索引
应该用什么数据结构呢?
用二叉树?可以但是效率低。主要是IO的问题。一次读取一个节点的话,只有两个孩子的信息。
用平衡二叉树?好一些但是高度还是高,高度高就意味着IO次数高。
用B树?基本可以,但是范围查询不好做(索引不是都在最后一排)。
B+树保证IO次数少,查询某个元素的效率相同,不会偏高偏低。并且可以做范围查询。
key: IO次数 范围查询。
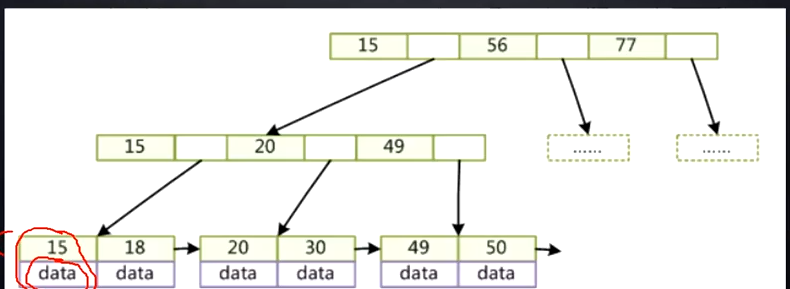
假设key是bigint类型,8字节。指针类型6字节。8+6=14字节,这是一组。
mysql的索引文件建议16kb,所以一个索引文件是1170个节点组。
第三层就可以有1170*1170个元素。
注意,Mysql的叶子结点的指针是双向的。
MyIASM的索引
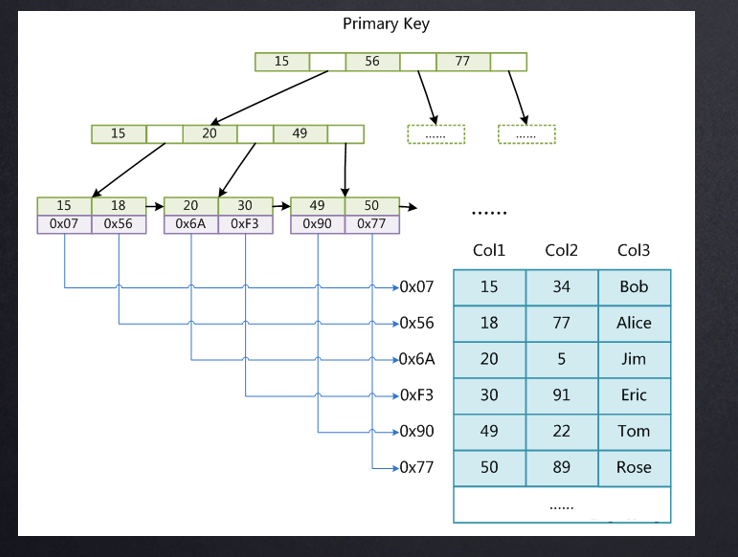
表结构、索引和数据分成了3个文件。也可以叫非聚集索引。
InnoDB索引
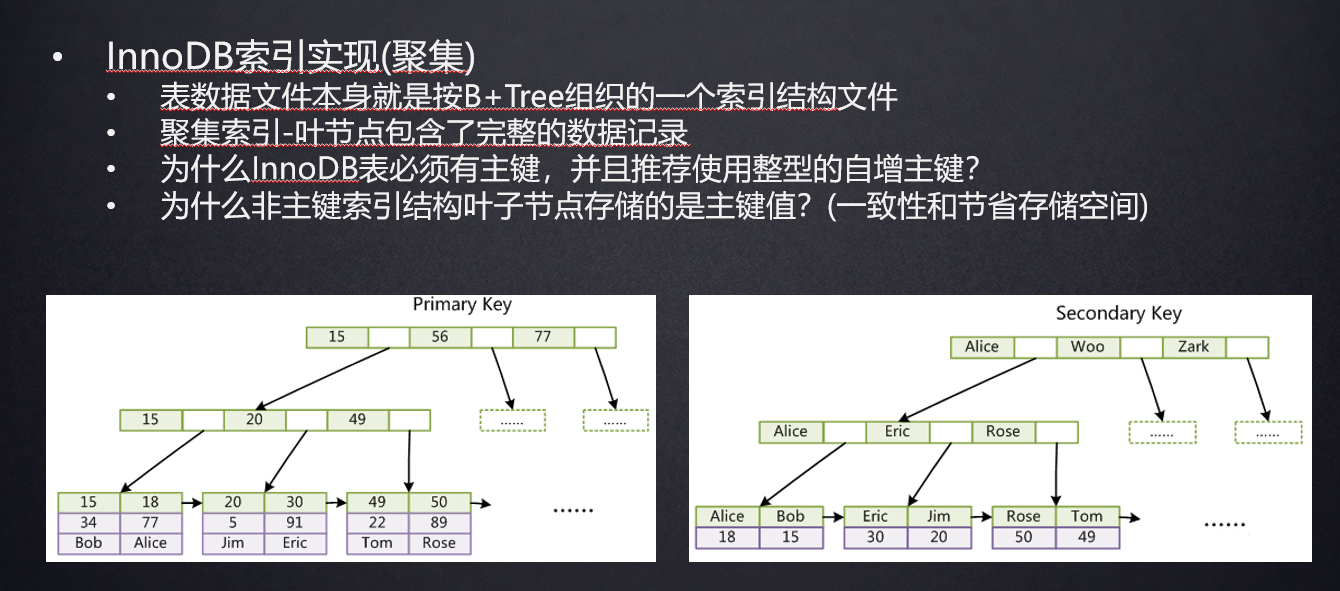
索引文件和数据文件是一个文件。
叶子结点包含完整的数据-聚集索引。
必须有主键是因为要建B+树。没有主键的话引擎会找一列唯一的列当索引。如果没找到用隐藏列rowid当索引。
推荐用自增整形的原因:
自增:为了防止B+树大范围的分裂。自增的话每次基本都插到最后,分裂范围小。
整形:比较方便。字符串的话比较不好比。
非主键索引存储的是主键的值。这是为了节省空间(要不然全部数据存了好几份)、便于维护一致性(否则你改主键那里还要把非主键的好几棵树都一起改了,很麻烦)。
联合索引
主键索引和非主键索引一个一棵树。联合索引是只有一棵树。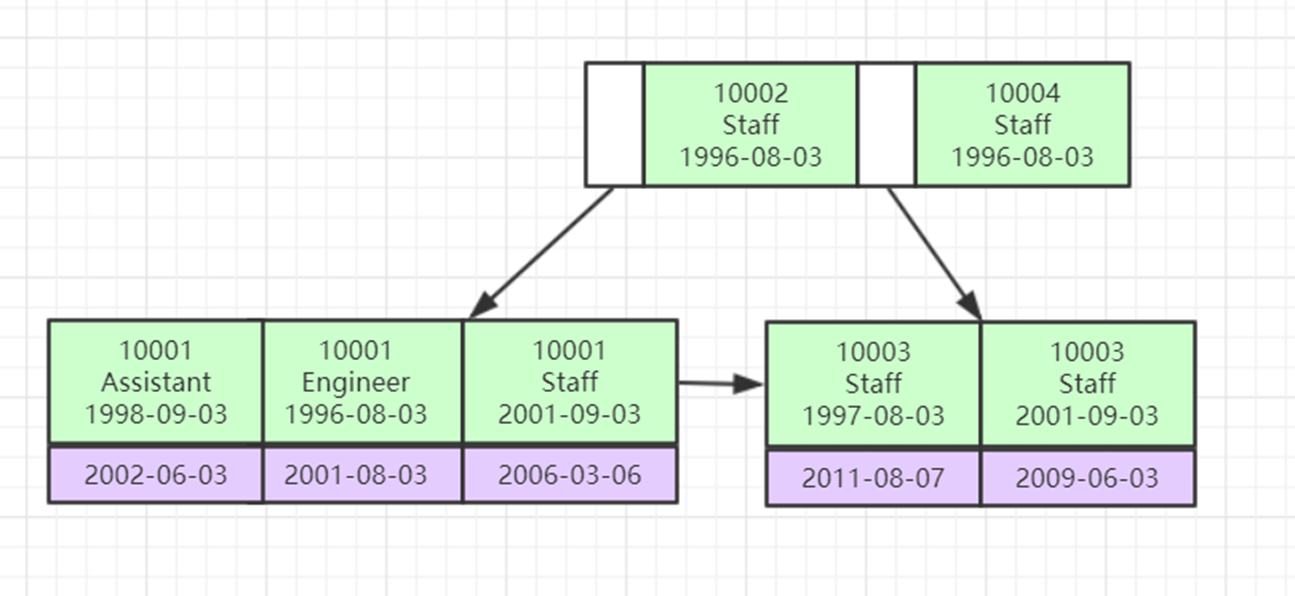
联合索引也是有序的。比较大小要按照建索引的顺序开始比。(也就是从左往右比。最左前缀)
最左前缀
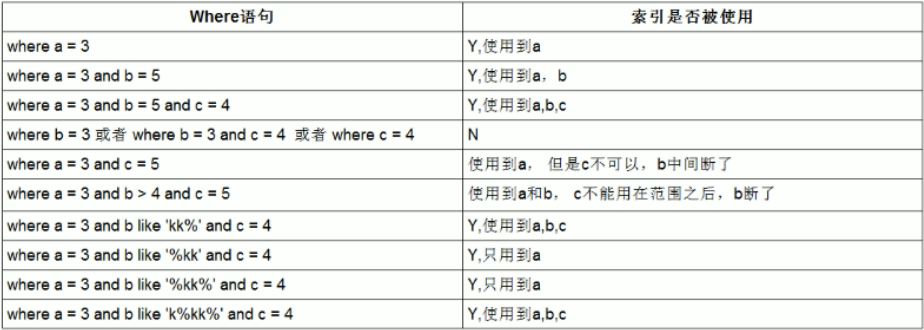
为什么有索引但是不走?
执行优化器扫描以后根据预估成本判断走索引的开销更大,所以不走。(比如select * 超过联合索引覆盖字段造成的回表问题)
通常可以考虑的优化点在让联合索引全覆盖。
OrderBy和GroupBy优化
1、MySQL支持两种方式的排序filesort和index,Using index是指MySQL扫描索引本身完成排序。index效率高,filesort效率低。
2、order by满足两种情况会使用Using index。 1) order by语句使用索引最左前列。 2) 使用where子句与order by子句条件列组合满足索引最左前列。
3、尽量在索引列上完成排序,遵循索引建立(索引创建的顺序)时的最左前缀法则。
4、如果order by的条件不在索引列上,就会产生Using filesort。
5、能用覆盖索引尽量用覆盖索引
6、group by与order by很类似,其实质是先排序后分组,遵照索引创建顺序的最左前缀法则。对于group by的优化如果不需要排序的可以加上order by null禁止排序。注意,where高于having,能写在where中的限定条件就不要去having限定了
UsingFileSort
单路排序:是一次性取出满足条件行的所有字段,然后在sort buffer中进行排序;
用trace工具可以看到sort_mode信息里显示< sort_key, additional_fields >或者
双路排序(又叫回表排序模式):是首先根据相应的条件取出相应的排序字段和可以直接定位行数据的行 ID,然后在 sort buffer 中进行排序,排序完后需要再次取回其它需要的字段;
用trace工具 可以看到sort_mode信息里显示< sort_key, rowid >
MySQL 通过比较系统变量 max_length_for_sort_data(默认1024字节) 的大小和需要查询的字段总大小来判断使用哪种排序模式。
如果 max_length_for_sort_data 比查询字段的总长度大,那么使用单路排序模式;
如果 max_length_for_sort_data 比查询字段的总长度小,那么使用 双路排序模式。
主从复制


若有收获,就点个赞吧
0 人点赞
