final V putVal(K key, V value, boolean onlyIfAbsent) {if (key == null || value == null) throw new NullPointerException();int hash = spread(key.hashCode());int binCount = 0;//进入循环for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;if (tab == null || (n = tab.length) == 0)tab = initTable();else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {//cas放置元素if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; // no lock when adding to empty bin}else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);else {V oldVal = null;synchronized (f) {if (tabAt(tab, i) == f) {if (fh >= 0) {binCount = 1;for (Node<K,V> e = f;; ++binCount) {K ek;if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);break;}}}else if (f instanceof TreeBin) {Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}}}addCount(1L, binCount);return null;}
初始化数组&put元素操作的cas操作
- int hash = spread(key.hashCode()); spread算法计算出一个hash值来

- 初始化数组 if (tab == null || (n = tab.length) == 0) tab = initTable(); 如果tab是空的就要初始化一个数组
- SIZECTL就是sizeCtl的偏移量,把这个偏移量设置成-1,代表当前线程在初始化
- 进入判断,因为当前数组是空的
- 此时sc=-1,因此取默认值,也就是默认的数组容量
- 构造一个nt数组
- 把这个nt赋值给ConcurrentHashMap中真实的table数组
- sc = 16-(16 >>> 2) 这个sc就是12,也就是那个阈值,数组长度*0.75
- 计算的阈值设置给sizeCtl,sizeCtl这个值用于表的初始化和控制扩容的变量 ```java /**
- 表初始化和调整大小控制。
- 当sizeCtl为负数时,表被初始化或调整大小:
- -1:用于初始化。
- -(1 +正在扩容的线程数):表示有1+N个线程正在扩容
- 否则,当table为null也就是未初始化时,表示table需要初始化的大小。
- 初始化后,保存下一个元素计数值,根据该值调整表的大小(这就是table大小的0.75倍就是那个阈值)。 */
private final Node
3. 此时,数组初始化完毕,进入下一轮循环。就该进入else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) 这个判断。
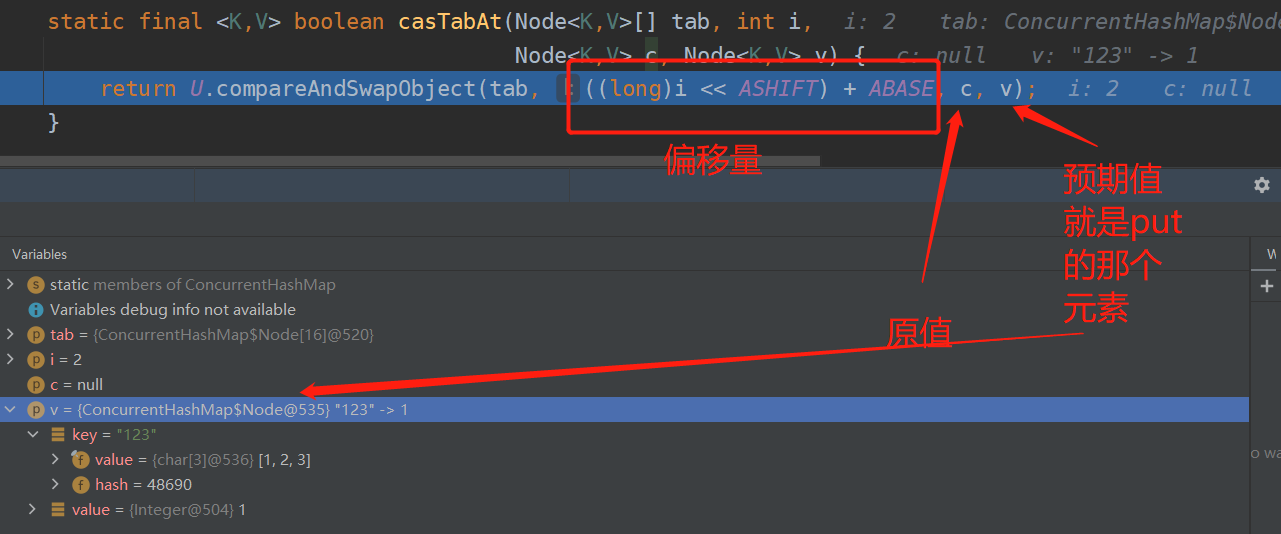
1. 拿到初始化的数组和put的key的hash值,通过unsafe类去获取一下那个位置的元素。

4. casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null);通过cas操作把put的那个值封装成node放入数组中
<br />到这里,初始化数组和put的流程就结束了,为什么说ConcurrentHashMap是线程安全的,首先的一点就是put的操作以及sizeCtl变量的操作都是通过cas来进行赋值,无锁化机制保证线程安全,同时性能比java层面的锁要高。
<a name="Vk5r4"></a>
# 当put的时候cas失败了怎么办
此时,其实就是casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))失败了,就是两个线程同时cas一个线程cas放置元素失败了,然后下面的else if都不走了。<br />下一步,就会进入下一轮循环。此时,红框if条件就不成立了,因为cas都失败,肯定有线程先一步往这个位置上放元素了。下一个else if 里面的判断,由于目前的情景是处理hash冲突问题这块先不考虑,这块实际上是控制并发扩容的核心地方,目前是条件是不成立的。<br />
> **初步体现分段加锁思想(cas):**
> 到现在这块,就已经初步体现出分段加锁的机制,其实就是没有对一个大的table数组做synchronized,仅仅是对那个位置的元素做互斥的操作,别的线程访问table数组的其他元素的时候是不会卡住的。cas不成功后再次进入for循环去把元素put进去。
> 现在的数组大小是16,意味着就可以16个线程过来,他们分别操作里面的16个元素的时候是并发的。可以理解成里面有多少个元素就有多少把隐式的锁,只有多个线程操作一个元素的时候才会出现线程互斥的情况。
现在就会进入下面的代码块。<br />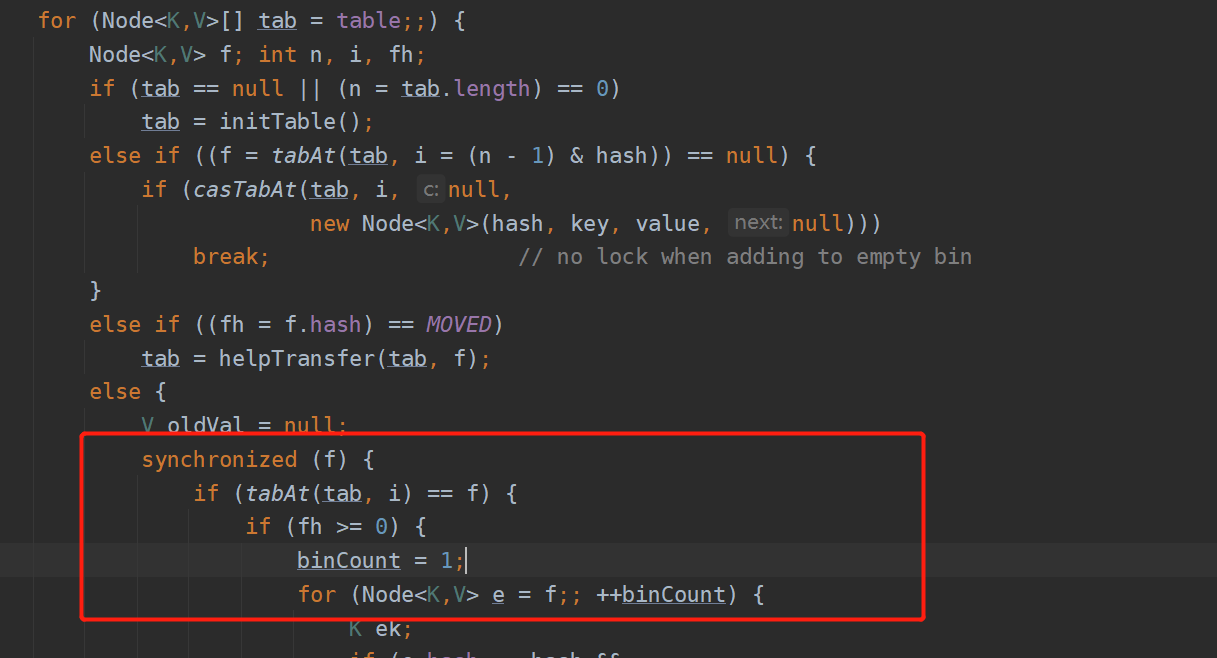<br />其实这里出现hash冲突的时候,同样是使用的链表加红黑的数据结构去解决哈希冲突的。
> **synchronized分段加锁思想:**
> 那么这里的重点是什么?就是分段加锁,synchronized (f),这个f变量就是else if ((f = tabAt(tab, i = (n - 1) & hash)) == null)这里获得的。这个就是所谓的JDK 1.8里的ConcurrentHashMap分段加锁的思想,淋漓尽致的体现,他仅仅就是对数组这个位置的元素加了一把锁而已
**开始处理hash冲突:**
```java
else {
V oldVal = null;
//对有冲突的位置上的元素加锁
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
//辅助变量
K ek;
//冲突位置上那个元素的hash值和新put的元素key的hash值一样否
//然后比对一下key值一样不,同时再用equals对比一下是键是否是同一个对象
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
//put的新值覆盖上去
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
//上面的if条件不成立,意味着要做链表处理了
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
//当节点是一个树节点,就应该做一些树的处理
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
//转红黑树
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
e.hash == hash &&
((ek = e.key) == key ||<br /> (ek != null && key.equals(ek)));1.用冲突位置上那个元素的hash值和新put的元素key的hash值一样否 2.然后比对一下key值一样不,同时再用equals对比一下是键是否是同一个对象 1&2都成立,意味着put的key是和那个位置上的key是一样的,就要覆盖
else if (f instanceof TreeBin)
当节点是一个树节点,就应该把元素添加到树上去
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)<br /> treeifyBin(tab, i);<br /> if (oldVal != null)<br /> return oldVal;<br /> break;<br /> }如果一个链表的元素的数量超过了8,达到了一个阈值之后,就会将链表转换为红黑树。如果转换为红黑树以后,下次如果有hash冲突的问题,是直接把key-value对加入到红黑树里去
扩容机制
就是在put操作的时候有个方法,addCount(1L,binCount);这里做了扩容。
里面有一个transfer方法,具体扩容图解如下
https://blog.csdn.net/ZOKEKAI/article/details/90051567?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163586071416780255296041%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=163586071416780255296041&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-90051567.pc_search_es_clickV2&utm_term=concurrenthashmap%E6%89%A9%E5%AE%B9&spm=1018.2226.3001.4187
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
//扩容
transfer(tab, null);
s = sumCount();
}
}
}

若有收获,就点个赞吧
0 人点赞
