太长不看部分
懒得看下面的原理解释可以只看这部分。
- 标准误:描述样本均数间的变异程度的统计量
- 中心极限定理:抽样样本足够大时,样本的均值近似正态分布
#card=math&code=N%28%5Cmu%2C%20%5Cfrac%7B%7B%5Csigma%7D%5E2%7D%7Bn%7D%29&id=Qmfxm)
正态分布的应用:
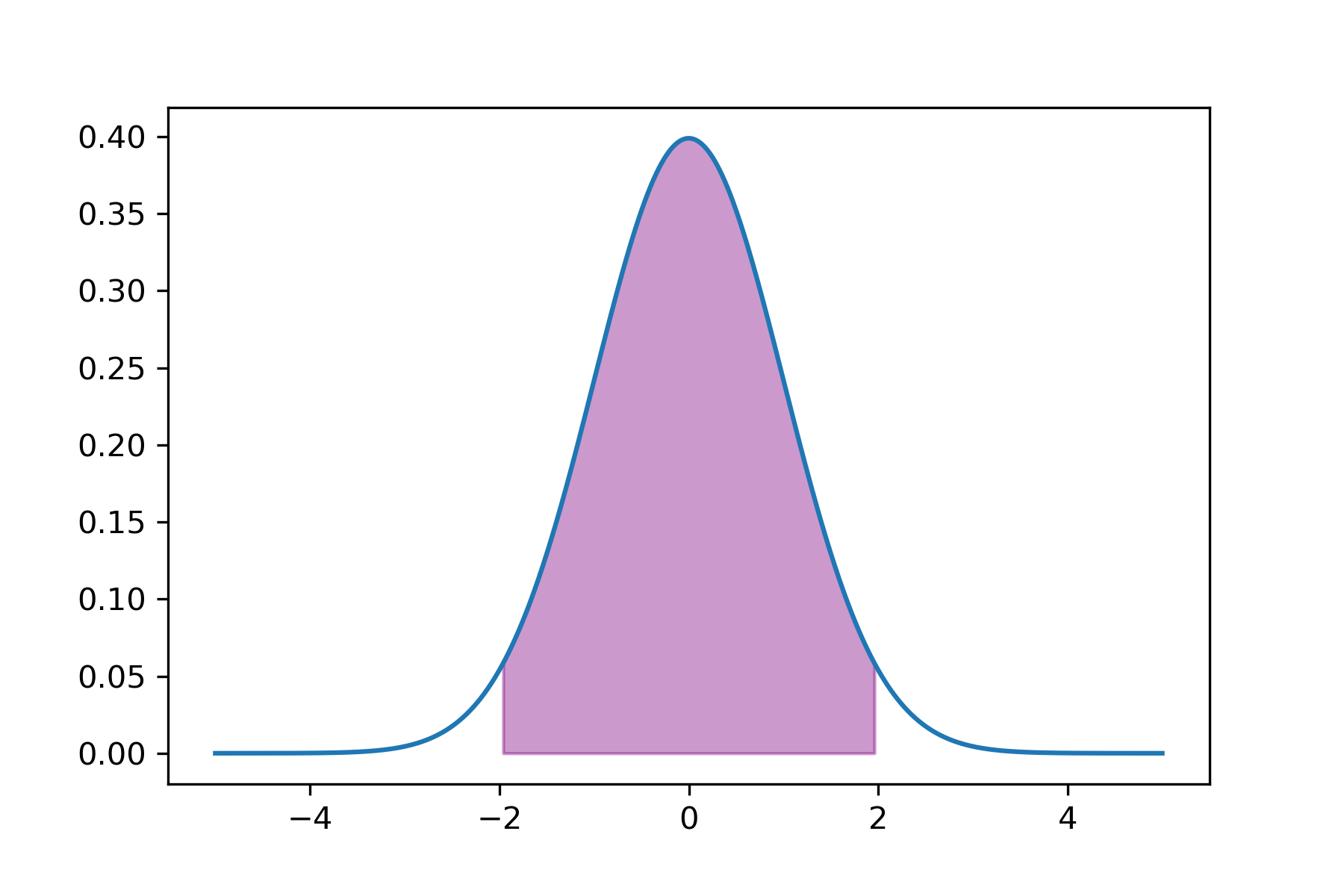
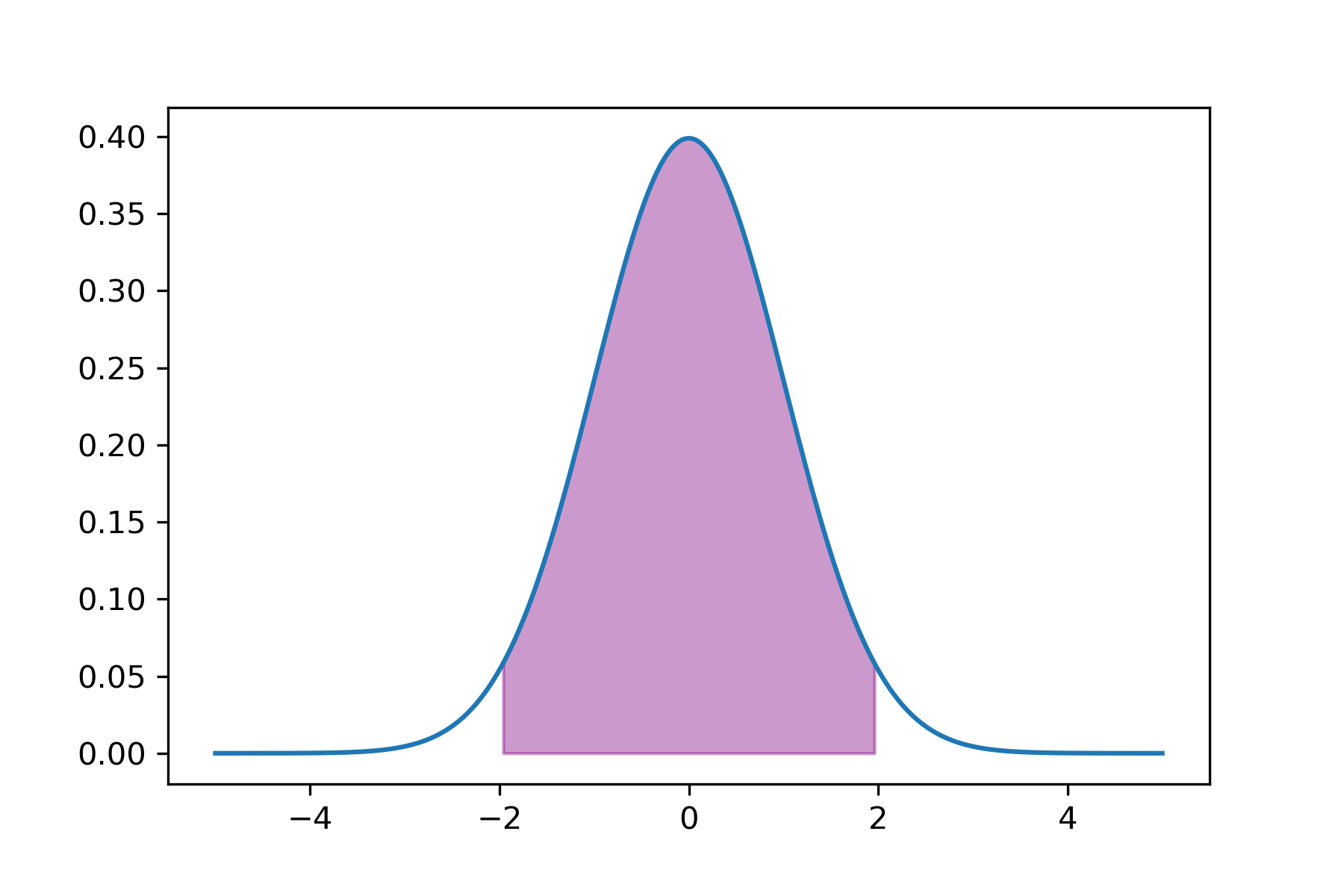
- 正态近似法:符合正态分布的资料,通过正态的累计面积确定大部分人(95%)具有的值(即取图中的紫色部分)
- 百分位数法:适用于偏态分布资料
区间估计分为以下情况:
已知:均数可信区间按照u分布截断,类似参考值的确定,不过是依据均值分布的正态分布
未知:按照t分布,
,又由于我们需要找
的概率处于分布中的范围,所以找到
对应的范围。
即:,将t代换回
即可得到:
抽样误差及标准误
- 抽样误差:由个体差异产生的,抽样造成的样本与样本、样本与总体相应统计指标之间的差异
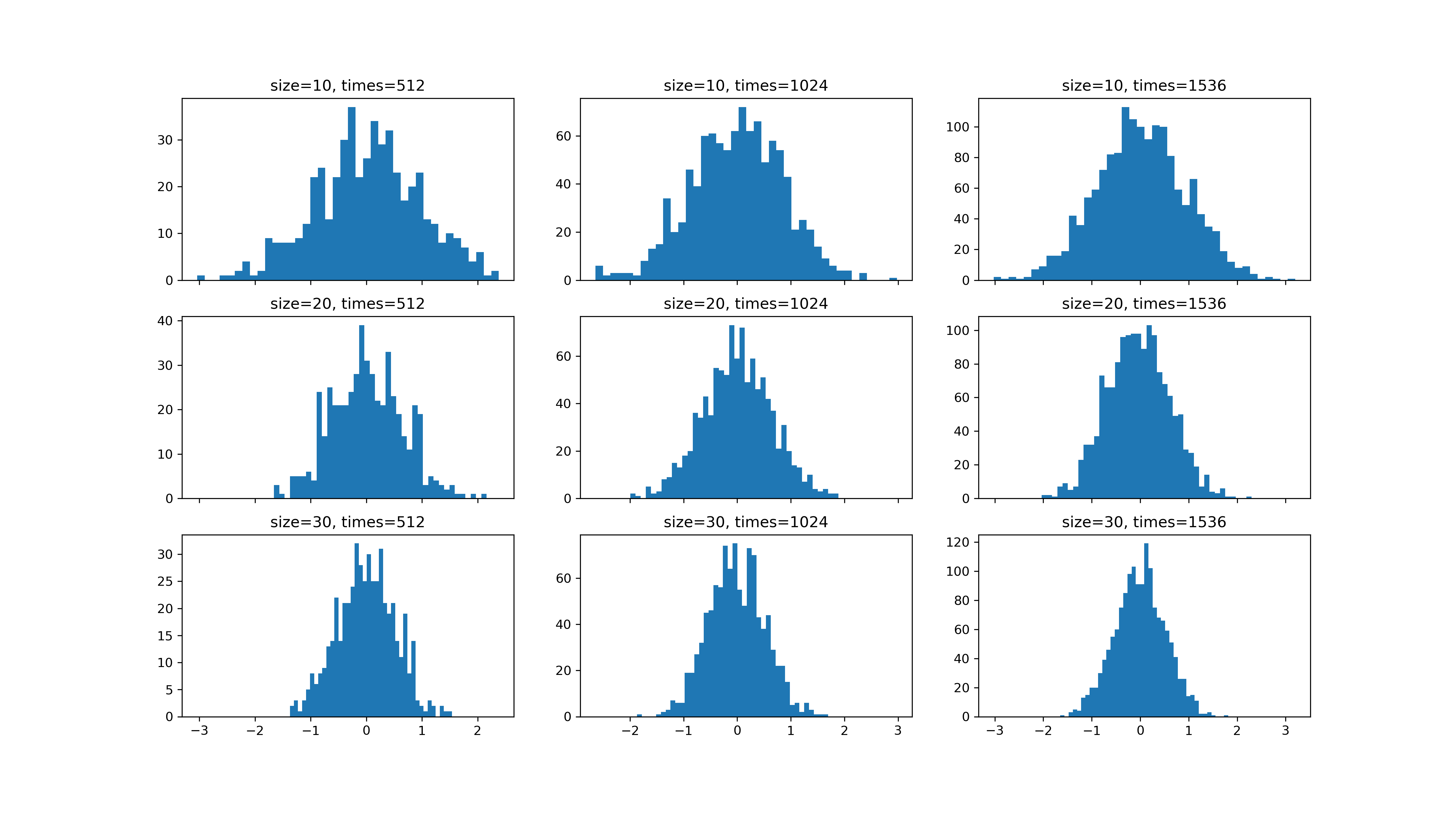
- 抽样分布:由于抽样误差的存在,从同一总体中随机抽取若干份样本,所得样本统计量不一致,差异无法避免,但存在一定的分布规律
- 样本均数恰好等于总体均数罕见
- 样本均数间存在差异
- 样本均数围绕总体均数,中间多,两边少,近似正态分布
- 样本均数间的变异小于原始变量值之间的变异,即SEM,$SEM=\frac{\sigma}{\sqrt{n}}
- 样本含量增大,样本均数变异范围缩小
- 中心极限定理:抽样样本足够大时,样本的均值近似正态分布
常见概率分布
正态分布
特征:
- 正态曲线在横轴上方均数处最高;
- 正态分布以均数为中心,左右对称;
为位置参数,
为变异度参数;
- 正态曲线下的面积分布有一定规律,横轴上正态曲线下的面积等于1。
应用:
- 正态近似法:符合正态分布的资料,通过正态的累计面积确定大部分人(95%)具有的值
- 百分位数法:适用于偏态分布资料
t分布
样本含量为n的样本均数服从
#card=math&code=N%28%5Cmu%2C%20SEM%5E2%29&id=f0351),则通过z变换可将其转换为标准正态分布
#card=math&code=N%280%2C%201%29&id=VPTf2),但由于
未知,以
代替,则
不再服从正态分布,而服从t分布
t分布的特征:
- 以0为中心,左右对称的单峰分布;
- t分布为一簇曲线,其形态变化与自由度
大小有关。
越小,t越分散,自由度
增大时,t分布逐渐逼近u分布;
- t分布曲线下总面积为1。
总体均数的估计
- 点估计:用样本统计量直接作为总体参数的估计值
- 区间估计:根据预先给定的概率确定包括未知总体参数的可能范围
- 可信度:预先给定的概率
- 可信区间:根据可信度确定的未知总体参数的可能范围
区间估计分为以下情况:
已知:均数可信区间按照u分布截断,类似参考值的确定,不过是依据均值分布的正态分布
未知:按照t分布,
,又由于我们需要找
的概率处于分布中的范围,所以找到
对应的范围。
即:,将t代换回
即可得到:
均数的可信区间与参考值范围区别:
- 意义:
- 均数的可信区间:按预先给定的概率,确定的包含总体均数的可能范围,因此它用于估计总体均数。可信度要高,但精度不能下降;
- 参考值范围的统计意义:正常人的指标波动范围
- 两者的计算公式:可信区间使用了样本分布,应用SEM计算,参考值适用的是s.

若有收获,就点个赞吧
0 人点赞
