visitParamExtractRaw
Lucene语法
appname: “usercenter2pro” AND path: “/home/admin/logs/tracelog/rpc-server-digest.log” AND tag: “sofa-log,tracelog,rpc-server-digest” AND main_data_parsed.state_code:”00”
转换为SPL语法
提取json字符串【main_data_parsed.state_code】中的数值需使用visitParamExtractString函数
select message from usercenter2pro where at_timestamp between toUnixTimestamp(‘$time$’) 1000 and toUnixTimestamp(‘$time$’) 1000 and tag = ‘sofa-log,tracelog,rpc-server-digest’ and
visitParamExtractString(main_data_parsed,’state_code’) = ‘00’
CAST
按照diskIndex字段排序,发现实际按照字符串进行排序1,10,11而非1,2,3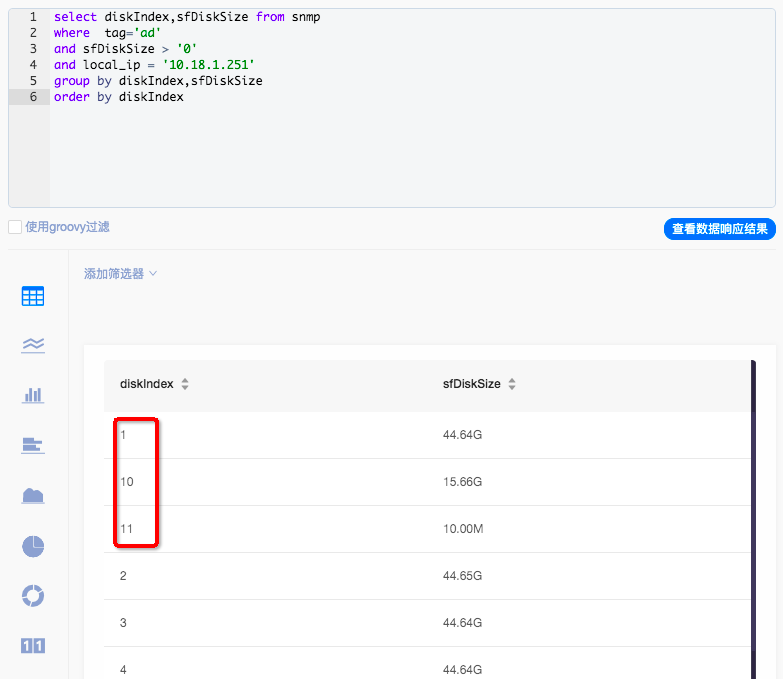
对diskIndex字段做字符类型转换处理CAST,再进行排序的结果就是1,2,3的顺序
select cast(diskIndex as integer) as diskIndex,sfDiskSize from snmpwhere tag='ad'and sfDiskSize > '0'and local_ip = '10.18.1.251'group by diskIndex,sfDiskSizeorder by diskIndex
TIPS:由于group by使用限制,select中的列如果不在GROUP BY中,则需要使用aggregate function,否则无法返回结果
按照diskIndex和sfFilesystemName同时进行分组
select cast(diskIndex as integer) as diskIndex,sfFilesystemName as mt_point from snmpwhere tag='ad'and sfFilesystemName != ''group by diskIndex,sfFilesystemName
只按照diskIndex分组,则需要对sfFilesystemName进行函数计算,搜索结果才会展示两列数据
select cast(diskIndex as integer) as diskIndex,max(sfFilesystemName) as mt_point from snmpwhere tag='ad'and sfFilesystemName != ''group by diskIndex
join….using
select time ,sfFilesystemName sfDiskUsedPercent from(select toDateTime((at_timestamp - at_timestamp%60000)/1000) as time,sfDiskUsedPercent,diskIndex from snmpwhere tag = 'ad'and sfDiskUsedPercent > '0'order by time desc limit 11)any left join(select toDateTime((at_timestamp - at_timestamp%60000)/1000) as time,sfFilesystemName,diskIndex from snmpwhere tag='ad'and sfFilesystemName != ''order by time desc limit 11)using diskIndexorder by diskIndex
CASE WHEN
ifIndex字段搜索对应的值为数字,想要转换为对应运营商标识,可以使用case when函数做转换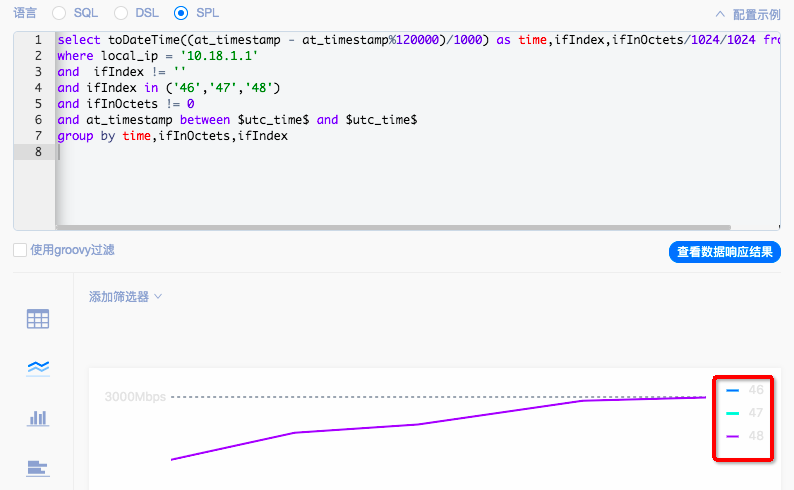
需要注意的是如果只有一个转换对象,else条件免去会报错,可使用‘其他’标识代替
case ifIndex when ‘47’ then ‘联通’ else ‘其他’ end
select toDateTime((at_timestamp - at_timestamp%120000)/1000) as time,case ifIndex when '46' then '电信'when '47' then '联通'else '移动' end ,ifInOctets/1024/1024 from snmpwhere local_ip = '10.18.1.1'and ifIndex != ''and ifIndex in ('46','47','48')and ifInOctets != 0and at_timestamp between $utc_time$ and $utc_time$group by time,ifInOctets,ifIndex
DEMO
select visitParamExtractString(SrcIPAddr_parsed,'value') srcIp,//选取 SrcIPAddr解析后的value字段 作 srcIP,SrcIPAddr(1003)=10.158.185.200解析后结果为SrcIPAddr_parsed.key=SrcIPAddr(1003),SrcIPAddr_parsed.value=10.158.185.200//函数visitParamExtractString(target, key) 表示从目标json格式的target里选取 KEY值为key的字段concat(substring(visitParamExtractString(BeginTime_e_parsed, 'value'),5,4),'-',substring(visitParamExtractString(BeginTime_e_parsed, 'value'),1,2),'-',substring(visitParamExtractString(BeginTime_e_parsed, 'value'),3,2),' ',substring(visitParamExtractString(BeginTime_e_parsed, 'value'),9,2),':',substring(visitParamExtractString(BeginTime_e_parsed, 'value'),11,2),':',substring(visitParamExtractString(BeginTime_e_parsed, 'value'),13,2)) beginTime,//把BeginTime_e_parsed,即03112019155853调整成时分秒格式,调整后字段名beginTime,目标格式2019-03-11 15:58:53//函数substring(target,5,4) 表示从目标字符串target里截取子串,从第5个字符开始截取,截取4个字符//函数concat(a,b,...)字符串拼接函数,参数个数不定(toUnixTimestamp(concat(substring(visitParamExtractString(BeginTime_e_parsed, 'value'),5,4),'-',substring(visitParamExtractString(BeginTime_e_parsed, 'value'),1,2),'-',substring(visitParamExtractString(BeginTime_e_parsed, 'value'),3,2),' ',substring(visitParamExtractString(BeginTime_e_parsed, 'value'),9,2),':',substring(visitParamExtractString(BeginTime_e_parsed, 'value'),11,2),':',substring(visitParamExtractString(BeginTime_e_parsed, 'value'),13,2)))+28800) beginTimeStamp,//把03112019155721转换成目标格式2019-03-11 15:58:53后,再转换成时间戳(s)//函数toUnixTimestamp(dateString) 表示把时间格式字符串转换成时间戳//+28800 表示把UTC时间的时间戳转换成北京时间时间戳,北京时间比UTC时间快8小时,8*60*60=28800EndTime_e_parsed as EndTime, messagefrom nat_nano where at_timestamp between toUnixTimestamp('$time$') * 1000 and toUnixTimestamp('$time$') * 1000 and BeginTime_e != ''//from tablename,tablename即数据接入时指定的服务名,nat_nano为NAT日志表名//格式语法,最近$time$时间,若time=3天,表示最近3天,at_timestamp between toUnixTimestamp('$time$') * 1000 and toUnixTimestamp('$time$') * 1000and EndTime_e_parsed != ''//sql 筛选条件and beginTime != ''and srcIp like '$ip$'//srcIp like '$ip$'表示用筛选器里的变量ip做结果过滤。ip为全部时选取全部and srcIp in (// 子查询,表示在WLAN登录日志里有过上线日志的IP集合select ip from wlan_nano_jsonwhere at_timestamp between toUnixTimestamp('$time$') * 1000 and toUnixTimestamp('$time$') * 1000and user_name != ''and user_name like '%$usefield$%'//'%$usefield$%' 用户名搜索框筛选and user_name like '$username$'//'$username$'用户名下拉框筛选group by user_name, iporder by user_name)
replaceAll
select `备份实例`,`备份成功次数`,`最后一次备份时间`,`备份集大小(G)`,`备份耗时(ms)` from(selectreplaceAll(visitParamExtractRaw(message,'backupEndTime'),'\"','') as `最后一次备份时间`,(toUnixTimestamp(replaceAll(replaceAll(replaceAll(visitParamExtractRaw(message,'backupEndTime'),'\"',''),'Z',''),'T','\n')) -toUnixTimestamp(replaceAll(replaceAll(replaceAll(visitParamExtractRaw(message,'backupStartTime'),'\"',''),'Z',''),'T','\n'))) as `备份耗时(ms)`,cast(replaceAll(visitParamExtractRaw(message,'backupSize'),'\"','') as integer)/1024/1024/1024 as `备份集大小(G)`,replaceAll(visitParamExtractRaw(message,'dBInstanceId'),'\"','') as `备份实例`from rdswhere tag = 'DBBackups'and hostname like '$hostname$'order by `最后一次备份时间` desc limit 1)any left join(selectreplaceAll(visitParamExtractRaw(message,'dBInstanceId'),'\"','') as `备份实例`,replaceAll(visitParamExtractRaw(message,'backupStatus'),'\"','') as `stat`,count(stat) as `备份成功次数`from rdswhere tag = 'DBBackups'and hostname like '$hostname$'and `stat` = 'Success'and at_timestamp between $time$ and $time$group by stat,`备份实例`)using `备份实例`
runningDifference
select toDateTime((at_timestamp - at_timestamp%$interval$)/1000) as ttime,'上行带宽' as `类型`,max(runningDifference(x)/(runningDifference(at_timestamp/1000)))/1024/1024*8from(select at_timestamp,visitParamExtractInt(message,'ifHCOutOctets') as `x` from snmpwhere local_ip='$address$'and replaceAll(visitParamExtractRaw(message,'ifDescr'),'\"','') = 'TenGigabitEthernet 1/2/13'and at_timestamp between $utc_time$ and $utc_time$and runningDifference(visitParamExtractInt(message,'ifHCOutOctets')) != 0order by at_timestamp asc)group by ttime,`类型`union allselect toDateTime((at_timestamp - at_timestamp%$interval$)/1000) as ttime,'下行带宽' as `类型`,max(runningDifference(x)/(runningDifference(at_timestamp/1000)))/1024/1024*8from(select at_timestamp,visitParamExtractInt(message,'ifHCInOctets') as `x` from snmpwhere local_ip='$address$'and replaceAll(visitParamExtractRaw(message,'ifDescr'),'\"','') = 'TenGigabitEthernet 1/2/13'and at_timestamp between $utc_time$ and $utc_time$and runningDifference(visitParamExtractInt(message,'ifHCInOctets')) != 0order by at_timestamp asc)group by ttime,`类型`
DataTimeFunctions
at_timestamp between (toUnixTimestamp(now())-180)*1000 and toUnixTimestamp(now())*1000at_timestamp > toUnixTimestamp(subtractMinutes(now(), 300))*1000
select multiIf((100-sum("链路分"))>=85,1,(100-sum("链路分"))>=70,2,3)from (select sum("链路状态")*100/5 as "链路分" from (select LinkIndex,at_timestamp,if ((BitIn+BitOut)/1024/1024/40000 > 80,2,if ((BitIn+BitOut) == 0,0,1)) as "链路状态"from(select at_timestamp,LinkIndex,adLinkBitIn as "BitIn" from snmp where at_date = toDate(now()) and at_timestamp between (toUnixTimestamp(now())-600)*1000 and toUnixTimestamp(now())*1000 and tag='ad' and LinkIndex <> '4' and adLinkBitIn > 0)any left join(select at_timestamp,LinkIndex,adLinkBitOut as "BitOut" from snmp where at_date = toDate(now()) and at_timestamp between (toUnixTimestamp(now())-600)*1000 and toUnixTimestamp(now())*1000 and tag='ad' and LinkIndex <> '4' and adLinkBitOut > 0 ) USING LinkIndexorder by at_timestamp desclimit 5)where "链路状态"=0union allselect sum("链路状态")*100/5/2 as "链路分" from (select LinkIndex,at_timestamp,if ((BitIn+BitOut)/1024/1024/20000 > 80,2,if ((BitIn+BitOut) == 0,0,1)) as "链路状态"from(select at_timestamp,LinkIndex,adLinkBitIn as "BitIn" from snmp where at_date = toDate(now()) and at_timestamp between (toUnixTimestamp(now())-600)*1000 and toUnixTimestamp(now())*1000 and tag='ad' and LinkIndex <> '4' and adLinkBitIn > 0)any left join(select at_timestamp,LinkIndex,adLinkBitOut as "BitOut" from snmp where at_date = toDate(now()) and at_timestamp between (toUnixTimestamp(now())-600)*1000 and toUnixTimestamp(now())*1000 and tag='ad' and LinkIndex <> '4' and adLinkBitOut > 0 ) USING LinkIndexorder by at_timestamp desclimit 5)where "链路状态"=2)
having
HAVING 的作用和 WHERE 一样,都是起到过滤的作用,只不过 WHERE 是用于数据行,而 HAVING 则作用于分组。
SELECTtoDateTime((at_timestamp - (at_timestamp % 5)) / 1000) AS ttime,max(toFloat64OrZero(visitParamExtractRaw(message, 'myCPUUtilization1Min'))) AS `cpu使用率`FROM snmpWHERE (local_ip = '10.160.1.11') AND (tag = 'switch') AND ((at_timestamp >= 1586745998833) AND (at_timestamp <= 1586745998833))GROUP BY ttimeHAVING `cpu使用率` != 0ORDER BY ttime DESC┌───────────────ttime─┬─cpu使用率─┐│ 2020-04-13 10:46:38 │ 39 │└─────────────────────┴───────────┘
如果把上面SQL 中HAVING 后的过滤条件替换成了 WHERE,SQL 则会报错。对于分组的筛选,一定要用 HAVING,而不是 WHERE。HAVING 支持所有 WHERE 的操作,因此所有需要 WHERE 子句实现的功能,可以使用 HAVING 对分组进行筛选。如果要用where,则应该对数据在max聚合分组前进行条件筛选过滤。
SELECTtoDateTime((at_timestamp - (at_timestamp % 5)) / 1000) AS ttime,max(toFloat64OrZero(visitParamExtractRaw(message, 'myCPUUtilization1Min'))) AS `cpu使用率`FROM snmpWHERE (local_ip = '10.160.1.11') AND (tag = 'switch') AND ((at_timestamp >= 1586745998833)AND (at_timestamp <= 1586745998833))AND (toFloat64OrZero(visitParamExtractRaw(message, 'myCPUUtilization1Min')) != 0)GROUP BY ttimeORDER BY ttime DESC┌───────────────ttime─┬─cpu使用率─┐│ 2020-04-13 10:46:38 │ 39 │└─────────────────────┴───────────┘
子查询
select clientip,phone,count(*) from(select arrayElement(splitByChar('=',arrayElement(splitByChar(' ',msg),13)),2) as clientip,arrayElement(splitByChar(' ',msg),5) as phone,count(1) as "次数"from auth where appModelName='cas' and log_level = 'INFO'and arrayElement(splitByChar(' ',msg),15) like '%failure%'group by clientip,phone order by "次数" desc)group by clientip,phone having count(*) > 2 limit 10

若有收获,就点个赞吧
0 人点赞
