为什么要优化?
初始化的时候会启动两个线程,首先会去拉取全量注册表,随后再去拉取增量注册表。
首先在启动线程这里没有做任何的操作,也就是说这两个线程是并发的,即使全量注册表数据没有拉取完毕,拉取增量注册表的线程也开始运行了,如果全量表的数据很多,就会发生这两个线程同时给客户端的缓存注册表变量赋值。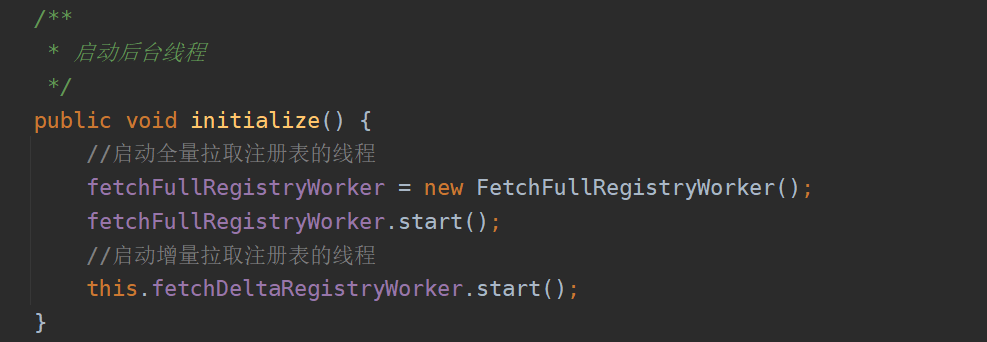
全量拉取线程赋值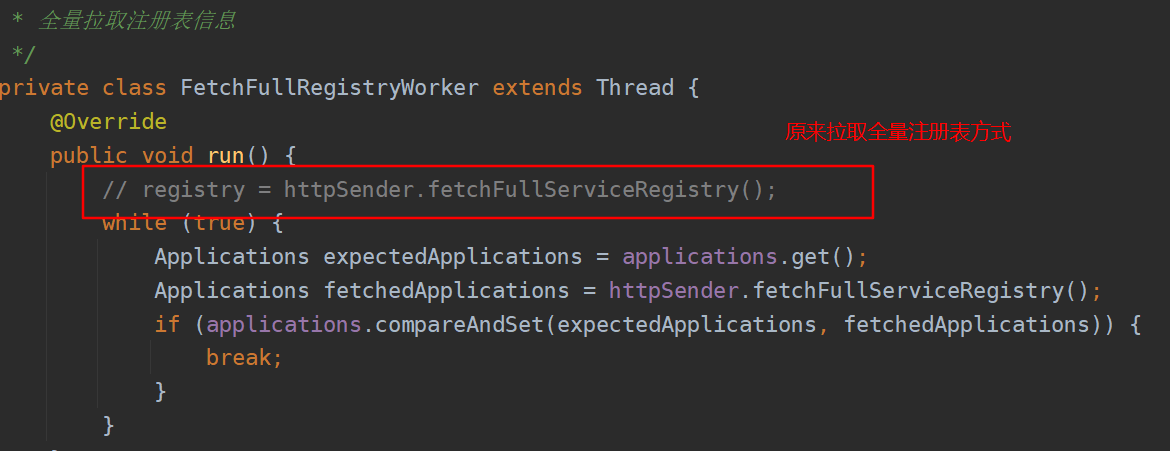
增量拉取注册表信息线程校验的时候赋值操作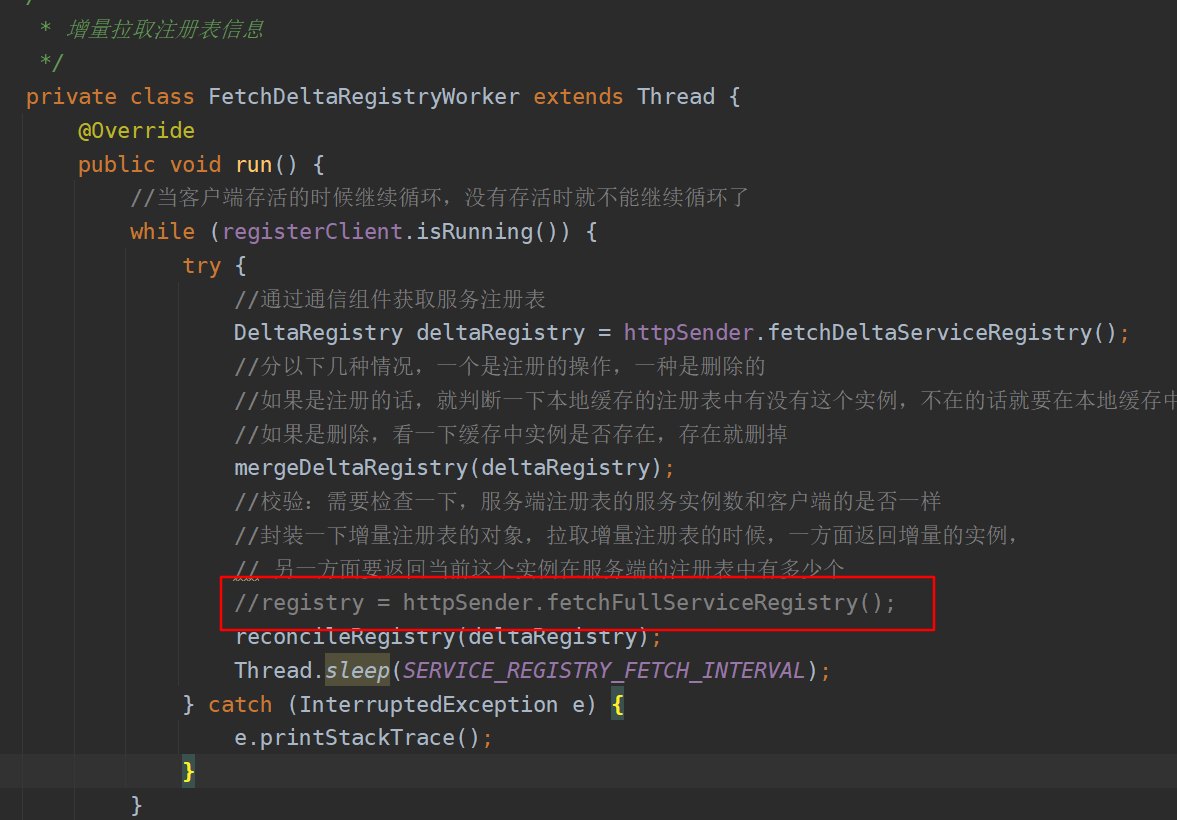
之前学了一个方法就是调用join,这种方法好吗?显然就是不好的,如果FetchFullRegistryWorker调用了join,这两个线程不就成串行化了,效率就比较低了。
因此,由于是针对一个变量的引用去赋值的操作,那么就可以使用AtomicReference去包裹一下缓存注册表变量,赋值的时候调用compareAndSet方法。由于这个操作是原子的,cas无锁的效率就会很高。(AtomicInteger针对变量做cas,AtomicReference针对对象的引用做cas)
实现
- 封装客户端缓存注册表变量
为了优化一部分代码,就把这个缓存注册表变量再次包装了一层
/*** 完整的服务实例信息*/public class Applications {private Map<String, Map<String, ServiceInstance>> registry = new HashMap<String, Map<String, ServiceInstance>>();public Applications() {}public Applications(Map<String, Map<String, ServiceInstance>> registry) {this.registry = registry;}public Map<String, Map<String, ServiceInstance>> getRegistry() {return registry;}public void setRegistry(Map<String, Map<String, ServiceInstance>> registry) {this.registry = registry;}}
- 用AtomicReference包裹Applications
/***客户端缓存的所有服务实例的信息*/private AtomicReference<Applications> applications =new AtomicReference<Applications>(new Applications());

若有收获,就点个赞吧
0 人点赞
