- 如何使用CPU呢? 让程序执行起来
- 如何充分利用CPU呢? 启动多个程序,交替执行
- 启动了的程序就是进程,所以是多个进程推进
- 操作系统只需要把这些进程记录好、要按照合理的次序推进(分配资源、进行调度)
- 这就是多进程图像…
进程控制块(PCB Process Control Block)
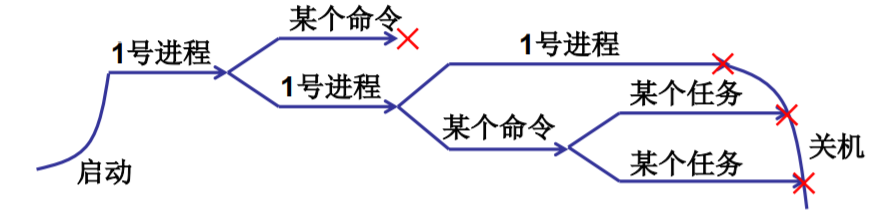
多进程图像从启动开始到关机结束
- main中的fork()创建了第1个进程
- init执行了shell(Windows桌面)
- shell再启动其他进程
int main(int argc, char * argv[]) {while(1) {scanf(“%s”, cmd);if(!fork()) {exec(cmd);}wait();}}
一命令启动一个进 程,返回shell再启 动其他进程…
多进程的组织:PCB+状态+队列
有一个进程在执行
有一些进程等待执行 (就绪队列)
有一些进程再等待某事件 (磁盘等待队列)
- 运行 -> 等待; 运行->就绪; 就绪->运行
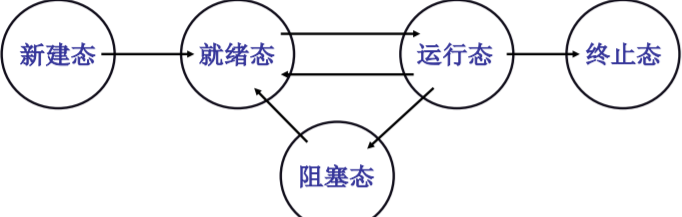
- 该图称为进程状态图
- 它能给出进程生存期的清晰描述
- 它是认识操作系统进程管理的一个窗口
交替的三个部分:队列操作+调度+切换
就是进程调度,一个很深刻的话题
- FIFO?
FIFO显然是公平的策略
FIFO显然没有考虑进程执行的任务的区别 - Priority?
优先级该怎么设定?可能会使某些进程饥饿
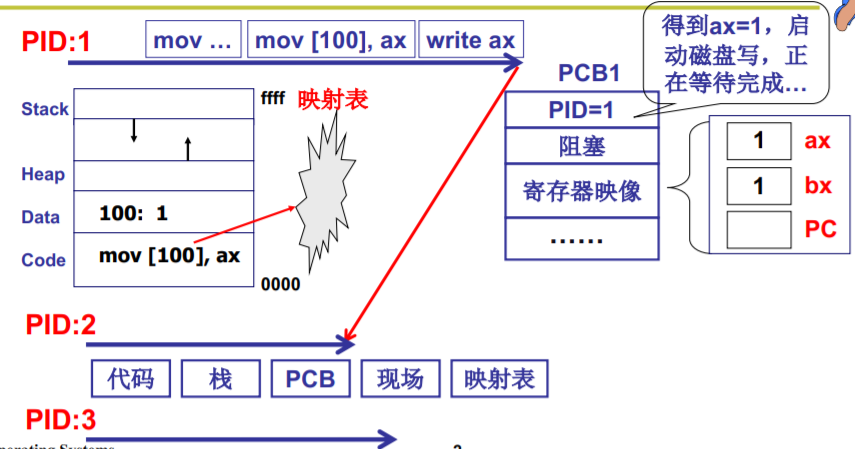
switch_to(pCur,pNew) {pCur.ax = CPU.ax;pCur.bx = CPU.bx;...pCur.cs = CPU.cs;pCur.retpc = CPU.pc; //oldCPU.ax = pNew.ax; //newCPU.bx = pNew.bx;...CPU.cs = pNew.cs;CPU.retpc = pNew.pc; }
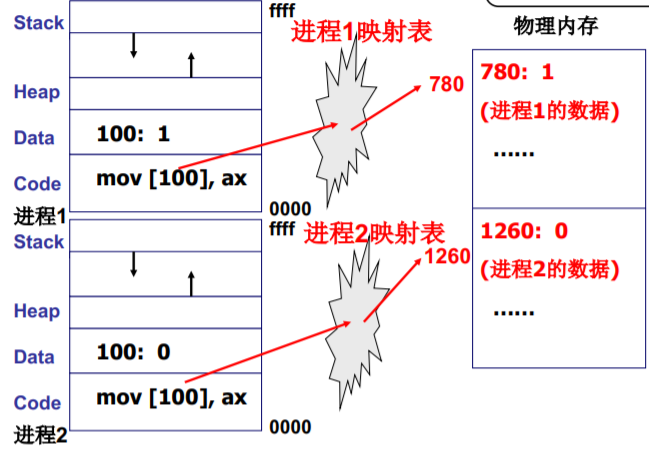
多进程如何影响
多个进程同时在存在于内存会出现下面的问题

解决的办法:限制对地址100的读写
多进程的地址空间分离:内存管理的主要内容
进程带动内存的使用
映射表的使用
多进程图像:多进程如何合作
想一想打印工作过程
- 应用程序提交打印任务
- 打印任务被放进打印队列
- 打印进程从队列中取出任务
- 打印进程控制打印机打印
从纸上到实际:生产者-消费者实例

两个合作的进程都要修改counter
一个可能的执行序列
P.register = counter;P.register = P.register + 1;C.register = counter;C.register = C.register - 1;counter = P.register;counter = C.register;
核心在于进程同步(合理的推进顺序)
写counter时阻断其 他进程访问counter

总结:如何形成多进程图像?
读写PCB,OS中最重要的结构,贯穿始终
要操作寄存器完成切换(L10,L11,L12)
要写调度程序(L13,L14)
要有进程同步与合作(L16,L17)
要有地址映射(L20)
L10 用户级线程
多进程是操作系统的基本图像
是否可以资源不动而切换指令序列?
- 进程 = 资源 + 指令执行序列
- 将资源和指令执行分开
- 一个资源 + 多个指令执行序列
- 线程: 保留了并发的优点, 避免了进程切换代价
- 实质就是映射表不变而PC指针变
切换线程——指令切换(PC指针切换),资源不切换(不更换映射表)
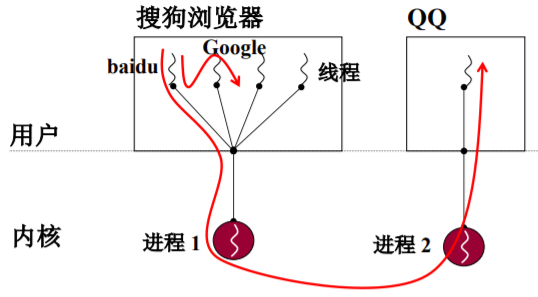
多个执行序列+一个地址空间是否实用
一个网页浏览器
- 一个线程用来从服务器接收数据
- 一个线程用来处理图片(如解压缩)
- 一个线程用来显示文本
- 一个线程用来显示图片
这些线程要共享资源吗?
- 接收数据放在100处,显示时要读…
- 所有的文本、图片都显示在一个屏幕上
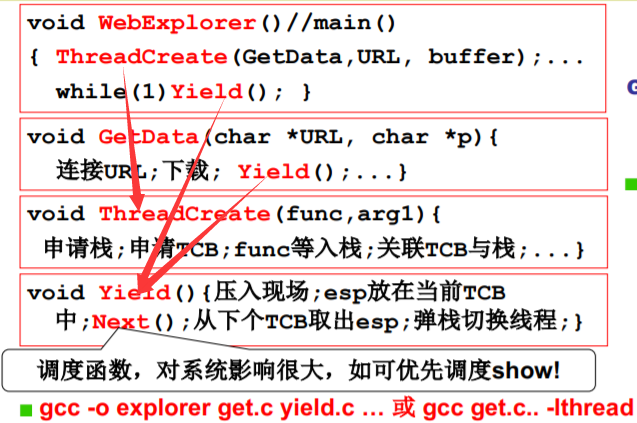
实现这个浏览器
void WebExplorer() {char URL[] = “http://cms.hit.edu.cn”;char buffer[1000];pthread_create(..., GetData, URL, buffer); //GetDatapthread_create(..., Show, buffer); //Show}void GetData(char *URL, char *p){...};void Show(char *p){...};
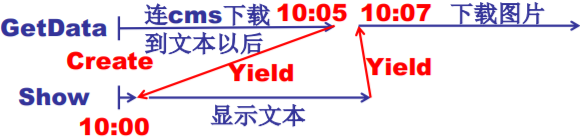
Create? Yield?
- 核心是Yield…
- 能切换了就知道切换时需要是个什么样子
- Create就是要制造出第一次切换时应该的样子
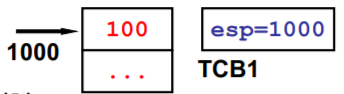
仔细看Yield,就是100跳到300
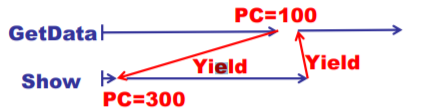
两个执行序列与一个栈
跳转的地址混乱,程序出现问题
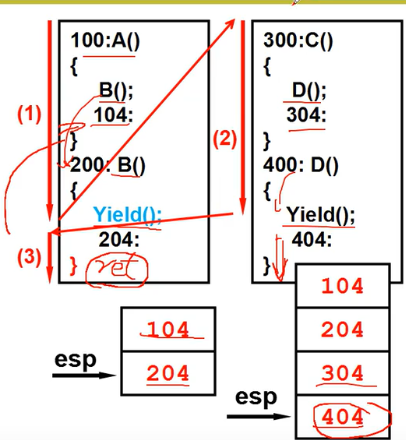
从一个栈到两个栈
TCB 和 栈 相互配合
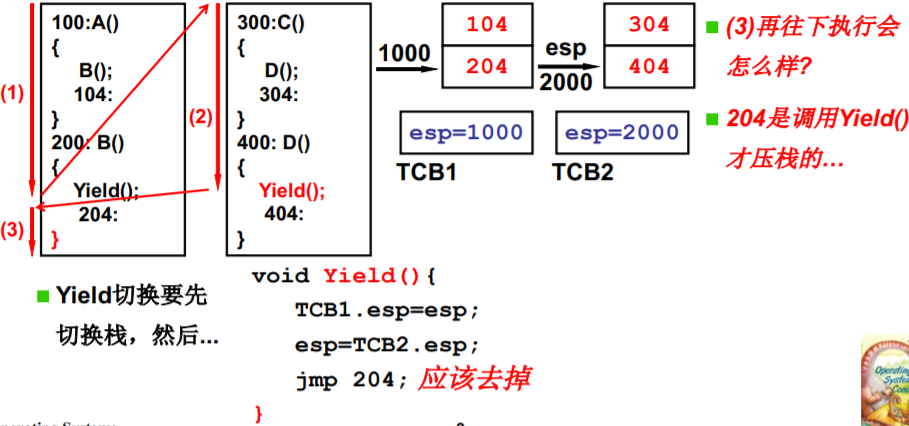
204是调用Yield() 才压栈的
jmp 204; 应该去掉,Yieid 执行完的下条指令 ,弹栈204执行jmp 204
两个线程的样子:两个TCB、两个栈、切换的PC在栈中
ThreadCreate的核心就是用程序做出这三样东西
void ThreadCreate(A){TCB *tcb=malloc();*stack=malloc();*stack = A;//100tcb.esp=stack;}
将所有的东西组合在一起……
用户级线程和核心级线程
- 为什么说是用户级线程——Yield是用户程序
如果用户级进程的某个线程进入内核并阻塞,则 容易造成卡死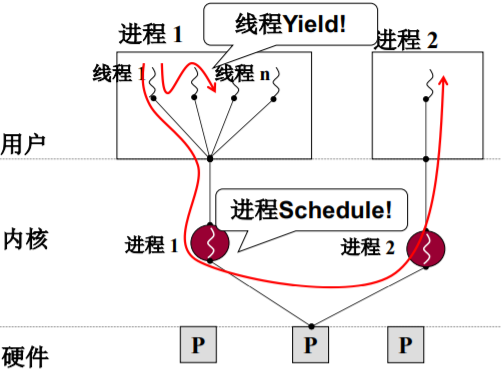
- ThreadCreate是系统调用,会进入内核,内核知道TCB (不用跳转进程,并发性更好)
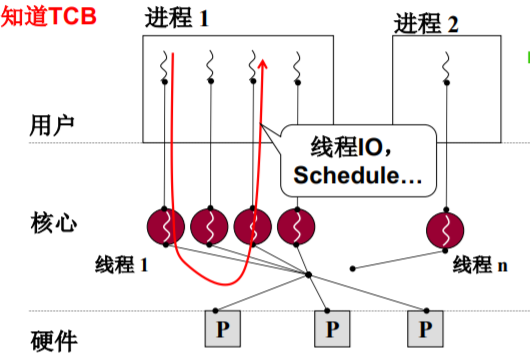
L11 内核级线程
开始核心级线程
多处理器和多核
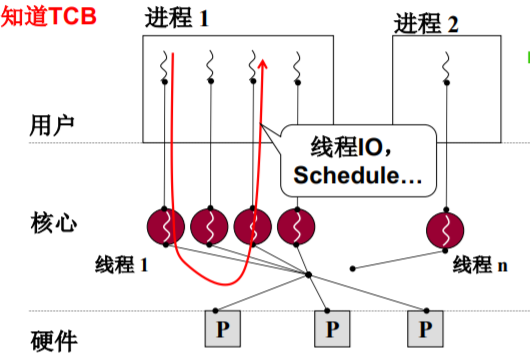
和用户级相比,核心级线程有什么不同?
- ThreadCreate是系统调用,内核管理TCB,内核负 责切换线程
- 如何让切换成型? - 内核栈,TCB
- 用户栈是否还要用? 执行的代码仍然在用户态,还要进行函数调用
- 一个栈(用户级) 到一套栈(核心级) ;两个栈(用户级) 到两套栈(核心级)
- TCB关联内核栈,那用户栈怎么办? TCB关联一套栈
一套栈

用户栈和内核栈之间的关联
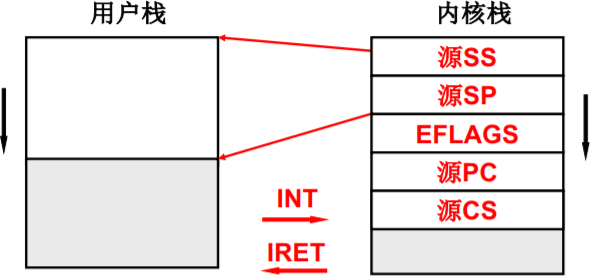
- 所有中断(时钟、外设、INT 指令)都引起上述切换用户栈
- 中断(硬件)又一次帮助了操作 系统…
内核线程switch_to的五段论


用户级线程、核心级线程的对比
L12 内核级线程实现
核心级线程的两套栈,核心是内核栈…
五段论
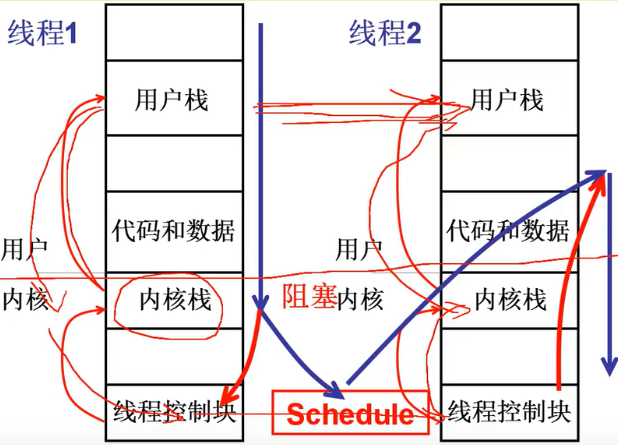
整个故事要从进入内核开始——某个中断开始
fork是系统调用,会引起中断…
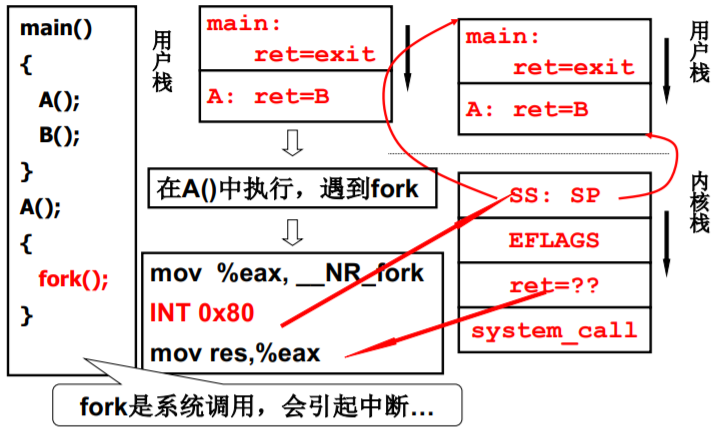
切换五段论中的switch_to
Linux 0.11用tss 切换,但也可以 用栈切换,因为 tss中的信息可以 写到内核栈中
L13 操作系统的那棵“树”
The mind is not a vessel that needs filling, but wood that needs igniting!
运转CPU(种子)
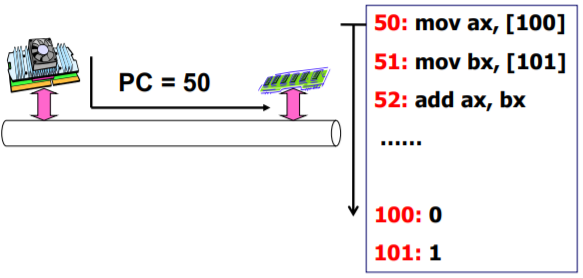
CPU没有好好运转

得让CPU好好运转
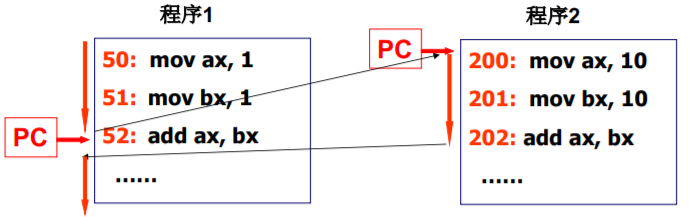
从A跳到B我们并不陌生
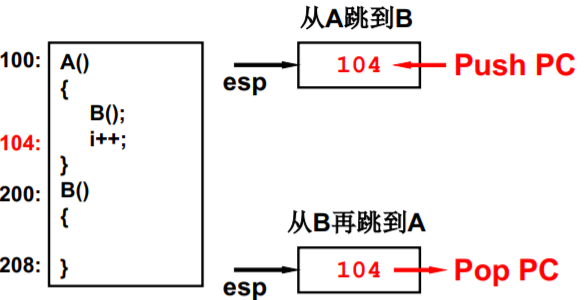
一个栈 一个进程里函数之间跳
一个栈+Yield造成的混乱
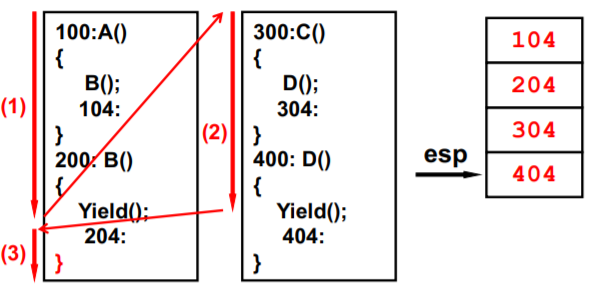
面对这样的栈你怎么可能从B顺利的回到A?
对于两个进程来说,一个栈不够用(如图的运行顺序 会造成混乱)
两个栈+两个用户TCB
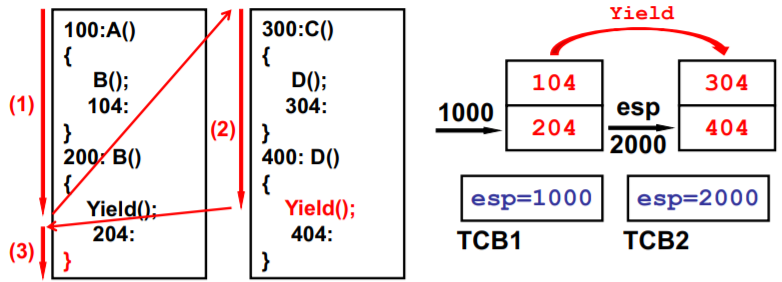
Yield()找到下一个TCB->找到新的栈->切到新的栈
一直在用户态那怎么行?
引入内核栈的切换
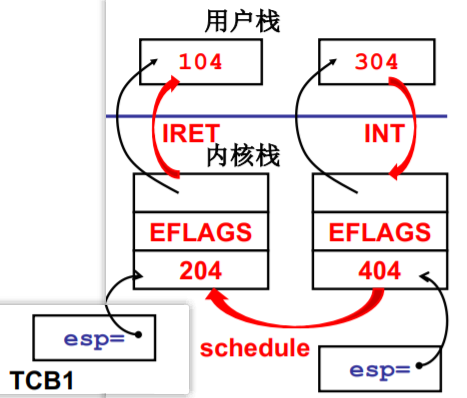
到实现idea的时候了(Linux 0.01)
从一个简单、清晰、明确的目标开始 交替的打出A和B (Linux 0.01)
从用户代码开始
main(){if(!fork()){while(1)printf(“A”);}if(!fork()){while(1)printf(“B”);}wait();}
程序是什么?就是人的思维的C表达
main(){mov __NR_fork, %eaxint 0x80 //INT进入内核100: mov %eax, rescmpl res,0jne 208200: printf(“A”)jmp 200208: ...304: wait()}
INT进入内核
开始sys_fork
开始copy_process
开始返回…
main继续执行,现在我们有了什么?
main继续,到了哪里?
schedule
switch_to切换
接下来会怎么样?
我们的目标是什么?
时钟中断
有那么一次时钟中断
schedule+switch_to
接下来会怎么样?
我们的目标达到了吗?
又有那么一次时钟中断, 再一次schedule+switch_to
接下来会怎么样?
L14 CPU调度策略
获得next
这两个进程,应该选择哪一个?
FIFO?
谁先进入,先调度谁: 简单有效
一个只简单询问业务的人该怎么办?
Priority?
任务短可以适当优先 (但你怎么知道这个任务将 来会执行多长时间呢?)
这人的询问越来越长怎么办?
那如果一个银行业务很长是因为客户需要填写一 个很长的表,该怎么办?
…
面对诸多场景,如何设计调度算法?
- 我们的算法应该让什么更好?
- 面对客户:银行调度算法的设计目标应该是用户满意
- 面对进程: CPU调度的目标应该是进程满意
- 那怎么才能让进程满意呢?时间…
- 尽快结束任务:周转时间(从任务进入到任务结束)短
- 用户操作尽快响应:响应时间(从操作发生到响应)短
- 系统内耗时间少:吞吐量(完成的任务量)
- 总原则:系统专注于任务执行,又能合理调配任务…
如何做到合理? 需要折中,需要综合…
- 吞吐量和响应时间之间有矛盾…
- 响应时间小->切换次数多->系统内耗大->吞吐量小
- 前台任务和后台任务的关注点不同…
- 前台任务关注响应时间,后台任务关注周转时间
- IO约束型任务和CPU约束型任务有各自的特点

I/O多(IO约束型任务) 的CPU长度较短的多 没I/O(CPU约束型) 的CPU长度较短
折中和综合让操作系统变得复杂, 但有效的系统又要求尽量简单…
各种CPU调度算法
响应时间 周转时间
- First Come, First Served (FCFS)
- 如何缩短周转时间? SJF: 短作业优先 (小顶堆)
- 响应时间该怎么办?

P2(用户)的等待时间非常长,一直没响应 (一点反应没有)
RR: 按时间片来轮转调度
时间片大: 响应时间太长;时间片小: 吞吐量小
折衷: 时间片10-100ms,切换时间0.1-1ms(1%) - 响应时间和周转时间同时存在,怎么办?
Word很关心响应时间,而gcc更关心周转时间,两类任务同时存在怎么办?
直观想法: 定义前台任务和后台任务两队列,前台RR,后台SJF,只有前台任务没有时才调度后台任务
如果一直有前台任务
- 后台任务可能一直得不到运行
- 后台任务优先级动态升高,但后台任务(用SJF调度)一旦执行,前台的响应时间…
- 前后台任务都用时间片,但又退化为了RR,后台任务的SJF如何体现?前台任务如何照顾?
还有很多问题…
- 我们怎么知道哪些是前台任务,哪些是后台任务,fork时告诉我们吗?
- gcc就一点不需要交互吗?Ctrl+C按键怎么工作? word就不会执行一段批处理吗?Ctrl+F按键?
- SJF中的短作业优先如何体现?如何判断作业的长度?这是未来的信息…
L15 一个实际的schedule函数
// linux-0.11/kernel/sched.cvoid schedule(void){int i,next,c;struct task_struct ** p;/* check alarm, wake up any interruptible tasks that have got a signal */for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)if (*p) {if ((*p)->alarm && (*p)->alarm < jiffies) {(*p)->signal |= (1<<(SIGALRM-1));(*p)->alarm = 0;}if (((*p)->signal & ~(_BLOCKABLE & (*p)->blocked)) &&(*p)->state==TASK_INTERRUPTIBLE)(*p)->state=TASK_RUNNING;}
Linux 0.11的调度函数schedule()
/* this is the scheduler proper: */while (1) {c = -1;next = 0;i = NR_TASKS;p = &task[NR_TASKS];while (--i) {if (!*--p)continue;if ((*p)->state == TASK_RUNNING && (*p)->counter > c)c = (*p)->counter, next = i;}if (c) break;for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)if (*p){(*p)->counter = ((*p)->counter >> 1) + (*p)->priority;}}switch_to(next);}
counter的作用: 时间片
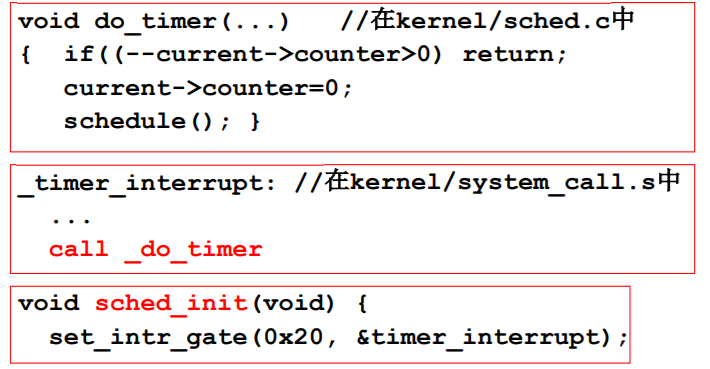
counter是典型的时间片,所以是轮转调度,保证了响应
counter的另一个作用: 优先级
while(--i){ if((*p->state == TASK_RUNNING&&(*p)->counter>c) c=(*p)->counter, next=i; }
找counter最大的任务调度,counter表示了优先级for(p=&LAST_TASK;p>&FIRST_TASK;--p)(*p)->counter=((*p)->counter>>1)+(*p)->priority;//(p)->priority 初值
counter代表的优先级可以动态调整
阻塞的进程再就绪以后优先级高于非阻塞进程,为什么?
*因为 会重复进入while循环 加上初值
进程为什么会阻塞? I/O,正是前台进程的特征
counter作用的整理
- counter保证了响应时间的界 c(t) = c(t-1)/2 + p c(0) = p c(∞) = ? < 2P
- 经过IO以后,counter就会变大;IO时间越长,counter越大(为什么? 被阻塞的多了),照顾了 IO进程,变相的照顾了前台进程
- 后台进程一直按照counter轮转,近似了SJF调度 (短作业的先轮转完)
- 每个进程只用维护一个counter变量,简单、高效
CPU调度: 一个简单的算法折中了 大多数任务的需求,这就是实际工作的schedule函数
L16 进程同步与信号量
进程合作:多进程共同完成一个任务
实例
司机 while (true){ 启动车辆; 正常运行; 到站停车;}
售票员 while (true){ 关门; 售票; 开门;} 实
等待信号

从纸上到实际:生产者-消费者实例
找到哪些地方要停,什么时候再走?
- 需要让“进程走走停停”来保证多进程合作的合理有序 这就是进程同步
共享数据
#define BUFFER_SIZE 10typedef struct { . . . } item;item buffer[BUFFER_SIZE];int in = out = counter = 0;
生产者进程
while (true) {while(counter== BUFFER_SIZE); //缓存区满,生产者要停;buffer[in] = item;in = (in + 1) % BUFFER_SIZE;counter++; //生产 发信号让消费者再走…}
消费者进程
while (true) {while(counter== 0); //缓存区空,消费者要停;item = buffer[out];out = (out + 1) % BUFFER_SIZE;counter--; //消费 发信号让生产者再走…}
只发信号还不能解决全部问题
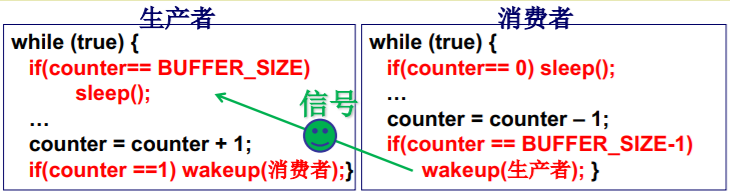
(1) 缓冲区满以后生产者P1生产一个item放入,会sleep 信号
(2) 又一个生产者P2生产一个item放入,会sleep
(3) 消费者C执行1次循环,counterBUFFER_SIZE-1, 发信号给P1,P1 wakeup
(4) 消费者C再执行1次循环,counterBUFFER_SIZE-2,P2不能被唤醒
从信号到信号量
- 不只是等待信号、发信号? 对应睡眠和唤醒!
- 还应该能记录一些信息
- 能记录有“2个进程等待”就可以了…
- (1) 缓冲区满,P1执行,P1 sleep,记录下1个进程等待
- (2) P2执行, P2 sleep,记录下2个进程等待
- (3) C执行1次循环,发现2个进程等待,wakeup 1个
- (4) C再执行1次循环,发现?个进程等待,再?
- (5) C再执行1次循环,怎么办? 此时再来P3怎么办?
- 什么是信号量?
- 记录一些信息(量),并根据这个信息决定睡眠还是唤醒(信号)。
信号量开始工作

正的——供小于求 负的——供大于求
什么是信号量? 信号量的定义…
- 信号量: 1965年,由荷兰学者Dijkstra提出的一种特殊整型变量,量用 来记录,信号用来sleep和wakeup
struct semaphore{int value; //记录资源个数PCB *queue;//记录等待在该信号量上的进程}P(semaphore s); //要消费资源 test一下V(semaphore s); //产生资源P(semaphore s){s.value--; //申请资源if(s.value < 0) { //没有sleep(s.queue); //阻塞}}V(semaphore s) //消费者调用{s.value++;if(s.value <= 0) { // p中睡眠的 swakeup(s.queue); //唤醒}}
P的名称来源于荷兰语的proberen,即test
V的名称也来源于荷兰语verhogen(increment) 增加
用信号量解生产者-消费者问题
用文件定义共享缓冲区
int fd = open(“buffer.txt”);write(fd, 0, sizeof(int)); //写inwrite(fd, 0, sizeof(int)); //写out
信号量的定义和初始化
semaphore full = 0;semaphore empty = BUFFER_SIZE;semaphore mutex = 1;
Producer(item) {P(empty);//判断有无要求P(mutex);//读入in;将item写入到in的位置上;V(mutex);V(full); //资源 + 1}Consumer() {P(full); //判断有无资源P(mutex);//读入out;从文件中的out位置读出到item;打印item;V(mutex);V(empty); //要求 + 1}
L17 信号量临界区保护
温故而知新:什么是信号量? 通过对这个量的访问和修改,让大家有序推进。
哪里还有问题吗?
共同修改信号量引出的问题
竞争条件(Race Condition)
- 竞争条件: 和调度有关的共享数据语义错误
错误由多个进程并发操作共享数据引起
错误和调度顺序有关,难于发现和调试
解决竞争条件的直观想法
- 在写共享变量empty 时阻止其他进程也访 问empty
原子操作

临界区(Critical Section)
- 临界区: 一次只允许一个进程进入的该进程的那几段代码中的一段
一个非常重要的工作: 找出进程 中的临界区代码
读写信号量的代码一 定是临界区…
临界区代码的保护原则
- 基本原则:
- 互斥进入: 如果一个进程在临界区中执行,则其他进程 不允许进入
- 这些进程间的约束关系称为互斥(mutual exclusion)
- 这保证了是临界区
- 好的临界区保护原则
- 有空让进: 若干进程要求进入空闲临界区时, 应尽快使一进程进入临界区
- 有限等待: 从进程发出进入请求到允许进入, 不能无限等待
进入临界区的一个尝试 - 轮换法

满足互斥进入要求
问题: P0完成后不能接着再次进入,尽管进程P1不在临界区…(不满足有空让进,P1不执行完P0不执行)
进入临界区的又一个尝试 - 标记法
买牛奶
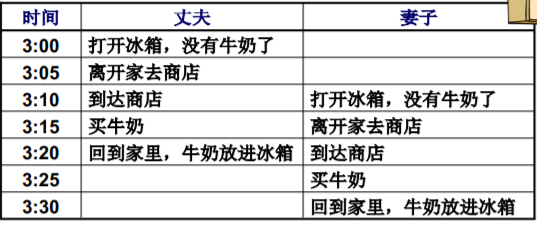
- 上面的轮换法类似于什么? 值日
- 更好的方法应该是立即去买,留一个便条

标记法能否解决问题? 无限等待
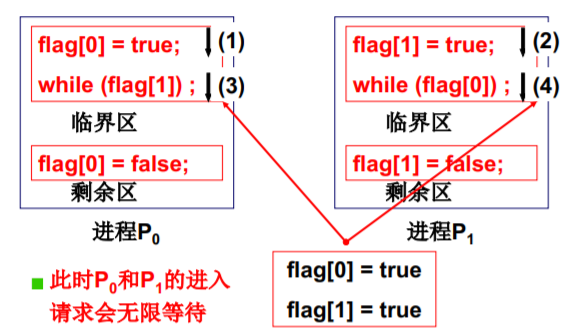
进入临界区的再一次尝试 - 非对称标记
- 带名字的便条 + 让一个人更加勤劳
丈 夫 是 那 个 更 勤 劳 的 人

- 关键: 选择一个进程进入,另一个进程循环等待
进入临界区Peterson算法
结合了标记和轮转两种思想

- 满足互斥进入: 如果两个进程都进入,则 flag[0]=flag[1]=true, turn01,矛盾!
- 满足有空让进: 如果进程P1不在临界区,则 flag[1]=false,或者turn=0, 都P0能进入!
- 满足有限等待: P0要求进入,flag[0]=true;后面的P1不可能一直进入,因为P1执行一次就会让turn=0。
多个进程怎么办? - 面包店算法 (软件)
仍然是标记和轮转的结合
- 如何轮转: 每个进程都获得一个序号, 序号最小的进入
- 如何标记: 进程离开时序号为0,不为0的 序号即标记
- 面包店: 每个进入商店的客户都获得一个号码,号码最小的先得到服务;号码相同时,名字靠前的先服务。
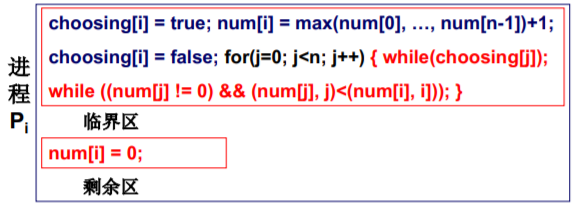
- 互斥进入: Pi 在临界区内,Pk试图进入,一定有(num[i], i)<(num[k],k),Pk循环等待。
- 有空让进: 如果没有进程在临界区中,最小序号的 进程一定能够进入。
- 有限等待: 离开临界区的进程再次进入一定排在最 后(FIFO),所以任一个想进入进程至多等n个进
一个显然的感觉是: 太复杂了,有 没有简单一些的…
临界区保护的另一类解法…
- 再想一下临界区:只允许一个进程进入,进入另一个进程意味着什么?
- 被调度: 另一个进程只有被调度才能执行,才可能进入临界区,如何阻止调度?
阻止中断 (中断寄存器)
只适合单CPU
- 被调度: 另一个进程只有被调度才能执行,才可能进入临界区,如何阻止调度?
什么时候不好使? 多CPU(多核)
临界区保护的硬件原子指令法
硬件对 mutex进行保护
方法:把修改mutex的方法 做成 一条指令 —— 原子指令 瞬间锁上
booleanTestAndSet(boolean &x){boolean rv = x;x = true;return rv;}while(TestAndSet(& lock)) ; //临界区lock = false; //剩余区
L18 信号量的代码实现
可以操刀了—从纸上到实际
if 选择最前面的

while + schdule 选择优先级最高的
从Linux 0.11那里学点东西…

L19 死锁处理
- 我们将这种多个进程由于互相等待对方持有的 资源而造成的谁都无法执行的情况叫死锁
死锁的成因
- 资源互斥使用,一旦占有别人无法使用
- 进程占有了一 些资源,又不释放,再去申请其他资源
- 各自占有的资源和互相申请的资源形成了环路等待
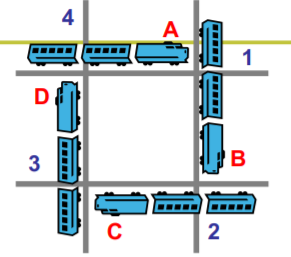
死锁的4个必要条件
- 互斥使用(Mutual exclusion) 资源的固有特性,如道口
- 不可抢占(No preemption) 资源只能自愿放弃,如车开走以后
- 请求和保持(Hold and wait) 进程必须占有资源,再去申请
- 循环等待(Circular wait) 在资源分配图中存在一个环路
死锁处理方法概述
- 死锁预防 “no smoking”,预防火灾
- 破坏死锁出现的条件
- 死锁避免 检测到煤气超标时,自动切断电源
- 检测每个资源请求,如果造成死锁就拒绝
- 死锁检测+恢复 发现火灾时,立刻拿起灭火器
- 检测到死锁出现时,让一些进程回滚,让出资源
- 死锁忽略 在太阳上可以对火灾全然不顾
- 就好像没有出现死锁一样
死锁预防的方法例子
- 在进程执行前,一次性申请所有需要的资源,不会占有资源再去申请其它资源
- 缺点1: 需要预知未来,编程困难
- 缺点2: 许多资源分配后很长时间后才使用,资源利用率低
- 对资源类型进行排序,资源申请必须按序进行,不会出现环路等待
- 缺点: 仍然造成资源浪费
问题:为什么使用这两种方法,一定不会死锁?
死锁避免: 判断此次请求是否引起死锁?
- 如果系统中的所有进程存在一个可完成的执行序列P1,…Pn,则称系统处于安全状态
安全序列: 上面的执行序列P1,…Pn 如何找?
找安全序列的银行家算法(Dijkstra提出)
int Available[1..m]; //每种资源剩余数量int Allocation[1..n,1..m]; //已分配资源数量int Need[1..n,1..m];//进程还需的各种资源数量int Work[1..m]; //工作向量bool Finish [1..n]; //进程是否结束
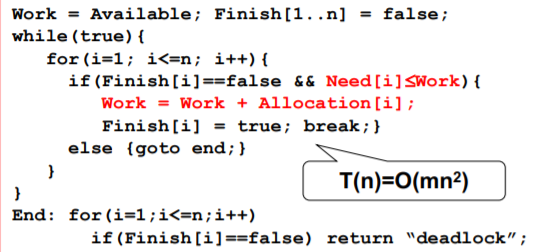
O(M * N^2) 成本太高
死锁避免之银行家算法实例
请求出现时: 首先假装分配,然后调用银行家算法(测试是否会造成死锁)
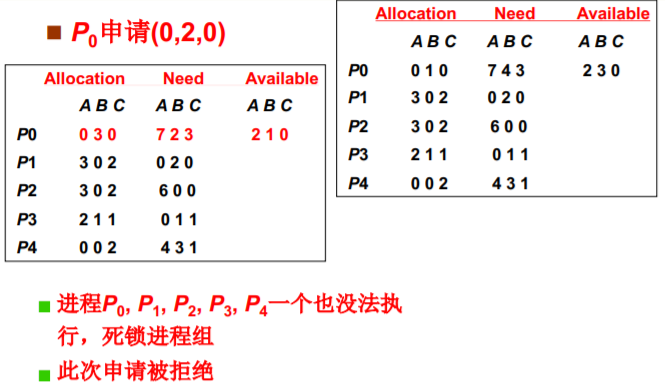
死锁检测+恢复: 发现问题再处理
- 基本原因: 每次申请都执行O(mn2),效率低。发现问题再处理
- 定时检测或者是发现资源利用率低时检测

- 选择哪些进程回滚? 优先级? 占用资源多的? …
- 如何实现回滚? 那些已经修改的文件怎么办
- 定时检测或者是发现资源利用率低时检测
死锁忽略的引出
- 死锁出现不是确定的,又可以用 重启动来处理死锁
- 有趣的是大多数非专门的操作系统都用它,如 UNIX,Linux,Windows
L20 内存使用与分段
如何让内存用起来?
仍然从计算机如何工作开始…
- 内存使用:将程序放到内存中,PC指向开始地址
首先程序进入内存
重定位: 修改程序中的地址(是相对地址)
40 —— 逻辑地址(相对地址)
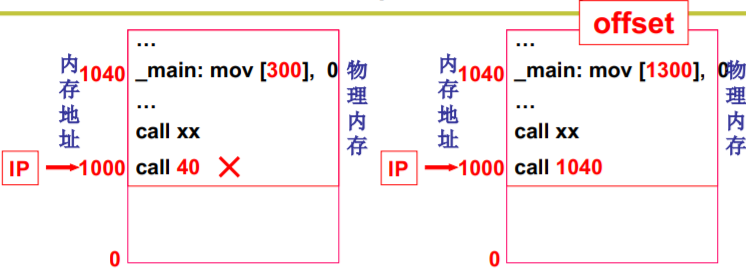
是么时候完成重定位? 编译时 载入时
- 编译时重定位的程序只能放在内存固定位置
- 载入时重定位的程序一旦载入内存就不能动了
程序载入后还需要移动…
- 一个重要概念: 交换(swap)
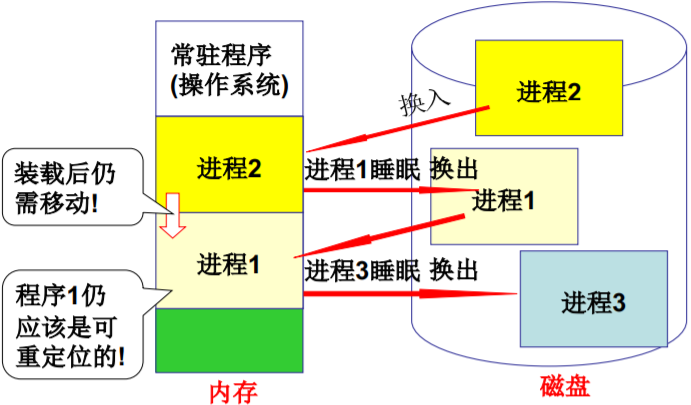
重定位最合适的时机 - 运行时重定位
- 在运行每条指令时才完成重定位
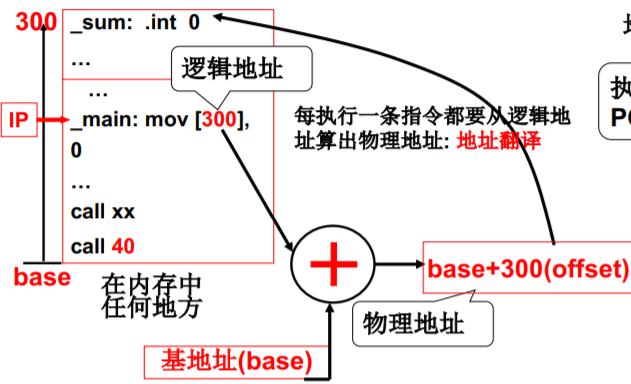
- 每个进程有各自的基地址,放在哪里?
- PCB
- 执行指令时第一步先从PCB中取出这个基地址
- 整理一下思路…
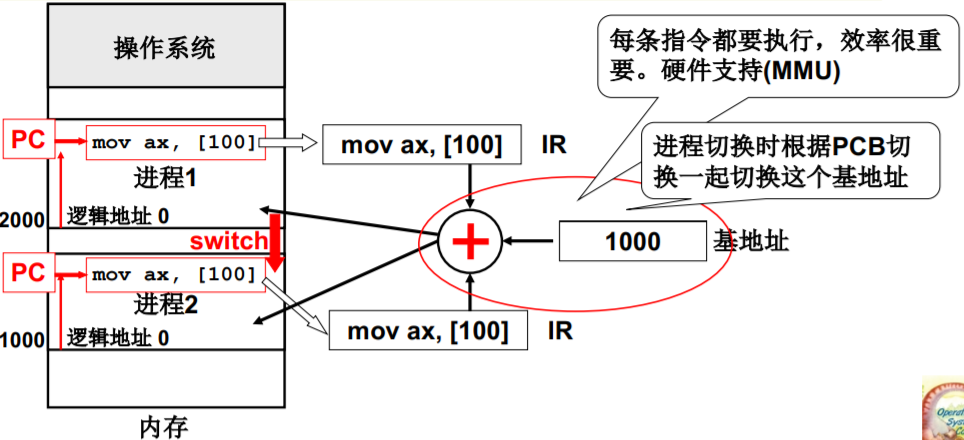
引入分段: 是将整个程序一起 载入内存中吗?
程序员眼中的程序
由若干部分(段)组成,
每个段有各自的特点、
用途:代码段只读,代码/数据段不会动态增长…
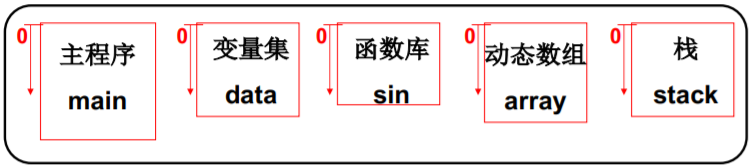
- 符合用户观点: 用户可独立考虑每个段(分治)
- 怎么定位具体指令(数据): <段号, 段内偏移> 如mov [es:bx], ax
不是将整个程序,是将各段分别放入内存
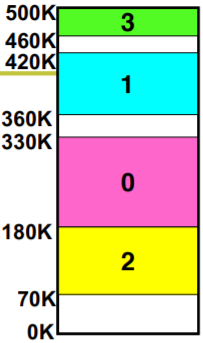
- 再进行运行时重定位会怎么样?
mov [DS:100], %eax jmpi 100, CS
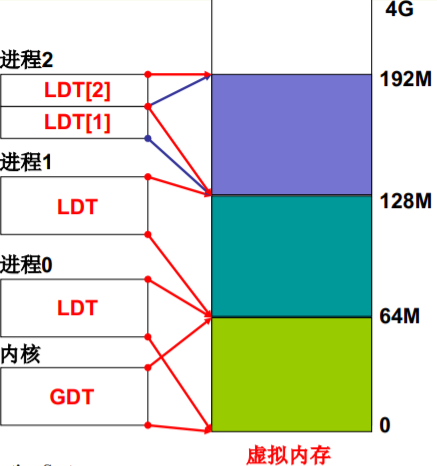
LTD表 (普通进程)
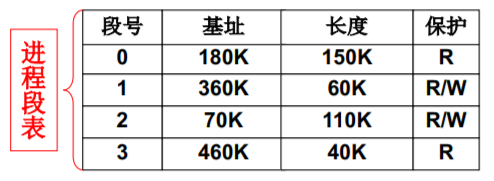
这个表似曾相识… 真正故事:GDT (操作系统) + LDT (普通进程)
LDTR
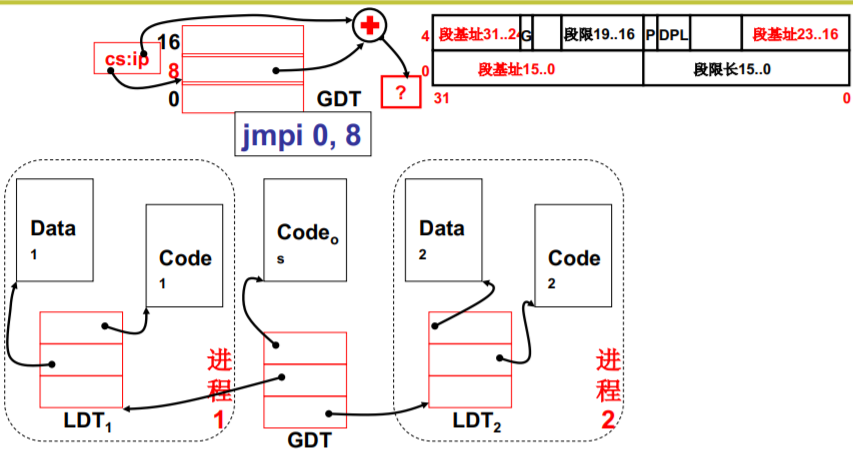
L21 内存分区与分页
- 程序分段 (编译阶段)
- 在内存中划分空闲区域
- 磁盘读写,找一段空闲分区读入内存 并用一块表将映射关系做好
接下来的问题是内存怎么割?
这样就可以将程序的各个段载入到相应的内 存分区中了
固定分区 与 可变分区
- 给你一个面包,一堆孩子来吃,怎么办?
- 等分,操作系统初始化时将内存等分成k个分区
- 但孩子有大有小,段也有大有小,需求不一定
可变分区的管理过程 — 核心数据结构
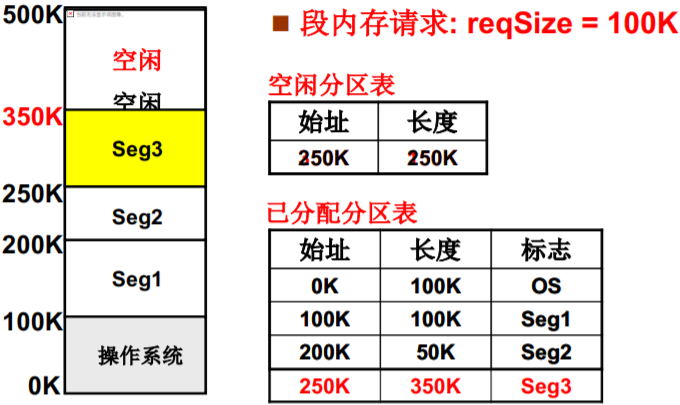
可变分区的管理—释放内存
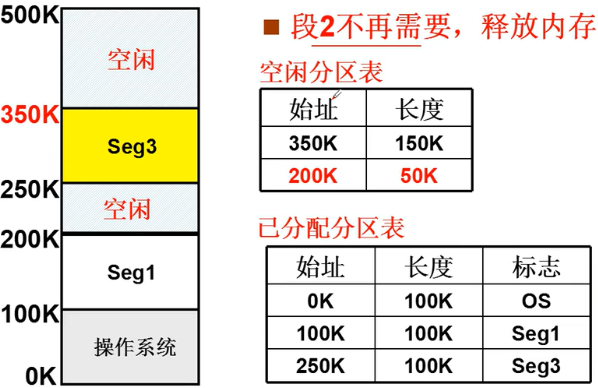
可变分区的管理—再次申请
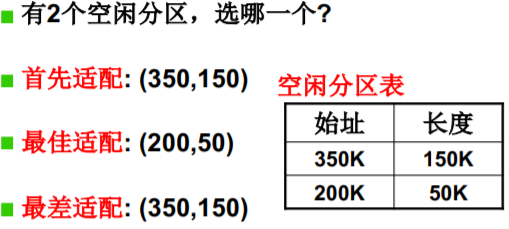
- 又一个段提出内存请求: reqSize=40K, 怎么办?
- 首先适配——均匀随机的选择 O(1)
最佳适配——与目标内存差距最小的选择 O(N)
最佳适配——与目标内存差距最大的选择 O(N)
引入分页: 解决内存分区导致的内存效率问题
可变分区造成的问题
- 发起请求reqSize=160K怎么办?
- 总空闲空间>160,但没有一个空闲分区>160,怎么办?
- 这就是内存碎片
- 将空闲分区合并,需要移动 1个段(复制内容):内存紧缩
- 内存紧缩需要花费大量时间,如果复制速度1M/1秒,
则1G内存 的紧缩时间为1000秒 接近17分钟 (相当于死机17分钟)
从连续到离散… (程序员角度要求分段,物理内存角度要求分页)
- 让给面包没有谁都不想要的碎末
- 将面包切成片,将内存分成页
- 针对每个段内存请求,系统一页一页的分配给这个段

问题:此时需要内存紧缩吗? 最大的内存浪费是多少?
不需要,每个段的最大内存浪费是一页
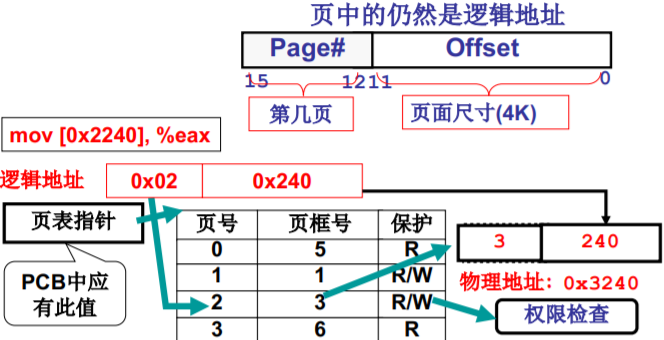
页已经载入了内存,接下来的事情…
- 页0放在页框5中,页0中的地址就需要重定位
- MMU内存管理单元
- 页表地址存储在PCB中,添加权限 R、W
L22 多级页表与快表
为了提高内存空间利用率,页应该小,但是页小了页表就大了…
页表会很大,页表放置就成了问题…
32位: 总空间[0,4G]
- 纸上和实际使用总是存在很大差别!
- 页面尺寸通常为4K,而地址是32位的,有2^20个页面 (32 - 12 = 20)
- 2^20个页表项都得放在内存中,需要4M内存;系统中并发10个进程,就需要 40M内存
- 实际上大部分逻辑地址根本不会用到
只存使用到的页面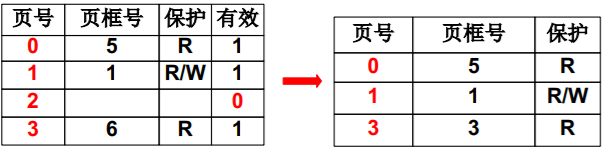
第一种尝试,只存放用到的页
- 很自然的想法:用到的逻辑页才有页表项
- 但页表中的页号不连续,就需要比较、查找,折半
log(2^20)=20,20次什么?
用4M,4M/4K = 1000,用一次查1000次(顺序查找)
没执行一次指令,访问内存500次(平均)
提高方法:折半查找 访问内存10次——仍然慢 - 32位地址空间+ 4K页面+页号必须连续 => 2^20个页表项 => 大页表占用内存,造成浪费
- 但页表中的页号不连续,就需要比较、查找,折半
既要连续又要让页表占用内存少,怎么办?
用书的章目录和节目录来类比思考…
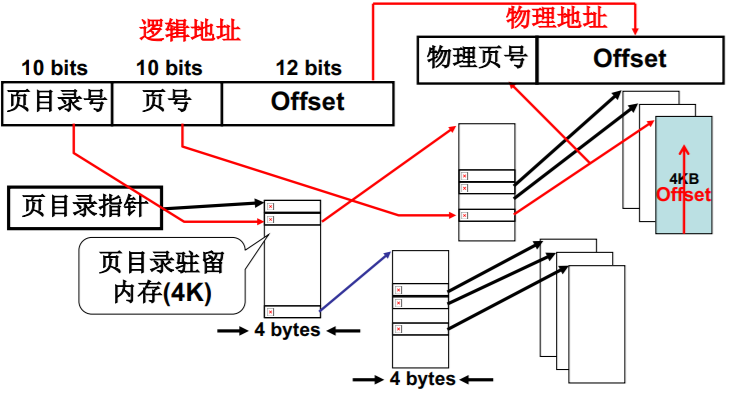
第二种尝试:多级页表,即页目录表(章)+页表(节)
页目录表(章)+页表(节)
既是连续的,又保证了放在内存中的页表项少了许多
210个目录项 * 4字节地址 = 4K,总共需要 16K<<4M
访问 3 * 4M的内存 ,额外开销为16k
页目录号 + 页号 + 页内偏移
多级页表提高了空间效率,但在时间上? TLB
- 多级页表增加了访存的次数,尤其是64位系统 (上图中的32位增加了一次)
- TLB是一组相联快速存储,是寄存器 TLB (快表)
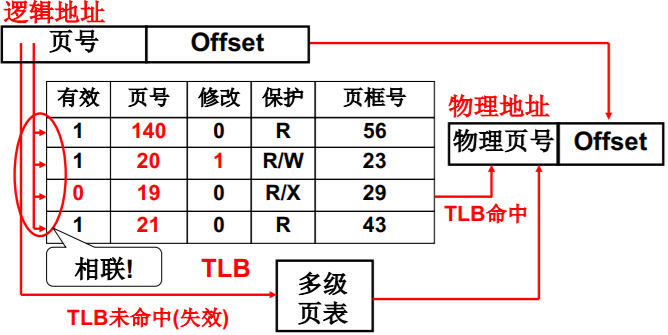
TLB得以发挥作用的原因
- TLB命中时效率会很高,未命中时效率降低
未命中时 假设为2MA
- 要想真正实现“近似访存1次” ,
TLB的命中率应该很高 - TLB越大越好,但TLB很贵,通常只有[64, 1024]
为什么TLB条目数可以在64-1024之间?
- 相比220个页,64很小,为什么TLB就能起作用?
- 程序的地址访问存在局部性
- 空间局部性(Locality in Space)
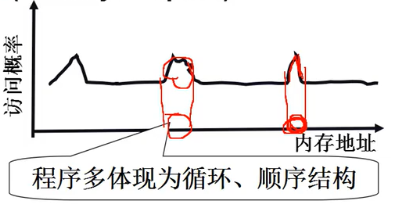
- 计算机系统设计时应该充分利用这一局部性
L23 段页结合的实际内存管理
段、页结合: 程序员希望用段, 物理内存希望用页,所以…
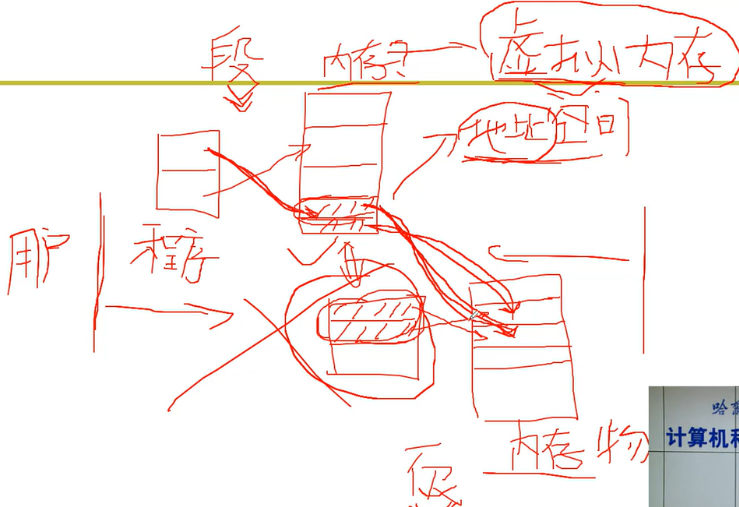
虚拟内存 将 页 和 段 的功能 融合在一起
段、页同时存在:段面向用户/页面向硬件
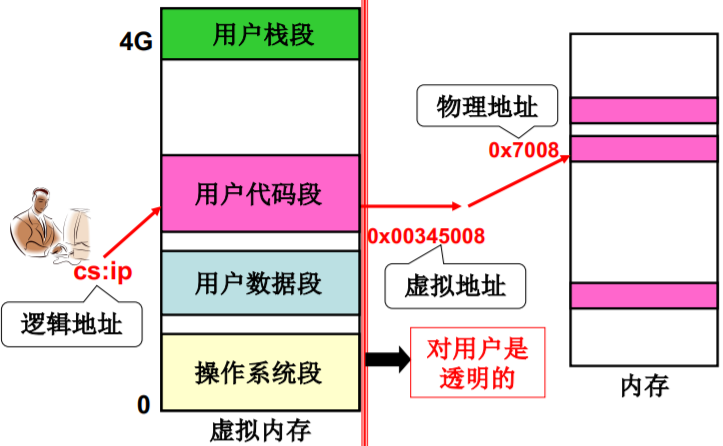
虚拟内存 对用户是 透明的
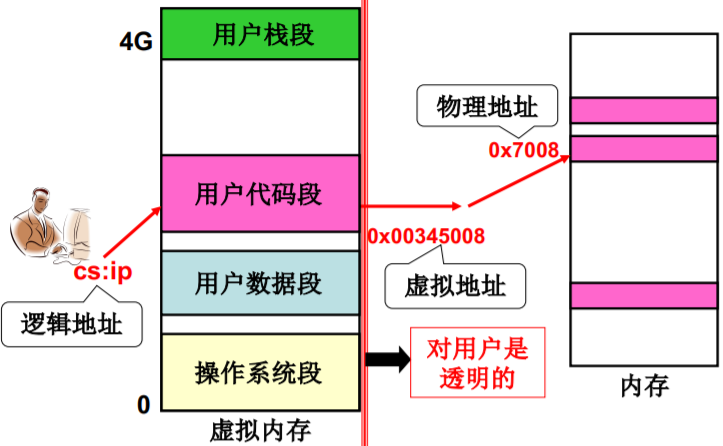
段、页同时存在是的重定位(地址翻译)
逻辑地址 -> 虚拟地址 -> 物理地址
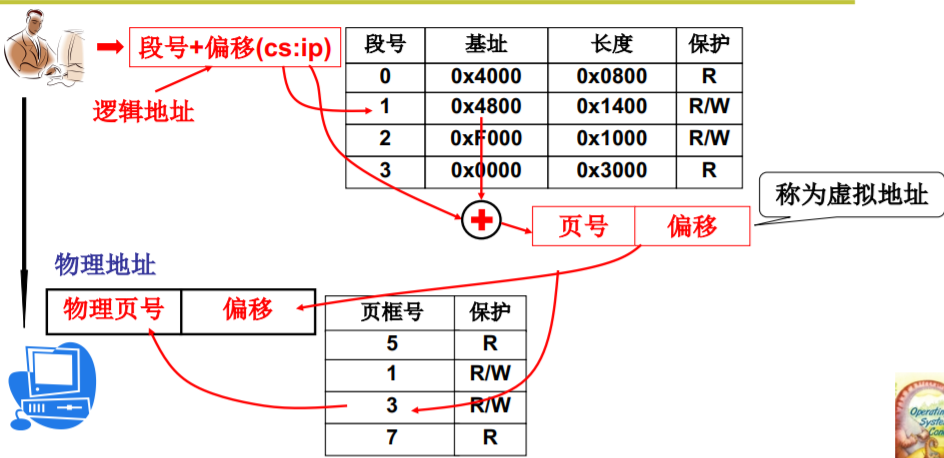
一个实际的段、页式内存管理
这个故事从哪里开始
- 内存管理核心就是内存分配,所以从程序放入内存、使用内存开始…
- 分配段、建段表;分配页、建页表
- 进程带动内存使用的图谱
- 从进程fork中的内存分配开始…
段、页式内存下程序如何载入内存?
一共五步
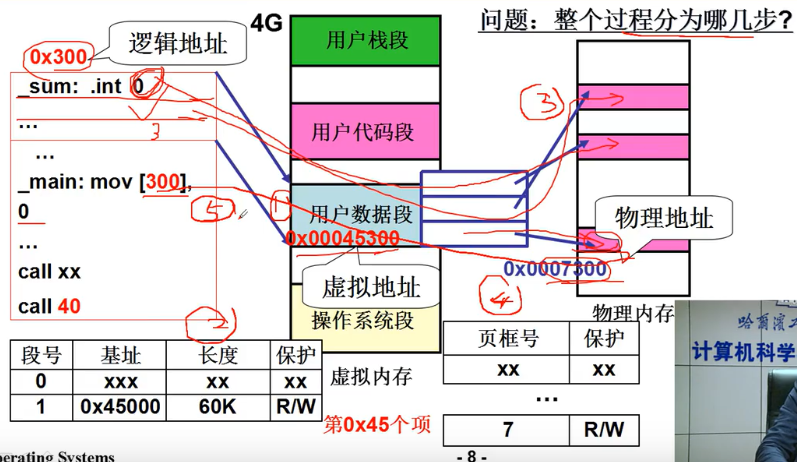
故事从fork()开始
分配虚存、建段表
fork() -> sys_fork -> copy_process的路都已经走过了
在linux/kernel/fork.c中int copy_process(int nr, long ebp,...){ ...copy_mem(nr, p); ...
现在开始分析当时那个神秘的copy_mem了
int copy_mem(int nr, task_struct *p){unsigned long new_data_base;new_data_base=nr*0x4000000; //64M*nr 分割虚拟内存set_base(p->ldt[1],new_data_base); // 5~6行 完成 对段和表的填写set_base(p->ldt[2],new_data_base);...
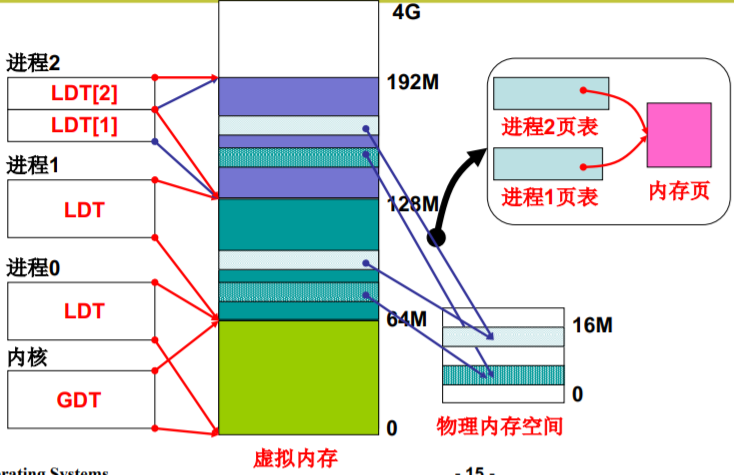
进程0、进程1、进程2的虚拟地址
- 每个进程的代码段、数据段都是一个段
- 每个进程占64M虚拟地址空间,互不重叠 (linux0.11 较为简单,实现的是互不重叠,意味着可以不用切换页,直接页内偏移)
问题:这意味着什么样的简化?
接下来应该是什么了?
分配内存、建页表
int copy_mem(int nr, task_struct *p) //不用分配内存,用父进程{ unsigned long old_data_base;old_data_base=get_base(current->ldt[2]);copy_page_tables(old_data_base,new_data_base,data_limit);
int copy_page_tables(unsigned long from,unsigned long to, long size) //建页表{ from_dir = (unsigned long *)((from>>20)&0xffc);to_dir = (unsigned long *)((to>>20)&0xffc);size = (unsigned long)(size+0x3fffff)>>22;for(; size-->0; from_dir++, to_dir++){from_page_table=(0xfffff000&*from_dir);to_page_table=get_free_page();
这里的from_dir,to_dir是什么?
from_dir = (unsigned long *)((from>>20)&0xffc);to_dir = (unsigned long *)((to>>20)&0xffc);size = (unsigned long)(size+0x3fffff)>>22;
- from是?
32位虚拟地址,这个地址的格式是否还记得?
为什么不是右移20位
from>>22得到目录项编号 (from>>22)4每项4字节
*&0xffc 把最后两位清为0 - from_page_table=(0xfffff000&*from_dir);
取页号
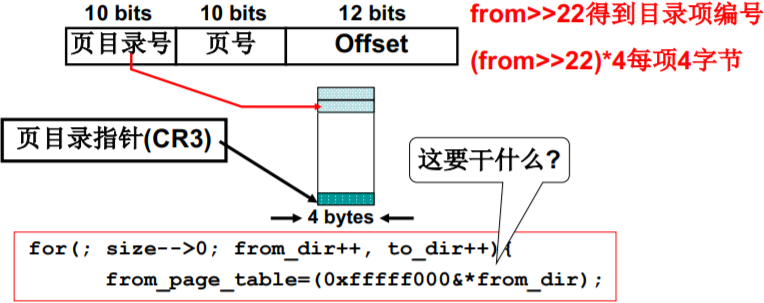
from_page_table与to_page_table?
for(; size-->0; from_dir++, to_dir++){to_page_table=get_free_page(); //建立映射 虚拟地址——物理地址*to_dir=((unsigned long)to_page_table)|7; //赋予页目录的地址
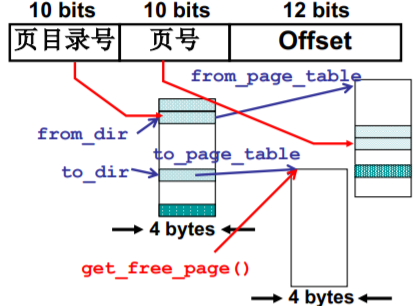
接下来干什么应该猜也猜的到…
开始对内存的拷贝
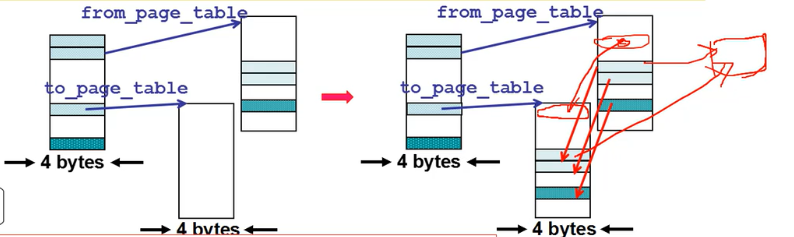
for(;nr-->0;from_page_table++,to_page_table++){this_page = *from_page_table;this_page&=~2;//只读 因为是共享的,所以是只读的, &~2——把最后两位清0*to_page_table=this_page;*from_page_table=this_page;this_page -= LOW_MEM; this_page >>= 12;mem_map[this_page]++; //共享 引用+1 }
程序、虚拟内存+物理内存的样子
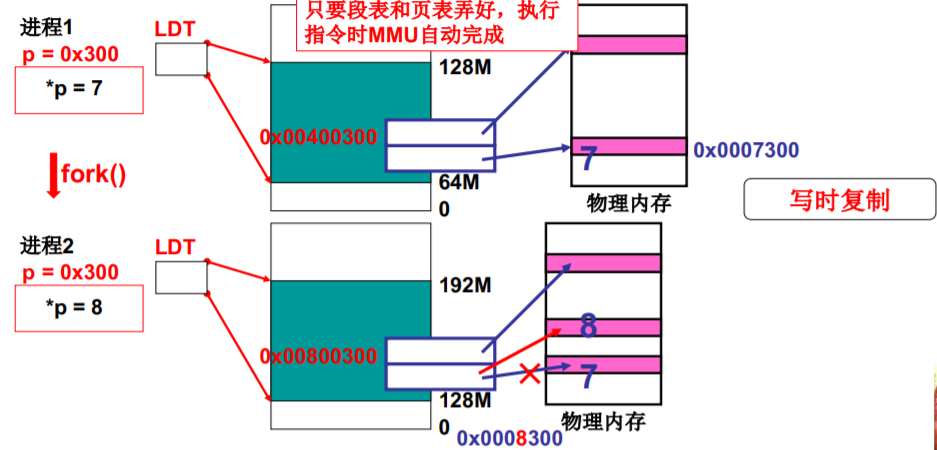
第五步(总结)
第五步 最终实现对物理内存的读写
p=7? 父进程p=7、子进程*p=8?
如何消除父子进程的相互影响
子进程对父进程 只读,如要写,自己开辟内存写
L24 内存换入-请求调页
Swap in
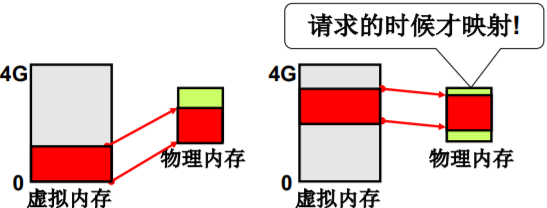
用户眼里的内存!
- *4GB(大且规整)的“内存” ,可供用户使用, 如char p, p=3G,实际上就是用地址
- 用户可随意使用该“内存” ,就象单独拥有4G内存
- 这个“内存”怎么映射到物理内存,用户全然不知
用换入、换出实现“大内存”
- 左边4G,右边1G怎么办?
- 访问p(=0G - 1G)时,将这部分映射到物理内存
- 再访问p(=3G - 4G)时,再映射这一部分
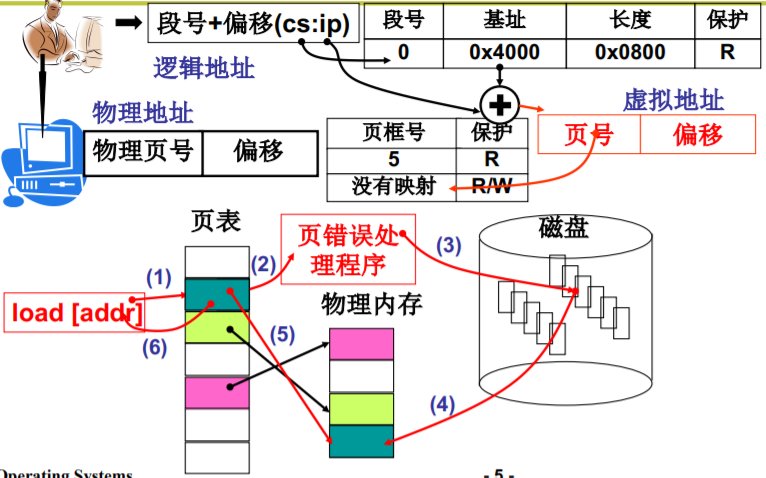
请求调页
缺页的情况
一个实际系统的请求调页
- 这个故事从哪里开始?
- 请求调页,当然从缺页中断开始

void trap_init(void){ set_trap_gate(14, &page_fault); }
#define set_trap_gate(n, addr) \_set_gate(&idt[n], 15, 0, addr);
处理中断page fault

do_no_page
//在linux/mm/memory.c中void do_no_page(unsigned long error_code,unsigned long address){ address&=0xfffff000; //页面地址tmp=address–current->start_code; //页面对应的偏移if(!current->executable||tmp>=current->end_data){get_empty_page(address); return; }page=get_free_page();bread_page(page, current->executable->i_dev, nr); //读文件系统put_page(page, address); //建立虚拟地址和页的映射
void get_empty_page(unsigned long address){ unsigned long tmp = get_free_page();put_page(tmp, address);}
put_page
//在linux/mm/memory.c中unsigned long put_page(unsigned long page, //物理地址unsigned long address){ unsigned long tmp, *page_table;page_table=(unsigned long *)((address>>20)&ffc); //页目录项if((*page_table)&1)page_table=(unsigned long*)(0xfffff000&*page_table);else{tmp=get_free_page();*page_table=tmp|7;page_table=(unsigned long*)tmp;}page_table[(address>>12)&0x3ff] = page|7; //物理页放在page_tablereturn page;}
L25 内存换出
Swap out
get_free_page? 还是…
page=get_free_page(); //申请空闲页bread_page(page, current->executable->i_dev, nr); //从磁盘读入
- 并不能总是获得新的页,内存是有限的
- 需要选择一页淘汰,换出到磁盘,选择哪一页?
- FIFO,最容易想到,但如果刚换入的页马上 又要换出怎么办?
- 有没有最优的淘汰方法? MIN
- 最优淘汰方法能不能实现,是否需要近似? LRU
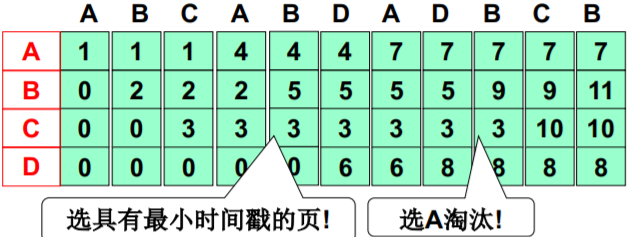
FIFO页面置换
- 一实例: 分配了3个页框(frame),页面引用序列为 A B C A B D A D B C B
- 评价准则: 缺页次数;本实例,FIFO导致7次缺页
MIN页面置换
- MIN算法: 选最远 (往后看) 将使用的页淘汰,是最优方案
继续上面的实例: (3frame)A B C A B D A D B C B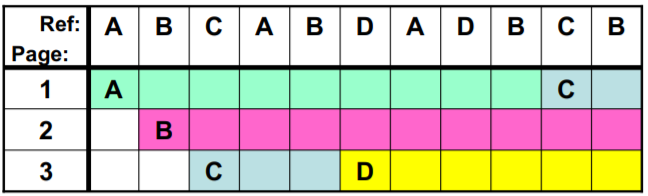
- 本实例,MIN导致5次缺页
- 可惜,MIN需要知道将来发生的事… 怎么办?
LRU页面置换
- 用过去的历史 (往前看) 预测将来。
LRU算法: 选最近最长一段时间没有使用的页淘汰(最近最少使用)。 对局部性规律的一种认识
继续上面的实例: (3frame)A B C A B D A D B C B - 和MIN完全一样
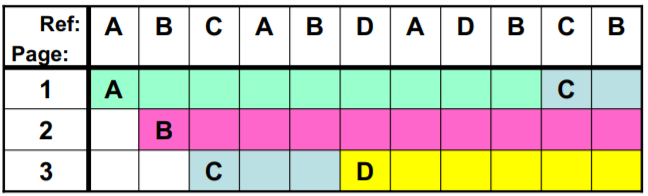
- 本实例,LRU也导致5次缺页
- LRU是公认的很好的页置换算法,怎么实现?
LRU的准确实现,用时间戳
- 每页维护一个时间戳(time stamp)
- 继续上面的实例: (3frame)A B C A B D A D B C B
- 每次地址访问都需要修改时间戳,需维护一个全局时钟,需找到最小值 … 实现代价较大
1、找到最小值 2、更新时间戳 (+1) 3、解决时间挫溢出的情况 4、赋值
- 继续上面的实例: (3frame)A B C A B D A D B C B
LRU准确实现,用页码栈
- 维护一个页码栈
- 继续上面的实例: (3frame)A B C A B D A D B C B
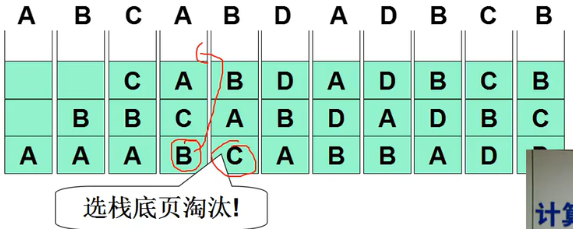
- 每次地址访问都需要修改栈 (总的修改10次左右栈指针) …
实现代价仍然较大 -> LRU准确实现用的少
- 继续上面的实例: (3frame)A B C A B D A D B C B
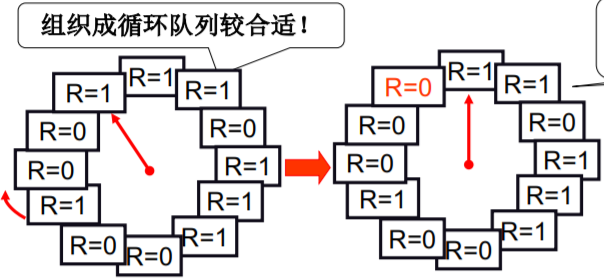
Clock算法
Clock算法 (最近没有使用 近似 之前最远使用)——(LRU近似实现 - 将时间计数变为是和否)
SCR这一实现方法称为 Clock Algorithm 再给一次机会(Second Chance Replacement)
- 每个页加一个引用位(reference bit)
- 每次访问一页时,硬件自动设置该位 (设置为 1)
- 选择淘汰页:扫描该位,是1时清0,并继续扫描;是0时淘汰该页
Clock算法的分析与改造
- 如果缺页很少,会? 所有的R=1
- hand scan一圈后淘汰当前页,将调入页插入hand位置,hand前移一位
退化为FIFO! - 原因:记录了太长的历史信息… 怎么办?
- 定时清除R位… (再来一个扫描指针!)
- 用来清除R位,移动速度要快! 快指针
- 用来选择淘汰页,移动速度慢! 慢指针
- hand scan一圈后淘汰当前页,将调入页插入hand位置,hand前移一位
置换策略有了,还需要解决一个问题
- 给进程分配多少页框(帧frame) (不够所有进程用时)
- 分配的多,请求调页导致的内存高效
- 利用就没用了! 那分配的太少呢?
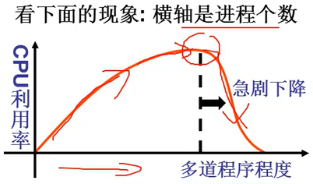
- 称这一现象为颠簸(thrashing)
解释: 系统内进程增多 -> 每个进程的缺页率增大 -> 缺页率增大到一定程度,进程总等待调页完成 ->
CPU利用率降低 -> 进程进一步增多,缺页率更大 …
总结(swap in swap out swap分区管理)
L26 I/O与显示器
让外设工作起来
- CPU向控制器中的寄存器 读写数据
- 控制器完成真正的工作, 并向CPU发中断信号
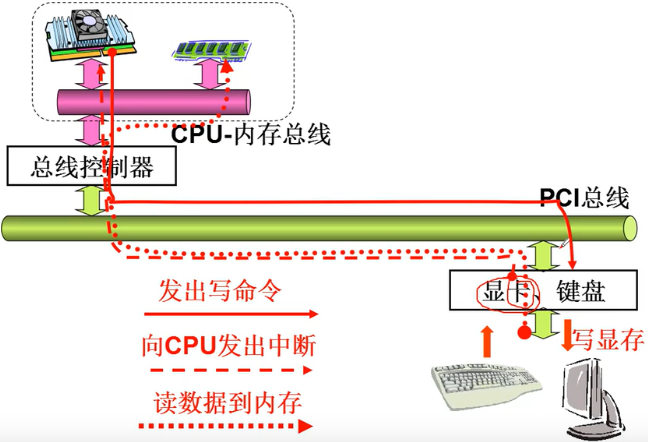
向设备控制器的寄存器写不就可以了吗?
- 需要查寄存器地址、内容的格式和语义…
- 操作系统要给用户提供一个简单 视图—文件视图,这样方便
外设驱动的3件事情
- 发出out指令(最核心的指令)
- 形成文件视图
- 形成中断处理
一段操纵外设的程序
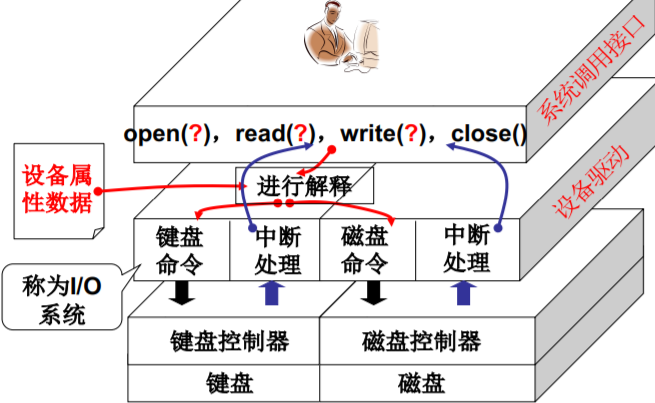
int fd = open(“/dev/xxx”);for (int i = 0; i < 10; i++) {write(fd,i,sizeof(int));}close(fd);
(1) 不论什么设备都是open, read, write, close 操作系统为用户提供统一的接口!
(2) 不同的设备对应不同的设备文件(/dev/xxx) 根据设备文件找到控制器的地址、内容格式等等!
一个统一的视图-文件视图
操作系统两大视图之一
概念有了,开始给显示器输出…
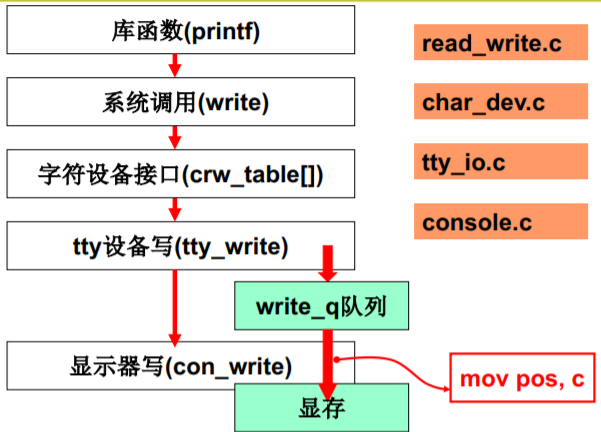
从哪里开始这个故事呢?
printf(“Host Name: %s”, name);printf库展开的部分我们已经知道:先创建缓存buf将格式化输出都写到那里, 然后再write(1,buf,…)
在linux/fs/read_write.c中int sys_write(unsigned int fd, char *buf,int count) //fd是找到file的索引!{ struct file* file;file = current->filp[fd]; //current不陌生吧,进程带动整个系统的视图inode = file->f_inode;
file的目的是得到inode,显示器信息应该就在这里
fd=1的filp从哪里来?
因为是被current指向,所以是从fork中来
int copy_process(...){*p = *current;for (i=0; i<NR_OPEN;i++)if ((f=p->filp[i])) f->f_count++;
- 显然是拷贝来的,那么是谁一开始打开的? shell进程启动了whoami命令,shell是其父进程
``` void main(void) { if(!fork()){ init(); }
void init(void) {open(“dev/tty0”,O_RDWR,0);dup(0);dup(0); //0 1 2open系统调用完成了什么? execve(“/bin/sh”,argv,envp)}
<a name="e72dcd6e"></a>## open系统调用完成了什么?
在linux/fs/open.c中 int sys_open(const char* filename, int flag) //解析目录,找到inode! { i=open_namei(filename,flag,&inode); cuurent->filp[fd]=f; //第一个空闲的fd f->f_mode=inode->i_mode; f->f_inode=inode; //存储下inode的信息 f->f_count=1; return fd; }
- 核心就是建立这样一个链<a name="077a7802"></a>## 准备好了,真正向屏幕输出!- 继续sys_write!
在linux/fs/read_write.c中 int sys_write(unsigned int fd, char *buf,int cnt) { inode = file->f_inode; if(S_ISCHR(inode->i_mode)) return rw_char(WRITE,inode->i_zone[0], buf,cnt); ///dev/tty0的inode中的信息是字符设备 …
- 转到rw_char
在linux/fs/char_dev.c中 int rw_char(int rw, int dev, char *buf, int cnt) { crw_ptr call_addr=crw_table[MAJOR(dev)]; call_addr(rw, dev, buf, cnt); …}
- 看看crw_table!
static crw_ptr crw_table[]={…,rw_ttyx,}; typedef (crw_ptr)(int rw, unsigned minor, char buf, int count)
```static int rw_ttyx(int rw, unsigned minor, char*buf, int count){ return ((rw==READ)? tty_read(minor,buf):tty_write(minor,buf));}
再转到tty_write! //实现输出的核心函数
在linux/kernel/tty_io.c中int tty_write(unsigned channel,char *buf,int nr){ struct tty_struct *tty;tty=channel+tty_table; //可以猜测:输出就是放入队列! 写到缓冲区sleep_if_full(&tty->write_q);...}
看看tty->write
在include/linux/tty.h中struct tty_struct{ void (*write)(struct tty_struct*tty); struct tty_queue read_q, write_q; }
需要看tty_struct结构的初始化!
struct tty_struct tty_table[] = {{con_write,{0,0,0,0,””},{0,0,0,0,””}},{},…};
到了con_write,真正写显示器
在linux/kernel/chr_drv/console.c中void con_write(struct tty_struct *tty){ GETCH(tty->write_q,c);if(c>31&&c<127){__asm__(“movb _attr,%%ah\n\t” //本质上是 out“movw %%ax,%1\n\t”::”a”(c),”m”(*(short*)pos):”ax”); pos+=2;}
只有一句话:mov pos
- 完成显示中最核心的秘密就是 mov pos, c

- pos的修改: pos+=2 为什么加2? 屏幕上的一个字符在显存中除了字符本身还应该有字符的属性(如颜色等)
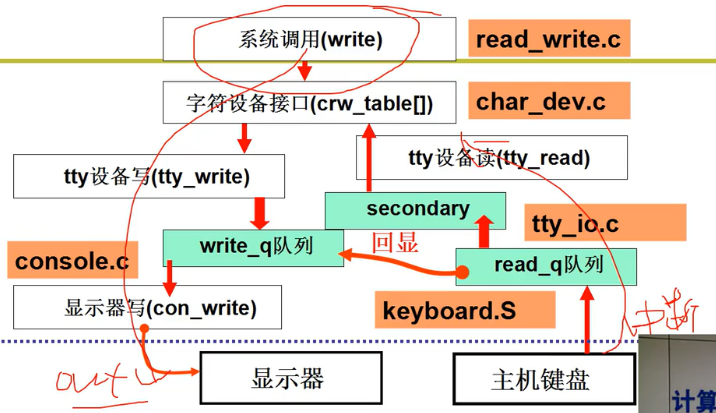
printf的整个过程
将mov pos, c 指令包装成 统一的文件view
并利用了缓冲技术和 消费者和生产者同步的机制
L27 键盘
终端设备包括显示器和键盘
- out指令 发 命令
- 形成统一的文件视图
- 进行中断处理
关于键盘的故事从哪里开始?
- 如何使用键盘?
- 对于使用者(人): 敲键盘、看结果
- 对于操作系统: “等着”你敲键盘,敲了就中断
- 所以故事该从键盘中断开始,从中断初始化开始…
void con_init(void) //应为键盘也是console的一部分{ set_trap_gate(0x21, &keyboard_interrupt); }
在kernel/chr_drv/keyboard.S中.globl _keyboard_interrupt_keyboard_interrupt:inb $0x60,%al //从端口0x60读扫描码 最核心的指令call key_table(,%eax,4) //调用key_table+eax*4... push $0 call _do_tty_interrupt
- 处理扫描码key_table+eax*4

- 从key_map中取出ASCII码
- put_queue将ASCII码放到? con.read_q
键盘处理…
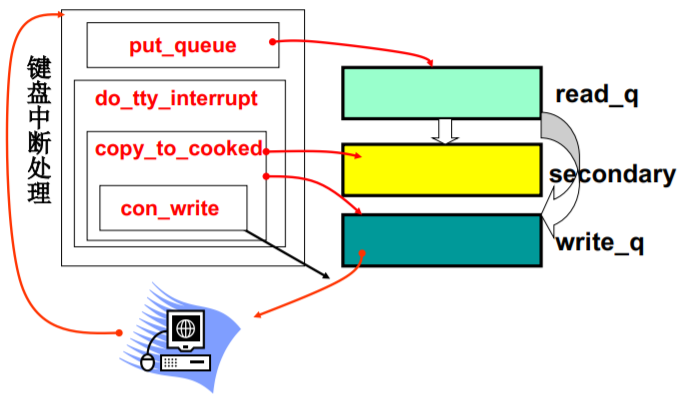
总结
L28 生磁盘的使用
抽象层次比键盘和显示器的多
仍然从硬件开始…
- CPU向磁盘控制器中的寄存器读写数据
- 磁盘控制器完成真正的工 作,并向CPU发中断信号
使用磁盘从认识磁盘开始
- 画一个示意图:
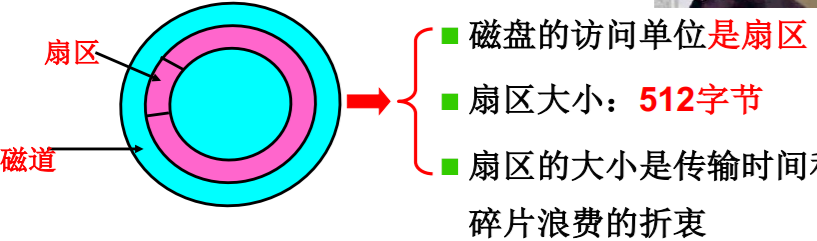
- 看看俯视图:
磁盘的I/O过程
- 仔细想想磁盘如何读/写1一 个字节? 读——磁生电 写——电生磁
- 磁盘I/O过程: 控制器->寻道->旋转->传输 (读/写) !
最直接的使用磁盘
- 只要往控制器中写 柱面 C、磁头 H、扇区 S、缓存位置 (通过指令发送)

void do_hd_request(void){ ...hd_out(dev,nsect,sec,head,cyl,WIN_WRITE,...);port_write(HD_DATA,CURRENT->buffer,256);}void hd_out(drive, nsect, sec, head, cyl, cmd...){ port = HD_DATA; //数据寄存器端口(0x1f0)outb_p(nsect,++port); outb_p(sect,++port);outb_p(cyl,++port); outb_port(cyl>>8,++port);outb_p(0xA0|(drive<<4)|head, ++port);outb_p(cmd, ++port); }
通过盘块号读写磁盘(一层抽象)
- 磁盘驱动负责从block计算出cyl,head,sec(CHS)
问题:如何编址?为什么这样编址? 希望 block相邻的盘块可以快速读出
磁盘访问时间 = 写入控制器时间 +
寻道时间(12 ms to 8 ms) + 旋转时间(4 ms) + 传输时间(约0.3ms)
减少寻道次数
从CHS到扇区号,从扇区到盘块
问题:C、H、S得到的扇区号是? C (Heads Sectors) + H * Sectors + S
磁盘访问时间 = 写入控制器时间 + 寻道时间 + 旋转时间 + 传输时间 (共计约10ms)
一次多读几个扇区
- 从扇区到盘块: (空间换时间) 可以每次读写一个盘块
每次读写1 K: 碎片0.5K;读写速度100K/秒;
每次读写1 M:碎片0.5M;读写速度约40M/秒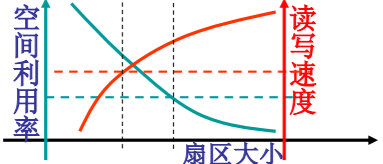
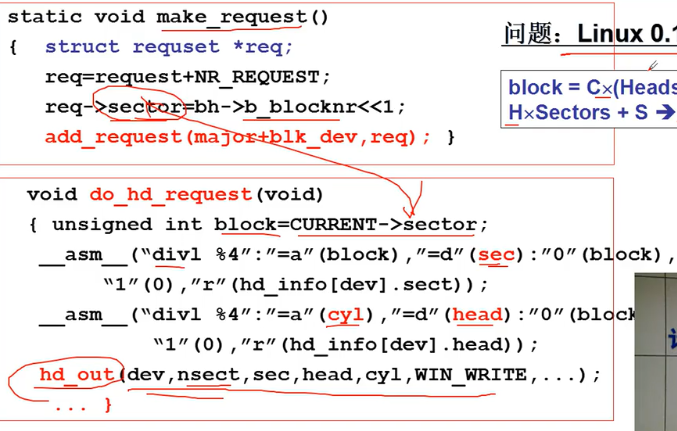
再接着使用磁盘:程序输出block
计算并输出 block = C(HeadsSectors) + H*Sectors + S -> S = block%Sectors
问题:Linux 0.11盘块多大?
两个扇区 req->sector=bh->b_blocknr<<1;
多个进程通过队列使用磁盘(第二层抽象)
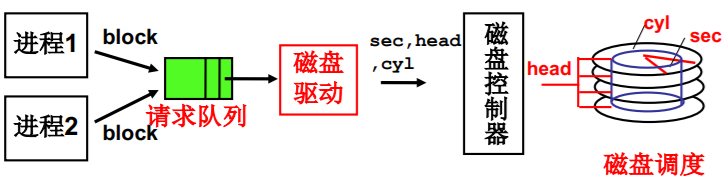
- 多个磁盘访问请求出现在请求队列怎么办?
- 调度的目标是什么? 调度时主要考察什么?
目标当然是平均访问延迟小!
寻道时间是主要矛盾! - 给调度算法,仍然从FCFS开始…
FCFS磁盘调度算法
- 最直观、最公平的调度: 顺序调度
- 一个实例: 磁头开始位置=53; 请求队列=98, 183, 37, 122, 14, 124, 65, 67
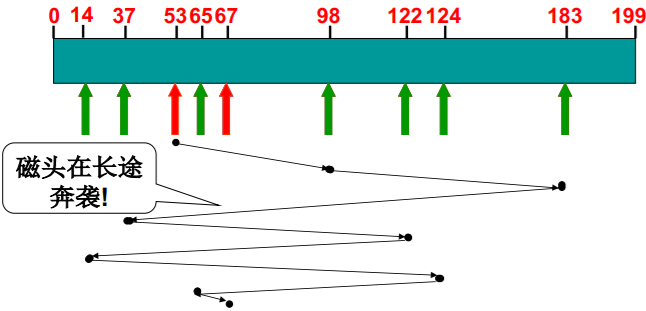
- FCFS: 磁头共 移动640磁道!
- 在移动过程中把经过 的请求处理了!
SSTF磁盘调度
- Shortest-seek-time First: 短寻道优先
- 继续该实例: 磁头开始位置=53; 请求队列=98, 183, 37, 122, 14, 124, 65, 67
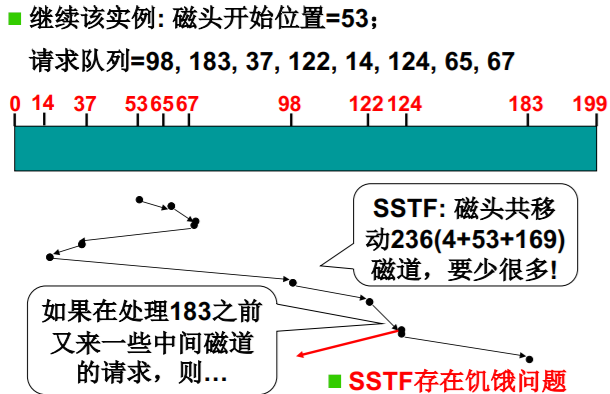
容易在局部晃荡,忽略边缘请求
SCAN磁盘调度
- SSTF+中途不回折:每个请求都有处理机会
- 继续该实例: 磁头开始位置=53; 请求队列=98, 183, 37, 122, 14, 124, 65, 67
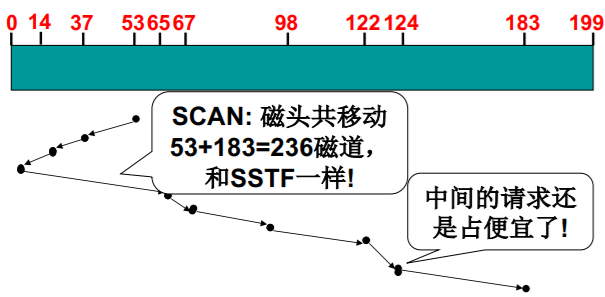
中间总是较为优先
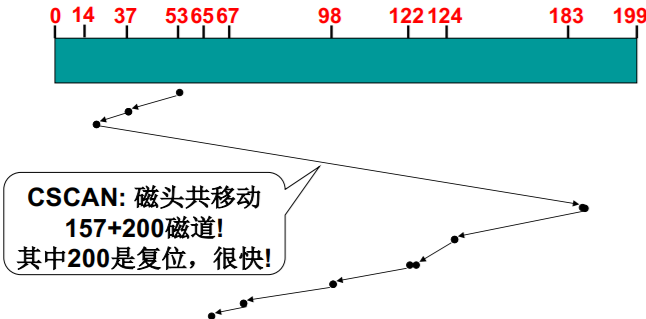
C-SCAN磁盘调度(电梯算法)
- SCAN+直接移到另一端 (复位) :两端请求都能很快处理 复位
- 继续该实例: 磁头开始位置=53; 请求队列=98, 183, 37, 122, 14, 124, 65, 67
多个进程共同使用磁盘
static void make_request(){ ...req->sector=bh->b_blocknr<<1;add_request(major+blk_dev,req); }
static void add_request(struct blk_dev_struct *dev,struct request *req){ struct requset *tmp=dev->current_request;req->next=NULL; cli(); //关中断(互斥)for(;tmp->next;tmp=tmp->next)if((IN_ORDER(tmp,req)||!IN_ORDER(tmp,tmp->next))&&IN_ORDER(req,tmp->next)) break;req->next=tmp->next; tmp->next=req; sti();}
#define IN_ORDER(s1, s2) \ //对柱面进行排序((s1)->dev<(s2)->dev)||((s1)->dev == (s2)->dev\&& (s1)->sector<(s2)->sector))
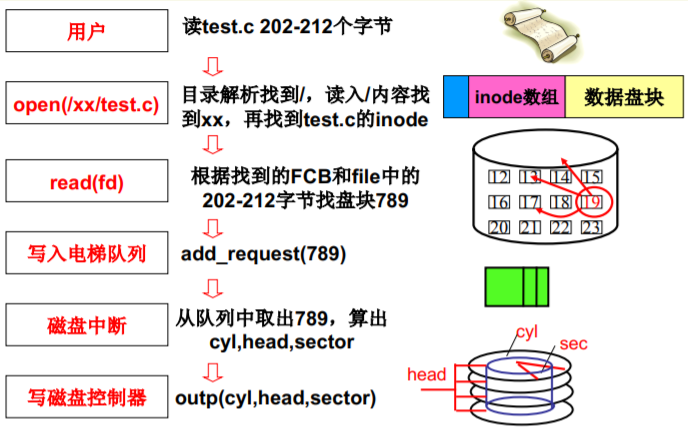
生磁盘(raw disk)的使用整理
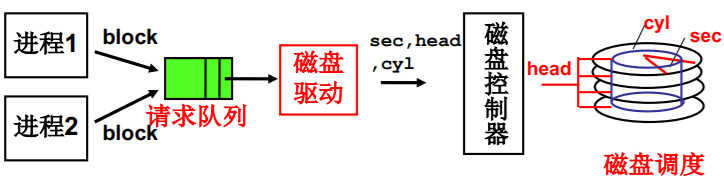
(1) 进程“得到盘块号” ,算出扇区号(sector)
(2) 用扇区号make req (本课程略去) ,用电梯算法add_request
(3) 进程sleep_on (进程同步)
(4) 磁盘中断处理
(5) do_hd_request算出cyl,head,sector
(6) hd_out调用outp(…)完成端口写
static void read_intr(void){ end_request(1);do_hd_request(); } //唤醒进程!
L29 从生磁盘到文件
为什么引入文件? —cooked disk
文件 —— 盘块号
引入文件,对磁盘使用的第三层抽象
- 让普通用户使用raw disk: 许多人连扇区都不知道是什么?要求他 们根据盘块号来访问磁盘…
- 需要在盘块上引入更高一层次的抽象概念! 文件
- 首先想一想用户眼里的文件是什么样子? 字符序列 (字符流)
- 磁盘上的文件是什么样子? 盘块集合
- 文件: 建立字符流到盘块集合的映射关系
映射的作用
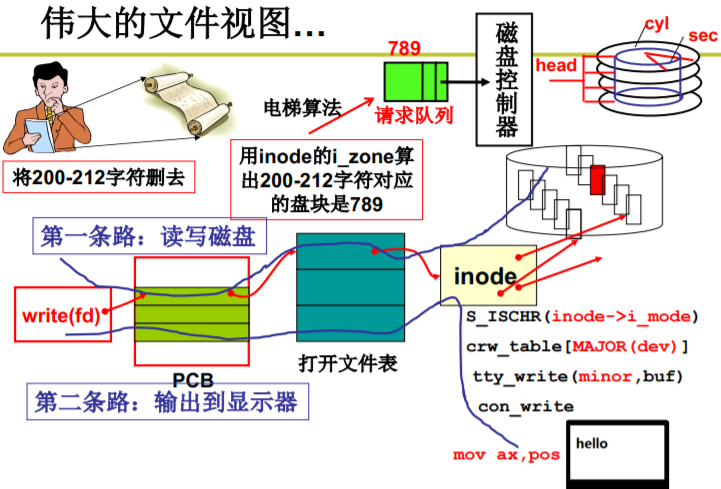
将200-212字符删去
- 连续结构来实现文件 类似数组(不适合动态变化,适合读取 顺序的)
问题:200-212在哪里, 如果盘块大小是100?
test.c中的200-212 字符对应盘块789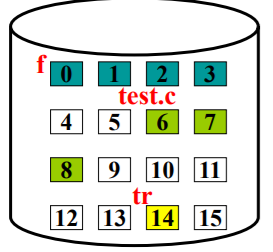
问题:要回答这个问题, 需要存储什么信息? 文件

- 链式结构也可以实现文件 类似链表(适合变化)

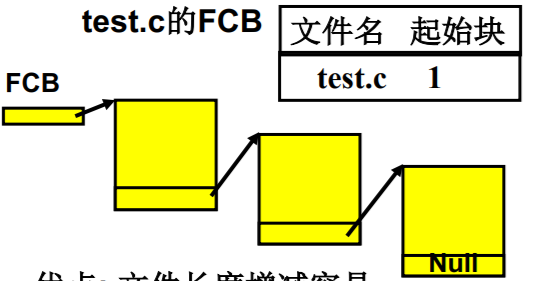
优点: 文件长度增减容易 缺点: 顺序访问慢、可靠性差
文件实现的第三种结构,索引结构
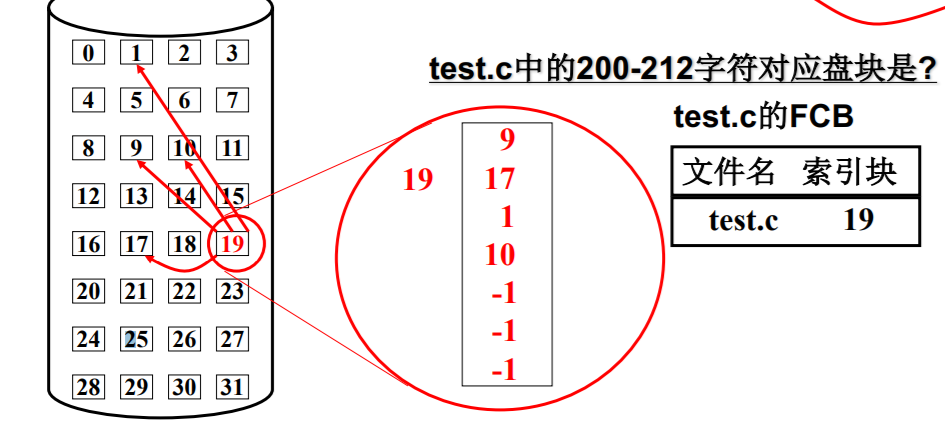
- 是连续和链式分配的有效折衷, 在实际操作系统中较常用!
实际系统是多级索引
index node —— inode
- 可以表示很大的文件
- 很小的文件高效访问
- 中等大小的文件访问速度也不慢!
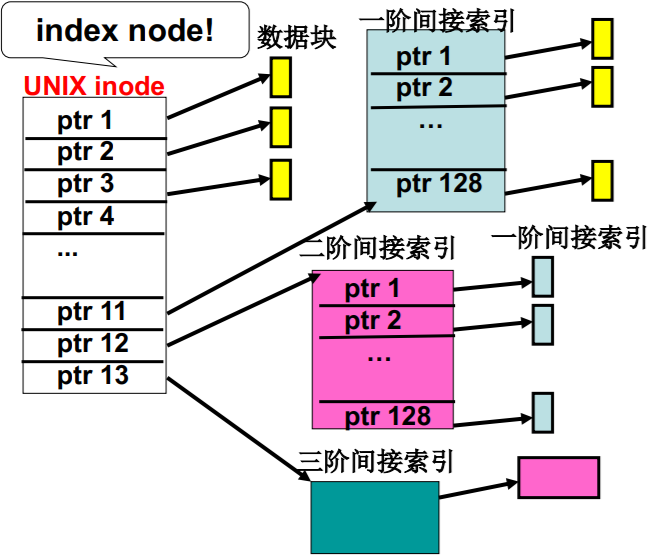
L30 文件使用磁盘的实现
再一次使用磁盘,通过文件使用
在fs/read_write.c中int sys_write(int fd, const char* buf, int count){ struct file *file = current->filp[fd];struct m_inode *inode = file->inode;if(S_ISREG(inode->i_mode))return file_write(inode, file, buf, count); }
用open建立这条链,open的核心 是读入inode
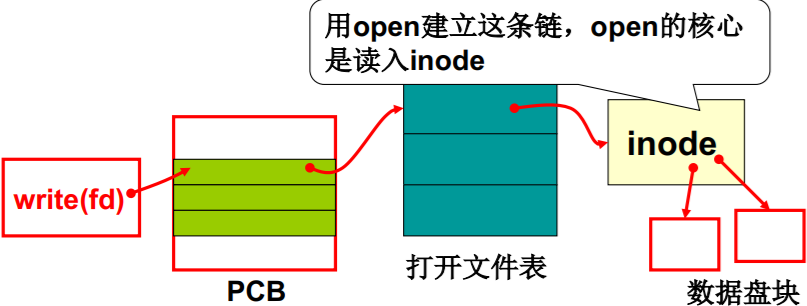
file_write的工作过程应该就是…
file_write(inode, file, buf, count);
(1)首先需要知道是些哪段字符?
file中一个读写指针, 是开始地址(fseek就是修改它),再加上count
(2)找到要写的盘块号?
inode就是用来干这事的
(3)用盘块号、buf等形成request放入“电梯”
file_write的实现
int file_write(struct m_inode *inode, struct file*filp, char *buf, int count){ off_t pos;if(filp->f_flags&O_APPEND) //用file知道文件流读写的字符区间,从哪到哪!pos=inode->i_size; else pos=filp->f_pos; //得到字符流中的读写位置
while(i<count){block=create_block(inode, pos/BLOCK_SIZE); //算出盘块号bh=bread(inode->i_dev, block); //放入“电梯”队列!int c=pos%BLOCK_SIZE; char *p=c+bh->b_data;bh->b_dirt=1; c=BLOCK_SIZE-c; pos+=c;... while(c-->0) *(p++)=get_fs_byte(buf++); //一块一块拷贝用户字符,并且释放写出!brelse(bh); }filp->f_pos=pos; } //修改pos,使之总是对!
create_block算盘块,文件抽象的核心
while(i<count){block=create_block(inode, pos/BLOCK_SIZE); //create=1的_bmap,没有映射时创建映射bh=bread(inode->i_dev, block);
int _bmap(m_inode *inode, int block, int create){ if(block<7){ if(create&&!inode->i_zone[block]){ inode->i_zone[block]=new_block(inode->i_dev);inode->i_ctime=CURRENT_TIME; inode->i_dirt=1;}return inode->i_zone[block];}block-=7; if(block<512){ //一个盘块号2个字节bh=bread(inode->i_dev,inode->i_zone[7]);return (bh->b_data)[block];} ...
struct d_inode{ unsigned short i_mode;...unsigned short i_zone[9];//(0-6):直接数据块,(7):一重间接,(8):二重间接 }
m_inode,设备文件的inode
struct m_inode{ //读入内存后的inode 前几项和d_inode一样!unsigned short i_mode; //文件的类型和属性...unsigned short i_zone[9]; //指向文件内容数据块struct task_struct *i_wait; //多个进程共享的打开这个inode,有的进程等待…unsigned short i_count;unsigned char i_lock;unsigned char i_dirt; ... }
int sys_open(const char* filename, int flag){ if(S_ISCHR(inode->i_mode)) //字符设备{ if(MAJOR(inode->i_zone[0])==4) //设备文件current->tty=MINOR(inode->i_zone[0]);}
#define MAJOR(a)(((unsigned)(a))>>8)) //取高字节#define MINOR(a)((a)&0xff) //取低字节
伟大的文件视图…
L31 目录与文件系统
文件,抽象一个磁盘块集合
- 用户眼里文件的样子 —— 字符序列 (字符流)
- 磁盘上的文件的样子 —— 扇区集合
- 磁盘文件: 建立了字符流到盘块集合的映射关系
文件系统,抽象整个磁盘(第四层抽象)
目录树
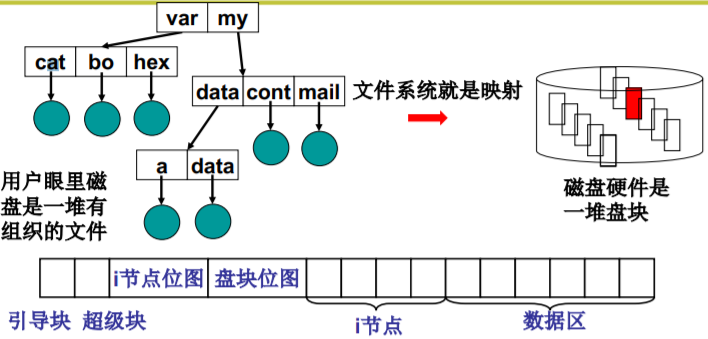
在其他计算机上:应用结构+存储的数据也可以得到那棵文件树,找到文件、读写文件…
故事先从多个文件开始…
- 所有文件放在一层(一个大集合)
- 怎么办? 集合划分、分治
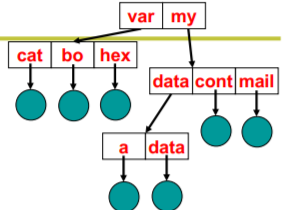
引入目录树
- 将划分后的集合再进行划分: k次划分后,每个 集合中的文件数为O(logkN)
- 这一树状结构扩展性好、表示清晰,最常用
- 引入了一个新的东西: 目录,表示一个文件集合
实现目录成为了关键问题…
- 首先需要回答:目录怎么用?
- 用“/my/data/a”定位文件a
问题:更准确的说,是要干什么?
根据/my/data/a,得到文件a的FCB - 问题:那么目录中应该存什么?
存放目录下的所有文件的FCB吗? 如果 是,解析my要干什么?
- 用“/my/data/a”定位文件a
问题:有什么办法(目录存什么)让系 统效率更高?
树状目录的完整实现 FCB数组
目录的数据块存的东西 —— 目录项:文件名+ 对应的FCB的 “地址”!
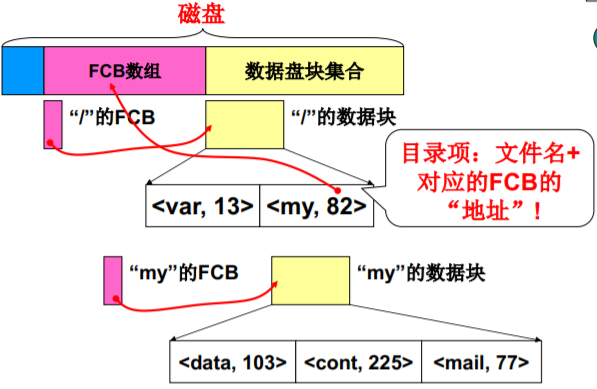
要使整个系统能自举,还需存一些信息
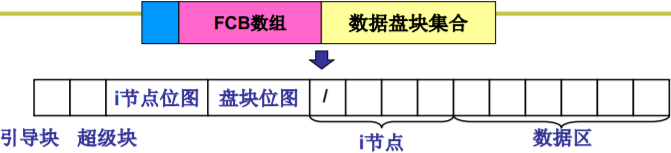
- inode位图: 哪些inode空闲,哪些被占用
- 盘块位图: 哪些盘块是空闲的,硬盘大小不同这个位图的大小也不同
空闲位图(位向量)… 0011110011101 表示磁盘块2、3、4、5、 8、9、10、12空闲 - 超级块: 记录两个位图有多大等信息
“完成全部映射下”的磁盘使用
L32 目录解析代码实现
一个实际运转的文件系统!
PCB 进程控制块 DCT设备控制表 FCB文件控制块
就是将open弄明白…
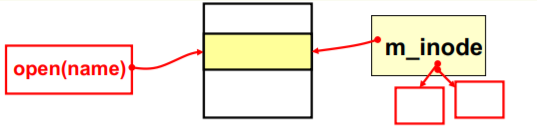
在linux/fs/open.c中int sys_open(const char* filename, int flag){ i=open_namei(filename,flag,&inode); //解析路径!... }
int open_namei(...){ dir=dir_namei(pathname,&namelen,&basename);
static struct m_inode *dir_namei(){ dir=get_dir(pathname); }
get_dir完成真正的目录解析
static struct m_inode *get_dir(const char *pathname){ if((c=get_fs_byte(pathname))==‘/’){inode=current->root; pathname++;} //PCB current->rootelse if(c) inode=current->pwd;while(1){if(!c) return inode; //函数的正确出口bh=find_entry(&inode,thisname,namelen,&de);int inr=de->inode; int idev=inode->i_dev;inode=iget(idev,inr); //根据目录项读取下一层inode}}
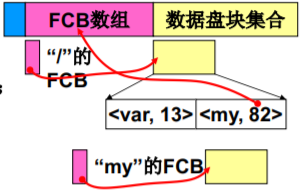
- 核心的四句话正好对应目录树的四个 重点:
(1)root:找到根目录;
(2)find_entry:从目录中读取目录项;
(3)inr:是目录项中的索引节点号;
(4)iget:再读下一层目录
目录解析 — 从根目录开始
inode=current->root;
- 又是current(task_struct),仍然是拷贝自init进程
void init(void){ setup((void *) &drive_info); //一句看过无数次,又略过无数次的语句
sys_setup(void * BIOS)//在kernel/hd.c中{ hd_info[drive].head = *(2+BIOS);hd_info[drive].sect = *(14+BIOS);mount_root(); ... }
void mount_root(void)//在fs/super.c中{mi=iget(ROOT_DEV,ROOT_INO)); //#define ROOT_INO 1current->root = mi;}
读取inode — iget
struct m_inode * iget(int dev, int nr){ struct m_inode * inode = get_empty_inode();inode->i_dev=dev; inode->i_num=nr;read_inode(inode); return inode;}
static void read_inode(struct m_inode *inode){ struct super_block *sb=get_super(inode->i_dev);;lock_inode(inode);block=2+sb->s_imap_blocks+sb->s_zmap_blocks+(inode->i_num-1)/INODES_PER_BLOCK;bh=bread(inode->i_dev,block);inode=bh->data[(inode->i_num-1)%INODES_PER_BLOCK];unlock_inode(inode); }

开始目录解析 — find_entry(&inode,name,…,&de)
- de: directory entry(目录项)
struct dir_entry{unsigned short inode; //i节点号char name[NAME_LEN]; //文件名 }
在fs/namei.c中static struct buffer_head *find_entry(struct m_inode**dir, char *name, ..., struct dir_entry ** res_dir){ int entries=(*dir)->i_size/(sizeof(struct dir_entry));int block=(*dir)->i_zone[0];*bh=bread((*dir)->i_dev, block);struct dir_entry *de =bh->b_data;while(i<entries) {if(match(namelen,name,de)){*res_dir=de; return bh;}de++; i++;} }
while(i<entries)…
while(i<entries) //entries是目录项数{ if((char*)de> = BLOCK_SIZE+bh->b_data){ //#define BLOCK_SIZE1024 //两个扇区brelse(bh);block=bmap(*dir,i/DIR_ENTRIES_PER_BLOCK);bh=bread((*dir)->i_dev,block);de=(struct dir_entry*)bh->b_data;} //读入下一块上的目录项继续matchif(match(namelen,name,de)){*res_dir=de;return bh;}de++; i++; }
操作系统全图
两大视图

若有收获,就点个赞吧
0 人点赞
