1.7如何加锁
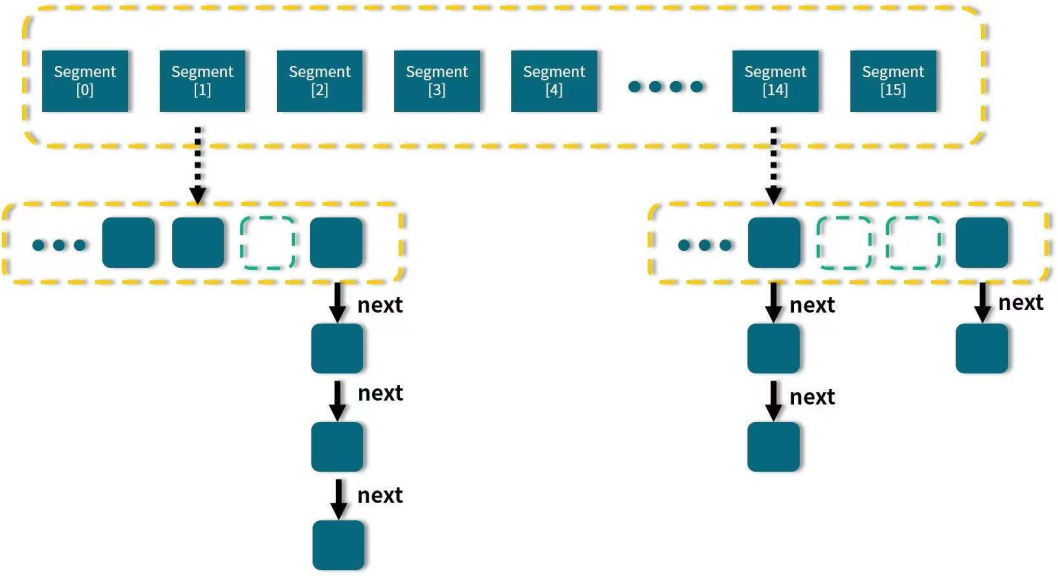
1.7的ConcurrentHashMap是用segment来加锁,16个Segment,16个分段,每个Segment对应Node[]数组,每个Segment有一把锁,也就是说对一个Segment里的Node[]数组的不同的元素如果要put操作的话,其实都是要竞争一个锁,串行化来处理的。
锁的粒度是比较粗的,因为一个Node[]数组是一把锁,但是他有多个Node[]数组。默认0-15一共16个segment,最多可以支持16个线程的并发操作。Segment[]的长度默认是16,可以在初始化的时候指定长度,长度最终是一个2的指数值,长度一旦确定就不能更改。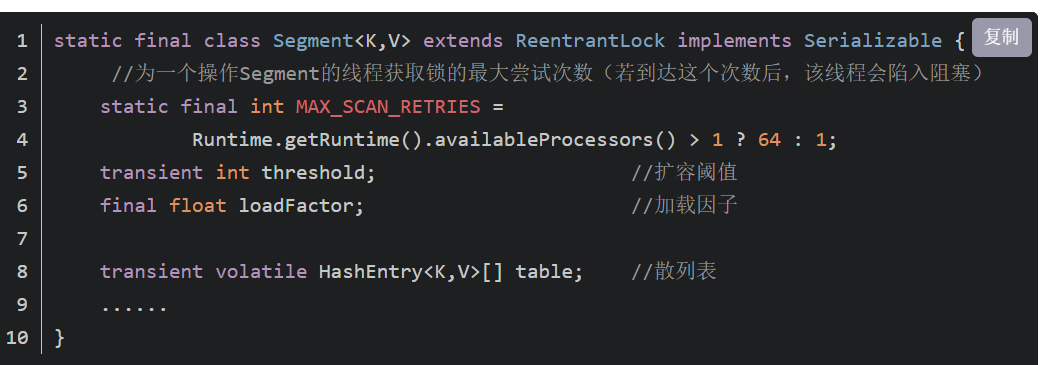
1.8如何优化
JDK 1.8的ConcurrentHashMap,把锁粒度细化,1.8里面就一个Node[]数组,正常会扩容的,但是他的锁粒度是针对的数组里的每个元素,每个元素的处理会加一把锁,不同的元素就会有不同的锁。大幅度的提升了多线程并发写ConcurrentHashMap的性能,降低了锁的冲突。同时,读的时候是不加锁,他通过volatile保证读到的一定是最新的数据。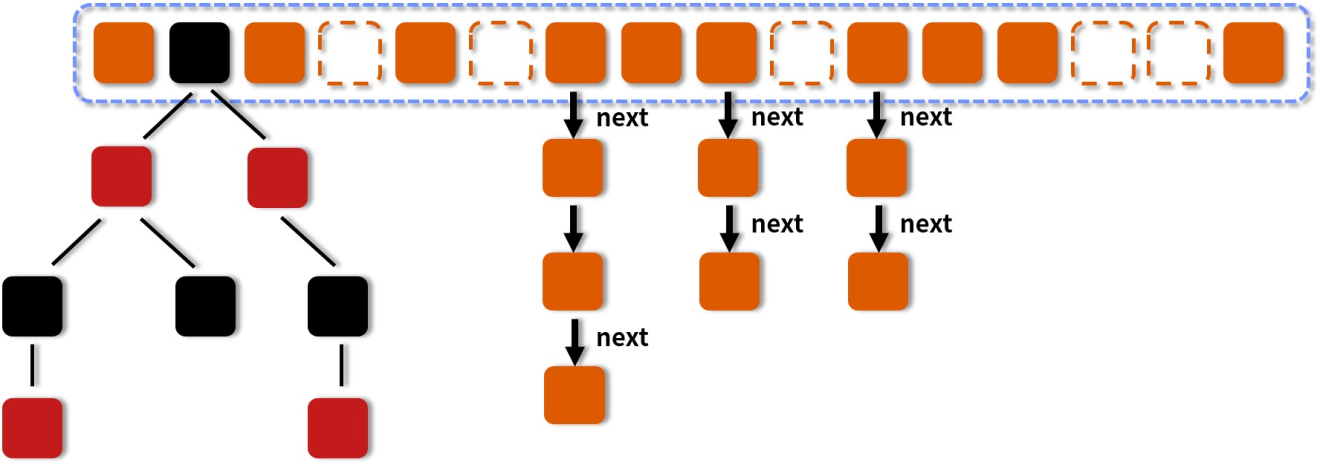

若有收获,就点个赞吧
0 人点赞
