总结
- pool 是用来缓解 Gc 压力的,会在每次 Gc 之前全部清空 pool,GC 默认每两分钟一次
- 在倒入 pool 包时执行的 init 函数会向 GC 注册
poolCleanup函数,也就是在 GC 之前会运行该函数。 - pool 也存在私有队列为空的时候,从全局队列偷取一部分
- noCopy 保证是一个空结构,用来防止 pool 在第一次使用后被复制
- 分为本地 local 和 global 队列 来绑定 P 进行操作
- poollocal 有 pad 来防止
false sharding
流程图
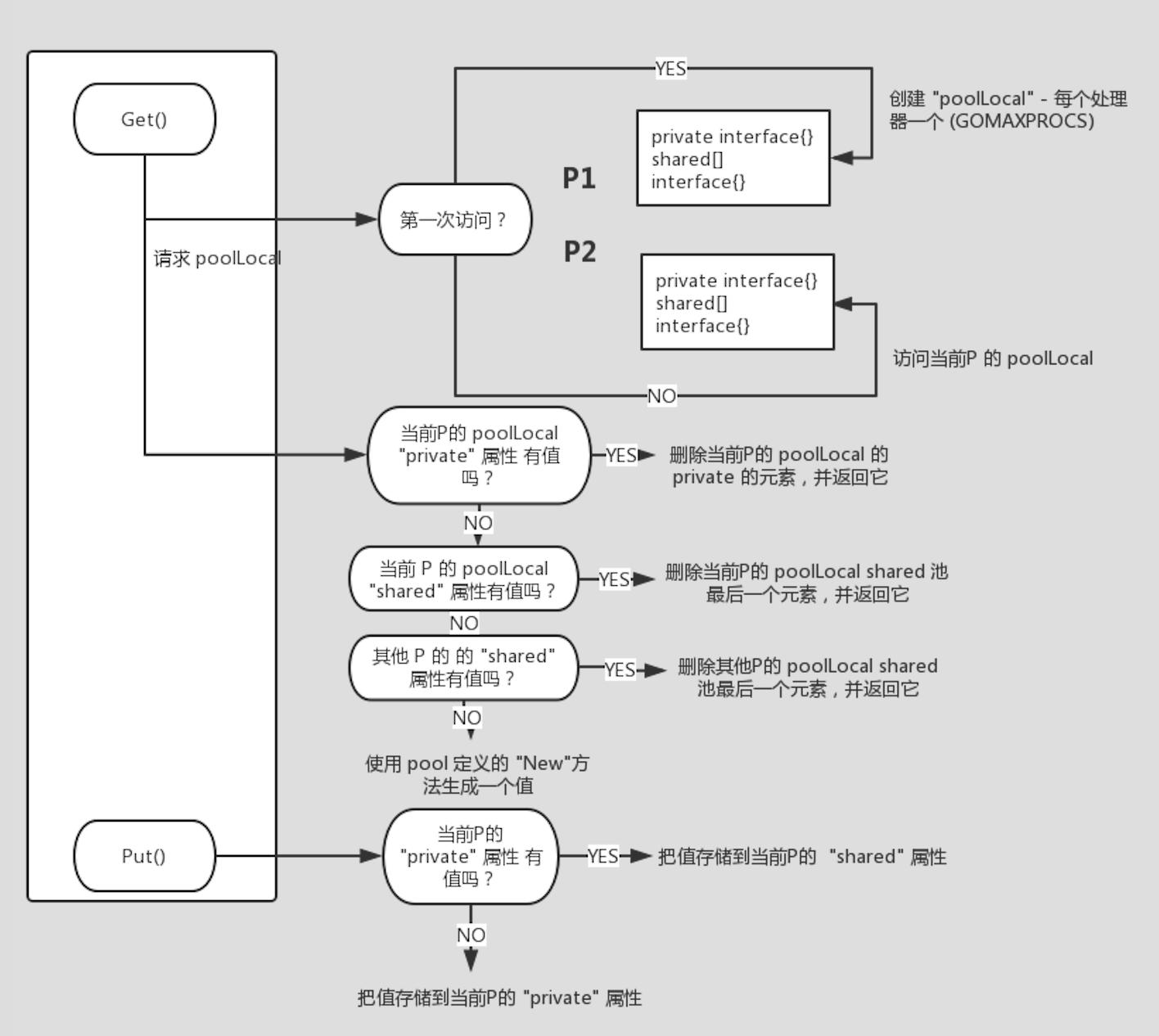
为了使得在多个 goroutine 中高效的使用 goroutine,sync.Pool 为每个 P(对应 CPU) 都分配一个本地池,当执行 Get 或者 Put 操作的时候,会先将 goroutine 和某个 P 的子池关联,再对该子池进行操作。 每个 P 的子池分为私有对象和共享列表对象,私有对象只能被特定的 P 访问,共享列表对象可以被任何 P 访问。因为同一时刻一个 P 只能执行一个 goroutine,所以无需加锁,但是对共享列表对象进行操作时,因为可能有多个 goroutine 同时操作,所以需要加锁。
值得注意的是 poolLocal 结构体中有个 pad 成员,目的是为了防止 false sharing。cache 使用中常见的一个问题是 false sharing。当不同的线程同时读写同一 cache line 上不同数据时就可能发生 false sharing。false sharing 会导致多核处理器上严重的系统性能下降。具体的可以参考伪共享 (False Sharing)。
false sharding
缓存系统中是以缓存行(cache line)为单位存储的。缓存行是 2 的整数幂个连续字节,一般为 32-256 个字节。最常见的缓存行大小是 64 个字节。当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。缓存行上的写竞争是运行在 SMP 系统中并行线程实现可伸缩性最重要的限制因素。有人将伪共享描述成无声的性能杀手,因为从代码中很难看清楚是否会出现伪共享。
为了让可伸缩性与线程数呈线性关系,就必须确保不会有两个线程往同一个变量或缓存行中写。两个线程写同一个变量可以在代码中发现。为了确定互相独立的变量是否共享了同一个缓存行,就需要了解内存布局
数据结构
type Pool struct {noCopy noCopy // noCopy 是一个空结构,用来防止 pool 在第一次使用后被复制local unsafe.Pointer // per-P pool, 实际类型为 [P]poolLocallocalSize uintptr // local 的 size// New 在 pool 中没有获取到,调用该方法生成一个变量New func() interface{}}// 具体存储结构type poolLocalInternal struct {private interface{} // 只能由自己的 P 使用shared []interface{} // 可以被任何的 P 使用Mutex // 保护 shared 线程安全}type poolLocal struct {poolLocalInternal// 避免缓存 false sharing,使不同的线程操纵不同的缓存行,多核的情况下提升效率。pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte}var (allPoolsMu MutexallPools []*Pool // 池列表)
- noCopy 保证是一个空结构,用来防止 pool 在第一次使用后被复制
- 分为本地 local 和 global 队列 来绑定 P 进行操作
- poollocal 有 pad 来防止
false sharding
主体流程
Put 方法
Put 方法的整个流程比较简单,主要是将用完的对象放回池中,看一**释就可以理解。
- 获取当前私有队列,放入私有本地队列失败,放入全局队列
func (p *Pool) Put(x interface{}) {...// 获取当前 P 的 pooll := p.pin()// 私有属性为空 放入if l.private == nil {l.private = xx = nil}runtime_procUnpin()// 私有属性放入失败 放入 shared 池if x != nil {l.Lock()l.shared = append(l.shared, x)l.Unlock()}...}
Get 方法
我们找到对应的代码如下,
func (p *Pool) Get() interface{} {...// 获取当前 P 的 poolLocall := p.pin()// 先从 private 读取x := l.privatel.private = nilruntime_procUnpin()// private 没有if x == nil {l.Lock()// 从当前 P 的 shared 末尾取一个last := len(l.shared) - 1if last >= 0 {x = l.shared[last]l.shared = l.shared[:last]}l.Unlock()// 还没有取到 则去其他 P 的 shared 取if x == nil {x = p.getSlow()}}...// 最后还没取到 调用 NEW 方法生成一个if x == nil && p.New != nil {x = p.New()}return x}
上面有一个 p.getSlow() 操作是说从其他的 P 中偷取一个,比较有意思,在 Go 的 GMP 模型中也存在这个偷的概念,基本和这个类似。我们来看看
func (p *Pool) getSlow() (x interface{}) {...// 尝试从其他 P 中窃取一个元素。pid := runtime_procPin()runtime_procUnpin()for i := 0; i < int(size); i++ {// 获取其他 P 的 poolLocall := indexLocal(local, (pid+i+1)%int(size))l.Lock()last := len(l.shared) - 1if last >= 0 {x = l.shared[last]l.shared = l.shared[:last]l.Unlock()break}l.Unlock()}return x}
存活周期以及内存回收
在倒入 pool 包时执行的 init 函数会向 GC 注册 poolCleanup 函数,也就是在 GC 之前会运行该函数。
func init() {runtime_registerPoolCleanup(poolCleanup)}
我们来看看 poolCleanup,该函数主要是将所有池的变量解除引用,为下一步的 GC 作准备。
func poolCleanup() {// 在 GC 时会调用此函数。// 它不能分配,也不应该调用任何运行时函数。// 防御性地将所有东西归零,原因有两个:// 1. 防止整个池的错误保留。// 2. 如果GC发生时goroutine与Put / Get中的l.shared一起使用,它将保留整个Pool。因此下一周期内存消耗将增加一倍。for i, p := range allPools {// 将所有池对象接触引用 等待 GC 回收allPools[i] = nilfor i := 0; i < int(p.localSize); i++ {l := indexLocal(p.local, i)l.private = nilfor j := range l.shared {l.shared[j] = nil}l.shared = nil}p.local = nilp.localSize = 0}allPools = []*Pool{}}

若有收获,就点个赞吧
0 人点赞
