二进制取反相加
1+1=0,产生进位
0+0=0,0+1=0,1+0=0
最高位进位向最低位进位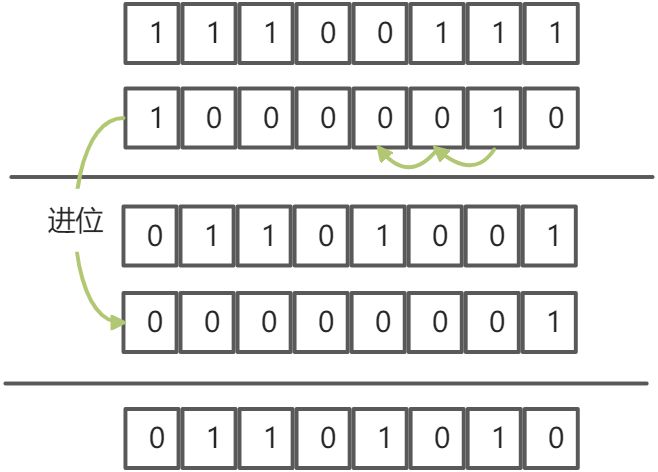
UDP校验和计算方法
计算内容
- 将UDP校验和位置为全0
添加伪首部12B | 源IP地址 | 4B | | —- | —- | | 目的IP地址 | 4B | | 0填充 | 1B | | 协议号17 | 1B | | UDP包长度(不含伪首部) | 2B |
如果需要,为数据字段填充0,使得数据字段长度为4的整数倍
- 将包含伪首部在内的整块UDP数据报以2B为单位进行切分,得到每个2B长的序列

- 对
 进行二进制取反相加
进行二进制取反相加 - 将结果取反作为校验和
:::info
一个有趣的发现,在UDP首部中本身就包含了UDP报文长度,但是为什么在伪首部中还要UDP长度呢?
为什么UDP校验和要计算两次UDP长度?——Stack Overflow
一个我觉得可信的答案就是伪首部原本是为TCP设计的,UDP的RFC(1980年8月)当时拿来就用了,毕竟方便嘛,可以认为这两长度是冗余的。他还提到,IPv4的RFC(1981年9月)是在UDPRFC出来一年多之后才出来的,历史因素也是原因之一。
:::
TCP检验和计算方法
计算内容
- 将UDP校验和位置为全0
添加伪首部12B | 源IP地址 | 4B | | —- | —- | | 目的IP地址 | 4B | | 0填充 | 1B | | 协议号6 | 1B | | TCP包长度(不含伪首部) | 2B |
如果需要,为数据字段填充0,使得数据字段长度为4的整数倍
- 将包含伪首部在内的整块UDP数据报以2B为单位进行切分,得到每个2B长的序列

- 对
 进行二进制取反相加
进行二进制取反相加 - 将结果取反作为校验和

若有收获,就点个赞吧
0 人点赞
