垃圾回收
JVM内存空间区域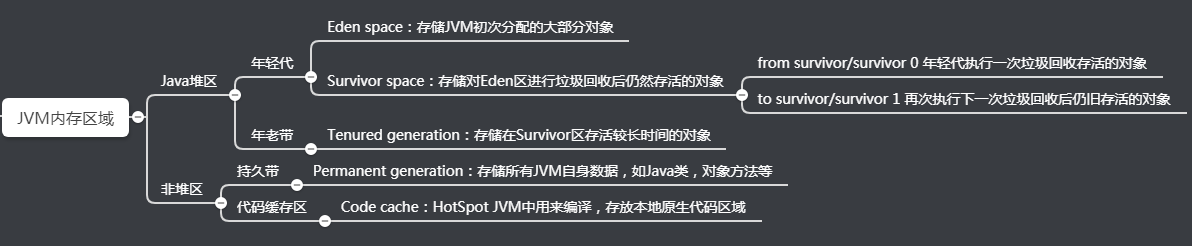
除了G1 GC,目前Java还在使用分带的垃圾回收机制,按照工作内存区间划分垃圾回收器,可分为年轻代和年老代。年轻代和年老代两种垃圾回收器并行运行,经历垃圾回收次数越多,越容易往老年代移。
常用命令
jps获取正在运行的Java进程和对应虚拟机的标识符
jstat检查垃圾回收器的工作状况
jstat -gcutil 12345 2000 1000-gcutil 告知jstat监控垃圾回收器的工作状态12345 JVM对应虚机的标识符2000 抽样时间,ms1000 抽样数

S0:表示survivor 0区的使用率,用百分比表示。
S1:表示survivor 1区的使用率,用百分比表示。
E:表示Eden区的使用率,用百分比表示。
O:表示年老代的使用率,用百分比表示。
YGC:表示年轻代垃圾回收事件的次数。
YGCT:表示年轻代垃圾回收耗时,单位为秒。
FGC:表示年老代垃圾回收事件的次数。
FGCT:表示年老代垃圾回收耗时,单位为秒。
GCT:表示垃圾回收总耗时。
TIPS:
ElasticSearch运行异常或者S0,S1,E列的值达到100%,并且垃圾回收对这些堆空间不起作用,可能是年轻代太小,在物理内存足够的情况下可以尝试适当调大。 如果O列的值达到100%且垃圾回收器多次尝试仍然无法释放它的空间,可能是由于没有足够的堆空间。
jmap命令可以获取特定时间点堆空间的内存快照,通过转储到文件,分析快照的存储内容,从而发现问题。
https://docs.oracle.com/javase/7/docs/technotes/tools/share/jmap.html
Jmap命令示例如下:
jmap -dump:file=esheap.dump 12345# 12345 Java应用PID# -dump:file=le 指定转储指定转储的目标文件
可以通过jhat软件进一步分析转储文件
https://docs.oracle.com/javase/7/docs/technotes/tools/share/jhat.html
windows可以使用JProfiler工具分析dump文件
垃圾收集器中吞吐量和低延迟的两个目标本身是相互矛盾的,需要根据实际的使用场景控制在折中的范围。对ElasticSearch来说保持程序性能的稳定性很重要,尽可能进行多次轻量级垃圾回收操作,而不是一次性、耗时很长的垃圾回收操作。长时间的垃圾回收操作会停止全局的垃圾回收事件,在短时间内冻结ElasticSearch的工作,从而使查询变慢且短期无法执行索引操作。
垃圾回收调优并不是一件一劳永逸的事情,需要反复试验,因为调优结果严重依赖于数据、查询和各种组合环境。
节流配置
Lucene是封装在elasticsearch下的IR库,它的工作方式是创建不可变的段(直到删除)并不断地合并它们(合并策略设置允许控制这些合并的发生方式)。索引合并的过程是异步的,从Lucene的角度看是不会干扰索引和查询过程的。然而,这很可能会出现问题,因为合并操作非常消耗I/O,需要先读取旧索引段,然后合并写入新索引段中。如果在此同时进行查询和索引,那么I/O子系统的负荷会非常大,这个问题在那些I/O速度较慢的系统中表现得尤为突出。这就是I/O节流的切入点。我们可以控制ElasticSearch使用的I/O量。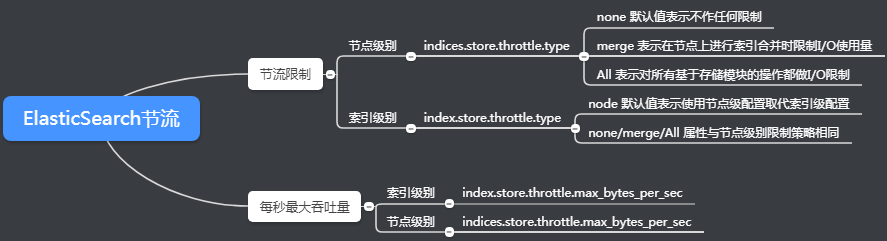
以上配置都可以通过elasticsearch.yml文件配置,也可以动态更新:使用集群更新设置接口来更新节点级配置,使用索引更新设置接口来更新索引级配置。
节点的默认节流配置
在节点级,I/O节流从ElasticSearch 0.90.1版本起就默认开启,其中indices.store.throttle.type的属性值为merge,indices.store.throttle.max_bytes_per_sec的属性值为20MB。但是6.0版本的ElasticSearch已经不在支持I/O节流的参数。
Store throttling has been removed. As a consequence, the indices.store.throttle.type and indices.store.throttle.max_bytes_per_sec cluster settings and the index.store.throttle.type and index.store.throttle.max_bytes_per_sec index settings are not recognized anymore.
预热器
在使用一些如父-子关系、切面计算和基于字段的排序等特定功能的场景下,ElasticSearch需要提前加载一些数据到缓存中。预加载过程需要花费一些时间和资源,在某些时候会使查询变慢。更要命的是,如果索引频繁更新,缓存就需要频繁刷新,而查询性能也就更糟了。因此ElasticSearch 0.20版本引入预热器API。
https://www.elastic.co/guide/en/elasticsearch/reference/0.90/indices-warmers.html
https://www.elastic.co/guide/cn/elasticsearch/guide/cn/preload-fielddata.html#index-warmers
预热器是一些标准查询,这些查询在ElasticSearch尚未对外提供查询服务时,先在冷的(尚未使用的)索引段上执行。查询操作不仅会在ElasticSearch启动时执行,在新索引段提交后也会执行。因此,使用一些合适的查询对系统进行预热后,会把所有需要的数据加载到缓存中,并且预热了操作系统的I/O缓存(通过加载冷的索引段)。做完这些之后,当索引段最终接受查询请求时,能确保得到最优的查询性能,且此时所需的数据都已经就位。但在5.6版本已经取消了预热器的设置。
Warmers have been removed. There have been significant improvements to the index that make warmers not necessary anymore.
热点线程
当集群变慢且占用较多CPU资源时,可以通过热点线程API找到问题根源。热点线程指CPU占用高且执行时间较长的Java线程,而热点线程API可以返回如下信息:从CPU视角看到的ElasticSearch中执行最频繁的代码段,以及ElasticSearch卡在什么地方。https://www.elastic.co/guide/en/elasticsearch/reference/6.4/cluster-nodes-hot-threads.html
热点线程API可以检查所有ElasticSearch节点、部分节点或某个特殊节点,只需使用/_nodes/hot_threads或/_nodes/{node or nodes}/hot_threads端点即可。例如,使用下面的命令来检查所有节点上的热点线程:
curl -X GET "localhost:9200/_nodes/hot_threads"curl -X GET "localhost:9200/_nodes/nodeId1,nodeId2/hot_threads"
热点线程API支持如下参数:
threads(默认值为3):经分析后输出的线程数,ElasticSearch会根据type参数指定的信息挑选出最“热”的threads个线程。
interval(默认值500ms):ElasticSearch需要分两次检查线程,目的是计算特定线程与type参数对应操作的耗时百分比。两次检查的间隔时间由interval参数设置。
type(默认值为cpu):本参数确定了要检查的线程状态的类型,具体支持如下状态类型:指定线程的CPU耗时(cpu)、BLOCK状态耗时(block)、WAITING状态耗时(wait)。
https://docs.oracle.com/javase/6/docs/api/java/lang/Thread.State.html
snapshots(默认值10):堆栈轨迹快照的数量。其中,堆栈轨迹指特定时间点的嵌套函数调用。
ElasticSearch首先扫描所有正在运行的线程并从它们那里收集多种信息,包括每个线程占用CPU的时间、特定线程被阻塞或处于等待状态的次数、阻塞或等待时长等。然后等待interval参数设定的时长后,再次扫描并收集同样的信息。接下来把两次收集得到的信息按type参数指定的线程执行时长做降序排序,之后,ElasticSearch分析threads参数取值的N个线程。
实际上ElasticSearch的做法是,每隔几毫秒就截取一些前N个线程的堆栈轨迹快照(快照数由snapshots参数指定)。最后,ElasticSearch把这些堆栈轨迹分组并可视化呈现线程状态的变化。


若有收获,就点个赞吧
0 人点赞
