广度优先搜索(BFS)的一个常见应用是找出从根结点到目标结点的最短路径。在本文中,我们提供了一个示例来解释在 BFS 算法中是如何逐步应用队列的。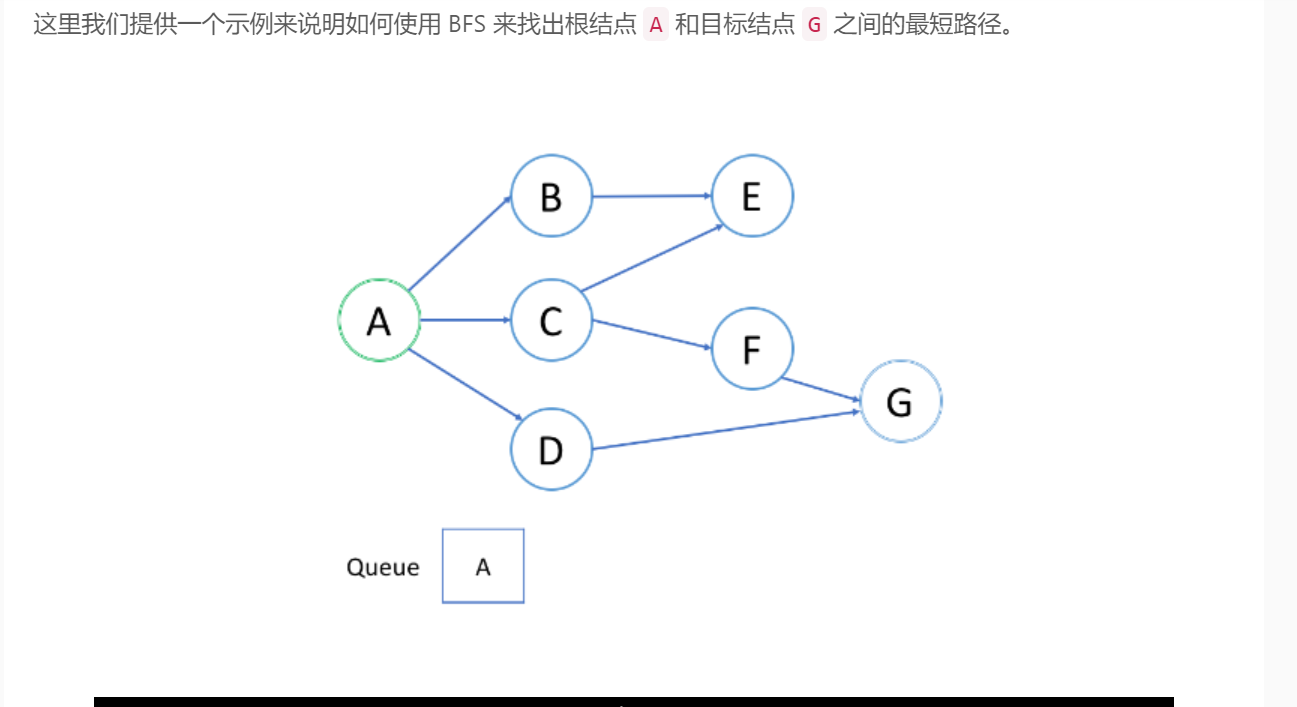
1. 结点的处理顺序是什么?
在第一轮中,我们处理根结点。在第二轮中,我们处理根结点旁边的结点;在第三轮中,我们处理距根结点两步的结点;等等等等。
与树的层序遍历类似,越是接近根结点的结点将越早地遍历。
如果在第 k 轮中将结点 X 添加到队列中,则根结点与 X 之间的最短路径的长度恰好是 k。也就是说,第一次找到目标结点时,你已经处于最短路径中。
2. 队列的入队和出队顺序是什么?
如上面的动画所示,我们首先将根结点排入队列。然后在每一轮中,我们逐个处理已经在队列中的结点,并将所有邻居添加到队列中。值得注意的是,新添加的节点不会立即遍历,而是在下一轮中处理。
结点的处理顺序与它们添加到队列的顺序是完全相同的顺序,即先进先出(FIFO)。这就是我们在 BFS 中使用队列的原因。
BFS模板1
/*** Return the length of the shortest path between root and target node.*/int BFS(Node root, Node target) {Queue<Node> queue; // store all nodes which are waiting to be processedint step = 0; // number of steps neeeded from root to current node// initializeadd root to queue;// BFSwhile (queue is not empty) {step = step + 1;// iterate the nodes which are already in the queueint size = queue.size();for (int i = 0; i < size; ++i) {Node cur = the first node in queue;return step if cur is target;for (Node next : the neighbors of cur) {add next to queue;}remove the first node from queue;}}return -1; // there is no path from root to target}
- 如代码所示,在每一轮中,队列中的结点是
等待处理的结点。 - 在每个更外一层的
while循环之后,我们距离根结点更远一步。变量step指示从根结点到我们正在访问的当前结点的距离。
BFS模板2
有时,确保我们永远不会访问一个结点两次很重要。否则,我们可能陷入无限循环。如果是这样,我们可以在上面的代码中添加一个哈希集来解决这个问题。这是修改后的伪代码:
/*** Return the length of the shortest path between root and target node.*/int BFS(Node root, Node target) {Queue<Node> queue; // store all nodes which are waiting to be processedSet<Node> used; // store all the used nodesint step = 0; // number of steps neeeded from root to current node// initializeadd root to queue;add root to used;// BFSwhile (queue is not empty) {step = step + 1;// iterate the nodes which are already in the queueint size = queue.size();for (int i = 0; i < size; ++i) {Node cur = the first node in queue;return step if cur is target;for (Node next : the neighbors of cur) {if (next is not in used) {add next to queue;add next to used;}}remove the first node from queue;}}return -1; // there is no path from root to target}

若有收获,就点个赞吧
0 人点赞
