表引擎
ReplicatedMergeTree: 复制表,复制粒度为表级别,通过zk协调不同副本表间的数据
Distributed: 分布式表,本身不存储数据,通过创建分布式表链接到其它表上。类似于ELaticsearch,有分片
的概念,数据存储在不同的分片上,通过搜索Distributed表聚合所有shards表上的数据返回
配置文件
Clickhouse主要的配置文件有config.xml和metrika.xml,config-preprocessed.xml为启动
clickhouse生成的文件。

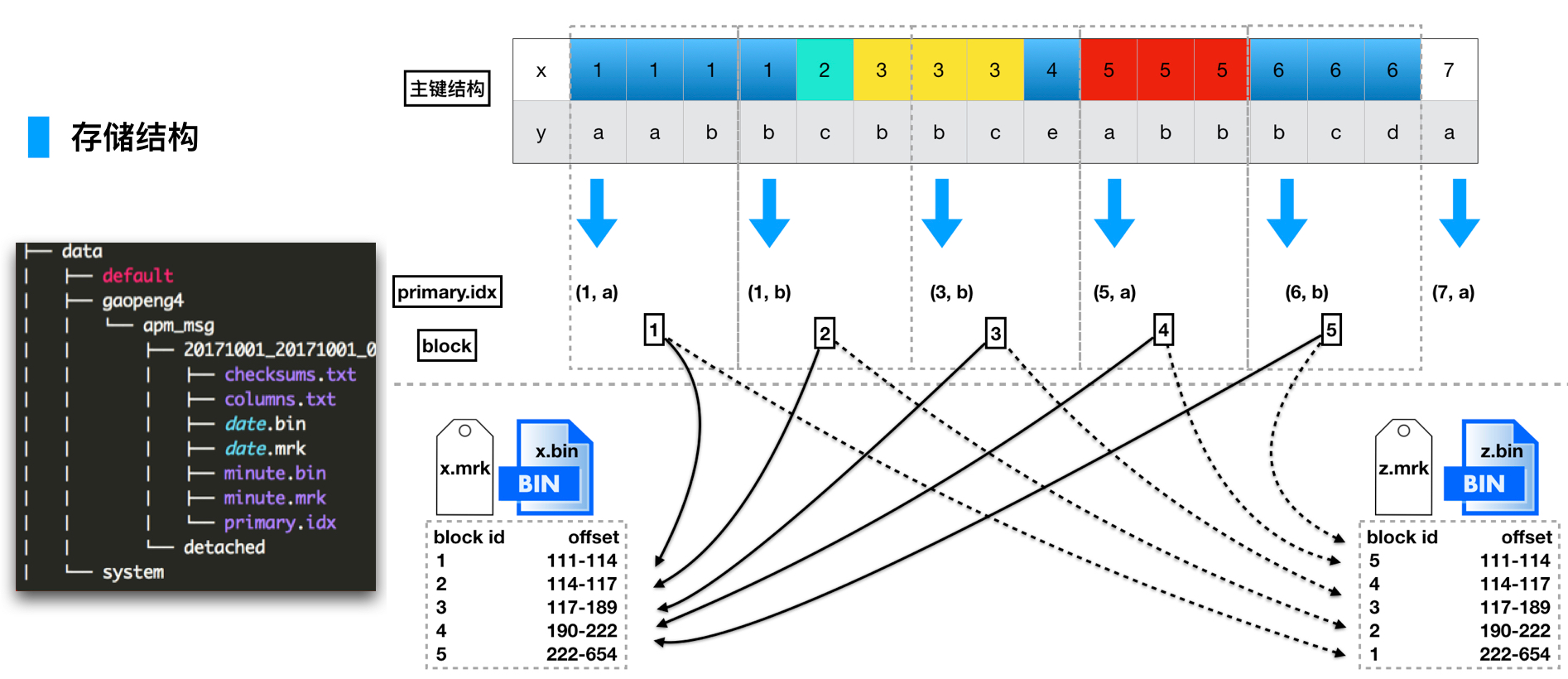
一 数据目录
Data目录 数据存储目录,数据按照part分成多个文件夹,每个文件夹下存储相应数据和对应的元信息文件
Metadata 表定义语句存储所有表的建表语句
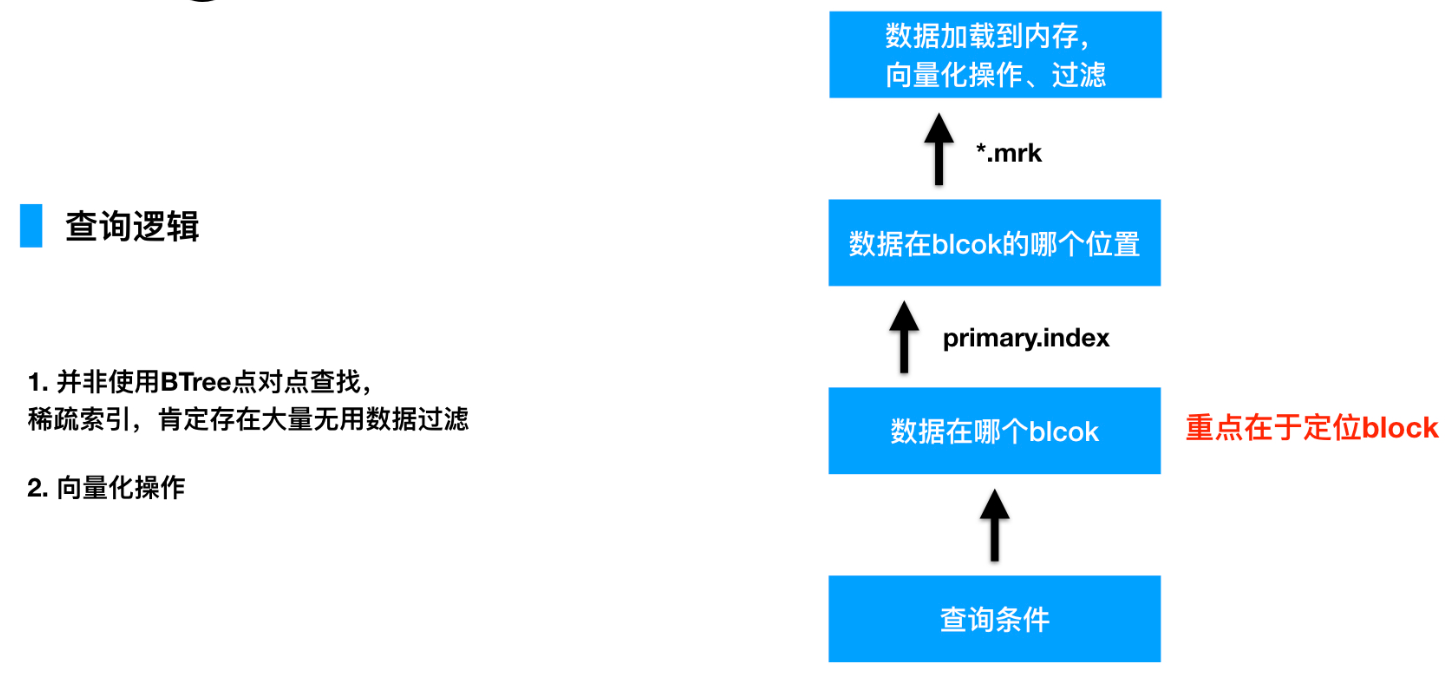
二 基本原理
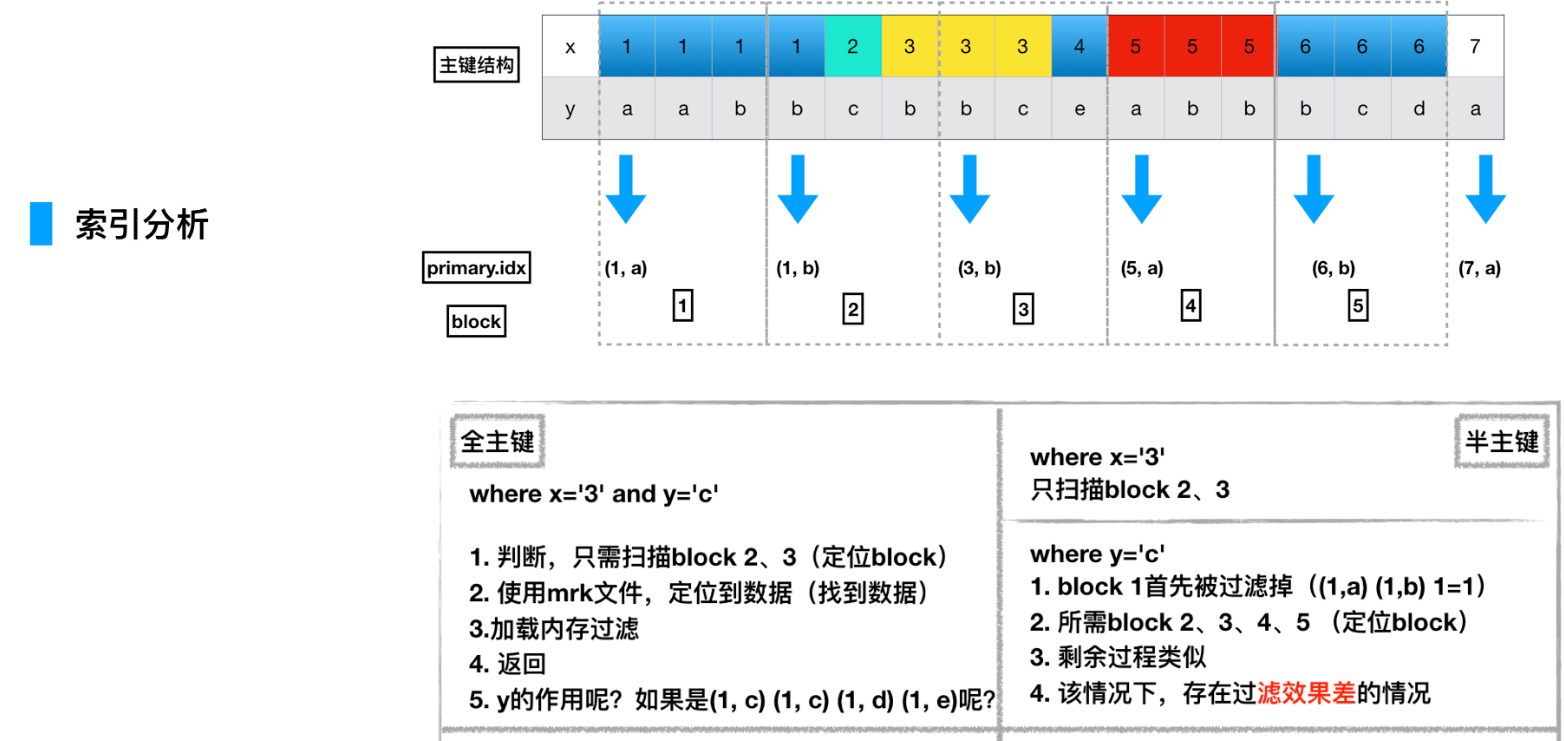
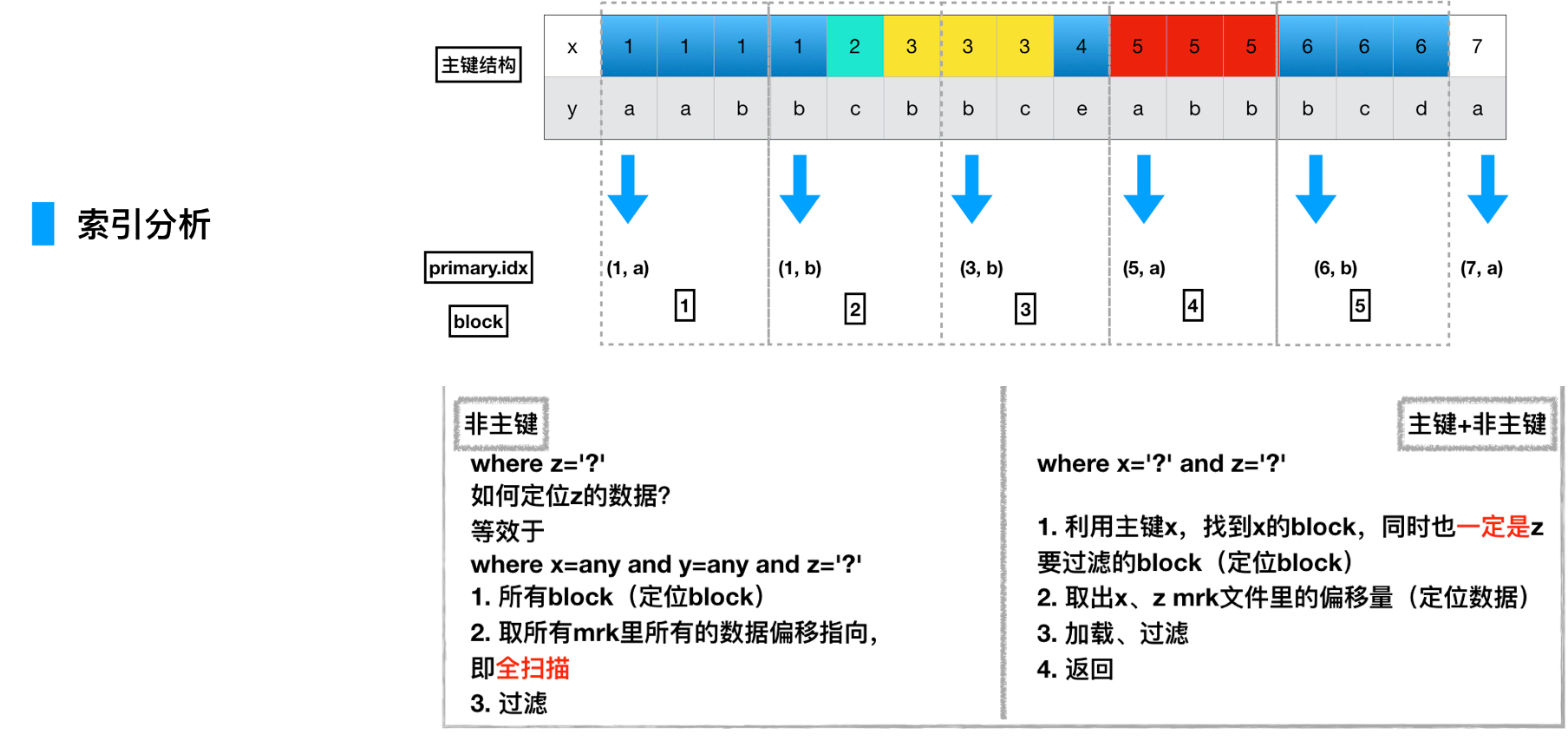
记录方式:每隔8192行数据,是1个block,主键会每隔8192,取一行主键列的数据,同时记录这是第几个block
查找过程:如果有索引,就通过索引定位到是哪个block,然后找到这个block对应的mrk文件,mrk文件里记录的是某个block的数据集,在整列bin文件的哪个物理偏移位加载数据到内存,之后并行化过滤
构成图如下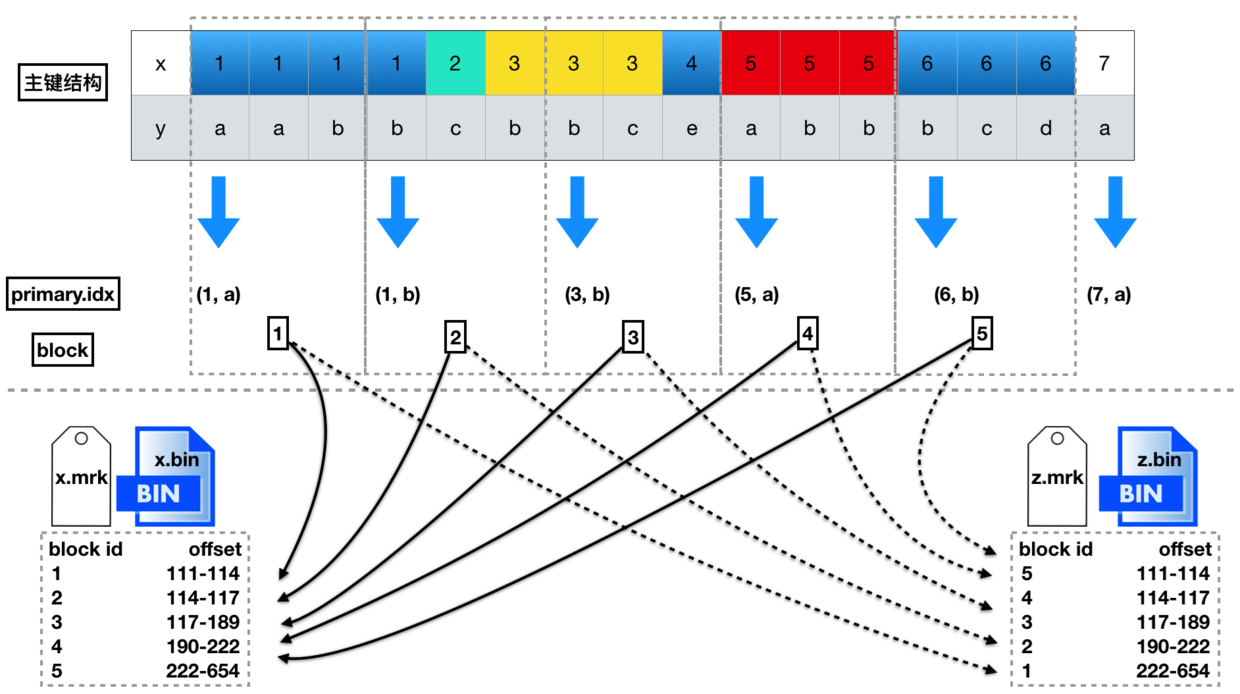
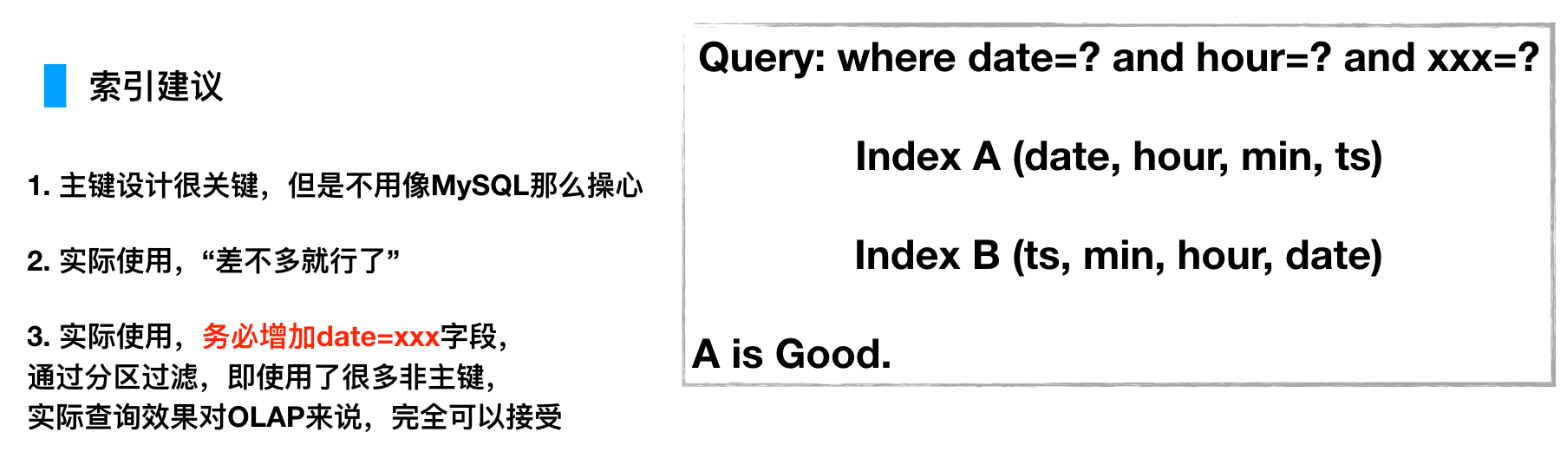
https://www.jianshu.com/u/3976aaeb39bb
https://www.jianshu.com/p/d95df0aee9fa

若有收获,就点个赞吧
0 人点赞
