聊聊HDFS
Mysql的弊端
假如,现在公司里的数据都是放在MySQL里的,那么就全部放在一台数据库服务器上,我们就假设这台服务器的磁盘空间有2T。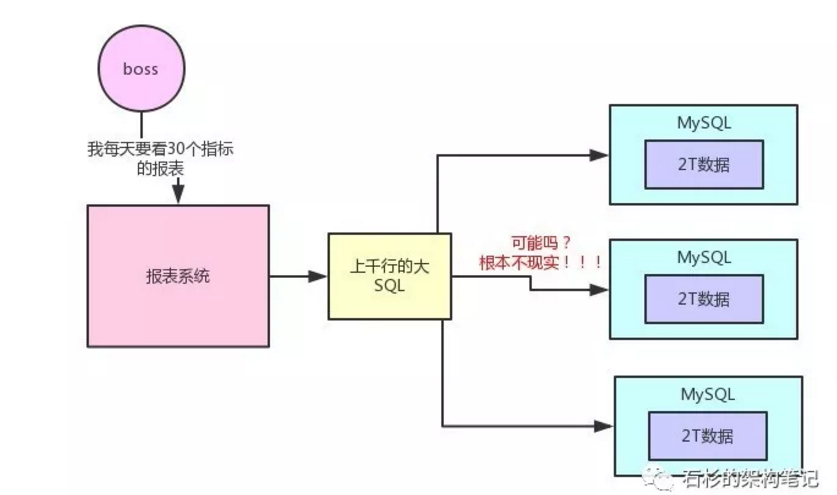
现在有个问题,不停的往这台服务器的mysql中放数据,结果数据越来越大了,超过了2T,应该怎么办?
如果选择分库、分表搞三台机器,每个机器可以存2T的数据。假设,有一个电商网站,现在要把这个电商网站里所有的用户在页面和APP上的点击、购买、浏览的行为日志都存放起来分析。现在把这些数据全都放在了3台MySQL服务器,数据量很大,但还是勉强可以放的下。
某天早上,有人要去看报表。比如要看每天网站的X指标、Y指标、Z指标,等等,二三十个数据指标。这种情况下去生成报表,绝对会写出来一个几百行起步,甚至上千行的超级复杂大SQL。MySQL分库分表后,几百行的大SQL跨库join,各种复杂的计算,根本不现实。
所以,大数据就可以解决这些问题的。
Hadoop的HDFS
HDFS大数据技术体系中的核心基石,负责分布式存储数据。HDFS全称是Hadoop Distributed File System,是Hadoop的分布式文件系统。
它由很多机器组成,每台机器上运行一个DataNode进程,负责管理一部分数据,多台机器有自己的一部分数据,就把数据分开了。
然后有一台机器上运行了NameNode进程,NameNode大致可以认为是负责管理整个HDFS集群的这么一个进程,他里面存储了HDFS集群的所有元数据。
MySQL并不是设计为分布式系统架构的,他在分布式数据存储这块缺乏很多数据保障的机制。但是HDFS天然就是分布式的技术,所以你上传大量数据,存储数据,管理数据,天然就可以用HDFS来做。
分布式计算
- 很多公司用Hive写几百行的大SQL(底层基于MapReduce)
- 也有很多公司开始慢慢的用Spark写几百行的大SQL(底层是Spark Core引擎)。
总之就是写一个大SQL,人家会拆分为很多的计算任务,放到各个机器上去,每个计算任务就负责计算一小部分数据,这就是所谓的分布式计算。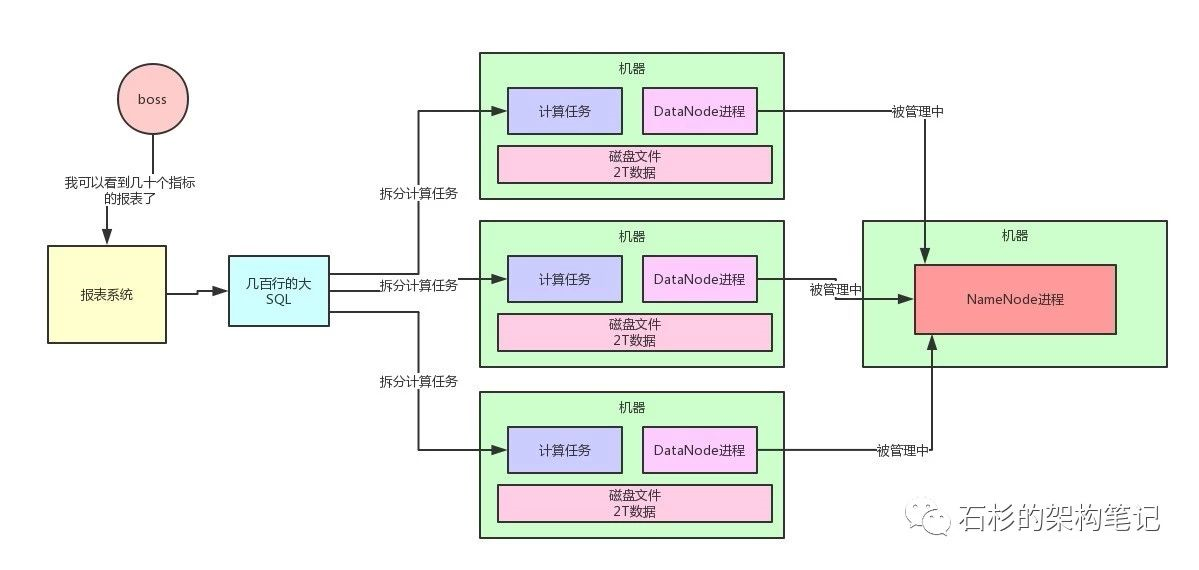
HDFS的NameNode架构原理
NameNode有一个很核心的功能:管理整个HDFS集群的元数据,比如说文件目录树、权限的设置、副本数的设置,等等。
看下文件目录树的维护这个功能,现在有一个客户端系统要上传一个1TB的大文件到HDFS集群里。
此时他会先跟NameNode通信,说:大哥,我想创建一个新的文件,他的名字叫“/usr/hive/warehouse/access_20180101.log”,大小是1TB,你看行不?然后NameNode就会在自己内存的文件目录树里,在指定的目录下搞一个新的文件对象,名字就是“access_20180101.log”。
但是有个问题,这个文件目录树是在NameNode的内存里的,如果这个机器宕机了那么内存的数据就没有了.
因此,每次内存里改完了,写一条edits log,元数据修改的操作日志到磁盘文件里,不修改磁盘文件内容,就是顺序追加,这个性能就高多了。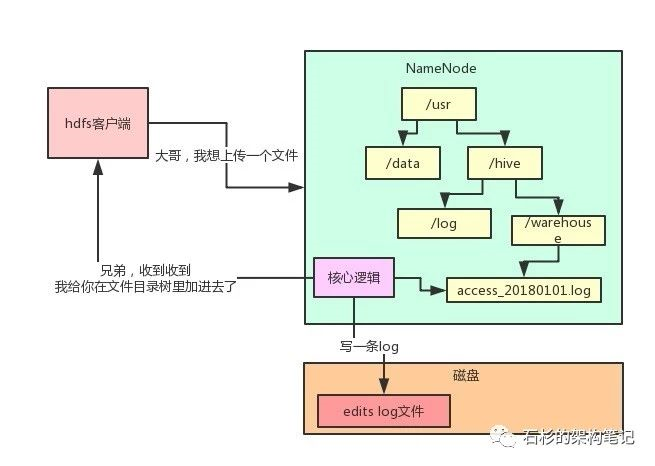
问题又来了,那edits log如果越来越大的话,岂不是每次重启都会很慢?因为要读取大量的edits log回放恢复元数据!
因此,HDFS又引入一个新的磁盘文件叫做fsimage,再引入一个JournalNodes集群,以及一个Standby NameNode(备用节点)。每次Active NameNode(主节点)修改一次元数据都会生成一条edits log,除了写入本地磁盘文件,还会写入JournalNodes集群。
然后Standby NameNode就可以从JournalNodes集群拉取edits log,应用到自己内存的文件目录树里,跟Active NameNode保持一致。
然后每隔一段时间,Standby NameNode都把自己内存里的文件目录树写一份到磁盘上的fsimage,这可不是日志,这是完整的一份元数据。这个操作就是所谓的checkpoint检查点操作。
然后把这个fsimage上传到到Active NameNode,接着清空掉Active NameNode的旧的edits log文件,这里可能都有100万行修改日志了!
然后Active NameNode继续接收修改元数据的请求,再写入edits log,写了一小会儿,这里可能就几十行修改日志而已!
如果说此时,Active NameNode重启了,bingo!没关系,只要把Standby NameNode传过来的fsimage直接读到内存里,这个fsimage直接就是元数据,不需要做任何额外操作,纯读取,效率很高!
然后把新的edits log里少量的几十行的修改日志回放到内存里就ok了!就不需要上百万行的edits log来恢复数据了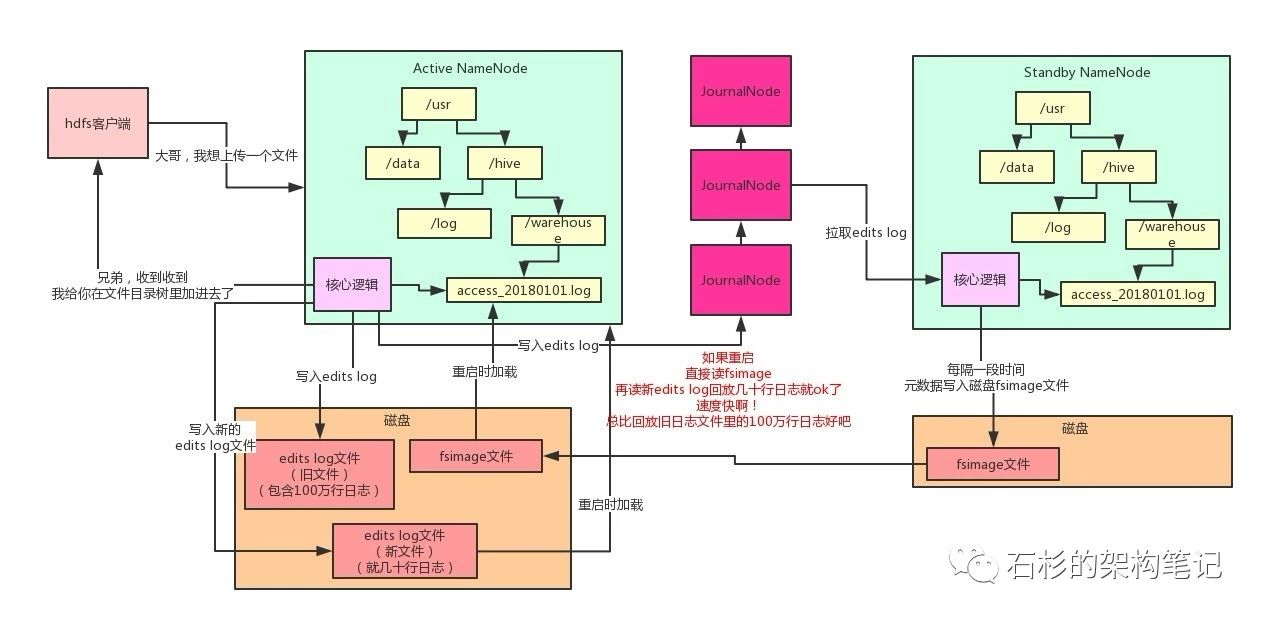
Hadoop NameNode如何承载每秒上千次的高并发
初始分析NameNode的性能缺陷
NameNode在写edits log时的第一条原则:
必须保证每条edits log都有一个全局顺序递增的transactionId(简称为txid),这样才可以标识出来一条一条的edits log的先后顺序。
那么如果要保证每条edits log的txid都是递增的,就必须得加锁。
每个线程修改了元数据,要写一条edits log的时候,都必须按顺序排队获取锁后,才能生成一个递增的txid,代表这次要写的edits log的序号。
如果,每次都在一个加锁的代码块中生成txid,然后再写磁盘文件edits log,网络请求写入JournalNodes,那这样没法玩!性能极差。
写本地磁盘 + 网络传输给journalnodes都加锁,完蛋啊,两大性能杀手!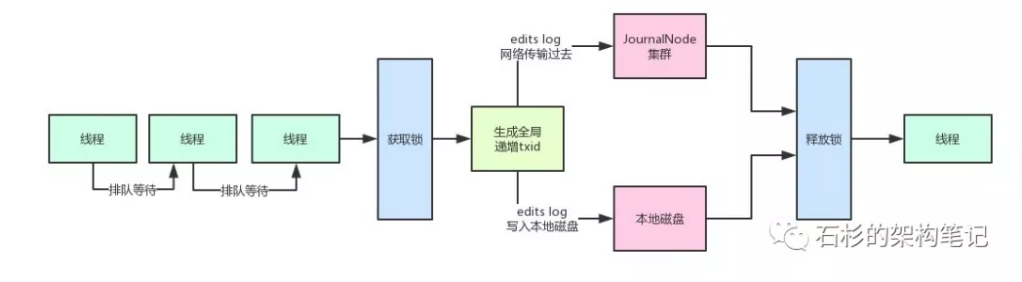
Hadoop优雅的解决方案
既然不想每个线程写edits log的时候,串行化排队生成txid + 写磁盘 + 写JournalNode。就可以加一个内存缓冲。
也就是说,多个线程可以快速的获取锁,生成txid,然后快速的将edits log写入内存缓冲。
接着就快速的释放锁,让下一个线程继续获取锁后,生成id + 写edits log进入内存缓冲。
然后接下来有一个线程可以将内存中的edits log刷入磁盘,但是在这个过程中,还是继续允许其他线程将edits log写入内存缓冲中。
但是这里又有一个问题了,如果针对同一块内存缓冲,同时有人写入,还同时有人读取后写磁盘,那也有问题,因为不能并发读写一块共享内存数据!
所以HDFS在这里采取了double-buffer双缓冲机制来处理!将一块内存缓冲分成两个部分:
其中一个部分可以写入
另外一个部分用于读取后写入磁盘和JournalNodes。
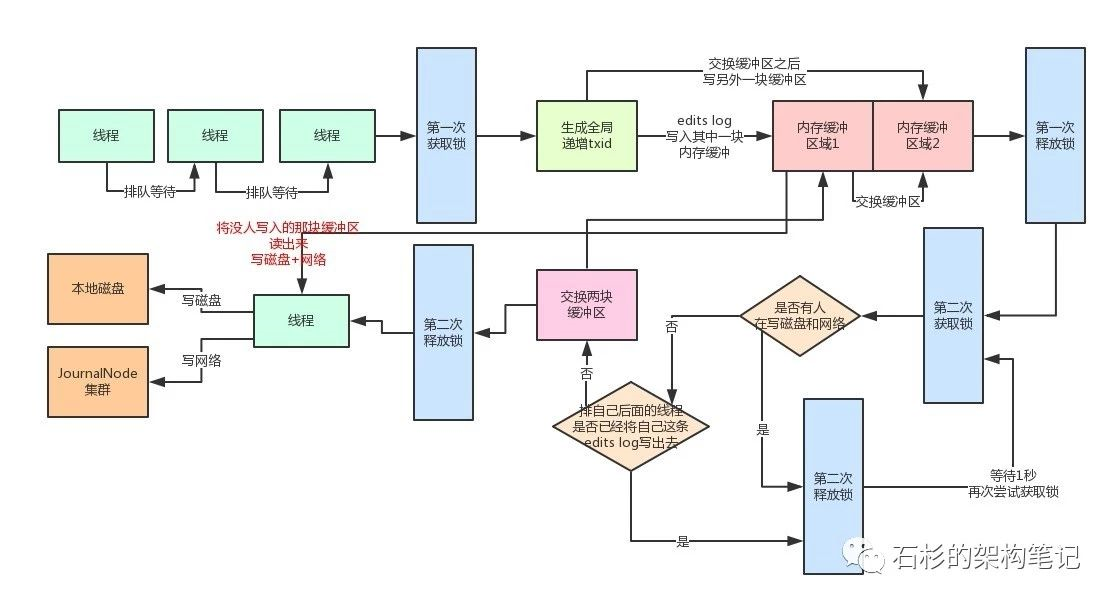
(1)分段加锁机制 + 内存双缓冲机制
首先各个线程依次第一次获取锁,生成顺序递增的txid,然后将edits log写入内存双缓冲的区域1,接着就立马第一次释放锁了。
趁着这个空隙,后面的线程就可以再次立马第一次获取锁,然后立即写自己的edits log到内存缓冲。此时还没有做磁盘io操作。
接着各个线程竞争第二次获取锁,有线程获取到锁之后(姑且称为线程A),就看看,有没有谁在写磁盘和网络。如果没有,直接交换双缓冲的区域1和区域2,接着第二次释放锁。这个过程相当快速,内存里判断几个条件,耗时不了几微秒。
到这一步为止,内存缓冲已经被交换了,后面的线程可以立马快速的依次获取锁,然后将edits log写入内存缓冲的区域2,区域1中的数据被锁定了,不能写。
(2)多线程并发吞吐量的百倍优化
接着,之前那个线程A,将内存缓冲的区域1中的数据读取出来(此时没人写区域1了,都在写区域2),将里面的edtis log都写入磁盘文件,以及通过网络写入JournalNodes集群。虽然这个数据写入得过程耗时,但是,之前的一些操作没有加锁,后面的线程可以噼里啪啦的快速的第一次获取锁后,立马写入内存缓冲的区域2,然后释放锁。
(3)缓冲数据批量刷磁盘 + 网络的优化
那么在线程A吭哧吭哧把数据写磁盘和网络的过程中,排在后面的大量线程,快速的第一次获取锁,写内存缓冲区域2,释放锁,之后,这些线程第二次获取到锁后会干嘛?
他们会发现有人在写磁盘啊,兄弟们!所以会立即休眠1秒。
此时大量的线程并发过来的话,都会在这里快速的第二次获取锁,然后发现有人在写磁盘和网络,快速的释放锁,休眠。
这个过程没有人长时间的阻塞其他人吧!因为都会快速的释放锁,所以后面的线程还是可以迅速的第一次获取锁后写内存缓冲!
一定会有很多线程发现,好像之前那个幸运儿线程的txid是排在自己之后的,那么肯定就把自己的edits log从缓冲里写入磁盘和网络了。
然后那个线程A写完磁盘和网络之后,就会唤醒之前休眠的那些线程。
那些线程会依次排队再第二次获取锁后进入判断,咦!发现没有人在写磁盘和网络了!
然后就会再判断,有没有排在自己之后的线程已经将自己的edtis log写入磁盘和网络了。
- 如果有的话,就直接返回了。
- 没有的话,那么就成为第二个幸运儿线程,交换两块缓冲区,区域1和区域2交换一下。
- 然后释放锁,自己开始吭哧吭哧的将区域2的数据写入磁盘和网络。

若有收获,就点个赞吧
0 人点赞
