本文翻译自《A visual guide to Go Memory Allocator from scratch (Golang)》。
当我刚开始尝试了解Go的内存分配器时,我发现这真是一件可以令人发疯的事情,因为所有事情似乎都像一个神秘的黑盒 (让我无从下手)。由于几乎所有技术魔法都隐藏在抽象之下,因此您需要逐一剥离这些抽象层才能理解它们。
在这篇文章中,我们就来这么做 (剥离抽象层去了解隐藏在其下面的技术魔法)。如果您想了解有关 Go 内存分配器的知识,那么本篇文章正适合您。
一. 物理内存 (Physical Memory) 和虚拟内存(Virtual Memory)
每个内存分配器都需要使用由底层操作系统管理的虚拟内存空间 (Virtual Memory Space)。让我们看看它是如何工作的吧。
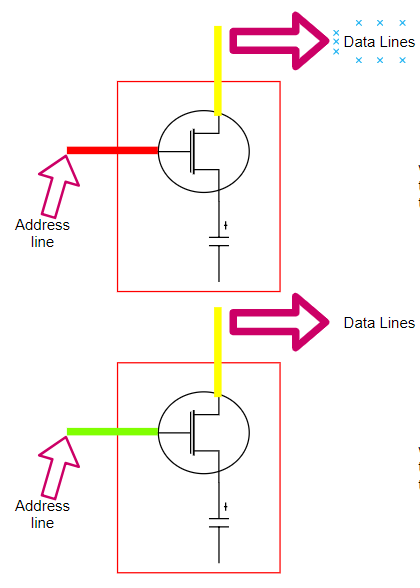
物理存储单元的简单图示(不精确的表示)
单个存储单元(工作流程)的简要介绍:
- 地址线 (address line, 作为开关的晶体管) 提供了访问电容器的入口(数据到数据线(data line))。
- 当地址线中有电流流动时(显示为红色),数据线可能会写入电容器,因此电容器已充电,并且存储的逻辑值为 “1”。
- 当地址线没有电流流动(显示为绿色)时,数据线可能不会写入电容器,因此电容器未充电,并且存储的逻辑值为 “0”。
- 当处理器 (CPU) 需要从内存 (RAM) 中“读取”一个值时,会沿着 “地址线” 发送电流(关闭开关)。如果电容器保持电荷,则电流流经“ DATA LINE”(数据线)得到的值为 1;否则,没有电流流过数据线,电容器将保持未充电状态,得到的值为 0。
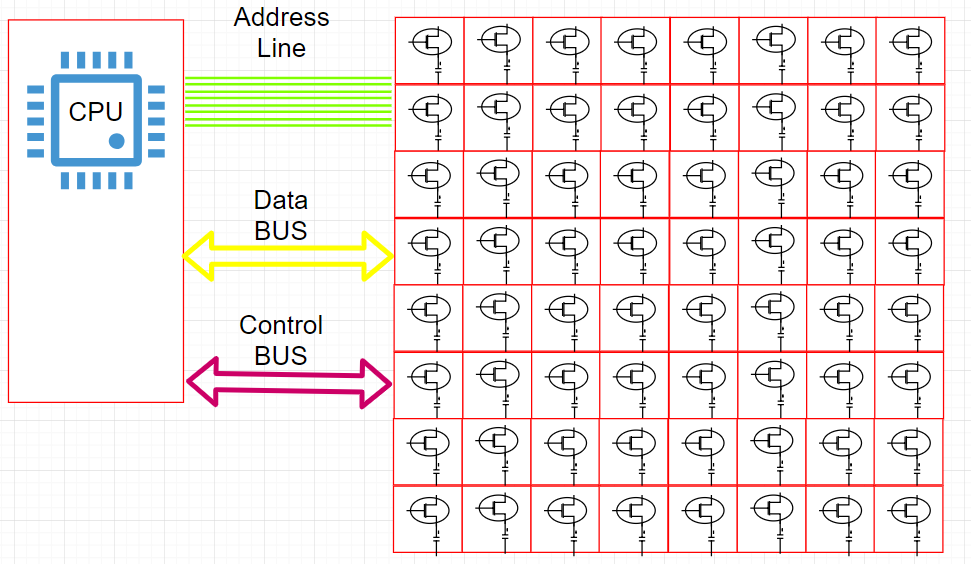
物理内存单元如何与 CPU 交互的简单说明
数据总线 (Data Bus):用于在 CPU 和物理内存之间传输数据。
让我们讨论一下地址线 (Address Line) 和可寻址字节(Addressable Bytes)。
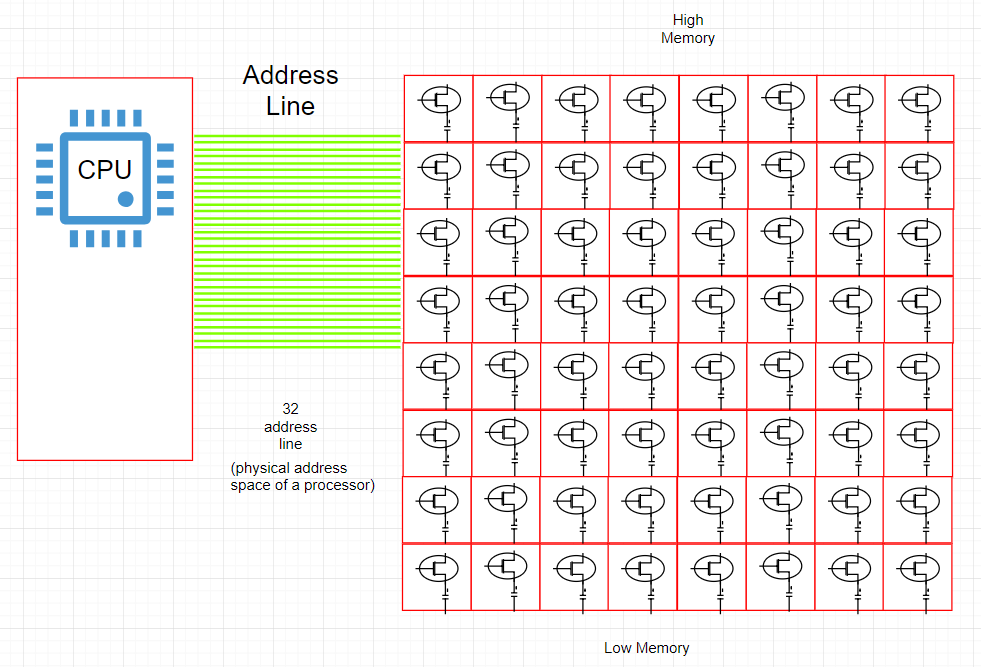
CPU 和物理内存之间的地址线的表示
- DRAM 中的每个 “字节(BYTE)” 都被分配有唯一的数字标识符(地址)。 但 “物理字节的表示 != 地址线的数量”。(例如:16 位 Intel 8088,PAE)
- 每条 “地址线” 都可以发送 1bit 值,因此它可以表示给定字节地址中指定“bit”。
- 在图中,我们有 32 条地址线。因此,每个可寻址字节都将拥有一个 “32bit” 的地址。
[ 00000000000000000000000000000000 ] — 低内存地址[ 11111111111111111111111111111111 ] — 高内存地址
- 由于每个字节都有一个 32bit 地址,所以我们的地址空间由 2 的 32 次方个可寻址字节(即 4GB)组成。
因此,可寻址字节取决于地址线的总量,对于 64 位地址线(x86–64 CPU),其可寻址字节为 2 的 64 次方个,但是大多数使用 64 位指针的体系结构实际上使用 48 位地址线(AMD64 )和 42 位地址线(英特尔),理论上支持 256TB 的物理 RAM(Linux 在 x86–64 上每个进程支持 128TB 以及 4 级页表 (page table) 和 Windows 每个进程则支持 192TB)
由于实际物理内存的限制,因此每个进程都在其自己的内存沙箱中运行 -“虚拟地址空间”,即虚拟内存。
该虚拟地址空间中字节的地址不再与处理器在地址总线上放置的地址相同。因此,必须建立转换数据结构和系统,以将虚拟地址空间中的字节映射到物理内存地址上的字节。
虚拟地址长什么样呢?
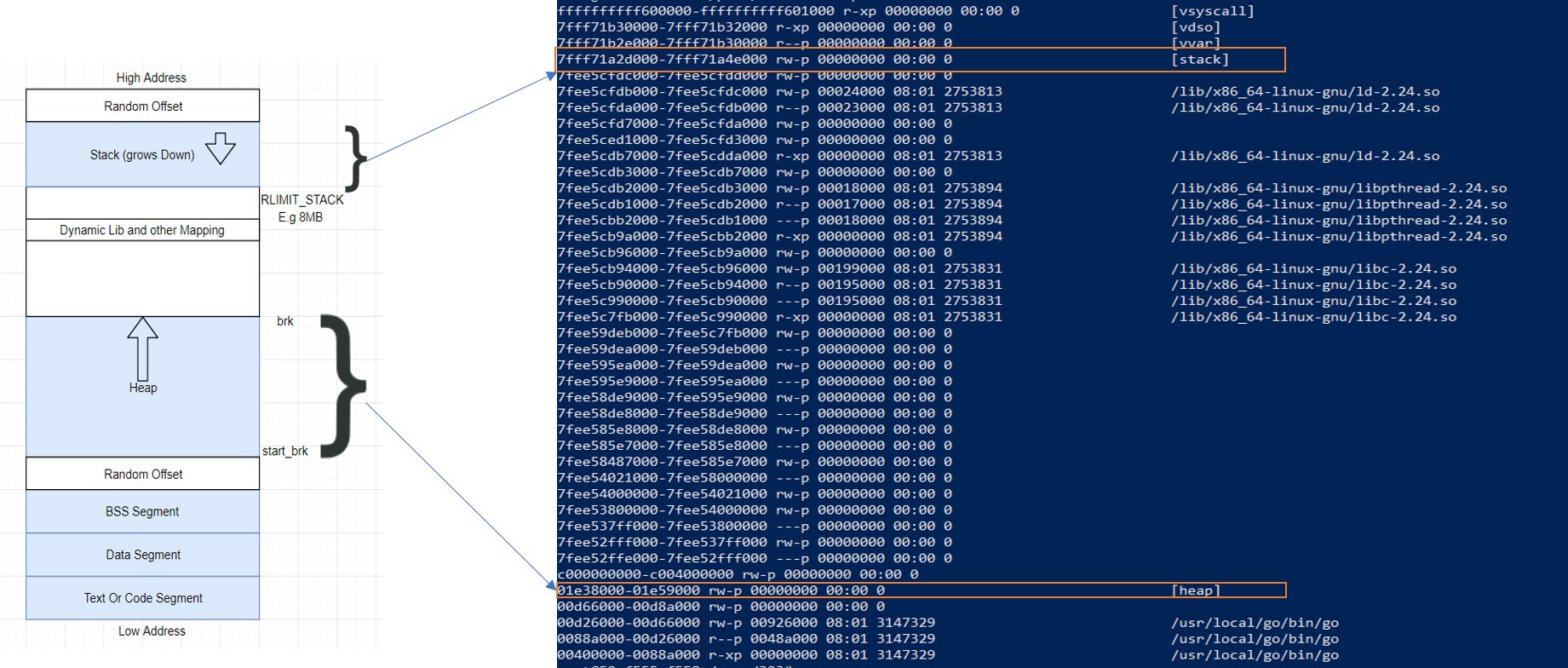
虚拟地址空间表示
因此,当 CPU 执行引用内存地址的指令时。第一步是将 VMA(virtual memory address) 中的逻辑地址转换为线性地址 (liner address)。这个翻译工作由内存管理单元 MMU(Memory Management Unit)完成。
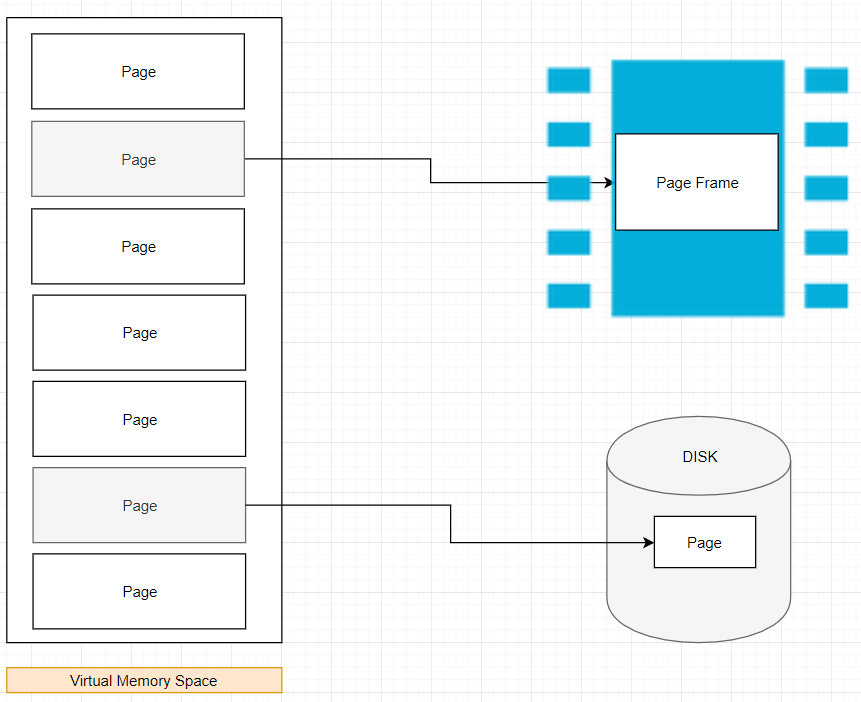
这不是物理图,仅是描述。为了简化,不包括地址翻译过程
由于此逻辑地址太大而无法单独管理(取决于各种因素),因此将通过页 (page) 对其进行管理。当必要的分页构造被激活后,虚拟内存空间将被划分为称为页的较小区域(大多数 OS 上页大小为 4KB,可以更改)。它是虚拟内存中用于内存管理的最小单位。虚拟内存不存储任何内容,仅简单地将程序的地址空间映射到真实的物理内存空间上。
单个进程仅将 VMA(虚拟内存地址) 视为其地址。这样,当我们的程序请求更多 “堆内存(heap memory)” 时会发生什么呢?
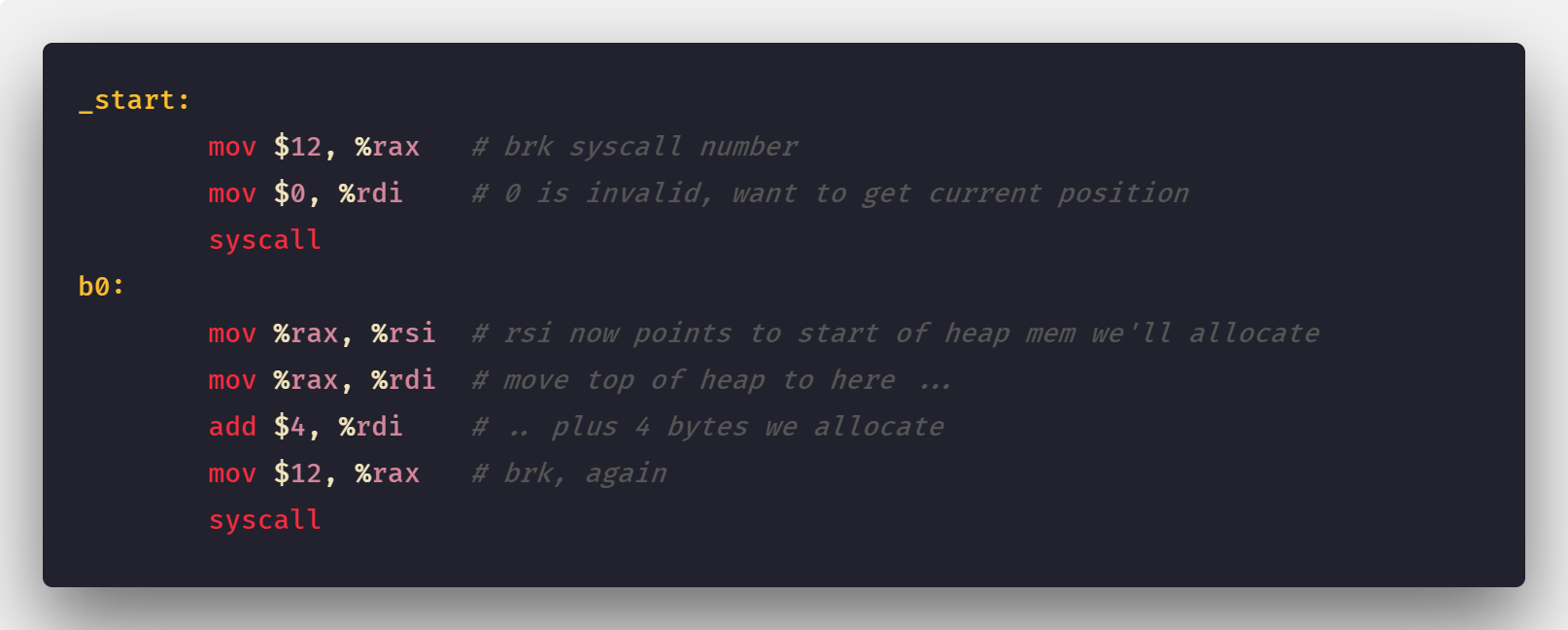
一段简单的用户请求更多堆内存的汇编代码
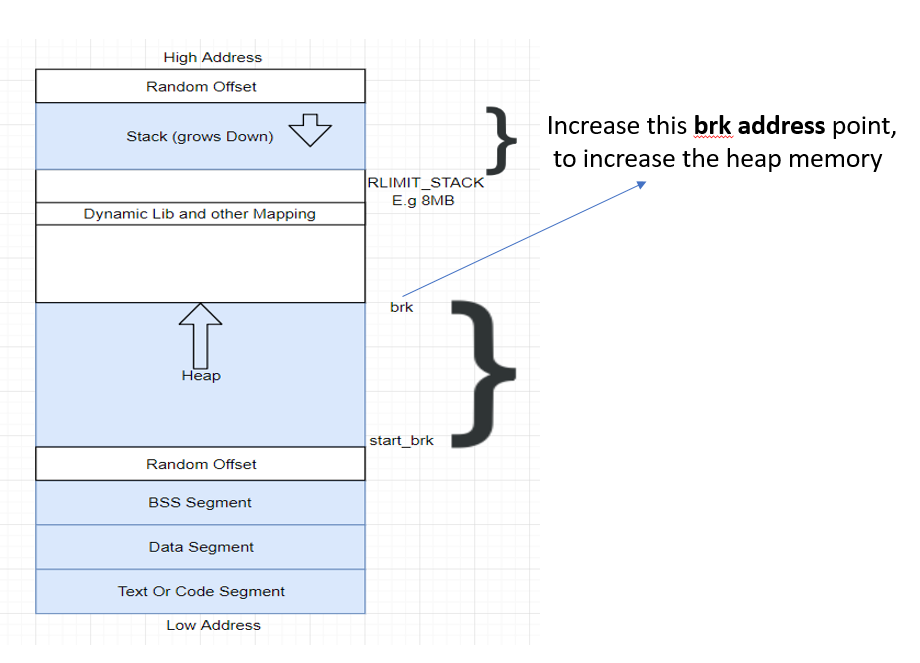
增加堆内存
程序通过brk(sbrk/mmap 等)系统调用请求更多内存。但内核实际上仅是更新了堆的 VMA。
注意:此时,实际上并没有分配任何页帧,并且新页面也没有在物理内存存在。这也是 VSZ 与 RSS 之间的差异点。
二. 内存分配器
有了 “虚拟地址空间” 的基本概述以及堆内存增加的理解之后,内存分配器现在变得更容易说明了。
如果堆中有足够的空间来满足我们代码中的内存请求,则内存分配器可以在内核不参与的情况下满足该请求,否则它会通过系统调用
brk扩大堆,通常会请求大量内存。(默认情况下,对于 malloc 而言,大量的意思是 > MMAP_THRESHOLD 字节 - 128kB)。
但是,内存分配器的责任不仅仅是更新brk 地址。其中一个主要的工作则是如何的降低内外部的内存碎片以及如何快速分配内存块。考虑按 p1~p4 的顺序,先使用函数malloc在程序中请求连续内存块,然后使用函数free(pointer)释放内存。
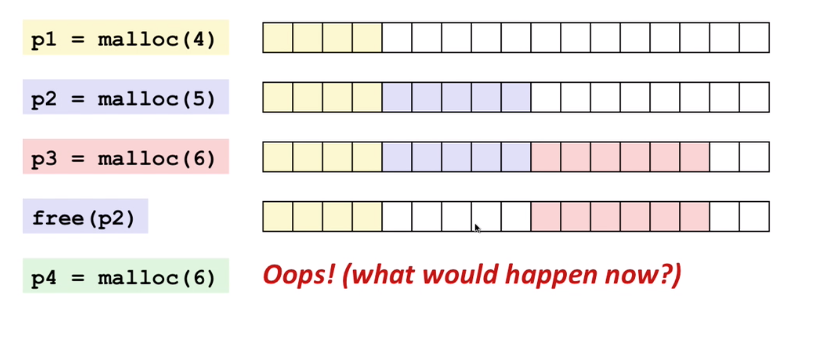
外部内存碎片演示
在第 4 步,即使我们有足够的内存块,我们也无法满足对 6 个连续内存块分配的请求,从而导致内存碎片。
那么如何减少内存碎片呢?这个问题的答案取决于底层库使用的特定的内存分配算法。
我们将研究 TCMalloc 内存分配器,Go 内存分配器采用的就是该内存分配器模型。
三. TCMalloc
TCMalloc(thread cache malloc)的核心思想是将内存划分为多个级别,以减少锁的粒度。在 TCMalloc 内部,内存管理分为两部分:线程内存和页堆 (page heap)。
线程内存 (thread memory)
每个内存页分为多级固定大小的 “空闲列表”,这有助于减少碎片。因此,每个线程都会有一个无锁的小对象缓存,这使得在并行程序下分配小对象(<= 32k)非常高效。
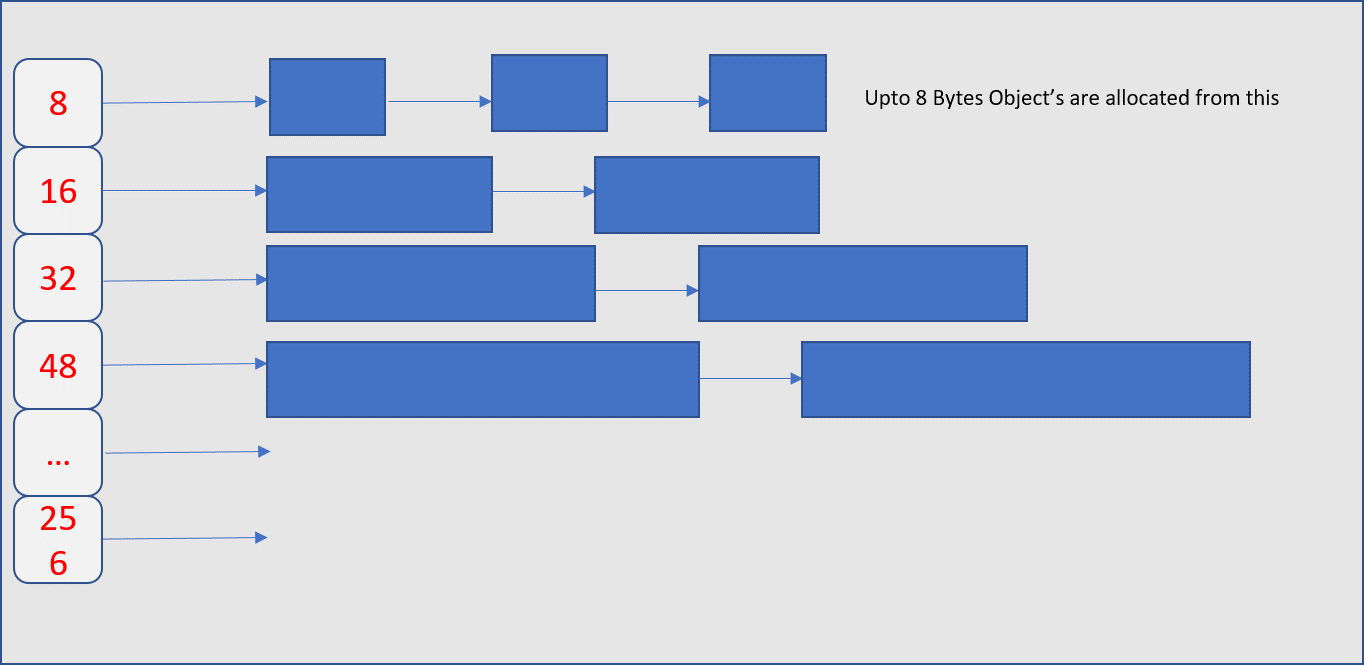
线程缓存(每个线程拥有此线程本地线程缓存)
页堆 (page heap)
TCMalloc 管理的堆由页集合组成,其中一组连续页的集合可以用span表示。当分配的对象大于 32K 时,将使用页堆进行分配。
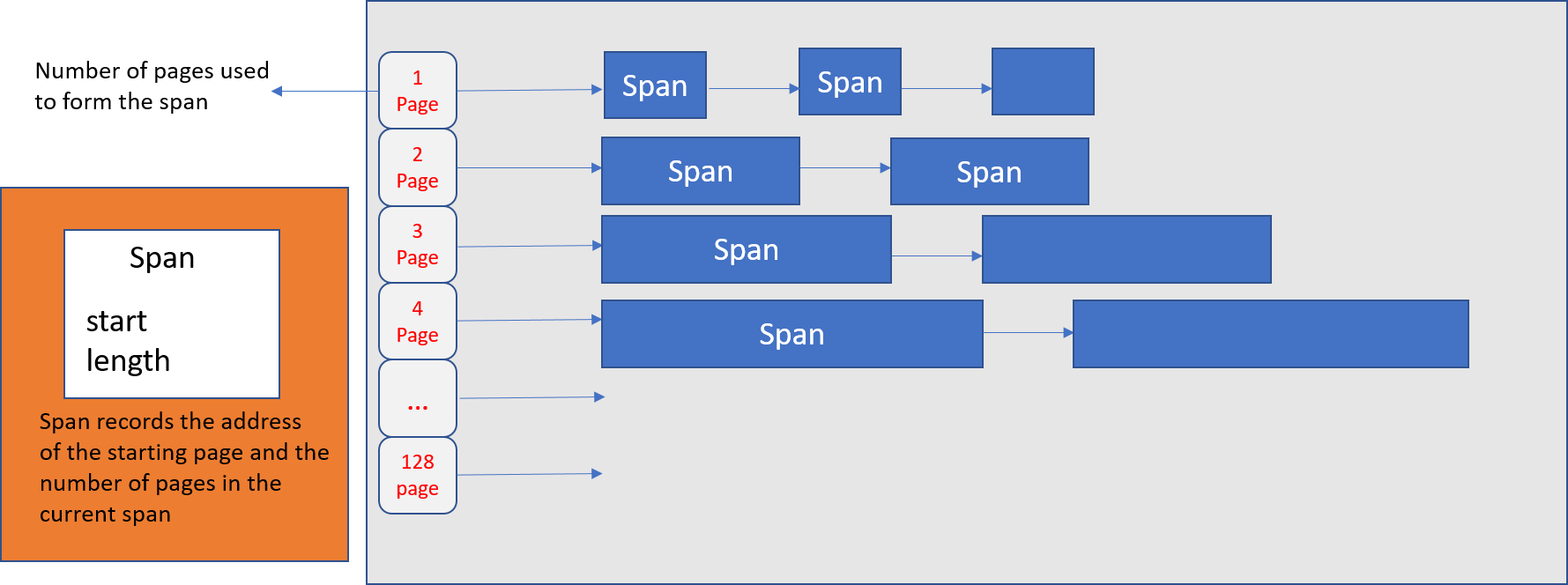
页堆(用于 span 管理)
如果没有足够的内存来分配小对象,内存分配器就会转到页堆以获取内存。如果还没有足够的内存,页堆将从操作系统中请求更多内存。
由于这种分配模型维护了一个用户空间的内存池,因此极大地提高了内存分配和释放的效率。
注意:尽管 go 内存分配器最初是基于 tcmalloc 的,但是现在已经有了很大的不同。
四. Go 内存分配器
我们知道 Go 运行时会将 Goroutines(G)调度到逻辑处理器(P)上执行。同样,基于 TCMalloc 模型的 Go 还将内存页分为 67 个不同大小级别。
如果您不熟悉 Go 调度程序,则可以在这里获取关于 Go 调度程序的相关知识。
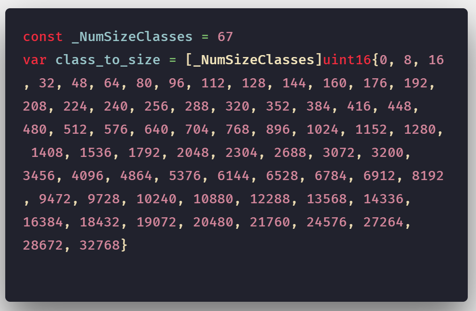
Go 中的内存块的大小级别
Go 默认采用 8192B 大小的页。如果这个页被分成大小为 1KB 的块,我们一共将拿到 8 块这样的页:

将 8 KB 页面划分为 1KB 的大小等级(在 Go 中,页的粒度保持为 8KB)
Go 中的这些页面运行也通过称为 mspan 的结构进行管理。
选择要分配给每个尺寸级别的尺寸类别和页面计数(将页面数分成给定尺寸的对象),以便将分配请求圆整 (四舍五入) 到下一个尺寸级别最多浪费 12.5%
mspan
简而言之,它是一个双向链表对象,其中包含页面的起始地址,它具有的页面的 span 类以及它包含的页面数。
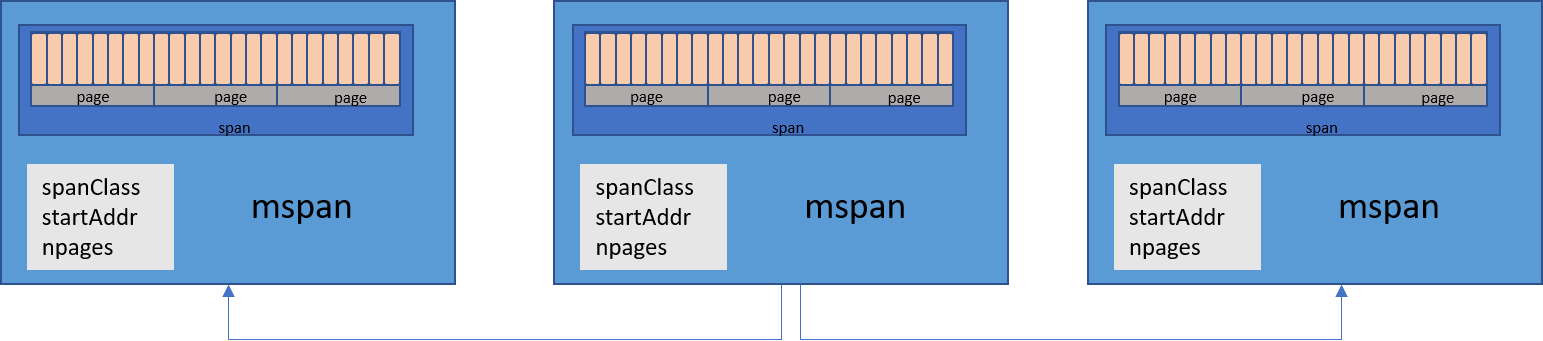
Go 内存分配器中 mspan 的表示形式
mcache
与 TCMalloc 一样,Go 为每个逻辑处理器(P)提供了一个称为mcache的本地内存线程缓存,因此,如果 Goroutine 需要内存,它可以直接从 mcache 中获取它而无需任何锁,因为在任何时间点只有一个 Goroutine 在逻辑处理器(P)上运行。
mcache 包含所有级别大小的 mspan 作为缓存。
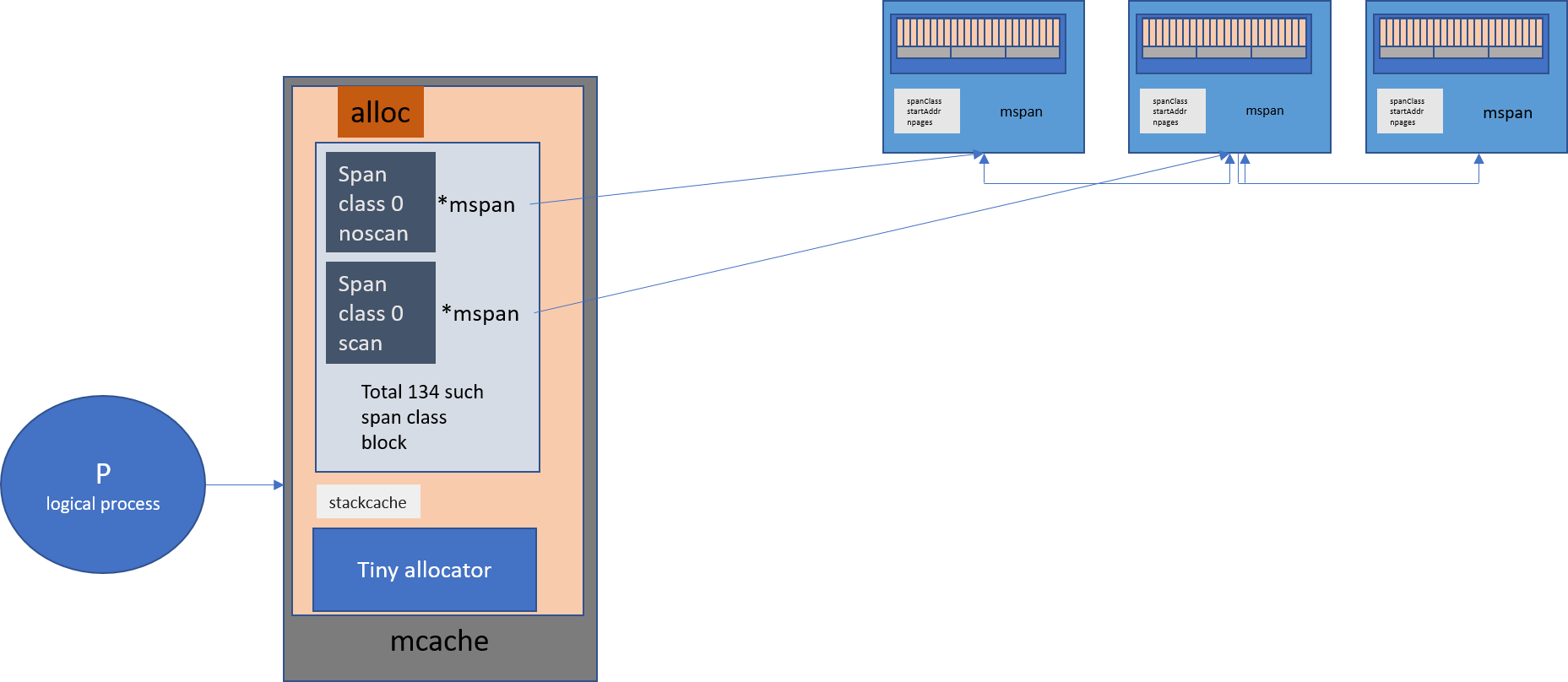
Go 中 P,mcache 和 mspan 之间的关系
由于每个 P 拥有一个 mcache,因此从 mcache 进行分配时无需加锁。
对于每个级别,都有两种类型。
- scan —包含指针的对象。
- noscan —不包含指针的对象。
这种方法的好处之一是在进行垃圾收集时,GC 无需遍历 noscan 对象。
什么 Go mcache?
对象大小 <= 32K 字节的分配将直接交给 mcache,后者将使用对应大小级别的 mspan 应对
当 mcache 没有可用插槽 (slot) 时会发生什么?
从 mcentral mspan list 中获取一个对应大小级别的新的 mspan。
mcentral
mcentral 对象集合了所有给定大小级别的 span,每个 mcentral 是两个 mspan 列表。
- 空的 mspanList — 没有空闲内存的 mspan 或缓存在 mcache 中的 mspan 的列表
- 非空 mspanList – 仍有空闲内存的 span 列表。
当从 mcentral 请求新的 Span 时,它将从非空 mspanList 列表中获取(如果可用)。这两个列表之间的关系如下:当请求新的 span 时,该请求从非空列表中得到满足,并且该 span 被放入空列表中。释放 span 后,将根据 span 中空闲对象的数量将其放回非空列表。
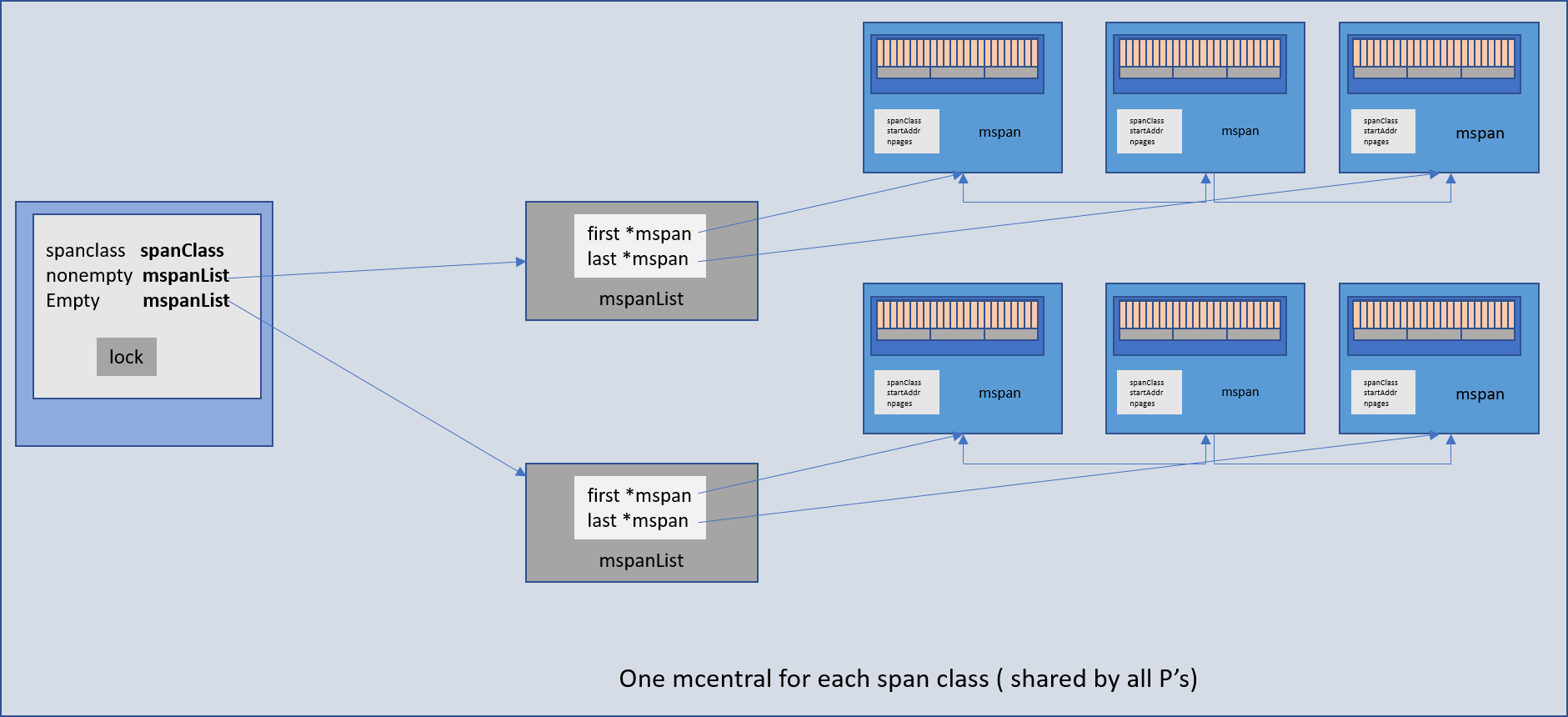
mcentral 表示
每个 mcentral 结构都在 mheap 中维护。
mheap
mheap 是在 Go 中管理堆的对象,且只有一个全局 mheap 对象。它拥有虚拟地址空间。
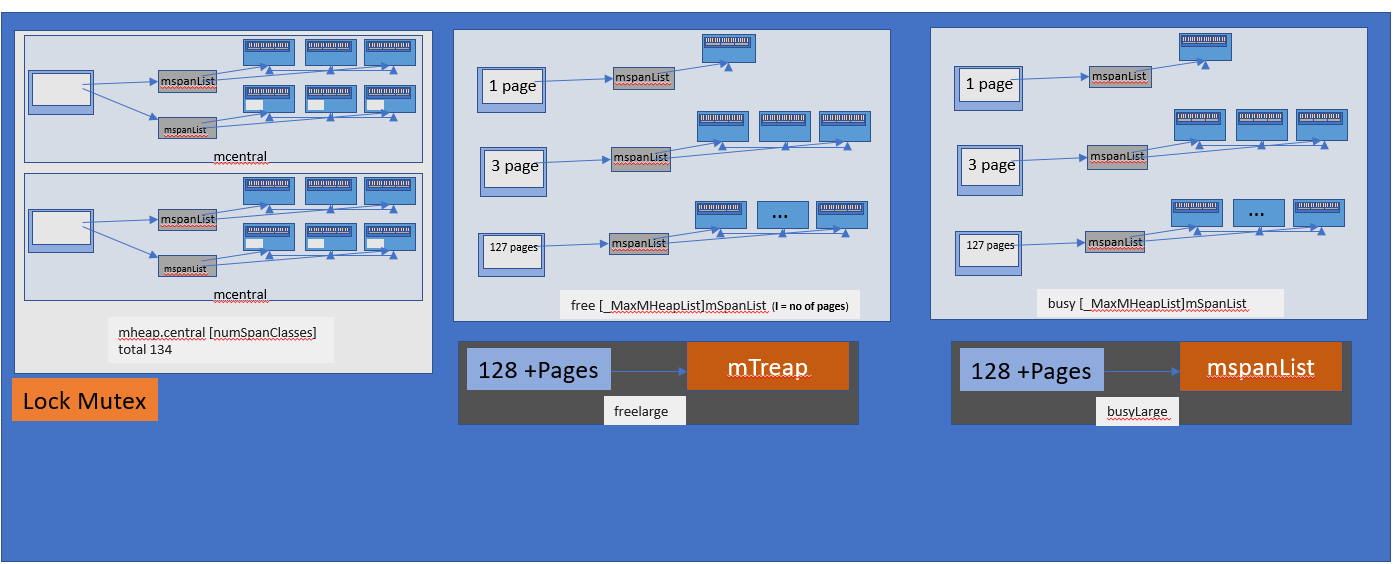
mheap 的表示
从上图可以看出,mheap 具有一个 mcentral 数组。此数组包含每个大小级别 span 的 mcentral。
central [numSpanClasses]struct {mcentral mcentralpad [sys.CacheLineSize unsafe.Sizeof(mcentral{})%sys.CacheLineSize]byte}
由于我们对每个级别的 span 都有 mcentral,因此当 mcache 从 mcentral 请求一个 mspan 时,仅涉及单个 mcentral 级别的锁,因此其他 mache 的不同级别 mspan 的请求也可以同时被处理。
padding 确保将 MCentrals 以CacheLineSize字节间隔开,以便每个 MCentral.lock 获得自己的缓存行,以避免错误的共享问题。
那么,当该 mcentral 列表为空时会发生什么?mcentral 将从 mheap 获取页以用于所需大小级别 span 的分配。
- free [_MaxMHeapList]mSpanList:这是一个 spanList 数组。每个 spanList 中的 mspan 由 1〜127(_MaxMHeapList-1) 页组成。例如,free[3]是包含 3 个页面的 mspan 的链接列表。Free 表示空闲列表,即尚未进行对象分配。它对应于忙碌列表 (busy list)。
- freelarge mSpanList:mspans 列表。每个 mspan 的页数大于 127。Go 内存分配器以 mtreap 数据结构来维护它。对应 busyLarge。
大小 > 32k 的对象是一个大对象,直接从 mheap 分配。这些较大的请求需要中央锁 (central lock),因此在任何给定的时间点只能满足一个 P 的请求
五. 对象分配流程
- 大小 > 32k 是一个大对象,直接从 mheap 分配。
- 大小 < 16B,使用 mcache 的 tiny 分配器分配
- 大小在 16B〜32k 之间,计算要使用的 sizeClass,然后在 mcache 中使用相应的 sizeClass 的块分配
- 如果与 mcache 对应的 sizeClass 没有可用的块,则向 mcentral 发起请求。
- 如果 mcentral 也没有可用的块,则向 mheap 请求。mheap 使用 BestFit 查找最合适的 mspan。如果超出了申请的大小,则会根据需要进行划分,以返回用户所需的页面数。其余页面构成一个新的 mspan,并返回 mheap 空闲列表。
- 如果 mheap 没有可用的 span,请向操作系统申请一组新的页(至少 1MB)。
但是 Go 在 OS 级别分配的页面甚至更大(称为 arena)。分配大量页面将分摊与操作系统进行对话的成本。
所有请求的堆内存都来自于 arena。让我们看看 arena 是什么。
六. Go 虚拟内存
让我们看一个简单 go 程序的内存。
func main(){for {}}
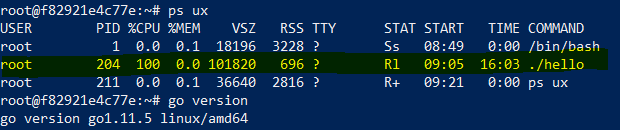
程序的进程状态
因此,即使是简单的 go 程序,占用的虚拟空间也是大约 100MB 而 RSS 只有 696kB。让我们尝试首先找出这种差异的原因。
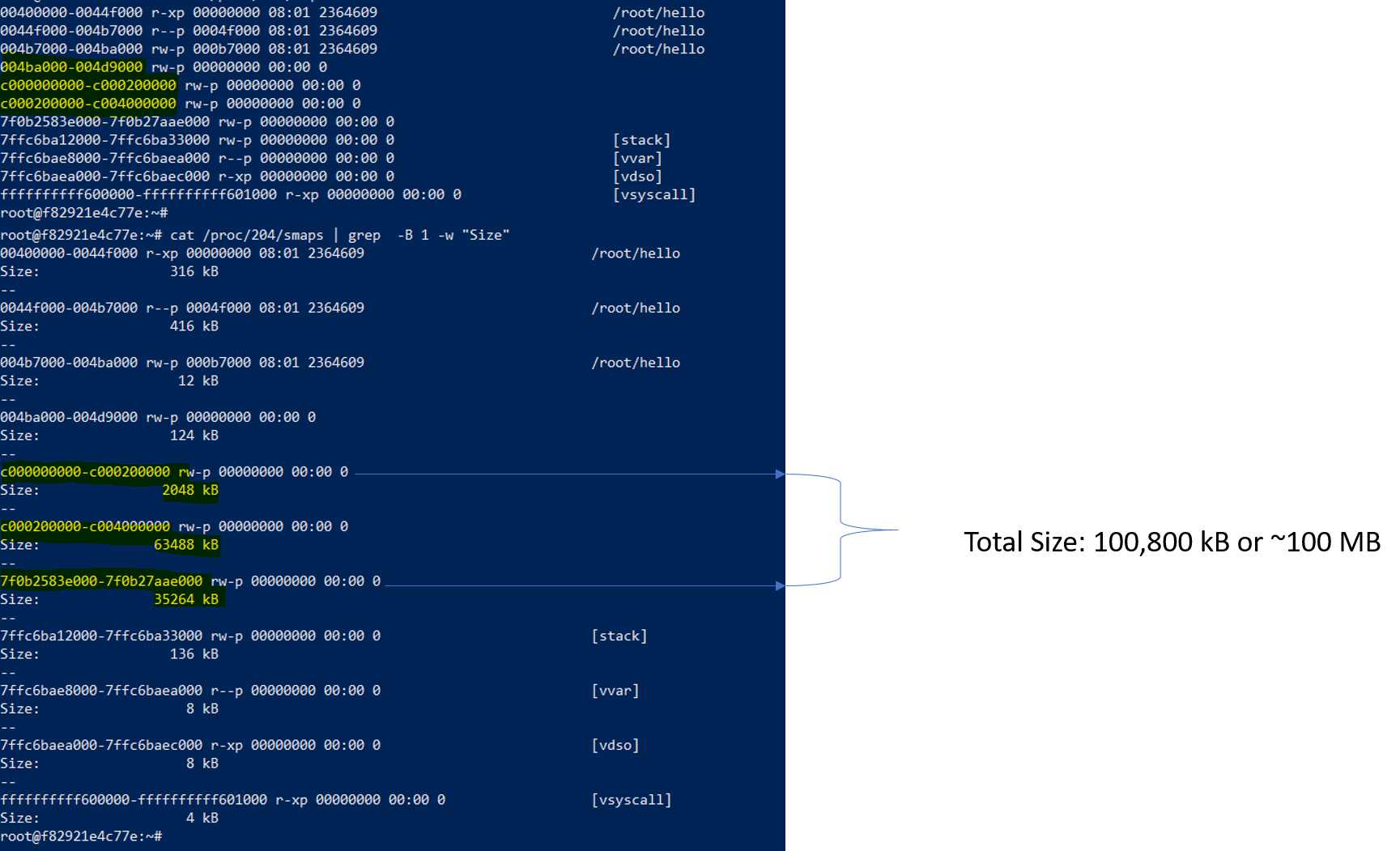
map 和 smap 统计信息
因此,内存区域的大小约为〜2MB, 64MB and 32MB。这些是什么?
Arena
原来,Go 中的虚拟内存布局由一组 arena 组成。初始堆映射是一个 arena,即 64MB(基于 go 1.11.5)。
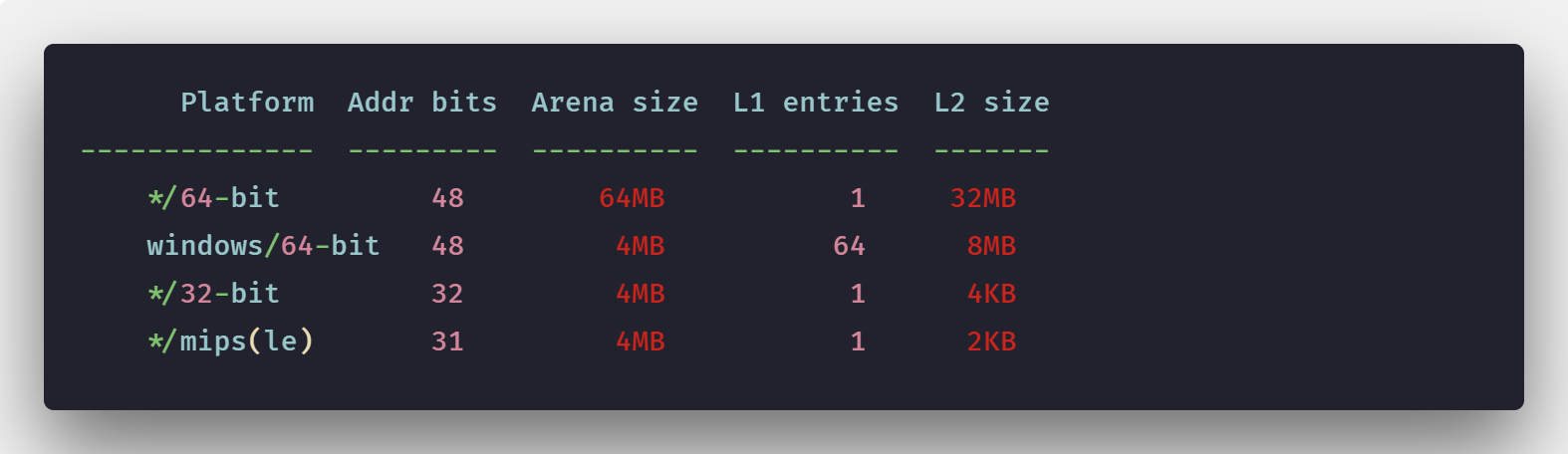
当前在不同系统上的 arena 大小。
因此,当前根据程序需要,内存以较小的增量进行映射,并且它以一个 arena(〜64MB)开始。
这是可变的。早期的 go 保留连续的虚拟地址,在 64 位系统上,arena 大小为 512 GB。(如果分配足够大并且被 mmap 拒绝,会发生什么?)
这个 arena 集合是我们所谓的堆。Go 以 8192B 大小粒度的页面管理每个 arena。

单个 arena(64 MB)。
Go 还有两个 span 和 bitmap 块。它们都在堆外分配,并存储着每个 arena 的元数据。它主要在垃圾收集期间使用(因此我们现在将其保留)。
我们刚刚讨论过的 Go 中的内存分配策略,但这些也仅是奇妙多样的内存分配的一些皮毛。
但是,Go 内存管理的总体思路是使用不同的内存结构为不同大小的对象使用不同的缓存级别内存来分配内存。将从操作系统接收的单个连续地址块分割为多级缓存以减少锁的使用,从而提高内存分配效率,然后根据指定的大小分配内存分配,从而减少内存碎片,并在内存释放 houhou 有利于更快的 GC。
现在,我将向您提供此 Go Memory Allocator 的全景图。
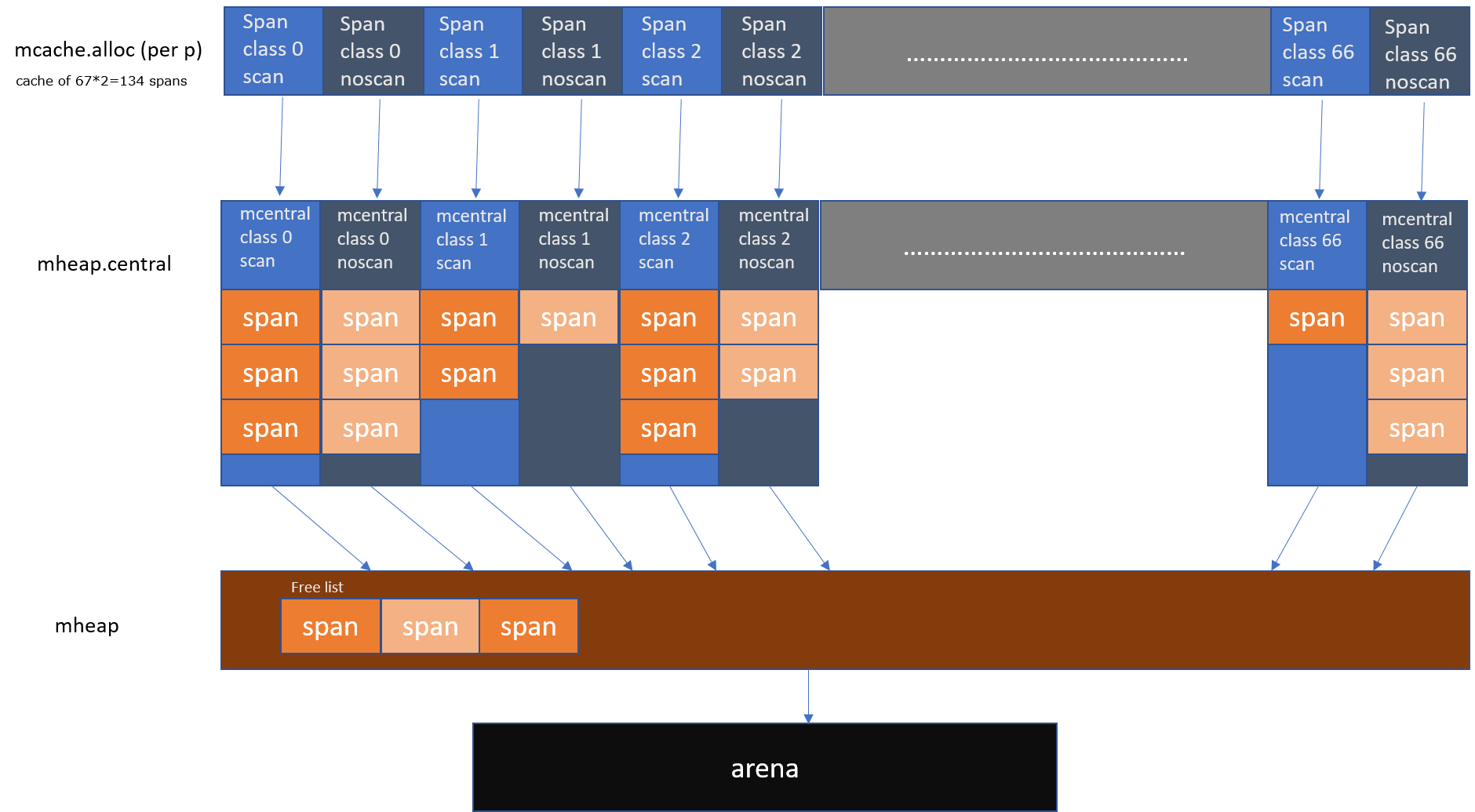
运行时内存分配器的可视化全景图。
我的网课 “Kubernetes 实战:高可用集群搭建、配置、运维与应用” 在慕课网上线了,感谢小伙伴们学习支持!
我爱发短信:企业级短信平台定制开发专家 https://51smspush.com/
smspush : 可部署在企业内部的定制化短信平台,三网覆盖,不惧大并发接入,可定制扩展; 短信内容你来定,不再受约束, 接口丰富,支持长短信,签名可选。
著名云主机服务厂商 DigitalOcean 发布最新的主机计划,入门级 Droplet 配置升级为:1 core CPU、1G 内存、25G 高速 SSD,价格 5$/ 月。有使用 DigitalOcean 需求的朋友,可以打开这个链接地址:https://m.do.co/c/bff6eed92687 开启你的 DO 主机之路。
Gopher Daily(Gopher 每日新闻) 归档仓库 – https://github.com/bigwhite/gopherdaily
我的联系方式:
微博:https://weibo.com/bigwhite20xx
微信公众号:iamtonybai
博客:tonybai.com
github: https://github.com/bigwhite
微信赞赏:

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。
© 2020, bigwhite. 版权所有.
Related posts:

若有收获,就点个赞吧
0 人点赞
