前面提到的数据传输是使用指令完成传输的,需要CPU参与,也就是需要CPU执行这样一条指令时,需要确定I/O设备是否准备就绪。但是CPU去确定I/O设备准备就绪的开销较大,因为每传输一个字大小的数据都需要执行多条程序指令(增加寄存器地址,记录字数,查询I/O状态或中断处理等)。
为了高速数据传输,使用另外一种方式,称为直接存储访问(DMA),当CPU需要与I/O设备进行传输的时候,不再自己亲自动手,而是给DMA传递一条指令,由DMA来控制传输,不需要CPU控制。
DMA在硬件实现在I/O设备接口的控制电路中,称为DMA控制器。
DMA被CPU调用去传输数据一块数据时,需要传递给DMA数据的起始地址,块内字数,传输方向等信息。得到控制信息之后,DMA开始执行指定操作,传输完毕产生一个中断信号通知CPU。
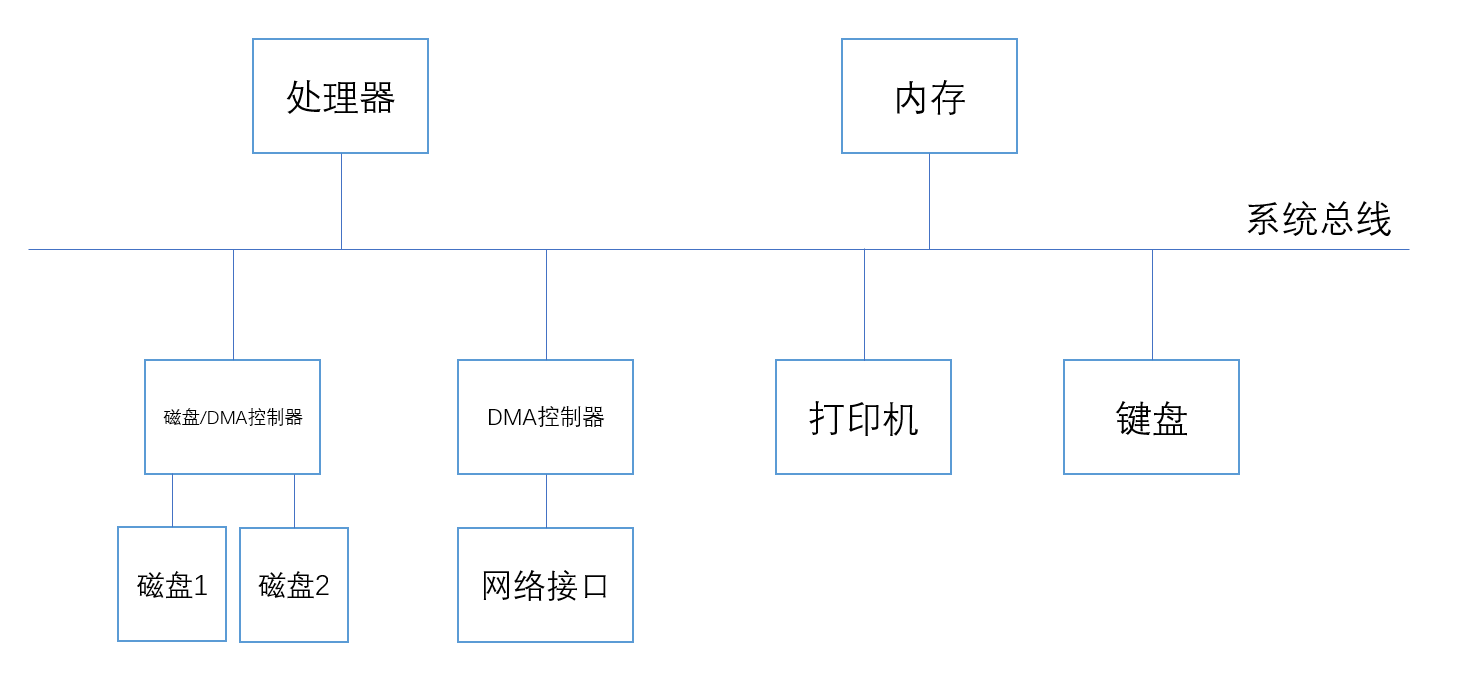
一个DMA控制器将网络接口连接到计算机总线上;磁盘控制器控制两个磁盘,同时具有DMA功能。
启动一次DMA数据传输,将数据从主存传送到其中一个磁盘,CPU将地址,字数等信息写入磁盘控制器相应的寄存器中,随后开始传输。CPU则可以去执行其他指令。
但是在DMA使用过程中,总线还是要使用的,也就是处理器和DMA要竞争总线使用权。
:::warning
这儿没整明白,CPU与DMA竞争情况下,总线的使用情况是怎么样的,资料暂时没找到,一种说法是CPU与DMA在一般情况下可以做到无竞争,CPU的cache使得CPU能够减少内存访问,同时内存也为DMA与CPU提供了不同的接口。使得互不影响。
:::
下面讨论多个设备竞争总线的情况,处理这种情况称为总线仲裁,主要分为集中和分布式仲裁
集中式仲裁
集中式仲裁的方案决定权在CPU中的总线仲裁器中,其仲裁方案与中断仲裁的方案类似。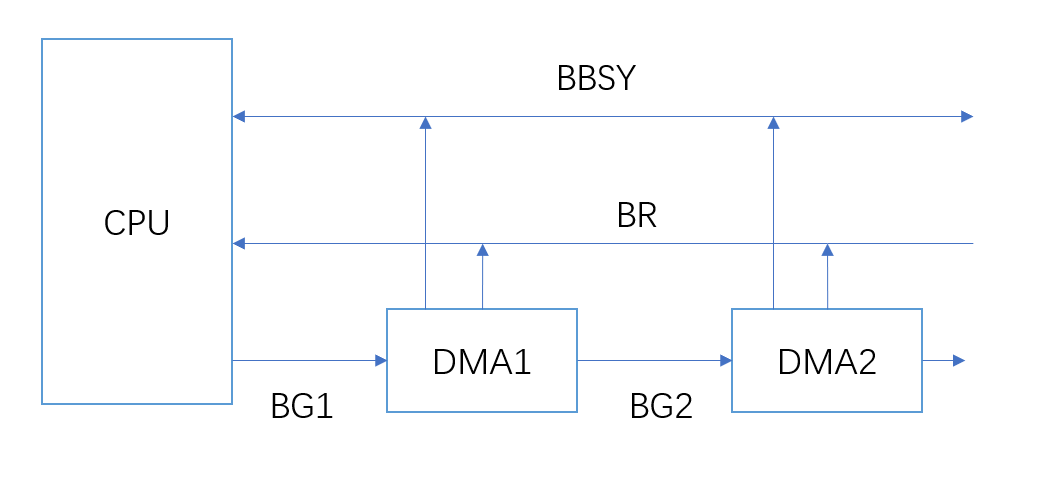
DMA2通过BR向总线仲裁器发起总线请求,CPU通过BG1返回信息表示可以在总线空闲时使用,DMA1接受到该信号但是自己并未发送总线请求,于是通过BG2线转发给DMA2,DMA2收到响应,截断该信号,不再转发。同时DMA等待BBSY的信号变为空闲,然后获得总线控制权,同时它激活BBSY通知其他设备表明总线正忙。传输完成之后,CPU重新获取总线控制权。
分布式仲裁
分布式仲裁中,所有设备都参与仲裁。
一种解决方案如下
每台设备分配一个4位ID,当两个设备同时请求总线使用时,设备激活START-ARBITRITION信号,随后加将自己的四位ID发送到总线上的ARB0-ARB3信号线上。
如设备A的ID为0101,设备B的ID为0110,两个设备都将ID传输到ARB0-ARB3上,信号线的结果是或操作的结果,即0111。设备A逐位比对,发现第三位开始不一样,于是撤销后两位信号,ARB0-ARB3上的信号变为0110,这表明设备B竞争胜利。
需要注意的是,信号线在短时间内仍然会是0111,B可能撤销第四位信号,但是一旦信号变为0110,B会重新激活第四位信号,竞争胜利。

若有收获,就点个赞吧
0 人点赞
