接着上文我们继续
本文需要大量对函数栈帧的理解 直通车:
上文我们进行到了schedinit函数,这是 runtime·rt0_go 函数里的一步
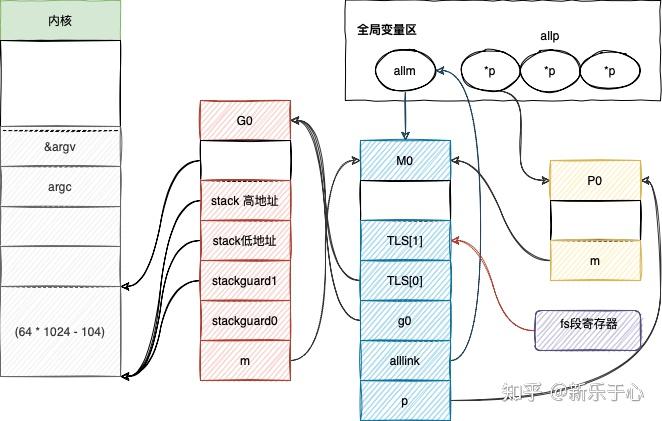
上面展示了 schedinit 执行完之后 g0 m0 p(…) 都已经初始化完毕 并互相绑定 全局链表allp allm 等也初始化完成。
那接下我们要做什么?正题开始: 启动 main goroutine 正式干活了
main goroutine 来了
TEXT runtime·rt0_go(SB),NOSPLIT,$0***上个章节代码***//TODO 参数初始化 栈空余的16利用CALL runtime·args(SB)//TODO 初始化系统核心数CALL runtime·osinit(SB)//TODO 开始初始化调度器CALL runtime·schedinit(SB)// create a new goroutine to start program//mainPC 代表的main函数的地址 main函数保存在AXMOVQ $runtime·mainPC(SB), AX // entry//压栈 参数AXPUSHQ AX//size main函数入参size main函数没有参数 为0PUSHQ $0 // arg size//调用关键函数 newproc 创建main goroutineCALL runtime·newproc(SB)POPQ AXPOPQ AX// start this MCALL runtime·mstart(SB)//主循环里调用了 schedule 不会返回 故出错了直接crashCALL runtime·abort(SB) // mstart should never returnRET//栈顶指针恢复 **// Prevent dead-code elimination of debugCallV1, which is// intended to be called by debuggers.MOVQ $runtime·debugCallV1(SB), AXRETDATA runtime·mainPC+0(SB)/8,$runtime·main(SB)GLOBL runtime·mainPC(SB),RODATA,$8
大概描述了一下过程
- 获取 main 函数的地址 并放入 AX 寄存器
- 发起函数调用 runtime.newproc 创建 main goroutine
- 启动调度循环
- 防止循环失败 crash
现在我们开始 newproc 核心函数的解析
/*newproc用于创建一个新的g 并运行fn函数而我们根据函数调用栈分析得知 当前栈在被调用函数的栈帧上故新的goroutine需要进行fn函数的参数拷贝,而拷贝就要知道参数大小 所以一个是size 一个是fn代表被调函数*///go:nosplitfunc newproc(siz int32, fn *funcval) {//获取fn函数的参数argp := add(unsafe.Pointer(&fn), sys.PtrSize)//获取当前g 启动时为g0gp := getg()//获取调用者的指令地址 调用newproc 由call指令压栈的返回地址 POPQ AXpc := getcallerpc()//切换到g0栈 执行 但是本身就在g0栈 忽略systemstack(func() {newproc1(fn, argp, siz, gp, pc)})}
主要操作在 newproc1 里
/*被调函数,g0栈上的参数(启动过程),size,原协程g,返回地址*/func newproc1(fn *funcval, argp unsafe.Pointer, narg int32, callergp *g, callerpc uintptr) {//获取当前g 启动时为g0_g_ := getg()if fn == nil {//crash_g_.m.throwing = -1 // do not dump full stacksthrow("go of nil func value")}//内存对齐相关acquirem() // disable preemption because it can be holding p in a local varsiz := nargsiz = (siz + 7) &^ 7// We could allocate a larger initial stack if necessary.// Not worth it: this is almost always an error.// 4*sizeof(uintreg): extra space added below// sizeof(uintreg): caller's LR (arm) or return address (x86, in gostartcall).if siz >= _StackMin-4*sys.RegSize-sys.RegSize {throw("newproc: function arguments too large for new goroutine")}_p_ := _g_.m.p.ptr()//从gfree里看看有没有g p的localnewg := gfget(_p_)if newg == nil {//分配新的g 2048bnewg = malg(_StackMin)//cas控制状态切换 为 dead状态casgstatus(newg, _Gidle, _Gdead)//放入全局变量allgs中allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.}//栈分配检查if newg.stack.hi == 0 {throw("newproc1: newg missing stack")}//状态检查if readgstatus(newg) != _Gdead {throw("newproc1: new g is not Gdead")}//内存对齐totalSize := 4*sys.RegSize + uintptr(siz) + sys.MinFrameSize // extra space in case of reads slightly beyond frametotalSize += -totalSize & (sys.SpAlign - 1) // align to spAlignsp := newg.stack.hi - totalSize//确定参数入栈位置spArg := spif usesLR {// caller's LR*(*uintptr)(unsafe.Pointer(sp)) = 0prepGoExitFrame(sp)spArg += sys.MinFrameSize}if narg > 0 {//从g0拷贝参数到 新的g栈 栈到栈copymemmove(unsafe.Pointer(spArg), argp, uintptr(narg))// This is a stack-to-stack copy. If write barriers// are enabled and the source stack is grey (the// destination is always black), then perform a// barrier copy. We do this *after* the memmove// because the destination stack may have garbage on// it.if writeBarrier.needed && !_g_.m.curg.gcscandone {f := findfunc(fn.fn)stkmap := (*stackmap)(funcdata(f, _FUNCDATA_ArgsPointerMaps))if stkmap.nbit > 0 {// We're in the prologue, so it's always stack map index 0.bv := stackmapdata(stkmap, 0)bulkBarrierBitmap(spArg, spArg, uintptr(bv.n)*sys.PtrSize, 0, bv.bytedata)}}}//清空newg的sched gobuf 上下文保存相关的memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))//设置gobuf寄存器相关newg.sched.sp = spnewg.stktopsp = sp//设置调度的执行开始指令 获取goexit的地址后增加1个地址的偏移newg.sched.pc = funcPC(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same functionnewg.sched.g = guintptr(unsafe.Pointer(newg))gostartcallfn(&newg.sched, fn)
记录下当前状态
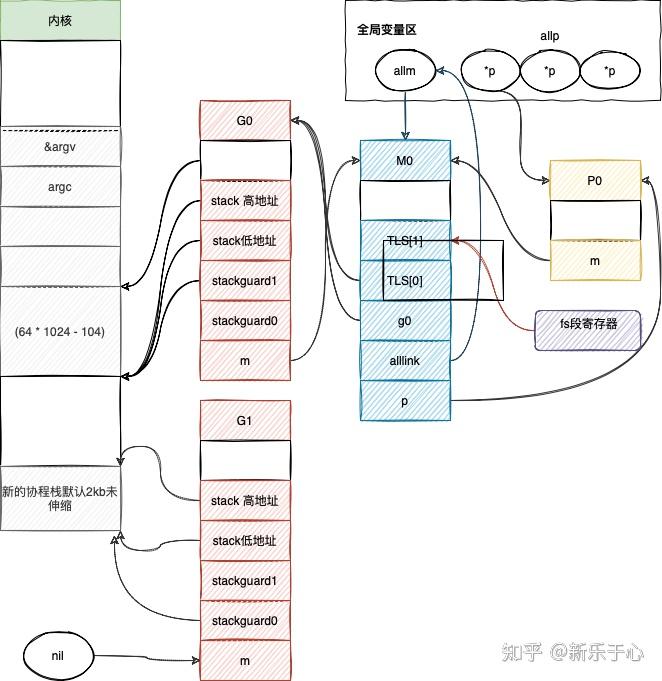
gostartcallfn
//拆解出了包含在 funcval 结构体里的函数指针//调用gostartcallfunc gostartcallfn(gobuf *gobuf, fv *funcval) {var fn unsafe.Pointerif fv != nil {fn = unsafe.Pointer(fv.fn)} else {fn = unsafe.Pointer(funcPC(nilfunc))}gostartcall(gobuf, fn, unsafe.Pointer(fv))}
gostartcall
func gostartcall(buf *gobuf, fn, ctxt unsafe.Pointer) {//g的栈顶 现在入栈的只有fn的参数 通过拷贝sp := buf.spif sys.RegSize > sys.PtrSize {sp -= sys.PtrSize*(*uintptr)(unsafe.Pointer(sp)) = 0}//预留返回地址空间sp -= sys.PtrSize//装入goexit函数 等于把goexit函数插入栈顶*(*uintptr)(unsafe.Pointer(sp)) = buf.pcbuf.sp = spbuf.pc = uintptr(fn)buf.ctxt = ctxt}
上面的gostartcallfn、gostartcall 主要就做了一件事情
把 goexit 函数强行插入 newg 的栈顶,等 newg 结束后方便进行清扫的工作
初始化完 newg 的 sched gobuf
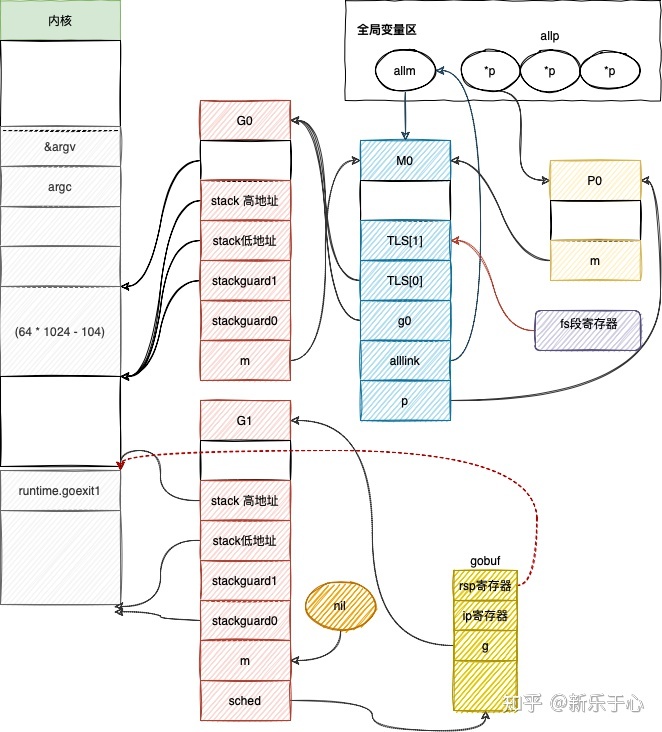
//修改运行状态为runnable cas修改casgstatus(newg, _Gdead, _Grunnable)if _p_.goidcache == _p_.goidcacheend {// Sched.goidgen is the last allocated id,// this batch must be [sched.goidgen+1, sched.goidgen+GoidCacheBatch].// At startup sched.goidgen=0, so main goroutine receives goid=1._p_.goidcache = atomic.Xadd64(&sched.goidgen, _GoidCacheBatch)_p_.goidcache -= _GoidCacheBatch - 1_p_.goidcacheend = _p_.goidcache + _GoidCacheBatch}//goid ~newg.goid = int64(_p_.goidcache)_p_.goidcache++if raceenabled {newg.racectx = racegostart(callerpc)}if trace.enabled {traceGoCreate(newg, newg.startpc)}//放入本地p的待运行队列runqput(_p_, newg, true)
修改状态 放入本地运行队列 p
//next为假 把g放到可运行队列的尾部//next为真 把g放到p.runnext//满了放到全局g队列func runqput(_p_ *p, gp *g, next bool) {if randomizeScheduler && next && fastrand()%2 == 0 {next = false}if next {retryNext:oldnext := _p_.runnext//cas操作是否有其他的并发操作//修改当前p的runnext 为新的gif !_p_.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) {goto retryNext}if oldnext == 0 {return}//取出旧的g丢到队列尾部gp = oldnext.ptr()}retry:h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with consumerst := _p_.runqtail//如果p本地队列未满 入队if t-h < uint32(len(_p_.runq)) {_p_.runq[t%uint32(len(_p_.runq))].set(gp)atomic.StoreRel(&_p_.runqtail, t+1) // store-release, makes the item available for consumptionreturn}//本地队列慢了,放入全局队列if runqputslow(_p_, gp, h, t) {return}// the queue is not full, now the put above must succeedgoto retry}
这里不展开分析 属于调度相关的源码,后面我们再进行专项调度代码的分析
这里我们已经做到了,新创建了一个 goroutine,设置好了 sched 成员的 sp 和 pc 字段,并且将其添加到了 p0 的本地可运行队列,坐等调度器的调度。
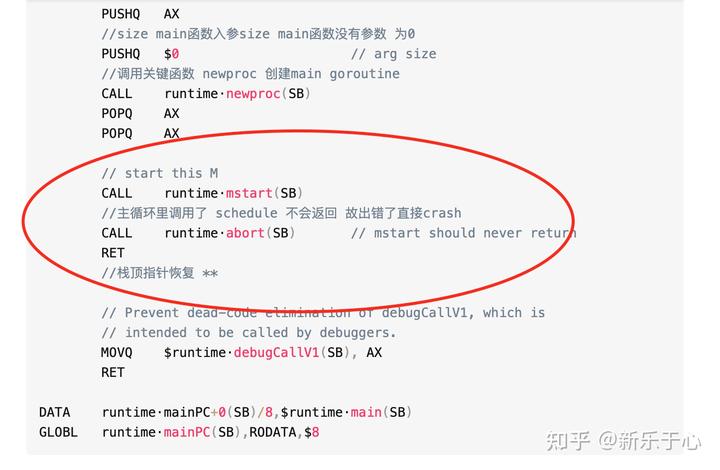
还剩余这个两个主要的 call 了,现在开始准备启动调度循环
mstart(0) 里调用了 mstart1
func mstart1() {//启动时为g0_g_ := getg()if _g_ != _g_.m.g0 {throw("bad runtime·mstart")}// Record the caller for use as the top of stack in mcall and// for terminating the thread.// We're never coming back to mstart1 after we call schedule,// so other calls can reuse the current frame.//调用schedule之后永远不会返回 所以复用栈帧//准备调度前保存调度信息到g0.schedsave(getcallerpc(), getcallersp())asminit()minit()// Install signal handlers; after minit so that minit can// prepare the thread to be able to handle the signals.if _g_.m == &m0 {mstartm0()}//执行启动函数 g0fn为nilif fn := _g_.m.mstartfn; fn != nil {fn()}if _g_.m != &m0 {acquirep(_g_.m.nextp.ptr())_g_.m.nextp = 0}// 进入调度循环。永不返回schedule()}
主要做的是协程切换时一些寄存器信息的保存和处理,之后开始调用 schedule 进入调度循环
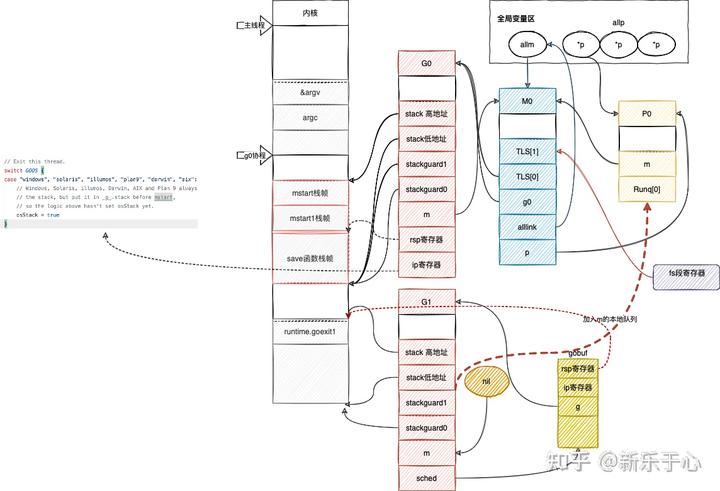
简单看下调度循环吧
func schedule() {//每个m对应的工作线程 启动时为m0的g0_g_ := getg()if _g_.m.locks != 0 {throw("schedule: holding locks")}if _g_.m.lockedg != 0 {stoplockedm()execute(_g_.m.lockedg.ptr(), false) // Never returns.}...var gp *gvar inheritTime bool...if gp == nil {// Check the global runnable queue once in a while to ensure fairness.// Otherwise two goroutines can completely occupy the local runqueue// by constantly respawning each other.//防止全局队列的g被饿死 所以写死61次就要从全局队列中获取if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {lock(&sched.lock)gp = globrunqget(_g_.m.p.ptr(), 1)unlock(&sched.lock)}}//从p的local queue里面获取gif gp == nil {gp, inheritTime = runqget(_g_.m.p.ptr())// We can see gp != nil here even if the M is spinning,// if checkTimers added a local goroutine via goready.}if gp == nil {//全局队列和本地队列都没有找到 从其他的工作线程进行偷取 偷不到当前工作线程睡眠 block阻塞等待获取到可以运行的ggp, inheritTime = findrunnable() // blocks until work is available}// This thread is going to run a goroutine and is not spinning anymore,// so if it was marked as spinning we need to reset it now and potentially// start a new spinning M.//清空自旋状态if _g_.m.spinning {resetspinning()}...//执行goroutine的被调函数//切换栈空间回到newG的栈和栈空间去执行execute(gp, inheritTime)}
摘抄了部分关键代码块,最后开始执行 execute 函数切换到 newG 开始执行
func execute(gp *g, inheritTime bool) {//当前获取的是g0_g_ := getg()// 关联gp和m_g_.m.curg = gpgp.m = _g_.m//修改运行状态 cas ==> _Grunningcasgstatus(gp, _Grunnable, _Grunning)gp.waitsince = 0gp.preempt = falsegp.stackguard0 = gp.stack.lo + _StackGuardif !inheritTime {//调度次数+1_g_.m.p.ptr().schedtick++}//核心函数//完成栈切换//cpu执行权转让gogo(&gp.sched)}
gogo 函数是一个汇编函数 这样可以精确地控制 cpu 寄存器和函数栈帧切换
TEXT runtime·gogo(SB), NOSPLIT, $16-8//buf = &gp.sched 进入bxMOVQ buf+0(FP), BX // gobuf//DX = gp.sched.gMOVQ gobuf_g(BX), DXMOVQ 0(DX), CX // make sure g != nil//把tls保存在CX寄存器上get_tls(CX)//gp.sched.g 放到tls0MOVQ DX, g(CX)//设置cpu的sp寄存器为 sched.sp 栈切换MOVQ gobuf_sp(BX), SP // restore SP//恢复调度上下文MOVQ gobuf_ret(BX), AXMOVQ gobuf_ctxt(BX), DXMOVQ gobuf_bp(BX), BP//清空原上下文MOVQ $0, gobuf_sp(BX) // clear to help garbage collectorMOVQ $0, gobuf_ret(BX)MOVQ $0, gobuf_ctxt(BX)MOVQ $0, gobuf_bp(BX)//把sched.pc 指令值放入BX寄存器MOVQ gobuf_pc(BX), BX//调到 sched.pc 开始执行JMP BX
从 g0 栈切换到 newg 栈 并把之前保存好的 sched 插入到对应的寄存器中,清空原来的 sched
减少 gc 的压力,最后 JMP 开始执行 main 函数。
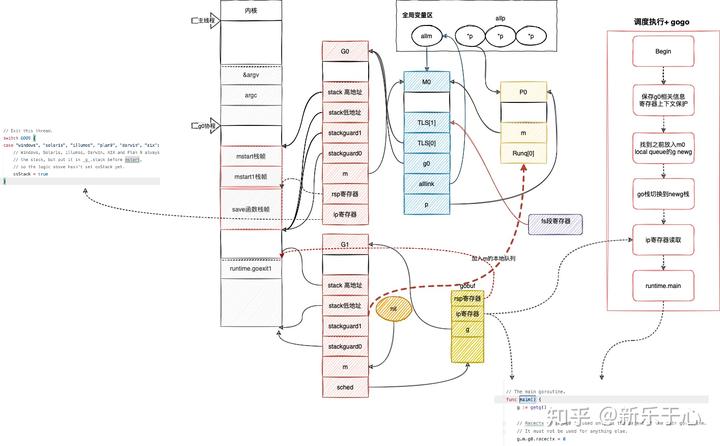
简单用一张图表示下全部过程

若有收获,就点个赞吧
0 人点赞
