互联网架构演变
第一阶段
数据访问量不大,简单的架构即可搞定! 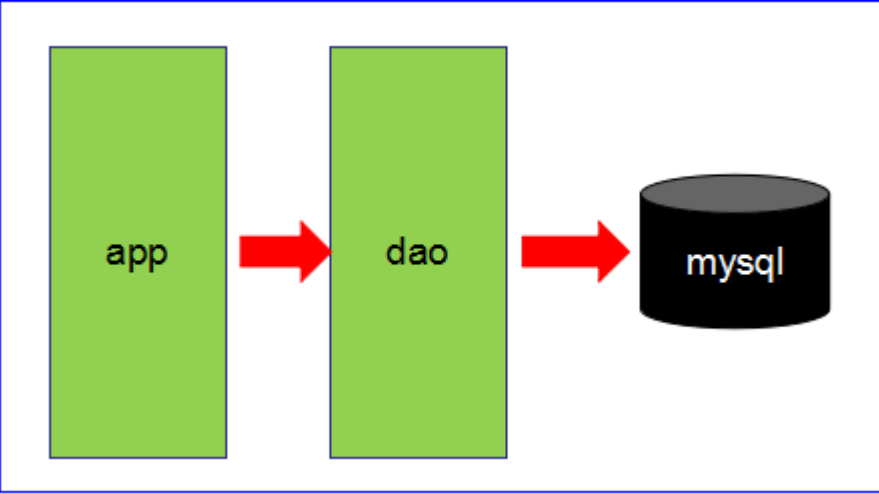
第二阶段
数据访问量大,使用缓存技术来缓解数据库的压力。
不同的业务访问不同的数据库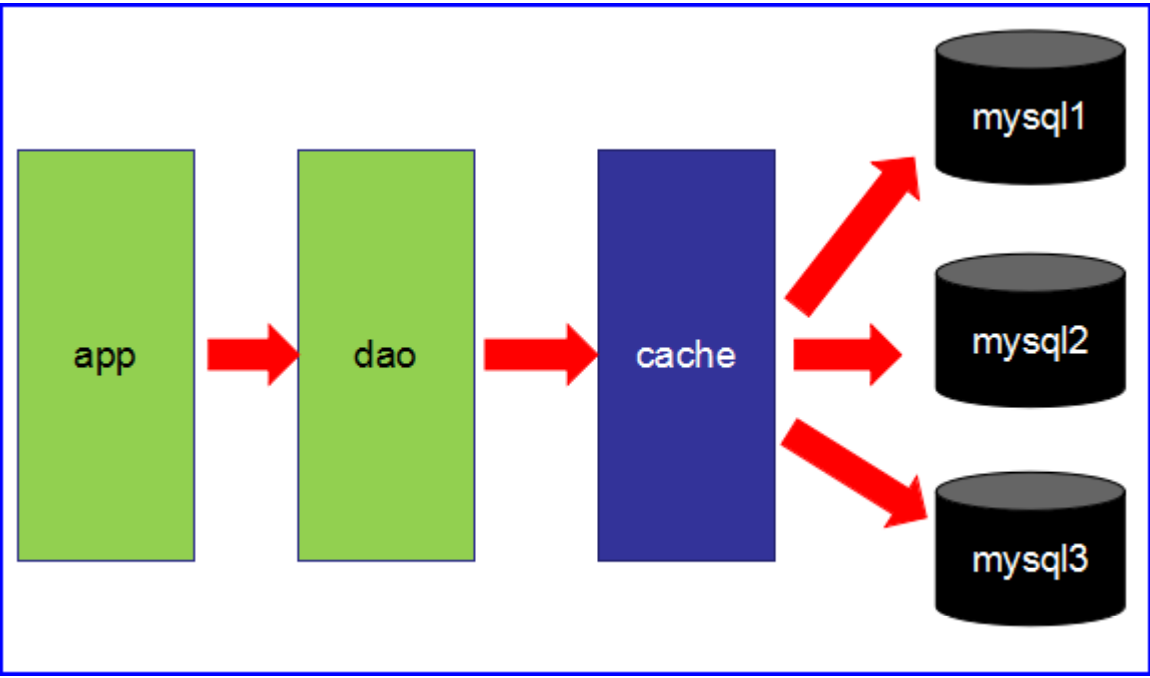
第三阶段 主从读写分离
之前的缓存确实能够缓解数据库的压力,但是写和读都集中在一个数据库上,压力又来了。
一个数据库负责写,一个数据库负责读。分工合作。愉快!
让master(主数据库)来响应事务性(增删改)操作,让slave(从数据库)来响应非事务性 (查询)操作,然后再采用主从复制来把master上的事务性操作同步到slave数据库中
mysql的master/slave就是网站的标配! 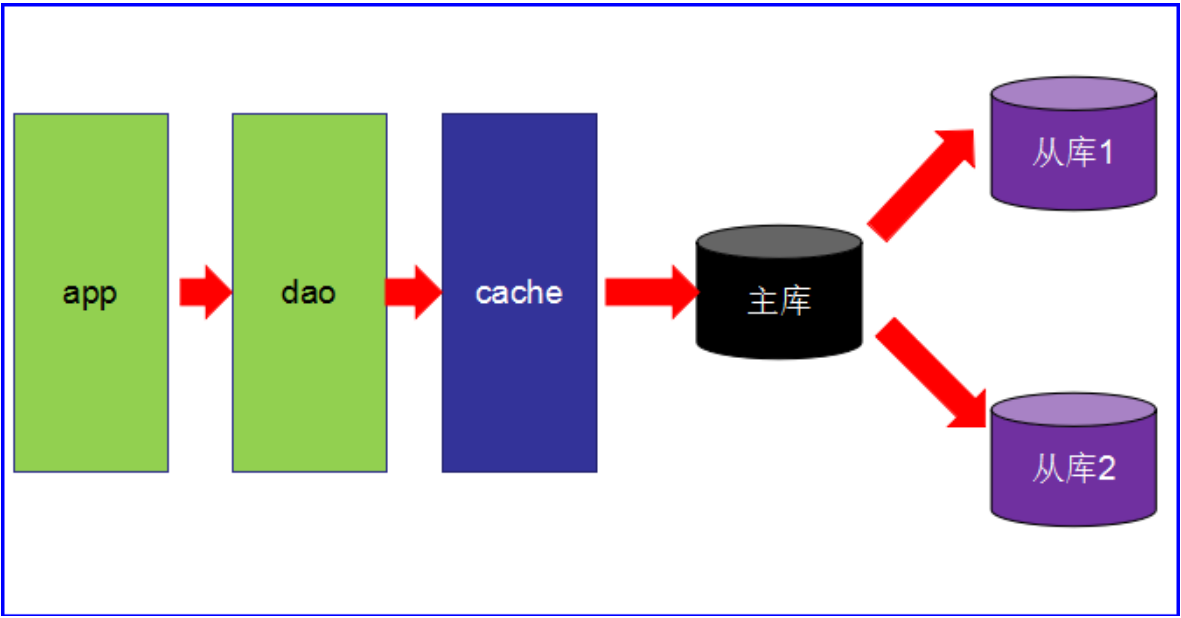
第四阶段
mysql的主从复制,读写分离的基础上,mysql的主库开始出现瓶颈
由于MyISAM使用表锁,所以并发性能特别差
分库分表开始流行,mysql也提出了表分区,虽然不稳定,但我们看到了希望
开始吧,mysql集群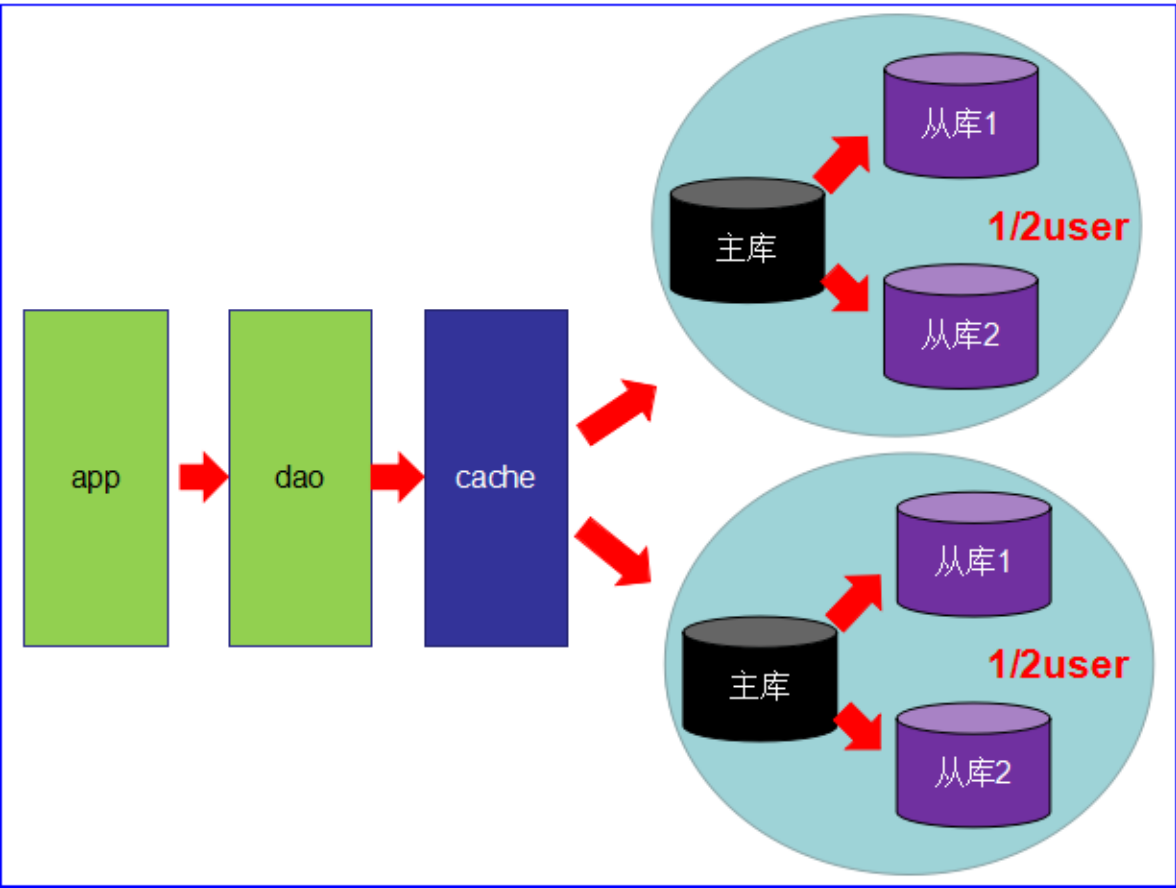
Redis入门介绍
互联网需求的3高
高并发,高可扩,高性能
Redis 是一种运行速度很快,并发性能很强,并且运行在内存上的NoSql(not only sql)数据库
NoSQL数据库 和 传统数据库 相比的优势
NoSQL数据库无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。
而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个噩梦
Redis的常用使用场景
缓存,毫无疑问这是Redis当今最为人熟知的使用场景。在提升服务器性能方面非常有效;一 些频繁被访问的数据,经常被访问的数据如果放在关系型数据库,每次查询的开销都会很大,而放在redis中,因为redis 是放在内存中的可以很高效的访问 。
排行榜,在使用传统的关系型数据库(mysql oracle 等)来做这个事儿,非常的麻烦,而利用Redis的SortSet(有序集合)数据结构能够简单的搞定;
计算器/限速器,利用Redis中原子性的自增操作,我们可以统计类似用户点赞数、用户访问数等,这类操作如果用MySQL,频繁的读写会带来相当大的压力;
限速器比较典型的使用场景是限制某个用户访问某个API的频率,常用的有抢购时,防止用户疯狂点击带来不必要的压力;
好友关系,利用集合的一些命令,比如求交集、并集、差集等。可以方便搞定一些共同好 友、共同爱好之类的功能;
简单消息队列,除了Redis自身的发布/订阅模式,我们也可以利用List来实现一个队列机制, 比如:到货通知、邮件发送之类的需求,不需要高可靠,但是会带来非常大的DB压力,完全可以用List来完成异步解耦
CAP
传统的关系型数据库事务具备ACID:
A:原子性 C:一致性 I:独立性 D:持久性
分布式数据库的CAP:
C(Consistency):强一致性 “all nodes see the same data at the same time”,即更新操作成功并返回客户端后,所 有节点在同一时间的数据完全一致,这就是分布式的一致性。一致性的问题在并发系统 中不可避免,对于客户端来说,一致性指的是并发访问时更新过的数据如何获取的问 题。从服务端来看,则是更新如何复制分布到整个系统,以保证数据最终一致。
A(Availability):高可用性 可用性指“Reads and writes always succeed”,即服务一直可用,而且要是正常的响应 时间。好的可用性主要是指系统能够很好的为用户服务,不出现用户操作失败或者访问 超时等用户体验不好的情况。
P(Partition tolerance):分区容错性 即分布式系统在遇到某节点或网络分区故障时,仍然能够对外提供满足一致性或可用性 的服务。 分区容错性要求能够使应用虽然是一个分布式系统,而看上去却好像是在一个可以运转 正常的整体。比如现在的分布式系统中有某一个或者几个机器宕掉了,其他剩下的机器 还能够正常运转满足系统需求,对于用户而言并没有什么体验上的影响。
CAP如何选择
CAP理论提出就是针对分布式数据库环境的,所以,P这个属性必须容忍它的存在,而且是必须具备的。
因为P是必须的,那么我们需要选择的就是A和C。
大家知道,在分布式环境下,为了保证系统可用性,通常都采取了复制的方式,避免一个节点损坏,导致系统不可用。那么就出现了每个节点上的数据出现了很多个副本的情况,而数据从一个节点复制到另外的节点时需要时间和要求网络畅通的。
所以,当P发生时,也就是无法向某个节点复制数据时,这时候你有两个选择: 选择可用性 A,此时,那个失去联系的节点依然可以向系统提供服务,不过它的数据就不能保证是同步的了(失去了C属性)。 选择一致性C,为了保证数据库的一致性,我们必须等待失去联系的节点恢复过来,在这个过程中,那个节点是不允许对外提供服务的,这时候系统处于不可用状态(失去了A属性)。
最常见的例子是读写分离,某个节点负责写入数据,然后将数据同步到其它节点,其它节点提供读取的服务,当两个节点出现通信问题时,你就面临着选择A(继续提供服务,但是数据不保证准确),C(用户处于等待状态,一直等到数据同步完成)。
分区是常态,不可避免,三者不可共存
可用性和一致性是一对冤家 一致性高,可用性低 一致性低,可用性高
因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三大类:
CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
CP - 满足一致性,分区容忍性的系统,通常性能不是特别高。
AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
redis启动
redis安装很简单 不记录了。
启动前修改配置文件redis.conf 把daemon那个改成yes。这样可以默认后台启动。
以后的启动命令为:
redis-server /usr/redis-5.0.4/redis.conf
检测6379端口
netstat -lntp | grep 6379
关闭单个实例
redis-cli shutdown
关闭多个实例
redis-cli -p 6379 shutdown
检测redis进程
ps -ef|grep redis
常用命令
连接并测试
redis-cliping
hello world
# 保存数据set k1 china# 获取数据get kl
测试性能(先退出客户端)
redis-benchmark
切换数据库
select 0~15 默认15个
数据库键的数量
dbsize
清空当前库
flushdb
清空所有库
flushall
模糊查询
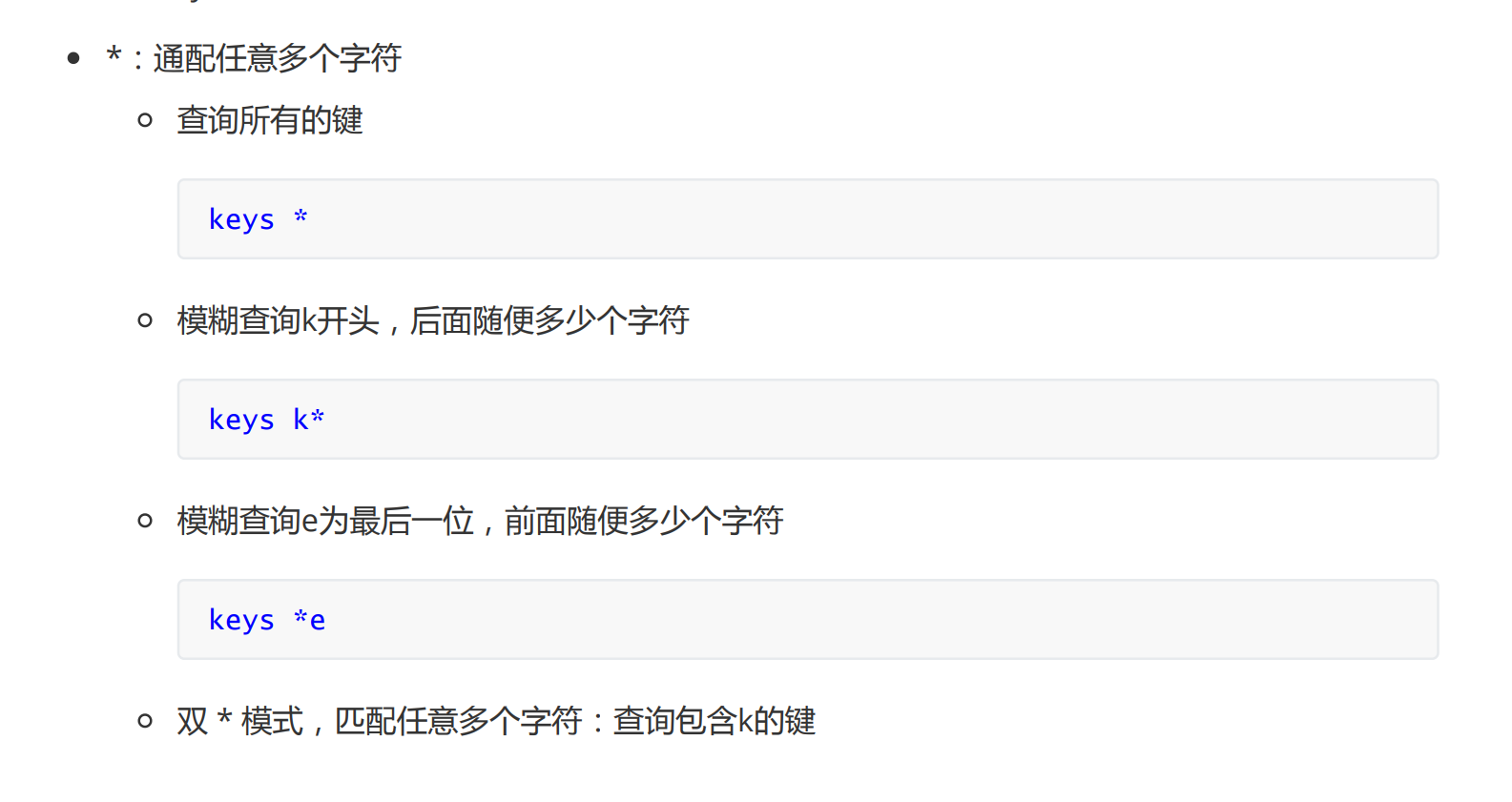
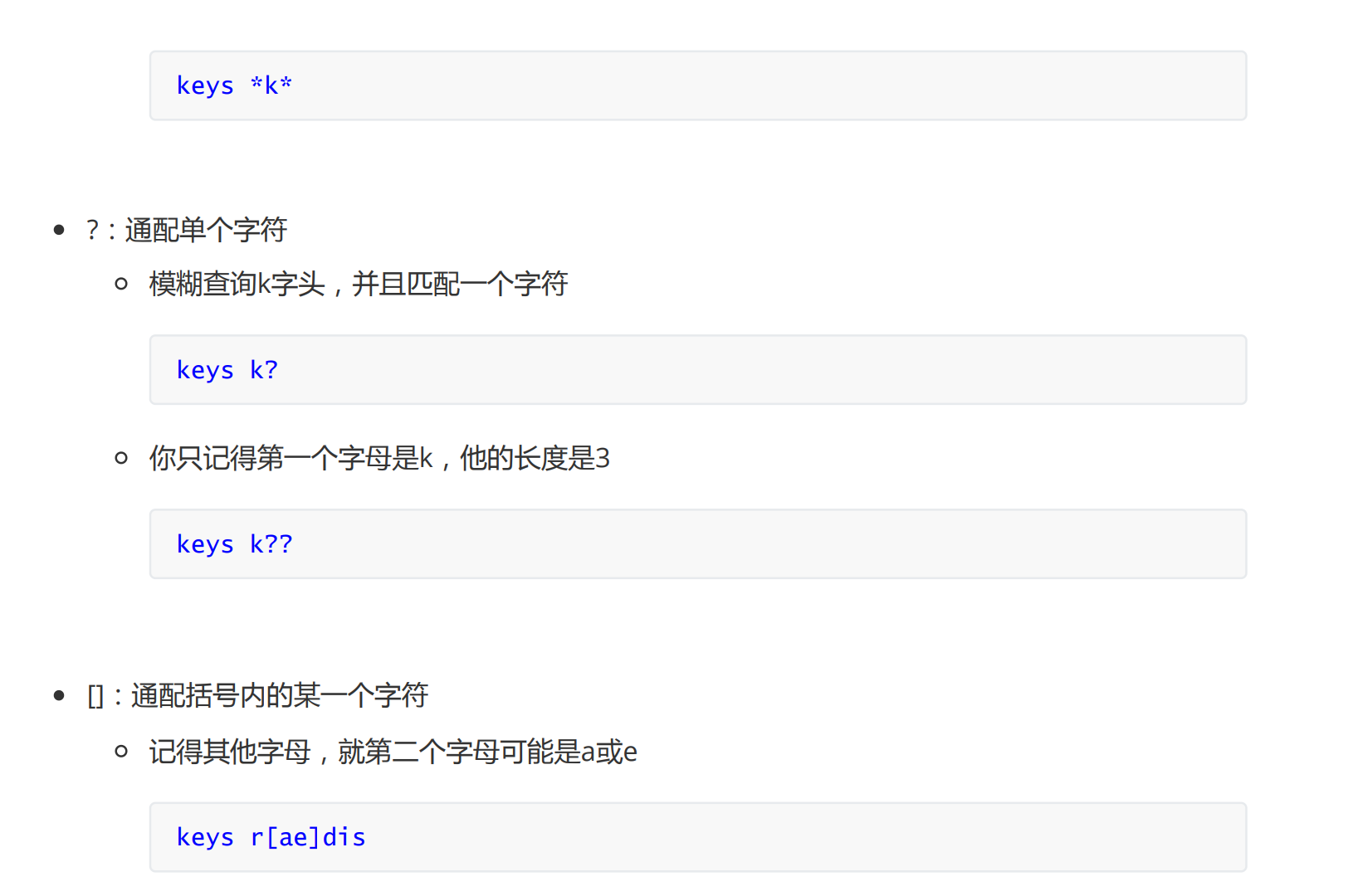
key
exists key:判断某个key是否存在
move key db:移动(剪切,粘贴)键到几号库
ttl key:查看键还有多久过期(-1永不过期,-2已过期)
time to live 还能活多久
expire key 秒:为键设置过期时间(生命倒计时)
type key:查看键的数据类型
String
set/get/del/append/strlen
incr/decr/incrby/decrby:加减操作,操作的必须是数字类型
getrange/setrange:类似between…and… 其实就是操作char[]的下标。字符串切片和切片赋值等。
setex/setnx
set with expir:添加数据的同时设置生命周期
set if not exist:添加数据的时候判断是否已经存在,防止已存在的数据被覆盖掉
mset/mget/msetnx more就是多。
getset:先get后set
list
lpush/rpush/lrange 压入/压入/get
lpop/rpop 那就是pop呗
lindex 通过下标get
llen 返回长度
lrem list01 2 3 从list01中移除2个3
ltrim key begindex endindex 裁剪list
rpoplpush list01 list02 list01右边出一个,从左进入到 list02的第一个位置
lset key index value 正常的set方法
linsert key before/after oldvalue newvalue 插入元素(指定某个元素之前/之后)
set
sadd/smembers/sismember:添加/查看/判断是否存在
scard:获得集合中的元素个数
srem:删除集合中的元素
srandmember:从集合中随机获取几个元素
smove set01 set02 3 # 将set01中的元素3移动到set02中
数学集合篇
sunion sinter sdiff
hashset
hset/hget/hmset/hmget/hgetall/hdel:添加/得到/多添加/多得到/得到全部(键和值)/删除属性
hlen:返回元素的属性个数
hexists:判断元素是否存在某个属性
hkeys/hvals:获得属性的所有key/获得属性的所有value
hincrby/hincrbyfloat:自增(整数)/自增(小数)
hsetnx:添加的时候,先判断是否存在
有序集合Zset
zadd/zrange (withscores):添加/查询
zrangebyscore:模糊查询
( ?: 不包含
limit ? ?:跳过几个截取几个
zrem ? ?:删除元素
zcard/zcount/zrank/zscore:集合长度/范围内元素个数/得元素下标/通过值得分数
zrevrank:逆序找下标(从下向上)
zrevrange:逆序查询
zrevrangebyscore:逆序范围查找
持久化-RDB
在指定的时间间隔内,将内存中的数据集的快照写入磁盘;
默认保存在/usr/local/bin中,文件名dump.rdb;
当然如果你只是用Redis的缓存功能,不需要持久化,那么你可以注释掉所有的 save 行来停用保存功能。可以直接一个空字符串来实现停用:save “”
使用shutdown命令关闭redis,redis会自动将数据库备份
手动执行save命令,可以马上备份。
配置文件与rdb相关的部分
stop-writes-on-bgsave-error:yes/no
yes:当后台备份时候反生错误,前台停止写入
no:不管死活,就是往里怼
rdbcompression:yes/no 一般是yes
对于存储到磁盘中的快照,是否启动LZF压缩算法,一般都会启动,因为这点性能,多买一台电脑,完全搞定N个来回了。
rdbchecksum:yes/no 在存储快照后,是否启动CRC64算法进行数据校验
开启后,大约增加10%左右的CPU消耗; 如果希望获得最大的性能提升,可以选择关闭;
dbfilename:快照备份文件名字
dir:快照备份文件保存的目录,默认为当前目录
持久化-AOF
以日志的形式记录每个写操作;
将redis执行过的写指令全部记录下来(读操作不记录);
只许追加文件,不可以改写文件;
redis在启动之初会读取该文件从头到尾执行一遍,这样来重新构建数据;
默认关闭,需要把appendonly改成yes才行。
aof和rdb都有的情况下,以aof优先。
修复aof文件的命令
如果把aof玩坏了,用下面的命令修复
reids-check-aof --fix appendonly.aof
配置文件与AOF相关的部分
appendonly:开启aof模式
appendfilename:aof的文件名字,最好别改!
appendfsync:追写策略
always:每次数据变更,就会立即记录到磁盘,性能较差,但数据完整性好
everysec:默认设置,异步操作,每秒记录,如果一秒内宕机,会有数据丢失
no:不追写
no-appendfsync-on-rewrite:重写时是否运用Appendfsync追写策略;用默认no即可,保证数据安全性。 AOF采用文件追加的方式,文件会越来越大,为了解决这个问题,增加了重写机制,redis会自动记录上一次AOF文件的大小,当AOF文件大小达到预先设定的大小时,redis就会启动 AOF文件进行内容压缩,只保留可以恢复数据的最小指令集合
auto-aof-rewrite-percentage:如果AOF文件大小已经超过原来的100%,也就是一倍,才重写压缩
auto-aof-rewrite-min-size:如果AOF文件已经超过了64mb,才重写压缩
事务
可以一次执行多个命令,是一个命令组,一个事务中,所有命令都会序列化(排队),不会被插队;
一个队列中,一次性,顺序性,排他性的执行一系列命令
三特性
隔离性:所有命令都会按照顺序执行,事务在执行的过程中,不会被其他客户端送来的命令打断
没有隔离级别:队列中的命令没有提交之前都不会被实际的执行,不存在“事务中查询要看到事务里的更新,事务外查询不能看到”这个头疼的问题
不保证原子性:冤有头债有主,如果一个命令失败,但是别的命令可能会执行成功,没有回滚
三步走
开启multi
入队queued
执行exec
与关系型数据库事务相比
multi:可以理解成关系型事务中的 begin
exec :可以理解成关系型事务中的 commit
discard :可以理解成关系型事务中的 rollback
同生
127.0.0.1:6379> multi # 开启事务OK127.0.0.1:6379> set k1 v1QUEUED # 加入队列127.0.0.1:6379> set k2 v2QUEUED # 加入队列127.0.0.1:6379> get k2QUEUED # 加入队列127.0.0.1:6379> set k3 v3QUEUED # 加入队列127.0.0.1:6379> exec # 执行,一起成功!1) OK2) OK3) "v2"4) OK
共死
127.0.0.1:6379> multi # 开启事务OK127.0.0.1:6379> set k1 v1111QUEUED127.0.0.1:6379> set k2 v2222QUEUED127.0.0.1:6379> discard # 放弃操作OK127.0.0.1:6379> get k1"v1" # 还是原来的值
一颗老鼠屎坏一锅汤
127.0.0.1:6379> multiOK127.0.0.1:6379> set k4 v4QUEUED127.0.0.1:6379> setlalala # 一句报错(error) ERR unknown command `setlalala`, with args beginning with:127.0.0.1:6379> set k5 v5QUEUED127.0.0.1:6379> exec # 队列中命令全部取消(error) EXECABORT Transaction discarded because of previous errors.127.0.0.1:6379> keys * # 还是原来的值1) "k2"2) "k3"3) "k1"
冤有头债有主
127.0.0.1:6379> multiOK127.0.0.1:6379> incr k1 # 虽然v1不能++,但是加入队列并没有报错,类似java中的通过编译QUEUED127.0.0.1:6379> set k4 v4QUEUED127.0.0.1:6379> set k5 v5QUEUED127.0.0.1:6379> exec1) (error) ERR value is not an integer or out of range # 真正执行的时候,报错2) OK # 成功3) OK # 成功127.0.0.1:6379> keys *1) "k5"2) "k1"3) "k3"4) "k2"5) "k4"
watch
127.0.0.1:6379> set in 100 # 收入100元OK127.0.0.1:6379> set out 0 # 支出0元OK127.0.0.1:6379> multiOK127.0.0.1:6379> decrby in 20 # 收入-20QUEUED127.0.0.1:6379> incrby out 20 # 支出+20QUEUED127.0.0.1:6379> exec1) (integer) 802) (integer) 20 # 结果,没问题!
如果有了watch
127.0.0.1:6379> watch in # 监控收入inOK127.0.0.1:6379> multiOK127.0.0.1:6379> decrby in 20QUEUED127.0.0.1:6379> incrby out 20QUEUED127.0.0.1:6379> exec(nil) # 在exec之前,我开启了另一个窗口(线程),对监控的in做了修改,所以本次的事务将被打断(失效),类似于“乐观锁”
unwatch:取消watch命令对所有key的操作
一旦执行了exec命令,那么之前加的所有监控自动失效!
发布订阅
进程间的一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
例如:微信订阅号 订阅一个或多个频道
订阅
subscribe cctv1 cctv5 cctv6
发布
publish cctv1 newspublish cctv5 basketball
主从复制
就是redis集群的策略
配从(库)不配主(库):小弟可以选择谁是大哥,但大哥没有权利去选择小弟
读写分离:主机写,从机读
一主二仆
查看当前节点状态
info replication
当小弟
slaveof 192.168.204.141 6379
成为小弟后,数据自动同步,包括之前大哥已经添加的值。
此后只有主机可以添加数据。
主机shutdown,从机依旧是slave。主机重启,从机依旧是slave。
从机shutdown,主机显示少了个slave。从机如果重启了,又恢复成大哥,需要重新 salveof
血脉相承
一个主机理论上可以多个从机,但是这样的话,这个主机会很累
我们可以使用java面向对象继承中的传递性来解决这个问题,减轻主机的负担,形成祖孙三代:
127.0.0.1:6379> slaveof 192.168.204.141 6379 # 142跟随141OK127.0.0.1:6379> slaveof 192.168.204.142 6379 # 143跟随142OK
篡权
slaveof no one
复制原理
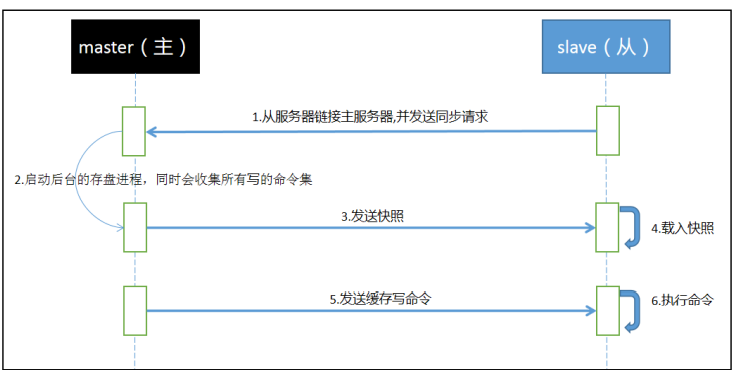
完成上面几个步骤后就完成了从服务器数据初始化的所有操作,从服务器此时可以接收来自用户的读请求
全量复制:Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。slave接收到数据文件后,存盘,并加载到内存中;(步骤1234)
增量复制:Slave初始化后,开始正常工作时主服务器发生的写操作同步到从服务器的过程;(步骤56)
Redis主从同步策略:主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。
当然,如果有需要,slave 在任何时候都可以发起全量同步。
redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
哨兵模式
自动版的谋权篡位!
有个哨兵一直在巡逻,突然发现!!!!!老大挂了,小弟们会自动投票,从众小弟中选出新的老大 Sentinel是Redis的高可用性解决方案: 由一个或多个Sentinel实例组成的Sentinel系统可以监视任意多个主服务器,以及所有从服务器,并在被监视的主服务器进入下线状态时,自动将下线主服务器属下的某个从服务器升级为新的主服务器,然后由新的主服务器代替已下线的主服务器继续处理命令请求
玩法:
先在/usr/local/bin下创建sentinel.conf
sentinel monitor redis1 192.168.42.131 6379 1
然后启动主redis 从redis
再启动sentinel
redis-sentinel sentinel.conf
然后可以把某个服务器shutdown,后台就会投票。之后就算再重启,也不会再变成大哥了,会变成新大哥的小弟。
哨兵模式的缺点
由于所有写操作都是主机上,然后再同步到slave上,所以两台机器之间通信会有延迟;
当系统很繁忙的时候,延迟问题会加重;
slave机器数量增加,问题也会加重
Jedis
依赖
<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>3.1.0</version></dependency>
测试连接
public class TestLink {public static void main(String[] args) {Jedis jedis = new Jedis("192.168.42.131", 6379);System.out.println(jedis.ping());}}// 运行前:// 1.关闭防火墙 systemctl stop firewalld.service// 2.修改redis.conf [ bind 0.0.0.0 ] 允许任何ip访问,以这个redis.conf启动redis服务(重启redis)// redis-server /opt/redis5.0.4/redis.conf
常用API
public class TestApi {public static void main(String[] args) {Jedis jedis = new Jedis("192.168.42.131", 6379);jedis.flushDB();System.out.println("----------------------------------");// string操作jedis.set("k1", "v1");jedis.set("k2", "v2");jedis.set("k3", "v3");Set<String> keys = jedis.keys("k[123]");for (String key : keys) {System.out.println("key: " + key + " val: " + jedis.get(key));}System.out.println(jedis.exists("k2"));System.out.println(jedis.ttl("k1"));jedis.mset("k4", "v4", "k5", "v5");System.out.println(jedis.mget("k1", "k2", "k3", "k4", "k5"));System.out.println("----------------------------------");// listjedis.rpush("list01","l1", "l2", "l3", "l4", "l5");List<String> list01 = jedis.lrange("list01", 0, -1);for (String s : list01) {System.out.println(s);}System.out.println("----------------------------------");// setjedis.sadd("order", "jd001");jedis.sadd("order", "jd002");jedis.sadd("order", "jd003");Set<String> order = jedis.smembers("order");for (String s : order) {System.out.println(s);}jedis.srem("order", "jd002");System.out.println(jedis.smembers("order").size());// hashSystem.out.println("----------------------------------");jedis.hset("user", "username", "alice");System.out.println(jedis.hget("user", "username"));HashMap<String, String> map = new HashMap<>();map.put("gender", "female");map.put("address", "US");map.put("age", "22");jedis.hmset("user", map);List<String> hmget = jedis.hmget("user", "gender", "age", "address");for (String s : hmget) {System.out.println(s);}System.out.println("----------------------------------");jedis.zadd("zset01", 60d, "zs1");jedis.zadd("zset01", 70d, "zs2");jedis.zadd("zset01", 80d, "zs3");jedis.zadd("zset01", 90d, "zs4");Set<String> zset01 = jedis.zrange("zset01", 0, -1);for (String s : zset01) {System.out.println(s);}}}
事务
首先要set yue 100 set zhichu 0
yue是余额,zhichu是支出
public class TestTx {public static void main(String[] args) {Jedis jedis = new Jedis("192.168.42.131", 6379);int yue = Integer.parseInt(jedis.get("yue"));int xiaofei = 10;jedis.watch("yue");if (yue < xiaofei) {jedis.unwatch();System.out.println("余额不足");} else {Transaction transaction = jedis.multi();transaction.decrBy("yue", xiaofei);transaction.incrBy("zhichu", xiaofei);transaction.exec();System.out.println("余额:" + jedis.get("yue"));System.out.println("支出:" + jedis.get("zhichu"));}}}
jedis连接池
依赖
<dependency><groupId>commons-pool</groupId><artifactId>commons-pool</artifactId><version>1.6</version></dependency>
public class JedisPoolUtil {private JedisPoolUtil(){}private volatile static JedisPool jedisPool = null;private volatile static Jedis jedis = null;// 返回一个连接池private static JedisPool getInstance(){// 双层检测锁(企业中用的非常频繁)if(jedisPool == null){ // 第一层:检测体温synchronized (JedisPoolUtil.class){ // 排队进站if(jedisPool == null) { //第二层:查看健康码JedisPoolConfig config = new JedisPoolConfig();config.setMaxTotal(1000); // 资源池中的最大连接数config.setMaxIdle(30); // 资源池允许的最大空闲连接数config.setMaxWaitMillis(60*1000); // 当资源池连接用尽后,调用者的最大等待时间(单位为毫秒)config.setTestOnBorrow(true); //向资源池借用连接时是否做连接有效性检测(业务量很大时候建议设置为false,减少一次ping的开销)jedisPool = new JedisPool( config, "192.168.204.141",6379 );}}}return jedisPool;}// 返回jedis对象public static Jedis getJedis(){if(jedis == null){jedis = getInstance().getResource();}return jedis;}}
Redisson实现的分布式锁
场景是redis里的phone对应的值是10
@Controllerpublic class TestKill {@Autowiredprivate StringRedisTemplate stringRedisTemplate;@Beanpublic Redisson getRedisson() {Config config = new Config();// config.useSingleServer().setAddress("xxxx").setDatabase(0);config.useClusterServers().setScanInterval(2000).addNodeAddress("redis://192.168.42.131:6379","redis://192.168.42.132:6379", "redis://192.168.42.133:6379");return (Redisson) Redisson.create(config);}@Autowiredprivate Redisson redisson;@RequestMapping("/kill")@ResponseBodypublic String kill() {String productKey = "Apple";RLock lock = redisson.getLock(productKey);lock.lock(30, TimeUnit.SECONDS);try {int phoneCount = Integer.parseInt(stringRedisTemplate.opsForValue().get("phone"));if (phoneCount > 0) {phoneCount--;stringRedisTemplate.opsForValue().set("phone", String.valueOf(phoneCount));System.out.println("库存-1, 剩余: " + phoneCount);} else {System.out.println("库存不足");}} catch (Exception e) {e.printStackTrace();} finally {lock.unlock();}return "over!";}}

若有收获,就点个赞吧
0 人点赞
