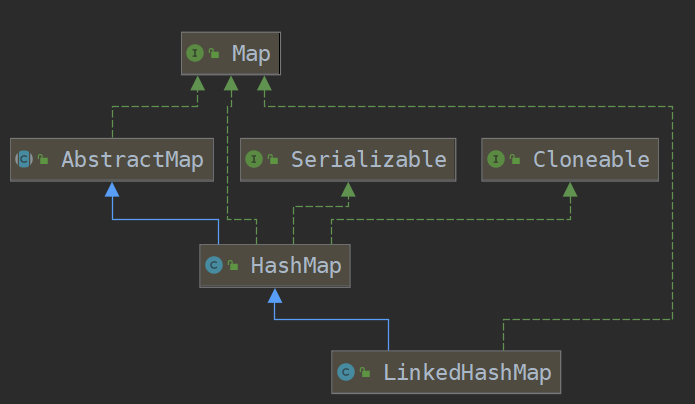
LinkedHashMap,继承了HashMap也就意味着实际上底层还是要借助HashMap的一些实现。
LinkedHashMap和HashMap的区别
HashMap,比如你放了一堆key-value对进去,后面的话呢如果你要遍历这个HashMap的话,遍历的顺序,并不是按照你插入的key-value的顺序来的。LinkedHashMap,他会记录你插入key-value的顺序,如果你在遍历的时候,他是按照插入key-value对的顺序给你遍历出来的。这就是最大的区别了。
put方法分析
用put就能看出是如何维护可以记录插入顺序的链表了。从图中看出put还是走的hashMap的方法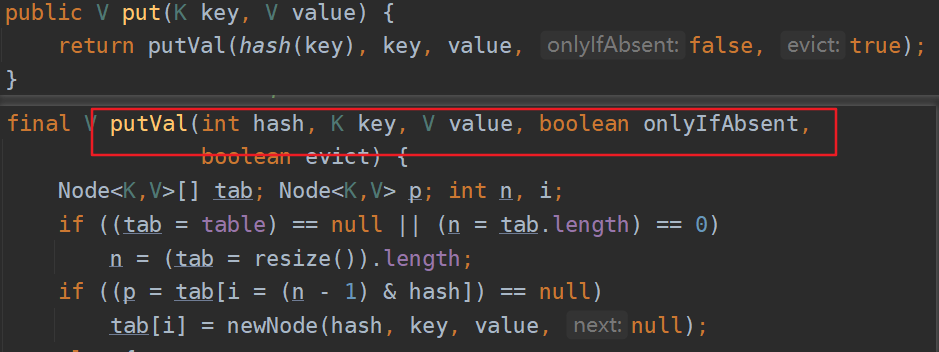
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)//1tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}//2if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize();//3afterNodeInsertion(evict);return null;}
- tab[i] = newNode(hash, key, value, null);当寻址的那个index位置没有元素,就走这一步插入。这里newNode是LinkedHashMap的实现方法,这里就把Node维护成一个按插入顺序的双向链表。
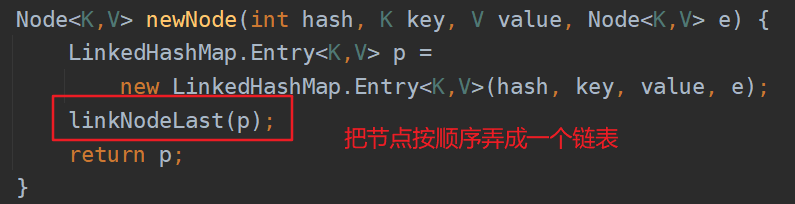
当插入的那个位置有元素了,就要走下面这个判断。同时执行一个很重要的方法,就是afterNodeAccess(e);
- (accessOrder && (last = tail) != e);这里有个判断,accessOrder属性在构造的时候传入进去,默认是false,如果是默认为false的话,如果get一个key或者是覆盖这个key的值,都不会改变这个key在链表里的顺序。如果accessOrder是true的话,当get一个key或者是覆盖这个key的值时,就会导致个key-value对顺序会在链表里改变,这个变动的元素就会被挪动到链表的尾部去,如果你把accessOrder指定为true,你每次修改一个key的值,或者是get访问一下这个key,都会导致这个key挪动到链表的尾部去
void afterNodeAccess(Node<K,V> e) { // move node to lastLinkedHashMap.Entry<K,V> last;if (accessOrder && (last = tail) != e) {LinkedHashMap.Entry<K,V> p =(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;p.after = null;if (b == null)head = a;elseb.after = a;if (a != null)a.before = b;elselast = b;if (last == null)head = p;else {p.before = last;last.after = p;}tail = p;++modCount;}}
- (accessOrder && (last = tail) != e);这里有个判断,accessOrder属性在构造的时候传入进去,默认是false,如果是默认为false的话,如果get一个key或者是覆盖这个key的值,都不会改变这个key在链表里的顺序。如果accessOrder是true的话,当get一个key或者是覆盖这个key的值时,就会导致个key-value对顺序会在链表里改变,这个变动的元素就会被挪动到链表的尾部去,如果你把accessOrder指定为true,你每次修改一个key的值,或者是get访问一下这个key,都会导致这个key挪动到链表的尾部去
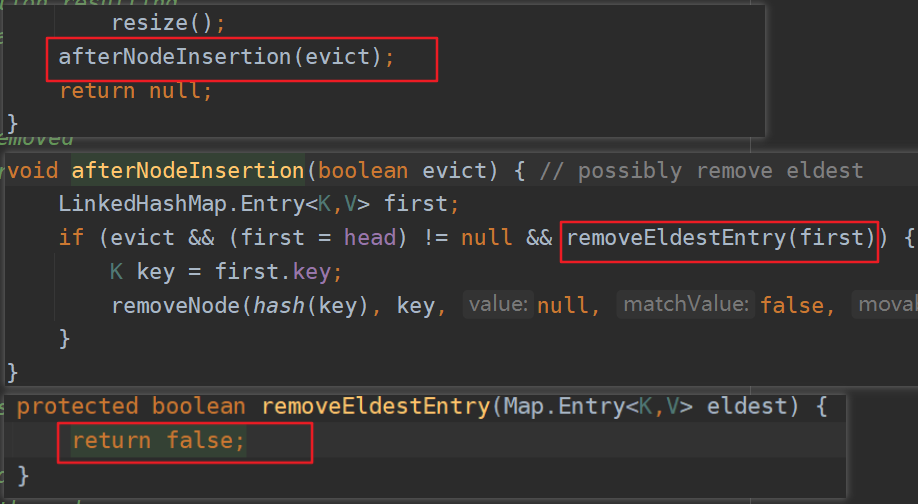
afterNodeInsertion(evict); LinkedHashMap中还重写了afterNodeInsertion(boolean evict)方法,它的目的是移除链表中最老的节点对象,也就是当前在头部的节点对象,但实际上在JDK8中不会执行,因为removeEldestEntry方法始终返回false。
LinkedHashMap如何遍历的?
其实就是进入LinkedHashMap类种有个Iterator内部类做遍历,按着之前的维护的一个链表做遍历。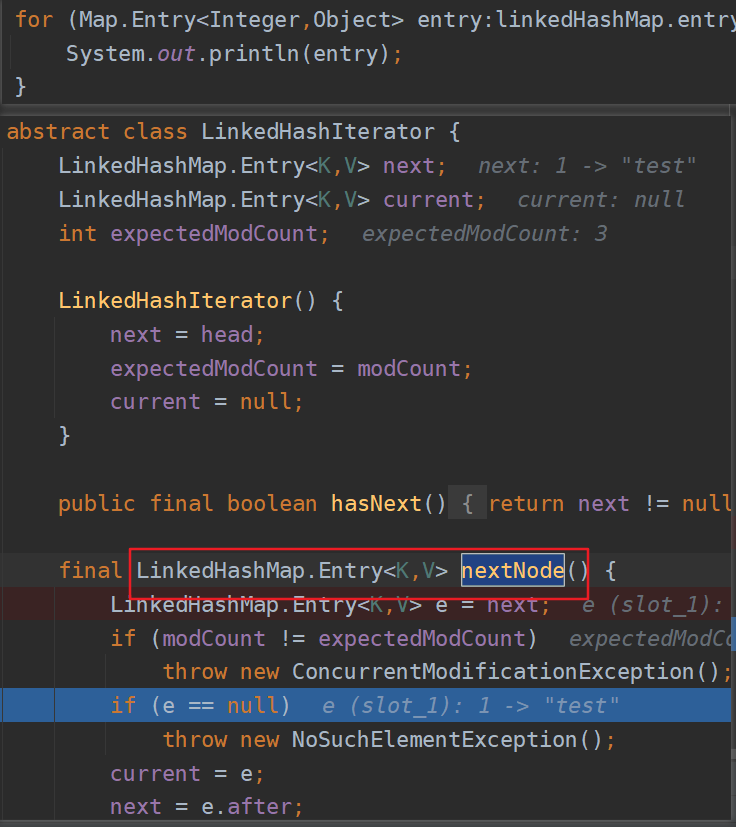
总结
实际上LinkedHashMap就是在原本HashMap的基础上,维护除了一个记录插入顺序的链表。使得遍历的时候是按插入顺序展示。而原本的HashMap是按Key值的顺序去插入的。

若有收获,就点个赞吧
0 人点赞
