C2 硬件结构
特权级
EL0 1 2 3, 分别对应用户态, 内核态,HyperVisor和Trust
EL0到EL1的转换方法
同步:系统调用、异常 触发异常时会查找异常向量表,找到异常处理函数
异步:中断
缓存行
通常由两部分组成,一个有效位和一个标记地址。有效位代表是否有效,标记地址代表物理地址。
IO与中断
MMIO
OS会把IO设备映射到内存空间中,这样可以通过读写内存的方式把数据存储到外设里。外设通过监听总线,完成CPU的请求。
注意MMIO只是把数据写到外设里,不能感知到数据来临
如何获取外部的写入数据?
轮训那些内存地址或中断
C3
C4
为什么需要虚拟内存
计算机中有多个程序在运行,如何分配物理内存给他们呢?
方法A:每个程序都可以使用全部的物理内存。切换的时候把内存的数据刷盘。这样做安全,简单,但是速度慢。
方法B:每个程序只能用一部分物理内存。这样做速度快,但是无法保证各个程序之间的隔离性,不安全。
综上,需要虚拟内存机制。提供安全、高效的方法让程序访问内存。
虚拟内存
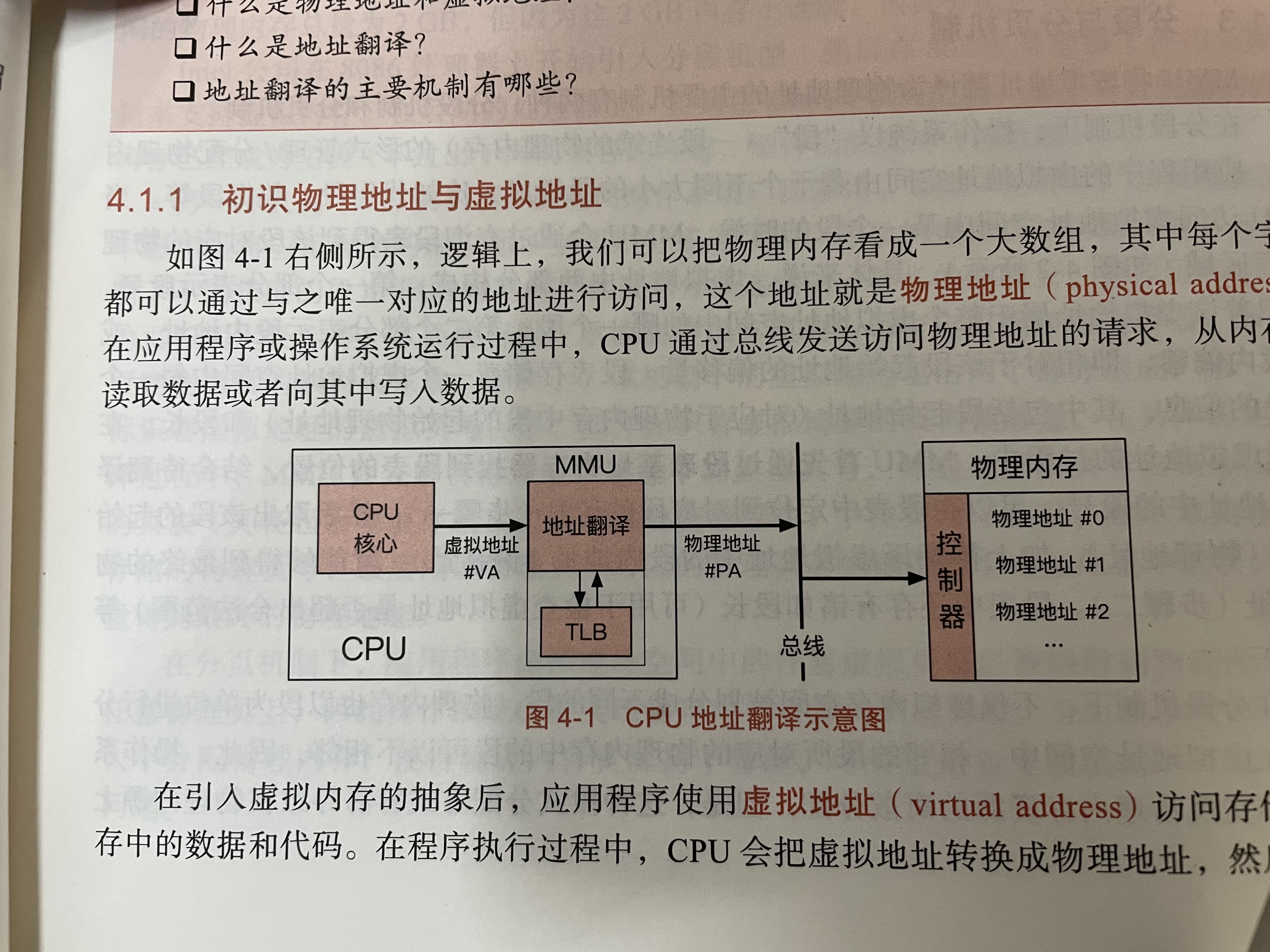
(TLB 转址旁路缓存)
分段内存管理
因为虚拟地址空间会被分成不同的段,如代码段、数据段等,可以根据这些段来管理内存。
具体的,我们有段表,段表每行有段号、段起始地址、段长。
应用程序的虚拟地址自然就包括了段号和段内偏移两部分,通过查找段基址寄存器,可以知道段表的起始位置,然后根据段号和段内偏移获得物理地址。
这种方式简单,但是有外部碎片。8086那个时候用,现在基本废弃,硬件保留寄存器(为了前向兼容)
分页内存管理
在这种思想下,虚拟内存和物理内存都被分为无数个大小相同的物理页。
找物理地址的时候,只需要根据每个进程私有的页表去找就可以了。
具体地,虚拟地址包括页号和页内偏移,根据页表基址寄存器去找页表的位置,再用页内偏移计算一下即可。
个人理解,段表是全局的,页表是进程私有的。
多级页表
单级页表太浪费内存了,所以需要多级页表。
多级页表就是把页号分成了几个部分而已。
AArch64分页内存管理
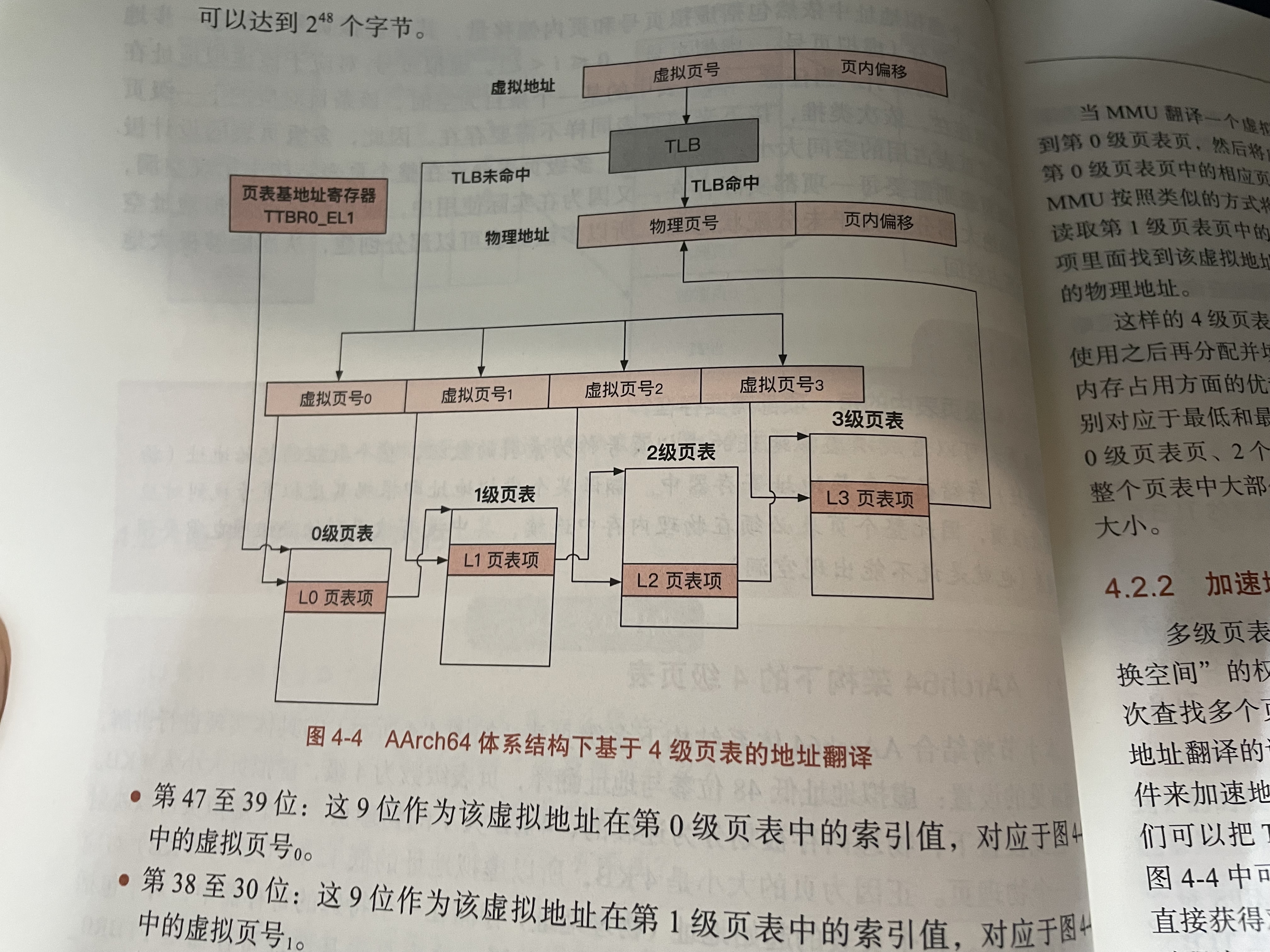
AArch64的低12位是页内偏移,也就是4KB。这意味着每个页是4KB
AArch64有4级页表,页表项大小是8B。4KB的页可以存下512个页表项,所以每一级页表需要9位
12 + 4 * 9 = 48,低48位参与地址翻译。剩下的位多是标志位,用于标记这个页可读/写/执行/标记是否写时拷贝等。
如果大页,8KB的话,低13位页内偏移,其他的每个页有10位。
TLB加速
每次通过MMU把虚拟地址变成物理地址是很大的开销,因此我们有TLB。TLB可以缓存我们查找过的虚拟页号。TLB就像哈希表,保存了虚拟地址到物理地址的映射。
然而,因为不同的应用程序可能使用相同的虚拟地址,因此在切换进程的时候需要进行TLB的刷新。
规避TLB刷新
可以在TLB存储的项的每一行加上进程独有的ASID(Address Space Identifier),这样不同进程的缓存可以共存(不冲突的情况下)。
当然,如果每个应用程序都使用了全部的TLB空间(比如树莓派只能有1000多个TLB项,也就是1000多个页,4MB的内存),那就没办法了。但这种情况比较少。
换页、缺页异常
考虑两个场景
场景1:我们打开多个程序,多个程序需要的内存量大于我们的物理内存大小,OS怎么让我们可以这么玩的呢?
场景2:我们写的程序一次性申请了大量的内存,OS如何让宝贵的物理内存不被浪费呢?
答案是通过换页。
我们可以把虚拟页对应的物理页暂存到磁盘上,然后去除掉页表里虚拟页对应的物理页。
在应用程序访问到这个页的时候,会触发缺页异常。可以分配空闲的物理页或根据换页的方式搞出一个物理页,把它赋给页表中对应的虚拟页号。
换页的优化
1 预取机制
根据局部性原理,我们可以一次取出大量的磁盘上的物理页。
2 按需页分配
当我们申请内存的时候,可以先分配虚拟页,不分配物理页。
换页的问题
情况1:我们的页表中,有的虚拟页是没有对应物理页的。比如物理页刚被换走。
情况2:有的虚拟页是根本不在页表里的。比如第一次分配这个虚拟页。(这里需要解释一下,比如我们在堆区新分配了4KB,那之前的结束地址里肯定是不包括这4KB的)
OS如何区分这两种情况呢?
在Linux中,内核会记录一个应用程序不同虚拟内存区域(比如堆 栈 数据 代码)的起始地址和结束地址。我们可以看看这个虚拟地址是否在虚拟内存区域里,如果在,就是情况1,如果不在,就是情况2。
页的替换
虚拟内存功能
共享内存
两个进程的各自有一个虚拟页,指向同一块物理页。这样他们可以开开心心的共享数据。
写时拷贝
fork进程的时候直接复制页表,把子进程的页表的所有页表项的虚拟页的高位都变成只读的。这样写的时候再更新物理页即可。
内存压缩
OS会把一些用的少的页压缩。对Linux来说,会放到ZSwap区。这样在换出的时候,先压缩放到ZSwap区,再考虑是否存到硬盘。不仅有几率节省磁盘IO,即使还是磁盘IO了,整体速度也更快。
大页
可能是几M甚至1G等大小的页,OS也可能把4KB的小虚拟页合成大页。
这样的好处是可以节省TLB缓存行,坏处是不一定用这个大页,另外不好管理内存。
物理内存分配与管理
物理内存分配器一方面要避免外部碎片和内部碎片,另一方面分配速度也要够快。
分配大内存(从4KB开始,到几十KB 甚至更多)时用伙伴系统,小内存时用SLAB。
伙伴系统
把多个页合成一个块。块是分配内存的基本单元。
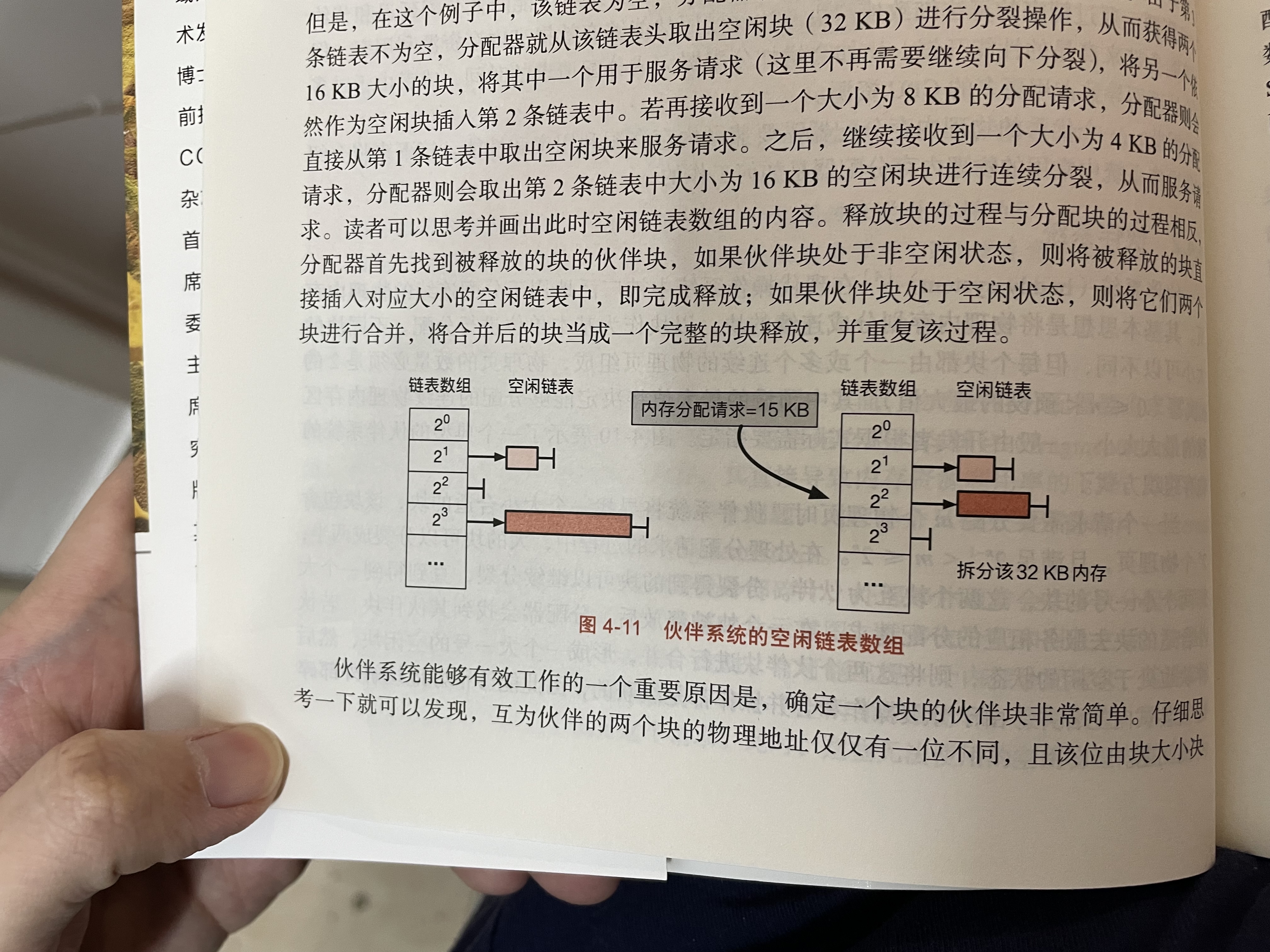
整体结构是数组+链表。
分配的时候可以把大块拆成两个小块,插入到下一级里。回收的时候可以把小块直接插入到链表中,也可能和伙伴块合并,然后插入上一级链表中。
SLAB(SLUB)分配器
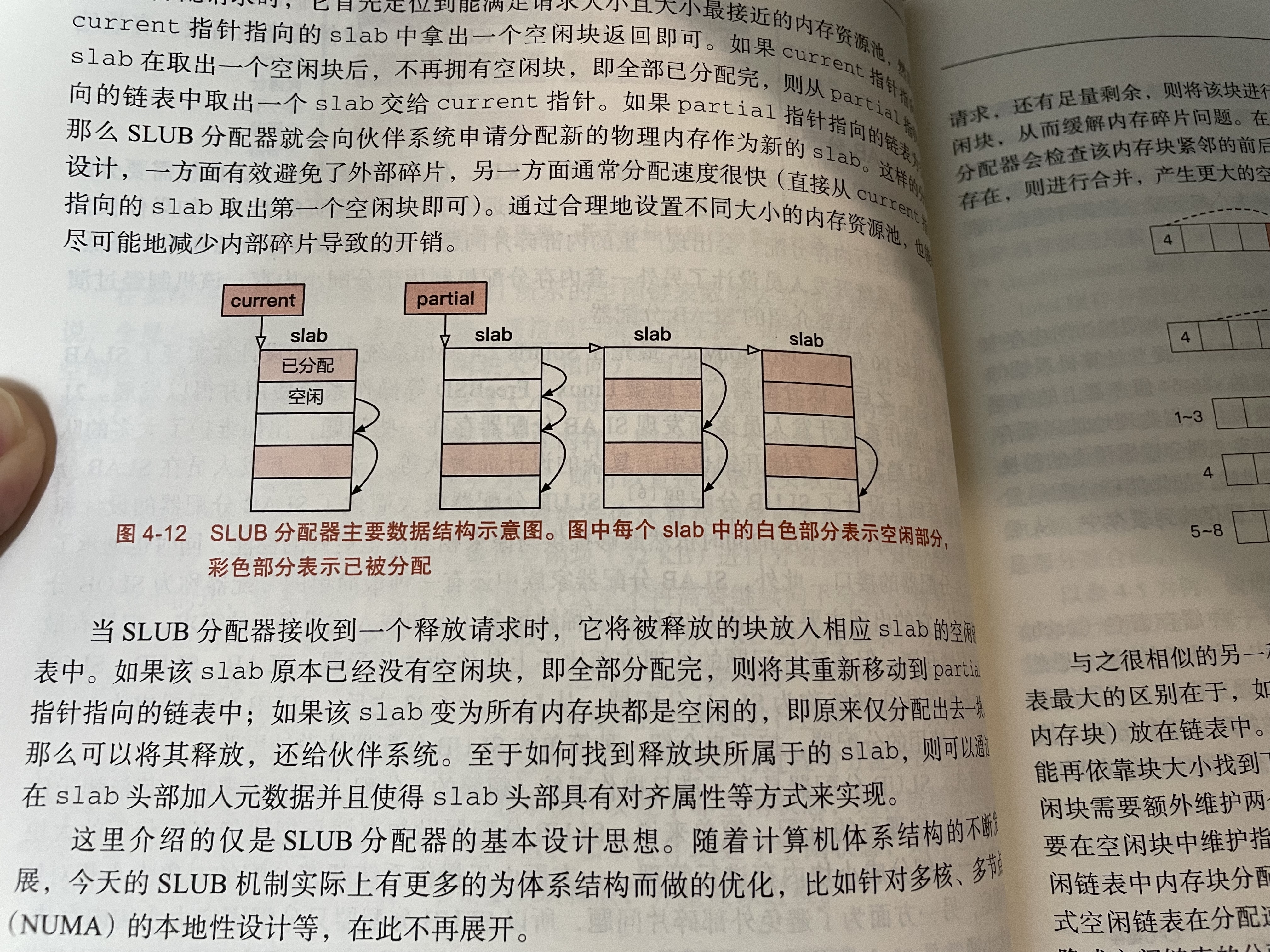
SLUB分配器会从伙伴系统里拿一块内存当做slab。slab会被分成很多小块。
我们有一个slab链表,链表头是partial。这相当于备用池。
还有一个链表节点,叫current,指向现在用的slab。
当需要分配内存时,从current指向的slab里分配一小条即可。如果current指向的slab没有空闲内存小条了,则让current指向partial里的下一块slab。如果partial也空了,重新从伙伴系统找个slab。
归还内存的时候,简单的更新current指针指向的slab即可,如果该slab里的小条原来都分配出去了,自己归还后又有了空闲小条,则可把它放回到partial链表里。
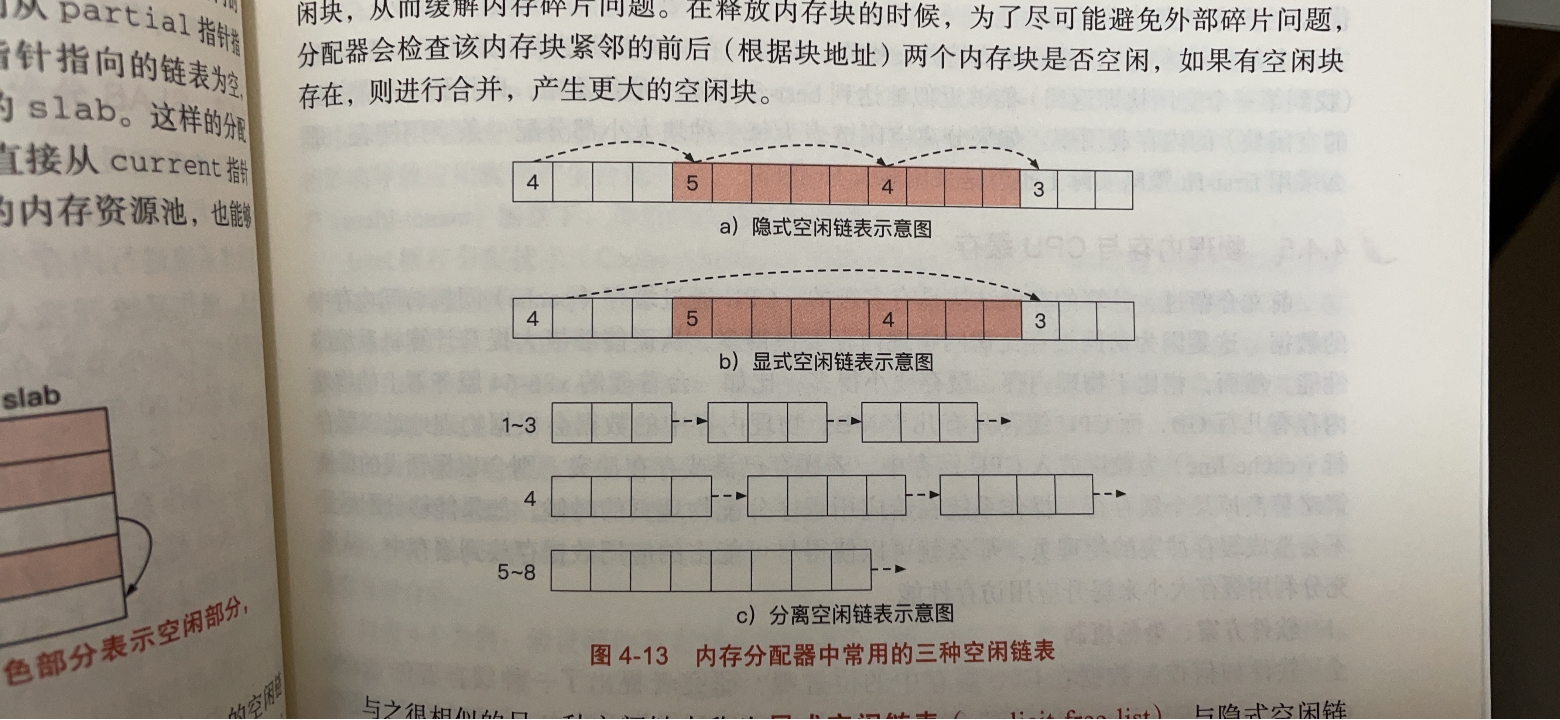
空闲链表(这些多用于用户态)
C5
进程
进程的状态

唯一的难点就是新生态到预备态(也就是新生->初始),这个是初始化数据结构的过程,别的都知道了。
进程的内存空间布局
 注意图里没标出共享内存、内存映射之类的区域。这些区域是匿名的。
注意图里没标出共享内存、内存映射之类的区域。这些区域是匿名的。
线程
为什么有了进程还要有线程?
1 创建进程的开销大,创建进程需要初始化栈、堆、载入数据、代码。
2 进程间的地址空间是隔离的。这意味着想要通信就要通过进程间通信手段,如共享内存等来实现。效率低。
用户态线程与内核态线程
内核态线程由内核创建,直接受操作系统调度器管理。
用户态线程是应用创建的,内核不可见。因此不受调度器管理。
用户态线程肯定更轻量,但是功能也少。需要与内核态线程协作,来实现一些功能,如系统调用。
为了协作,操作系统会建立两种线程直接的关系,也叫多线程模型,有一一 多一 多多。
多对一最简单,但是同一时刻只能有一个用户级线程与内核交互。效果差。
一一是最常见的。
多对一可以把较多的用户级线程映射到较少的内核级线程上。
TCB
内核态的线程的TCB和PCB差不多。
用户态的TCB主要看线程库实现。
fiber
由于内核态线程和用户态线程通常是一对一的,所以用户级线程通常也就直接受到CPU调度器的影响。
但事实上,应用程序也许可以比CPU更好地对线程进行调度。
此外,切换用户级线程的开销小。
因此fiber也就是用户态线程(不与内核态线程连接)
程序语言提供的fiber叫协程。
C6
计算机的调度主要有任务调度 IO调度和内存调度
C6主要介绍操作系统调度。
C7
主要是进程间通信
通信方式有:
管道、消息队列、信号量、共享内存、信号、套接字。
管道(特点:父子进程、两个fd)
管道会提供文件描述符让用户态程序使用,但实际上驻留在内存中,不走文件系统。
管道会返回两个文件描述符,一个读一个写。
通常的使用方法是先创建管道,然后fork。这样的话父子进程都可以拥有两个文件描述符,可以对管道进行读写操作。注意,读数据的时候可能阻塞,也可能返回EOF。这是因为写的进程可能把写端关闭了。。。
命名管道可以解决这个问题,创建命名管道就像创建一个文件一样。
消息队列(特点:消息抽象,多个发送者、接收者)
消息队列可以同时存在多个消息发送者和接收者。
消息队列是个链表结构,链表内有大量的消息结构体。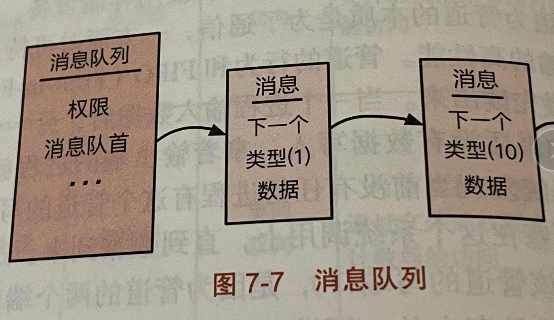
消息的类型对OS内核来说是不可知的,用户程序之间协商好就可以了。
信号量(特点:提供强制同步)
共享内存(性能好,没有抽象)
其他的通信机制都需要内核参与,另外对数据也做了抽象。这样性能会有损失。
直接操作内存基本没损失的。
信号(单向、信号集)
信号一般是单向的,主要是做通知。
内核的信号处理时机一般是从内核态返回到用户态的时候,转去处理信号,然后返回用户态之前执行的程序。
信号有两个集合,阻塞信号集和未决信号集。阻塞信号集可以让我们有能力拒收一些信号,当然SIGINT和SIGSTOP不行。
未决信号集相当于缓存,但是同类信号只能缓存一个。
当CPU执行完内核态下的中断、异常之类的事情时,会处理未决信号集,拿它与阻塞信号集做运算,处理那些不被阻塞的信号。
socket(远程网络通信等)
C8
同步指的是并发的任务需要按照一定次序先后访问共享资源。
这样可以保证程序在多线程执行下的结果的正确性。
为了实现同步,需要下面的同步原语
互斥锁
任意时刻最多允许一个线程访问的方式被称为互斥访问。这些线程访问的代码区域被称为临界区。
实现互斥锁的三个条件:互斥访问、有限等待、空闲让进
互斥锁实现方式
硬件方式:关闭中断
纯软件方式:皮特森算法
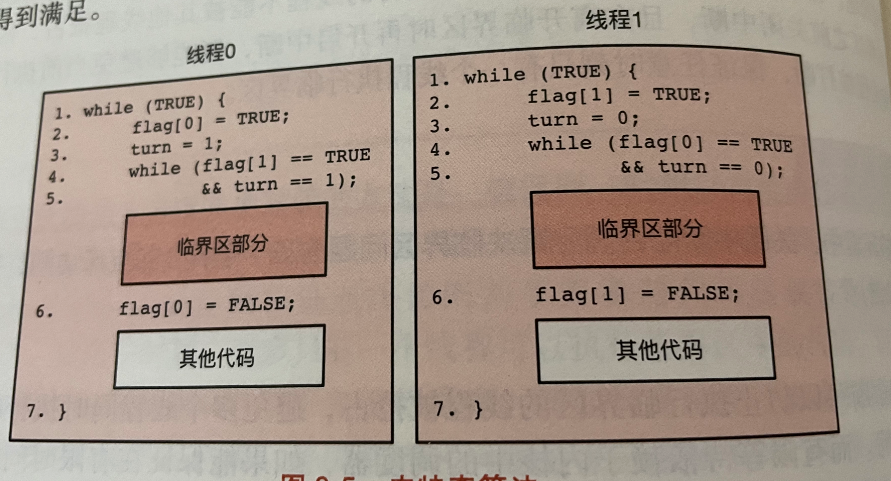
flag表示当前线程是否请求进入临界区
turn表示让哪个线程进入临界区
皮特森算法只能解决两个线程情况下的互斥问题。此外,还必须禁止CPU的指令重排。
软硬件协同->原子操作实现互斥锁
如CAS、Fetch And Add等
对CAS来说,Intel平台使用带lock前缀的指令实现CAS,如lock cmpxchg
AArch64使用LL/SC或新的LSE指令。
条件变量
互斥锁的实现通常是依靠CAS同步原语。这样抢不到互斥锁的线程通常要一直自旋。为了避免长时间自旋,需要条件变量这种机制来让线程阻塞。
这就提醒自己其实加锁和条件变量是两回事。一个解决同步问题,保证正确性。一个解决忙等问题。(指的是力扣多线程那道题)
条件变量必须搭配锁使用。一个条件变量搭配一把锁。
信号量
信号量是用来辅助控制多个线程访问有限数量的共享资源的。
信号量可以由条件变量和互斥锁来实现,也就是说信号量利用条件变量实现了更高层次的抽象。
读写锁
知道概念暂时应该就可以了
管程
管程包含两部分,一部分是共享的数据,另一部分是操作共享数据的函数。
Java里的管程的实现是基于synchronized关键字的。
死锁
4个条件
互斥访问 不可剥夺 保持请求 循环引用
C9
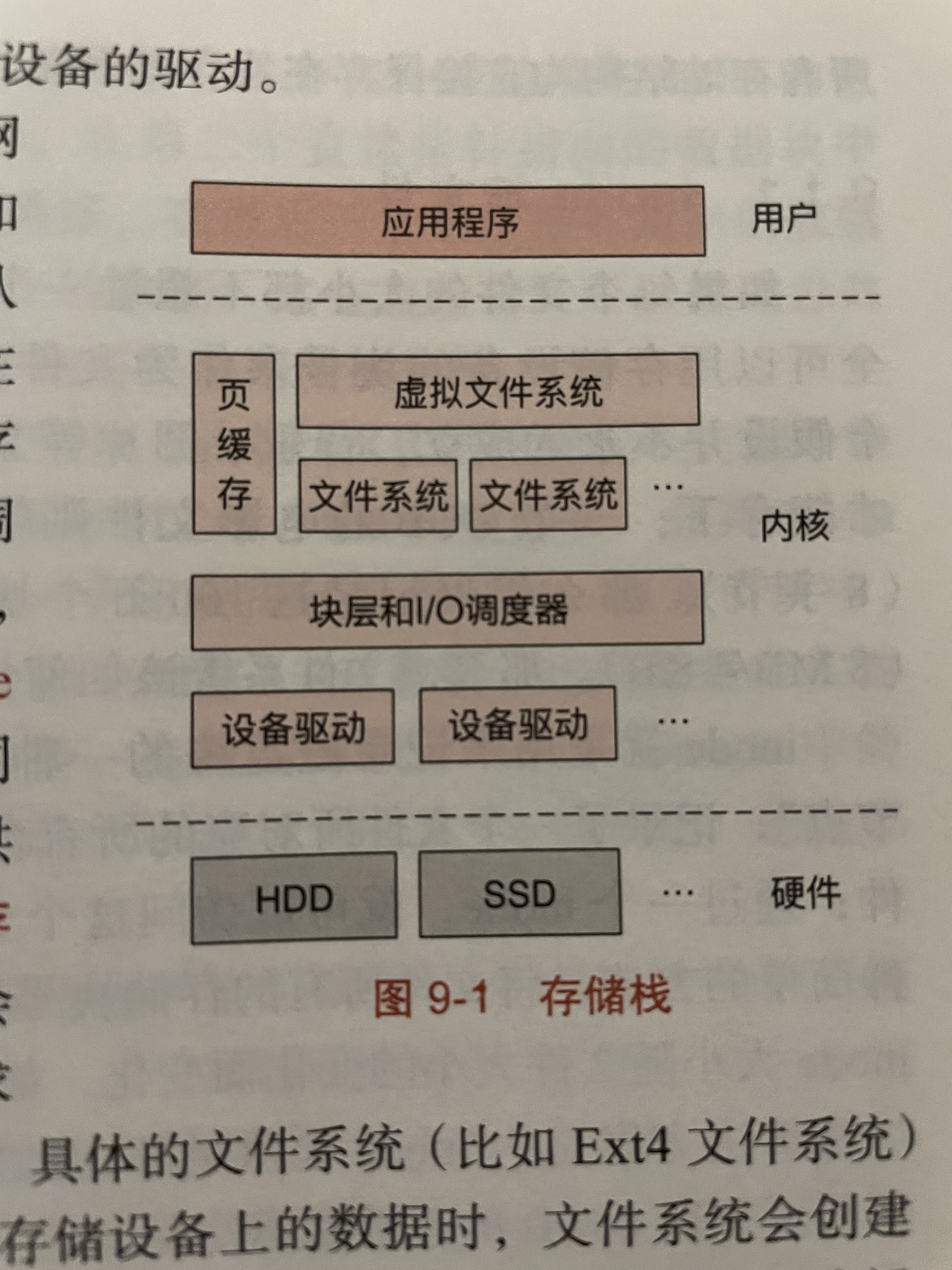
基于inode的文件系统
inode
inode就是index node,记录一个文件用到了哪些块。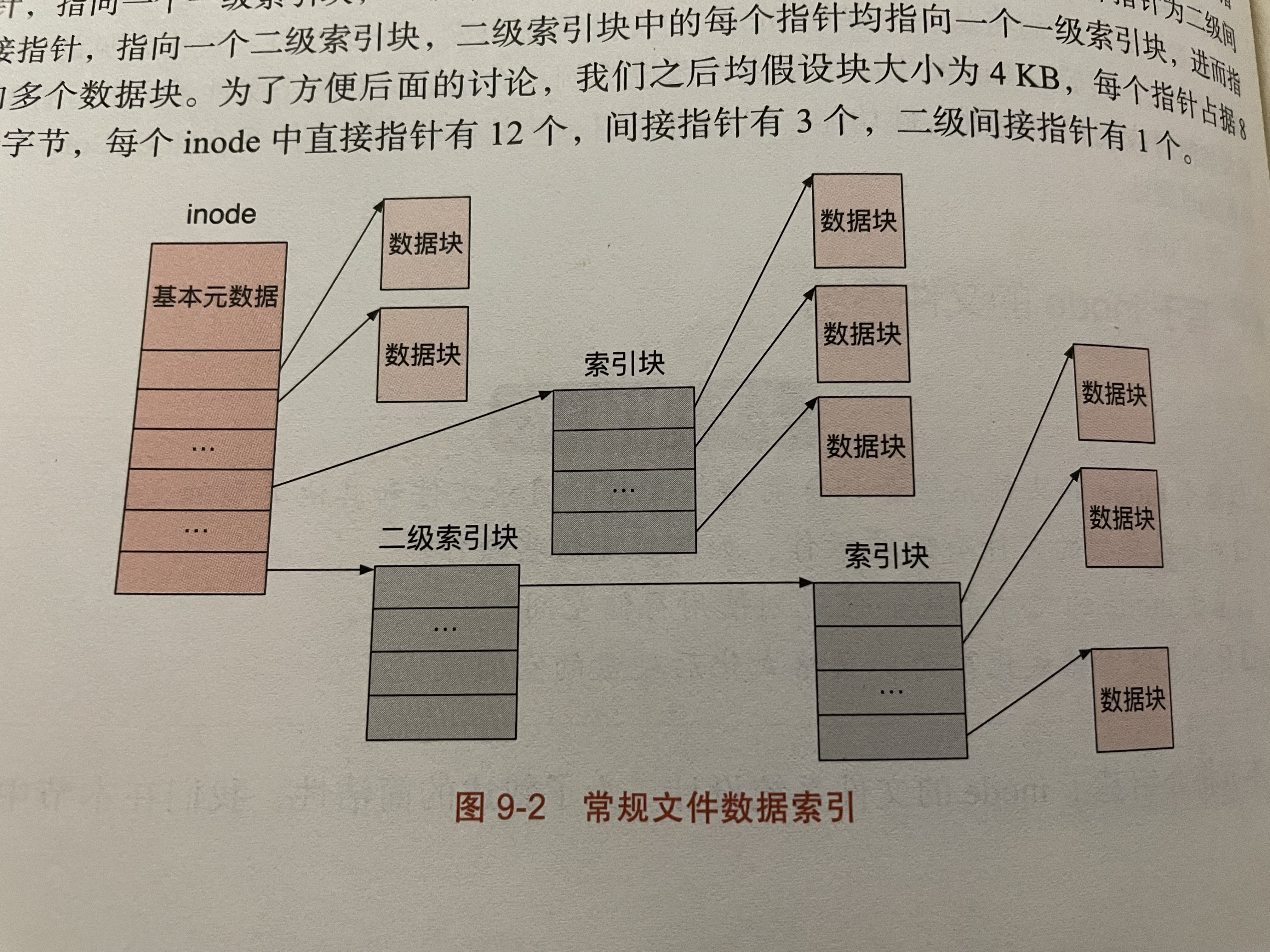
inode节点里有12个直接指针,3个一级指针,1个二级指针。
每个块4kb,12个直接指针能保存文件的48kb
一级索引块里全是直接指针。每个指针指向4kb的块,一个指针8b,也就是说一个索引块能存储2M的数据
3个一级索引块就是6M
二级索引块能保存1G
由此可看出,单个文件最大大小受OS表示的限制。
文件的元数据包括文件模式,链接数,用户ID,用户组ID,文件大小,最近访问时间,最近修改时间,文件元数据最近修改时间等等。但是不包括文件名!
文件名与目录
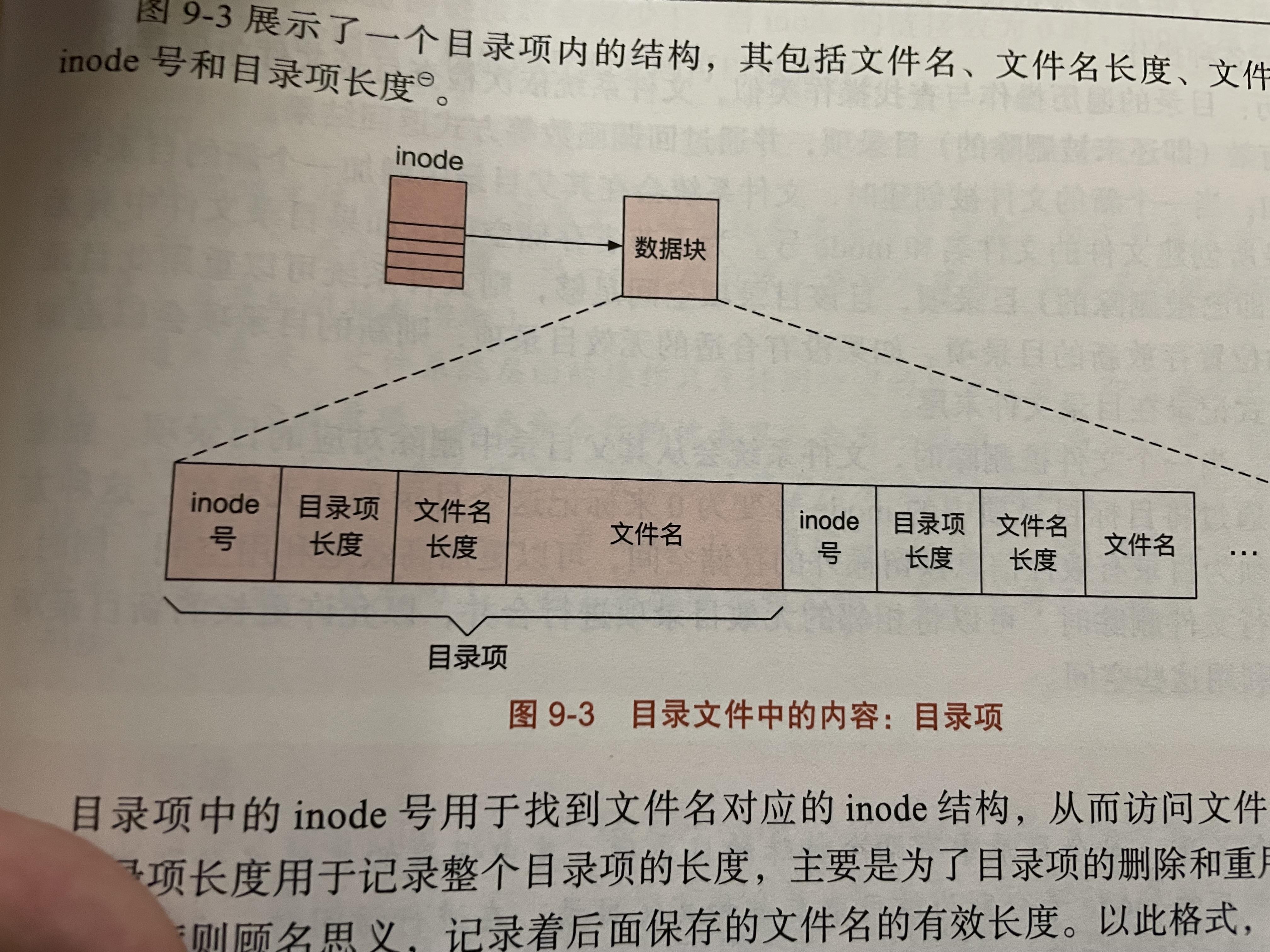
硬链接与软链接
硬链接:多一个目录项,保存相应的inode。只有一个inode没有任何硬链接指向了,才会被删除
命令:ln filename linkedNewFileName
软链接:创建一个文件,保存字符串(路径),被指向的文件称为目标文件。
硬链接必须和指向的文件在一个目录系统里。软链接不必。硬链接创建的目录项和原有目录项地位相同。
软链接可以指向不存在的地方。
补充 磁盘调度算法

C10
计算机设备的连接和通信
可编程IO
CPU通常通过读写设备寄存器的方式与设备通信。
访问设备寄存器的方式一般有两种,一种是通过内存映射,另一种是通过端口映射IO。端口映射IO就是通过指令直接操纵端口了。
DMA
直接内存访问。
本质是在内存中开辟一块区域,设备的IO都由这块内存和设备来完成。CPU不参与IO过程。
设备完成IO后以中断方式通知CPU。
在设备与内存IO的过程中,有可能需要DMA控制器的参与,让它获得总线的控制权。这种叫做第三方DMA。不需要DMA控制器的是第一方DMA。
IOMMU
设备访问的地址是总线地址。总线地址对应到物理内存需要IOMMU。如果没有IOMMU的话,就只能访问到物理内存中的一段固定范围。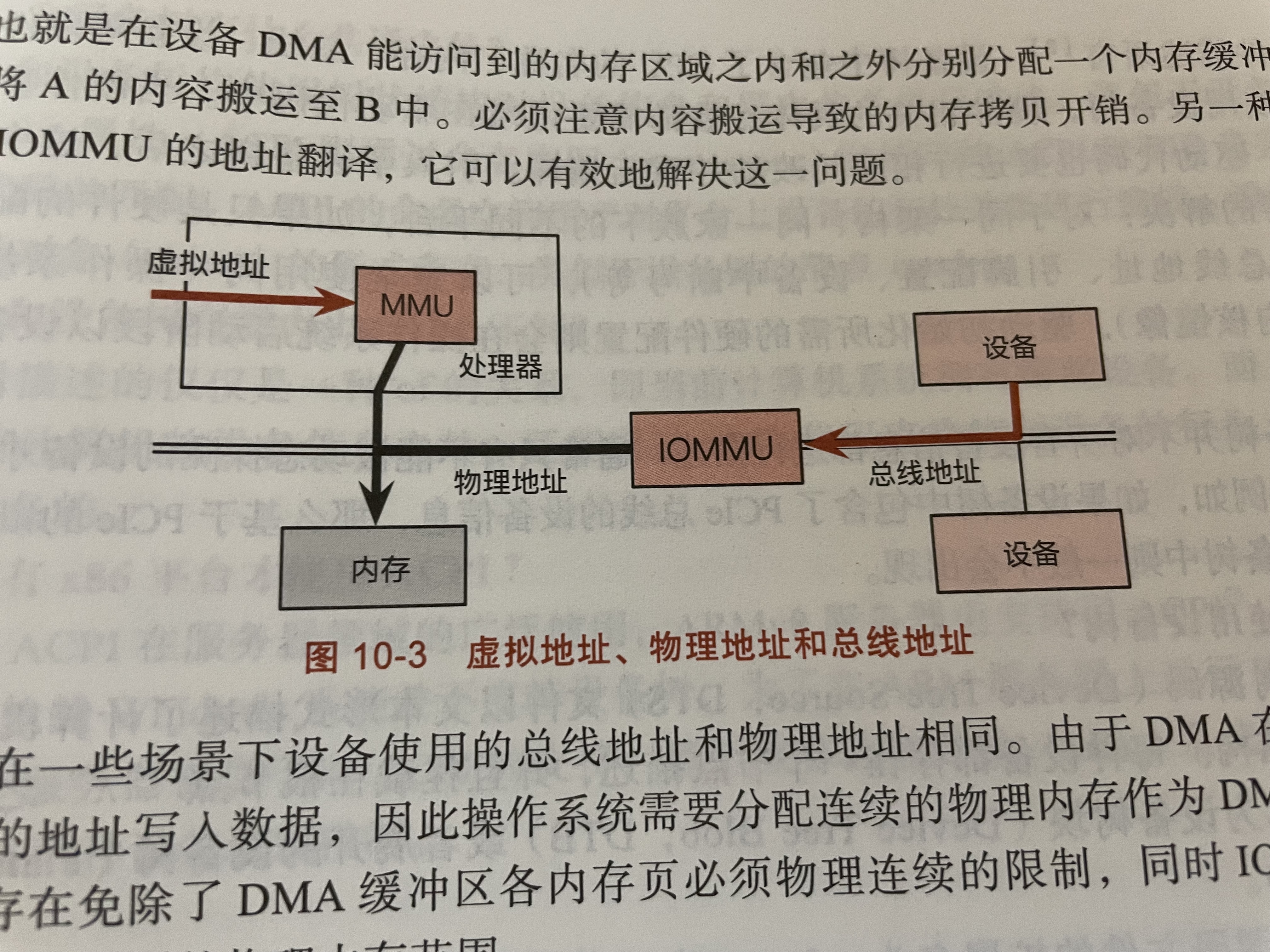
设备的中断处理
中断控制器
外部设备IO结束后会发生中断来通知CPU处理数据。
然而设备种类太多,而且不同中断的优先级也不一样,这就需要中断控制器了。
设备驱动
这里就简单记录一下Linux相关的机制。Linux抽象了100多种设备,把他们抽象成文件。如字符设备、块设备、网络设备等。

若有收获,就点个赞吧
0 人点赞
