4-23
内存模型
Java线程之间的通信由Java内存模型控制,JMM决定一个线程对共享变量的写入何时对另一个线程可见。从抽象的角度来看,JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(Main Memory)中,每个线程都有一个私有的本地内存(Local Memory),本地内存中存储了该线程以读/写共享变量的副本。本地内存是JMM的一个抽象概念,并不真实存在。它涵盖了缓存、写缓冲区、寄存器以及其他的硬件和编译器优化。
具体的规则可以看happenes-before。
要注意的点
- 缓存一致性协议(如MESI)和Java内存模型没有必然关系。JMM既是规范,也是抽象。
- Java从源码到运行可能经历编译器重排序、指令重排序、内存重排序。了解JMM使得你可以不必学习缓存一致性协议、CPU流水线机制与指令重排、内存屏障等概念,只需要记住happens before等一系列基本规则即可。
ConcurrentHashMap——put
// put方法直接调用了这个final V putVal(K key, V value, boolean onlyIfAbsent) {if (key == null || value == null) throw new NullPointerException();//这里是高位与低位^操作。这是为了分布均衡。//否则的话如果单纯用hashcode,hashcode增长是有规律的。可能导致很多高位相关的桶利用率低。int hash = spread(key.hashCode());int binCount = 0;for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh; K fk; V fv;if (tab == null || (n = tab.length) == 0)//桶里没东西就初始化tab = initTable();else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {//如果桶里没有元素,CAS去设置头节点if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))break; // no lock when adding to empty bin}else if ((fh = f.hash) == MOVED)//如果hash是MOVED,说明在扩容移动元素,则让当前线程参与扩容tab = helpTransfer(tab, f);else if (onlyIfAbsent // check first node without acquiring lock&& fh == hash&& ((fk = f.key) == key || (fk != null && key.equals(fk)))&& (fv = f.val) != null)return fv;else {V oldVal = null;synchronized (f) {if (tabAt(tab, i) == f) {if (fh >= 0) {binCount = 1;for (Node<K,V> e = f;; ++binCount) {K ek;if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key, value);break;}}}else if (f instanceof TreeBin) {Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}else if (f instanceof ReservationNode)throw new IllegalStateException("Recursive update");}}if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}}}addCount(1L, binCount);return null;}
5.8
Synchronized和ReentratLock的区别
最直观的区别是,一个是关键字,一个是并发包里的类。
Lock有更好的拓展性,具体地,可以实现公平非公平、读写等针对业务场景的实现。
Synchronize是非公平锁,用户无法改变这点,这与它的底层实现有关。
此外,前者可以锁方法,后者只能锁代码块。
但Synchronized有个很大的优势,就是可以自动释放。因为忘记释放锁而产生死锁的场景是非常多的。
Synchronized底层如何实现?锁升级过程
https://blog.csdn.net/Ning862217083/article/details/123535229?spm=1001.2014.3001.5501
这里记录了以前的学习,大体记录了如何实现。主要是依靠虚拟机的monitor对象去抽象一个内核级的锁。(Linux的话,就是mutex)
锁升级过程网上已经有很多图了。其实主要就是修改对象头的markword。偏向锁就只修改markword成线程Id,轻量锁则是在线程栈里开辟空间,存储lock record,让他和markword互相引用。
线程池有哪几种?分别什么特点
https://www.cnblogs.com/gujiande/p/9488462.html
其实只要搞清楚线程池的构造器参数就可以了。
手写快速排序?多线程快速排序?
private void quickSort(int[] arr, int l, int r) {if (l >= r) return;int i = l - 1, j = r + 1, mid = l + r >> 1;while (i < j) {while (arr[++i] < arr[mid]);while (arr[--j] > arr[mid]);if (i < j) {swap(arr, i, j);}}quickSort(arr, l, j); // have to be j!quickSort(arr, j+1, r);// 因为快排固定好了位置,所以左右递归可以让新的线程去做}
5.15
ForkJoinPool
fork就不多说了,和linux下创建子进程的系统调用是一个意思。克隆本身的树和fork的树也是一样的。
join意思是把结果合并。
总体来说是分派任务给多个线程去计算然后合并。
比较重要的一点是工作窃取,就是每个线程完成了自己的任务后还会去队列里取别的任务。
CF
cf主要是对Future的加强。类似于Stream对Collection的加强。
假如我们有三个异步任务,分别是a b c,我们想希望用a和b的结果作为参数传入c。
这种需求如果你用future做是比较麻烦的,但是用cf的类流式操作,可以很快很优雅的把各种任务combine到一起。
归并排序
import java.util.Arrays;import java.util.stream.Collectors;public class Main {public static int[] tmp;public static void main(String[] args) {int[] arr = new int[]{2,3,4,5,1,7,8,6,9,10};tmp = new int[arr.length];mergeSort(arr, 0, arr.length-1);System.out.println(Arrays.stream(arr).boxed().collect(Collectors.toList()));}public static void mergeSort(int[] arr, int l, int r) {if (l >= r) {return;}int mid = l + r >> 1;mergeSort(arr, l, mid);mergeSort(arr, mid+1, r);merge(arr, l, r);}public static void merge(int[] arr, int l, int r) {if (l >= r) return;int mid = l + r >> 1, i = l, j = mid+1, k = l;while (i <= mid && j <= r) {if (arr[i] <= arr[j]) {tmp[k++] = arr[i++];} else {tmp[k++] = arr[j++];}}while (i <= mid) {tmp[k++] = arr[i++];}while (j <= r) {tmp[k++] = arr[j++];}for (i=l; i<=r; i++) {arr[i] = tmp[i];}}}public static void mergeSortAsync(int[] arr, int l, int r) {if (l >= r) return;int mid = l + r >> 1;ForkJoinTask<?> t1 = forkJoinPool.submit(() -> mergeSortAsync(arr, l, mid));ForkJoinTask<?> t2 = forkJoinPool.submit(() -> mergeSortAsync(arr, mid + 1, r));try {t1.get();t2.get();merge(arr, l, r);} catch (ExecutionException | InterruptedException e) {e.printStackTrace();}}
5.22
IoC
ioc是控制反转。控制指的是管理对象生命周期的能力,反转指的是把对象生命周期的管理交给容器。
IOC在编写大规模的程序时才能发挥力量。具体地,当大部分对象的创建都依赖于大量其他对象时,如果手动去set是很劳累的事情。
解决循环依赖
其实这很自然
A a = new A();B b = new B();a.setB(b);b.setA(a);
只要我们先创建对象,后调用setter就可以了。
https://blog.csdn.net/weixin_43966635/article/details/118608808
AoP
面向切面编程,意思是我们需要提取一些公共操作,然后让所有符合条件的函数都去执行这些操作。
这是一种很常见的编程思想。我们经常会把打印日志等操作抽取成公共的。
像Golang的gin框架大量的使用了中间件这个概念,一个中间件可以被认为是一个函数。在每个操作后调用这些函数即可。
具体地, AoP的实现依赖于动态代理。动态代理的实现方法有Jdk自带和Cglib修改字节码这两种。如果用Jdk动态代理要求被代理对象实现了某个接口。
5.29
画循环依赖的图
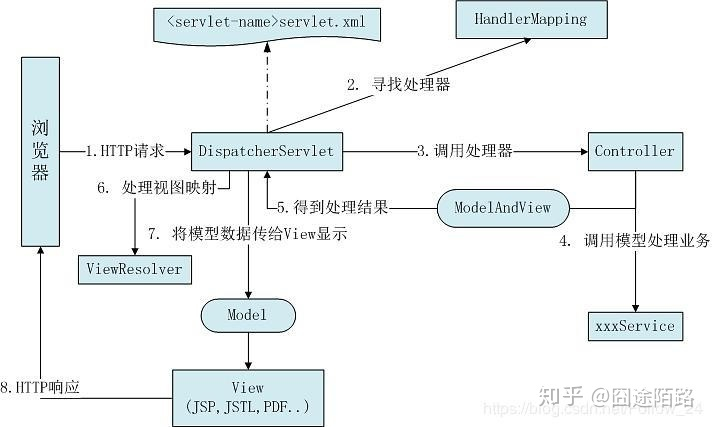
SpringMVC执行流程
SpringBoot与SpringFramework的关系
SpringBoot简化了配置,日常开发大多数的参数是不会变动的,这部分参数就用默认值。
也就是“约定优于配置”。即使需要配置的部分,大多也以注解完成。
6.12
spring boot 启动流程
说实话实在太长了。。。
启动流程
spring boot如何内嵌tomcat
6.19
SpringCloud 常用组件
https://www.kancloud.cn/hanxt/springcloud/1599297
CAP
CAP分别是一致性、可用性、分区容错性。
三者只能取其中二者。
一些具体解释
分布式一致性算法
主要是raft和pacos的变体
分布式一致性算法

若有收获,就点个赞吧
0 人点赞
