/*** Implements Map.put and related methods** @param hash hash for key* @param key the key* @param value the value to put* @param onlyIfAbsent if true, don't change existing value* @param evict if false, the table is in creation mode.* @return previous value, or null if none*/final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize();afterNodeInsertion(evict);return null;}
put操作原理和hash寻址算法
假设hashmap为空,容量是16
- if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length; 刚开始table数组是空的,就会分配一个默认的数组大小是16
- (p = tab[i = (n - 1) & hash]) == null ,寻址
- n位数组的大小(n-1)=15
- (n - 1) & hash
0000 0000 0000 0000 0000 0000 0000 1111
& (都是1结果才是1 否则都是0)
1111 1111 1111 1111 0000 0101 1000 0011
0000 0000 0000 0000 0000 0000 0000 0011,转成10进制就是3
寻址并不是用hash取模,取模性能不高。1.8优化的一个效果就是,保证数组未来每次扩容的值都是2的n次方的情况下提升性能。(n - 1) & hash的效果和hash % 数组.length取模效果是一样。
这块也解释了为什么hash算法要优化。由于要提升性能,所以这块用了&运算。如果直接使用hashCode和(n-1)进行运算的话,首先(n-1)的值不大况且是比hash值要小很多的.因此(n-1)的2进制的高16位往往都是0。而hashcode的高16位大部分情况下都是1。这两个高16位做&运算结果是什么呢?肯定都是0。无论hashCode的高16位怎么变大概率下运算出的结果都是0,因此拿原来未处理的hashcode做的话高16位的数字就没有派上用场,因此hash冲突的概率就增大了,如果做了处理特征都在低16位上再去运算,hash冲突的概率就降低了。
tab[i] = newNode(hash, key, value, null);因为一开始的时候里面是没东西的就要创建一个Node并把它放进数组里。
hash冲突的链表处理
就是两个key值,hash值一样,导致hash冲突了。这个概率极低的。
第一个冲突值
p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)));就是来判断传入的hash值和寻址到当前数组index位置的这个Node里面的hash值一样不,同时要看下一key的值一样不。一样的话搞一个中间变量e = p;后面的else判断都不走了,就开始做值覆盖的操作了。
 拿到中间变量e,在后面就开始判断了
拿到中间变量e,在后面就开始判断了- V oldValue = e.value;把原来的vlaue给OldValue
- e.value = value;数组那个位置的Node的value设置为新的value
- 返回oldValue旧值
如果1没有走进去,就一意味着key不同hash值相同或者key一样hash值不一样。
- else if (p instanceof TreeNode),如果当前位置是一个红黑树应该怎么处理
- key不一样出现了hash冲突,此时不是红黑树而是用链表处理。

- (e = p.next) == null;这个next一定是null,因此e指向了这个null。
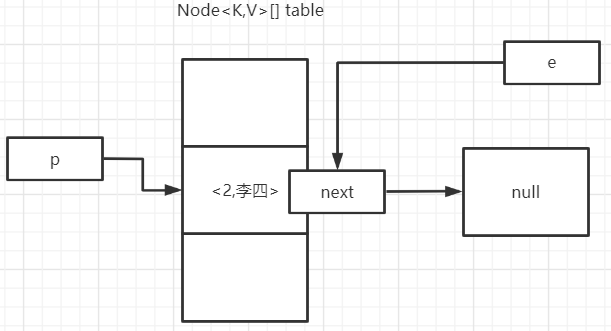
2. p.next = newNode(hash, key, value, null);把next指针指向冲突的节点,e也跟着指过去了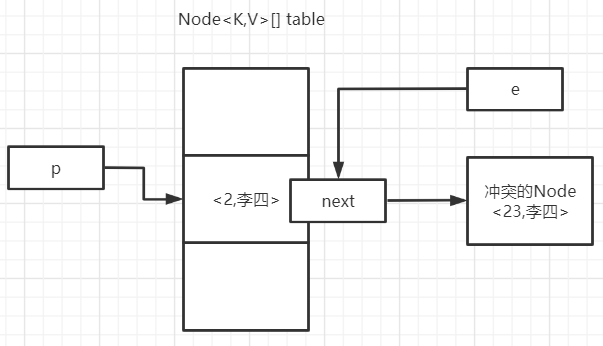2. if (binCount >= TREEIFY_THRESHOLD - 1){ treeifyBin(tab, hash);} 如果当前链表的长度大于等于TREEIFY_THRESHOLD - 1的话就要开始转变成红黑树了。
- e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k)));这里就是要判断一下是否退出循环的。其实第一轮循环的时候e其实指向了null,然后这里是进不去的。直至执行了p = e;下一轮循环的时候当前这个判断就能进去了
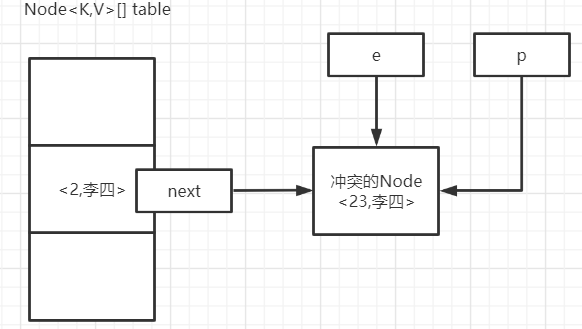
第二个冲突值
当第二个冲突的值也进来,的时候p在这个位置。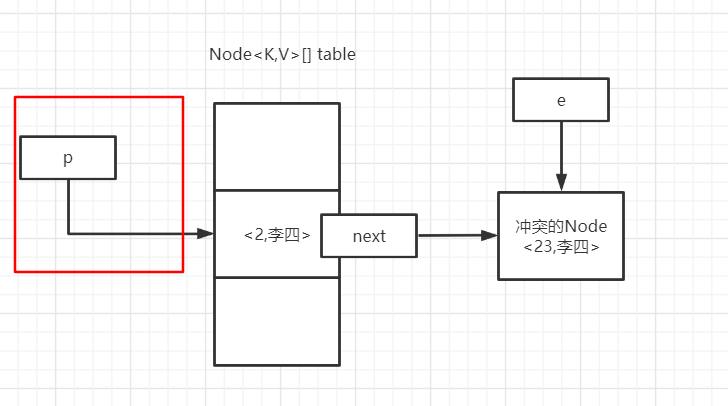
随后进入 for (int binCount = 0; ; ++binCount)循环,进去之后里里面的两个if肯定都不会进去的。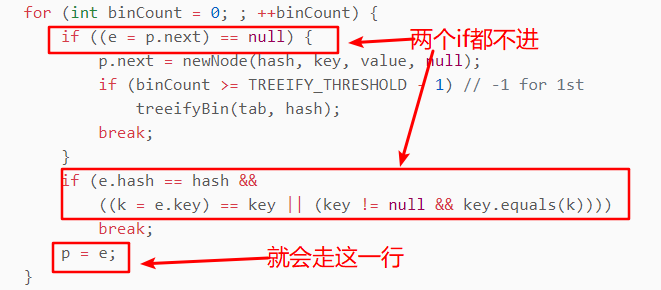
随后就又回到这个样子,之后就开始了和处理第一个冲突值一样的操作。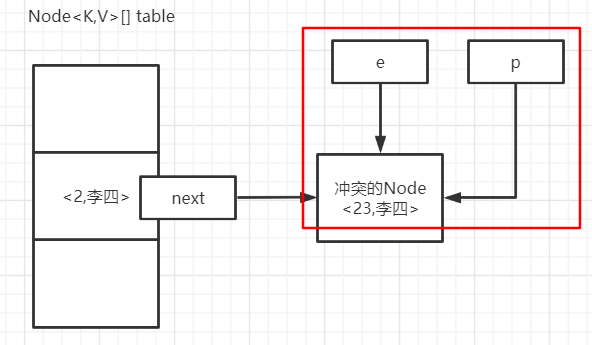
hash冲突的红黑树处理
如果发生大量的hash冲突了,如果单纯用链表去解决,就会出现get操作的时间复杂度是O(N),性能就不太好了,因此就要转一下红黑树去降低时间复杂度。图中treeifyBin就是转红黑树的方法。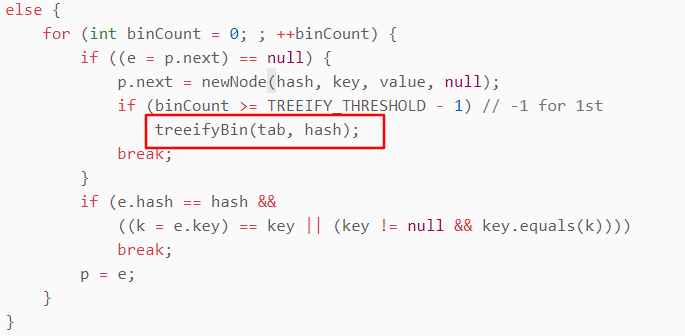
/*** Replaces all linked nodes in bin at index for given hash unless* table is too small, in which case resizes instead.*/final void treeifyBin(Node<K,V>[] tab, int hash) {int n, index; Node<K,V> e;if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)resize();//1.else if ((e = tab[index = (n - 1) & hash]) != null) {TreeNode<K,V> hd = null, tl = null;do {TreeNode<K,V> p = replacementTreeNode(e, null);if (tl == null)hd = p;else {p.prev = tl;tl.next = p;}tl = p;} while ((e = e.next) != null);if ((tab[index] = hd) != null)hd.treeify(tab);}}
- else if ((e = tab[index = (n - 1) & hash]) != null) ;获取e,e就是那个数组里面冲突的index,拿到e就是拿到了那个链表
- TreeNode
都转红黑树了还出现了hash冲突怎么办
首先,冲突的时候就会进入下面红框的分支,由于已经是红黑树的节点了,就会在原来的红黑树上去挂新的节点。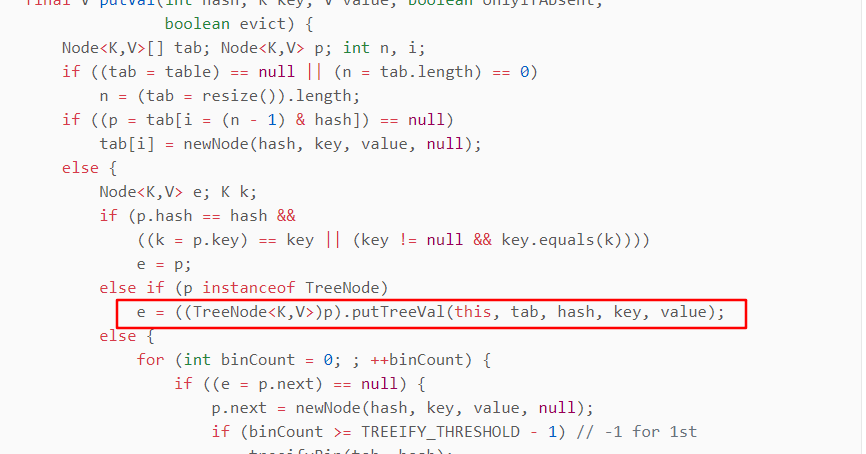
总结:
如果有hash冲突,要么是key不一样,结果你的hashCode()方法乱写,导致hash值一样;但是大多数是key不一样,同时hash值也不一样,但是呢,hash寻址过后找到的这个数组中的位置是一样的,出现了hash碰撞。
出现了这种情况先是挂链表,如果链表长度超过了8,就将链表转为红黑树。

若有收获,就点个赞吧
0 人点赞
