在上篇中,我们已经讨论过如何去实现一个 Map 了,并且也讨论了诸多优化点。在下篇中,我们将继续讨论如何实现一个线程安全的 Map。说到线程安全,需要从概念开始说起。

线程安全就是如果你的代码块所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。
如果代码块中包含了对共享数据的更新操作,那么这个代码块就可能是非线程安全的。但是如果代码块中类似操作都处于临界区之中,那么这个代码块就是线程安全的。
通常有以下两类避免竞争条件的方法来实现线程安全:
第一类 —— 避免共享状态
- 可重入 Re-entrancy)
通常在线程安全的问题中,最常见的代码块就是函数。让函数具有线程安全的最有效的方式就是使其可重入。如果某个进程中所有线程都可以并发的对函数进行调用,并且无论他们调用该函数的实际执行情况怎么样,该函数都可以产生预期的结果,那么就可以说这个函数是可重入的。
如果一个函数把共享数据作为它的返回结果或者包含在它返回的结果中,那么该函数就肯定不是一个可重入的函数。任何内含了操作共享数据的代码的函数都是不可重入的函数。
为了实现线程安全的函数,把所有代码都置放于临界区中是可行的。但是互斥量的使用总会耗费一定的系统资源和时间,使用互斥量的过程总会存在各种博弈和权衡。所以请合理使用互斥量保护好那些涉及共享数据操作的代码。
注意:可重入只是线程安全的充分不必要条件,并不是充要条件。这个反例在下面会讲到。
- 线程本地存储
如果变量已经被本地化,所以每个线程都有自己的私有副本。这些变量通过子程序和其他代码边界保留它们的值,并且是线程安全的,因为这些变量都是每个线程本地存储的,即使访问它们的代码可能被另一个线程同时执行,依旧是线程安全的。
- 不可变量
对象一旦初始化以后就不能改变。这意味着只有只读数据被共享,这也实现了固有的线程安全性。可变(不是常量)操作可以通过为它们创建新对象,而不是修改现有对象的方式去实现。 Java,C#和 Python 中的字符串的实现就使用了这种方法。
第二类 —— 线程同步
第一类方法都比较简单,通过代码改造就可以实现。但是如果遇到一定要进行线程中共享数据的情况,第一类方法就解决不了了。这时候就出现了第二类解决方案,利用线程同步的方法来解决线程安全问题。
今天就从线程同步开始说起。
一. 线程同步理论
在多线程的程序中,多以共享数据作为线程之间传递数据的手段。由于一个进程所拥有的相当一部分虚拟内存地址都可以被该进程中所有线程共享,所以这些共享数据大多是以内存空间作为载体的。如果两个线程同时读取同一块共享内存但获取到的数据却不同,那么程序很容易出现一些 bug。
为了保证共享数据一致性,最简单并且最彻底的方法就是使该数据成为一个不变量。当然这种绝对的方式在大多数情况下都是不可行的。比如函数中会用到一个计数器,记录函数被调用了几次,这个计数器肯定就不能被设为常量。那这种必须是变量的情况下,还要保证共享数据的一致性,这就引出了临界区的概念。
临界区的出现就是为了使该区域只能被串行的访问或者执行。临界区可以是某个资源,也可以是某段代码。保证临界区最有效的方式就是利用线程同步机制。
先介绍 2 种共享数据同步的方法。
1. 互斥量
在同一时刻,只允许一个线程处于临界区之内的约束称为互斥,每个线程在进入临界区之前,都必须先锁定某个对象,只有成功锁定对象的线程才能允许进入临界区,否则就会阻塞。这个对象称为互斥对象或者互斥量。
一般我们日常说的互斥锁就能达到这个目的。
互斥量可以有多个,它们所保护的临界区也可以有多个。先从简单的说起,一个互斥量和一个临界区。
(一) 一个互斥量和一个临界区
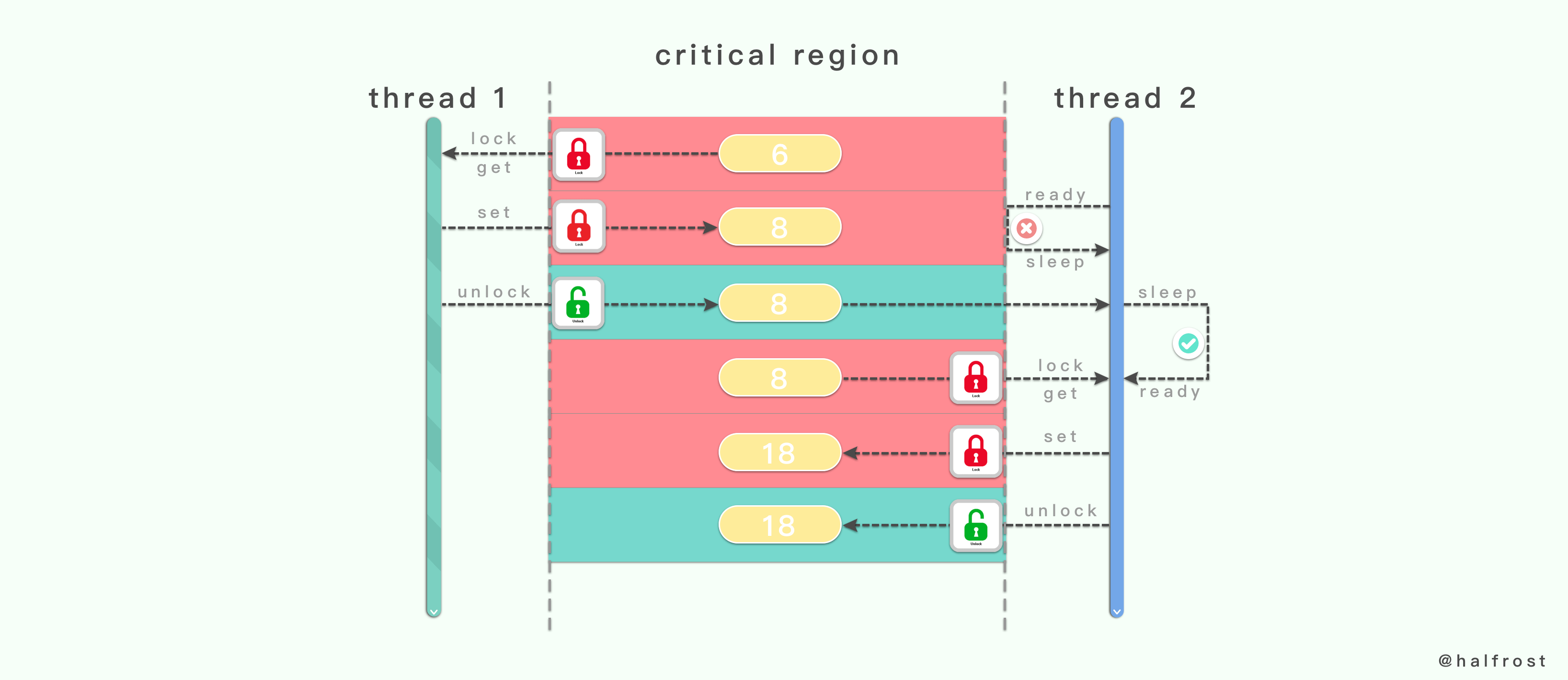
上图就是一个互斥量和一个临界区的例子。当线程 1 先进入临界区的时候,当前临界区处于未上锁的状态,于是它便先将临界区上锁。线程 1 获取到临界区里面的值。
这个时候线程 2 准备进入临界区,由于线程 1 把临界区上锁了,所以线程 2 进入临界区失败,线程 2 由就绪状态转成睡眠状态。线程 1 继续对临界区的共享数据进行写入操作。
当线程 1 完成所有的操作以后,线程 1 调用解锁操作。当临界区被解锁以后,会尝试唤醒正在睡眠的线程 2。线程 2 被唤醒以后,由睡眠状态再次转换成就绪状态。线程 2 准备进入临界区,当临界区此处处于未上锁的状态,线程 2 便将临界区上锁。
经过 read、write 一系列操作以后,最终在离开临界区的时候会解锁。
线程在离开临界区的时候,一定要记得把对应的互斥量解锁。这样其他因临界区被上锁而导致睡眠的线程还有机会被唤醒。所以对同一个互斥变量的锁定和解锁必须成对的出现。既不可以对一个互斥变量进行重复的锁定,也不能对一个互斥变量进行多次的解锁。
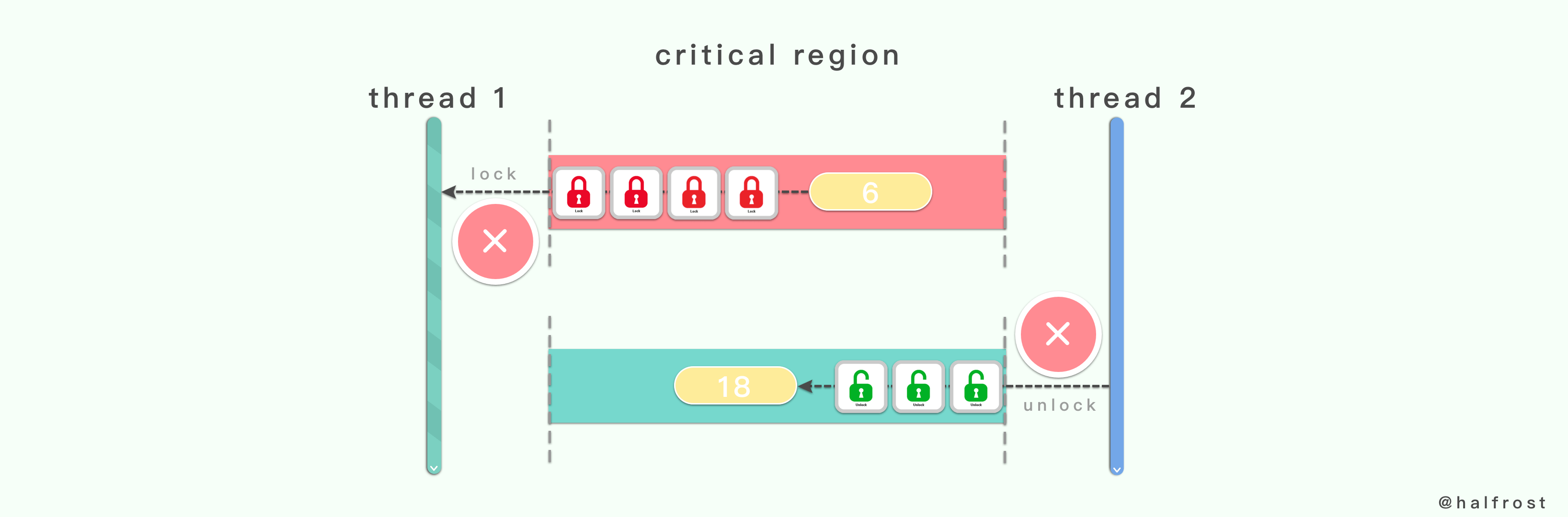
如果对一个互斥变量锁定多次可能会导致临界区最终永远阻塞。可能有人会问了,对一个未锁定的互斥变成解锁多次会出现什么问题呢?
在 Go 1.8 之前,虽然对互斥变量解锁多次不会引起任何 goroutine 的阻塞,但是它可能引起一个运行时的恐慌。Go 1.8 之前的版本,是可以尝试恢复这个恐慌的,但是恢复以后,可能会导致一系列的问题,比如重复解锁操作的 goroutine 会永久的阻塞。所以 Go 1.8 版本以后此类运行时的恐慌就变成了不可恢复的了。所以对互斥变量反复解锁就会导致运行时操作,最终程序异常退出。
(二) 多个互斥量和一个临界区
在这种情况下,极容易产生线程死锁的情况。所以尽量不要让不同的互斥量所保护的临界区重叠。
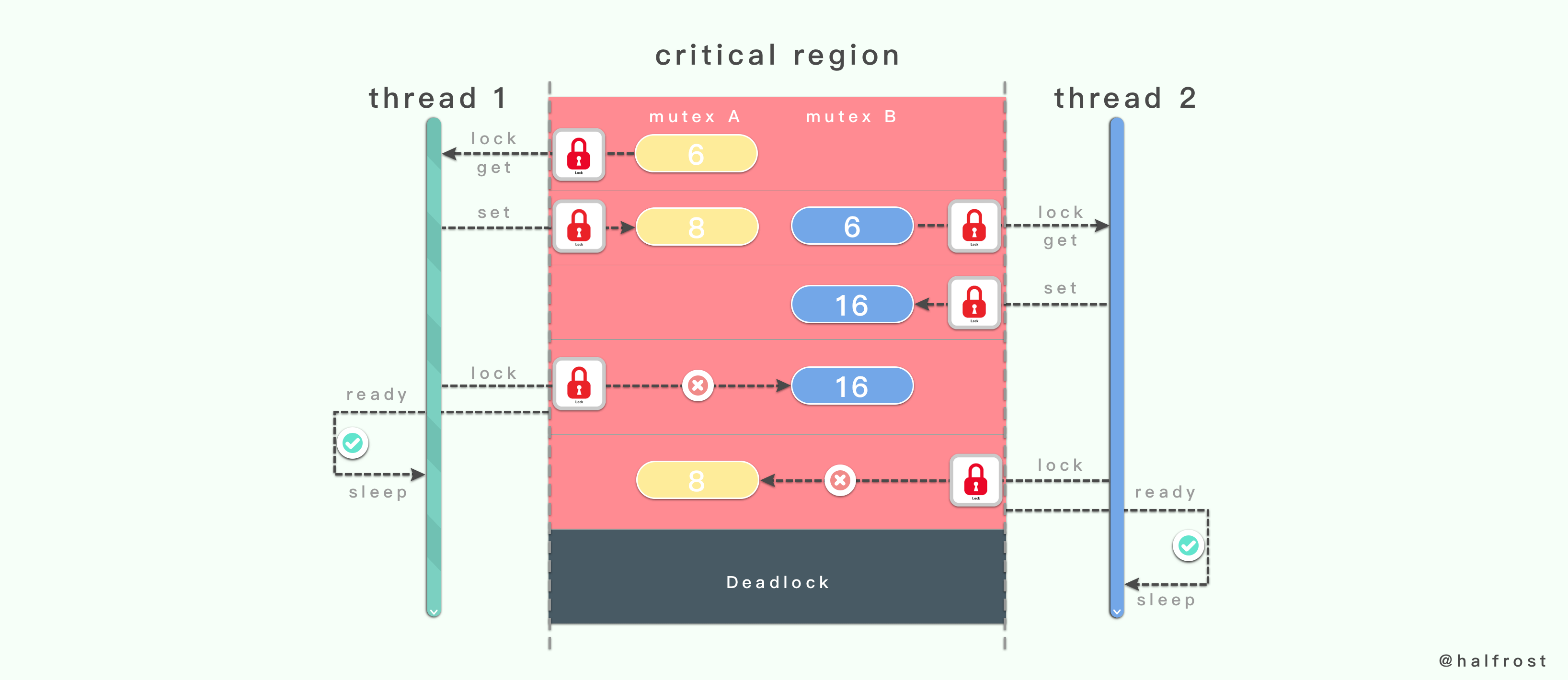
上图这个例子中,一个临界区中存在 2 个互斥量:互斥量 A 和互斥量
B。
线程 1 先锁定了互斥量 A ,接着线程 2 锁定了互斥量 B。当线程 1 在成功锁定互斥量 B 之前永远不会释放互斥量 A。同样,线程 2 在成功锁定互斥量 A 之前永远不会释放互斥量 B。那么这个时候线程 1 和线程 2 都因无法锁定自己需要锁定的互斥量,都由 ready 就绪状态转换为 sleep 睡眠状态。这是就产生了线程死锁了。
线程死锁的产生原因有以下几种:
- 系统资源竞争
- 进程推荐顺序非法
- 死锁必要条件(必要条件中任意一个不满足,死锁都不会发生)
(1). 互斥条件
(2). 不剥夺条件
(3). 请求和保持条件
(4). 循环等待条件
- 死锁必要条件(必要条件中任意一个不满足,死锁都不会发生)
想避免线程死锁的情况发生有以下几种方法可以解决:
- 预防死锁
(1). 资源有序分配法(破坏环路等待条件)
(2). 资源原子分配法(破坏请求和保持条件)
- 预防死锁
- 避免死锁
银行家算法
- 避免死锁
- 检测死锁
死锁定理(资源分配图化简法),这种方法虽然可以检测,但是无法预防,检测出来了死锁还需要配合解除死锁的方法才行。
- 检测死锁
彻底解决死锁有以下几种方法:
- 剥夺资源
- 撤销进程
- 试锁定 — 回退
如果在执行一个代码块的时候,需要先后(顺序不定)锁定两个变量,那么在成功锁定其中一个互斥量之后应该使用试锁定的方法来锁定另外一个变量。如果试锁定第二个互斥量失败,就把已经锁定的第一个互斥量解锁,并重新对这两个互斥量进行锁定和试锁定。
- 试锁定 — 回退
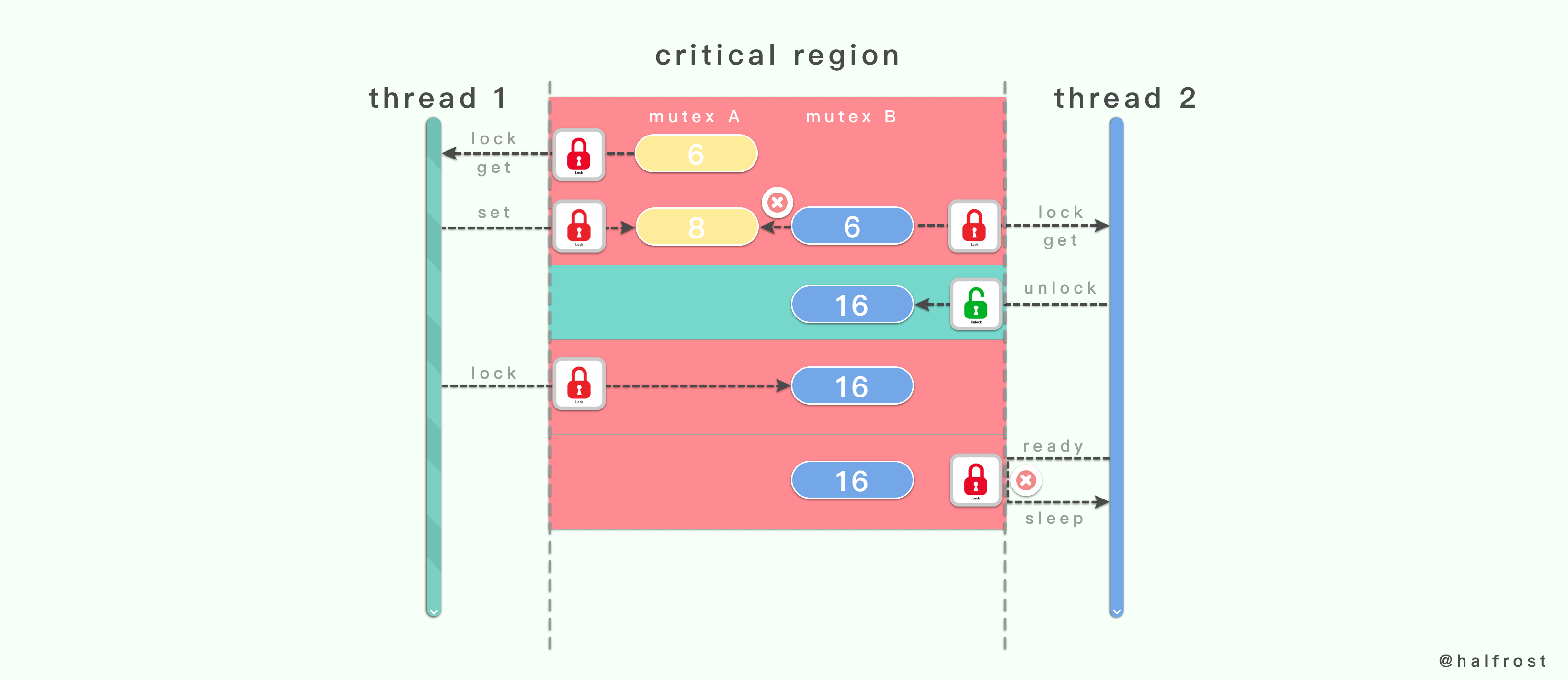
如上图,线程 2 在锁定互斥量 B 的时候,再试锁定互斥量 A,此时锁定失败,于是就把互斥量 B 也一起解锁。接着线程 1 会来锁定互斥量 A。此时也不会出现死锁的情况。
- 固定顺序锁定
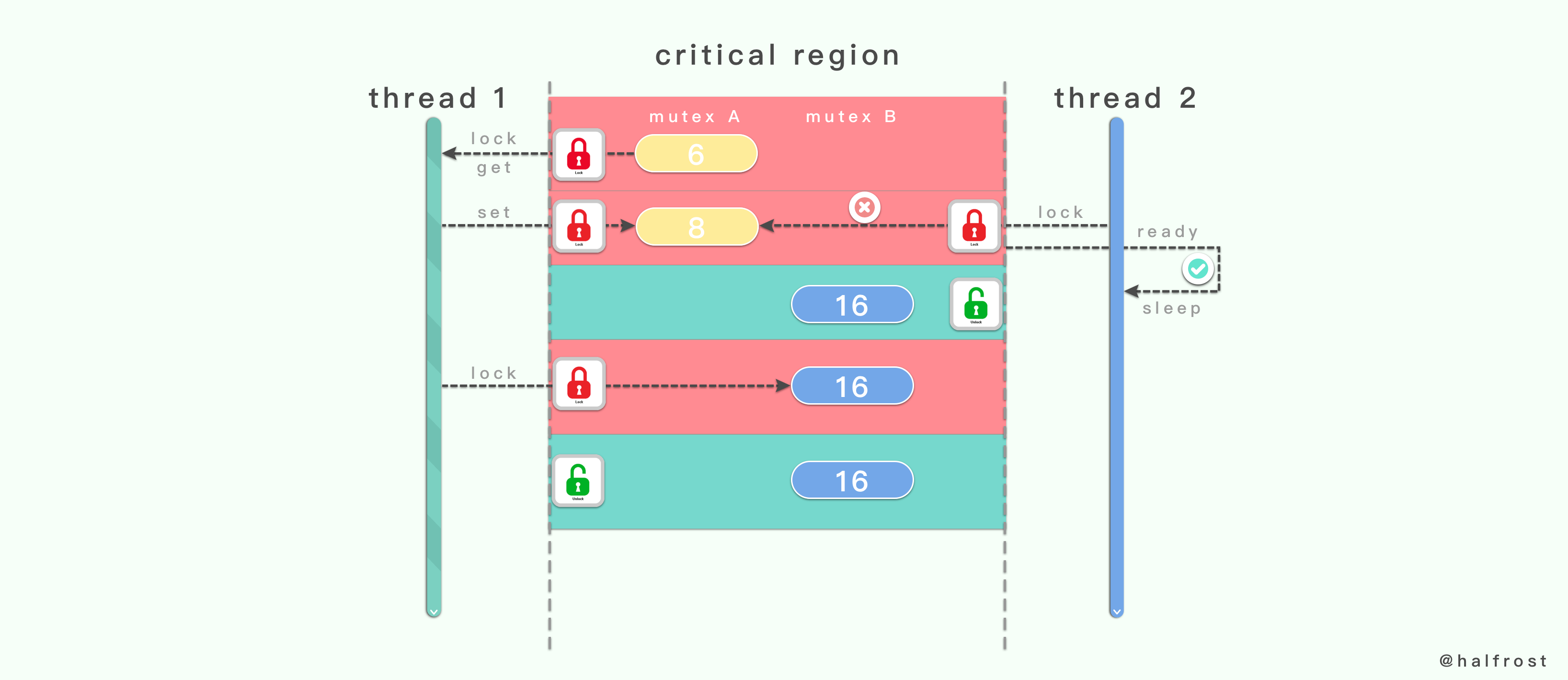
这种方式就是让线程 1 和线程 2 都按照相同的顺序锁定互斥量,都按成功锁定互斥量 1 以后才能去锁定互斥量 2 。这样就能保证在一个线程完全离开这些重叠的临界区之前,不会有其他同样需要锁定那些互斥量的线程进入到那里。
(三) 多个互斥量和多个临界区
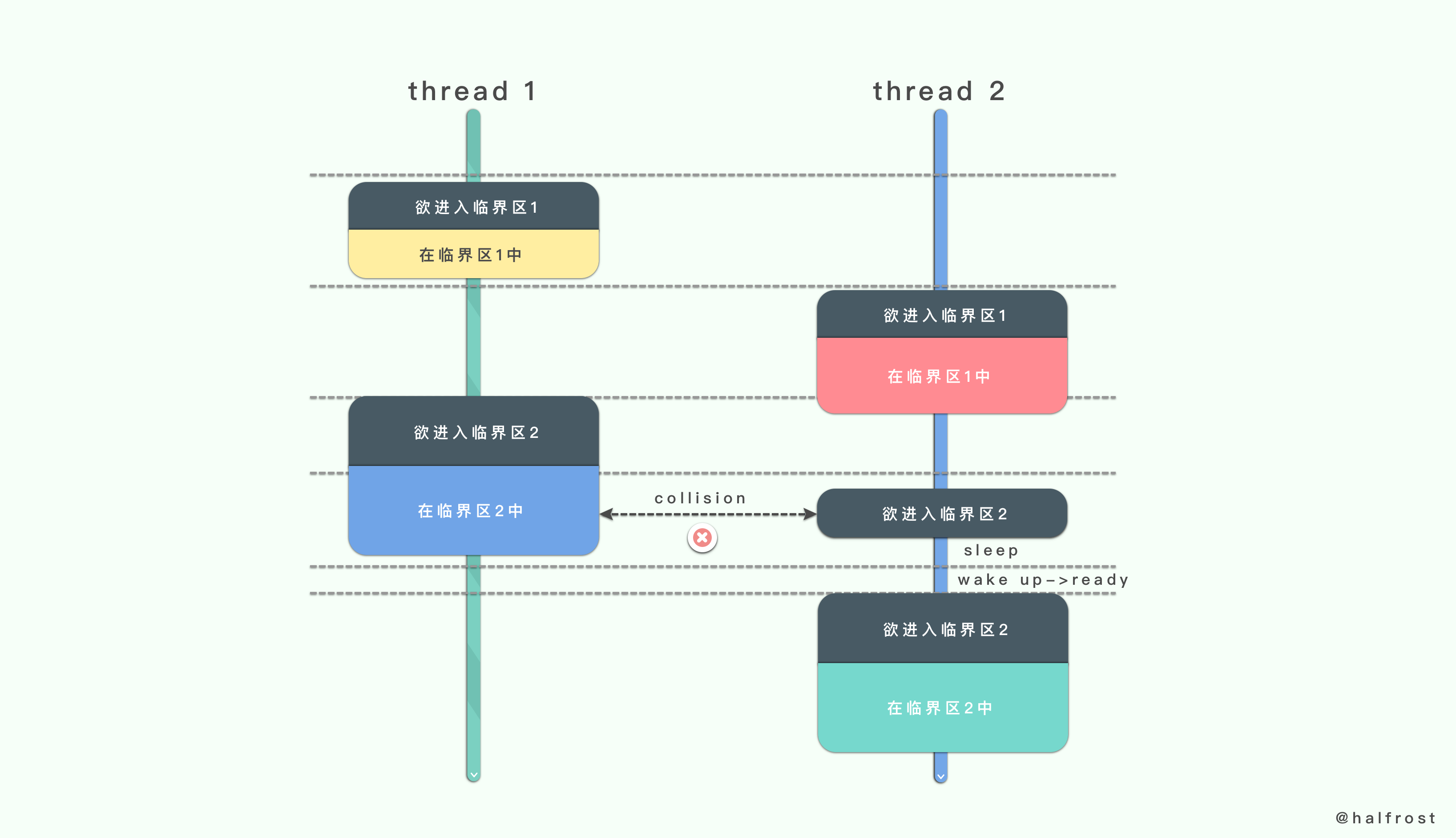
多个临界区和多个互斥量的情况就要看是否会有冲突的区域,如果出现相互交集的冲突区域,后进临界区的线程就会进入睡眠状态,直到该临界区的线程完成任务以后,再被唤醒。
一般情况下,应该尽量少的使用互斥量。每个互斥量保护的临界区应该在合理范围内并尽量大。但是如果发现多个线程会频繁出入某个较大的临界区,并且它们之间经常存在访问冲突,那么就应该把这个较大的临界区划分的更小一点,并使用不同的互斥量保护起来。这样做的目的就是为了让等待进入同一个临界区的线程数变少,从而降低线程被阻塞的概率,并减少它们被迫进入睡眠状态的时间,这从一定程度上提高了程序的整体性能。
在说另外一个线程同步的方法之前,回答一下文章开头留下的一个疑问:可重入只是线程安全的充分不必要条件,并不是充要条件。这个反例在下面会讲到。
这个问题最关键的一点在于:mutex 是不可重入的。
举个例子:
在下面这段代码中,函数 increment_counter 是线程安全的,但不是可重入的。
#include <pthread.h>int increment_counter (){static int counter = 0;static pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;pthread_mutex_lock(&mutex);++counter;int result = counter;pthread_mutex_unlock(&mutex);return result;}
上面的代码中,函数 increment_counter 可以在多个线程中被调用,因为有一个互斥锁 mutex 来同步对共享变量 counter 的访问。但是如果这个函数用在可重入的中断处理程序中,如果在
pthread_mutex_lock(&mutex) 和
pthread_mutex_unlock(&mutex) 之间产生另一个调用函数 increment_counter 的中断,则会第二次执行此函数,此时由于 mutex 已被 lock,函数会在 pthread_mutex_lock(&mutex) 处阻塞,并且由于 mutex 没有机会被 unlock,阻塞会永远持续下去。简言之,问题在于 pthread 的 mutex 是不可重入的。
解决办法是设定 PTHREADMUTEX_RECURSIVE 属性。然而对于给出的问题而言,专门使用一个 mutex 来保护一次简单的增量操作显然过于昂贵,因此 c++11 中的 [原子变量](https://zh.wikipedia.org/w/index.php?title=Atomic(C%2B%2B%E6%A0%87%E5%87%86%E5%BA%93)&action=edit&redlink=1) 提供了一个可使此函数既线程安全又可重入(而且还更简洁)的替代方案:
#include <atomic>int increment_counter (){static std::atomic<int> counter(0);int result = ++counter;return result;}
在 Go 中,互斥量在标准库代码包 sync 中的 Mutex 结构体表示的。sync.Mutex 类型只有两个公开的指针方法,Lock 和 Unlock。前者用于锁定当前的互斥量,后者则用于对当前的互斥量进行解锁。
2. 条件变量
在线程同步的方法中,还有一个可以与互斥量相提并论的同步方法,条件变量。
条件变量与互斥量不同,条件变量的作用并不是保证在同一时刻仅有一个线程访问某一个共享数据,而是在对应的共享数据的状态发生变化时,通知其他因此而被阻塞的线程。条件变量总是与互斥变量组合使用的。
这类问题其实很常见。先用生产者消费者的例子来举例。
如果不用条件变量,只用互斥量,来看看会发生什么后果。
生产者线程在完成添加操作之前,其他的生产者线程和消费者线程都无法进行操作。同一个商品也只能被一个消费者消费。
如果只用互斥量,可能会出现 2 个问题。
- 生产者线程获得了互斥量以后,却发现商品已满,无法再添加新的商品了。于是该线程就会一直等待。新的生产者也进入不了临界区,消费者也无法进入。这时候就死锁了。
- 消费者线程获得了互斥量以后,却发现商品是空的,无法消费了。这个时候该线程也是会一直等待。新的生产者和消费者也都无法进入。这时候同样也死锁了。
这就是只用互斥量无法解决的问题。在多个线程之间,急需一套同步的机制,能让这些线程都协作起来。
条件变量就是大家熟悉的 P - V 操作了。这块大家应该比较熟悉,所以简单的过一下。
P 操作就是 wait 操作,它的意思就是阻塞当前线程,直到收到该条件变量发来的通知。
V 操作就是 signal 操作,它的意思就是让该条件变量向至少一个正在等待它通知的线程发送通知,以表示某个共享数据的状态已经变化。
Broadcast 广播通知,它的意思就是让条件变量给正在等待它通知的所有线程发送通知,以表示某个共享数据的状态已经发生改变。
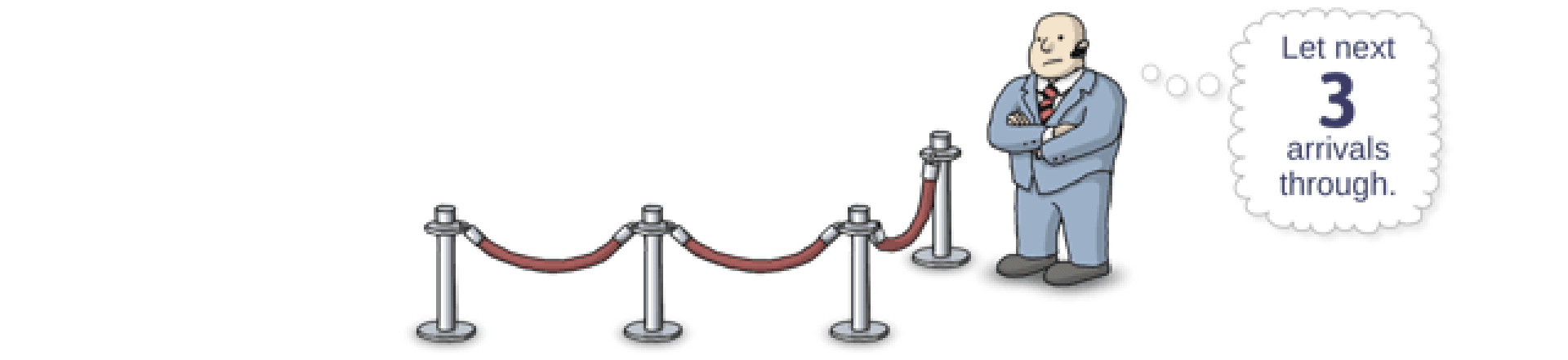
signal 可以操作多次,如果操作 3 次,就代表发了 3 次信号通知。如上图。
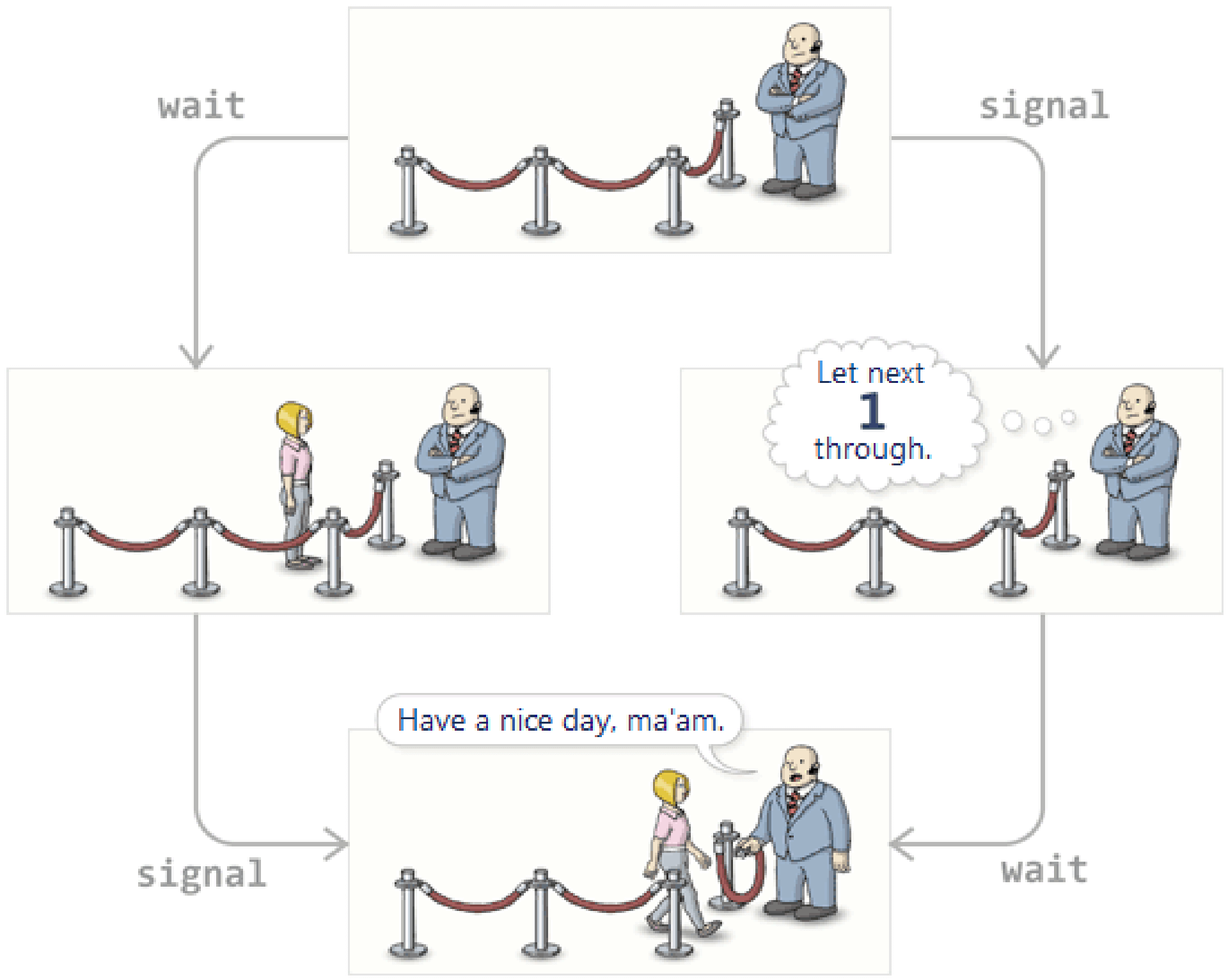
P - V 操作设计美妙之处在于,P 操作的次数与 V 操作的次数是相同的。wait 多少次,signal 对应的有多少次。看上图,这个循环就是这么的奇妙。
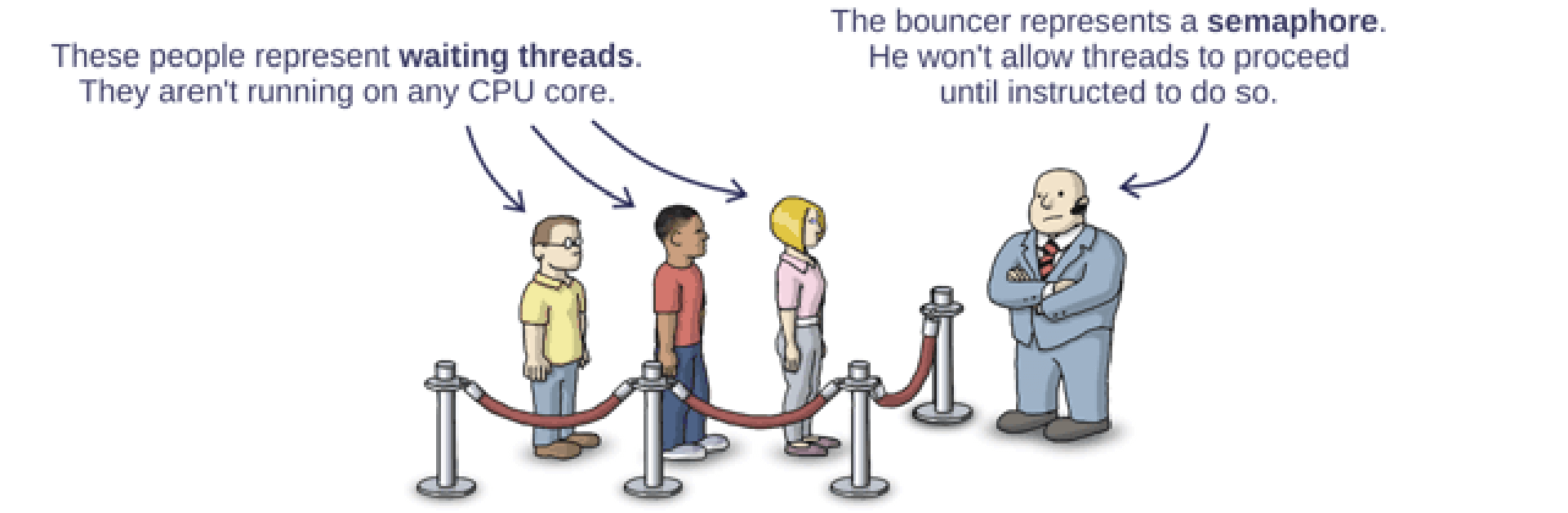
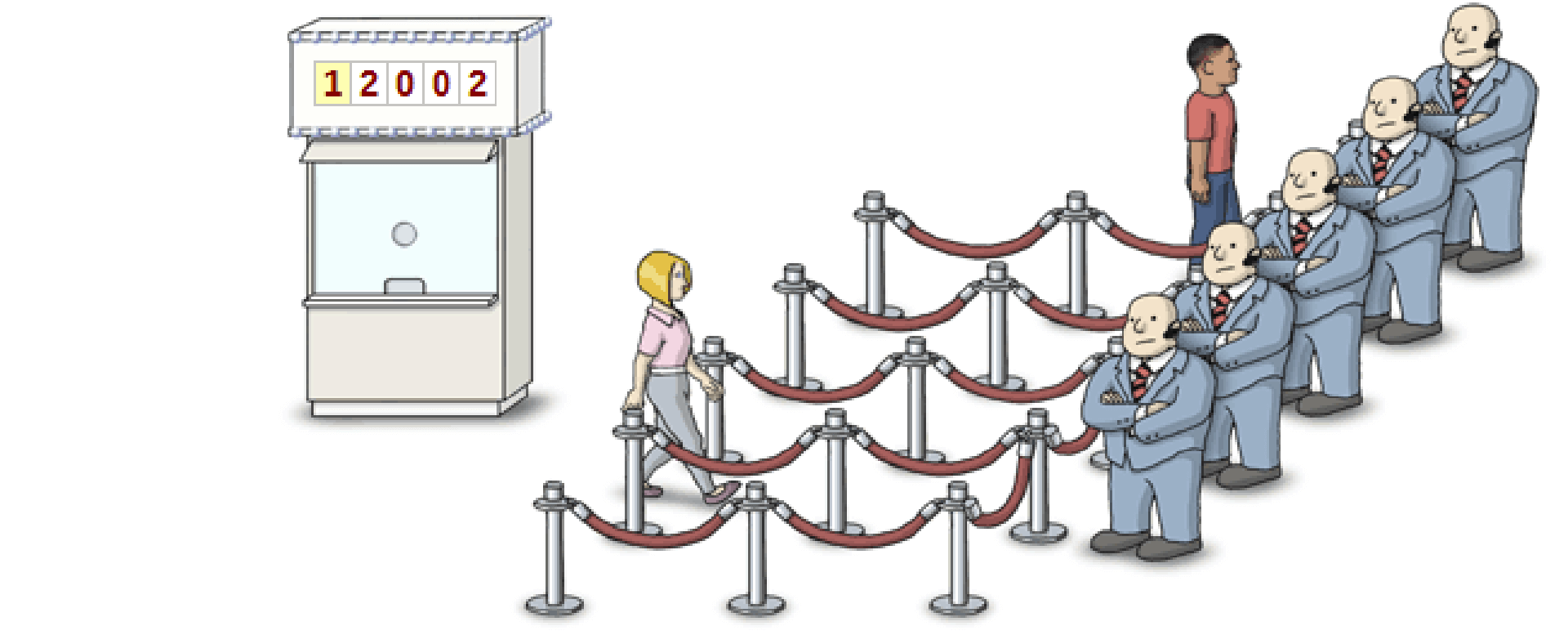
生产者消费者问题
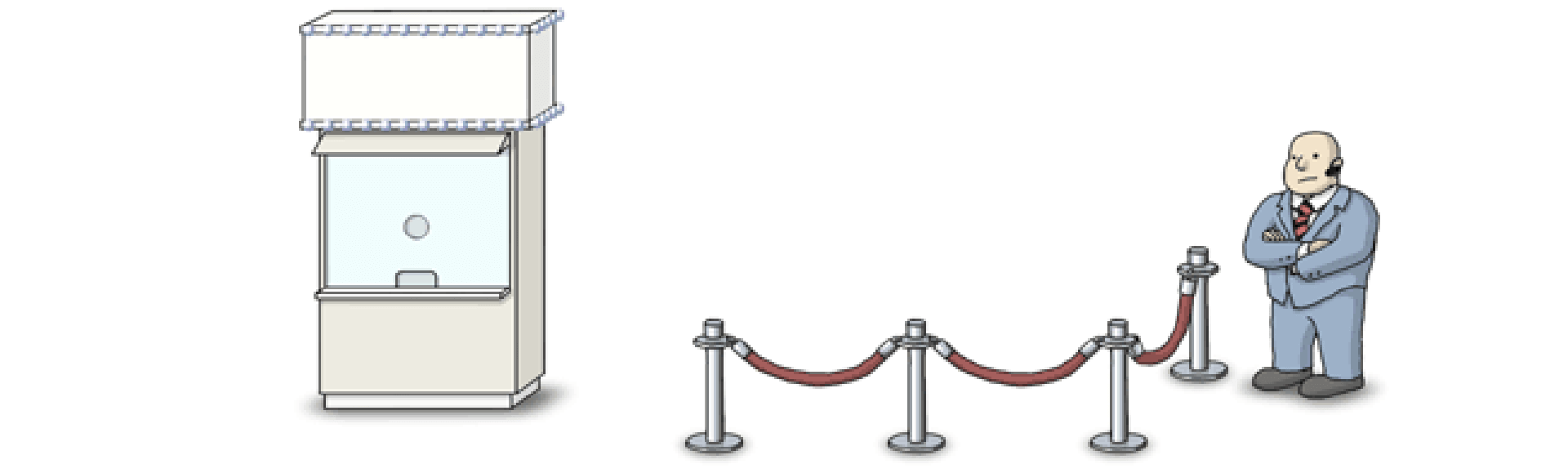
这个问题可以形象的描述成像上图这样,门卫守护着临界区的安全。售票厅记录着当前 semaphone 的值,它也控制着门卫是否打开临界区。
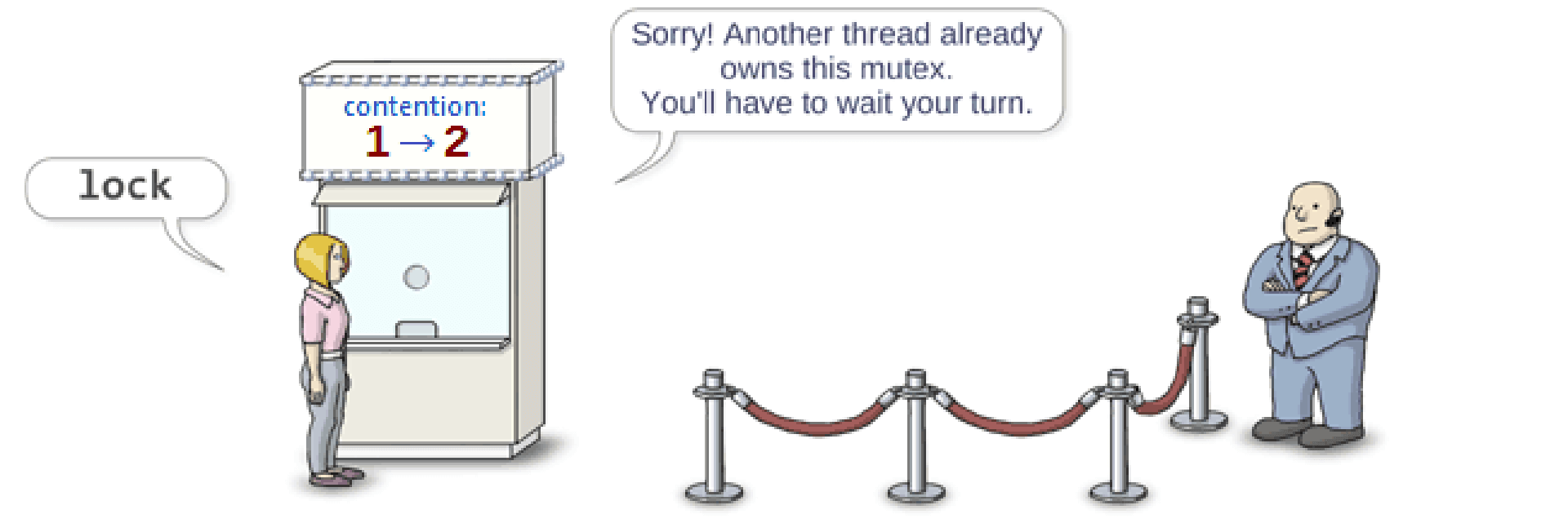
临界区只允许一个线程进入,当已经有一个线程了,再来一个线程,就会被 lock 住。售票厅也会记录当前阻塞的线程数。
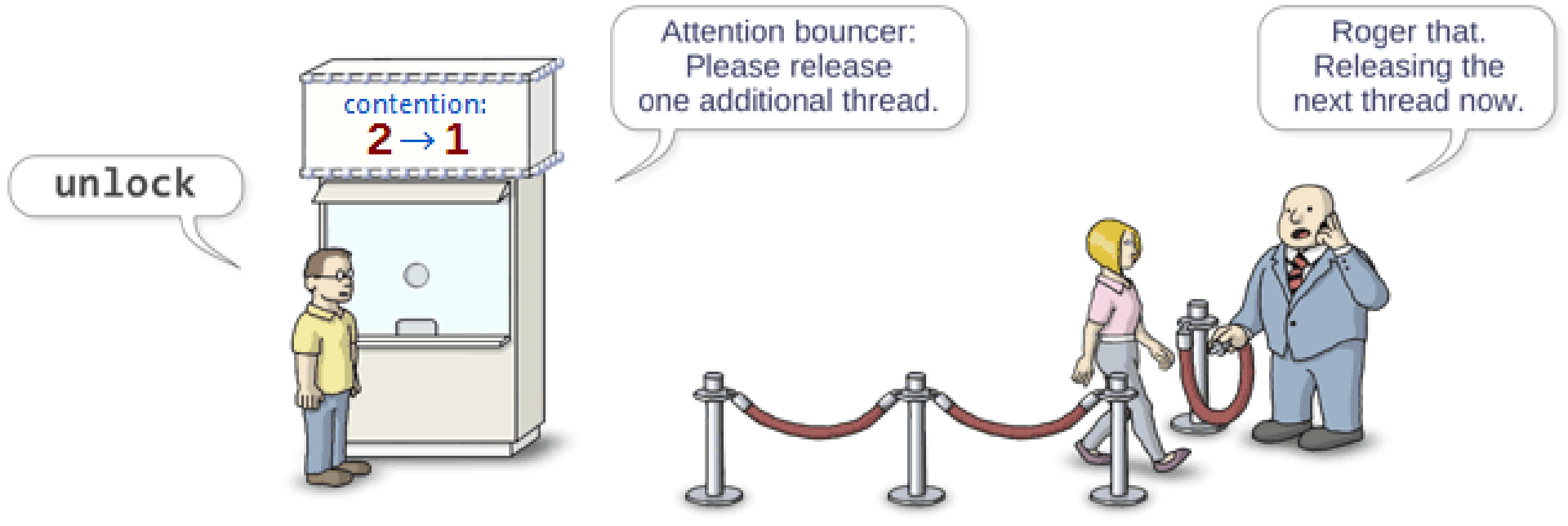
当之前的线程离开以后,售票厅就会告诉门卫,允许一个线程进入临界区。
用 P-V 伪代码来描述生产者消费者:
初始变量:
semaphore mutex = 1;semaphore empty = n;semaphore full = 0;
生产者线程:
producer(){while(1) {produce an item in nextp;P(empty);P(mutex);add nextp to buffer;V(mutex);V(full);}}
消费者线程:
consumer(){while(1) {P(full);P(mutex);remove an item from buffer;V(mutex);V(empty);consume the item;}}
虽然在生产者和消费者单个程序里面 P,V 并不是成对的,但是整个程序里面 P,V 还是成对的。
读者写者问题——读者优先,写者延迟
读者优先,写进程被延迟。只要有读者在读,后来的读者都可以随意进来读。
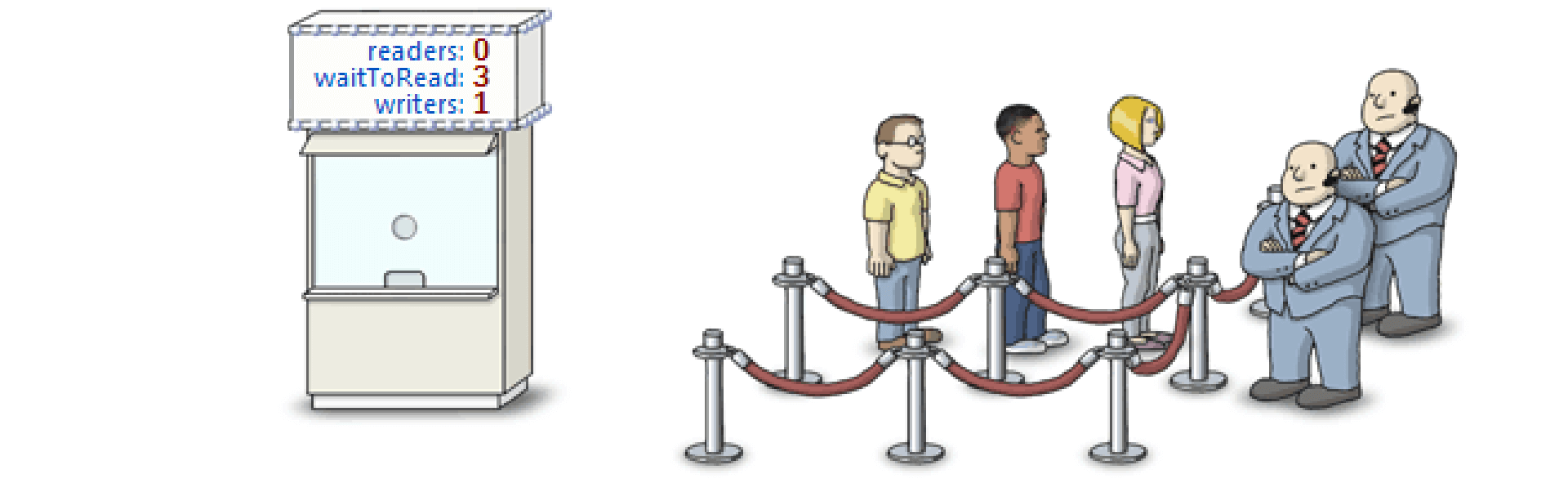
读者要先进入 rmutex ,查看 readcount,然后修改 readcout 的值,最后再去读数据。对于每个读进程都是写者,都要进去修改 readcount 的值,所以还要单独设置一个 rmutex 互斥访问。
初始变量:
int readcount = 0;semaphore rmutex = 1;semaphore wmutex = 1;
读者线程:
reader(){while(1) {P(rmutex);if(readcount == 0) {P(wmutex);}readcount ++;V(rmutex);reading;P(rmutex);readcount --;if(readcount == 0) {V(wmutex);}V(rmutex);}}
写者线程:
writer(){while(1) {P(wmutex);writing;V(wmutex);}}
读者写者问题——写者优先,读者延迟
有写者写,禁止后面的读者来读。在写者前的读者,读完就走。只要有写者在等待,禁止后来的读者进去读。
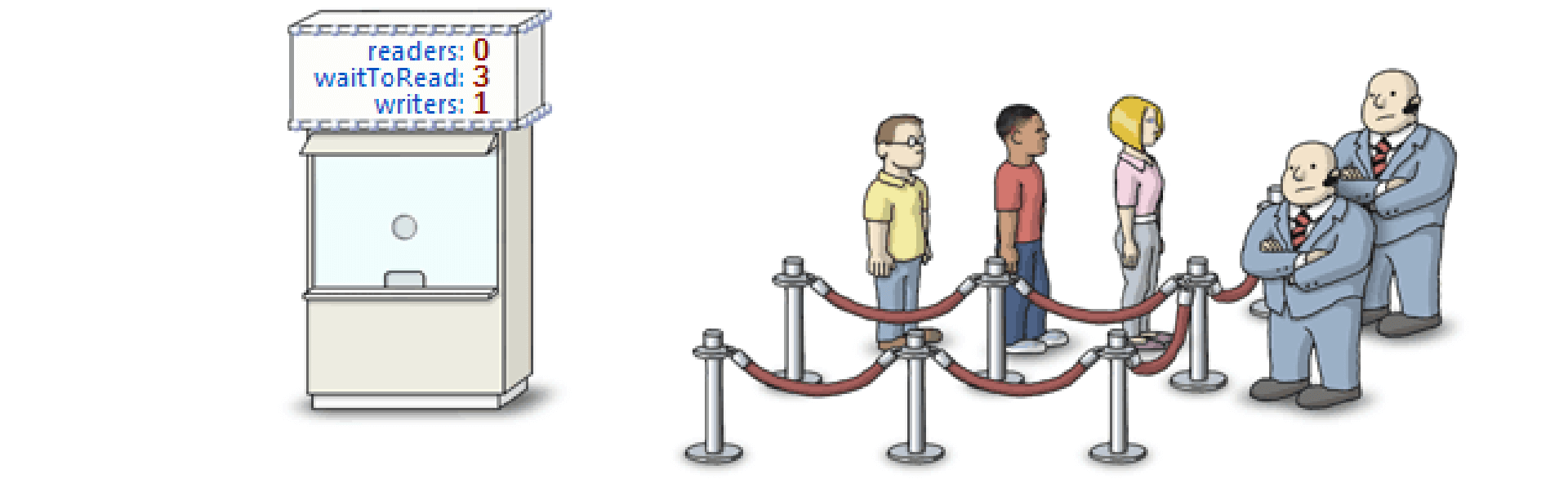
初始变量:
int readcount = 0;semaphore rmutex = 1;semaphore wmutex = 1;semaphore w = 1;
读者线程:
reader(){while(1) {P(w);P(rmutex);if(readcount == 0) {P(wmutex);}readcount ++;V(rmutex);V(w);reading;P(rmutex);readcount --;if(readcount == 0) {V(wmutex);}V(rmutex);}}
写者线程:
writer(){while(1) {P(w);P(wmutex);writing;V(wmutex);V(w);}}
哲学家进餐问题
假设有五位哲学家围坐在一张圆形餐桌旁,做以下两件事情之一:吃饭,或者思考。吃东西的时候,他们就停止思考,思考的时候也停止吃东西。餐桌中间有一大碗意大利面,每两个哲学家之间有一只餐叉。因为用一只餐叉很难吃到意大利面,所以假设哲学家必须用两只餐叉吃东西。他们只能使用自己左右手边的那两只餐叉。哲学家就餐问题有时也用米饭和筷子而不是意大利面和餐叉来描述,因为很明显,吃米饭必须用两根筷子。
初始变量:
semaphore chopstick[5] = {1,1,1,1,1};semaphore mutex = 1;
哲学家线程:
Pi(){do {P(mutex);P(chopstick[i]);P(chopstick[ (i + 1) % 5 ]);V(mutex);eat;V(chopstick[i]);V(chopstick[ (i + 1) % 5 ]);think;}while(1);}
综上所述,互斥量可以实现对临界区的保护,并会阻止竞态条件的发生。条件变量作为补充手段,可以让多方协作更加有效率。
在 Go 的标准库中,sync 包里面 sync.Cond 类型代表了条件变量。但是和互斥锁和读写锁不同的是,简单的声明无法创建出一个可用的条件变量,还需要用到 sync.NewCond 函数。
func NewCond( l locker) *Cond
*sync.Cond 类型的方法集合中有 3 个方法,即 Wait、Signal 和 Broadcast 。
二. 简单的线程锁方案
实现线程安全的方案最简单的方法就是加锁了。
先看看 OC 中如何实现一个线程安全的字典吧。
在 Weex 的源码中,就实现了一套线程安全的字典。类名叫 WXThreadSafeMutableDictionary。
@interface WXThreadSafeMutableDictionary<KeyType, ObjectType> : NSMutableDictionary@property (nonatomic, strong) dispatch_queue_t queue;@property (nonatomic, strong) NSMutableDictionary* dict;@end
具体实现如下:
- (instancetype)initCommon{self = [super init];if (self) {NSString* uuid = [NSString stringWithFormat:@"com.taobao.weex.dictionary_%p", self];_queue = dispatch_queue_create([uuid UTF8String], DISPATCH_QUEUE_CONCURRENT);}return self;}
该线程安全的字典初始化的时候会新建一个并发的 queue。
- (NSUInteger)count{__block NSUInteger count;dispatch_sync(_queue, ^{count = _dict.count;});return count;}- (id)objectForKey:(id)aKey{__block id obj;dispatch_sync(_queue, ^{obj = _dict[aKey];});return obj;}- (NSEnumerator *)keyEnumerator{__block NSEnumerator *enu;dispatch_sync(_queue, ^{enu = [_dict keyEnumerator];});return enu;}- (id)copy{__block id copyInstance;dispatch_sync(_queue, ^{copyInstance = [_dict copy];});return copyInstance;}
读取的这些方法都用 dispatch_sync 。
- (void)setObject:(id)anObject forKey:(id<NSCopying>)aKey{aKey = [aKey copyWithZone:NULL];dispatch_barrier_async(_queue, ^{_dict[aKey] = anObject;});}- (void)removeObjectForKey:(id)aKey{dispatch_barrier_async(_queue, ^{[_dict removeObjectForKey:aKey];});}- (void)removeAllObjects{dispatch_barrier_async(_queue, ^{[_dict removeAllObjects];});}
和写入相关的方法都用 dispatch_barrier_async。
再看看 Go 用互斥量如何实现一个简单的线程安全的 Map 吧。
既然要用到互斥量,那么我们封装一个包含互斥量的 Map 。
type MyMap struct {sync.Mutexm map[int]int}var myMap *MyMapfunc init() {myMap = &MyMap{m: make(map[int]int, 100),}}
再简单的实现 Map 的基础方法。
func builtinMapStore(k, v int) {myMap.Lock()defer myMap.Unlock()myMap.m[k] = v}func builtinMapLookup(k int) int {myMap.Lock()defer myMap.Unlock()if v, ok := myMap.m[k]; !ok {return -1} else {return v}}func builtinMapDelete(k int) {myMap.Lock()defer myMap.Unlock()if _, ok := myMap.m[k]; !ok {return} else {delete(myMap.m, k)}}
实现思想比较简单,在每个操作前都加上 lock,在每个函数结束 defer 的时候都加上 unlock。
这种加锁的方式实现的线程安全的字典,优点是比较简单,缺点是性能不高。文章最后会进行几种实现方法的性能对比,用数字说话,就知道这种基于互斥量加锁方式实现的性能有多差了。
在语言原生就自带线程安全 Map 的语言中,它们的原生底层实现都不是通过单纯的加锁来实现线程安全的,比如 Java 的 ConcurrentHashMap,Go 1.9 新加的 sync.map。
三. 现代线程安全的 Lock - Free 方案 CAS
在 Java 的 ConcurrentHashMap 底层实现中大量的利用了 volatile,final,CAS 等 Lock-Free 技术来减少锁竞争对于性能的影响。
在 Go 中也大量的使用了原子操作,CAS 是其中之一。比较并交换即 “Compare And Swap”,简称 CAS。
func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool)func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool)func CompareAndSwapUint32(addr *uint32, old, new uint32) (swapped bool)func CompareAndSwapUint64(addr *uint64, old, new uint64) (swapped bool)func CompareAndSwapUintptr(addr *uintptr, old, new uintptr) (swapped bool)func CompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer) (swapped bool)
CAS 会先判断参数 addr 指向的被操作值与参数 old 的值是否相等。如果相当,相应的函数才会用参数 new 代表的新值替换旧值。否则,替换操作就会被忽略。
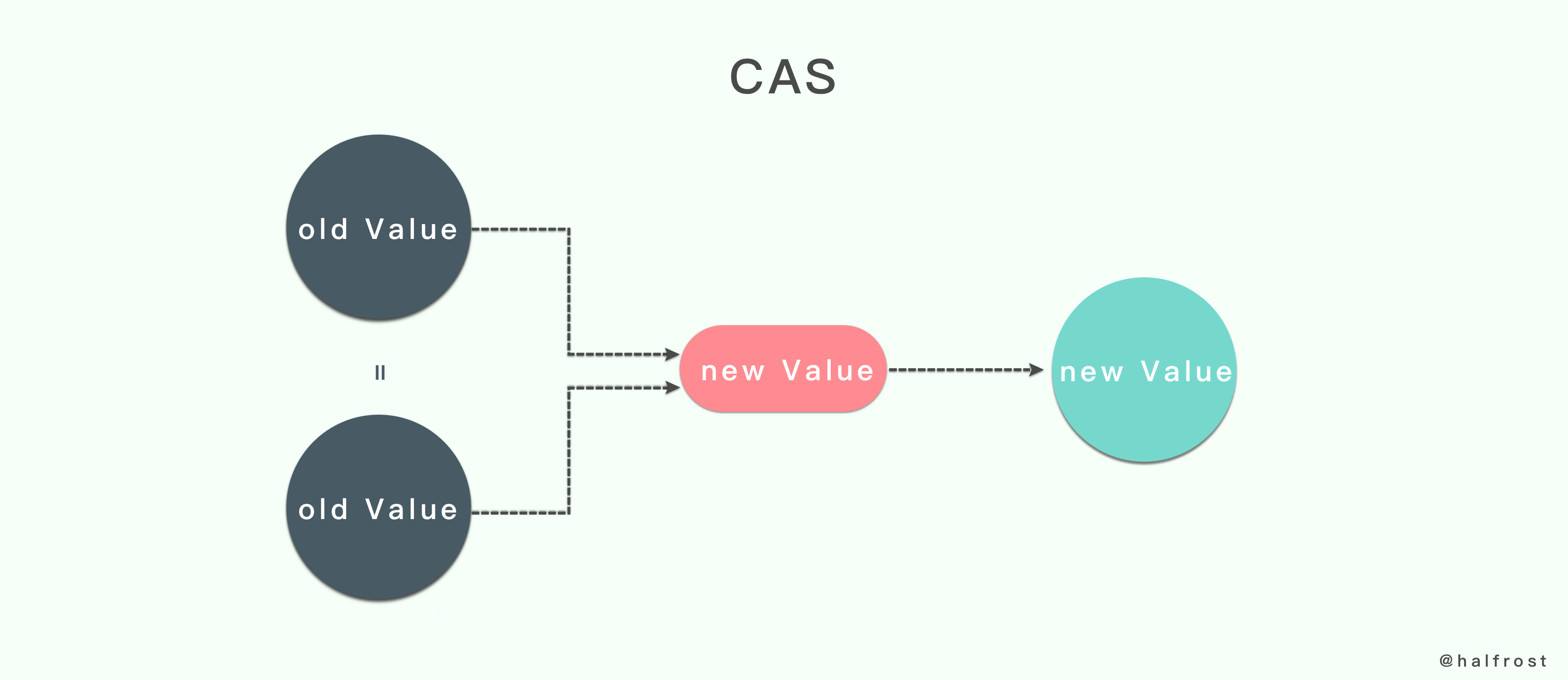
这一点与互斥锁明显不同,CAS 总是假设被操作的值未曾改变,并一旦确认这个假设成立,就立即进行值的替换。而互斥锁的做法就更加谨慎,总是先假设会有并发的操作修改被操作的值,并需要使用锁将相关操作放入临界区中加以保护。可以说互斥锁的做法趋于悲观,CAS 的做法趋于乐观,类似乐观锁。
CAS 做法最大的优势在于可以不创建互斥量和临界区的情况下,完成并发安全的值替换操作。这样大大的减少了线程同步操作对程序性能的影响。当然 CAS 也有一些缺点,缺点下一章会提到。
接下来看看源码是如何实现的。以下以 64 位为例,32 位类似。
TEXT ·CompareAndSwapUintptr(SB),NOSPLIT,$0-25JMP ·CompareAndSwapUint64(SB)TEXT ·CompareAndSwapInt64(SB),NOSPLIT,$0-25JMP ·CompareAndSwapUint64(SB)TEXT ·CompareAndSwapUint64(SB),NOSPLIT,$0-25MOVQ addr+0(FP), BPMOVQ old+8(FP), AXMOVQ new+16(FP), CXLOCKCMPXCHGQ CX, 0(BP)SETEQ swapped+24(FP)RET
上述实现最关键的一步就是 CMPXCHG。
查询 Intel 的文档

文档上说:
比较 eax 和目的操作数 (第一个操作数) 的值,如果相同,ZF 标志被设置,同时源操作数 (第二个操作) 的值被写到目的操作数,否则,清
ZF 标志,并且把目的操作数的值写回 eax。
于是也就得出了 CMPXCHG 的工作原理:
比较 _old 和 (__ptr) 的值,如果相同,ZF 标志被设置,同时
_new 的值被写到 (ptr),否则,清 ZF 标志,并且把 (*ptr) 的值写回 _old。
在 Intel 平台下,会用 LOCK CMPXCHG 来实现,这里的 LOCK 是 CPU 锁。
Intel 的手册对 LOCK 前缀的说明如下:
- 确保对内存的读 - 改 - 写操作原子执行。在 Pentium 及 Pentium 之前的处理器中,带有 LOCK 前缀的指令在执行期间会锁住总线,使得其他处理器暂时无法通过总线访问内存。很显然,这会带来昂贵的开销。从 Pentium 4,Intel Xeon 及 P6 处理器开始,Intel 在原有总线锁的基础上做了一个很有意义的优化:如果要访问的内存区域(area of memory)在 LOCK 前缀指令执行期间已经在处理器内部的缓存中被锁定(即包含该内存区域的缓存行当前处于独占或以修改状态),并且该内存区域被完全包含在单个缓存行(cache line)中,那么处理器将直接执行该指令。由于在指令执行期间该缓存行会一直被锁定,其它处理器无法读 / 写该指令要访问的内存区域,因此能保证指令执行的原子性。这个操作过程叫做缓存锁定(cache locking),缓存锁定将大大降低 LOCK 前缀指令的执行开销,但是当多处理器之间的竞争程度很高或者指令访问的内存地址未对齐时,仍然会锁住总线。
- 禁止该指令与之前和之后的读和写指令重排序。
- 把写缓冲区中的所有数据刷新到内存中。
看完描述,可以看出,CPU 锁主要分两种,总线锁和缓存锁。总线锁用在老的 CPU 中,缓存锁用在新的 CPU 中。
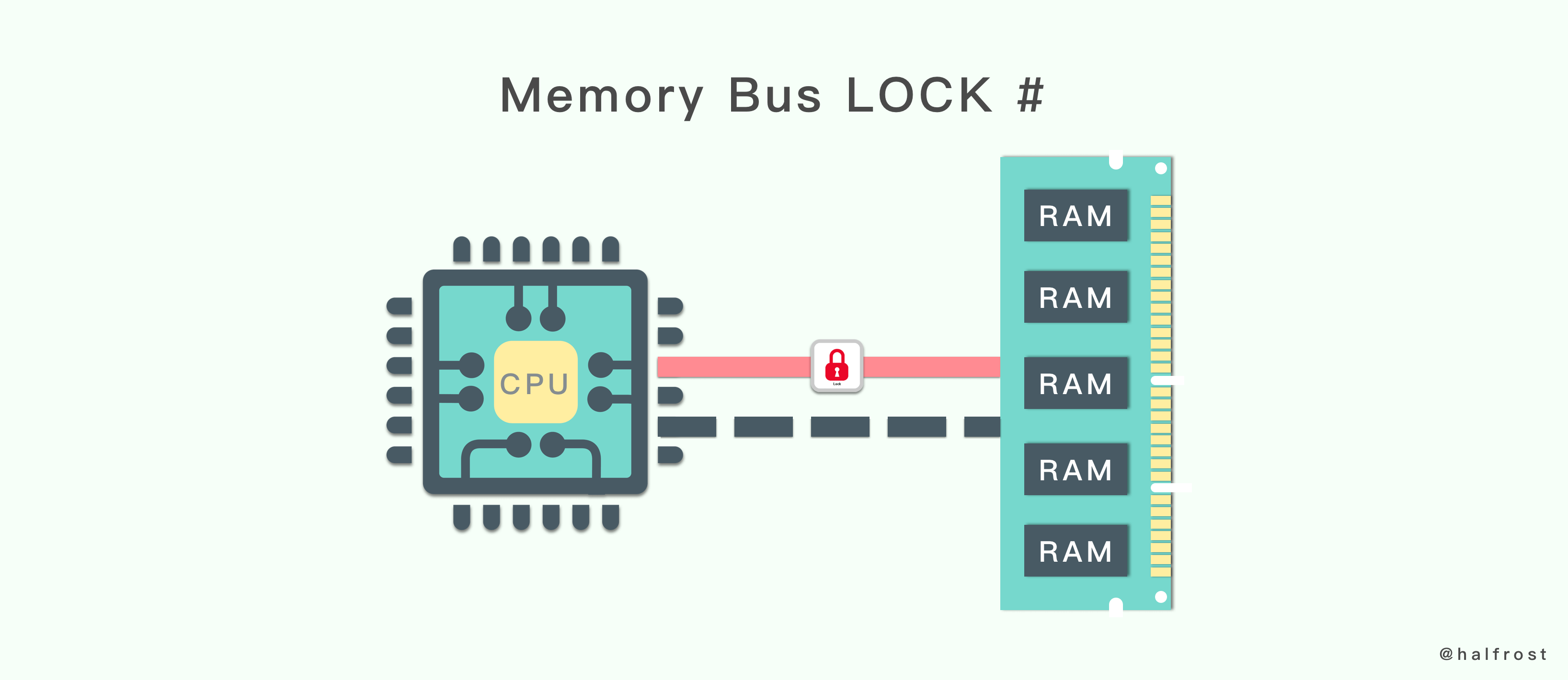
所谓总线锁就是使用 CPU 提供的一个 LOCK#信号,当一个处理器在总线上输出此信号时,其他处理器的请求将被阻塞住,那么该 CPU 可以独占使用共享内存。总线锁的这种方式,在执行期间会锁住总线,使得其他处理器暂时无法通过总线访问内存。所以总线锁定的开销比较大,最新的处理器在某些场合下使用缓存锁定代替总线锁定来进行优化。
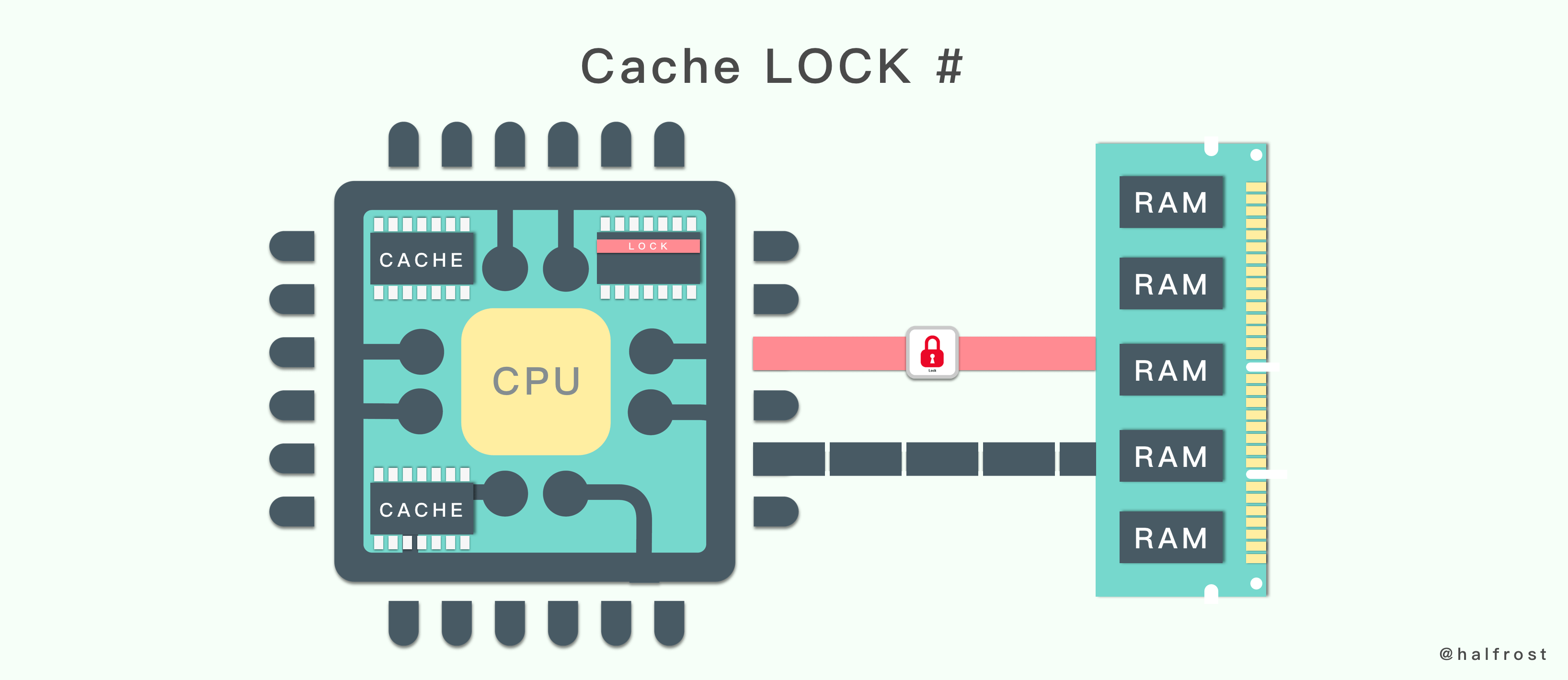
所谓缓存锁定就是如果缓存在处理器缓存行中内存区域在 LOCK 操作期间被锁定,当它执行锁操作回写内存时,处理器不在总线上产生
LOCK#信号,而是修改内部的内存地址,并允许它的缓存一致性机制来保证操作的原子性,因为缓存一致性机制会阻止同时修改被两个以上处理器缓存的内存区域数据,当其他处理器回写已被锁定的缓存行的数据时会对缓存行无效。
有两种情况处理器无法使用缓存锁。
- 第一种情况是,当操作的数据不能被缓存在处理器内部,或操作的数据跨多个缓存行(cache line),则处理器会调用总线锁定。
- 第二种情况是:有些处理器不支持缓存锁定。一些老的 CPU 就算锁定的内存区域在处理器的缓存行中也会调用总线锁定。
虽然缓存锁可以大大降低 CPU 锁的执行开销,但是如果遇到多处理器之间的竞争程度很高或者指令访问的内存地址未对齐时,仍然会锁住总线。所以缓存锁和总线锁相互配合,效果更佳。
综上,用 CAS 方式来保证线程安全的方式就比用互斥锁的方式效率要高很多。
四. CAS 的缺陷
虽然 CAS 的效率高,但是依旧存在 3 大问题。
1. ABA 问题
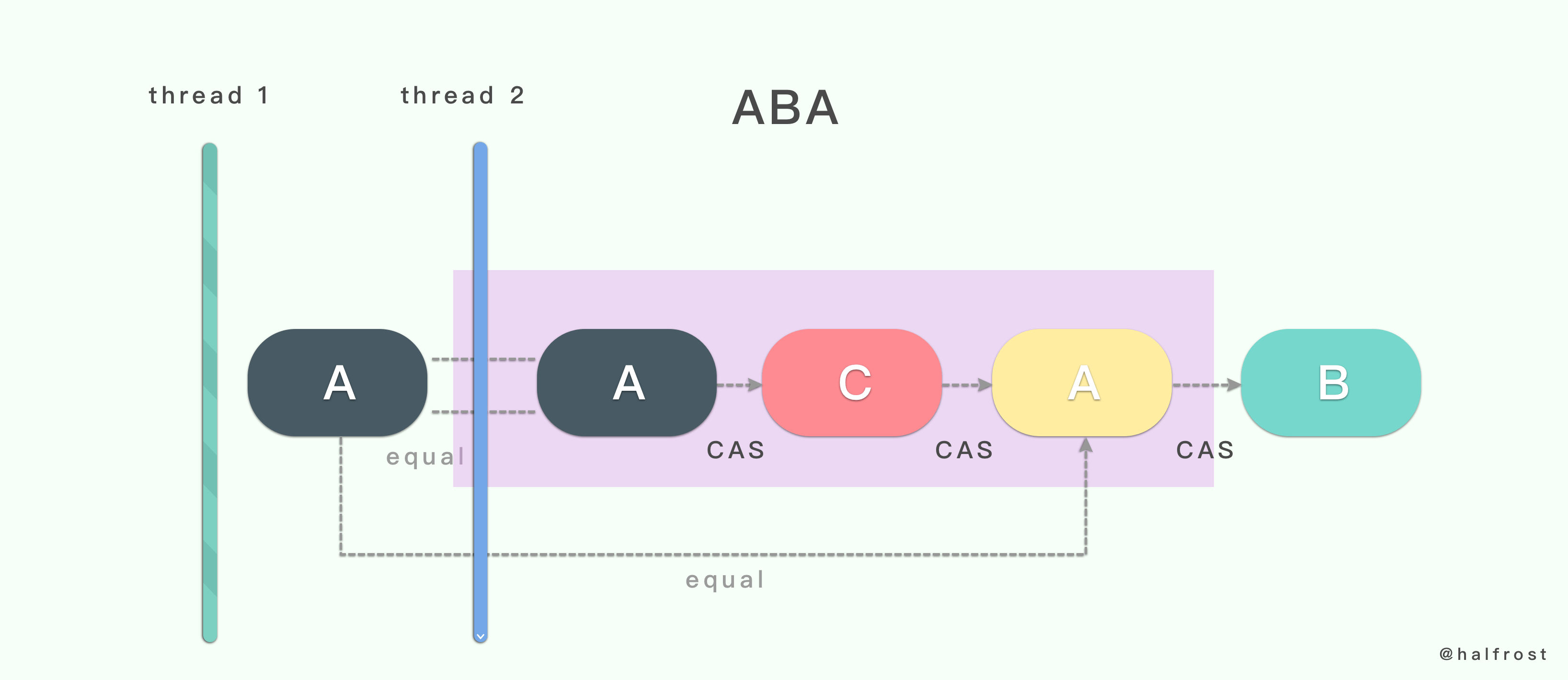
线程 1 准备用 CAS 将变量的值由 A 替换为 B ,在此之前,线程 2 将变量的值由 A 替换为 C ,又由 C 替换为 A,然后线程 1 执行 CAS 时发现变量的值仍然为 A,所以 CAS 成功。但实际上这时的现场已经和最初不同了。图上也为了分开两个 A 不同,所以用不同的颜色标记了。最终线程 2 把 A 替换成了 B 。这就是经典的 ABA 问题。但是这会导致项目出现什么问题呢?
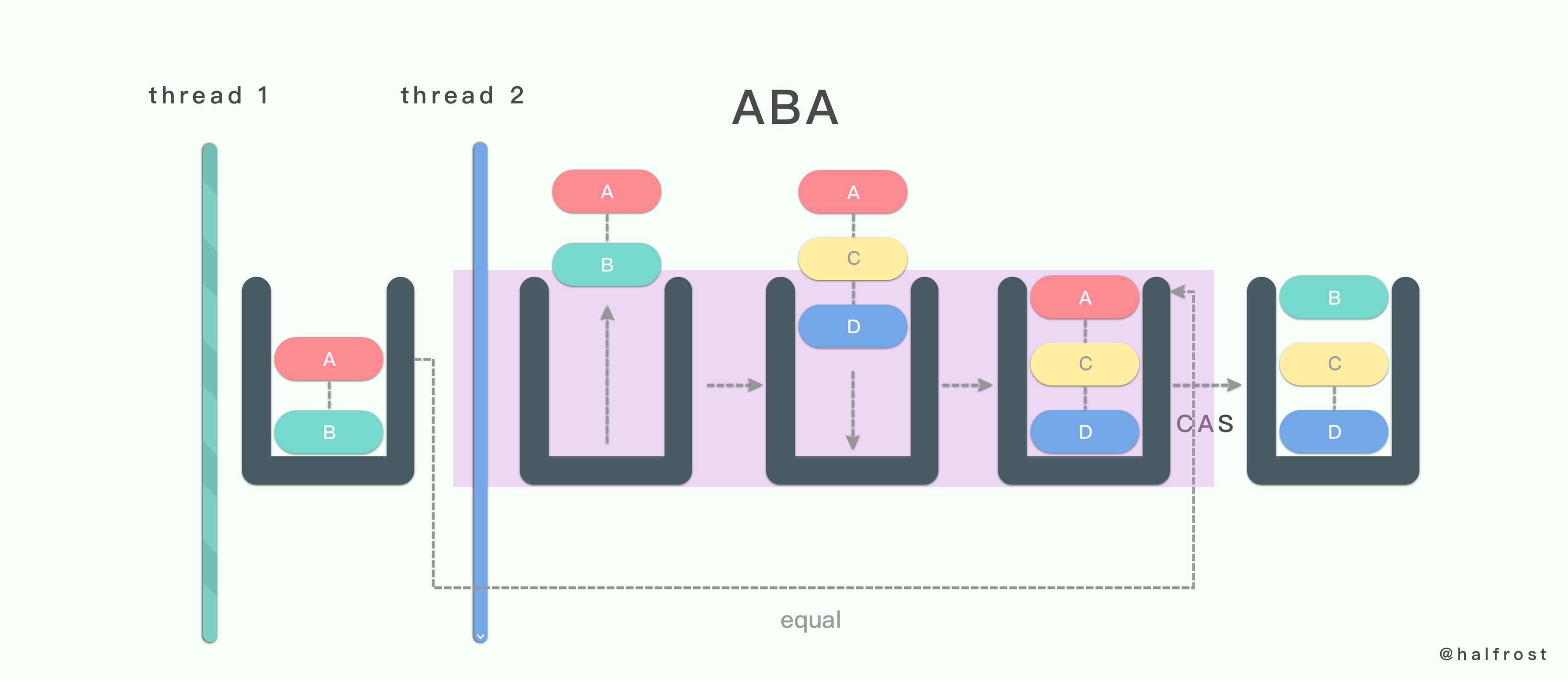
设想存在这样一个链栈,栈里面存储了一个链表,栈顶是 A,A 的 next 指针指向 B。在线程 1 中,要将栈顶元素 A 用 CAS 把它替换成 B。接着线程 2 来了,线程 2 将之前包含 A,B 元素的链表都 pop 出去。然后 push 进来一个 A - C - D 链表,栈顶元素依旧是 A。这时线程 1 发现 A 没有发生变化,于是替换成 B。这个时候 B 的 next 其实为 nil。替换完成以后,线程 2 操作的链表 C - D 这里就与表头断开连接了。也就是说线程 1 CAS 操作结束,C - D 就被丢失了,再也找不回来了。栈中只剩下 B 一个元素了。这很明显出现了 bug。
那怎么解决这种情况呢?最通用的做法就是加入版本号进行标识。
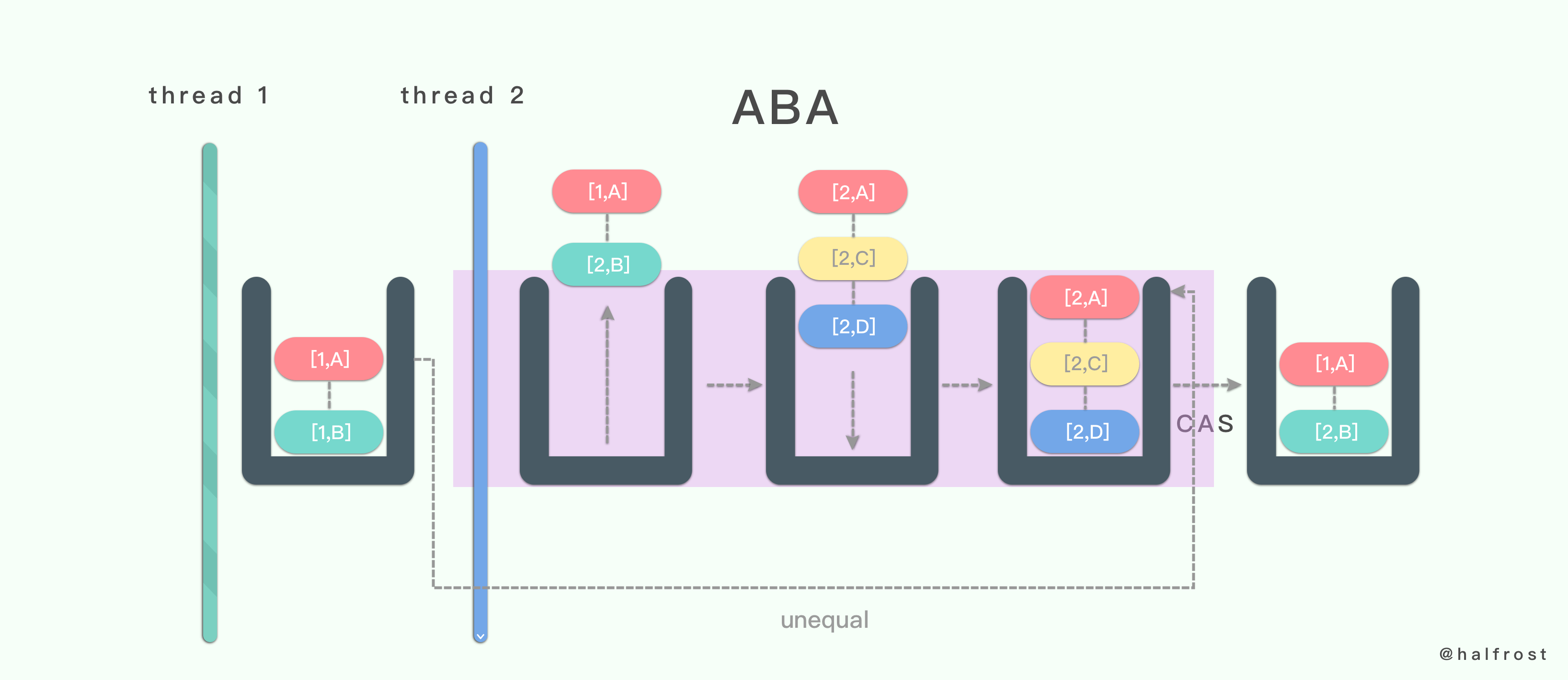
每次操作都加上版本号,这样就可以完美解决 ABA 的问题了。
2. 循环时间可能过长
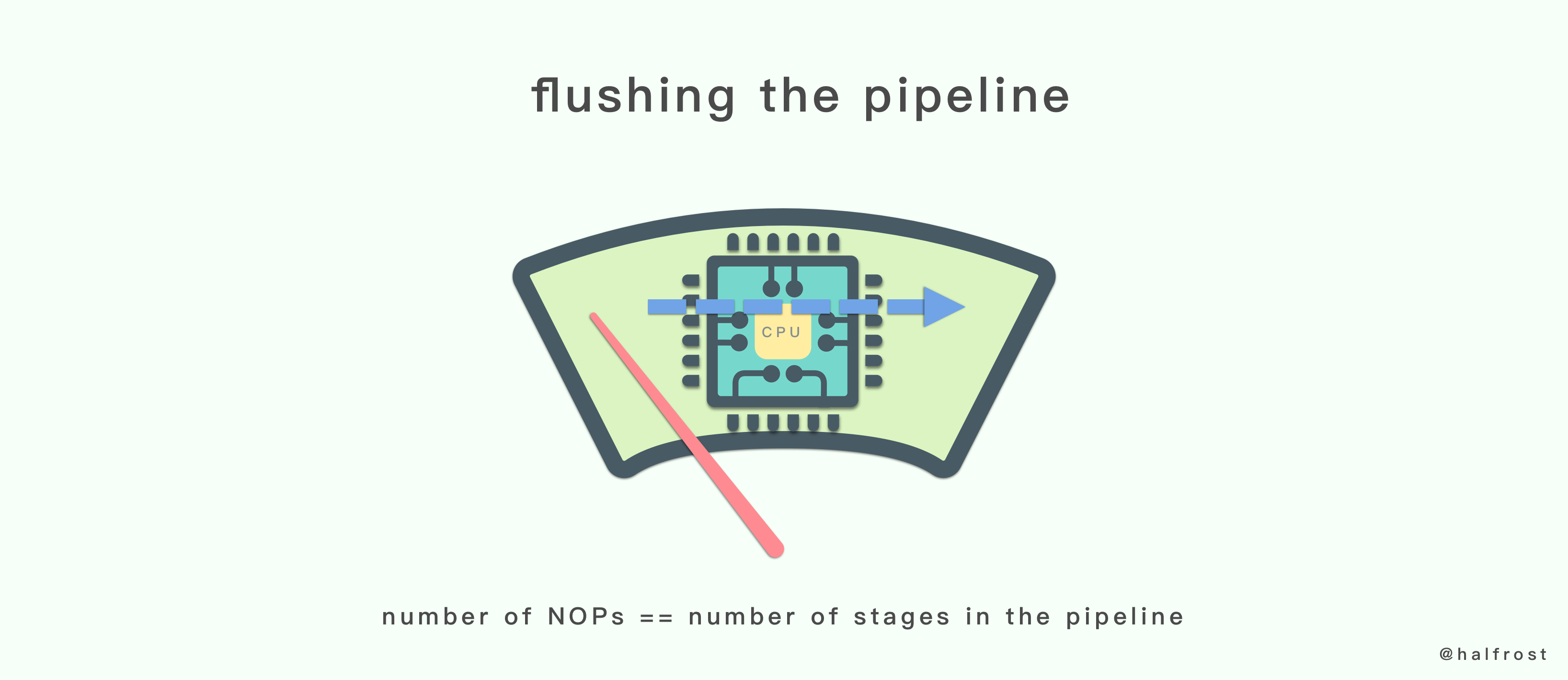
自旋 CAS 如果长时间不成功,会给 CPU 带来非常大的执行开销。如果能支持 CPU 提供的 Pause 指令,那么 CAS 的效率能有一定的提升。Pause 指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使 CPU 不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起 CPU 流水线被清空(CPU pipeline flush),从而提高 CPU 的执行效率。
3. 只能保证一个共享变量的原子操作
CAS 操作只能保证一个共享变量的原子操作,但是保证多个共享变量操作的原子性。一般做法可能就考虑利用锁了。
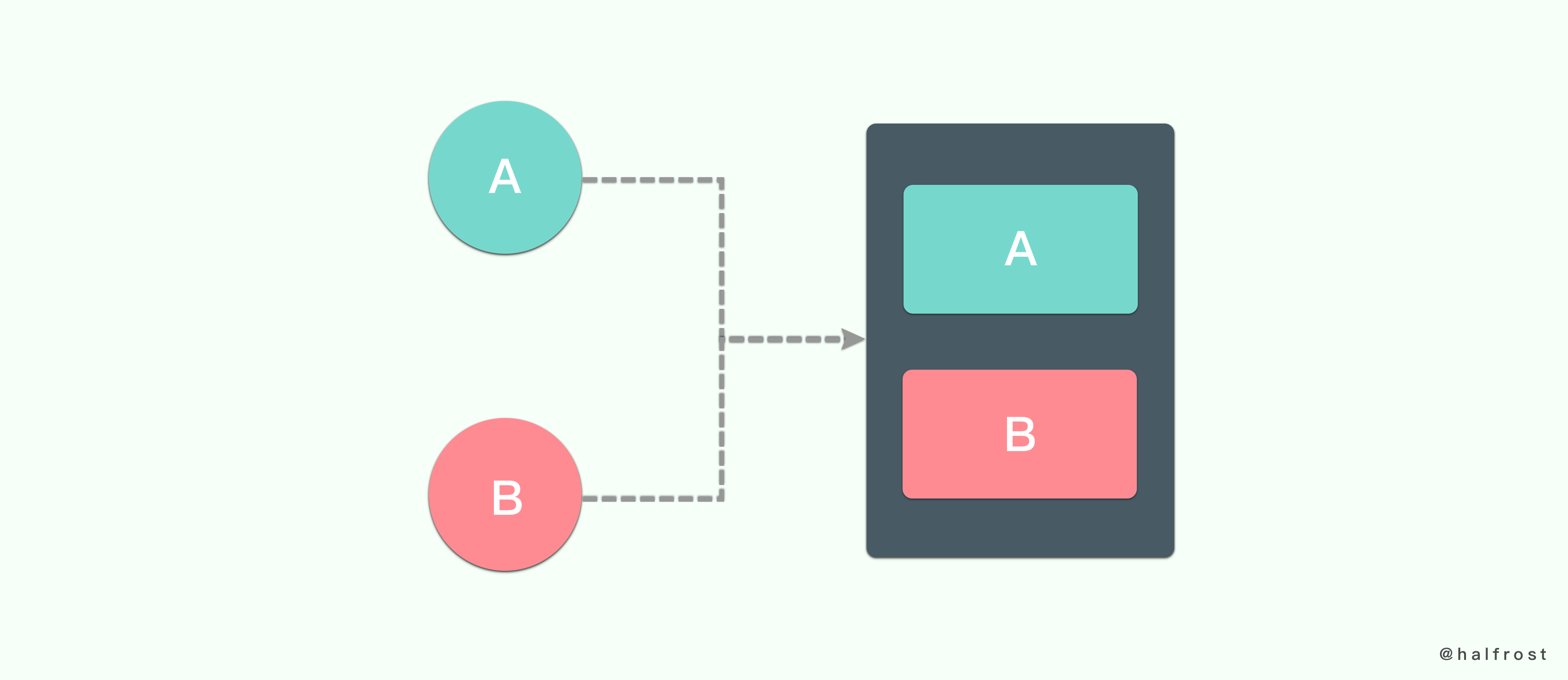
不过也可以利用一个结构体,把两个变量合并成一个变量。这样还可以继续利用 CAS 来保证原子性操作。
五. Lock - Free 方案举例
在 Lock - Free 方案举例之前,先来回顾一下互斥量的方案。上面我们用互斥量实现了 Go 的线程安全的 Map。至于这个 Map 的性能如何,接下来对比的时候可以看看数据。
1. NO Lock - Free 方案
如果不用 Lock - Free 方案也不用简单的互斥量的方案,如何实现一个线程安全的字典呢?答案是利用分段锁的设计,只有在同一个分段内才存在竞态关系,不同的分段锁之间没有锁竞争。相比于对整个
Map 加锁的设计,分段锁大大的提高了高并发环境下的处理能力。
type ConcurrentMap []*ConcurrentMapSharedtype ConcurrentMapShared struct {items map[string]interface{}sync.RWMutex}
分段锁 Segment 存在一个并发度。并发度可以理解为程序运行时能够同时更新 ConccurentMap 且不产生锁竞争的最大线程数,实际上就是 ConcurrentMap 中的分段锁个数。即数组的长度。
var SHARD_COUNT = 32
如果并发度设置的过小,会带来严重的锁竞争问题;如果并发度设置的过大,原本位于同一个 Segment 内的访问会扩散到不同的 Segment 中,CPU cache 命中率会下降,从而引起程序性能下降。
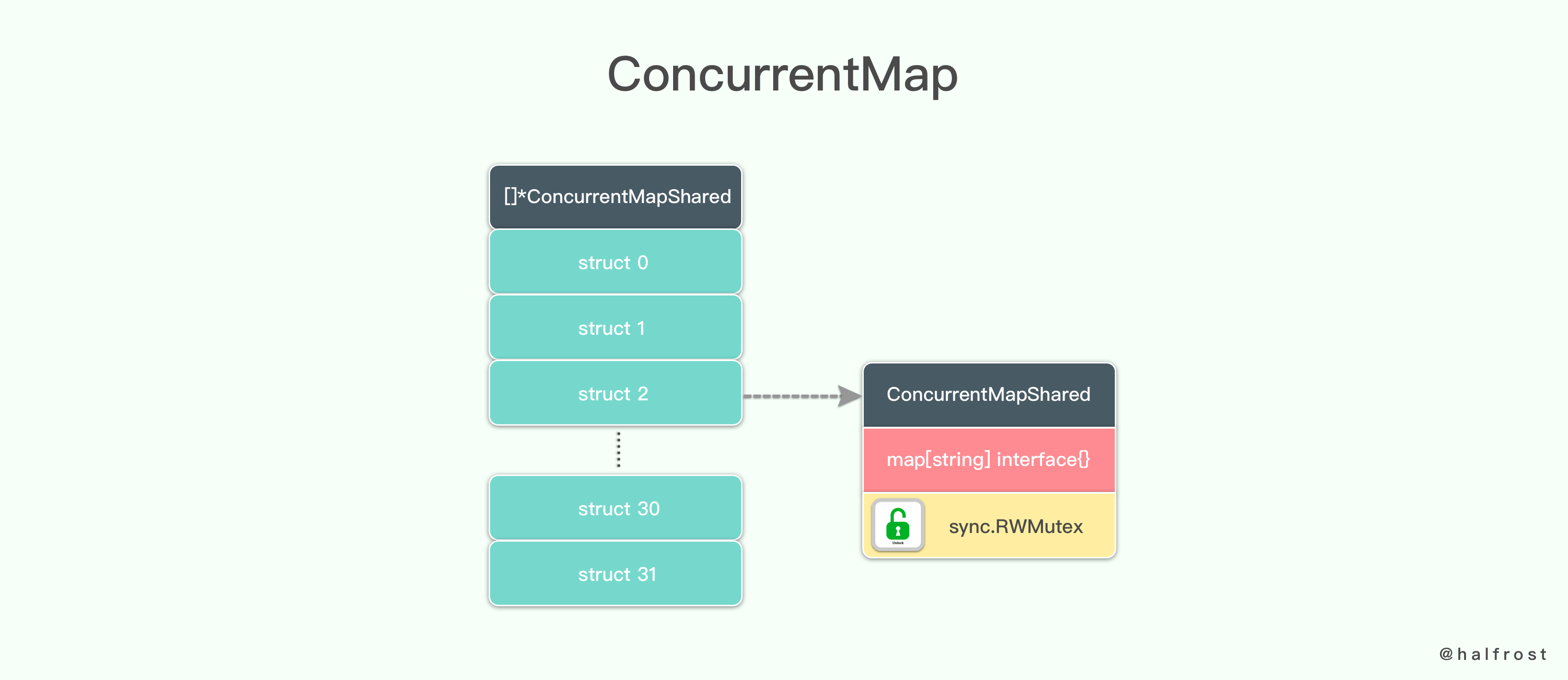
ConcurrentMap 的初始化就是对数组的初始化,并且初始化数组里面每个字典。
func New() ConcurrentMap {m := make(ConcurrentMap, SHARD_COUNT)for i := 0; i < SHARD_COUNT; i++ {m[i] = &ConcurrentMapShared{items: make(map[string]interface{})}}return m}
ConcurrentMap 主要使用 Segment 来实现减小锁粒度,把 Map 分割成若干个 Segment,在 put 的时候需要加读写锁,get 时候只加读锁。
既然分段了,那么针对每个 key 对应哪一个段的逻辑就由一个哈希函数来定。
func fnv32(key string) uint32 {hash := uint32(2166136261)const prime32 = uint32(16777619)for i := 0; i < len(key); i++ {hash *= prime32hash ^= uint32(key[i])}return hash}
上面这段哈希函数会根据每次传入的 string ,计算出不同的哈希值。
func (m ConcurrentMap) GetShard(key string) *ConcurrentMapShared {return m[uint(fnv32(key))%uint(SHARD_COUNT)]}
根据哈希值对数组长度取余,取出 ConcurrentMap 中的 ConcurrentMapShared。在 ConcurrentMapShared 中存储对应这个段的 key - value。
func (m ConcurrentMap) Set(key string, value interface{}) {shard := m.GetShard(key)shard.Lock()shard.items[key] = valueshard.Unlock()}
上面这段就是 ConcurrentMap 的 set 操作。思路很清晰:先取出对应段内的 ConcurrentMapShared,然后再加读写锁锁定,写入 key - value,写入成功以后再释放读写锁。
func (m ConcurrentMap) Get(key string) (interface{}, bool) {shard := m.GetShard(key)shard.RLock()val, ok := shard.items[key]shard.RUnlock()return val, ok}
上面这段就是 ConcurrentMap 的 get 操作。思路也很清晰:先取出对应段内的 ConcurrentMapShared,然后再加读锁锁定,读取 key - value,读取成功以后再释放读锁。
这里和 set 操作的区别就在于只需要加读锁即可,不用加读写锁。
func (m ConcurrentMap) Count() int {count := 0for i := 0; i < SHARD_COUNT; i++ {shard := m[i]shard.RLock()count += len(shard.items)shard.RUnlock()}return count}
ConcurrentMap 的 Count 操作就是把 ConcurrentMap 数组的每一个分段元素里面的每一个元素都遍历一遍,计算出总数。
func (m ConcurrentMap) Keys() []string {count := m.Count()ch := make(chan string, count)go func() {wg := sync.WaitGroup{}wg.Add(SHARD_COUNT)for _, shard := range m {go func(shard *ConcurrentMapShared) {shard.RLock()for key := range shard.items {ch <- key}shard.RUnlock()wg.Done()}(shard)}wg.Wait()close(ch)}()keys := make([]string, 0, count)for k := range ch {keys = append(keys, k)}return keys}
上述是返回 ConcurrentMap 中所有 key ,结果装在字符串数组中。
type UpsertCb func(exist bool, valueInMap interface{}, newValue interface{}) interface{}func (m ConcurrentMap) Upsert(key string, value interface{}, cb UpsertCb) (res interface{}) {shard := m.GetShard(key)shard.Lock()v, ok := shard.items[key]res = cb(ok, v, value)shard.items[key] = resshard.Unlock()return res}
上述代码是 Upsert 操作。如果已经存在了,就更新。如果是一个新元素,就用 UpsertCb 函数插入一个新的。思路也是先根据 string 找到对应的段,然后加读写锁。这里只能加读写锁,因为不管是 update 还是 insert 操作,都需要写入。读取 key 对应的 value 值,然后调用 UpsertCb 函数,把结果更新到 key 对应的 value 中。最后释放读写锁即可。
UpsertCb 函数在这里值得说明的是,这个函数是回调返回待插入到 map 中的新元素。这个函数当且仅当在读写锁被锁定的时候才会被调用,因此一定不允许再去尝试读取同一个 map 中的其他 key 值。因为这样会导致线程死锁。死锁的原因是 Go 中 sync.RWLock 是不可重入的。
完整的代码见concurrent_map.go
这种分段的方法虽然比单纯的加互斥量好很多,因为 Segment 把锁住的范围进一步的减少了,但是这个范围依旧比较大,还能再进一步的减少锁么?
还有一点就是并发量的设置,要合理,不能太大也不能太小。
2. Lock - Free 方案
在 Go 1.9 的版本中默认就实现了一种线程安全的 Map,摒弃了 Segment(分段锁)的概念,而是启用了一种全新的方式实现,利用了 CAS 算法,即 Lock - Free 方案。
采用 Lock - Free 方案以后,能比上一个分案,分段锁更进一步缩小锁的范围。性能大大提升。
接下来就让我们来看看如何用 CAS 实现一个线程安全的高性能 Map 。
官方是 sync.map 有如下的描述:
这个 Map 是线程安全的,读取,插入,删除也都保持着常数级的时间复杂度。多个 goroutines 协程同时调用 Map 方法也是线程安全的。该 Map 的零值是有效的,并且零值是一个空的 Map 。线程安全的 Map 在第一次使用之后,不允许被拷贝。
这里解释一下为何不能被拷贝。因为对结构体的复制不但会生成该值的副本,还会生成其中字段的副本。如此一来,本应施加于此的并发线程安全保护也就失效了。
作为源值赋给别的变量,作为参数值传入函数,作为结果值从函数返回,作为元素值通过通道传递等都会造成值的复制。正确的做法是用指向该类型的指针类型的变量。
Go 1.9 中 sync.map 的数据结构如下:
type Map struct {mu Mutexread atomic.Valuedirty map[interface{}]*entrymisses int}
在这个 Map 中,包含一个互斥量 mu,一个原子值 read,一个非线程安全的字典 map,这个字典的 key 是 interface{} 类型,value 是 *entry 类型。最后还有一个 int 类型的计数器。
先来说说原子值。atomic.Value 这个类型有两个公开的指针方法,Load 和 Store 。Load 方法用于原子地的读取原子值实例中存储的值,它会返回一个 interface{} 类型的结果,并且不接受任何参数。Store 方法用于原子地在原子值实例中存储一个值,它接受一个 interface{} 类型的参数而没有任何结果。在未曾通过 Store 方法向原子值实例存储值之前,它的 Load 方法总会返回 nil。
在这个线程安全的字典中,Load 和 Store 的都是一个 readOnly 的数据结构。
type readOnly struct {m map[interface{}]*entryamended bool}
readOnly 中存储了一个非线程安全的字典,这个字典和上面 dirty map 存储的类型完全一致。key 是 interface{} 类型,value 是 *entry 类型。
type entry struct {p unsafe.Pointer}
p 指针指向 *interface{} 类型,里面存储的是 entry 的地址。如果 p = = nil,代表 entry 被删除了,并且 m.dirty = = nil。如果 p = = expunged,代表 entry 被删除了,并且 m.dirty != nil ,那么 entry 从 m.dirty 中丢失了。
除去以上两种情况外,entry 都是有效的,并且被记录在 m.read.m[key] 中,如果 m.dirty!= nil,entry 被存储在 m.dirty[key] 中。
一个 entry 可以通过原子替换操作成 nil 来删除它。当 m.dirty 在下一次被创建,entry 会被 expunged 指针原子性的替换为 nil,m.dirty[key] 不对应任何 value。只要 p != expunged,那么一个 entry 就可以通过原子替换操作更新关联的 value。如果 p = = expunged,那么一个 entry 想要通过原子替换操作更新关联的 value,只能在首次设置 m.dirty[key] = e 以后才能更新 value。这样做是为了能在 dirty map 中查找到它。
所以从上面分析可以看出,read 中的 key 是 readOnly 的(key 的集合不会变,删除也只是打一个标记),value 的操作全都可以原子完成,所以这个结构不用加锁。dirty 是一个 read 的拷贝,加锁的操作都在这里,如增加元素、删除元素等(dirty 上执行删除操作就是真的删除)具体操作见下面分析。
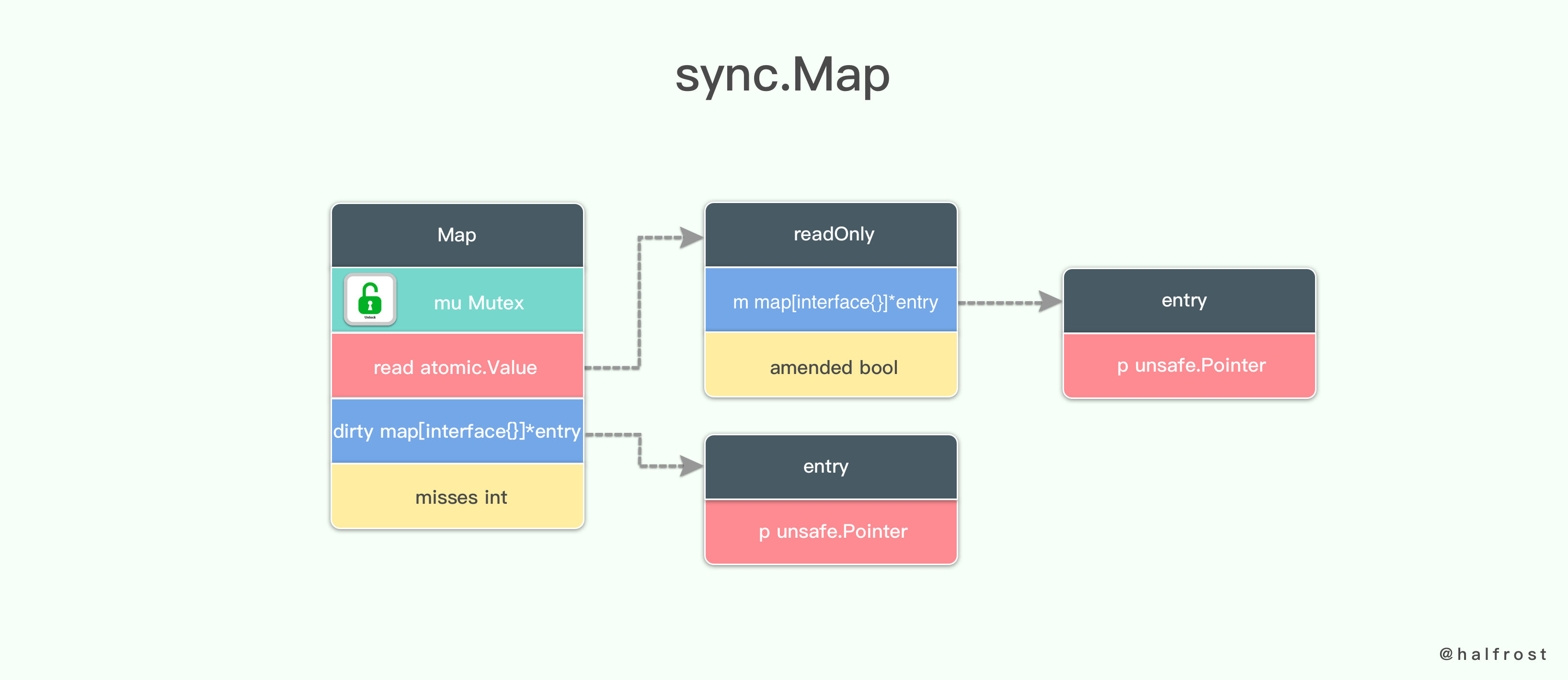
总结一下,sync.map 的数据结构如上。
再看看线程安全的 sync.map 的一些操作。
func (m *Map) Load(key interface{}) (value interface{}, ok bool) {read, _ := m.read.Load().(readOnly)e, ok := read.m[key]if !ok && read.amended {m.mu.Lock()read, _ = m.read.Load().(readOnly)e, ok = read.m[key]if !ok && read.amended {e, ok = m.dirty[key]m.missLocked()}m.mu.Unlock()}if !ok {return nil, false}return e.load()}
上述代码是 Load 操作。返回的是入参 key 对应的 value 值。如果 value 不存在就返回 nil。dirty map 中会保存一些 read map 里面不存在的 key,那么就要读取出 dirty map 里面 key 对应的 value。注意读取的时候需要加互斥锁,因为 dirty map 是非线程安全的。
func (m *Map) missLocked() {m.misses++if m.misses < len(m.dirty) {return}m.read.Store(readOnly{m: m.dirty})m.dirty = nilm.misses = 0}
上面这段代码是记录 misses 次数的。只有当 misses 个数大于 dirty map 的长度的时候,会把 dirty map 存储到 read map 中。并且把 dirty 置空,misses 次数也清零。
在看 Store 操作之前,先说一个 expunged 变量。
var expunged = unsafe.Pointer(new(interface{}))
expunged 变量是一个指针,用来标记从 dirty map 中删除的 entry。
func (m *Map) Store(key, value interface{}) {read, _ := m.read.Load().(readOnly)if e, ok := read.m[key]; ok && e.tryStore(&value) {return}m.mu.Lock()read, _ = m.read.Load().(readOnly)if e, ok := read.m[key]; ok {if e.unexpungeLocked() {m.dirty[key] = e}e.storeLocked(&value)} else if e, ok := m.dirty[key]; ok {e.storeLocked(&value)} else {if !read.amended {m.dirtyLocked()m.read.Store(readOnly{m: read.m, amended: true})}m.dirty[key] = newEntry(value)}m.mu.Unlock()}
Store 优先从 read map 里面去读取 key ,然后存储它的 value。如果 entry 是被标记为从 dirty map 中删除过的,那么还需要重新存储回 dirty map 中。
如果 read map 里面没有相应的 key,就去 dirty map 里面去读取。dirty map 就直接存储对应的 value。
最后如何 read map 和 dirty map 都没有这个 key 值,这就意味着该 key 是第一次被加入到 dirty map 中。在 dirty map 中存储这个 key 以及对应的 value。
func (e *entry) tryStore(i *interface{}) bool {p := atomic.LoadPointer(&e.p)if p == expunged {return false}for {if atomic.CompareAndSwapPointer(&e.p, p, unsafe.Pointer(i)) {return true}p = atomic.LoadPointer(&e.p)if p == expunged {return false}}}
tryStore 函数的实现和 CAS 原理差不多,它会反复的循环判断 entry 是否被标记成了 expunged,如果 entry 经过 CAS 操作成功的替换成了 i,那么就返回 true,反之如果被标记成了 expunged,就返回 false。
func (e *entry) unexpungeLocked() (wasExpunged bool) {return atomic.CompareAndSwapPointer(&e.p, expunged, nil)}
如果 entry 的 unexpungeLocked 返回为 true,那么就说明 entry 已经被标记成了 expunged,那么它就会经过 CAS 操作把它置为 nil。
再来看看删除操作的实现。
func (m *Map) Delete(key interface{}) {read, _ := m.read.Load().(readOnly)e, ok := read.m[key]if !ok && read.amended {m.mu.Lock()read, _ = m.read.Load().(readOnly)e, ok = read.m[key]if !ok && read.amended {delete(m.dirty, key)}m.mu.Unlock()}if ok {e.delete()}}
delete 操作的实现比较简单,如果 read map 中存在 key,就可以直接删除,如果不存在 key 并且 dirty map 中有这个 key,那么就要删除 dirty map 中的这个 key。操作 dirty map 的时候记得先加上锁进行保护。
func (e *entry) delete() (hadValue bool) {for {p := atomic.LoadPointer(&e.p)if p == nil || p == expunged {return false}if atomic.CompareAndSwapPointer(&e.p, p, nil) {return true}}}
删除 entry 具体的实现如上。这个操作里面都是原子性操作。循环判断 entry 是否为 nil 或者已经被标记成了 expunged,如果是这种情况就返回 false,代表删除失败。否则就 CAS 操作,将 entry 的 p 指针置为 nil,并返回 true,代表删除成功。
至此,关于 Go 1.9 中自带的线程安全的 sync.map 的实现就分析完了。官方的实现里面基本没有用到锁,互斥量的 lock 也是基于 CAS 的。read map 也是原子性的。所以比之前加锁的实现版本性能有所提升。
如果 read 中的一个 key 被删除了,即被打了 expunged 标记,然后如果再添加相同的 key,不需要操作 dirty,直接恢复回来就可以了。
如果 dirty 没有任何数据的时候,删除了 read 中的 key,同样也是加上 expunged 标记,再添加另外一个不同的 key,dirtyLocked() 函数会把 read 中所有已经有的 key-value 全部都拷贝到 dirty 中保存,并再追加上 read 中最后添加上的和之前删掉不同的 key。
这就等同于:
当 dirty 不存在的时候,read 就是全部 map 的数据。
当 dirty 存在的时候,dirty 才是正确的 map 数据。
从 sync.map 的实现中我们可以看出,它的思想重点在读取是无锁的。字典大部分操作也都是读取,多个读者之间是可以无锁的。当 read 中的数据 miss 到一定程度的时候,(有点命中缓存的意思),就会考虑直接把 dirty 替换成 read,整个一个赋值替换就可以了。但是在 dirty 重新生成新的时候,或者说第一个 dirty 生成的时候,还是需要遍历整个 read,这里会消耗很多性能,那官方的这个 sync.map 的性能究竟是怎么样的呢?
究竟 Lock - Free 的性能有多强呢?接下来做一下性能测试。
五. 性能对比
性能测试主要针对 3 个方面,Insert,Get,Delete。测试对象主要针对简单加互斥锁的原生 Map ,分段加锁的 Map,Lock - Free 的 Map 这三种进行性能测试。
性能测试的所有代码已经放在 github 了,地址在这里,性能测试用的指令是:
go test -v -run=^$ -bench . -benchmem
1. 插入 Insert 性能测试
func BenchmarkSingleInsertAbsentBuiltInMap(b *testing.B) {myMap = &MyMap{m: make(map[string]interface{}, 32),}b.ResetTimer()for i := 0; i < b.N; i++ {myMap.BuiltinMapStore(strconv.Itoa(i), "value")}}func BenchmarkSingleInsertAbsent(b *testing.B) {m := New()b.ResetTimer()for i := 0; i < b.N; i++ {m.Set(strconv.Itoa(i), "value")}}func BenchmarkSingleInsertAbsentSyncMap(b *testing.B) {syncMap := &sync.Map{}b.ResetTimer()for i := 0; i < b.N; i++ {syncMap.Store(strconv.Itoa(i), "value")}}
测试结果:
BenchmarkSingleInsertAbsentBuiltInMap-4 2000000 857 ns/op 170 B/op 1 allocs/opBenchmarkSingleInsertAbsent-4 2000000 651 ns/op 170 B/op 1 allocs/opBenchmarkSingleInsertAbsentSyncMap-4 1000000 1094 ns/op 187 B/op 5 allocs/op
实验结果是分段锁的性能最高。这里说明一下测试结果,-4 代表测试用了 4 核 CPU ,2000000 代表循环次数,857 ns/op 代表的是平均每次执行花费的时间,170 B/op 代表的是每次执行堆上分配内存总数,allocs/op 代表的是每次执行堆上分配内存次数。
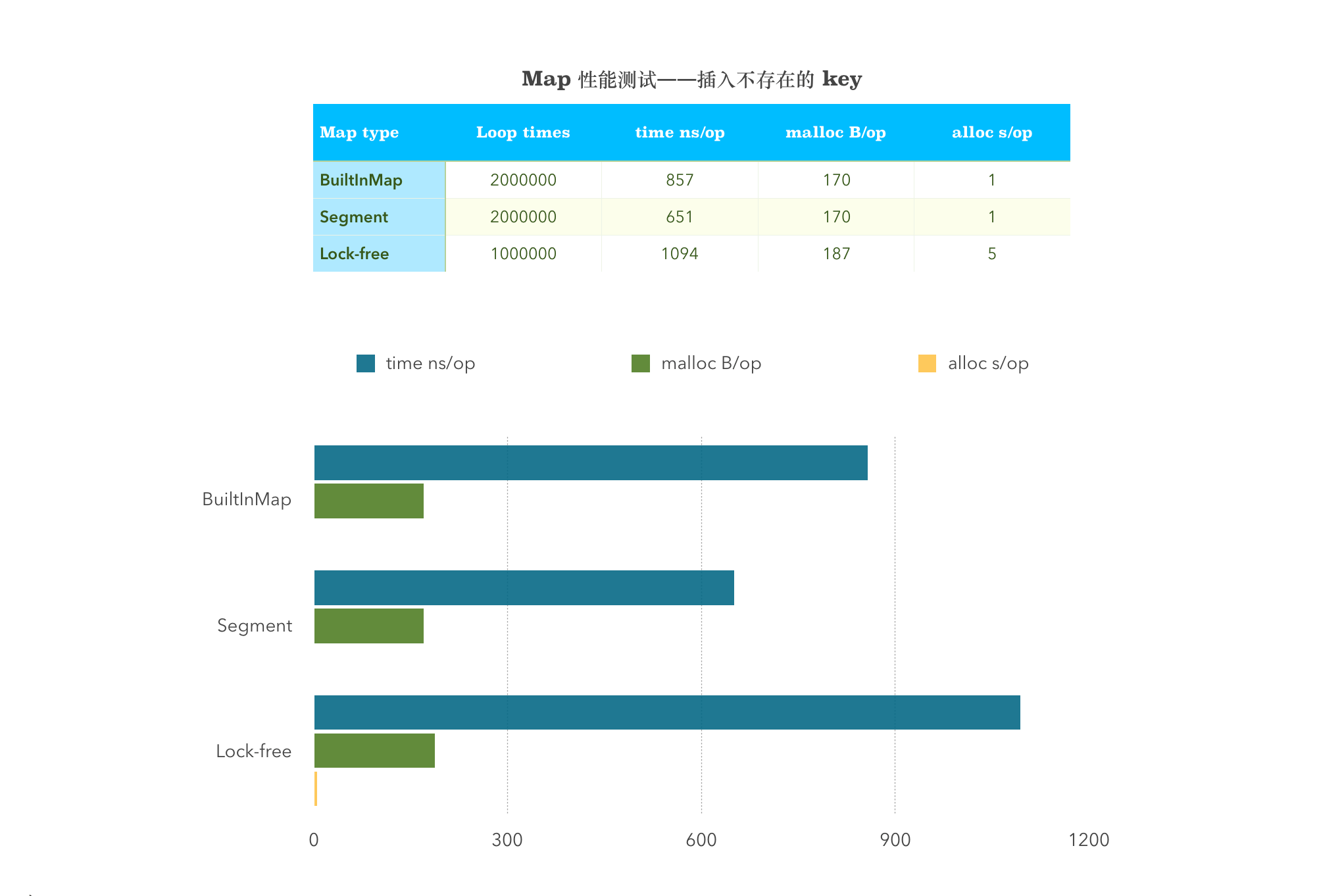
这样看来,循环次数越多,花费时间越少,分配内存总数越小,分配内存次数越少,性能就越好。下面的性能图表中去除掉了第一列循环次数,只花了剩下的 3 项,所以条形图越短的性能越好。以下的每张条形图的规则和测试结果代表的意义都和这里一样,下面就不再赘述了。
func BenchmarkSingleInsertPresentBuiltInMap(b *testing.B) {myMap = &MyMap{m: make(map[string]interface{}, 32),}myMap.BuiltinMapStore("key", "value")b.ResetTimer()for i := 0; i < b.N; i++ {myMap.BuiltinMapStore("key", "value")}}func BenchmarkSingleInsertPresent(b *testing.B) {m := New()m.Set("key", "value")b.ResetTimer()for i := 0; i < b.N; i++ {m.Set("key", "value")}}func BenchmarkSingleInsertPresentSyncMap(b *testing.B) {syncMap := &sync.Map{}syncMap.Store("key", "value")b.ResetTimer()for i := 0; i < b.N; i++ {syncMap.Store("key", "value")}}
测试结果:
BenchmarkSingleInsertPresentBuiltInMap-4 20000000 74.6 ns/op 0 B/op 0 allocs/opBenchmarkSingleInsertPresent-4 20000000 61.1 ns/op 0 B/op 0 allocs/opBenchmarkSingleInsertPresentSyncMap-4 20000000 108 ns/op 16 B/op 1 allocs/op
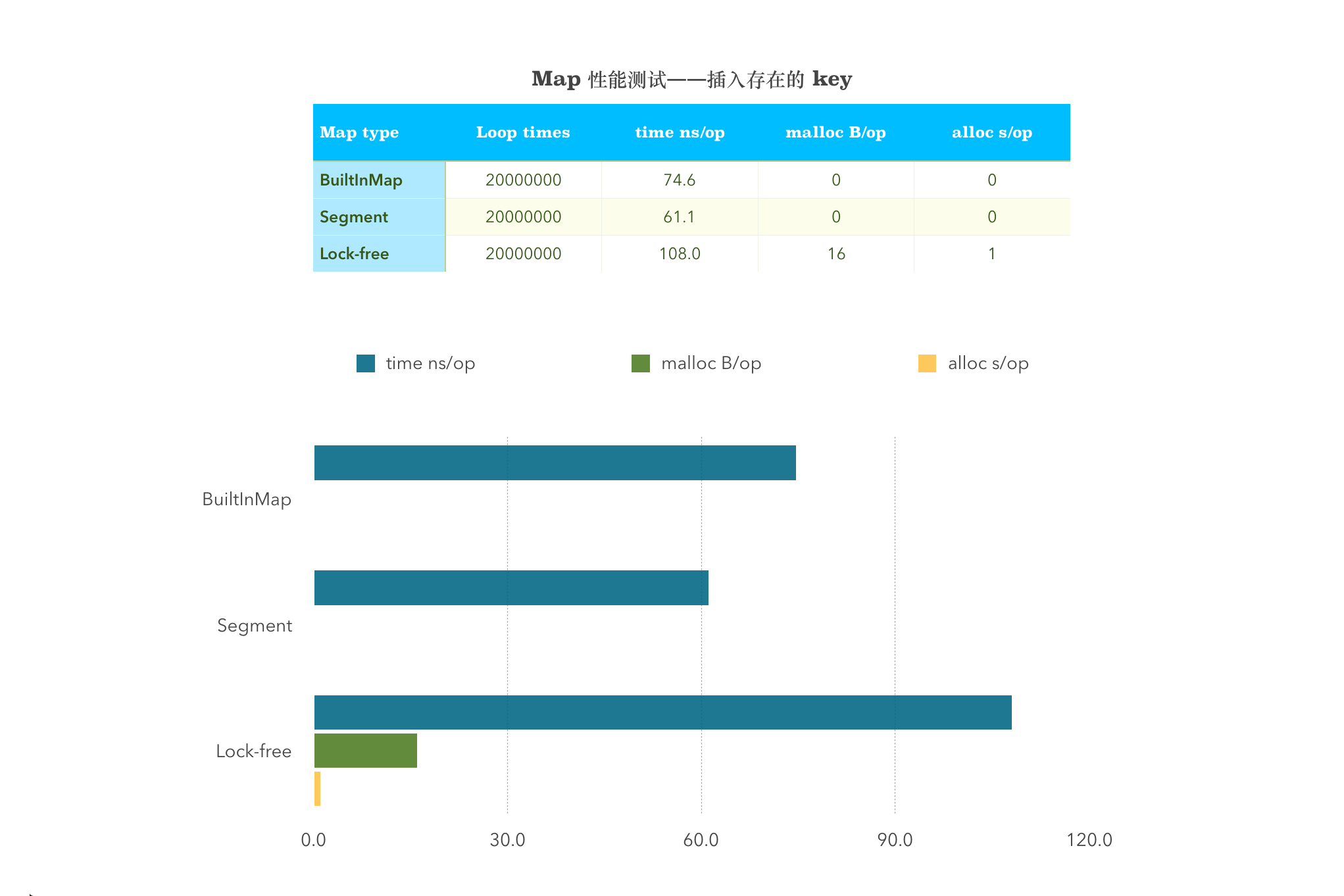
从图中可以看出,sync.map 在涉及到 Store 这一项的均比其他两者的性能差。不管插入不存在的 Key 还是存在的 Key,分段锁的性能均是目前最好的。
2. 读取 Get 性能测试
func BenchmarkSingleGetPresentBuiltInMap(b *testing.B) {myMap = &MyMap{m: make(map[string]interface{}, 32),}myMap.BuiltinMapStore("key", "value")b.ResetTimer()for i := 0; i < b.N; i++ {myMap.BuiltinMapLookup("key")}}func BenchmarkSingleGetPresent(b *testing.B) {m := New()m.Set("key", "value")b.ResetTimer()for i := 0; i < b.N; i++ {m.Get("key")}}func BenchmarkSingleGetPresentSyncMap(b *testing.B) {syncMap := &sync.Map{}syncMap.Store("key", "value")b.ResetTimer()for i := 0; i < b.N; i++ {syncMap.Load("key")}}
测试结果:
BenchmarkSingleGetPresentBuiltInMap-4 20000000 71.5 ns/op 0 B/op 0 allocs/opBenchmarkSingleGetPresent-4 30000000 42.3 ns/op 0 B/op 0 allocs/opBenchmarkSingleGetPresentSyncMap-4 30000000 40.3 ns/op 0 B/op 0 allocs/op
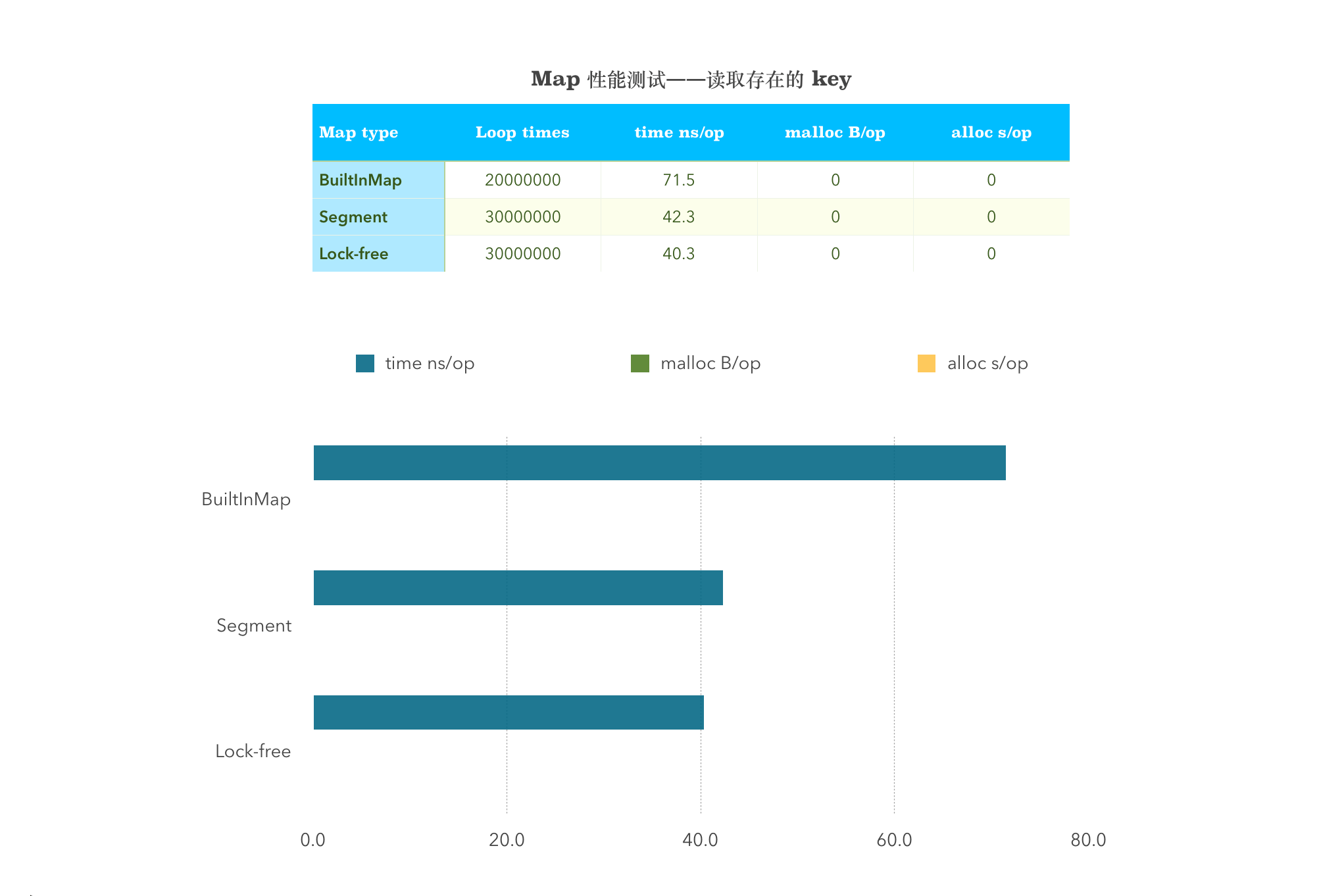
从图中可以看出,sync.map 在 Load 这一项的性能非常优秀,远高于其他两者。
3. 并发插入读取混合性能测试
接下来的实现就涉及到了并发插入和读取了。由于分段锁实现的特殊性,分段个数会多多少少影响到性能,那么接下来的实验就会对分段锁分 1,16,32,256 这 4 段进行测试,分别看看性能变化如何,其他两种线程安全的 Map 不变。
由于并发的代码太多了,这里就不贴出来了,感兴趣的同学可以看这里
下面就直接放出测试结果:
并发插入不存在的 Key 值
BenchmarkMultiInsertDifferentBuiltInMap-4 1000000 2359 ns/op 330 B/op 11 allocs/opBenchmarkMultiInsertDifferent_1_Shard-4 1000000 2039 ns/op 330 B/op 11 allocs/opBenchmarkMultiInsertDifferent_16_Shard-4 1000000 1937 ns/op 330 B/op 11 allocs/opBenchmarkMultiInsertDifferent_32_Shard-4 1000000 1944 ns/op 330 B/op 11 allocs/opBenchmarkMultiInsertDifferent_256_Shard-4 1000000 1991 ns/op 331 B/op 11 allocs/opBenchmarkMultiInsertDifferentSyncMap-4 1000000 3760 ns/op 635 B/op 33 allocs/op
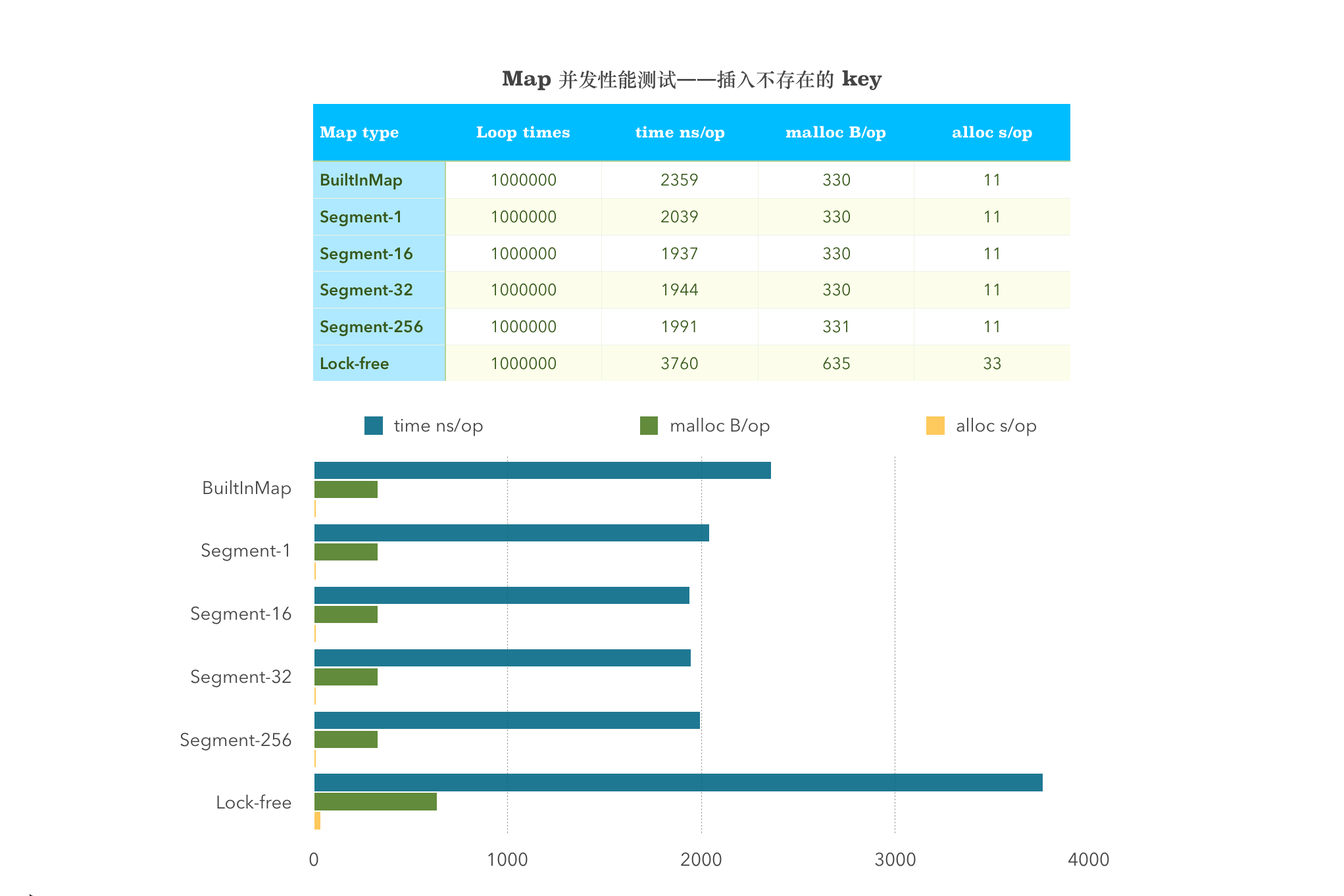
从图中可以看出,sync.map 在涉及到 Store 这一项的均比其他两者的性能差。并发插入不存在的 Key,分段锁划分的 Segment 多少与性能没有关系。
并发插入存在的 Key 值
BenchmarkMultiInsertSameBuiltInMap-4 1000000 1182 ns/op 160 B/op 10 allocs/opBenchmarkMultiInsertSame-4 1000000 1091 ns/op 160 B/op 10 allocs/opBenchmarkMultiInsertSameSyncMap-4 1000000 1809 ns/op 480 B/op 30 allocs/op
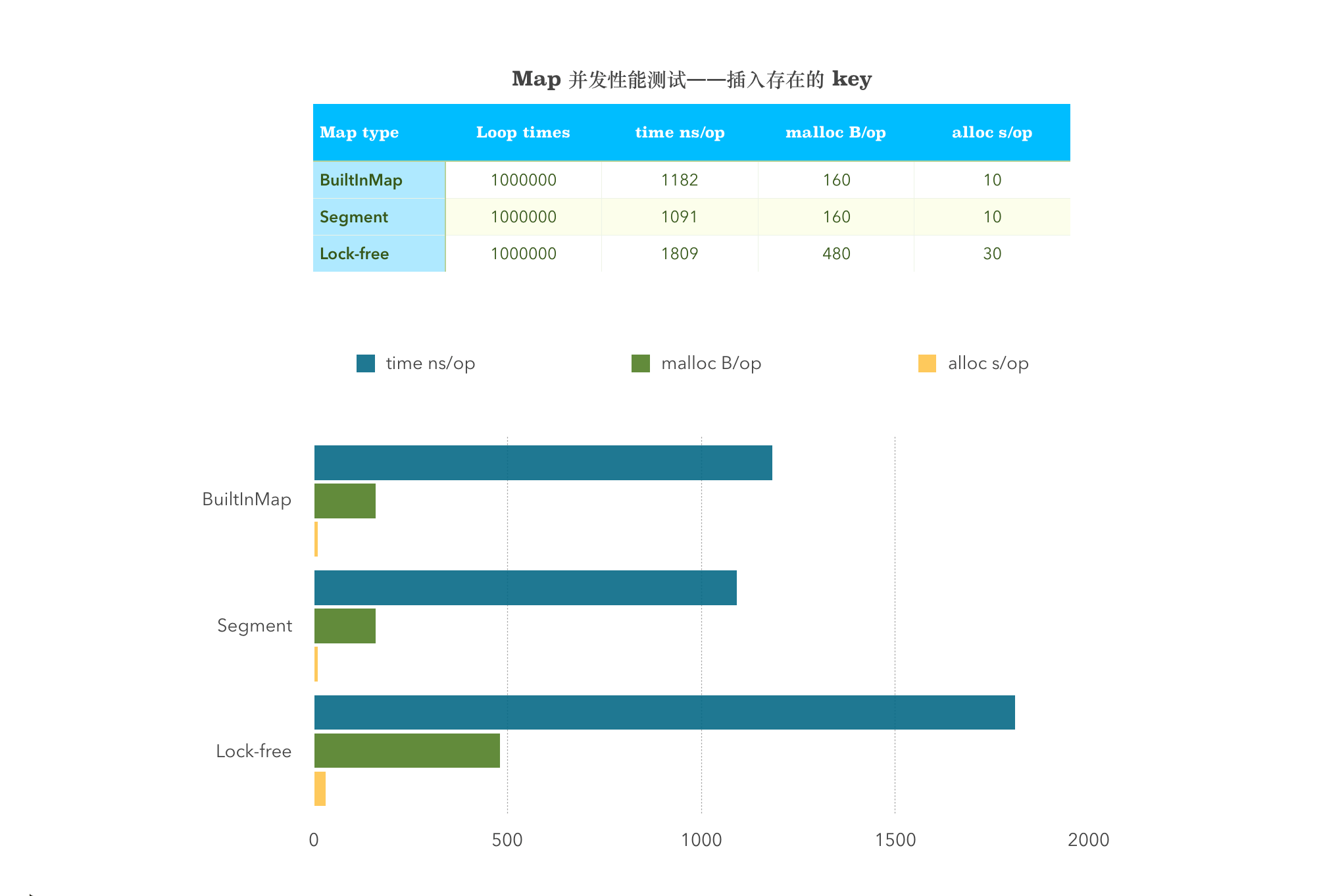
从图中可以看出,sync.map 在涉及到 Store 这一项的均比其他两者的性能差。
并发的读取存在的 Key 值
BenchmarkMultiGetSameBuiltInMap-4 2000000 767 ns/op 0 B/op 0 allocs/opBenchmarkMultiGetSame-4 3000000 481 ns/op 0 B/op 0 allocs/opBenchmarkMultiGetSameSyncMap-4 3000000 464 ns/op 0 B/op 0 allocs/op
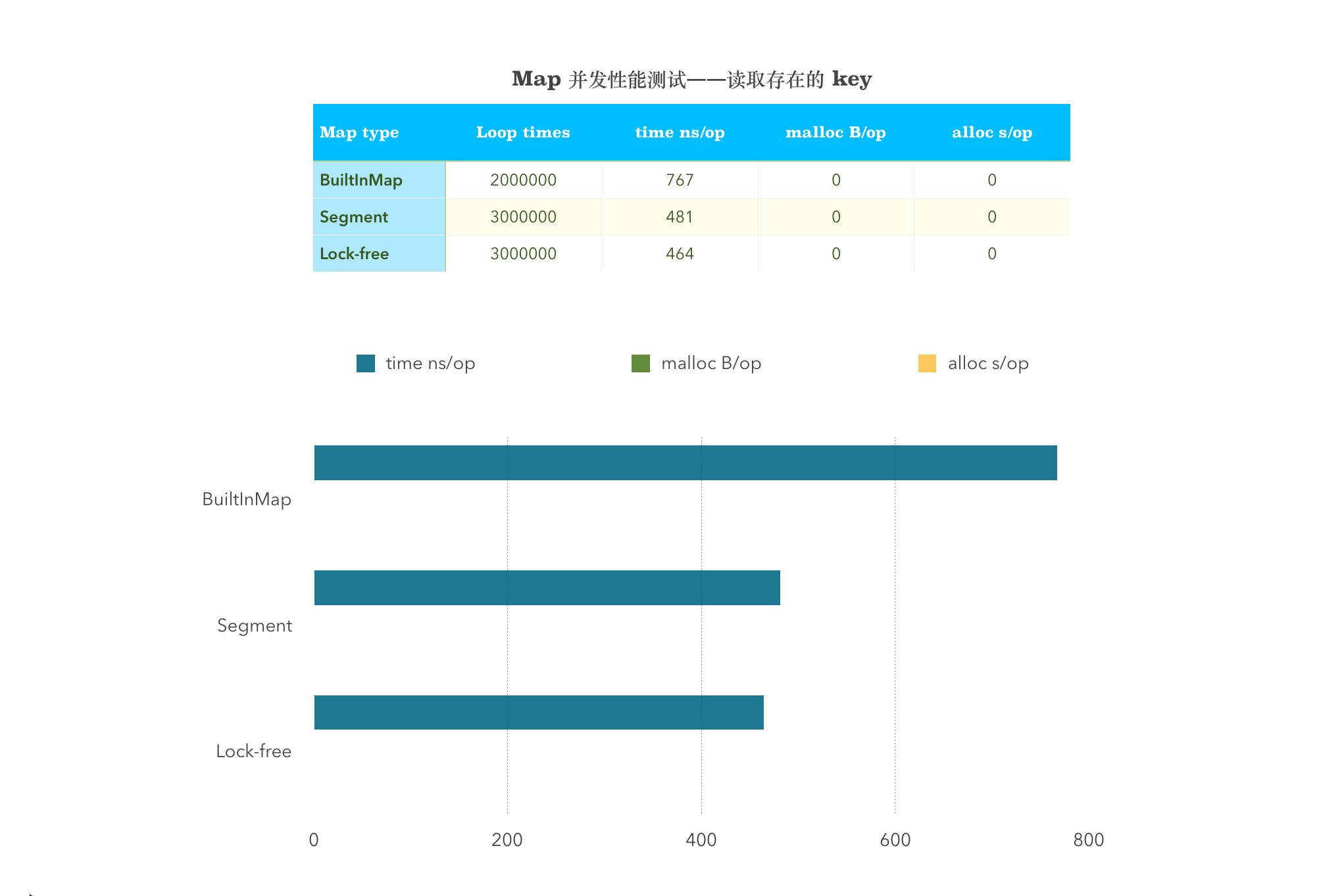
从图中可以看出,sync.map 在 Load 这一项的性能远超多其他两者。
并发插入读取不存在的 Key 值
BenchmarkMultiGetSetDifferentBuiltInMap-4 1000000 3281 ns/op 337 B/op 12 allocs/opBenchmarkMultiGetSetDifferent_1_Shard-4 1000000 3007 ns/op 338 B/op 12 allocs/opBenchmarkMultiGetSetDifferent_16_Shard-4 500000 2662 ns/op 337 B/op 12 allocs/opBenchmarkMultiGetSetDifferent_32_Shard-4 1000000 2732 ns/op 337 B/op 12 allocs/opBenchmarkMultiGetSetDifferent_256_Shard-4 1000000 2788 ns/op 339 B/op 12 allocs/opBenchmarkMultiGetSetDifferentSyncMap-4 300000 8990 ns/op 1104 B/op 34 allocs/op
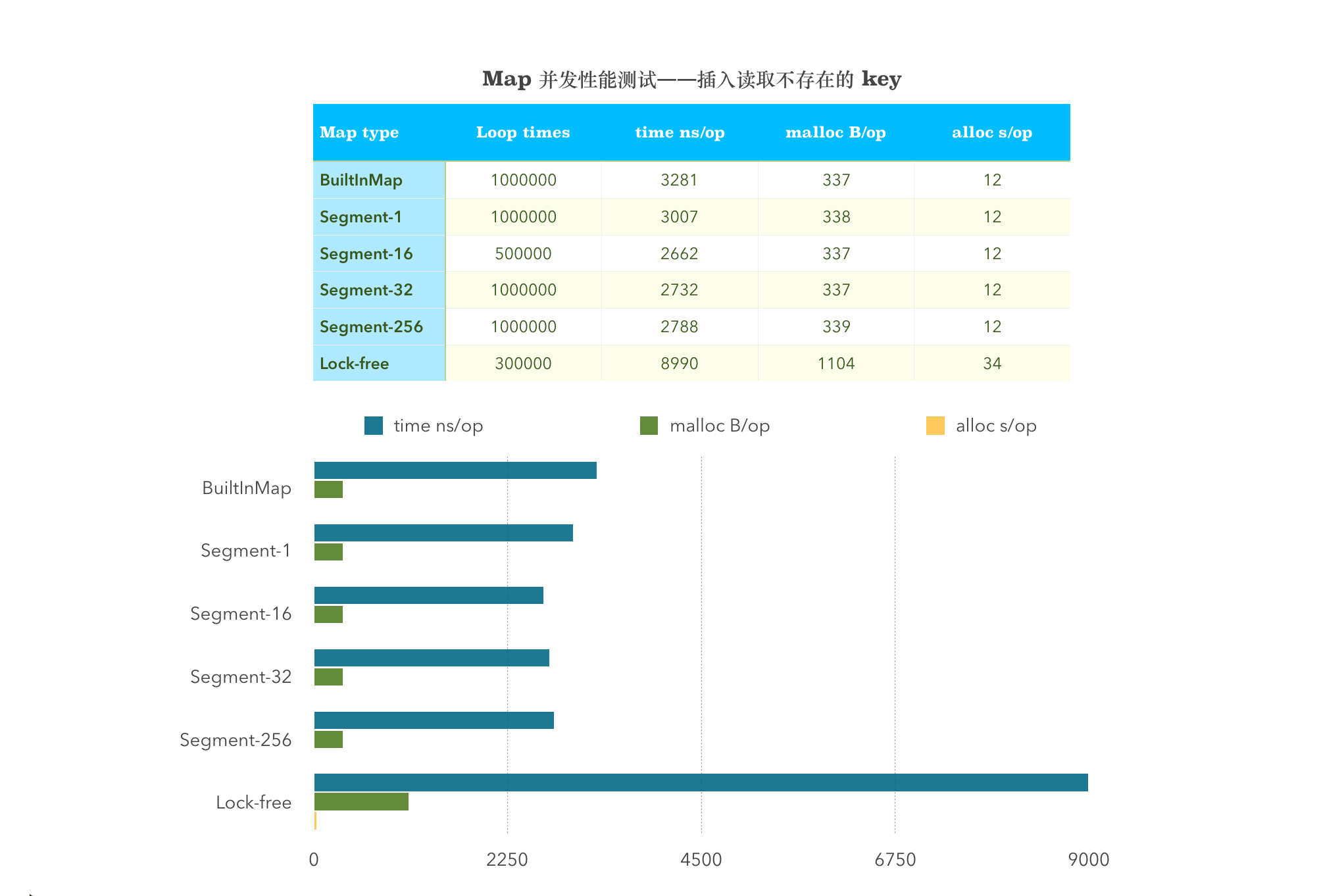
从图中可以看出,sync.map 在涉及到 Store 这一项的均比其他两者的性能差。并发插入读取不存在的 Key,分段锁划分的 Segment 多少与性能没有关系。
并发插入读取存在的 Key 值
BenchmarkMultiGetSetBlockBuiltInMap-4 1000000 2095 ns/op 160 B/op 10 allocs/opBenchmarkMultiGetSetBlock_1_Shard-4 1000000 1712 ns/op 160 B/op 10 allocs/opBenchmarkMultiGetSetBlock_16_Shard-4 1000000 1730 ns/op 160 B/op 10 allocs/opBenchmarkMultiGetSetBlock_32_Shard-4 1000000 1645 ns/op 160 B/op 10 allocs/opBenchmarkMultiGetSetBlock_256_Shard-4 1000000 1619 ns/op 160 B/op 10 allocs/opBenchmarkMultiGetSetBlockSyncMap-4 500000 2660 ns/op 480 B/op 30 allocs/op
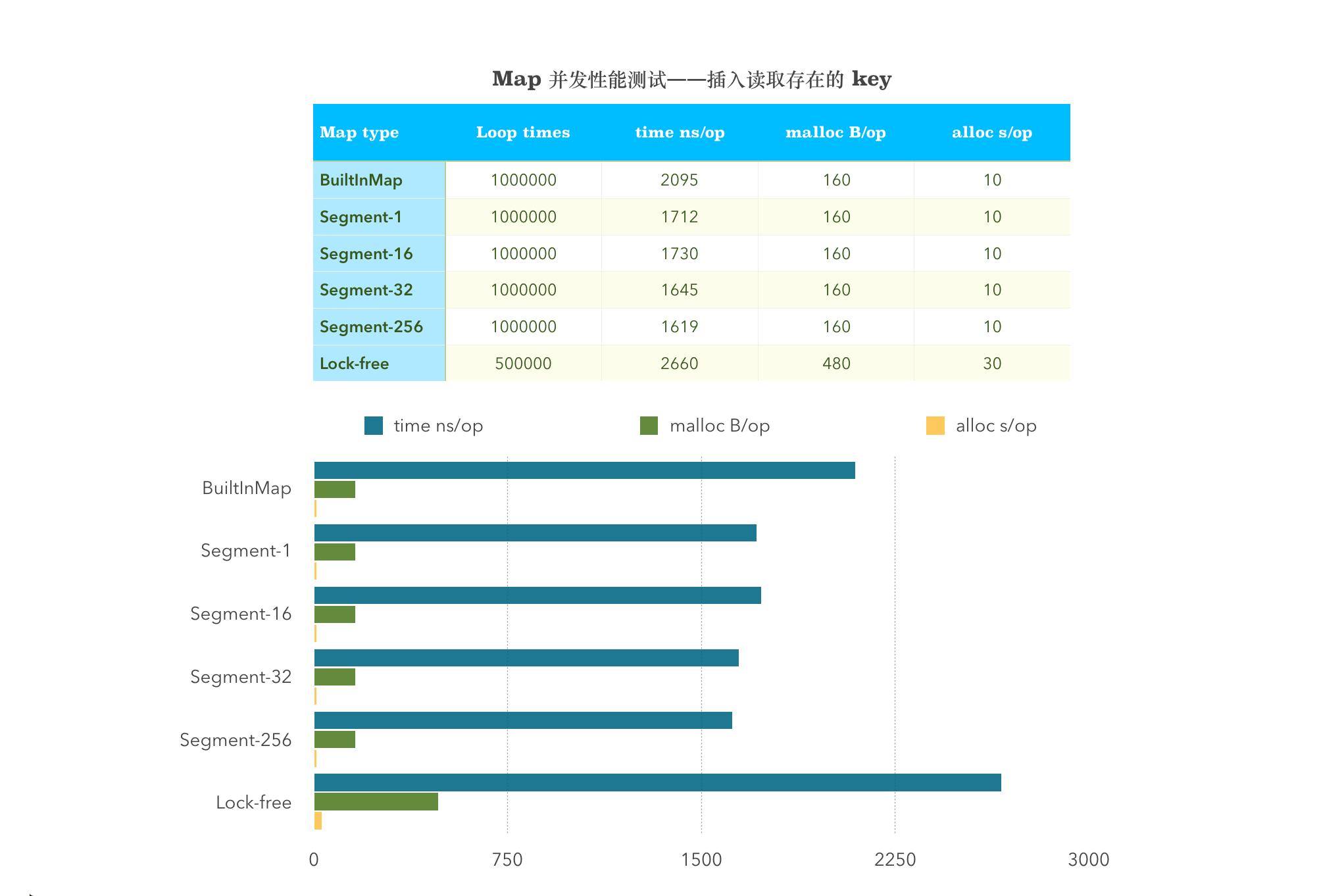
从图中可以看出,sync.map 在涉及到 Store 这一项的均比其他两者的性能差。并发插入读取存在的 Key,分段锁划分的 Segment 越小,性能越好!
4. 删除 Delete 性能测试
func BenchmarkDeleteBuiltInMap(b *testing.B) {myMap = &MyMap{m: make(map[string]interface{}, 32),}b.RunParallel(func(pb *testing.PB) {r := rand.New(rand.NewSource(time.Now().Unix()))for pb.Next() {k := r.Intn(100000000)myMap.BuiltinMapDelete(strconv.Itoa(k))}})}func BenchmarkDelete(b *testing.B) {m := New()b.RunParallel(func(pb *testing.PB) {r := rand.New(rand.NewSource(time.Now().Unix()))for pb.Next() {k := r.Intn(100000000)m.Remove(strconv.Itoa(k))}})}func BenchmarkDeleteSyncMap(b *testing.B) {syncMap := &sync.Map{}b.RunParallel(func(pb *testing.PB) {r := rand.New(rand.NewSource(time.Now().Unix()))for pb.Next() {k := r.Intn(100000000)syncMap.Delete(strconv.Itoa(k))}})}
测试结果:
BenchmarkDeleteBuiltInMap-4 10000000 130 ns/op 8 B/op 1 allocs/opBenchmarkDelete-4 20000000 76.7 ns/op 8 B/op 1 allocs/opBenchmarkDeleteSyncMap-4 30000000 45.4 ns/op 8 B/op 0 allocs/op
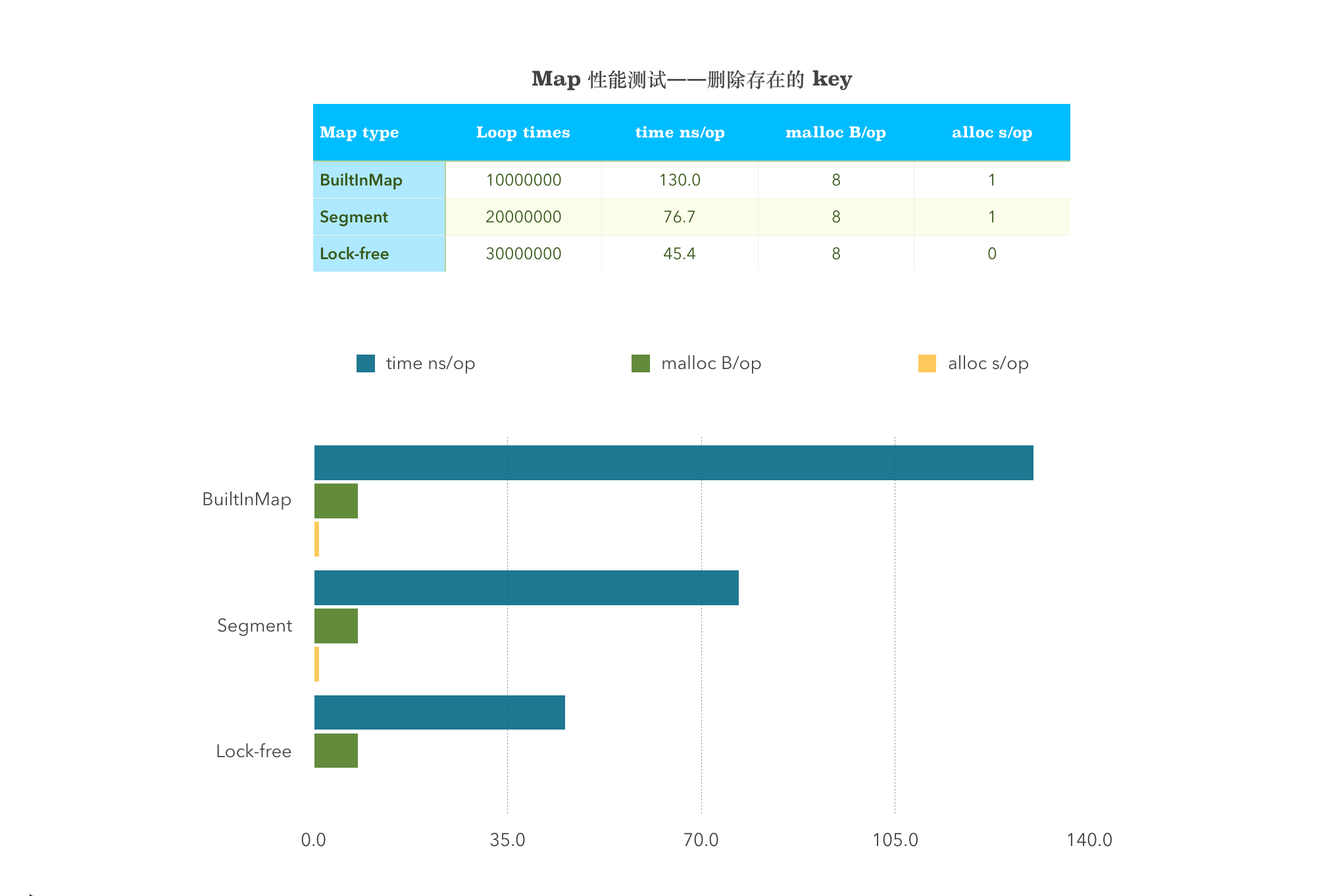
从图中可以看出,sync.map 在 Delete 这一项是完美的超过其他两者的。
六. 总结

本文从线程安全理论基础开始讲了线程安全中一些处理方法。其中涉及到互斥量和条件变量相关知识。从 Lock 的方案谈到了 Lock - Free 的 CAS 相关方案。最后针对 Go 1.9 新加的 sync.map 进行了源码分析和性能测试。
采用了 Lock - Free 方案的 sync.map 测试结果并没有想象中的那么出色。除了 Load 和 Delete 这两项远远甩开其他两者,凡是涉及到 Store 相关操作的性能均低于其他两者 Map 的实现。不过这也是有原因的。
纵观 Java ConcurrentHashmap 一路的变化:
JDK 6,7 中的 ConcurrentHashmap 主要使用 Segment 来实现减小锁粒度,把 HashMap 分割成若干个 Segment,在 put 的时候需要锁住 Segment,get 时候不加锁,使用 volatile 来保证可见性,当要统计全局时(比如 size),首先会尝试多次计算 modcount 来确定,这几次尝试中,是否有其他线程进行了修改操作,如果没有,则直接返回 size。如果有,则需要依次锁住所有的 Segment 来计算。
JDK 7 中 ConcurrentHashmap 中,当长度过长碰撞会很频繁,链表的增改删查操作都会消耗很长的时间,影响性能, 所以 JDK8 中完全重写了 concurrentHashmap,代码量从原来的 1000 多行变成了 6000 多行,实现上也和原来的分段式存储有很大的区别。
JDK 8 的 ConcurrentHashmap 主要设计上的变化有以下几点:
- 不采用 Segment 而采用 node,锁住 node 来实现减小锁粒度。
- 设计了 MOVED 状态 当 Resize 的中过程中线程 2 还在 put 数据,线程 2 会帮助 resize。
- 使用 3 个 CAS 操作来确保 node 的一些操作的原子性,这种方式代替了锁。
- sizeCtl 的不同值来代表不同含义,起到了控制的作用。
可见 Go 1.9 一上来第一个版本就直接摒弃了 Segment 的做法,采取了 CAS 这种 Lock - Free 的方案提高性能。但是它并没有对整个字典进行类似 Java 的 Node 的设计。但是整个 sync.map 在 ns/op ,B/op,allocs/op 这三个性能指标上是普通原生非线程安全 Map 的三倍!
不过相信 Google 应该还会继续优化这部分吧,毕竟源码里面还有几处 TODO 呢,让我们一起其他 Go 未来版本的发展吧,笔者也会一直持续关注的。
(在本篇文章截稿的时候,笔者又突然发现了一种分段锁的 Map 实现,性能更高,它具有负载均衡等特点,应该是目前笔者见到的性能最好的 Go 语言实现的线程安全的 Map ,关于它的实现源码分析就只能放在下篇博文单独写一篇或者以后有空再分析啦)
Reference:
《Go 并发实战编程》
Split-Ordered Lists: Lock-Free Extensible Hash Tables
Semaphores are Surprisingly Versatile
线程安全
JAVA CAS 原理深度分析
Java ConcurrentHashMap 总结
GitHub Repo:Halfrost-Field
Follow: halfrost · GitHub


若有收获,就点个赞吧
0 人点赞
