查询缓存
执行查询语句的时候,会先查询缓存。不过,MySQL 8.0 版本后移除,因为这个功能不太实用
my.cnf加入以下配置,重启MySQL开启查询缓存:
query_cache_type=1query_cache_size=600000Copy to clipboardErrorCopied
MySQL执行以下命令也可以开启查询缓存:
set global query_cache_type=1;set global query_cache_size=600000;
如上,开启查询缓存后在同样的查询条件以及数据情况下,会直接在缓存中返回结果。这里要求查询的SQL语句必须相同,如果有任何字符不同,就不从缓存中返回结果。
缓存建立之后,MySQL的查询缓存系统会跟踪查询中涉及的每张表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。
缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。 因此,开启缓存查询要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十MB比较合适。此外,还可以通过sql_cache和sql_no_cache来控制某个查询语句是否需要缓存:
**
select sql_no_cache count(*) from usr;
事务
事务是逻辑上的一组操作,要么都执行,要么都不执行。
事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红转账1000元,这个转账会涉及到两个关键操作就是:将小明的余额减少1000元,将小红的余额增加1000元。万一在这两个操作之间突然出现错误比如银行系统崩溃,导致小明余额减少而小红的余额没有增加,这样就不对了。事务就是保证这两个关键操作要么都成功,要么都要失败。
事务的四大特性
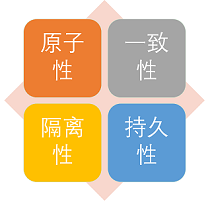
- 原子性(Atomicity): 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
- 一致性(Consistency): 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
- 隔离性(Isolation): 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
- 持久性(Durability): 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
一致性与隔离性的区别
原子性:一个事务内的操作,要么同时成功,要么同时失败
一致性:一个事务必须使数据库从一个一致性状态变换到另一个一致性状态首先回顾一下一致性的定义。所谓一致性,指的是数据处于一种有意义的状态,这种状态是语义上的而不是语法上的。最常见的例子是转帐。例如从帐户A转一笔钱到帐户B上,如果帐户A上的钱减少了,而帐户B上的钱却没有增加,那么我们认为此时数据处于不一致的状态。
从这段话的理解来看,所谓一致性,即,从实际的业务逻辑上来说,最终结果是对的、是跟程序员的所期望的结果完全符合的
一致性是基础,也是最终目的,其他三个特性(原子性、隔离性和持久性)都是为了保证一致性的。**
但是,原子性并不能完全保证一致性。在多个事务并行进行的情况下,即使保证了每一个事务的原子性,仍然可能导致数据不一致的结果。例如,事务1需要将100元转入帐号A:先读取帐号A的值,然后在这个值上加上100。但是,在这两个操作之间,另一个事务2修改了帐号A的值,为它增加了100元。那么最后的结果应该是A增加了200元。但事实上, 事务1最终完成后,帐号A只增加了100元,因为事务2的修改结果被事务1覆盖掉了。
为了保证并发情况下的一致性,引入了隔离性,即保证每一个事务能够看到的数据总是一致的,就好象其它并发事务并不存在一样。用术语来说,就是多个事务并发执行后的状态,和它们串行执行后的状态是等价的。
如何实现隔离性?
怎样实现隔离性,原则上无非是两种类型的锁:
一种是悲观锁,即当前事务将所有涉及操作的对象加锁,操作完成后释放给其它事务使用。为了尽可能提高性能,发明了各种粒度(数据库级/表级/行级……)/各种性质(共享锁/排他锁/共享意向锁/排他意向锁/共享排他意向锁……)的锁。为了解决死锁问题,又发明了两阶段锁协议/死锁检测等一系列的技术。
一种是乐观锁,即不同的事务可以同时看到同一对象(一般是数据行)的不同历史版本。如果有两个事务同时修改了同一数据行,那么在较晚的事务提交时进行冲突检测。实现也有两种,一种是通过日志UNDO的方式来获取数据行的历史版本,一种是简单地在内存中保存同一数据行的多个历史版本,通过时间戳来区分。
并发事务带来哪些问题?
在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对同一数据进行操作)。并发虽然是必须的,但可能会导致以下的问题。
- 脏读(Dirty read): 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
- 丢失修改(Lost to modify): 指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。 例如:事务1读取某表中的数据A=20,事务2也读取A=20,事务1修改A=A-1,事务2也修改A=A-1,最终结果A=19,事务1的修改被丢失。
- 不可重复读(Unrepeatableread): 指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
幻读(Phantom read): 幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
不可重复读和幻读区别
不可重复读的重点是修改比如多次读取一条记录发现其中某些列的值被修改,幻读的重点在于新增或者删除比如多次读取一条记录发现记录增多或减少了。
事务的隔离级别
SQL 标准定义了四个隔离级别:
READ-UNCOMMITTED(读取未提交): 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
- READ-COMMITTED(读取已提交): 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
- REPEATABLE-READ(可重复读): 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
- SERIALIZABLE(可串行化): 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。 | 隔离级别 | 脏读 | 不可重复读 | 幻影读 | | —- | —- | —- | —- | | READ-UNCOMMITTED | √ | √ | √ | | READ-COMMITTED | × | √ | √ | | REPEATABLE-READ | × | × | √ | | SERIALIZABLE | × | × | × |
索引
索引是一种用于快速查询和检索数据的数据结构。常见的索引结构有: B树, B+树和Hash。
索引的作用就相当于目录的作用。打个比方: 我们在查字典的时候,如果没有目录,那我们就只能一页一页的去找我们需要查的那个字,速度很慢。如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
优缺点
优点
可以大大加快数据的检索速度 (大大减少的检索的数据量), 这也是创建索引的最主要的原因。毕竟大部分系统的读请求总是大于写请求的。 另外,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
缺点
- 创建索引和维护索引需要耗费许多时间:当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低SQL执行效率。
- 占用物理存储空间 :索引需要使用物理文件存储,也会耗费一定空间。
SQL执行流程
一条SQL语句在MySQL中如何执行的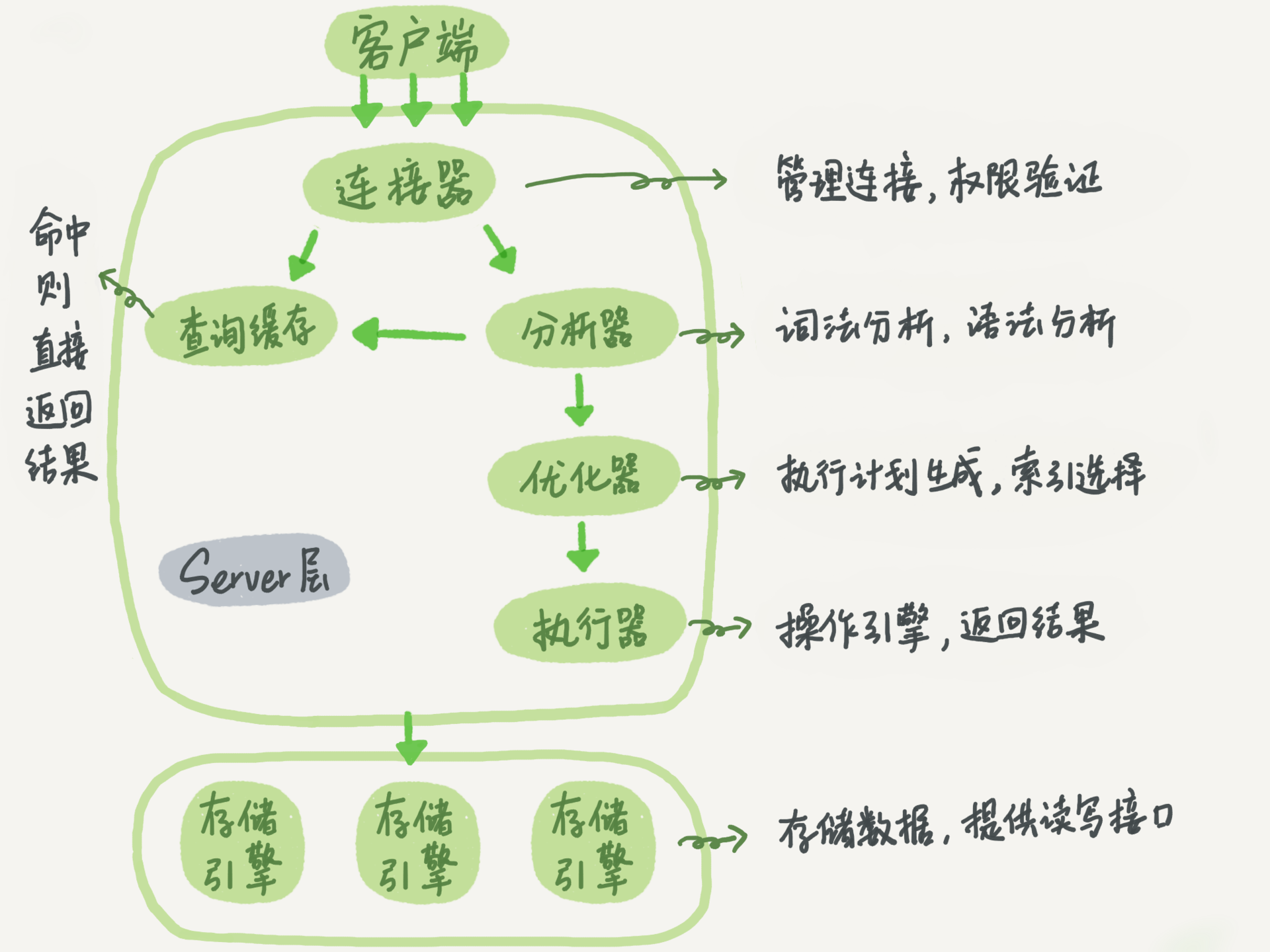
- 分析器判断语句是否正确,表是否存在,字段是否存在。
- 执行器执行前会对sql语句进行权限验证,通过就执行,不通过返回错误。
触发器
触发器仅作用于CREATE TRIGGER <触发器名> < BEFORE | AFTER ><INSERT | UPDATE | DELETE >ON <表名> FOR EACH Row<触发器主体>
insert,update,delete变量
变量以@开头,如@count
定义一个变量,员工表插入就更新变量
@countcreate trigger updateCount after inserton emp for each rowset @count=@count+new.salary
set @count=0;insert into emp(name,salary) values("emp1",1000),("emp2",2000);select @count;
结果是
3000。插入操作
CREATE TRIGGER double_salaryAFTER INSERT ON tb_emp6FOR EACH ROWINSERT INTO tb_emp7VALUES (NEW.id,NEW.name,deptId,2*NEW.salary);
查看触发器
SHOW TRIGGERS;
删除触发器
DROP TRIGGER <triggerName>;
存储过程
类似于编程语言的函数方法,存储过程就是具有名字的一段代码,用来完成一个特定的功能。
声明语句结束符,可以自定义:
DELIMITER $$或DELIMITER //
声明存储过程:
CREATE PROCEDURE demo_in_parameter(IN p_in int)
存储过程开始和结束符号:
BEGINEND
变量赋值:
SET @p_in=1
变量定义:
DECLARE l_int int unsigned default 4000000;
创建mysql存储过程、存储函数:
create procedure 存储过程名(参数)
存储过程体:
create function 存储函数名(参数)
推荐阅读
参考

若有收获,就点个赞吧
0 人点赞
