查询语句执行过程

连接器
负责跟客户端建立连接、获取权限、维持和管理连接。
连接器通过用户输入的用户名和密码验证用户身份:
- 验证失败,用户会收到一个
Access denied for user的错误。 - 验证成功,连接器会到权限表中查询该用户所拥有的权限,此次连接中的权限判断都依赖于此时读取到的权限。
因此当用户成功建立连接后,即使你的权限被修改,也不会影响已存在连接的权限,只有建立新的连接才会使用新的权限设置。
MySQL通常使用长连接,而执行过程中临时使用的内存都是管理在连接对象中的,只有当连接关闭资源才会被释放。如果长连接过多,会导致内存占用太大,被系统强行杀掉,导致MySQL异常重启。
分析器
- 词法分析
判断输入的字符在MySQL中代表什么:表名、列名……
- 语法分析
优化器
执行器
首先判断是否拥有对要查询的表执行查询的权限,没有则返回权限错误,有权限则打开表继续执行
redo log、binlog
不同点
- redo log(重做日志)是InnoDB引擎特有的日志,是物理日志,记录的是「在某个数据页上做了什么修改」
- binlog(归档日志)是MySQL的Server层实现的,是逻辑日志,记录的是这个语句的原始逻辑,比如 「给 ID=2 这一行的 c 字段加 1 」
redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。「追加写」 是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志
更新执行流程

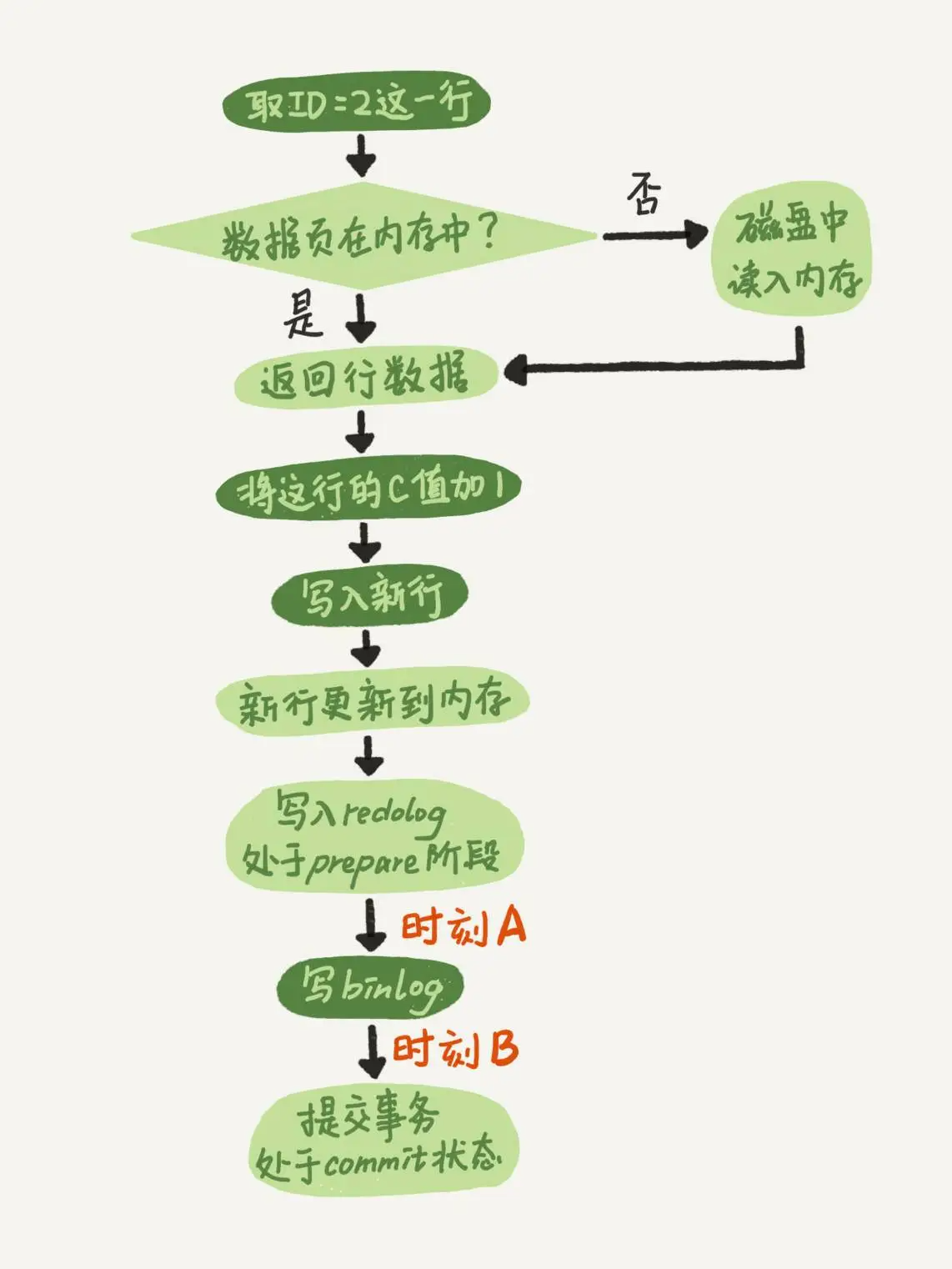
执行器先找引擎取 ID=2 这一行。ID 是主键,引擎直接用树搜索找到这一行。如果 ID=2 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据,把这个值加上 1,比如原来是 N,现在就是 N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。
崩溃恢复
崩溃恢复时的原则:如果 redo log 里面的事务是完整的,也就是已经有了commit标识,则直接提交;
- 如果 redo log 里面的事务只有完整的 prepare,则判断对应的事务binlog是否存在并完整(statement格式的 binlog,最后会有 COMMIT;row 格式的 binlog,最后会有一个 XID event):
a. 如果是,则提交事务;
b. 否则,回滚事务。
时刻A发生crash对应2(b),时刻B发生crash对应2(a)
JOIN
使用Index Nested-Loop Join(NLJ)算法,也就是说可以用上被驱动表上的索引,此时适合使用JOIN。当使用Block Nested-Loop Join(BNL)算法,扫描行数就会过多。尤其是在大表上的join操作,这样可能要扫描被驱动表很多次,会占用大量的系统资源。所以这种join尽量不要用。
参考

若有收获,就点个赞吧
0 人点赞
