1 漏洞原理
敏感信息泄露漏洞,其挖掘难度和技术含量不高,但是危害性往往比较大。
以下是OWASP Top 10对敏感信息泄露的说明:
A6 敏感信息泄露 Sensitive Data Exposure
保护与加密敏感数据已经成为网络应用的最重要的组成部分。最常见的漏洞是应该进行加密的数据没有进行加密。使用加密的情况下常见问题是不安全的密钥和使用弱算法加密防范: 1.加密存储和传输所有的敏感数据 2.确保使用合适强大的标准算法和密钥,并且密钥管理到位 3.确保使用密码专用算法存储密码 4.及时清除没有必要存放的重要的/敏感数据 5.禁用自动收集敏感数据,禁用包含敏感数据的页面缓存 加密方法:采用非对称加密算法管理对称加密算法密钥,用对称加盟算法加密数据
基于个人认知,这里暂时将自己接触到的敏感信息泄露分为两类:人员敏感信息泄露(身份证,手机号,用户名,密码等等),网站敏感信息泄露(网站源码,数据库备份,日志等等)
1.1 人员敏感信息泄露
人员敏感信息泄露主要由于网站未对上传目录或者下载目录进行限制,导致谷歌(居多)或百度爬虫爬取到储存有人员敏感信息的文档(xls,pdf,docx等)。对于这类敏感信息的挖掘很简单,只需要借助谷歌语法或百度语法即可。
谷歌语法:
site:example.edu.cnfiletype:xls|doc|docx|ppt|pptx|pdf 身份证|password|密码|手机号
百度语法:
filetype:xls site:(*.tongji.edu.cn) (身份证 | 手机号 | 学号 | 密码)
修复方案:
对该目录访问进行限制或删除文件
1.2 网站敏感信息泄露
相对于人员敏感信息泄露,网站敏感信息泄露兴许直接危害要更大一些。如果不确定有哪些算敏感信息,可以去Github看一下lijiejie的BBScan的字典。另外,这是一款很优秀的敏感信息扫描工具, github地址: BBScan
这里简单介绍几种网站敏感信息:
1)备份文件泄露
前缀往往是域名或者常见文件名,后缀一般为.rar,.zip,.7z,.tar等。直接泄露源码,可通过简单审计找到网站后台,找到管理员密码或者数据库密码。有精力还可进行白盒审计,发现黑盒测试难以发现的漏洞。
备份文件有时也会出现一些问题:
1.压缩包有密码:爆破(从来没爆破出来过--)
(小技巧:在压缩包无法解密的情况下,双击压缩包,全屏显示,浏览目录查看是否有敏感信息(比如后台地址,备份数据库文件等等)
2.密码MD5解不开、数据库不外连: 尝试一下后台密码是否是数据库连接密码
mdb数据库查看工具(Excel也可): 链接
db,sqlite数据库查看工具: 链接
mdf文件查看工具: 链接
2).git源码泄露
原理: 开发人员在开发时,常常会先把源码提交到远程托管网站(如github),最后再从远程托管网站把源码pull到服务器的web目录下,如果忘记把.git文件删除,就造成此漏洞。利用.git文件恢复处网站的源码,而源码里可能会有数据库的信息。
探测路径: /.git 或 /.git/config
输入.git能目录遍历,一般能dump所有源码,.git 403而.git/config能访问,这时候也能dump部分源码
Githack工具: Githack
3).svn源码泄露
原理: Subversion是源代码版本管理软件,造成SVN源代码漏洞的主要原因是管理员操作不规范。在使用SVN管理本地代码过程中,会自动生成一个名为.svn的隐藏文件夹,其中包含重要的源代码信息。但一些网站管理员在发布代码时,不愿意使用’导出’功能,而是直接复制代码文件夹到WEB服务器上,这就使.svn隐藏文件夹被暴露于外网环境,黑客可以借助其中包含的用于版本信息追踪的entries文件,逐步摸清站点结构。利用.svn/entries文件,获取到服务器源码、svn服务器账号密码等信息。
探测路径: /.svn/entries
svnExploit工具: svnExploit
4).idea敏感信息泄露
原理: _Jet Brains产品的项目配置目录。一般用pycharm,idea等工具开发生成的项目配置目录。从中可泄露文件路径文件名等敏感信息
探测路径: /.idea/workspace.xml
idea_exploit工具: idea_exploit
5).DS_Store敏感信息泄露
原理: .DS_Store(英文全称 Desktop Services Store)是一种由苹果公司的Mac OS X操作系统所创造的隐藏文件,目的在于存贮目录的自定义属性,例如文件们的图标位置或者是背景色的选择。相当于 Windows 下的 desktop.ini。一般泄露目录结构信息和文件信息。
探测路径: /.DS_Store
ds_store_exp工具: ds_store_exp
6)java web配置信息泄露
原理: Tomcat的WEB-INF目录,每个j2ee的web应用部署文件默认包含这个目录。Nginx在映射静态文件时,把WEB-INF目录映射进去,而又没有做Nginx的相关安全配置(或Nginx自身一些缺陷影响)。从而导致通过Nginx访问到Tomcat的WEB-INF目录,根据web.xml配置文件路径或通常开发时常用框架命名习惯,找到其他配置文件或类文件路径。dump class文件进行反编译。—— 详情
探测路径: /WEB-INF/web.xml
java反编译工具: Luyten
7)apache日志泄露
探测路径: /server-status
可以实时查看apache日志信息,泄露请求信息
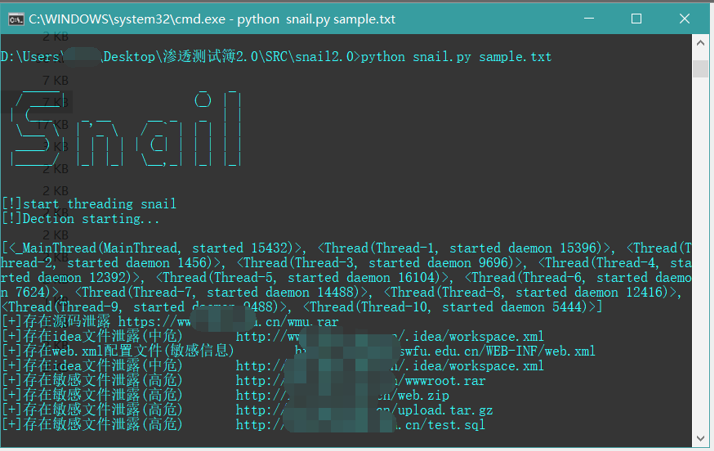
2 漏洞感知
开发环境: python 3
工具地址: Snail2.0
其中针对.git、.svn、.idea、ds_store、apache状态日志扫描的轮子已经有了,就不再重复开发了,着重需要开发的是备份文件扫描功能。网站备份文件规律一般来说存在两种可能: 一是固定类型(www.rar,db.zip)等等,另外一种比较典型的就是与域名相关(xxx.edu.cn.zip)。对于固定类型搜集网上典型字典进行扫描。域名相关直接脚本生成即可。以下简要介绍相关函数。
#根据域名,生成敏感字典def genWeak(name):exts=['.rar','.zip','.7z','.tar','.tar.7z','.tar.gz','.tar.bz2','.tgz']res=[]element=name.split('.')#print(element)for ext in exts:domain=""for ele in element:res.append(ele+ext)domain+='.'+eleres.append(domain+ext)data=[]for s in res:data.append(s.strip('.'))data=list(set(data))return data# 返回包条件设置: 返回码+Content-Length字段if req.status_code==200 and int(req.headers["Content-Length"])>=1000000:print("[+]存在源码泄露\t"+vulnurl)return [domain,tag,payload]
除了扫描功能,还在该工具中添加了域名搜集功能,分别是百度的一个域名查询接口和网页链接爬取,聊胜于无。同时为了避免扫描太快网站禁用IP,可以设置延时扫描。
#百度云观测接口def baiduyun(domain):try:res=requests.get("http://ce.baidu.com/index/getRelatedSites?site_address="+domain)data=json.loads(res.text)domain=[]for value in data["data"]:domain.append(value["domain"])return domainexcept:return [domain]#爬取域名,加入队列def spider(url,time_out):try:headers = {"User-Agent":"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50"}rex=url.split('.')if rex[-1]=="com":s=rex[-2]+"."+rex[-1]elif rex[-1]=="cn":if rex[-2] in ["gov","edu"]:s=rex[-3]+"."+rex[-2]+"."+rex[-1]patt=re.compile(r"http[s]?:.{1,40}."+s)res=requests.get(url,headers=headers,timeout=3)data=patt.findall(res.text)data=list(set(data))tmp=[]for d in data:d=d.split("/")[2]if d not in domains:domains.append(d)tmp.append(d)if len(tmp)==0:returnif len(tmp)==1:params=([tmp,time_out],None)request = makeRequests(scan, params)[pool.putRequest(req) for req in request]returnparams = [([d, time_out],None) for d in tmp]request = makeRequests(scan, params)[pool.putRequest(req) for req in request]except:pass
3 漏洞案例
该漏洞案例蛮多的,这里只简单记录几个以证明其存在且具有危害。(以下漏洞均已通报修复)
3.1 案例一
扫描到某高校校长办公室网站源码。
源码中泄露管理员账号密码 admin/123123, 登录后台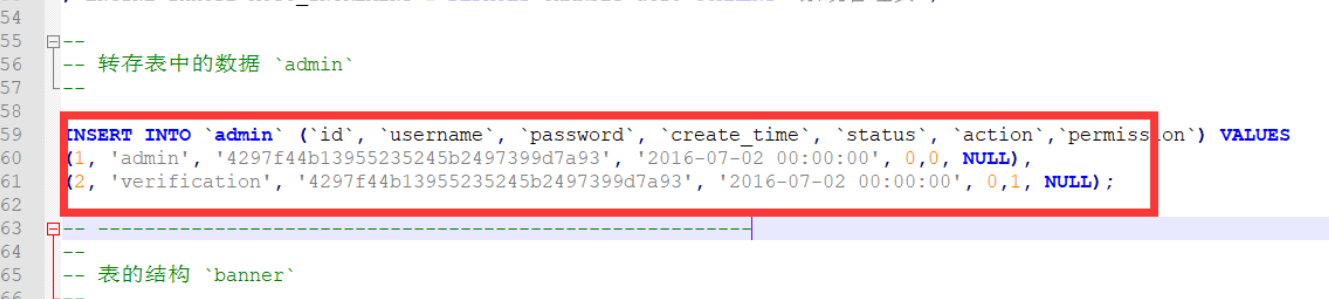
3.2 案例二
某高校网站源码泄露
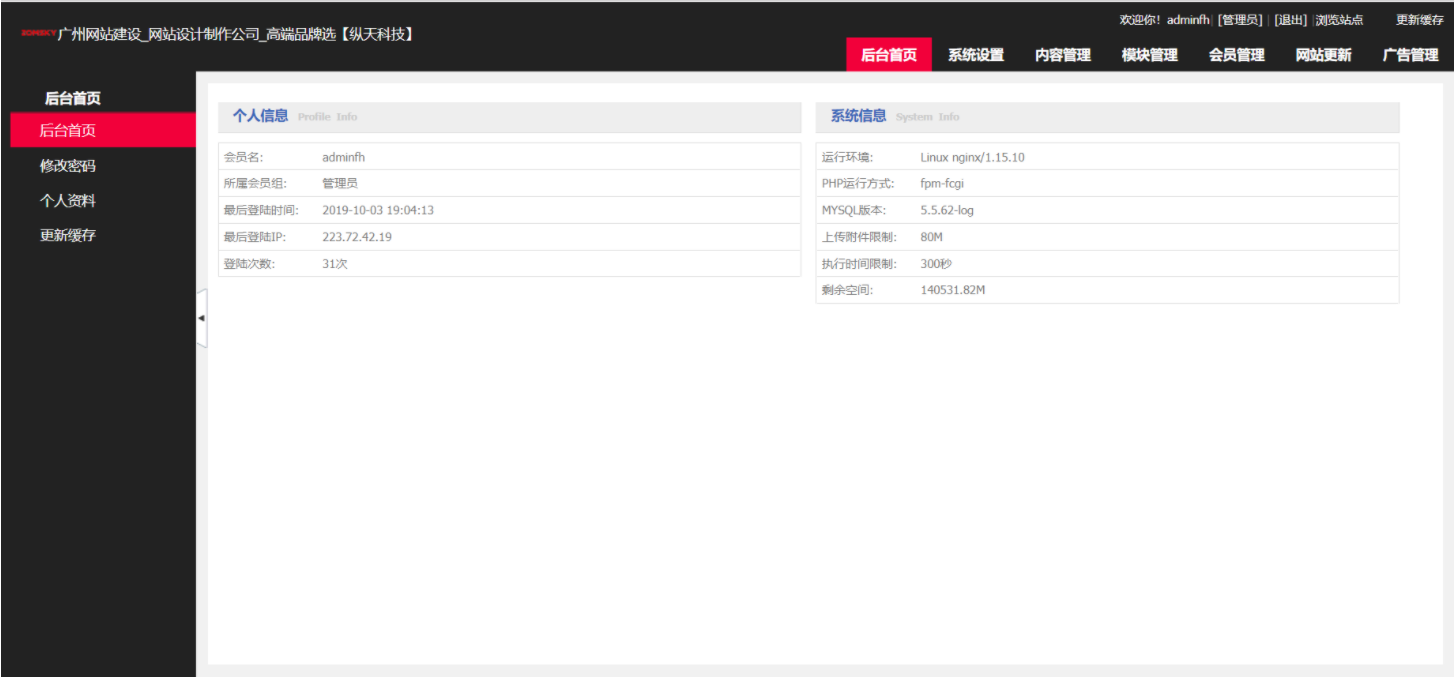
通过源码获得后台地址、管理员账号密码,登录后台
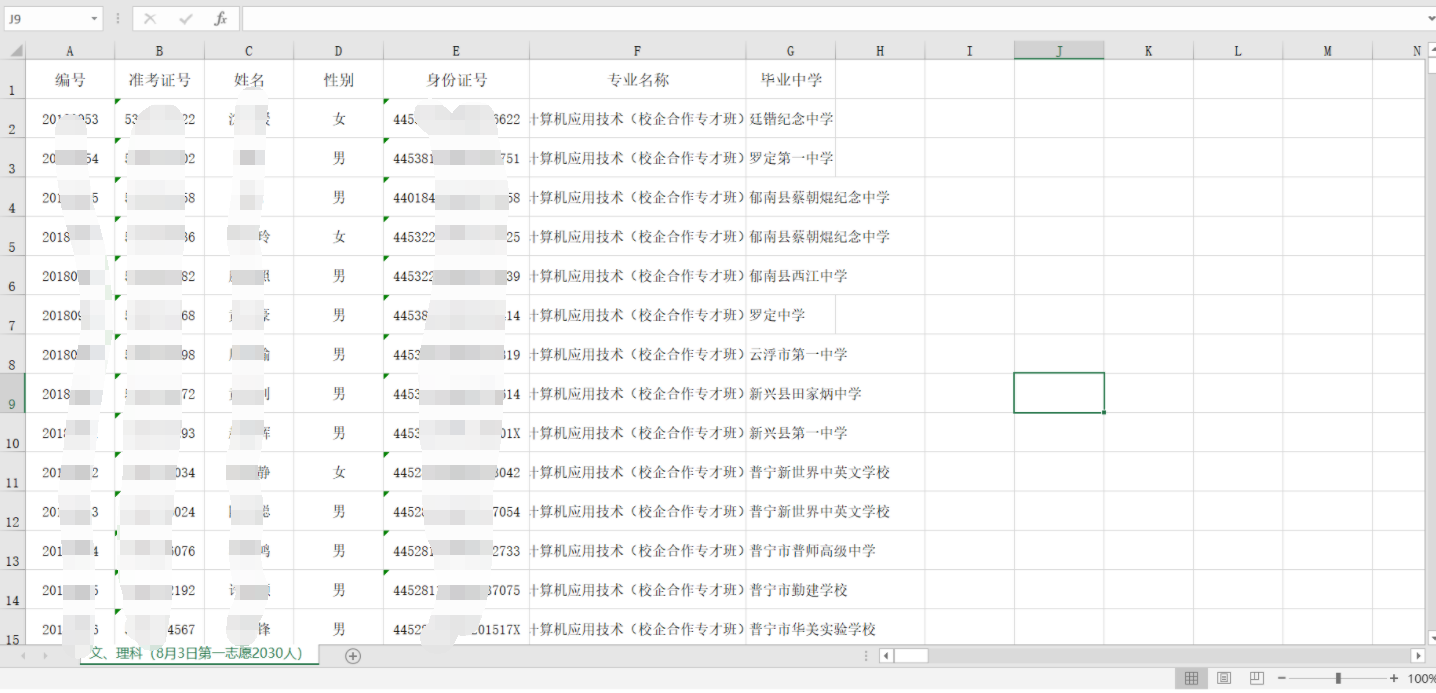
同时,源码中还泄露了近5000人的身份证信息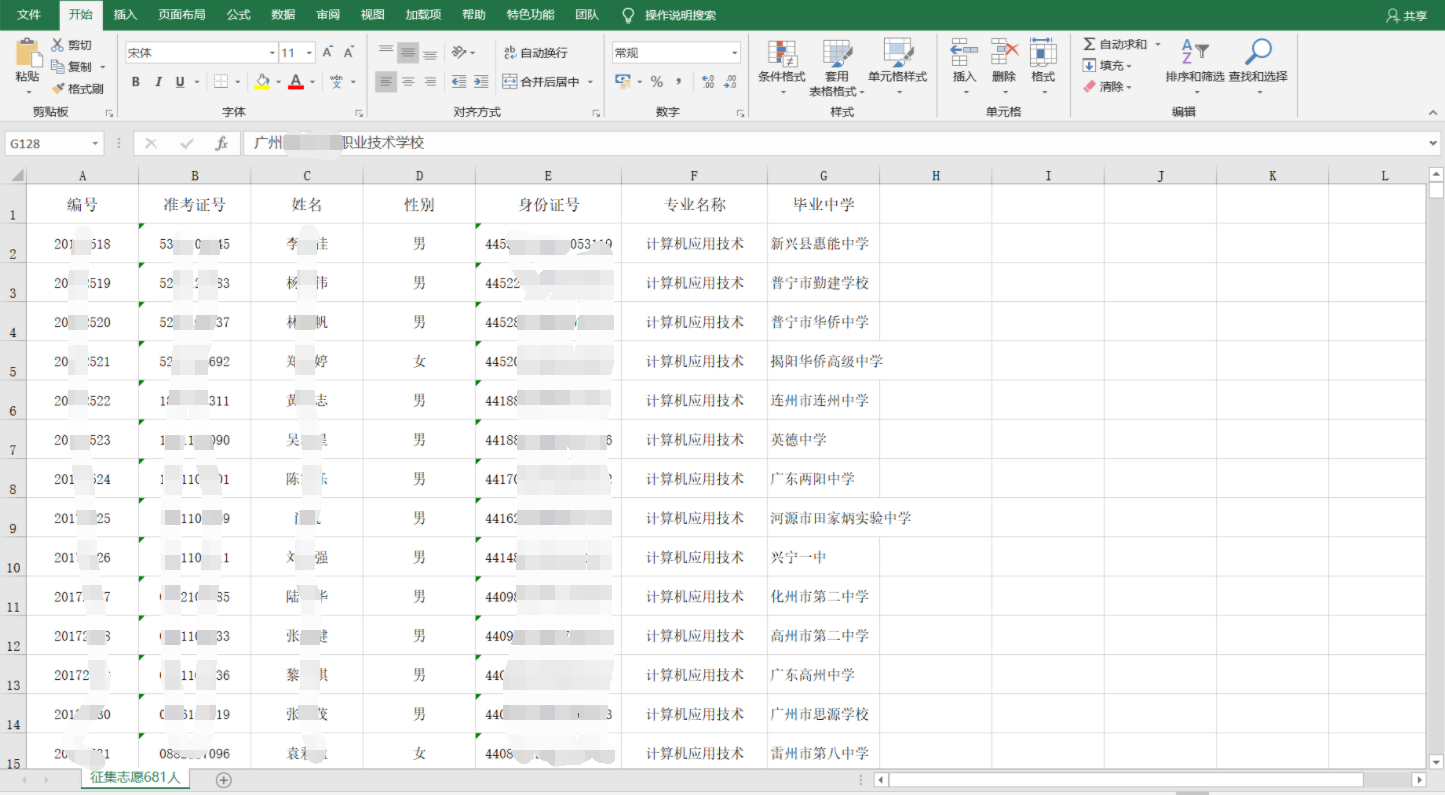
3.3 案例三
同样某高校源码泄露
泄露一处可外连的数据库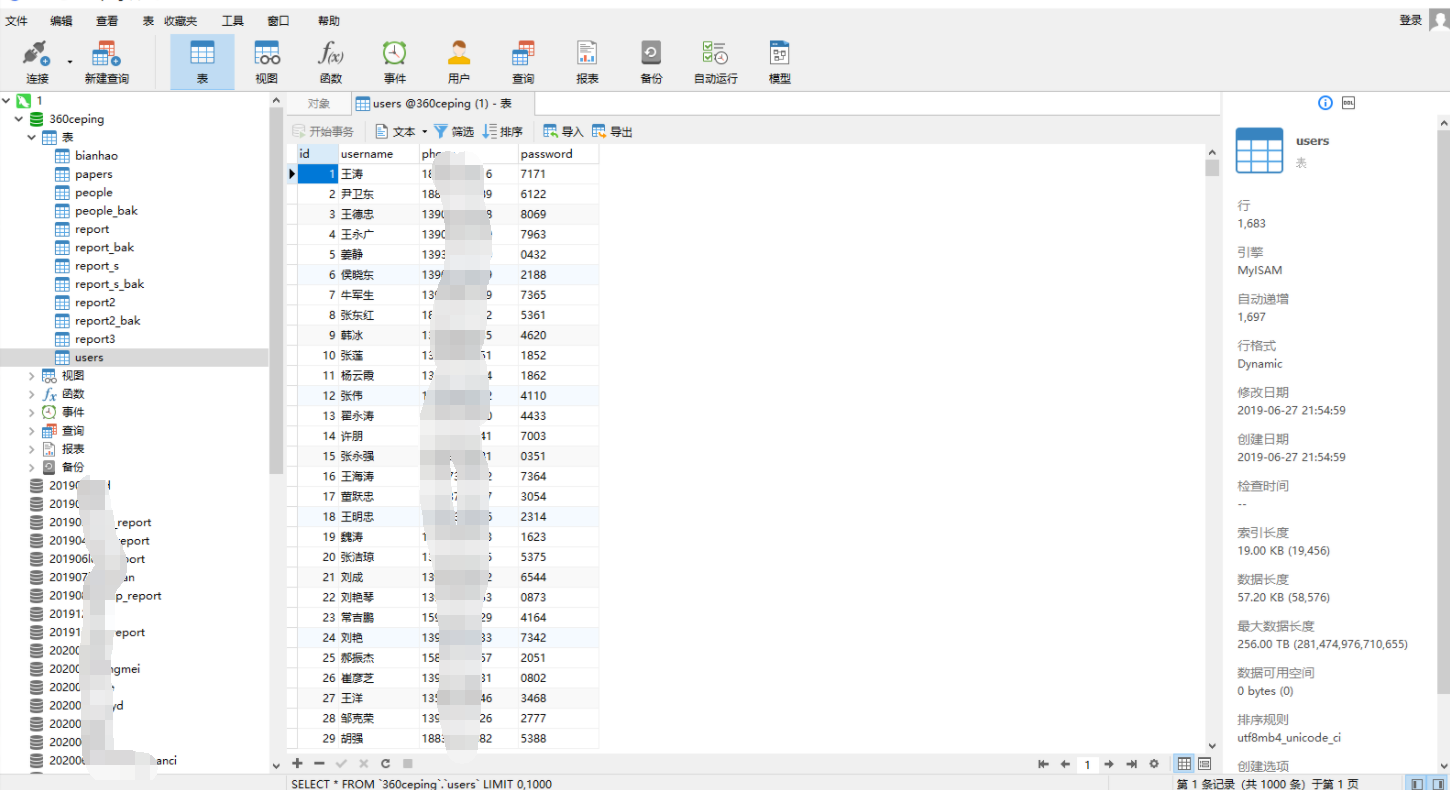
通过代码审计,发现一处任意文件读取及文件上传漏洞,可获得shell
该上传点并未进行任何过滤,但是存在玄武盾云waf,只要是php就干掉,上传了也无法访问
构造上传代码:
<html><body><form action="http://xxx.xxx.cn/webup/server/fileupload.php" method="post" enctype="multipart/form-data"><input type="file" name="file"><button type="submit">提交</button></form></body></html>
关于云waf的绕过,最好的方式莫过于找到该网站的真实IP,试用了很多DNS历史查询网站都没有找到,最后在微步在线威胁情报社区查找到历史解析IP。
修改host文件,绕过waf:xx.xx.xx.xx xxx.xx.cn
成功上传webshell(真传shell还是有风险的,建议上传无害文件)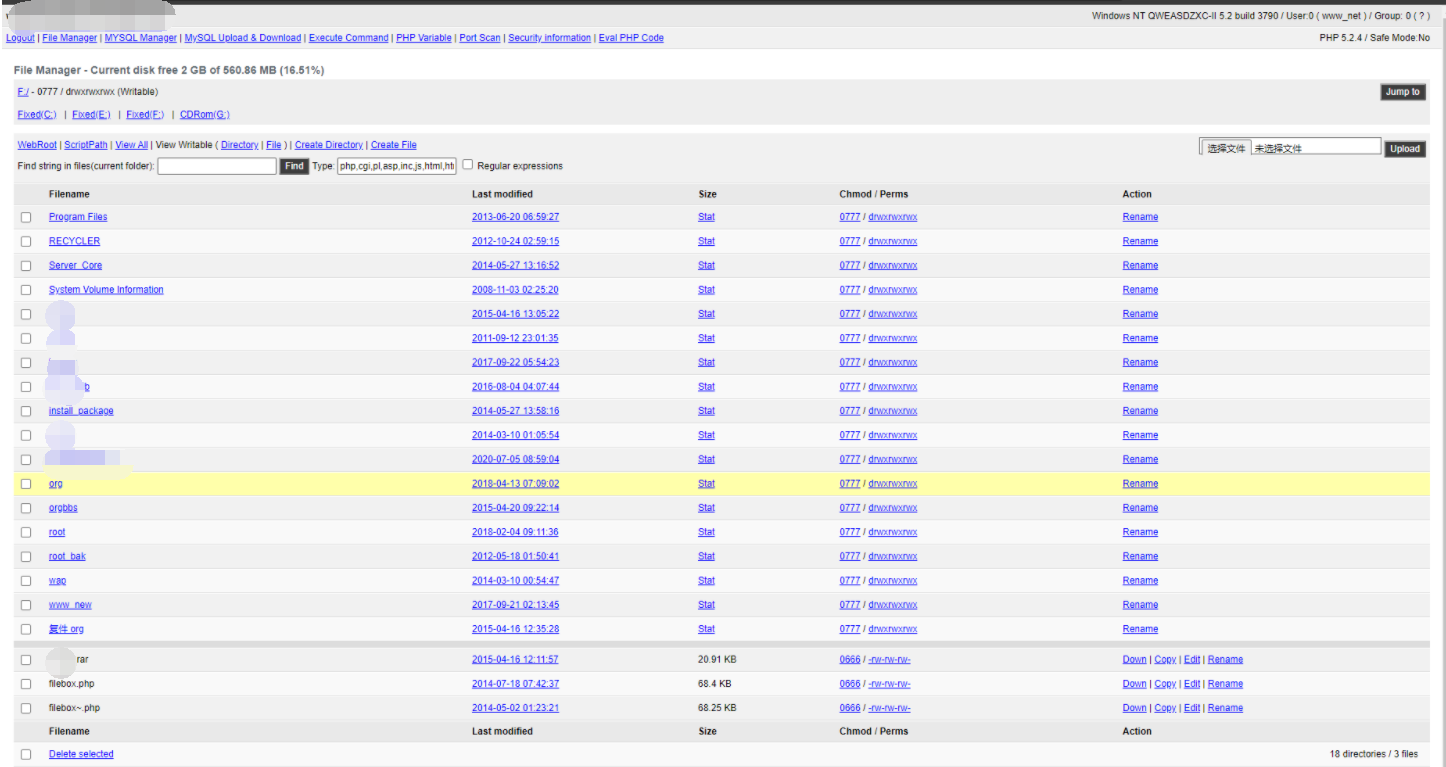
PS: 有些时候,我们总执着于第一个挖到的漏洞类型,陷入故步自封。

若有收获,就点个赞吧
0 人点赞
