基于zk的表复制
https://www.jianshu.com/p/d1842290bd48
https://clickhouse.yandex/docs/en/operations/table_engines/replication/
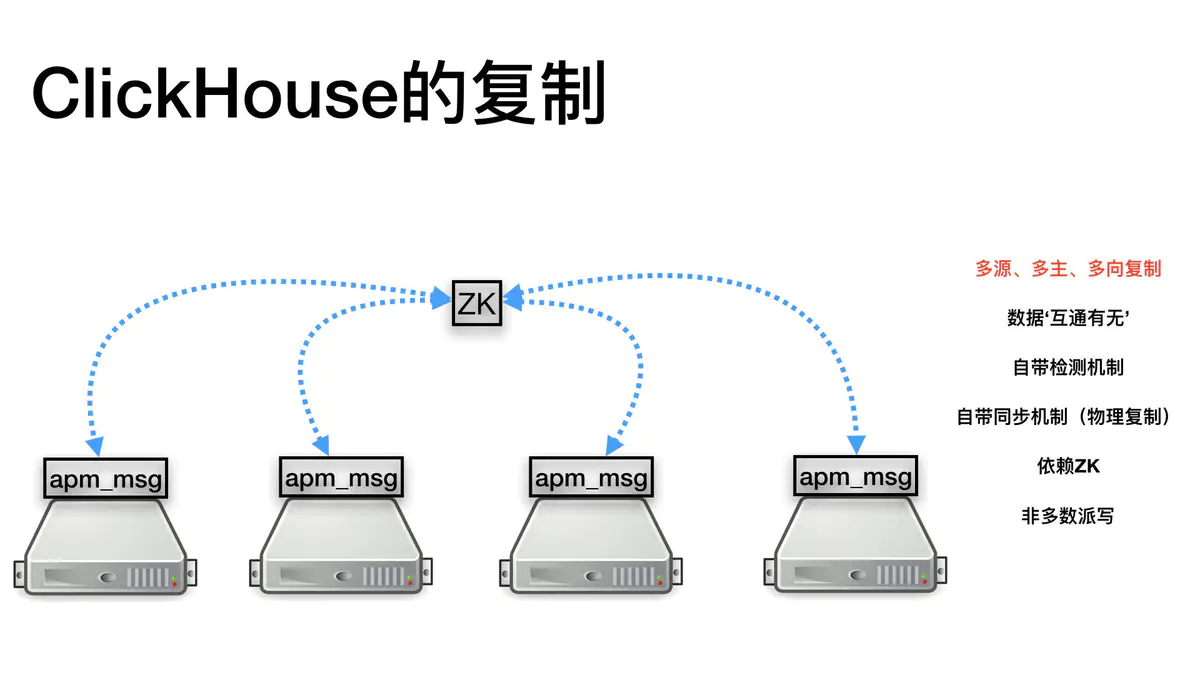
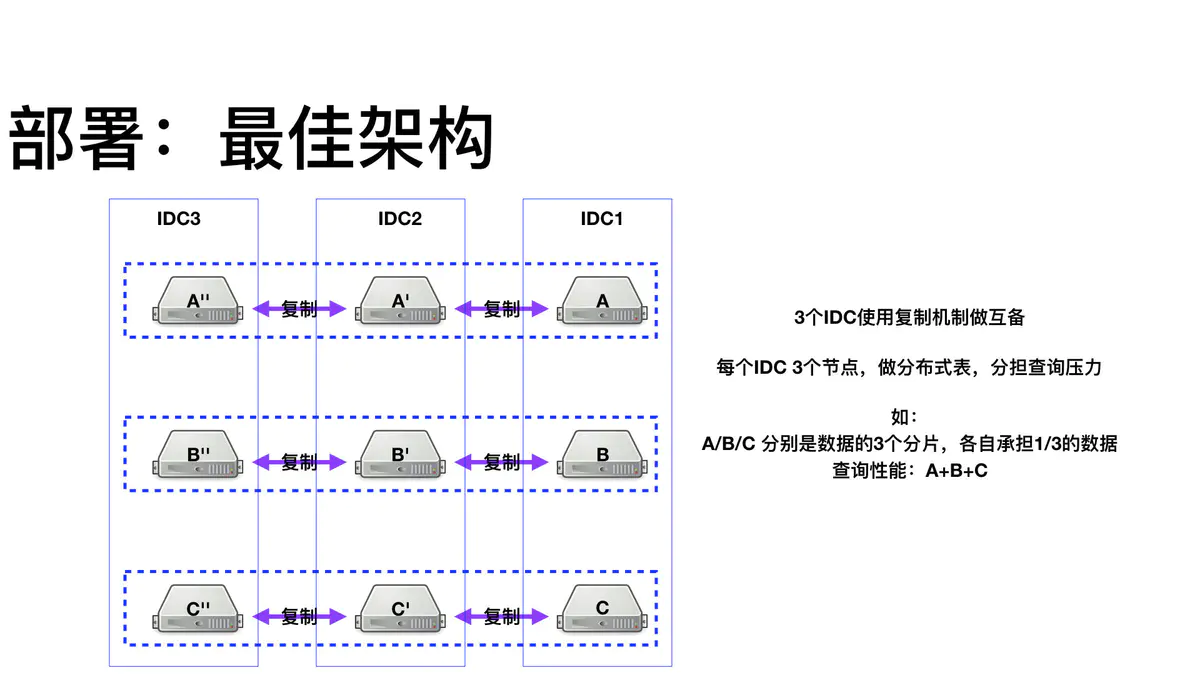
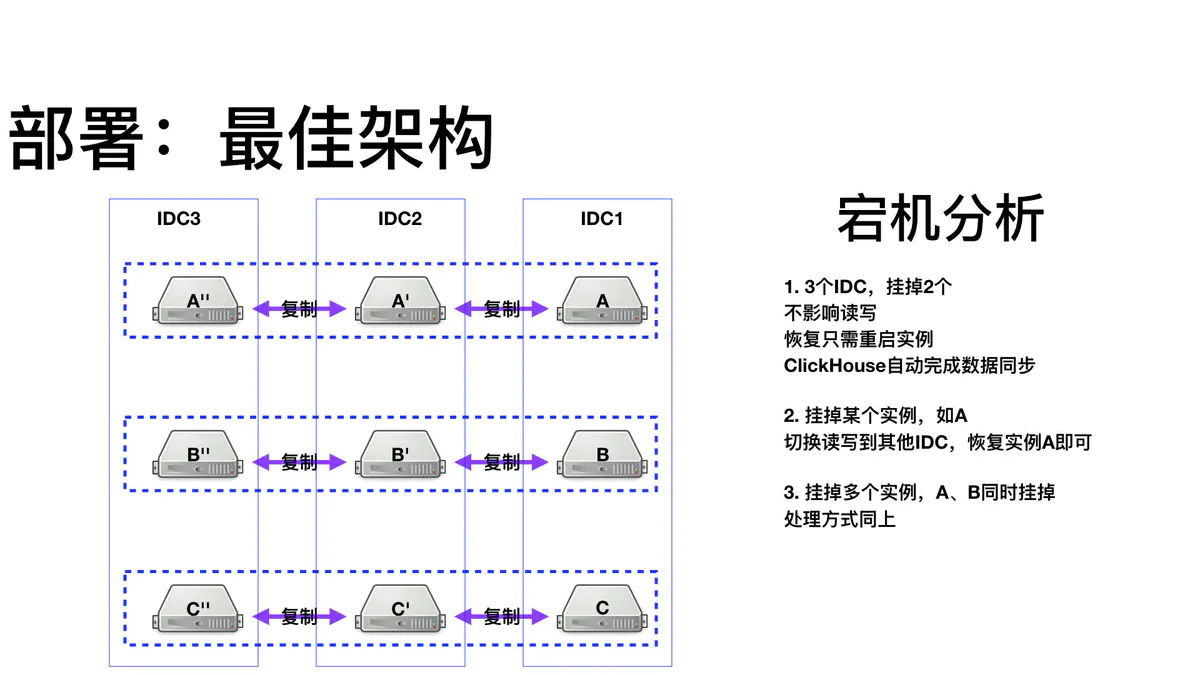
可靠性,通过使用复制机制,来抵抗单机宕机、机房宕机风险
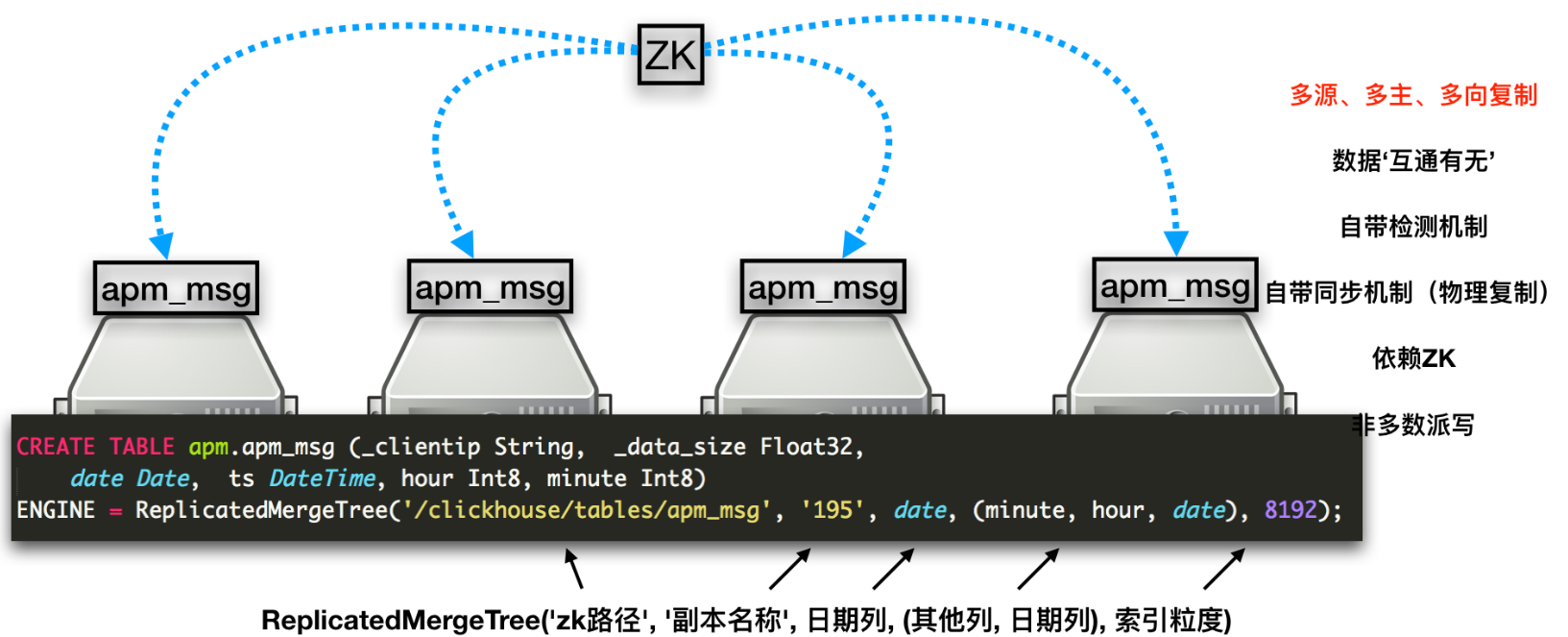
依赖ClickHouse的复制引擎—ReplicatedMergeTree,在ZK的基础上,共享同一个ZK路径的节点,会相互同步数据复制表配置
复制表通过zookeeper协调不同副本之间的数据<zookeeper optional="true"><node index="1"><host>172.16.8.179</host><port>2181</port></node><node index="2"><host>172.16.8.95</host><port>2181</port></node><node index="3"><host>172.16.8.72</host><port>2181</port></node></zookeeper>

故障:ReplicatedMergeTree表引擎,双副本,其中一台机器宕机或者是硬件故障
思路::一个副本数据损坏,jlogclickhouse会报zk中元数据不一致错误,不会在新启动的机器上创建相应的库和表,需要手动创建
准备工作: 将新机器准备好或者硬盘更换后,启动clickhouse
机器: 故障机A,正常机B,替换机C
开始:
1、将Jlogclickhouse中配置ck集群的地址将故障机A移除并重启;
2、在替换机C上根据租户ID分别创建local_x和distributed_x数据库(已经安装并启动clickhouse);
3、在正常机B上通过show create table 查看各个库的建表语句,然后在替换机C上执行;
4、等所有表结构创建好后,观察替换机C其中一个表的数据看是不是正常了。正常的情况下,应该已经将正常机B机器的数据同步部分过来了;
5、数据同步OK后,在Jlogclickhouse上添加替换机C IP地址;
只要通过创建表在zk中注册相应的信息,ck默认会同步副本之间的数据

若有收获,就点个赞吧
0 人点赞
