拆分索引
如果业务上有大量的查询上基于一个字段进行Filter,该字段又上一个数量有限的枚举值
- 例如订单所在地区
如果在单个索引又大量的数据,可以考虑将索引拆分成多个索引
- 查询性能可以得到提高
- 如果要对多个索引进行查询,可以在查询中指定多个索引得以实现
如果业务上有大量的查询上基于一个字段进行Filter,该字段数值并不固定
可以启用routing功能,按照filter字段的值分布到集群中不同的shard,降低查询相关的shard,提高cpu使用率
容量规
一个集群需要多少个节点?一个索引需要设置成几个分片?
规划需要保持一定的预留,以应对当负载出现波动,节点掉线时,集群还能正常运行
其他因素
- 机器的软硬件配置
- 单条文档的尺寸/文档总数据量/索引的总数据量(Time base数据保留时间)/副本分片数
- 文档如何写入(bulk尺寸)
-
评估业务的性能需求
数据吞吐及性能的需求
数据写入的吞吐量,每秒要求写入多少数据?
- 查询的吞吐量?
-
了解业务数据
数据的格式和数据的Mapping
-
常见用例
搜索:固定大小的数据集,数据增长相对较缓慢
例如产品信息
特性:
被搜索的数据集很大,但是增长相对较慢,不会又大量的写入,更关系搜索和聚合的读取性能
数据的重要性与时间范围无关,关注的是搜索的相关度估算索引的数据量,然后确定分片的大小
单个分片的数据不要超过20GB
可以通过增加副本分片提高查询的吞吐量
日志:基于时间序列的数据使用ES存放日志与性能指标,每天数据不断写入,增长速度较快
- 结合warm node做数据的老化处理
- 相关案例日志/指标/安全事件/舆情分析
特性:
每条数据都有时间戳,文档一旦创建基本不会被更新
一般更多查询近期的数据,对旧数据的查询相对较少
对数据的写入性能要求比较高创建基于时间序列的索引
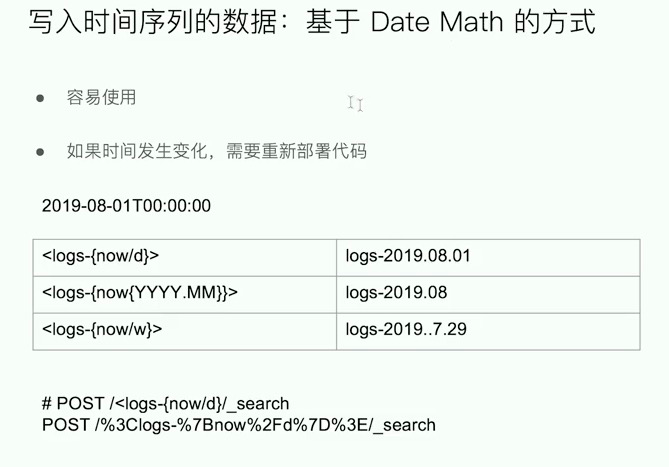
在索引名字中增加时间信息
按照每天/每周/每月的方式进行划分
好处:更加合理组织索引,例如随着时间推移,便于对索引做老化处理
利用hot & warm架构
备份和删除的效率高(delete by query执行速度慢,底层也不会立即释放空间,而merger)硬件配置
选择合理的硬件,数据节点尽可能使用SSD
搜索等性能要求较高的场景,建议SSD,按照1:10的比例配置内存和硬盘
日志类和查询并发较低的场景,可以考虑使用机械硬盘存储,按照1:50的比例配置内存和硬盘
单节点的数据建议控制在2TB以内,最大不建议超过5TB
JVM配置机器内存的一般,不超过32G部署方式
如果需要考虑可靠性高可用,建议部署3台master节点
如果又复杂的查询和聚合,建议设置coordinating节点集群扩容
增加coordinating/ingest node解决cpu和内存开销的问题
增加数据节点
解决存储容量的问题
为避免分片分布不均的问题,监控磁盘空间(70%),提前清理数据或者增加节点


若有收获,就点个赞吧
0 人点赞
