数据类型之哈希

原理:
底层的实现结构,与HashMap也一样,是“数组+链表”的二维结构,第一维hash的数据位置碰撞时,将碰撞元素用链表串接起来,不同的是,redis字 典的值只能是字符串,而且两者的rehash方式不同。java的hashmap是一次全部rehash,耗时较高,redis为了优化性能,采用渐进式rehash策略。具体方式为,同时保留新旧两个hash结构,然后
逐步搬迁,搬迁完成后再取而代之。
HashMap
HashMap
HashMap
HashMap
HashMap
命令:
1) 存取数据
hset
hget 
hmset/hmget 批量处理更便捷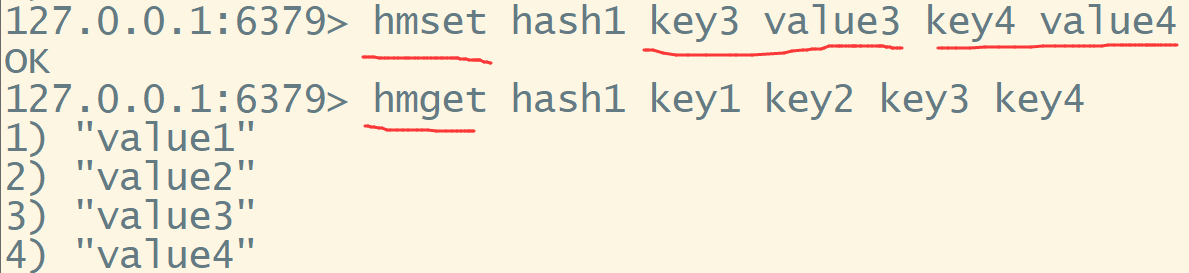
hsetnx 如果不存在即set新的key值 ,存在则操作失败返回0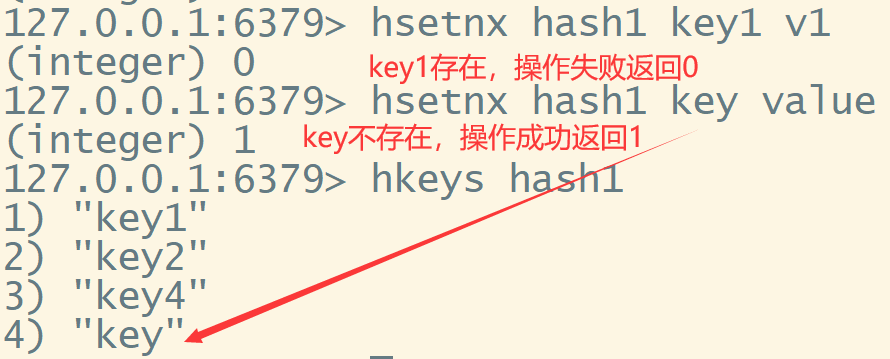
2) 遍历数据
hkeys 查看所有的key值 
hvals 查看所有的value值 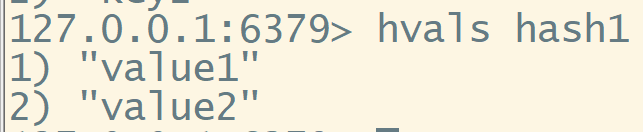
hlen 查看数据长度 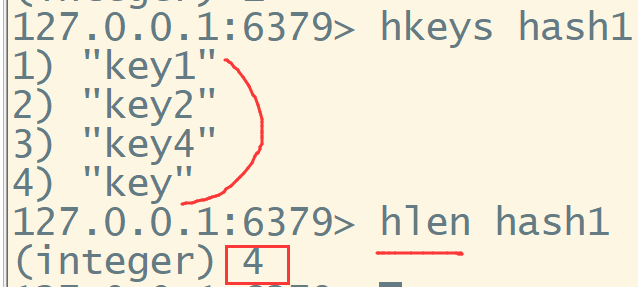
hgetall 返回全部的key和value 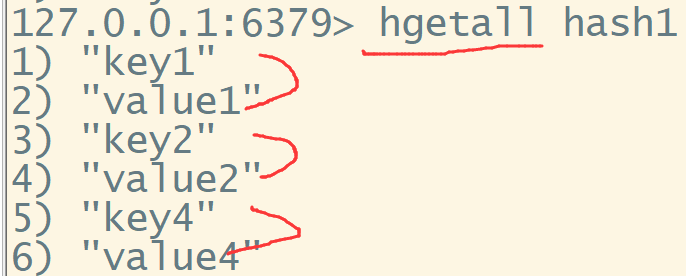
hexists 判断是否存在某个key, 存在返回1,不存在返回0
3) 变更数据
hdel 删除数据 , 使用方式 hdel key field_key 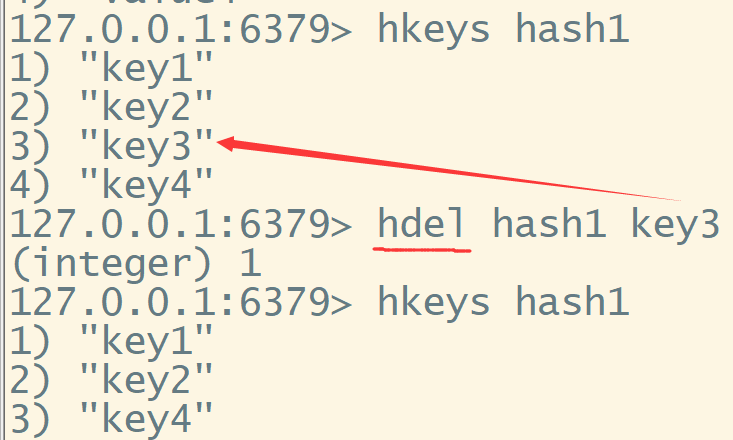
hincrby 对整数的增加操作,指定增加的范围 使用方式 hincrby key field_key num 
数据类型之Set集合

java的集合中有list/set/map list可以存储有序的重复数据, 而set可以存储无序的不重复数据。
原理:类似HashSet,也是通过哈希表实现的,相当于所有的value都是空。通过计算hash的方式来快速排重,也是set能提供判断一个成员是否在集合内的原因。
1 命令:
1)读写操作:
sadd 创建set类型的value
scard key 查看set的大小
smembers key 查询set中的所有值 
sismember key value 判断value是否在key所对应的set中, 如果在返回1,如果不在返回0 
2)更新操作:
srem key value1 value2 删除set中一至多个数据的值 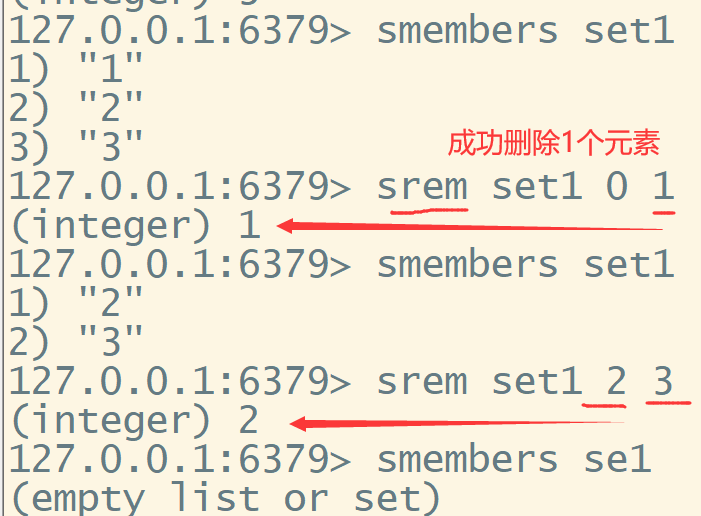
srandmember key num 可以在set中随机出num个元素 
spop key num 可以随机弹出num个元素返回 
3) 交互操作:
smove key1 key2 value 移动元素value从key1到key2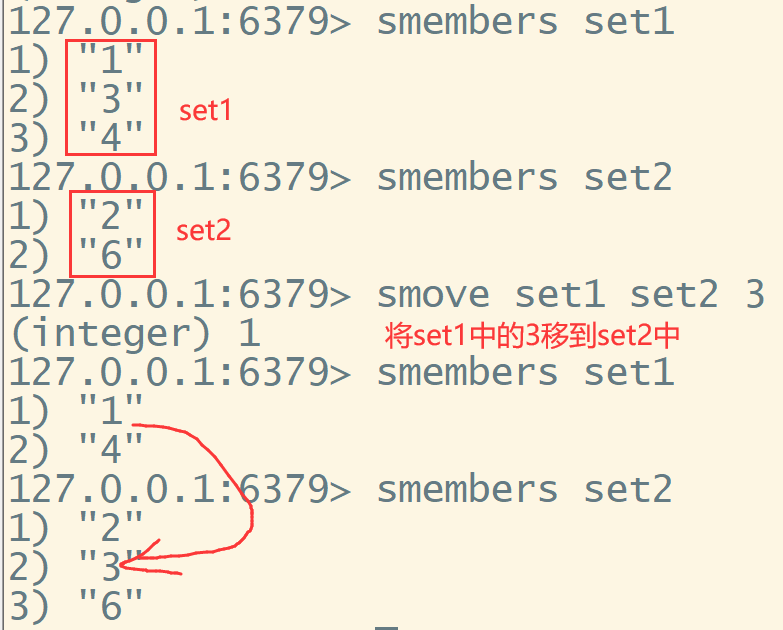
还支持求并集、交集和差集。
sinter key1 key2 代表求两个集合的交集(两者都有的元素)。
sdiff key1 key2 返回存在在key1中但不存在在key2中的元素,两者的差集
sunion key1 key2 返回并集(两个集合中的所有元素)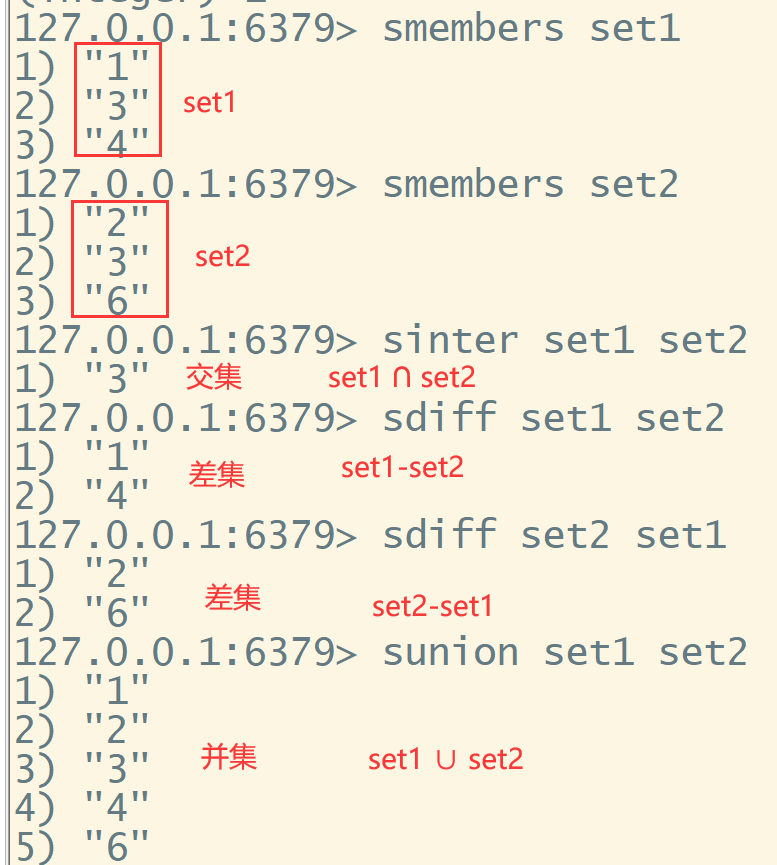
拓展问题: 在java的set中,如何求交集、差集、并集?
方法: retainAll()、removeAll()、addAll()
数据类型之Zset(有序集合)

原理:
类似于SortedSet和HashMap的结合,内部实现是一种叫“跳跃列表”的数据结构。通过层级制,将元素分层并串联,每隔几个元素选出一个代表,再将代表使用另外一级指针串起来,以此类推,形成金字塔结构。同一个元素在不同层级之间身兼数职,是为“跳跃”。新元素插入时,逐层下潜,直到找到合适的位置。
命令
1)读取操作
zadd 创建或增加zset的元素值,每一个元素值都包含 <分数,value> 使用方式: zadd key1 score1 value1 score2 value2 …
zrange key1 start end 指定在start到end的范围内查看元素 如果要查看分数 ,加上withscores 
zrangebyscore key1 minScore maxScore 指定分数范围内查询元素
参数说明 分数前增加“(” 代表开区间(不包含当前值)
支持limit分页 limit + offset(偏移量) + num(返回的数量) 
zrem key1 + value 删除指定的value值 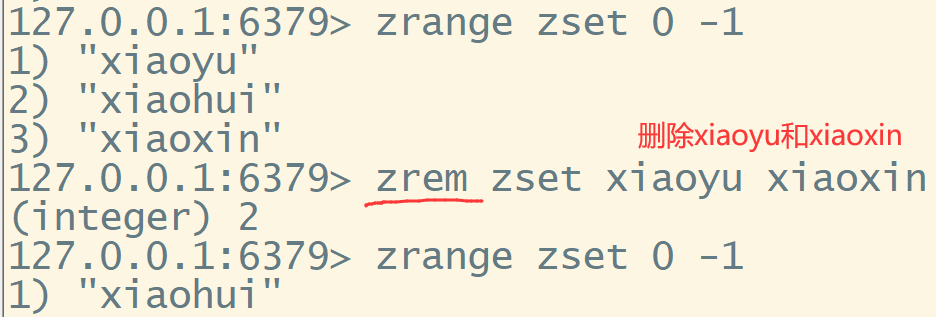
2)统计操作
zcard + key 统计元素个数
zcount + key + minScore + maxScore 统计给定分数范围内的元素个数 比如统计及格人数等需求。
zscore + key + member 查询指定成员的分数
zrank + key + member 返回指定成员的索引位置(因为有序,所以位置代表排名,从低到高)
zrevrank + key + member 默认从低到高排序,逆序正好代表排名
zrevrange 原来是从小到大排列,逆序后从大到小排列

若有收获,就点个赞吧
0 人点赞
