Zookeeper可以简单理解一个数据库。但不要把zookeeper当做数据库用,因为zookeeper官网一直强调快(响应快、从不可用选出leader快),快就要求所有节点的传输数据体量要小,这样才能快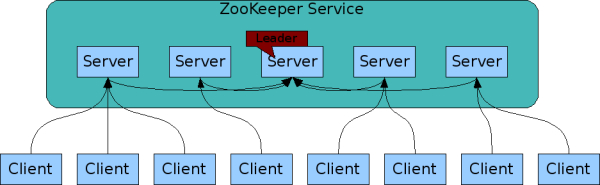
zookeeper特点
分布式读写
客户端的所有写入请求都被转发到单个服务器,称为领导者,_ZooKeeper 服务器的其余部分,称为追随者_,接收来自领导者的数据传递。(数据量最好不要超过1M)。
全局数据一致性
每个server节点保存相同的数据副本,Client无论链接哪个server,数据都是一致的。有一种情况是如果Leader写完数据后,正在同步给其他follow节点,数据还没同步完成,此时如果一个Client正在链接这个follow节点,Client就会先阻塞,等leader同步完数据后,Client才能进行访问。
实时性
在一定时间范围内,Client能读到最新数据(一般毫秒级别)
选举过程
http://dockone.io/article/696772
leader肯定有挂的可能性,造成服务不可用。这就会产生一个问题,我们需要有一种机制能够快速的产生一个leader出来,让整个集群达到可用状态,而且这种不可用的状态到达可用的状态越快越好,官方压测200ms就能恢复。
数据模型
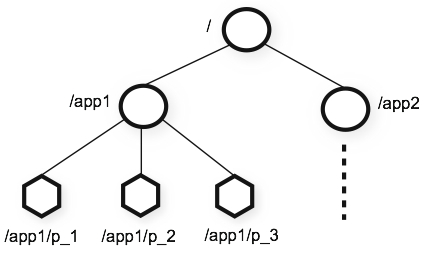
每个节点在zookeeper中叫znode,每个znode有一个唯一的路径标识并且每个节点只能存放一个数据,
节点类型
持久节点(分为:持久节点、持久顺序节点)
相当于数据保存在硬盘中。
创建持久节点
create /rootZnode test1
创建持久顺序节点
用于控制很多客户端Client同时向同一个节点进行写操作,如果写入的节点名称相同会自定生成不同节点的名称。
[zk: localhost:2181(CONNECTED) 3] create -s /sZodeCreated /sZode0000000002[zk: localhost:2181(CONNECTED) 4] create -s /sZode1Created /sZode10000000003
临时节点(分为:临时节点、临时顺序节点)
- 数据保存在内存中,会话(session)断开,数据就会删除,每当一个客户端连接到follow或master的时候就会创建一个session连接,并且这个session会被leader进行写操作,写完后还会同步到其他follow,所以当一个Client连接的follow挂掉后,Client还能连接到其他follow并且复用之前的session。
创建临时节点
create -e /tempZnode tempTest1
不允许创建子节点
create -e /tempZnode/tZonde1 tempTest1Ephemerals cannot have children: /tempZnode/tZonde1
查看创建的Znode节点
[zk: localhost:2181(CONNECTED) 0] ls -R ///rootZnode/sZode0000000002/sZode10000000003/zookeeper/zookeeper/config/zookeeper/quota ls /[rootZnode, tempZnode, zookeeper]
关闭当前的Client,临时节点会删除。
quit./zkCli.shls /[rootZnode, zookeeper]
API操作
API的操作相对简单,包括连接zookeeper集群、创建节点、更新节点、获取节点、删除节点。
<!-- 官方自带的客户端操作 --><dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.6.3</version></dependency>
可以把服务端的log文件放到客户端里面,能够详细看到zookeeper连接、断开以及操作数据的详细过程。 ```java
import org.apache.zookeeper.*; import org.apache.zookeeper.data.Stat; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import java.io.IOException; import java.util.concurrent.CountDownLatch;
@Configuration public class ZookeeperAPI { //zookeeper集群,zookeeper的ip与端口,这里测试一台机器开启三个zookeeper,会随机链接一台 private static final String ZK_SERVER_LIST = “120.53.119.107:2181,120.53.119.107:2182,120.53.119.107:2183”; //设置超时时间,当节点3s后没反应就认该节点已经挂了,比如创建临时节点客户端关闭链接后3s,临时节点才移除 private static final int sessionTimeout = 3000; private ZooKeeper zk;
@Beanpublic ZooKeeper zooKeeper1() throws IOException, InterruptedException, KeeperException {/*** watch分为两类:第一类:创建ZooKeeper对象(new ZooKeeper)时候传入的watch,这个watch为session级别的watch。* 当ZooKeeper链接成功或断开等会监听到,如果断开连接,还有其他服务可用,会自动连接到其他节点,并收到通知,而且session是不变的。* 如果ZooKeeper节点变化删除、更新等是监听不到的。*/CountDownLatch countDownLatch = new CountDownLatch(1);zk = new ZooKeeper(ZK_SERVER_LIST, sessionTimeout, new Watcher() {@Overridepublic void process(WatchedEvent event) {Event.KeeperState state = event.getState();Event.EventType type = event.getType();System.out.println("new ZooKeeper Watcher连接成功");//状态switch (state) {case Unknown -> {}case Disconnected -> {}case NoSyncConnected -> {}case SyncConnected -> {System.out.println("new ZooKeeper Watcher连接成功");countDownLatch.countDown();}case AuthFailed -> {}case ConnectedReadOnly -> {}case SaslAuthenticated -> {}case Expired -> {}case Closed -> {}}}});countDownLatch.await();//在这里会阻塞//创建节点的方式大概可以分为两类API,一个是阻塞的,创建节点成功才返回值、一个是不阻塞创建成功使用回调的函数返回结果值。String pathName = zk.create("/znodexx","test".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL);//取数据的同时注册了一个观察,取完数据后,未来如果该节点数据发生变化,就会回调这个WatchStat stat = new Stat();//获取源数据,zookeeper内部会对其赋值byte[] znodData = zk.getData("/znodexx", new Watcher() {//这个只会调用1次,需要重复注册才能解决修改该节点后再次调用@Overridepublic void process(WatchedEvent event) { //什么时候节点变化才会回调,并且是在另一个线程回调System.out.println("哈哈getData watch : " + event.toString());//注意这种重复注册监听,第二个参数传true,会调用创建new ZooKeeper时的watch//zk.getData("/znodexx",true,stat);try {//第二个参数传递的是this,当该节点变化时,会调用当前watch而不是创建ZooKeeper时的watchzk.getData("/znodexx",this,stat);} catch (KeeperException e) {e.printStackTrace();} catch (InterruptedException e) {e.printStackTrace();}}},stat);System.out.println("获取到数据");System.out.println(new String(znodData));Stat stat1 = zk.setData("/znodexx","hhh".getBytes(),0);//触发上面的回调zk.setData("/znodexx","00hhh00".getBytes(),stat1.getVersion());//触发上面的回调System.out.println("async --------begin");//异步回调的使用,拿到结果数据会回调processResult函数,代码不阻塞,继续执行zk.getData("/znodexx", false, new AsyncCallback.DataCallback() {@Overridepublic void processResult(int rc, String path, Object ctx, byte[] data, Stat stat) {System.out.println("path = " + path); //路径System.out.println("ctx = " + ctx.toString()); //传入的上下文信息System.out.println("data = " + new String(data)); //返回的数据System.out.println("stat = " + stat.toString());//返回源数据信息}},"xxxx");System.out.println("async --------end");return zk;}
}

若有收获,就点个赞吧
0 人点赞
