下载并解压
下载并解压,https://mirror.bit.edu.cn/apache/hbase/1.4.13/hbase-1.4.13-bin.tar.gz
wget https://mirror.bit.edu.cn/apache/hbase/1.4.13/hbase-1.4.13-bin.tar.gztar -zxvf hbase-1.4.13-bin.tar.gz -C /opt/module
配置环境变量
# vim /etc/profile
添加环境变量:
export HBASE_HOME=/opt/module/hbase-1.4.13export PATH=$HBASE_HOME/bin:$PATH
使得配置的环境变量立即生效:
# source /etc/profile
集群配置
进入 ${HBASE_HOME}/conf 目录下,修改配置:
hbase-env.sh
# 配置JDK安装位置export JAVA_HOME=/opt/module/jdk1.8.0_241# 不使用内置的zookeeper服务export HBASE_MANAGES_ZK=false
hbase-site.xml
<configuration><property><!-- 指定 hbase 以分布式集群的方式运行 --><name>hbase.cluster.distributed</name><value>true</value></property><property><!-- 指定 hbase 在 HDFS 上的存储位置 --><name>hbase.rootdir</name><value>hdfs://node01:8020/hbase</value></property><property><!-- 指定 zookeeper 的地址--><name>hbase.zookeeper.quorum</name><value>node01:2181,node02:2181,node03:2181,node04:2181,node05:2181</value></property></configuration>
regionservers
node03
node04
node05
backup-masters
node02
backup-masters 这个文件是不存在的,需要新建,主要用来指明备用的 master 节点,可以是多个,这里我们以 1 个为例。
HDFS客户端配置
这里有一个可选的配置:如果您在 Hadoop 集群上进行了 HDFS 客户端配置的更改,比如将副本系数 dfs.replication 设置成 5,则必须使用以下方法之一来使 HBase 知道,否则 HBase 将依旧使用默认的副本系数 3 来创建文件:
- Add a pointer to your
HADOOP_CONF_DIRto theHBASE_CLASSPATHenvironment variable in hbase-env.sh.- Add a copy of hdfs-site.xml (or hadoop-site.xml) or, better, symlinks, under ${HBASE_HOME}/conf, or
- if only a small set of HDFS client configurations, add them to hbase-site.xml.
以上是官方文档的说明,这里解释一下:
第一种 :将 Hadoop 配置文件的位置信息添加到 hbase-env.sh 的 HBASE_CLASSPATH 属性,示例如下:
export HBASE_CLASSPATH=/opt/module/hadoop-2.7.7/etc/hadoop
第二种 :将 Hadoop 的 hdfs-site.xml 或 hadoop-site.xml 拷贝到 ${HBASE_HOME}/conf 目录下,或者通过符号链接的方式。如果采用这种方式的话,建议将两者都拷贝或建立符号链接,示例如下:
# 拷贝
cp core-site.xml hdfs-site.xml /usr/app/hbase-1.2.0-cdh5.15.2/conf/
# 使用符号链接
ln -s /usr/app/hadoop-2.6.0-cdh5.15.2/etc/hadoop/core-site.xml
ln -s /usr/app/hadoop-2.6.0-cdh5.15.2/etc/hadoop/hdfs-site.xml
注:
hadoop-site.xml这个配置文件现在叫做core-site.xml
第三种 :如果你只有少量更改,那么直接配置到 hbase-site.xml 中即可。
安装包分发
将 HBase 的安装包分发到其他服务器,分发后建议在这四台服务器上也配置一下 HBase 的环境变量。
scp -r /opt/module/hbase-1.4.13 node02:/opt/module
启动集群
启动ZooKeeper集群
分别到五台服务器上启动 ZooKeeper 服务:
zkServer.sh start
启动Hadoop集群
# 启动dfs服务
start-dfs.sh
# 启动yarn服务
start-yarn.sh
启动HBase集群
进入 node01 的 ${HBASE_HOME}/bin,使用以下命令启动 HBase 集群。执行此命令后,会在 node01 上启动 Master 服务,在 node02 上启动备用 Master 服务,在 regionservers 文件中配置的所有节点启动 region server 服务。
${HBASE_HOME}/bin/start-hbase.sh
查看服务
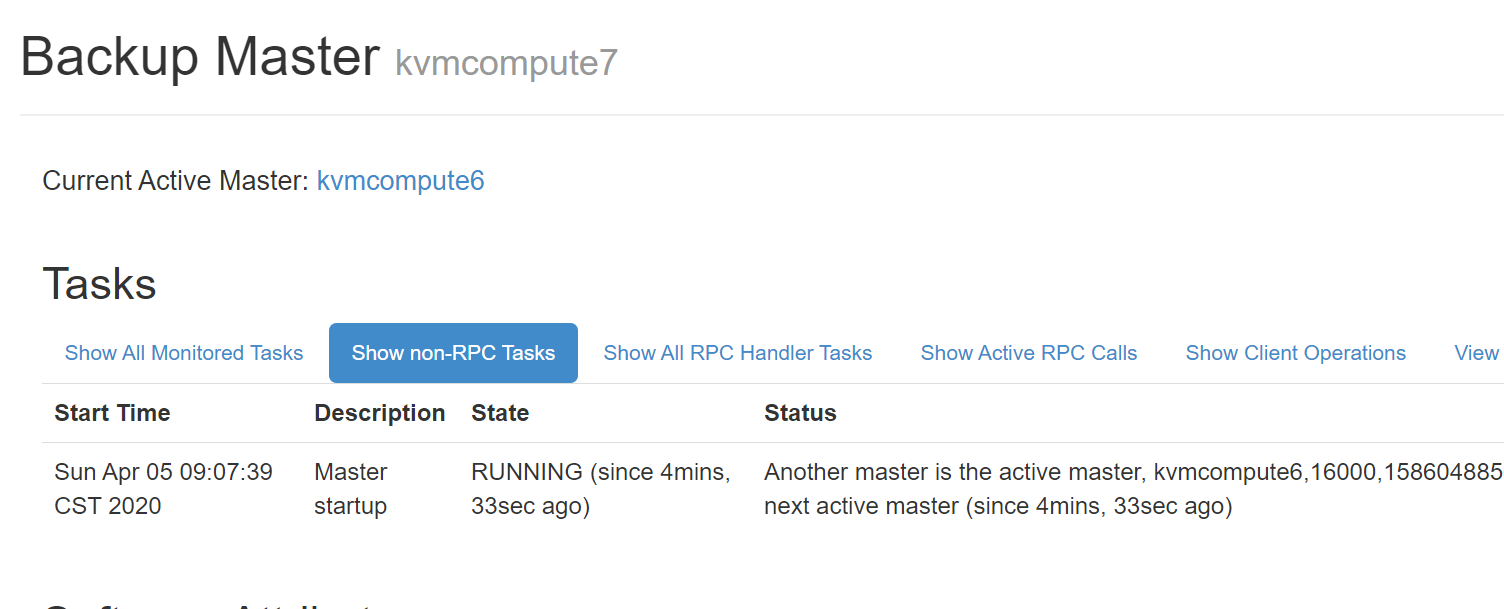
访问 HBase 的 Web-UI 界面,访问端口号为 16010。可以看到 Master 在 node01 上,三个 Regin Servers 分别在node03,node04,和 node05 上,并且还有一个 Backup Matser 服务在 node02 上。
node02 上的 HBase 出于备用状态: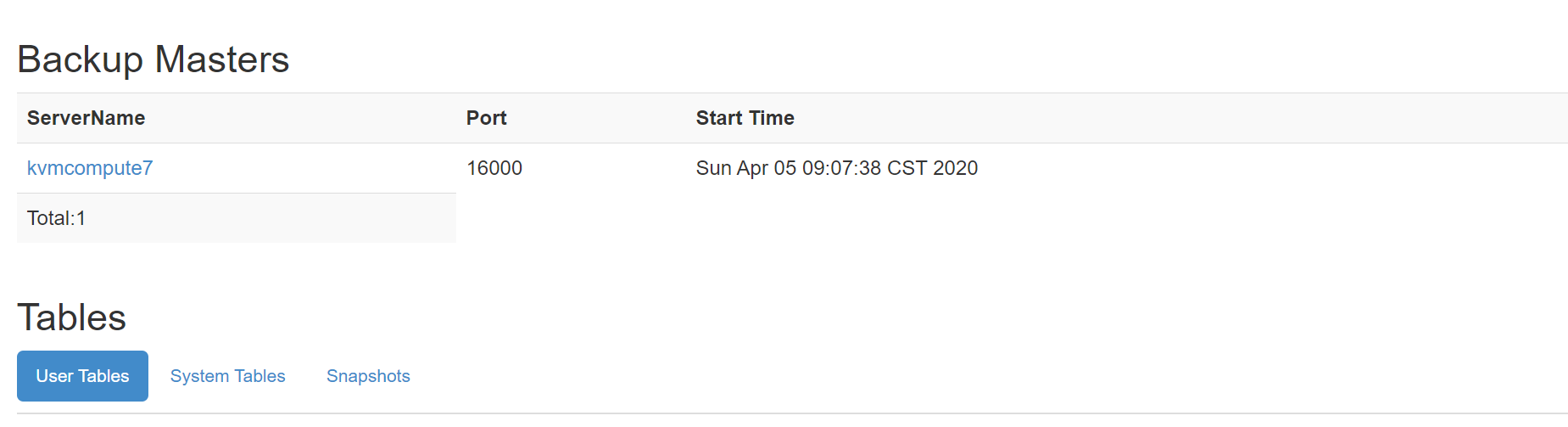
过滤器
- BinaryComparator : 使用
Bytes.compareTo(byte [],byte [])按字典序比较指定的字节数组。 - BinaryPrefixComparator : 按字典序与指定的字节数组进行比较,但只比较到这个字节数组的长度。
- RegexStringComparator : 使用给定的正则表达式与指定的字节数组进行比较。仅支持
EQUAL和NOT_EQUAL操作。 - SubStringComparator : 测试给定的子字符串是否出现在指定的字节数组中,比较不区分大小写。仅支持
EQUAL和NOT_EQUAL操作。 - NullComparator :判断给定的值是否为空。
- BitComparator :按位进行比较。
HTable table1 = new HTable("table1");
//...
HTable table2 = new HTable("table2");
is less efficient than the following code:
Configuration conf = HBaseConfiguration.create();
HTable table1 = new HTable(conf, "table1");
//...
HTable table2 = new HTable(conf, "table2");
hbase-site.xml
<property>
<name>hbase.snapshot.enabled</name>
<value>true</value>
</property>
配置phoenix
创表
CREATE TABLE IF NOT EXISTS us_population (
state CHAR(2) NOT NULL,
city VARCHAR NOT NULL,
population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city));
导入数据
UPSERT INTO us_population VALUES('NY','New York',8143197);
UPSERT INTO us_population VALUES('CA','Los Angeles',3844829);
UPSERT INTO us_population VALUES('IL','Chicago',2842518);
UPSERT INTO us_population VALUES('TX','Houston',2016582);
UPSERT INTO us_population VALUES('PA','Philadelphia',1463281);
UPSERT INTO us_population VALUES('AZ','Phoenix',1461575);
UPSERT INTO us_population VALUES('TX','San Antonio',1256509);
UPSERT INTO us_population VALUES('CA','San Diego',1255540);
UPSERT INTO us_population VALUES('TX','Dallas',1213825);
UPSERT INTO us_population VALUES('CA','San Jose',912332);
CRUD
-- 插入主键相同的数据就视为更新
UPSERT INTO us_population VALUES('NY','New York',999999);
DELETE FROM us_population WHERE city='Dallas';
SELECT state as "州",count(city) as "市",sum(population) as "热度"
FROM us_population
GROUP BY state
ORDER BY sum(population) DESC;
对于HBase 来说,所有的非CRUD操作,都是通过“!”开头的
退出:
!quit
phoenix jar
<!-- https://mvnrepository.com/artifact/org.apache.phoenix/phoenix-core -->
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>4.14.0-cdh5.14.2</version>
</dependency>
HBase
<property>
<name>hbase.snapshot.enabled</name>
<value>true</value>
</property>

若有收获,就点个赞吧
0 人点赞
