Gitbook
https://yunlzheng.gitbook.io/prometheus-book/
https://songjiayang.gitbooks.io/prometheus/
什么是Prometheus?
Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库(TSDB)。Prometheus使用Go语言开发,是Google BorgMon监控系统的开源版本。
2016年由Google发起Linux基金会旗下的原生云基金会(Cloud Native Computing Foundation), 将Prometheus纳入其下第二大开源项目。Prometheus目前在开源社区相当活跃。
Prometheus和Heapster(Heapster是K8S的一个子项目,用于获取集群的性能数据。)相比功能更完善、更全面。Prometheus性能也足够支撑上万台规模的集群。
Prometheus的特点
- 多维度数据模型。
- 灵活的查询语言。
- 不依赖分布式存储,单个服务器节点是自主的。
- 通过基于HTTP的pull方式采集时序数据。
- 可以通过中间网关进行时序列数据推送。
- 通过服务发现或者静态配置来发现目标服务对象。
-
Prometheus 核心组件
Prometheus Server, 主要用于抓取数据和存储时序数据,另外还提供查询和 Alert Rule 配置管理。
- client libraries,用于对接 Prometheus Server, 可以查询和上报数据。
- push gateway ,用于批量,短期的监控数据的汇总节点,主要用于业务数据汇报等。
- 各种汇报数据的 exporters ,例如汇报机器数据的 node_exporter, 汇报 MongoDB 信息的 MongoDB exporter 等等。
- 用于告警通知管理的 alertmanager
Prometheus的架构
下面这张图说明了Prometheus的整体架构,以及生态中的一些组件作用: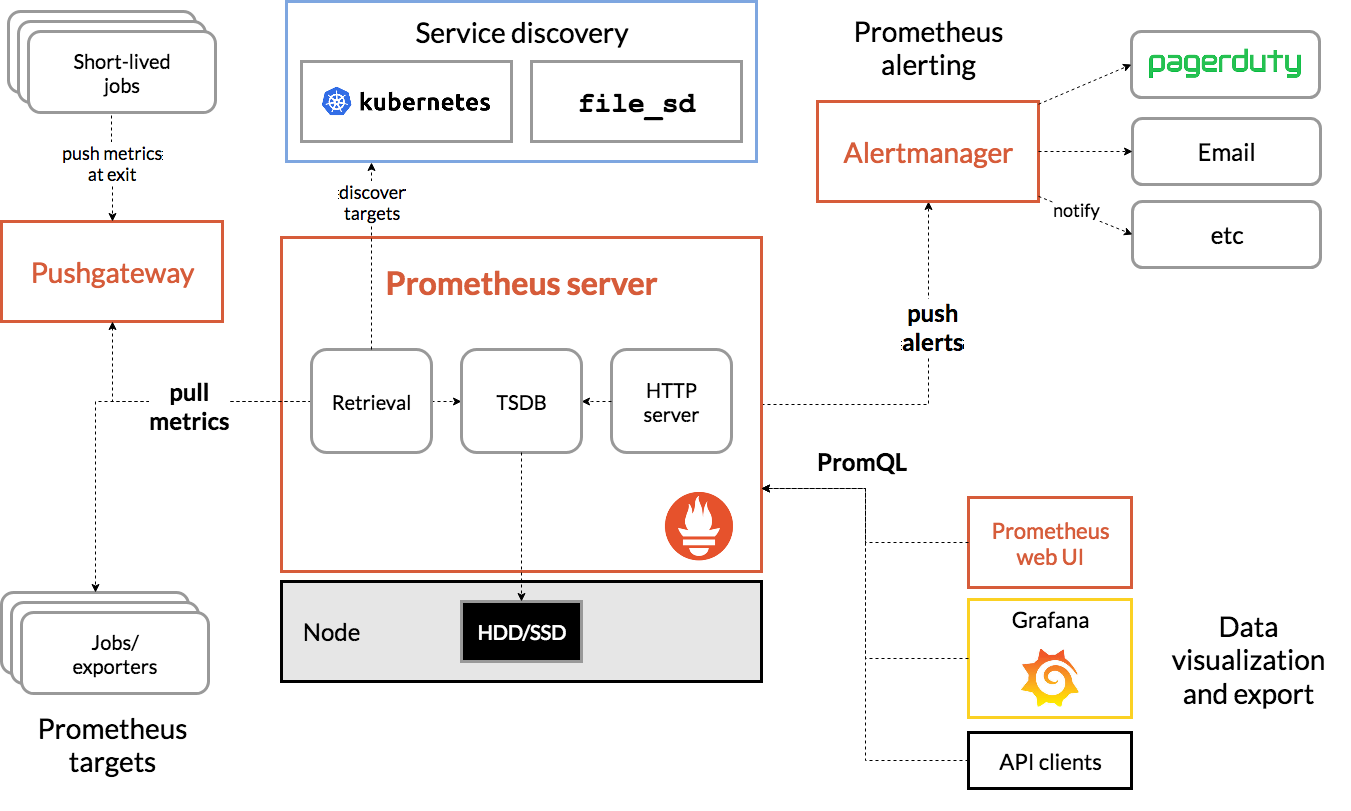
Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux系统信息(包括磁盘、内存、CPU、网络等等)。
Prometheus服务过程大概是这样:
- Prometheus server 定期从静态配置的 targets 或者服务发现的 targets 拉取数据。
- 当新拉取的数据大于配置内存缓存区的时候,Prometheus 会将数据持久化到磁盘(如果使用 remote storage 将持久化到云端)。
- Prometheus 可以配置 rules,然后定时查询数据,当条件触发的时候,会将 alert 推送到配置的 Alertmanager。
- Alertmanager 收到警告的时候,可以根据配置,聚合,去重,降噪,最后发送警告。
- 可以使用 API, Prometheus Console 或者 Grafana 查询和聚合数据。
Prometheus适用的场景
Prometheus在记录纯数字时间序列方面表现非常好。它既适用于面向服务器等硬件指标的监控,也适用于高动态的面向服务架构的监控。对于现在流行的微服务,Prometheus的多维度数据收集和数据筛选查询语言也是非常的强大。Prometheus是为服务的可靠性而设计的,当服务出现故障时,它可以使你快速定位和诊断问题。它的搭建过程对硬件和服务没有很强的依赖关系。Prometheus不适用的场景
Prometheus 它的价值在于可靠性,甚至在很恶劣的环境下,你都可以随时访问它和查看系统服务各种指标的统计信息。 如果你对统计数据需要100%的精确,它并不适用,例如:它不适用于实时计费系统。
Prometheus 官网:https://prometheus.io/TSDB
TSDB(Time Series Database)时序列数据库,数据中的数组是由时间进行索引的。时间序列数据库的特点
- 大部分时间都是写入操作。
- 写入操作几乎是顺序添加,大多数时候数据到达后都以时间排序。
- 写操作很少写入很久之前的数据,也很少更新数据。大多数情况在数据被采集到数秒或者数分钟后就会被写入数据库。
- 删除操作一般为区块删除,选定开始的历史时间并指定后续的区块。很少单独删除某个时间或者分开的随机时间的数据。
- 基本数据大,一般超过内存大小。一般选取的只是其一小部分且没有规律,缓存几乎不起任何作用。
- 读操作是十分典型的升序或者降序的顺序读。
- 高并发的读操作十分常见。
样本
Prometheus会将所有采集到的样本数据以时间序列(time-series)的方式保存在内存数据库中,并且定时保存到硬盘上。time-series是按照时间戳和值的序列顺序存放的,我们称之为向量(vector). 每条time-series通过指标名称(metrics name)和一组标签集(labelset)命名。如下所示,可以将time-series理解为一个以时间为Y轴的数字矩阵:
^│ . . . . . . . . . . . . . . . . . . . node_cpu{cpu="cpu0",mode="idle"}│ . . . . . . . . . . . . . . . . . . . node_cpu{cpu="cpu0",mode="system"}│ . . . . . . . . . . . . . . . . . . node_load1{}│ . . . . . . . . . . . . . . . . . .v<------------------ 时间 ---------------->
在time-series中的每一个点称为一个样本(sample),样本由以下三部分组成:
- 指标(metric):metric name和描述当前样本特征的labelsets;
- 时间戳(timestamp):一个精确到毫秒的时间戳;
- 样本值(value): 一个float64的浮点型数据表示当前样本的值。
<--------------- metric ---------------------><-timestamp -><-value->http_request_total{status="200", method="GET"}@1434417560938 => 94355http_request_total{status="200", method="GET"}@1434417561287 => 94334
metrics 类型
Counter
Counter 表示收集的数据是按照某个趋势(增加/减少)一直变化的,我们往往用它记录服务请求总量、错误总数等。
例如 Prometheus server 中 http_requests_total, 表示 Prometheus 处理的 http 请求总数,我们可以使用 delta, 很容易得到任意区间数据的增量,这个会在 PromQL 一节中细讲。
Gauge
Gauge 表示搜集的数据是一个瞬时的值,与时间没有关系,可以任意变高变低,往往可以用来记录内存使用率、磁盘使用率等。
例如 Prometheus server 中 go_goroutines, 表示 Prometheus 当前 goroutines 的数量。
Histogram
Histogram 由 <basename>_bucket{le="<upper inclusive bound>"},<basename>_bucket{le="+Inf"}, <basename>_sum,<basename>_count 组成,主要用于表示一段时间范围内对数据进行采样(通常是请求持续时间或响应大小),并能够对其指定区间以及总数进行统计,通常它采集的数据展示为直方图。
例如 Prometheus server 中 prometheus_local_storage_series_chunks_persisted, 表示 Prometheus 中每个时序需要存储的 chunks 数量,我们可以用它计算待持久化的数据的分位数。
Summary
Summary 和 Histogram 类似,由 <basename>{quantile="<φ>"},<basename>_sum,<basename>_count 组成,主要用于表示一段时间内数据采样结果(通常是请求持续时间或响应大小),它直接存储了 quantile 数据,而不是根据统计区间计算出来的。
例如 Prometheus server 中 prometheus_target_interval_length_seconds
安装Prometheus
Prometheus 官方给出了多重部署方案,比如:Docker 容器、Ansible、Chef、Puppet、Saltstack等。
Docker安装
若没有安装Docker,见https://yq.aliyun.com/articles/110806
拉取镜像
docker pull prom/prometheus
手动创建配置文件
为了更加方便的修改Prometheus的配置文件,将本机文件映射到docker容器中,所以需要手动创建一个默认文件
[root@control01 ~]# mkdir -p /etc/prometheus/[root@control01 ~]# vim /etc/prometheus/prometheus.ymlglobal:scrape_interval: 15s # 默认抓取间隔, 15秒向目标抓取一次数据。evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.# scrape_timeout is set to the global default (10s).# 这个标签是在本机上每一条时间序列上都会默认产生的,主要可以用于联合查询、远程存储、Alertmanger时使用。external_labels:monitor: 'codelab-monitor'# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.rule_files:# - "first.rules"# - "second.rules"# 这里就表示抓取对象的配置# 这里是抓去promethues自身的配置scrape_configs:# job name 这个配置是表示在这个配置内的时间序例,每一条都会自动添加上这个{job_name:"prometheus"}的标签。- job_name: 'prometheus'# metrics_path defaults to '/metrics'# scheme defaults to 'http'.# 重写了全局抓取间隔时间,由15秒重写成5秒。scrape_interval: 5sstatic_configs:- targets: ['172.16.143.13:9090']
启动容器
docker run -d -p 9090:9090 --name prometheus -v prometheus:/prometheus -v /etc/prometheus:/etc/prometheus prom/prometheus --config.file=/etc/prometheus/prometheus.yml
- 该
-d选项以分离模式启动Prometheus容器,这意味着容器将在后台启动,并且不会通过按下终止CTRL+C。 - 该
-p 9090:9090选项公开了Prometheus的Web端口(9090),并使其可通过主机系统的外部IP地址访问。 - 该
-v [...]选项将prometheus.yml配置文件从主机文件系统安装到Prometheus期望它的容器内的位置(/etc/prometheus/prometheus.yml,仅需更改宿主配置即可更新prometheus的配置 - 第一个
-v选项是用来指定存放容器数据的,当容器删除也不会被清理,实现数据持久化https://deepzz.com/post/the-docker-volumes-basic.html - 该
-config.file选项根据容器中 Prometheus配置文件的位置进行设置。
访问自带Web
Prometheus自带一个比较简单的Web,可以查看表达式搜索结果、报警配置、prometheus配置,exporter状态等。自带Web默认在http://ip:9090。
Prometheus本身也是自带exporter的,我们通过请求 http://ip:9090/metrics 可以查看从exporter中能具体抓到哪些数据。
这里以Prometheus本身数据为例,简单演示下在Web中查询指定表达式及图形化显示查询结果。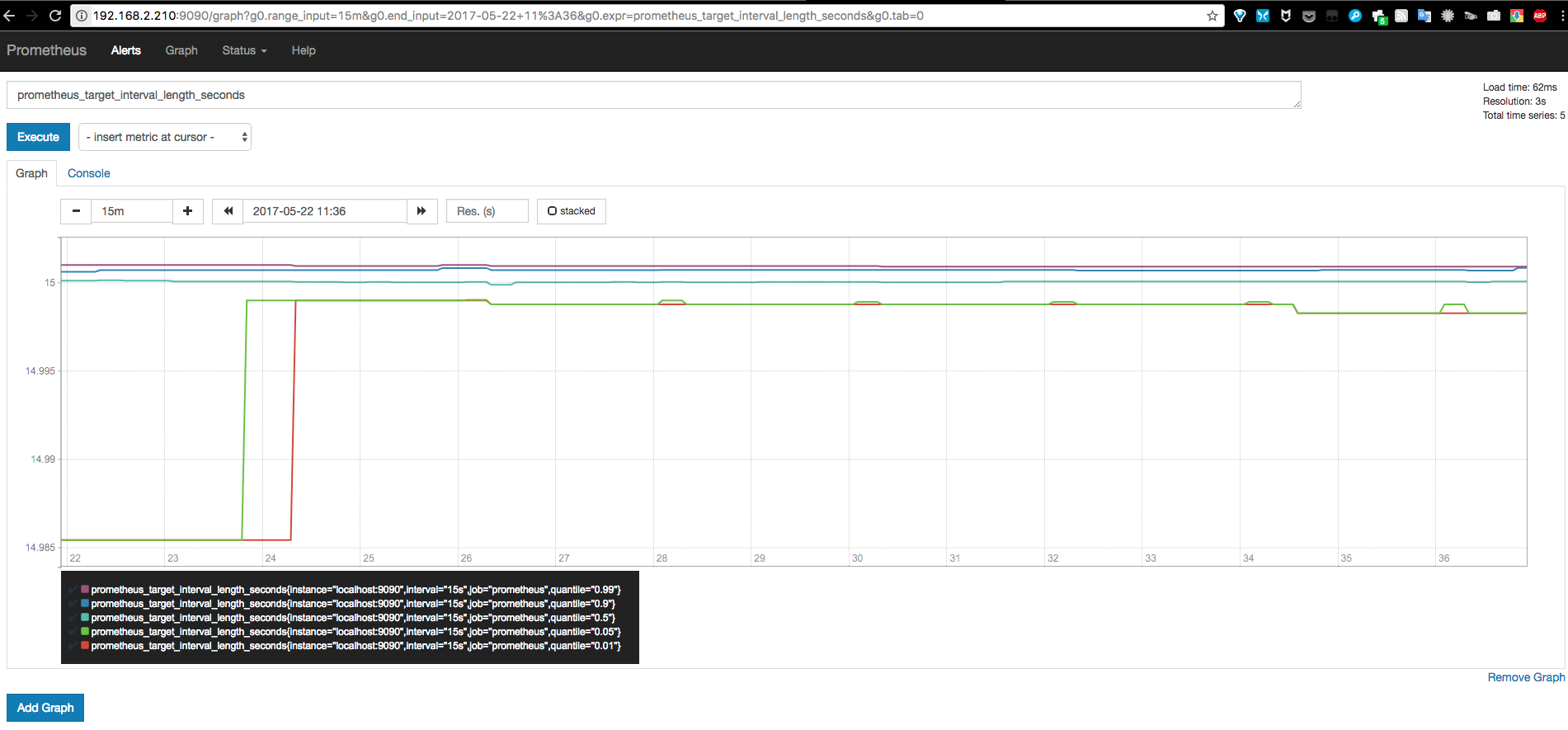
告警处理
当监控的数据不符要求或者超出阈值的时候,我们应该对此情形进行告警,并通知监控平台人员处理。Prometheus 提供了 alertmanager 来实现这个功能。
告警能力在Prometheus的架构中被划分成两个独立的部分。如下所示,通过在Prometheus中定义AlertRule(告警规则),Prometheus会周期性的对告警规则进行计算,如果满足告警触发条件就会向Alertmanager发送告警信息。
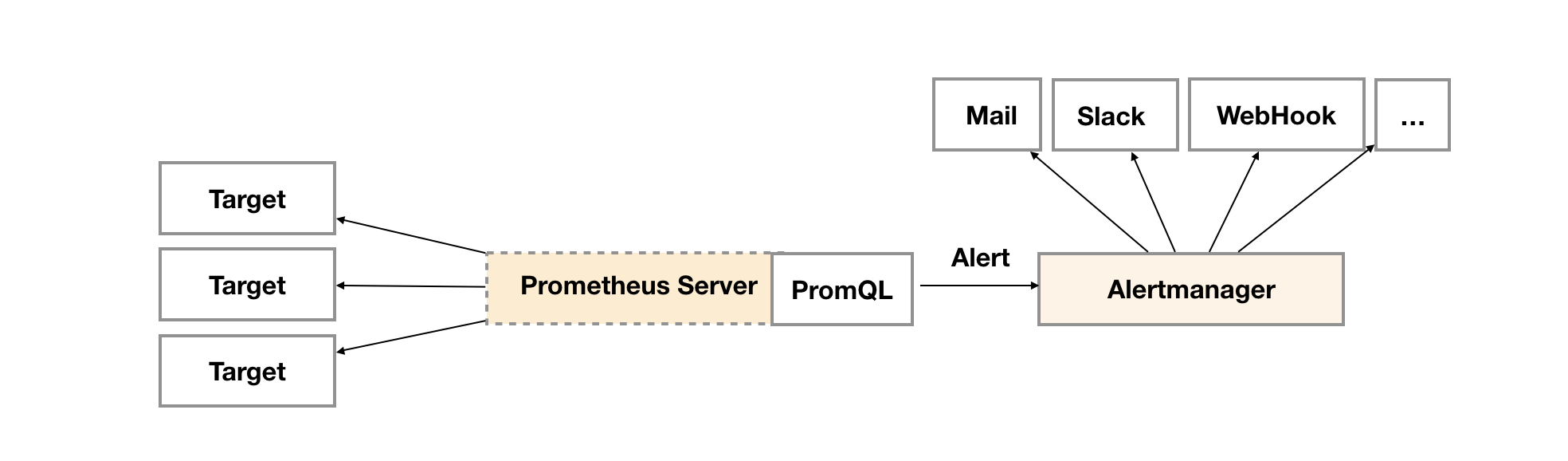
Prometheus 告警
在 Prometheus 中,一条告警规则分为两部分
- 告警名称:用户需要为告警规则命名,当然对于命名而言,需要能够直接表达出该告警的主要内容
- 告警规则:告警规则实际上主要由PromQL进行定义,其实际意义是当表达式(PromQL)查询结果持续多长时间(During)后出发告警
对于一组相关的告警如某一exporter的所有告警,可以采取 Group 的方式来统一定义。
定义告警规则
一般定义的告警规则可放在 Prometheus.yml 同级的 rules 目录下,然后根据相应的告警类型来编写 yaml 文件
groups:- name: examplerules:# Alert for any instance that is unreachable for >5 minutes.- alert: InstanceDownexpr: up == 0for: 5mlabels:severity: pageannotations:summary: "Instance {{ $labels.instance }} down"description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."# Alert for any instance that has a median request latency >1s.- alert: APIHighRequestLatencyexpr: api_http_request_latencies_second{quantile="0.5"} > 1for: 10mannotations:summary: "High request latency on {{ $labels.instance }}"description: "{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"
在告警规则文件中,我们可以将一组相关的规则设置定义在一个group下。在每一个group中我们可以定义多个告警规则(rule)。一条告警规则主要由以下几部分组成:
- alert:告警规则的名称。
- expr:基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件。
- for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending。
- labels:自定义标签,允许用户指定要附加到告警上的一组附加标签。
- annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager。
告警规则还需要让 Prometheus 知道他们的位置,如下:
rule_files:
[ - <filepath_glob> ... ]
Prometheus 默认每分钟对这些告警规则进行计算,用户也可以自定义时间
global:
[ evaluation_interval: <duration> | default = 1m ]
模板化
一般来说,在告警规则文件的annotations中使用summary描述告警的概要信息,description用于描述告警的详细信息。同时Alertmanager的UI也会根据这两个标签值,显示告警信息。为了让告警信息具有更好的可读性,Prometheus支持模板化label和annotations的中标签的值。
通过$labels.<labelname>变量可以访问当前告警实例中指定标签的值。$value则可以获取当前PromQL表达式计算的样本值。
查看告警状态
如下所示,用户可以通过Prometheus WEB界面中的Alerts菜单查看当前Prometheus下的所有告警规则,以及其当前所处的活动状态
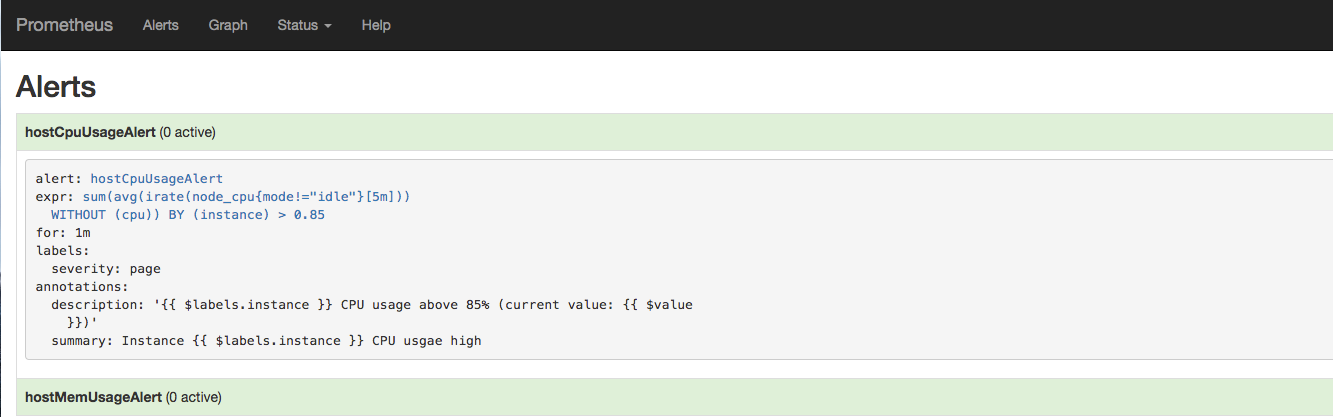
同时对于已经pending或者firing的告警,Prometheus也会将它们存储到时间序列ALERTS{}中。
可以通过表达式,查询告警实例:
ALERTS{alertname="<alert name>", alertstate="pending|firing", <additional alert labels>}
样本值为1表示当前告警处于活动状态(pending或者firing),当告警从活动状态转换为非活动状态时,样本值则为0
重启Prometheus后访问Prometheus UIhttp://127.0.0.1:9090/rules可以查看当前以加载的规则文件。State 代表Prometheus检测到的告警规则状态:是否有语法错误,能否检测的到等,当告警规则触发时,它的值依旧为 OK 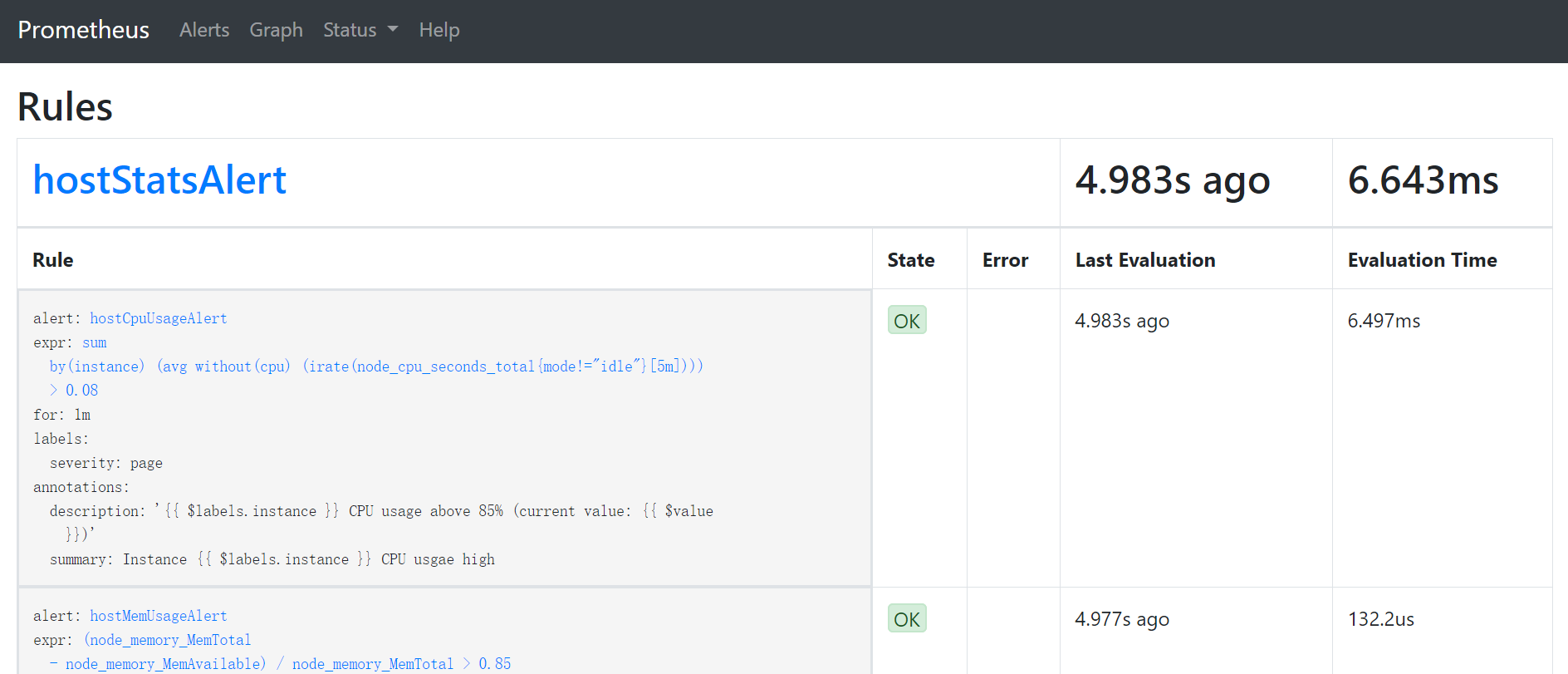
切换到Alerts标签http://127.0.0.1:9090/alerts可以查看当前告警的活动状态。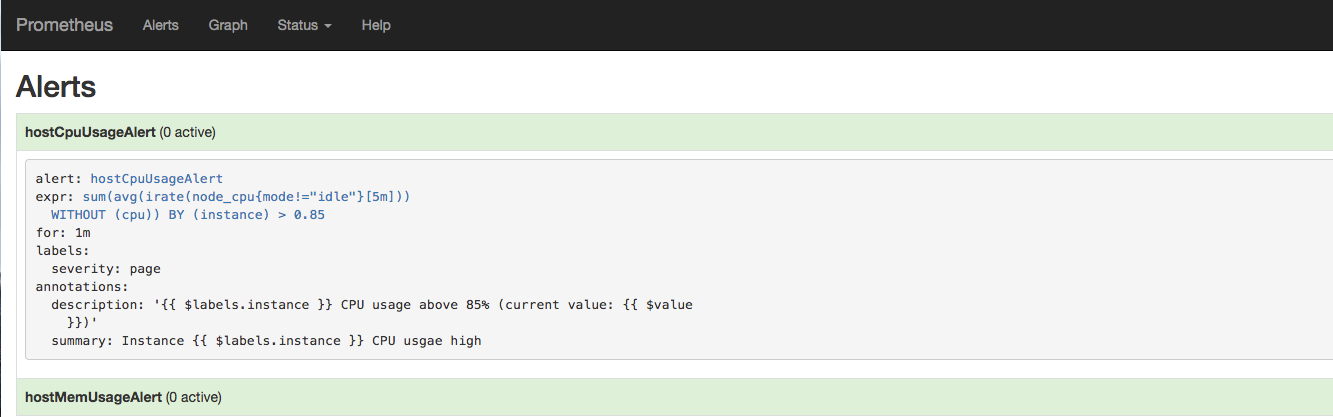
alertmanager
安装
docker pull prom/alertmanager
docker run -d -p 9093:9093 -v /etc/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml --name alertmanager prom/alertmanager
配置文件
在安装的时候手动创建了一个配置文件 alertmanager.yml
监控服务器
上面用Prometheus本身的数据简单演示了监控数据的查询,这里我们用一个监控服务器状态的例子来更加直观说明。
为监控服务器CPU、内存、磁盘、I/O等信息,首先需要安装 node_exporter 。 node_exporter 的作用是用于机器系统数据收集。
node_exporter安装
docker安装需要注意
- 拉取镜像
docker pull prom/node-exporter
- 运行容器
docker run -d --net="host" --pid="host" -v "/:/host:ro,rslave" prom/node_exporter --path.rootfs=/host
- 配置
Prometheus
- job_name: node
static_configs:
- targets: ['172.19.132.2:9100']
- 重启Prometheus
[root@control01 prometheus]# docker restart prometheus
- 在Prometheus Web查看监控的目标
访问Prometheus Web,在Status->Targets页面下,我们可以看到我们配置的两个Target,它们的State为UP。
使用Prometheus Web来验证Node Exporter的数据已经被正确的采集。
a) 查看当前主机的CPU使用情况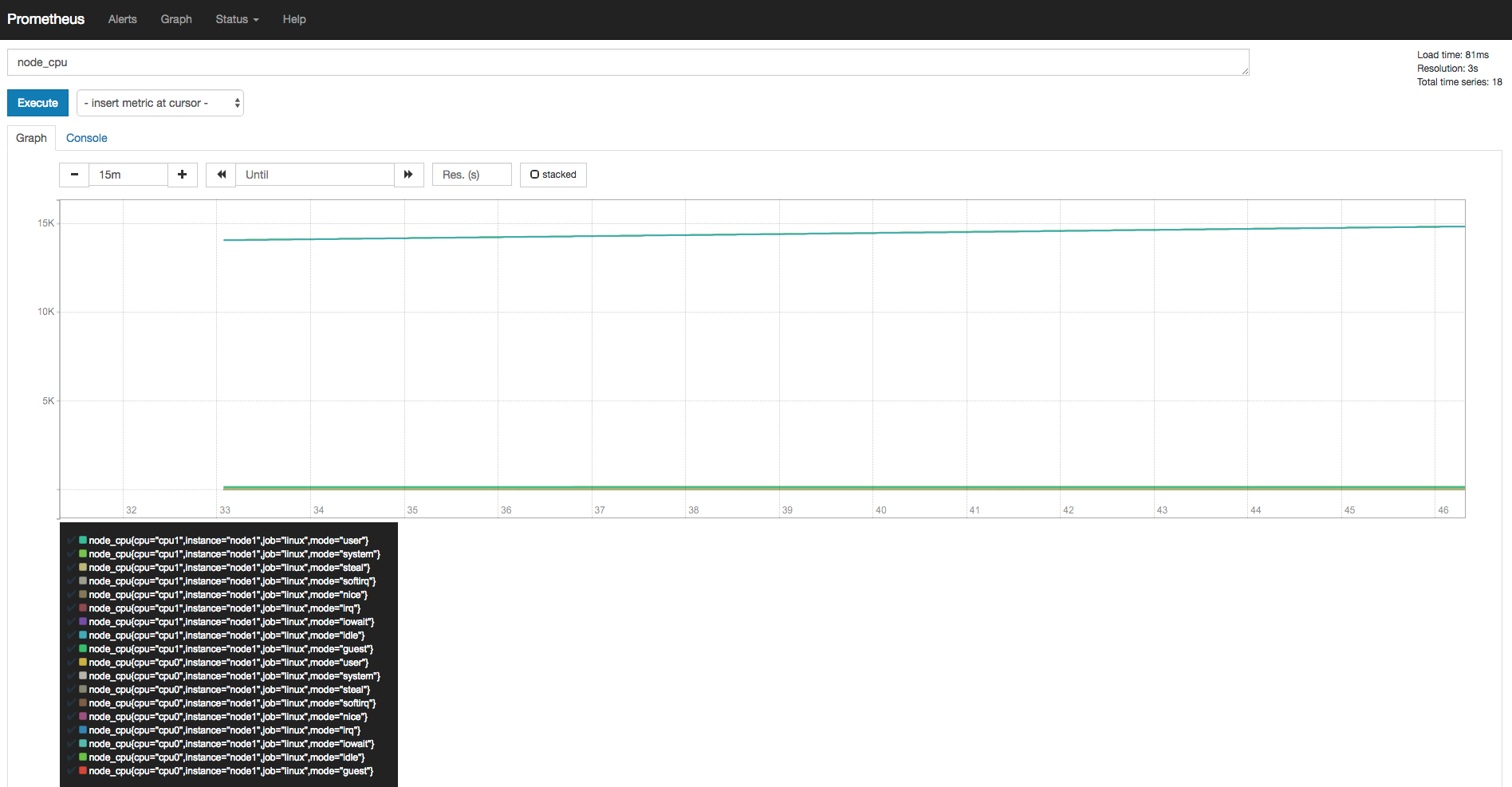
b) 查看当前主机的CPU负载情况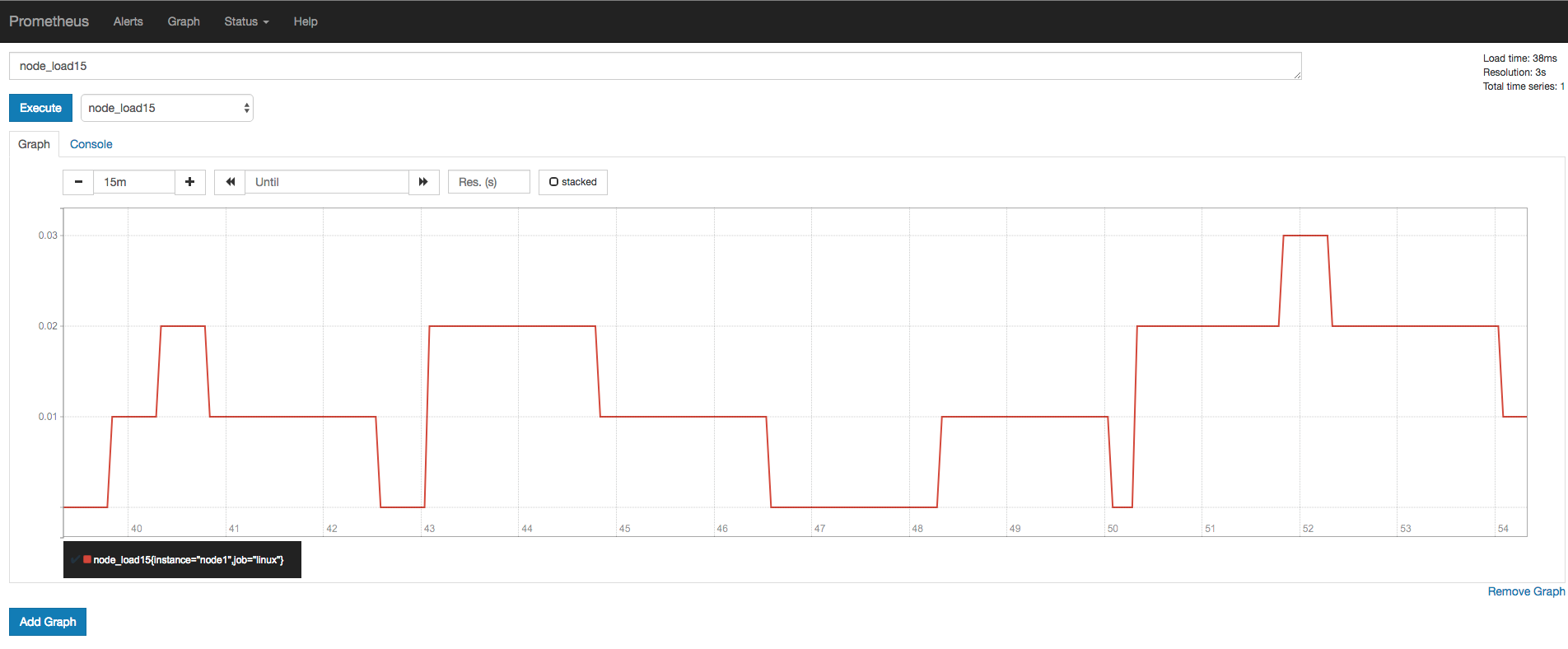
Prometheus Web界面自带的图表是非常基础的,比较适合用来做测试。如果要构建强大的Dashboard,还是需要更加专业的工具才行。接下来我们将使用Grafana来对Prometheus采集到的数据进行可视化展示。
Grafana
Grafana是用于可视化大型测量数据的开源程序,它提供了强大和优雅的方式去创建、共享、浏览数据。Dashboard中显示了你不同metric数据源中的数据。
Grafana最常用于因特网基础设施和应用分析,但在其他领域也有用到,比如:工业传感器、家庭自动化、过程控制等等。Grafana支持热插拔控制面板和可扩展的数据源,目前已经支持Graphite、InfluxDB、OpenTSDB、Elasticsearch、Prometheus等。
通过http://ip:3000访问Grafana Web界面(缺省帐号/密码为admin/admin)
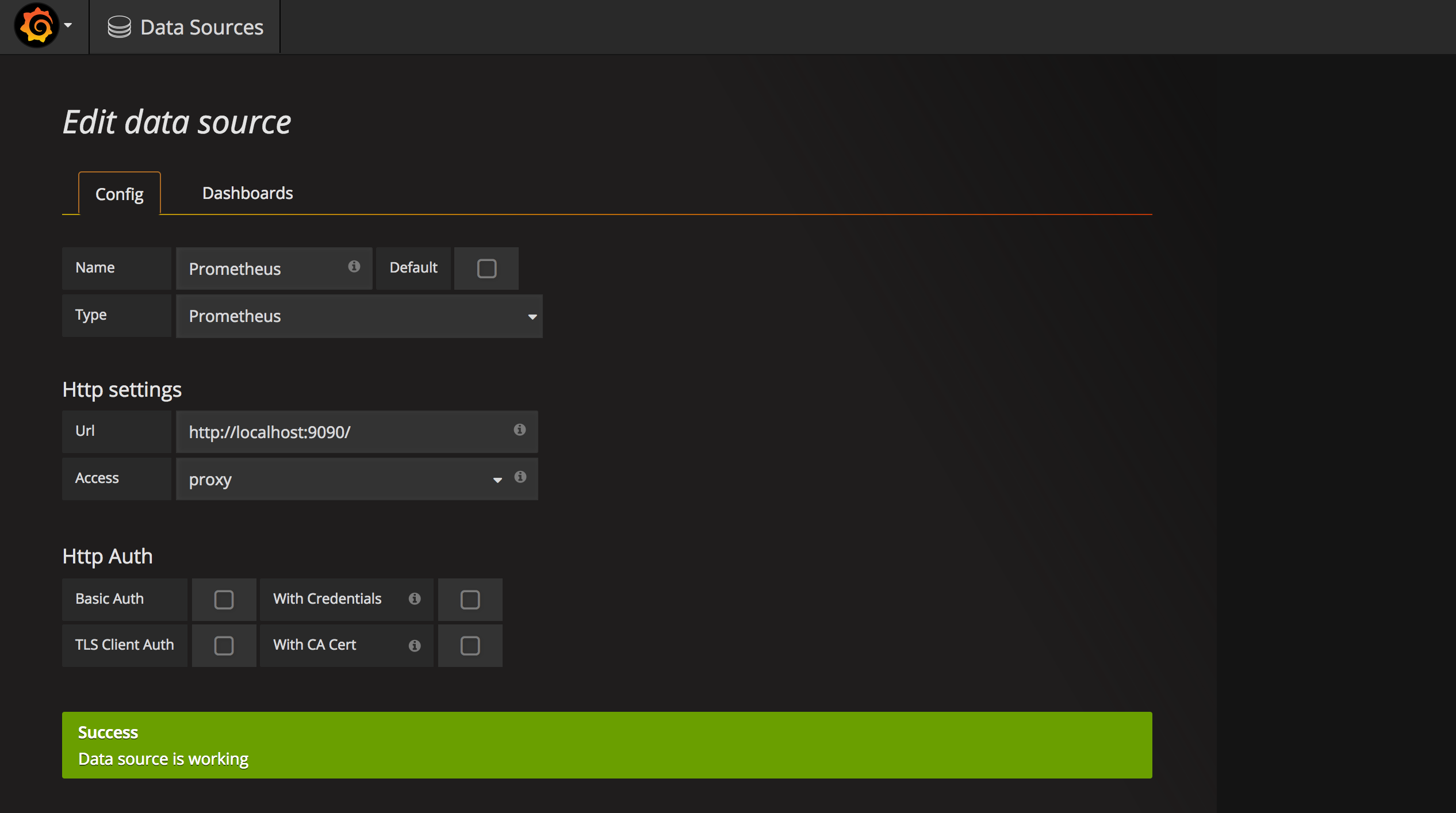
- 在Grafana中添加Prometheus数据源
在Dashboards页面导入自带的Prometheus Status模板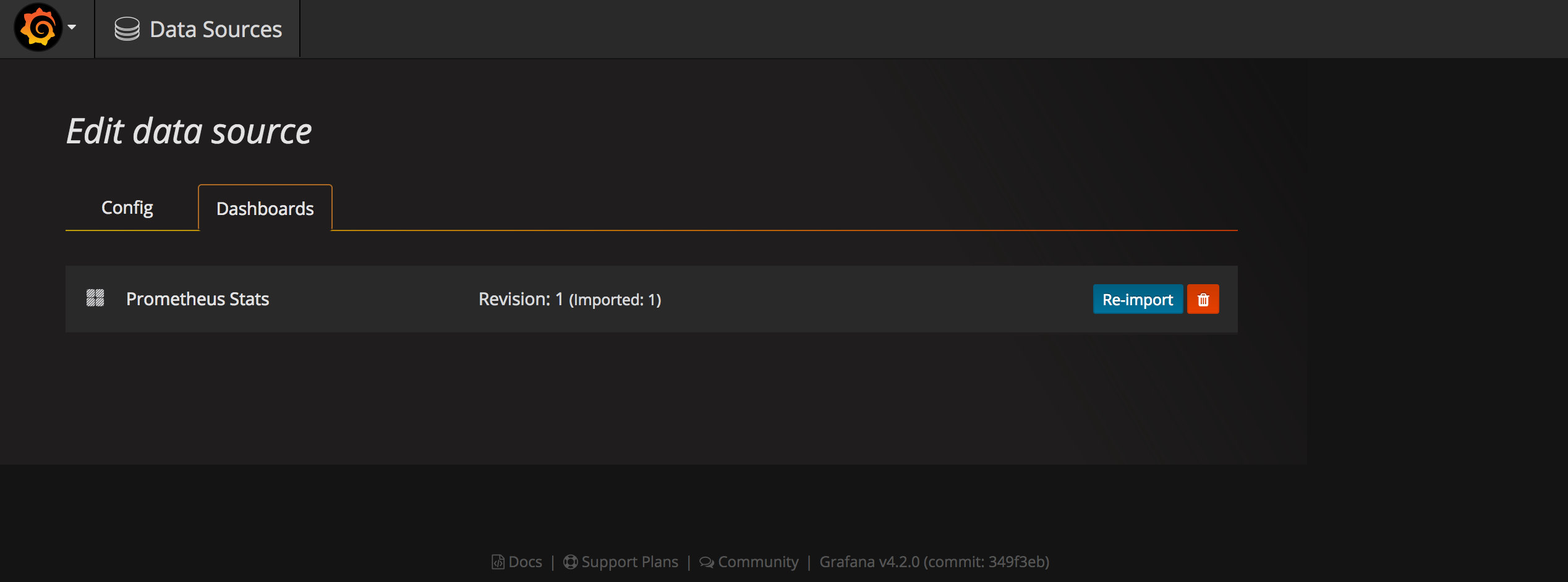
- 导入Node Exporter Server Metrics模板
访问https://grafana.com/dashboards/405,从这里下载Node Exporter Server Metrics模板的JSON文件。
在Grafana--Dashboard中导入这个文件,数据源选择Prometheus。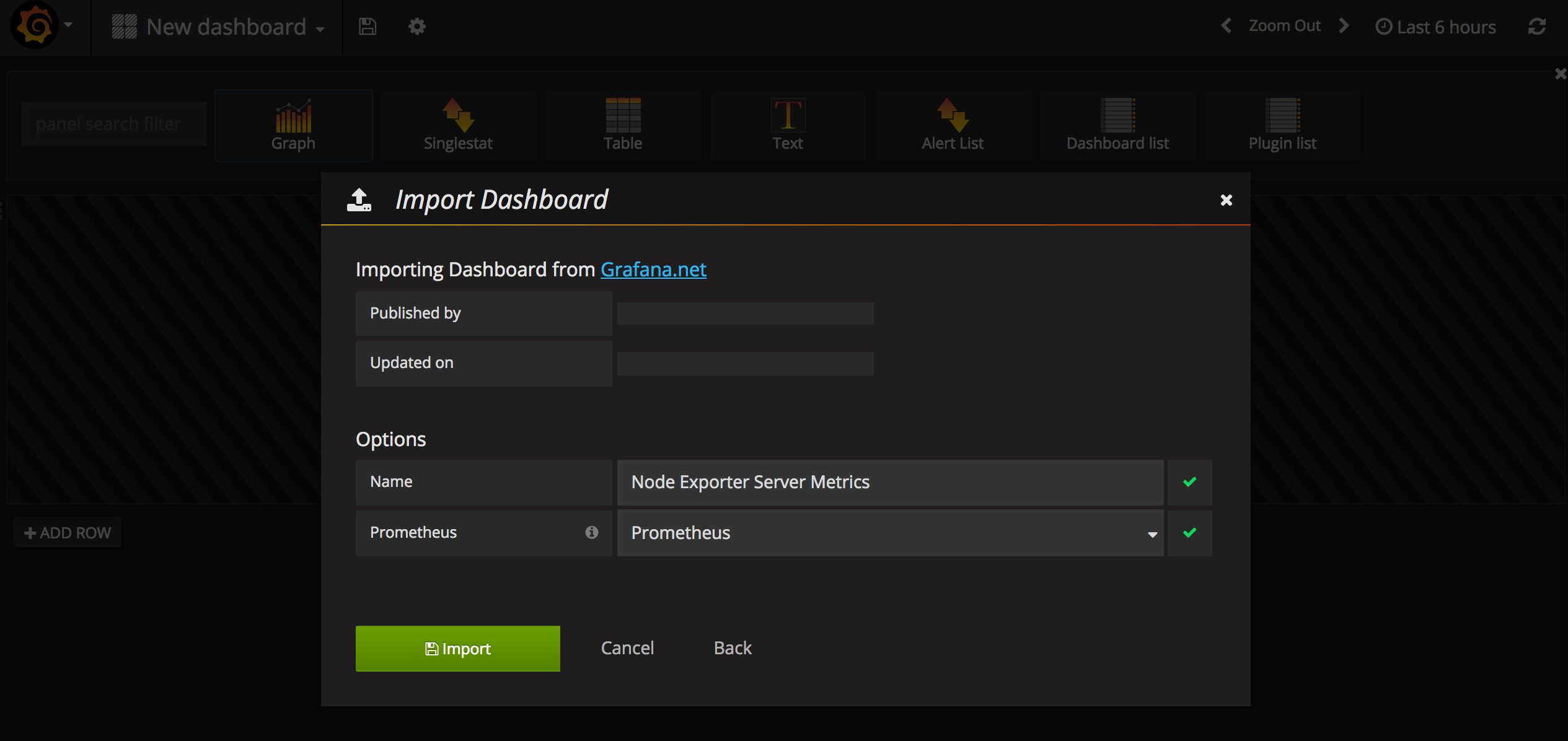
- 访问Dashboards
在Dashboards上选Node Exporter Server Metrics模板,就可以看到被监控服务器的CPU, 内存, 磁盘等统计信息。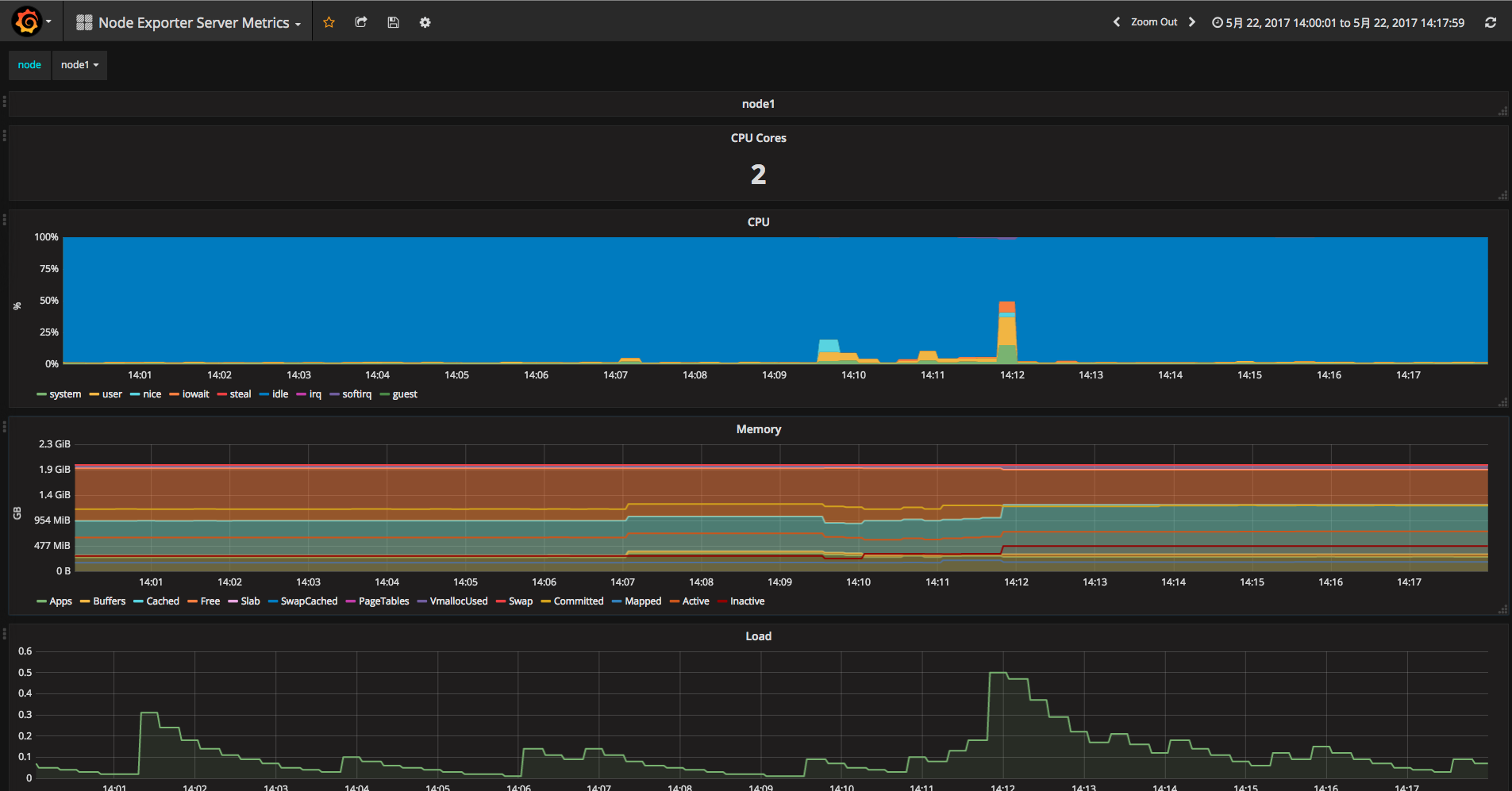
如果想具体查看某一项指标也是可以的。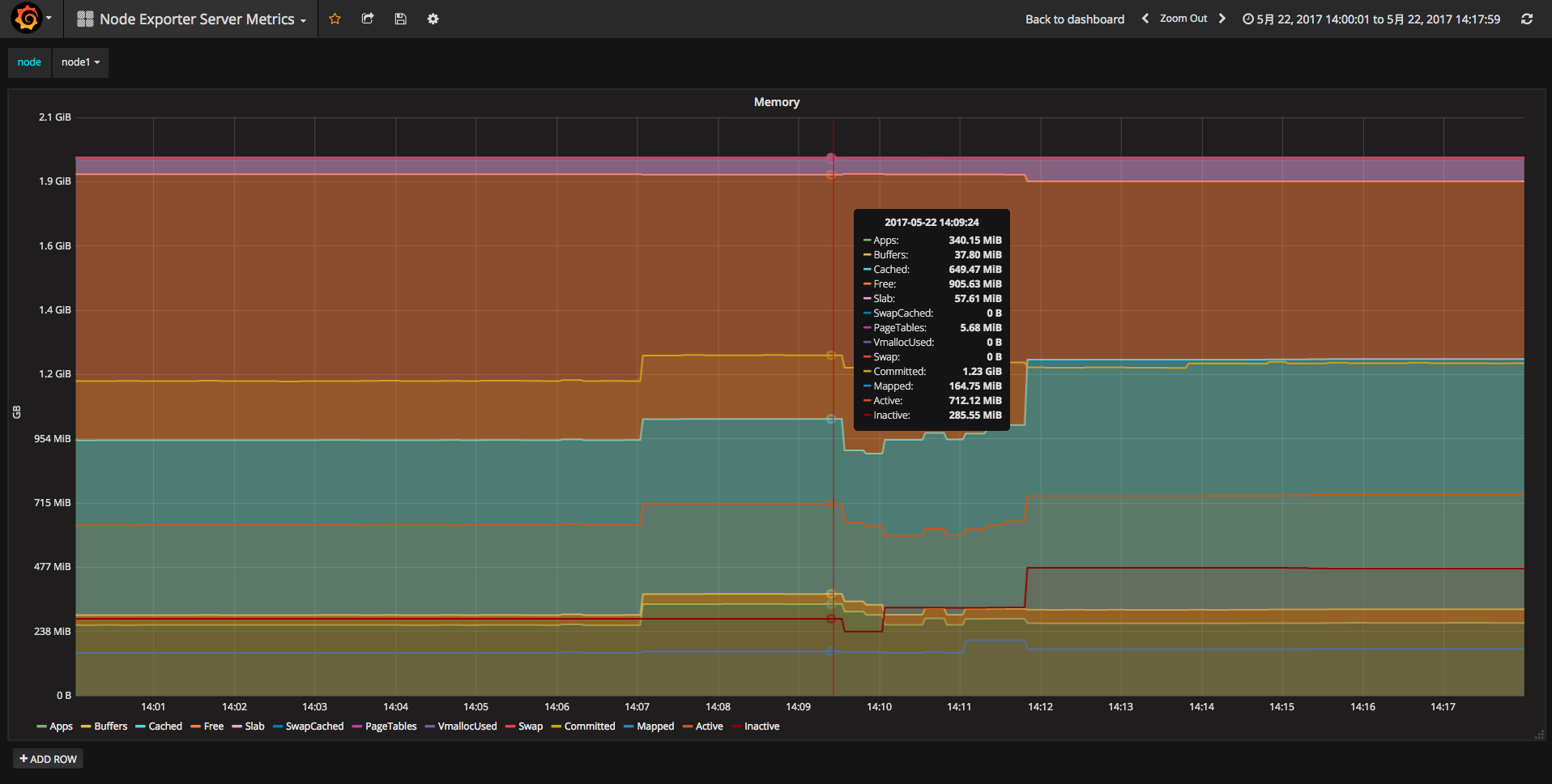
在Dashboards上选Prometheus Status模板,查看Prometheus各项指标数据。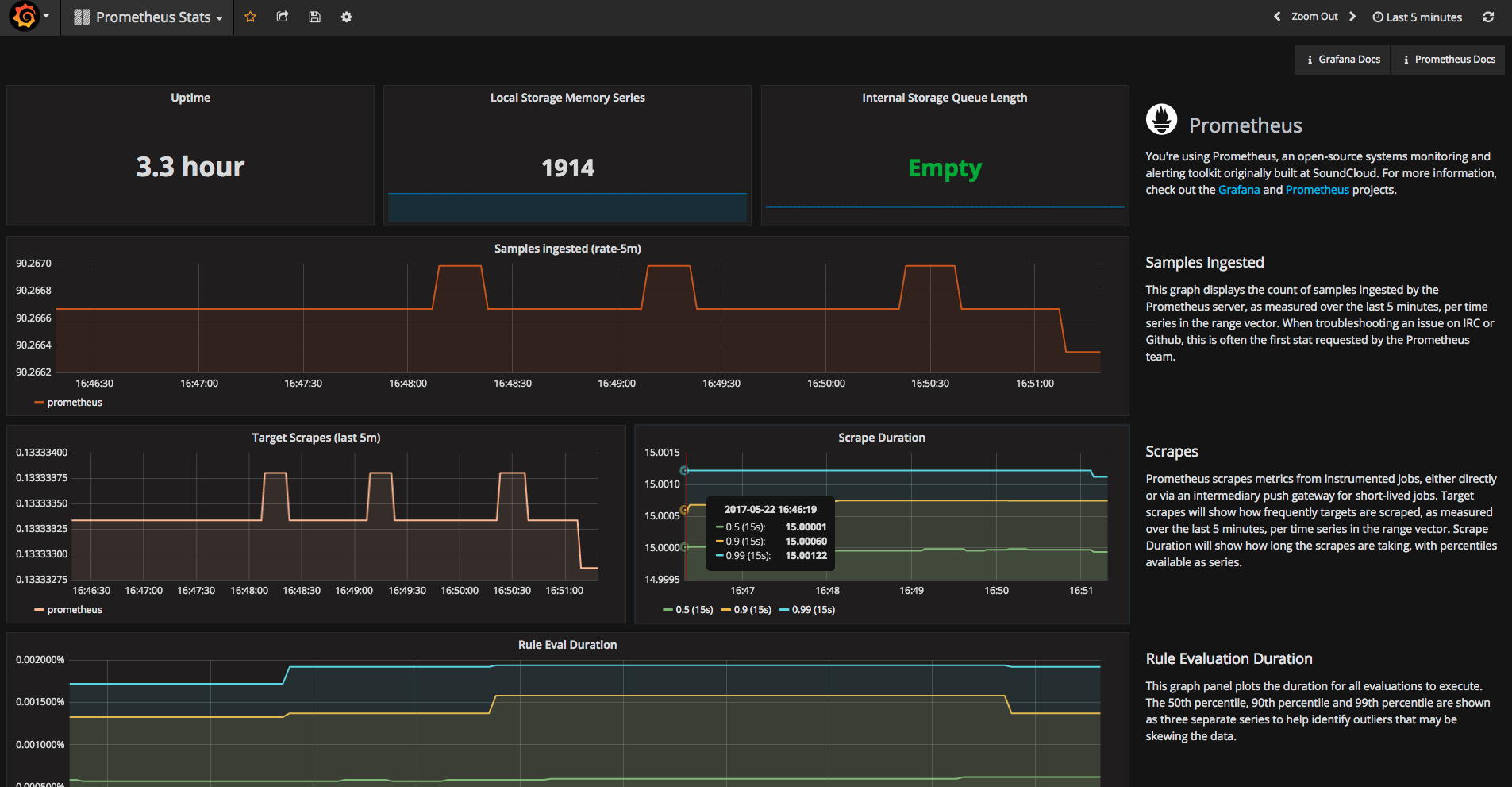
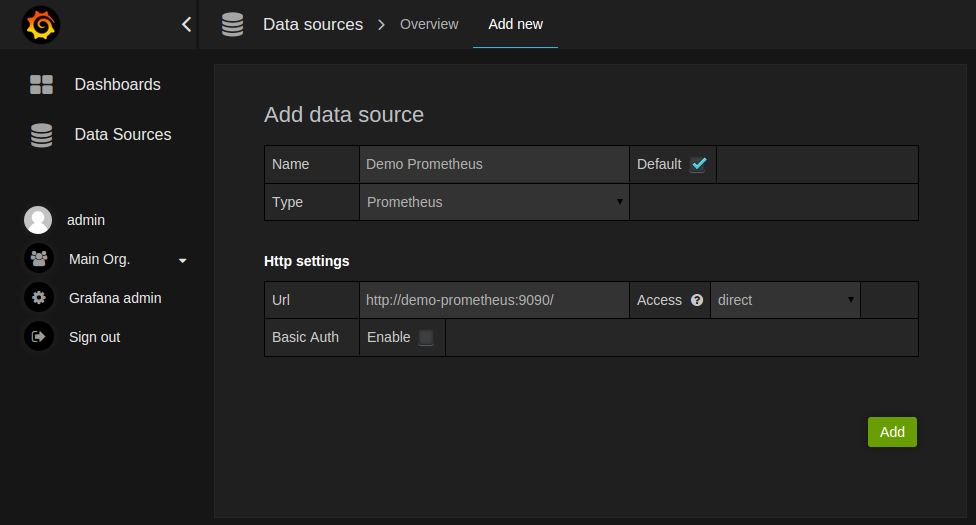
创建 Prometheus 数据源
创建一个 Prometheus 数据源操作步骤:
- 单击 Grafana 徽标以打开侧边栏菜单。
- 单击侧栏中的“Data Source”。
- 单击“Add New”。
- 选择“Prometheus”作为类型。
- 设置适当的 Prometheus 服务器的 HTTP URL
- 根据需要调整其他数据源设置(例如,关闭代理访问)。
- 单击“Add”以保存新数据源。
创建 Prometheus 数据图表
按照添加新 Grafana 图的标准方式:
- 单击图表标题,然后单击“Edit”。
- 在“Metrics”选项卡下,选择 Prometheus 数据源(右下角)。
- 在“Query”字段中输入任何 PromQL 表达式,同时使用“Metric”字段通过自动完成查找度量标准。
- 要格式化时间序列的图例名称,请使用“Legend format”输入。 例如,要仅显示返回的查询结果的
method和status标签(以短划线分隔),您可以使用图例格式字符串{{method}} - {{status}}。 - 调整其他设置,直到您有一个满意的图像。
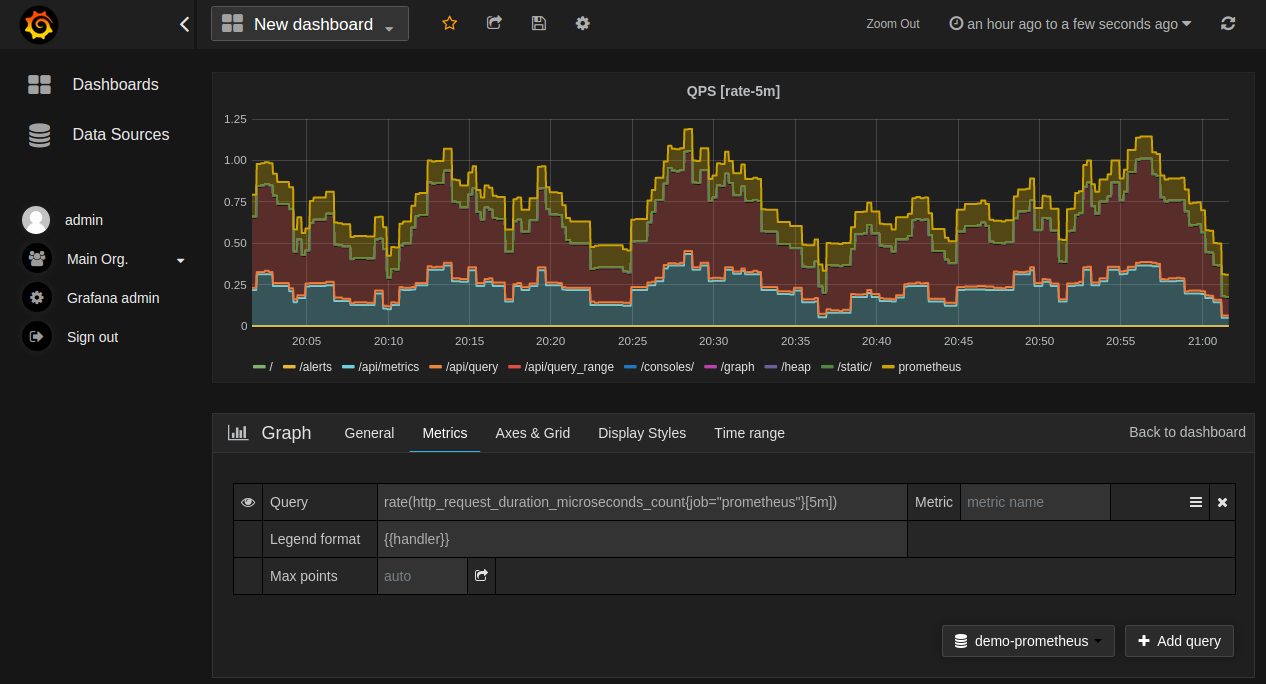
从Grafana.com导入预先构建的仪表板
Grafana.com维护一个 dashboard 共享库,它们能够下载并在Grafana服务中使用。使用 Grafana.net 的“Filter”选项去浏览来自 Prometheus 数据源的 dashboards 。当前必须手动编辑下载下来的 JSON 文件和更改datasource: 选择 Prometheus 服务作为 Grafana 的数据源,使用“Dashboard”->”Home”->”Import”选项去导入编辑好的 dashboard 文件到你的 Grafana 中。
SNMP
通过snmp_exporter监控交换机和服务器数据,snmp_exporter可以安装在任意机器上,只需要配置 prometheus.yml 指定要监控的机器即可
监控交换机
监控项
我们要先确定需求,根据需求查找监控项,华为交换机可以去链接查找
如:查找温度,我们找到了对象名称和所属 MIB 文件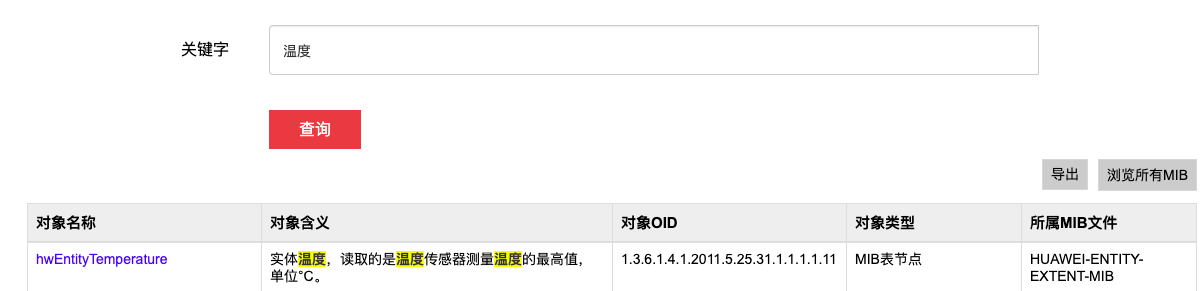
整理成表,如下:
| 监控项 | MIB | |
|---|---|---|
| hwCpuDevDuty | HUAWEI-CPU-MIB | |
| hwAvgDuty1min | HUAWEI-CPU-MIB | |
| hwAvgDuty5min | HUAWEI-CPU-MIB | |
| hwEntityFanPresent | HUAWEI-ENTITY-EXTENT-MIB | |
| hwEntityFanSpeed | HUAWEI-ENTITY-EXTENT-MIB | |
| hwEntityFanReg | HUAWEI-ENTITY-EXTENT-MIB | |
| hwEntityFanSpdAdjMode | HUAWEI-ENTITY-EXTENT-MIB | |
| hwEntityFanState | HUAWEI-ENTITY-EXTENT-MIB | |
| hwEntityTemperature | HUAWEI-ENTITY-EXTENT-MIB | |
| hwMemoryDevSize | HUAWEI-MEMORY-MIB | |
| hwMemoryDevFree | HUAWEI-MEMORY-MIB | |
| hwMemoryDevFree / hwMemoryDevSize * 100 | 此处是计算公式,可通过 | |
| ifHCOutOctets | IF-MIB | |
| ifHCInOctets | IF-MIB | |
| ifOperStatus | IF-MIB |
Generator
- 根据监控项去MIBS库下载所需
mib,放在/etc/snmp_exporter/mibs /etc/snmp_exporter目录下配置generator.yml,可参考 Github snmp-generator ```yaml modules: huawei: #模块名,snmp_exporter的Module输入 walk:- hwCpuDevDuty
- hwAvgDuty1min
- hwAvgDuty5min
- hwEntityFanPresent
- hwEntityFanSpeed
- hwEntityFanReg
- hwEntityFanSpdAdjMode
- hwEntityFanState
- hwEntityTemperature
- hwMemoryDevSize
- hwMemoryDevFree
- sysUpTime # 因为要添加
- interfaces
- ifXTable version: 2 lookups:
- source_indexes: [ifIndex] lookup: ifAlias
- source_indexes: [ifIndex] lookup: ifDescr
- source_indexes: [ifIndex]
Use OID to avoid conflict with Netscaler NS-ROOT-MIB.
lookup: 1.3.6.1.2.1.31.1.1.1.1 # ifName overrides: ifAlias: ignore: true # Lookup metric ifDescr: ignore: true # Lookup metric ifName: ignore: true # Lookup metric ifType: type: EnumAsInfo
4. generator 生成配置文件
```shell
docker pull prom/snmp-generator:v0.17.0
docker run -ti \
-v "${PWD}:/opt/" \
prom/snmp-generator:v0.17.0 generate
能生成配置文件即成功,日志中的错误信息忽略即可, Ctrl+C 停止,当前目录下生成了 snmp.yml
[root@control01 snmp_exporter]# docker run -ti \
> -v "${PWD}:/opt/" \
> prom/snmp-generator:v0.17.0 generate
level=info ts=2020-03-27T09:46:03.318Z caller=net_snmp.go:142 msg="Loading MIBs" from=mibs
level=warn ts=2020-03-27T09:46:03.383Z caller=main.go:120 msg="NetSNMP reported parse error(s)" errors=1
level=info ts=2020-03-27T09:46:03.427Z caller=main.go:52 msg="Generating config for module" module=huawei
level=info ts=2020-03-27T09:46:03.440Z caller=main.go:67 msg="Generated metrics" module=huawei metrics=50
level=info ts=2020-03-27T09:46:03.456Z caller=main.go:92 msg="Config written" file=/opt/snmp.yml
Exporter
- 运行
exporterdocker pull prom/snmp-exporter:v0.17.0 docker run -d --name="snmp_exporter" -p 9116:91116 -v "/etc/snmp_exporter/snmp.yml:/etc/snmp_exporter/snmp.yml" prom/snmp-exporter:v0.17.0
查看exporter获取的数据
- 访问
exporter,地址为http://exporter安装地址:9116 - 输入要监控的ip地址——Target,用到的模块——Module(监控华为的就用上面的huawei)
- 得到数据,如下:

Prometheus
配置很简单,只需要设置module、targets和exporter的地址即可
scrape_configs:
- job_name: snmp_exporter_huawei
scrape_interval: 60s
scrape_timeout: 30s
static_configs:
- targets:
- 172.16.208.2:10161
metrics_path: /snmp
params:
module: ['huawei']
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: "172.16.143.13:9116"
- 可以添加多个 targets 目标,只要监控项都再同一个module中
- 如果多个 targets 用到不同的 module,需要另添加一个 job,设置 module
比如又需要监控cisco交换机,用到了 cisco 模块,则需要添加一个 job,module 名设置 cisco
监控服务器
snmpwalk 命令行测试能否获取华为服务器数据
snmpwalk -v3 -l authPriv -u root -a SHA -A $(cat 1.txt) -x AES -X $(cat 1.txt) 192.168.2.105用
$(cat 1.txt)而不直接使用密码的原因是因为此处服务器的密码有$下载
HUAWEI-SERVER-IBMC-MIB,放到默认的/root/.snmp/mibs- 配置
generator.yml
modules:
huawei-ibmc:
walk:
- fanMode
- fanLevel
- fanStatus
- fanEntireStatus
- fanSpeed
- fanSpeedRatio
- hardDiskTemperature
- temperatureEntireStatus
- systemCpuUsage
- cpuStatus
- cpuEntireStatus
- systemMemUsage
- memoryStatus
- memoryEntireStatus
- raidControllerMode
- raidControllerHealthStatus
- hardDiskStatus
- hardDiskEntireStatus
- hardDiskPresence
- hardDiskFwState
- hardDiskPowerState
- hardDiskTemperature
version: 3
auth:
security_level: authPriv
username: "root"
password: "Huawei12$#"
auth_protocol: SHA
priv_protocol: AES
priv_password: "Huawei12$#"
generator生成snmp.yml
/go/bin/generator generate # 在 docker shell 中
- 启动
snmp_exporter
./snmp_exporter
- 配置
prometheus.yml
- job_name: snmp_server
scrape_interval: 1m
scrape_timeout: 30s
metrics_path: /snmp
static_configs:
- targets:
- 192.168.2.105
params:
module:
- huawei-ibmc
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 172.16.143.12:9116
snmptranslate
解析mib文件中的变量
snmptranslate -On SNMPv2-MIB::system.sysUpTime.0
获取华为服务器数据
[root@control01 ~]# snmpwalk -v3 -l authPriv -u root -a SHA -x AES -A Huawei12$# -X Huawei12$# 192.168.2.105
snmpwalk: Authentication failure (incorrect password, community or key)
Huawei12$# 密码中有 $ , $ 在shell中用来表示变量,所以 Huawe12$# 会变成 Huawei120 导致密码错误。感谢link的提示!
IPMI
安装
docker pull dragonphy/ipmi_exporter:v1.1.0
手动创建配置文件
与prometheus的安装类似,将配置文件放在宿主机上,方便修改
[root@control01 ~]# mkdir -p /etc/ipmi_exporter
[root@control01 ipmi-exporter]# vim /etc/ipmi_exporter/config.yml
modules:
172.16.140.202:
user: "root"
pass: "99cloud@sh@vgpu"
driver: "LAN_2_0"
collectors:
- bmc
- ipmi
- chassis
- dcmi
172.16.140.203:
user: "root"
pass: "99cloud@sh@vgpu"
driver: "LAN_2_0"
collectors:
- bmc
- ipmi
- chassis
- dcmi
192.168.2.105:
user: "root"
pass: "Huawei12$#"
driver: "LAN_2_0"
collectors:
- bmc
- ipmi
- chassis
- dcmi
启动容器
docker run -d --name ipmi_exporter -p 9290:9290 -v /etc/ipmi_exporter/config.yml:/config.yml dragonphy/ipmi_exporter:v1.1.0 --config.file=/config.yml
修改prometheus配置文件
- 在
/etc/prometheus目录下创建ipmi_exporter目录,添加YAML文件targets.yml,这是因为ipmi_exporter配置文件有三个模块,为了方便配置文件的管理,采用动态加载配置文件的方式
- job_name: ipmi
scrape_interval: 1m
scrape_timeout: 30s
metrics_path: /ipmi
file_sd_configs:
- files:
- /etc/prometheus/ipmi_exporter/targets.yml # 需手动创建
refresh_interval: 5m
relabel_configs:
- source_labels: [__address__]
separator: ;
regex: (.*)
target_label: __param_target
replacement: ${1}
action: replace
- source_labels: [__param_target]
separator: ;
regex: (.*)
target_label: instance
replacement: ${1}
action: replace
- source_labels: [__address__]
separator: ;
regex: (.*)
target_label: __param_module
replacement: ${1}
action: replace
- separator: ;
regex: .*
target_label: __address__
replacement: 172.16.143.11:9290 # 此处为ipmi_exporter安装机器ip、端口
action: replace
Prometheus热更新
当 Prometheus 有配置文件修改,我们可以采用 Prometheus 提供的热更新方法实现在不停服务的情况下实现配置文件的重新加载。
配置文件
kill -HUP pid
对于Docker安装的需要进入容器内部,然后执行 kill -HUP pid ,可编写 shell 脚本,定时检测配置文件是否改变
[root@control01 ~]# docker exec -it prometheus sh
/prometheus $ ps -ef | grep prom
1 nobody 6:14 /bin/prometheus --config.file=/etc/prometheus/prometheus.yml
58 nobody 0:00 grep prom
/prometheus $ kill -HUP 1
curl -X POST http://IP/-/reload
需要在启动prometheus进程时,指定 --web.enable-lifecycle ,默认是没有指定的,所以需要修改Docker镜像
问题
- ipmi无法连接华为服务器:
ipmi-sensors: authentication type unavailable for attempted privilege level
- IPMI LAN(RMCP) 没有启用
- ipmi_ctx_open_outofband: BMC busy
1)使用ipmitool
当同时向 BMC 发送过多 IPMI 查询时,将发生此错误。[1] 尤其是在用于监视 IPMI 传感器的不同软件执行 IPMI 查询而不缓存传感器数据记录 (SDR) 存储库数据时,这种情况尤其发生。经验表明,查询此 SDR 存储库最多可能需要 10 秒或更长时间。 FreeIPMI 会自动创建此类缓存,使用 ipmitool,必须手动创建缓存,并在以后使用该选项。以下是 ipmitool 曼页中的相应摘录:
-S
-S <sdr_cache_file>
Use local file for remote SDR cache. Using a local SDR cache
can drastically increase performance for commands that require
knowledge of the entire SDR to perform their function. Local
SDR cache from a remote system can be created with the sdr dump
command.
2)freeipmi
太多ipmi的请求以致BMC无法处理全部,可以考虑增加 scrape_interval ,或者查看是否有多个exporter在请求同一个BMC
targets中的Error栏目报 context deadline exceeded
爬取超时问题,可能是node_exporter响应时间长,或者是网络问题。 修改 scrape_timeout: 1s 时间,如果scrape_interval时间少于10s,则超时时间默认为scrape_interval爬取时间。
one or more errors occurred while applying the new configuration (—config.file=\”/etc/prometheus/prometheus.yml\”)”
参考
- 如何保存prometheus容器的数据
- 解决freeipmi连接RH2288 V3服务器失败问题-authentication
- Prometheus 热更新
- Prometheus安装与配置
- 如何让snmp_generator识别到mibs
- snmpwalk command
- snmpwalk: Authentication failure (incorrect password, community or key)解题思路
- context deadline exceeded
- ipmi_ctx_open_outofband: BMC busy
- how to use snmp generator & generator logs error%7Csort:date)

若有收获,就点个赞吧
0 人点赞
