Elasticsearch集群重建索引的过程中,数据节点发生ekd-h1掉线,随即重新上线。集群JVM设置添加了参数,对full gc前后的head进行dump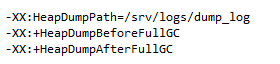
master节点日志显示ekd-h1掉线及上线时间点
[2018-10-22T08:18:38,463][INFO ][o.e.c.s.ClusterService ] [ekm-h0] removed {{ekd-h1}{wFBHutzXSA29FGogJmklTA}{t_7mlO7vRwu8Hijk6K6CVw}{ekd-h1}{10.163.146.77:9002}{ml.enabled=true},}, reason:zen-disco-receive(from master [master {ekm-h2}{XxqzcL6nRVqoO09A3aZ-nQ}{u7dPB6kRy-jJLBE-T5kAw}{ekm-h2}{10.163.144.227:9002}{ml.enabled=true} committed version [8054]])
……………………………………………………………………..
[2018-10-22T08:19:38,034][INFO ][o.e.c.s.ClusterService ] [ekm-h0] added {{ekd-h1}{wFBHutzXSA29FGogJmklTA}{t7mlO7vRwu8Hijk6K6CVw}{ekd-h1}{10.163.146.77:9002}{ml.enabled=true},}, reason: zen-disco-receive(from master [master {ekm-h2}{XxqzcL6nRVqoO09A3aZ-nQ}{_u7dPB6kRy-jJLBE-T5kAw}{ekm-h2}{10.163.144.227:9002}{ml.enabled=true} committed version [8064]])
ekd-h1日志显示ekd-h1在08:19:34进行了一次full gc,随后脱离集群
[2018-10-22T08:19:34,831][WARN ][o.e.m.j.JvmGcMonitorService] [ekd-h1] [gc][old][370251][880] duration [11.8s], collections [1]/[2.4m], total [11.8s]/[2.1m], memory [18.4gb]->[8.4gb]/[24.8gb]
, all_pools {[young] [1.4gb]->[306.4mb]/[1.4gb]}{[survivor] [162.3mb]->[0b]/[191.3mb]}{[old] [16.8gb]->[8.1gb]/[23.1gb]}
[2018-10-22T08:19:34,838][INFO ][o.e.d.z.ZenDiscovery ] [ekd-h1] master_left [{ekm-h2}{XxqzcL6nRVqoO09A3aZ-nQ}{_u7dPB6kRy-jJLBE-T5kAw}{ekm-h2}{10.163.144.227:9002}{ml.enabled=true}], reason [failed to ping, tried [3] times, each with maximum [30s] timeout]
进一步分析ekd-h1的gc日志,找到异常时间戳打印,由于CMS垃圾回收是并发进行,上一阶段的gc(Allocation Failure)还没有完成,就接着打印新的时间戳,同时有promotion failed关键词。
在进行Minor GC时,Survivor Space容纳不了剩余对象,剩余对象只能放入老年代,而此时老年代也放不下造成了promotion failed。
2018-10-22T08:17:08.047+0800: 370789.675: [GC (Allocation Failure) 2018-10-22T08:17:08.047+0800: 370789.675: [ParNew (promotion failed): 1733898K->1686363K(1763584K), 0.1568841 secs]2018-10-22T08:17:08.204+0800: 370789.832: [Heap Dump (before full gc): , 108.9673271 secs]2018-10-22T08:18:57.171+0800: 370898.799: [CMS: 17670649K->8560649K(24254912K), 11.8056446 secs]2018-10-22T08:19:08.977+0800: 370910.605: [Heap Dump (after full gc): , 25.8345334 secs] 19381598K->8560649K(26018496K), [Metaspace: 74771K->74771K(1120256K)], 146.7648798 secs] [Times: user=99.95 sys=28.64, real=146.74 secs]
将gc日志上传到http://www.gceasy.io进行分析,发现GC暂停时间超长,怀疑与dump参数设置有关。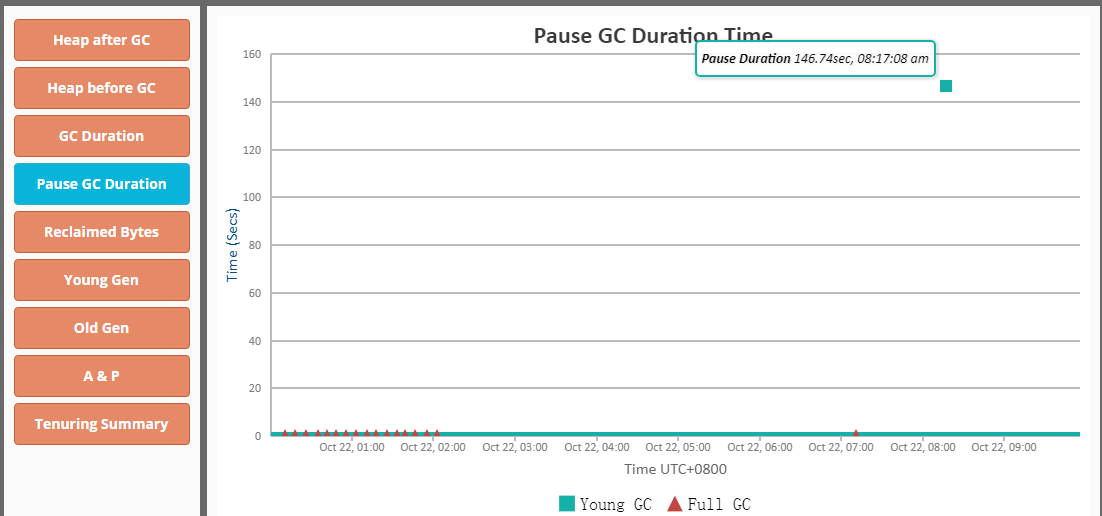
对比日志时间可见08:17:08进行[Heap Dump (before full gc): 108.9673271 secs],导致master调用zen-disco-receive检测节点健康状态时,与ekd-h1通信超时([2018-10-22T08:18:38,463][INFO ][o.e.c.s.ClusterService ] [ekm-h0] removed {{ekd-h1}),导致节点掉线,随后 [Heap Dump (after full gc): 25.8345334 secs]完成,ekd-h1重新加入集群[2018-10-22T08:19:38,034][INFO ][o.e.c.s.ClusterService ] [ekm-h0] added {{ekd-h1}
dump内存会占用较低的系统资源。
HeapDumpOnOutOfMemoryError参数设置,在Out Of Memory,JVM快死掉的时候,输出Heap Dump到指定文件。路径只指向目录,JVM会保持文件名的唯一性,叫java_pid${pid}.hprof。如果指向文件,而文件已存在,反而不能写入。
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${LOGDIR}/
但在容器环境下,输出4G的HeapDump,在普通硬盘上会造成20秒以上的硬盘IO跑满,也是个十足的恶邻,影响了同一宿主机上所有其他的容器。
Tips
146.7648798 secs] [Times: user=99.95 sys=28.64, real=146.74 secs] ‘real’ time是GC事件经过的总时间,这基本上就是在时钟里看到的时间。 ‘user’ time是在用户模式下(内核之外)CPU花费的时间。 ‘Sys’ time是在内核中花费的CPU时间,即在内核中执行系统调用所花费的CPU时间,与库代码相反,库代码仍然在用户空间中运行。 在绝大多数GC事件中,’real’ time小于user + sys time,因为多个GC线程并发工作以分摊工作任务,假设用户+系统时间是2秒。有5个GC线程同时工作,那么’real’ time应该在400毫秒左右(2秒/ 5个GC线程)。 但是在某些情况下,可能会看到’real’ time比user + sys time更大。 [Times: user=0.20 sys=0.01, real=18.45 secs] 如果在GC日志中多次出现以上的记录,可能表示IO繁忙或者CPU资源告急。可参考https://blog.gceasy.io/2016/12/08/real-time-greater-than-user-and-sys-time/ 可能导致长时间GC pause的情况以及建议
https://blogs.oracle.com/poonam/troubleshooting-long-gc-pauses https://www.cakesolutions.net/teamblogs/low-pause-gc-on-the-jvm

若有收获,就点个赞吧
0 人点赞
