核心概念
Topic
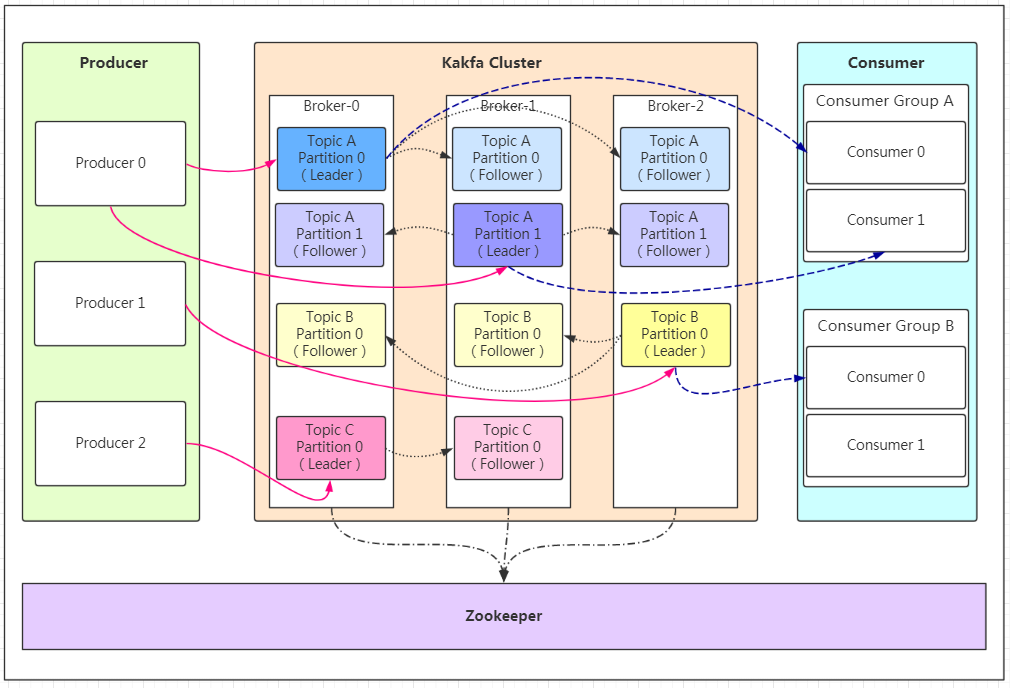
消息的主题,可以理解为消息的分类,实际使用过程中多用来区分具体的业务。kafka的数据就保存在topic。每个broker可以创建多个topic。
Partition
Topic的分区,每个topic可以有多个分区(编号从0开始),每个分区是一组有序的消息日志,生产者的生产的每条消息只会被发送到一个分区中,无论该topic设置了几个分区,即同一个topic在不同的分区的数据是不重复的。
分区的作用是做负载,提高kafka的吞吐量和伸缩性—Scalability。以避免Leader积累太多的数据以至于单台broker机器无法容纳。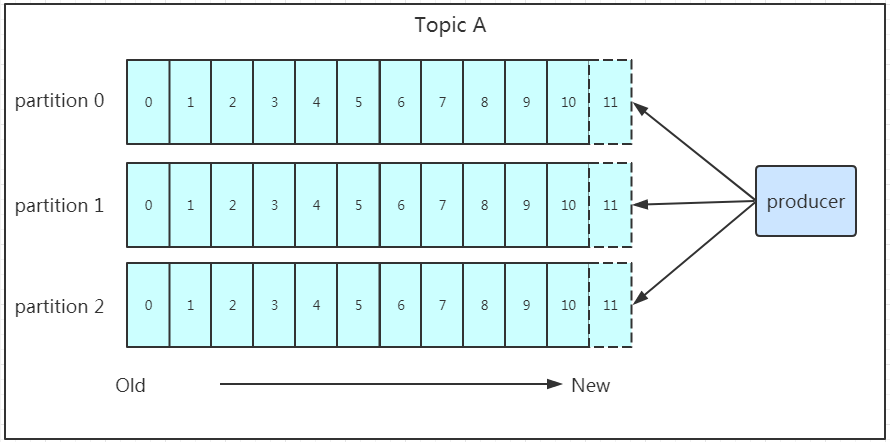
producer采用push模式将数据发布到broker,每条消息追加到分区中,顺序写入磁盘,所以保证同一分区内的数据是有序的。
Replication
一个分区可以对应多个副本以实现高可用,同一条消息被拷贝到多个地方以提供数据冗余。
follower主动的去leader进行同步。当主分区(Leader)故障的时候会选择一个(Follower)上位,成为Leader。
默认最大副本数量是10个,且副本的数量不能大于集群Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。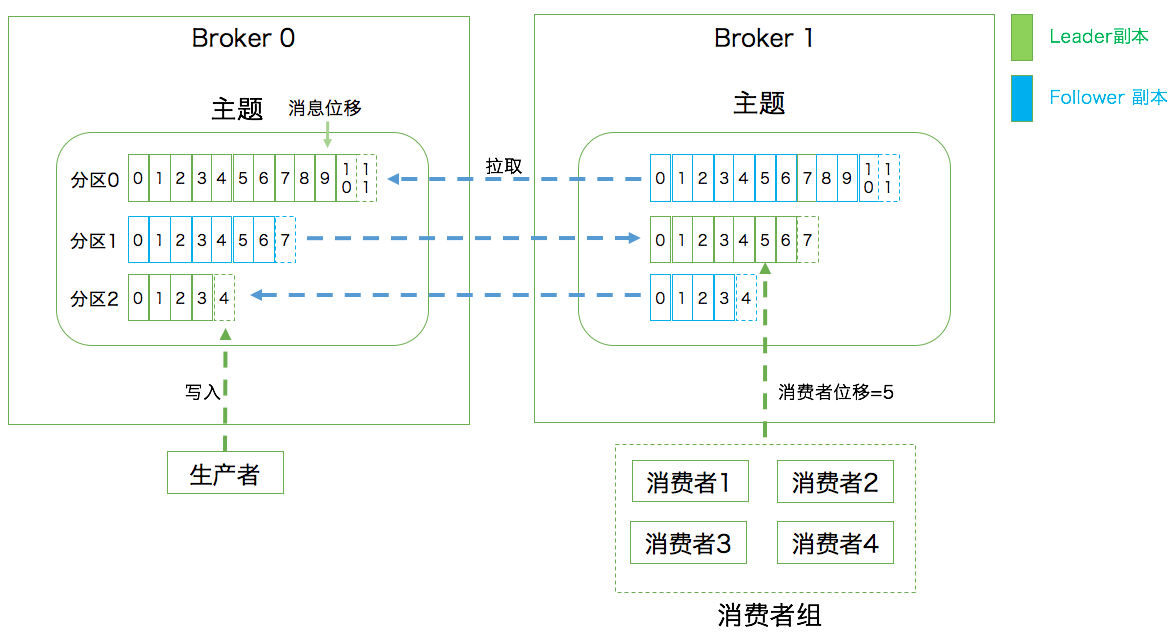
Peer2Peer
点对点模型,一条消息只能被下游的一个消费者消费。实现P2P模型的方法就是引入了消费者组,即多个消费者实例组队消费同一个topic,该topic中的每个partition只会被组内的一个消费者消费。
通过引入消费者组ConsumerGroup,多个消费者实例同时消费,以加速整个消费端的吞吐量。
Rebalance
ConsumerGroup中的某个消费者实例挂掉,kafka能够自动检测,然后把这个Failed实例之前负责的分区转移给其他存活的消费者。
consumer offset
数据持久化
kafka使用消息日志Log来保存数据,一个日志就是磁盘上一个只能追加写消息的物理文件。由于只能追加写入,避免了缓慢的随机I/O操作,改为性能较好的顺序写I/O操作,这也是kafka实现高吞吐量特性的一个重要手段。
kafka底层通过日志段Log Segment机制讲一个日志又近一步细分成多个日志段,当写满一个日志段,kafka自动切分出一个新的日志段,老的日志段封存,通过后台定时任务判断老的日志段是否可被删除,从而实现磁盘空间回收的目的。
分区的表现形式就是/path/to/kafka/log/下【topic名称_分区编号】的文件夹。
数据发送流程
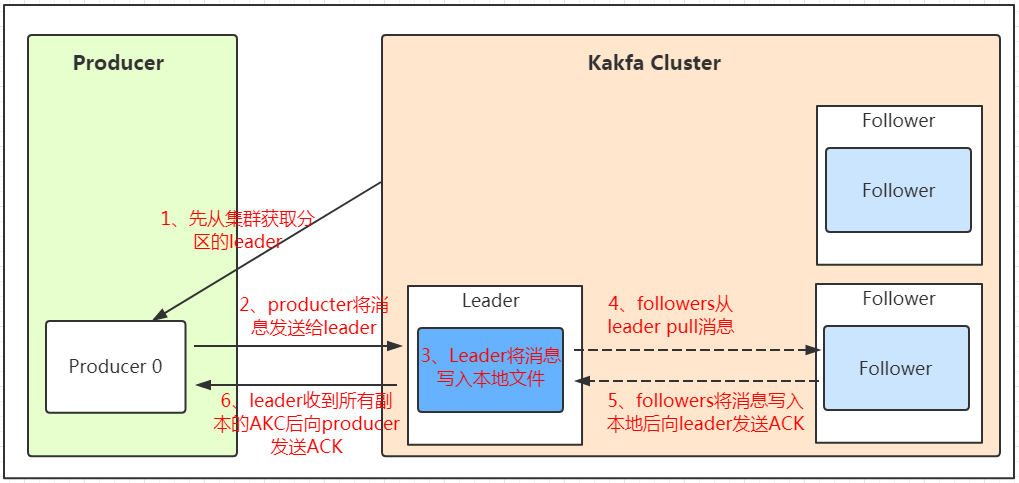
ACK应答机制对应的参数设置是权衡吞吐量和保证消息不丢失的结果。
关键步骤
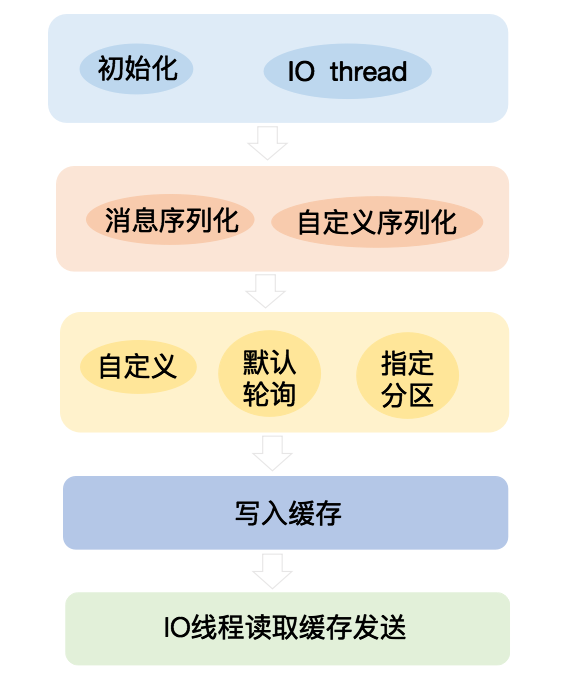
1、初始化以及真正发送消息的 kafka-producer-network-thread IO 线程。
2、将消息序列化。
3、producer得到需要把数据发送到哪个目标partition分区,路由规则如下
- 如果在写入时有指定需要写入的partition,则写入对应的partition。
- 如果没有指定partition,但是设置了数据的key,则会根据key的值hash。
- 如果既没指定partition,又没有设置key,则会轮询选出一个partition。
4、写入内部的一个缓存区中。
5、初始化的 IO 线程不断的消费这个缓存来发送消息。

若有收获,就点个赞吧
0 人点赞
