线程池工作原理
图解线程池
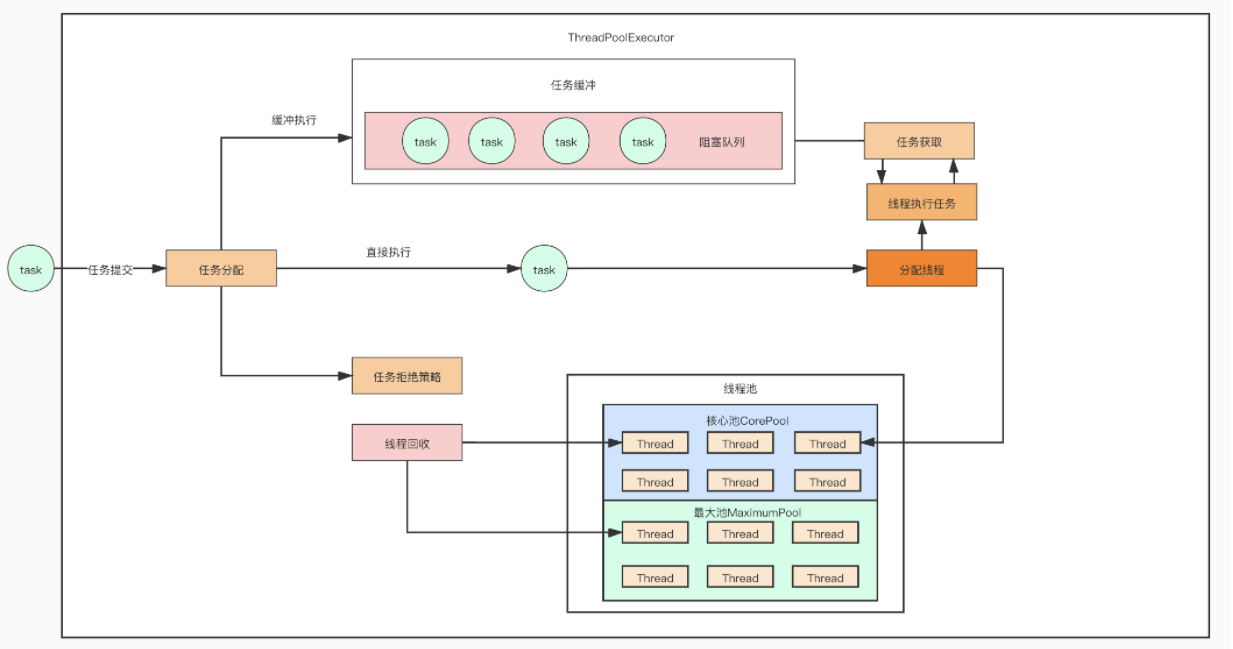
- Executor:代表线程池的接口,有个execute()方法,扔进去一个Runnable类型对象,就可以分配一个线程给你执行
- ExecutorService:这是Executor的子接口,相当于是一个线程池的接口,有销毁线程池等方法
- Executors:线程池的辅助工具类,辅助入口类,可以通过Executors来快捷的创建你需要的线程池
ThreadPoolExecutor:这是ExecutorService的实现类,这才是正儿八经代表一个线程池的类,一般在Executors里创建线程池的时候,内部都是直接创建一个ThreadPoolExecutor的实例对象返回的,然后同时给设置了各种默认参数
线程池之Two-phase Termination
Two-phaseTermination两段终止模式
发出信号,告知正在运行的线程将被终止。
- 接收到此信号的线程,做完善后工作,停止运行。
示例:线程现在按部就班的从数据队列中获取数据,如果要停止拉取取就得让线程终止,此时如果立马终止则会导致一部分数据是要丢失掉的。因此不能这么做,就需要按照上面1,2步骤去做。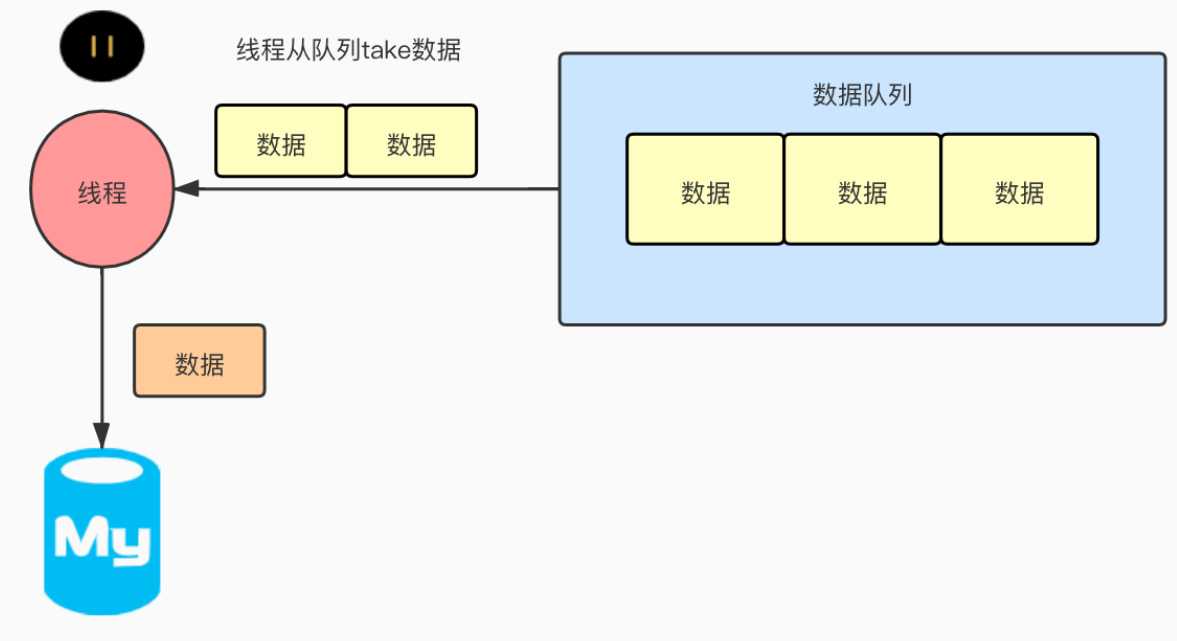
ShutDown中应用
线程池之生产消费者模式
线程池中存在一个参数就是Work queue,这里传的就是各种的BlockingQueue的实现类。
队列就可想到解耦、削峰,也就是生产者-消费者模式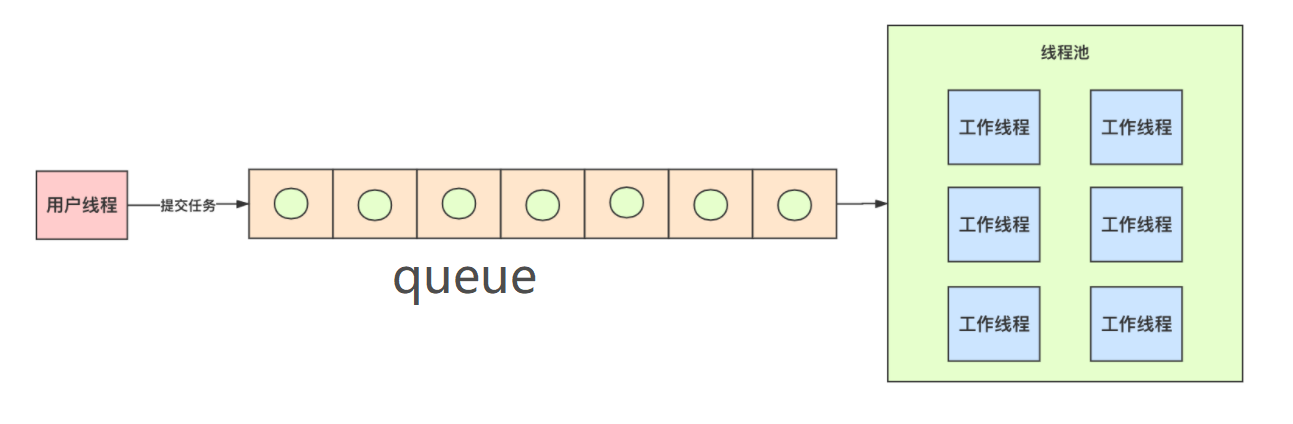
任务如何被提交
1.原子变量ctl共同存储 线程状态+线程个数。用一个int型变量存储两个数,高3位表示线程状态,后面29位表示线程的个数
2.判断当前线程数小于核心线程数,就直接通过addWorker将任务交给worker去执行。
3.如果线程池处于RUNNING状态,添加任务到阻塞队列
4.重新获取下ctl的值,因为把任务添加到队列时,线程的状态可能已经改变,这里重新获取下
5.线程状态不是RUNNING状态,从队列里删除
6.如果当前线程池一个线程也没有,添加一个线程
7.如果队列满了,则添加新的线程(非核心线程),如果新增失败,执行拒绝策略
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));public void execute(Runnable command) {if (command == null)throw new NullPointerException();1. int c = ctl.get();2. if (workerCountOf(c) < corePoolSize) {if (addWorker(command, true))return;c = ctl.get();}3. if (isRunning(c) && workQueue.offer(command)) {4. int recheck = ctl.get();5. if (! isRunning(recheck) && remove(command))reject(command);6. else if (workerCountOf(recheck) == 0)addWorker(null, false);}7. else if (!addWorker(command, false))reject(command);}
任务如何被线程池消费
线程池执行任务流程是这样的:ThreadPoolExecutor->execute然后执行线程
在execute中没有看到具体的start方法,查看上面代码的3、4、5、6、7的逻辑可以推断出任务是要进入addWorker中的。进入addWorker方法,可以找到t.start()的执行。t对象就是Worker中的thread。
private boolean addWorker(Runnable firstTask, boolean core) {retry:for (;;) {...省略}boolean workerStarted = false;boolean workerAdded = false;Worker w = null;try {w = new Worker(firstTask);final Thread t = w.thread;//这里是之前没有将任务线程交给worker就要将任务加入worker中再执行。if (t != null) {final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {// Recheck while holding lock.// Back out on ThreadFactory failure or if// shut down before lock acquired.int rs = runStateOf(ctl.get());if (rs < SHUTDOWN ||(rs == SHUTDOWN && firstTask == null)) {if (t.isAlive()) // precheck that t is startablethrow new IllegalThreadStateException();workers.add(w);int s = workers.size();if (s > largestPoolSize)largestPoolSize = s;workerAdded = true;}} finally {mainLock.unlock();}if (workerAdded) {t.start();workerStarted = true;}}} finally {if (! workerStarted)addWorkerFailed(w);}return workerStarted;}
查看Worker内部类,它实现了Runnable,那么执行任务的操作一定是在run方法中。
找到run发现又调用了runWorker方法,这里面关键的就是通过getTask()去获取任务,进入getTask()可以找到 workQueue.take();获取任务线程。
public void run() {runWorker(this);}final void runWorker(Worker w) {Thread wt = Thread.currentThread();Runnable task = w.firstTask;w.firstTask = null;w.unlock(); // allow interruptsboolean completedAbruptly = true;try {while (task != null || (task = getTask()) != null) {w.lock();if ((runStateAtLeast(ctl.get(), STOP) ||(Thread.interrupted() &&runStateAtLeast(ctl.get(), STOP))) &&!wt.isInterrupted())wt.interrupt();try {beforeExecute(wt, task);Throwable thrown = null;try {task.run();} catch (RuntimeException x) {thrown = x; throw x;} catch (Error x) {thrown = x; throw x;} catch (Throwable x) {thrown = x; throw new Error(x);} finally {afterExecute(task, thrown);}} finally {task = null;w.completedTasks++;w.unlock();}}completedAbruptly = false;} finally {processWorkerExit(w, completedAbruptly);}}private Runnable getTask() {boolean timedOut = false; // Did the last poll() time out?for (;;) {int c = ctl.get();int rs = runStateOf(c);// Check if queue empty only if necessary.if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {decrementWorkerCount();return null;}int wc = workerCountOf(c);// Are workers subject to culling?boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;if ((wc > maximumPoolSize || (timed && timedOut))&& (wc > 1 || workQueue.isEmpty())) {if (compareAndDecrementWorkerCount(c))return null;continue;}try {Runnable r = timed ?workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :workQueue.take();if (r != null)return r;timedOut = true;} catch (InterruptedException retry) {timedOut = false;}}}
线程池之Active Object
Active Object主动对象模式
为了简化异步调用的复杂性,主动对象模式分离了方法的执行和调用。使用这个模型,无论一个对象中是否有独立的线程进行异步调用,客户端从外部访问它时,感觉是一样的。主动对象模型由六大组件组成:
1、Proxy
这其实可以理解为一个代理对象,主要用于对外暴露异步方法。包含asyncService方法,这是主动对象模型执行的入口。在主动对象模式中,请求都是先发往Proxy的asyncService方法。然后不等具体逻辑执行完成,很快返回一个Futrue对象给客户端。
2、Future
主动对象模型是一种异步模式,任务的提交和执行是分离的,而且任务从提交到执行完成可能需要较长时间,甚至是不固定,那客户端发完请求后要怎么才能知道任务的执行结果呢?Futrue实例其实就是用来获取执行结果的。客户端提交任务后,Proxy会立马返回一个Futrue对象。客户端拿到这个对象,需要时就可以通过Futrue对象来获取任务执行结果。任务从提交到返回Futrue的过程如下图所示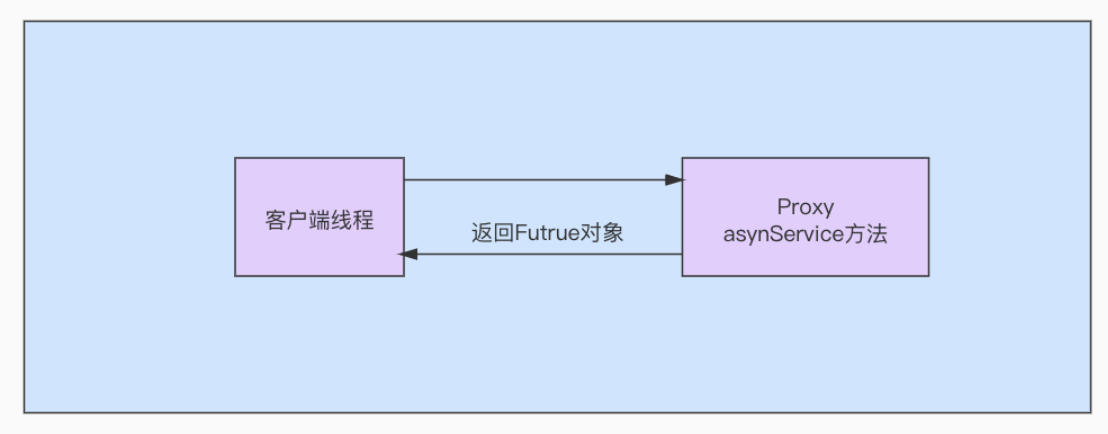 :
:
3、MethodRequest
在请求发给Proxy时,Proxy不会直接处理这个请求,而是会将请求参数等上下文信息封装为一个MethodRequest对象。MethodRequest对象中包含了一个核心方法call。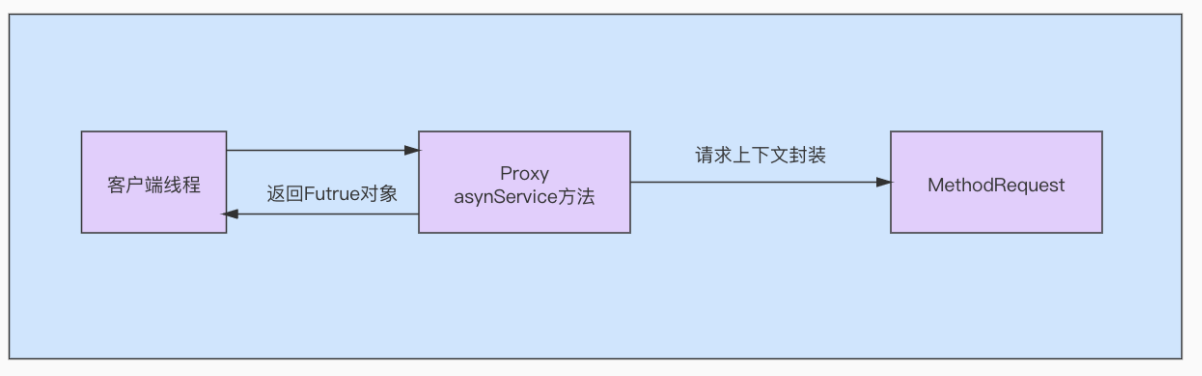
4、ActivationQueue
ActivationQueue即任务缓冲区,是Active Object模式中的另一个重要组件。当请求太多了超过工作线程处理上限,就将任务先放进这个缓冲区中。等待工作线程有空闲时再从缓冲区中读取出任务来执行。
5、Scheduler
Scheduler即调度器。Active Object模式,是一种异步编程模式,会将方法的调用和执行分开,但是什么时候执行,如何执行,这个其实不是由任务提交者(客户端)来控制的,而是通过调度器来控制。
6、Servant
Servant实现了Proxy所暴露的异步方法。并且负责执行Proxy所暴露的异步方法对应的任务。 任务是在Proxy处提交,但真正执行是在这里。执行完成之后,会将执行结果绑定到Futrue实例上。。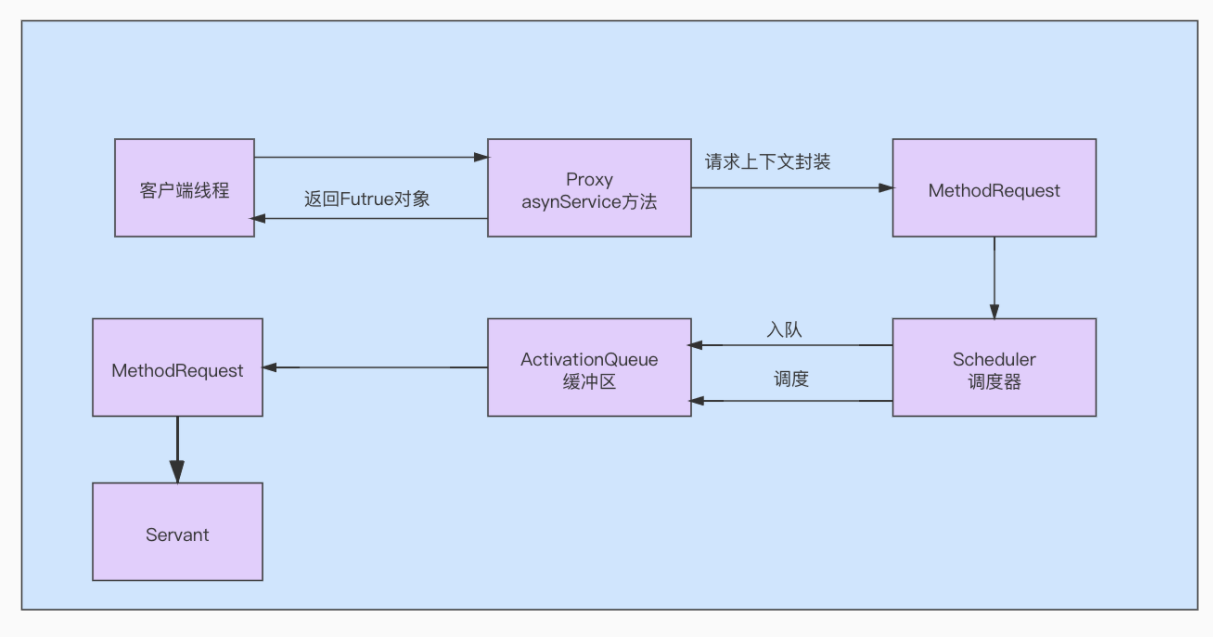
Active Object在线程池体现
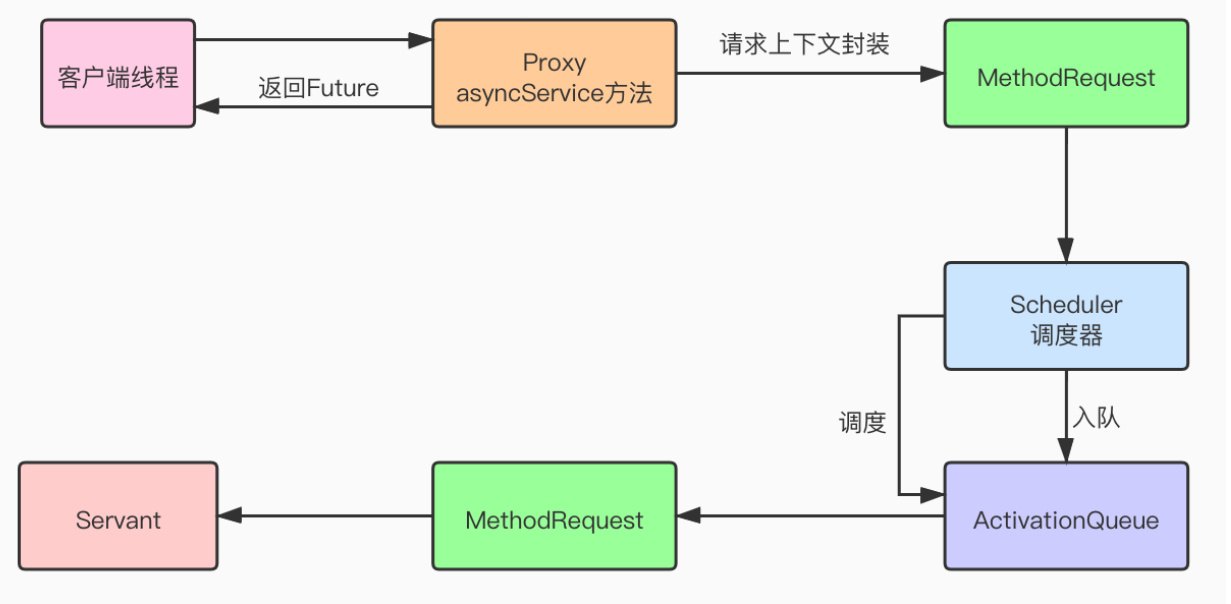
1.Proxy 任务提交
Proxy中是要有asyncService这种异步调用方法,ThreadPoolExecutor就可以胜任这个工作。ThreadPoolExecutor继承了AbstractExecutorService,用的模板方法模式,因此提交任务可以另外几种方法去做
这几种方式,底层对应的逻辑都是一样。最终都会调用execute(Runnable command)方法,剩下几个方法都是对这个方法的封装。
public
Future submit(Callable task) public Future<?> submit(Runnable task) public Future submit(Runnable task, T result)
2.返回futrue对象
在主动对象模式中,如果你需要返回值,那提交之后就可拿到一个Futrue对象。在线程池中如果你需要返回值,就将任务封装为Callable对象提交,然后可以拿到一个Futrue对象。
3.MethodRequest 任务请求封装
使用线程池,一般需要将任务封装为Runnale或者Callable对象,那Runnale或者Callable类就是 MethodRequest的实现。
4.ActivationQueue缓冲区
在jdk提供的几种常用线程池中:fixedThreadPool和singleThreadExecutor用的LinkedBlockingQueue; cachedThreadPool用的是SynchronousQueue。也可以自定义queue都可以
5.Scheduler调度
具体的就是之前分析过的ThreadPoolExecutor中execute方法的执行逻辑。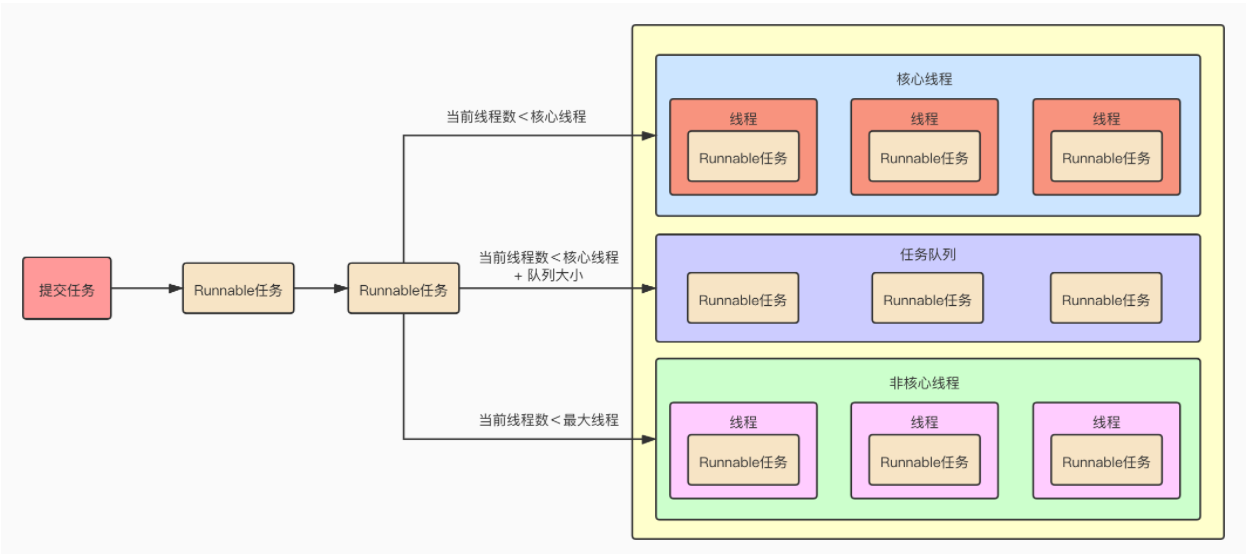
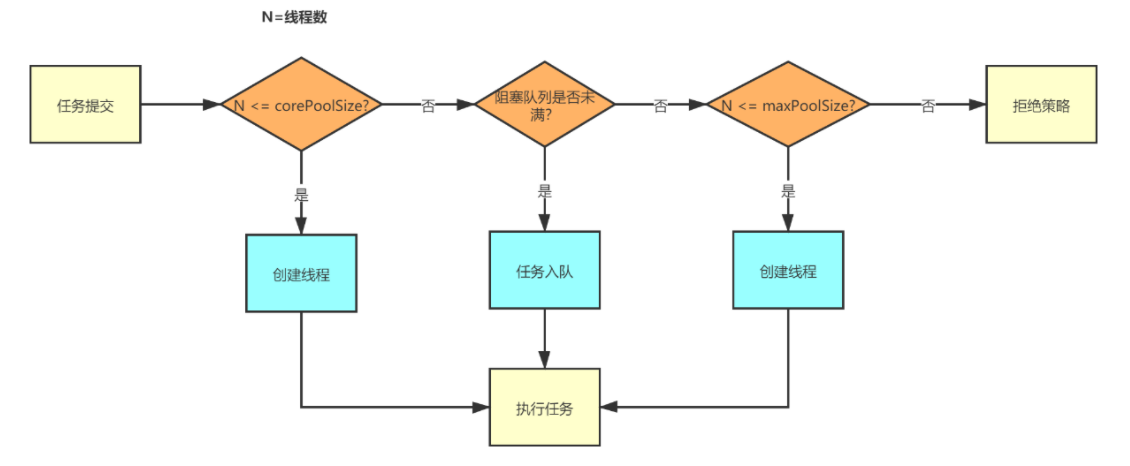
线程池工作原理之源码分析
任务提交
任务都是由execute或者submit提交,而submit最终也会调用到execute方法,因此以execute来进行分析
1&2:判断一下线程池中运行的线程个数(workerCountOf(c))是否小于corePoolSize,如果满足条件就调用addWorker(command, true)方法去执行任务。这个方法实际上最终就是开启了新的线程去执行任务。
3.如果说线程池处于RUNNING状态,也就是isRunning(c)返回true,那么就将任务添加到阻塞队列。也就是执行workQueue.offer(command)。
4&5:为了确保能够准确的将任务添加成功,线程池在这里做了二次校验,看这个线程池是否活着。这里是因为,如果将任务添加到线程池之后,有可能线程池状态已经变化了,所以要校验一下,看看当前的线程池状态还是不是RUNNING。
6.检查这个recheck通过wokerCountOf去换算一下同时和0比较,看一下当前线程池里面是不是一个可用的线程都没有,没有的话就要通过addWorker去创建一个工作线程。
7.在执行[3]的时候对任务进行添加,如果添加失败就说明任务队列已经满了。这个时候只要queue任务还是满的就要去创建新的worker线程了,如果addWorker失败了那么意味着worker线程数已经达到设置的最大线程数了,此时就能进入这个判断的代码块了。就开始执行这个reject方法(拒绝策略)。
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
1. int c = ctl.get();
2. if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
3. if (isRunning(c) && workQueue.offer(command)) {
4. int recheck = ctl.get();
5. if (! isRunning(recheck) && remove(command))
reject(command);
6. else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
7. else if (!addWorker(command, false))
reject(command);
}
工作线程创建,启动流程
大致流程可以这么说,线创建woker线程,随后将自己的线程去启动。
1.声明了一个Worker线程,并把它持有的thread成员变量的引用,赋值给final修饰的Thread t临时变量,然后判断t是否是alive状态。如果是,那么就抛出一个IllegalThreadStateException异常,因为已经启动了,就再无需启动了。
2.将这个新的Worker线程添加到工作线程集合中,并设置WorkerAdded状态变量为true。
3.校验WorkerAdded状态变量为true成立,就通过start()方法启动工作线程。
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
//做一些判断,看是否可以去执行任务或者添加工作线程。
for (;;) {
...省略
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
1. w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
2. workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
3. t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
工作线程执行任务流程
woker是一个实现了Runnable接口的内部类,执行方法一定是在run方法中。
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
1. Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
2. while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
3. task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
1.将工作线程对象中的任务给一个引用
2.从队列中获取程序里提交的任务,这里要注意getTask()方法,while条件正是通过这个方法作为条件来判断当前worker线程是不是要关闭。
可以看到Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :workQueue.take(); 这一行就是用于获取queue的队列的。
首先存在一个参数timed这个参数的值由( int wc = workerCountOf(c);boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;)决定,一个是allowCoreThreadTimeOut 参数:含义是,如果为false(默认值),即使在空闲时核心线程也会保持活动。如果为true,核心线程使用keepAliveTime超时等待工作。另一个是当前线程数是否大于核心线程数。
可以发现这里有一个keepAliveTime参数。当timed为true时,也就是当前线程数大于核心线程数或者allowCoreThreadTimeOut 为true,这个keepAliveTime才能被用上。当keepAliveTime的时间过后就会返回null。也就是说当前线程取不到任务执行了,那么当前这个worker线程就可以开始走线程退出的流程了。
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// Are workers subject to culling?
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
//获取任务队列的任务
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
3.启动这个任务线程
Worker线程退出流程
在runWorker的流程中,当执行任务的while循环跳出后,就会进入线程清理的流程processWorkerExit(w, completedAbruptly);
- 统计在执行线程退出之前,线程池会先统计池子里完成任务的数量,然后通过workers.remove(w)把当前这个worker移除掉。要注意的是在统计之前加了全局锁,保证统计的准确性。
- 如果当前线程池状态是SHUTDOWN状态并且工作队列已经为空,或者当前线程池已经是STOP状态,或者说当前线程池中没有活动的线程,则尝试对线程池状态设置为TERMINATED。
- 如果线程池状态为
SHUTDOWN或RUNNING,
此时有两种情况:
(1)worker是不正常的退出,就直接要去添加一个worker补上去
(2)woker正常退出。分两种情况,由allowThreadTimeOut决定。如果它为false,同时阻塞队列中还有任务。那么就要判断下当前线程池中的线程是否大于等于1,不满足这个判断就要新增一个worker线程进去执行任务。如果allowThreadTimeOut为true,就要判断下当前池内的线程是否大于等于核心线程数,如果不大于就要新增worker线程进去。
private void processWorkerExit(Worker w, boolean completedAbruptly) {
if (completedAbruptly) // If abrupt, then workerCount wasn't adjusted
decrementWorkerCount();
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
1. completedTaskCount += w.completedTasks;
workers.remove(w);
} finally {
mainLock.unlock();
}
2. tryTerminate();
int c = ctl.get();
3. if (runStateLessThan(c, STOP)) {
//completedAbruptly 外部方法runWorker中,工作线程执行任务的时候是否正常退出while循环 completedAbruptly=false为正常 ,不正常退出的时候这个worker一定是有问题的,就要重新添加worker
if (!completedAbruptly) {
//正常退出后就要进入这个逻辑
//线程是否超时allowCoreThreadTimeOut是超时标记 fasle的话最小线程就是corePoolSize,true就是0
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
//也就是说非核心线程数超时的话,同时任务队列还有任务,那当前这个worker是不能停止工作的,因此就要去设置一个最小的min
if (min == 0 && ! workQueue.isEmpty())
min = 1;
//判断线程池中还有没有线程可以继续去执行这个任务,有线程的话当前的worker就可以顺利停止工作了
if (workerCountOf(c) >= min)
return; // replacement not needed
}
//worker执行异常了,直接重新添加一个worker进去。
addWorker(null, false);
}
}
自定义线程池
合适的线程数&CPU核心数和线程数
在cpu执行任务的时候存在两种类型的任务一个时CPU密集型一个是I/O密集型的任务
CPU密集型:
例如解压,解密,加密操作就是比较耗费cpu资源的操作,对于这种类型的任务应该设置的线程数量是cpu核心数的1-2倍,过多设置并不会有更好的效果,因为每个线程在处理的时候要耗费大量的CPU资源,每个核心都是满负载在工作,并且在调度线程的时候也需要耗费资源,那么过多的线程就会造成cpu资源的浪费。
I/O密集型任务:
例如对数据库的读写,文件读写,网络通信这些任务,它们都是要求线程去等待任务完成的。相比CPU密集型任务,I/O密集型任务在执行过程中由于等待I/O结果花费的时间要明显大于CPU计算所花费的时间,而且处于I/O等待状态的线程并不会消耗CPU资源,因此可以多设置一些线程。在这种情况下最大线程数一般会大于CPU核心的很多倍。
核心线程数不用设置的很大,原因在于I/O操作本身会导致上下文切换的发生,尤其是阻塞式I/O。因此建议将I/O密集型的核心线程数corePoolSize限制为1,最大线程数maximumPoolSize设置为N(CPU个数)*2。当线程池中只要一个线程的时候,能够从容应对提交的任务,此时的上下文切换相当少。然后随着任务逐渐增加,再慢慢的增加线程数量至最大线程数。这样做既不浪费资源,还很灵活的支持了任务增加的场景。
合理设置线程数:线程数 = CPU 核心数 (1+平均等待时间/平均工作时间)(摘自并发编程实战)
*总结:
线程的平均工作时间所占比例越高,就需要越少的线程;
线程的平均等待时间所占比例越高,就需要越多的线程;
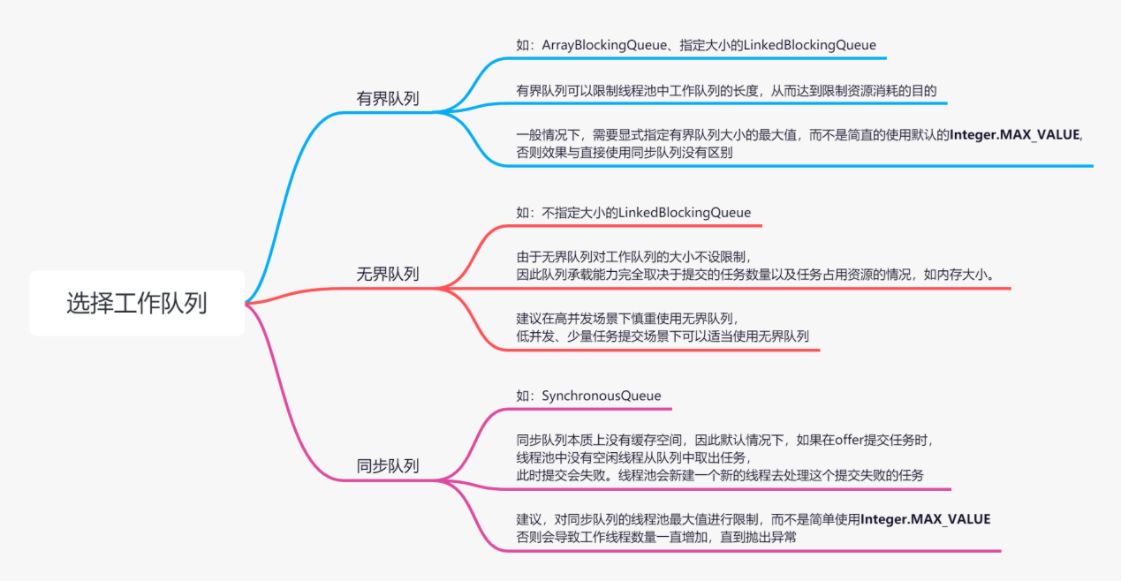
工作队列选择
自定义线程工厂
给自定义的线程池起一个个性化的名字,这有助于我们在查找日志的时候精确的定位到具体的某个线程池。
实现ThreadFactory接口,重写方法即可。同时netty和tomcat也都有自定义的线程工厂实现。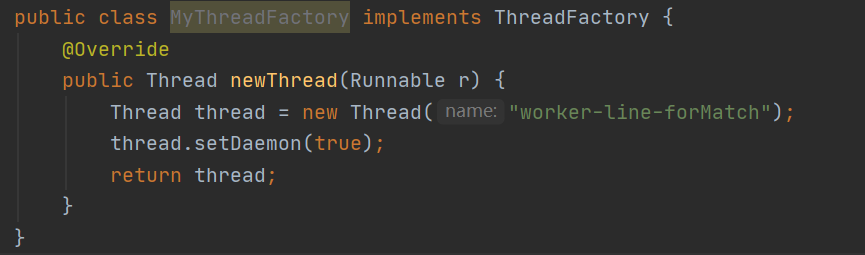

若有收获,就点个赞吧
0 人点赞
