Development vs Production Mode
从ES5开始,支持生产和开发两种模式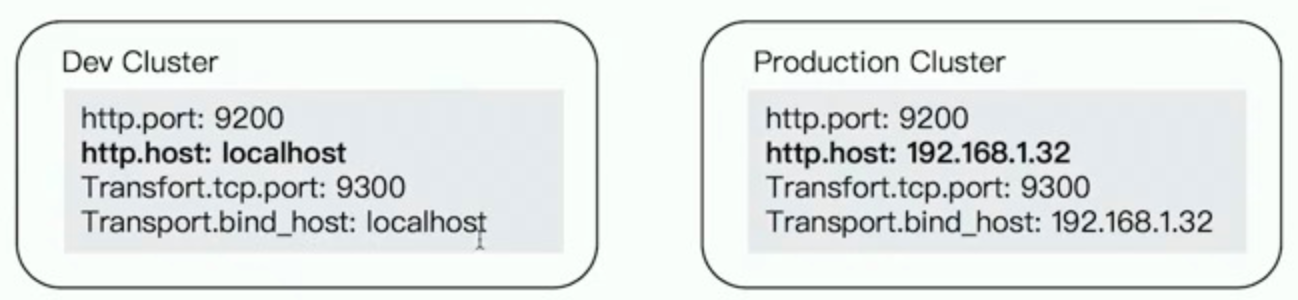
Bootstrap Checks
一个集群在Production Mode时,启动时必须通过所有Bootstrap检测,否则会启动失败
Bootstrap检测分为两类:JVM&Linux Checks(只针对Linux系统)
https://www.elastic.co/guide/en/elasticsearch/reference/master/bootstrap-checks.html
JVM设定
从ES6开始,只支持64位的JVM
配置文件config/jvm.options
避免修改默认配置
将内存Xms和Xmx设置成一样,避免heap resize时引发停顿
Xmx设置不要超过物理内存的50%;单个节点上,最大内存不超过32G
https://www.elastic.co/cn/blog/a-heap-of-trouble
生产环境,JVM必须使用Server模式
关闭JVM Swapping
集群API设定
静态设置和动态设定
静态配置文件尽量简洁:按照文档设置所有相关的系统参数,elasticsearch.yml配置文件中尽量只写必备参数。
其他设置想可以通过API动态进行设定,动态设定分transient(临时)和persistent(永久)两种,都会覆盖elasticsearch.yml配置文件中的设置
系统设置
https://www.elastic.co/guide/en/elasticsearch/reference/master/system-config.html
最佳实践网络
单个集群不要跨数据中心进行部署(不要使用WAN)
节点之间的hpos越少越好
如果有多块网卡,最好将transport和http绑定到不同的网卡,并设置不同的防火墙Rules
按需为Coordinating Node或Ingest Node配置负载均衡
最佳实践内存
内存大小要根据Node需要存储的数据来进行估算
- 搜索类比例建议:1:16
- 日志类:1:48-1:96之间
总数量量1T,设置一个副本=2T总数据量
搜索类项目,每个节点3116=496G,加上预留空间。所以每个节点最多400G数据,至少需要5个数据节点。
日志类项目,每个节点3150=1550GB,2个数据节点即可。
最佳实践存储
推荐使用SSD,使用本地存储(Local Disk),避免使用SAN NFS/AWS/Azure filesystem
可以在本地指定多个“path.data”,以支持使用多块磁盘
ES本身提供很好的HA机制,无需使用RAID 1/5/10
可以在warm节点上使用SpinningDisk,但是需要关闭Concurrent Merges
index.merge.scheduler.max_thread_count:1
Trim SSD
https://www.elastic.co/cn/blog/is-your-elasticsearch-trimmed
最佳实践服务器硬件
建议使用中等配置机器,不建议使用过于强劲的硬件配置
不建议在一台服务器上运行多个节点
集群设置:
Throttles限流
为Relocation和Recovery设置限流,避免过多任务对集群产生性能影响
Relocation
cluster.routing.allocation.cluster_concurrent_rebalance:2
Recovery
cluster.routing.allocation.cluster_concurrent_recoveries:2
关闭Dynamic Indexes
可以考虑关闭动态创建索引功能
PUT _cluster/settings{"persistent": {"action.auto_create_index":false}}
或者通过模版设置白名单
PUT _cluster/settings{"persistent": {"action.auto_create_index":"log-*,.nginx*"}}
集群安全设定
为Elasticsearch和Kibana配置安全功能
打开Authentication&Authorization
实现索引和字段级的安全控制
节点间通信加密
使用HTTPS
Audit logs

若有收获,就点个赞吧
0 人点赞
