Dapper 论文中文版
dapper分布式跟踪系统原文.zip
一、Introduce
当代的互联网服务,通常是结构复杂大规模的分布式集群。且集群对应的软件应用模块,可能由不同的团队开发,使用不同的编程语言进行开发。
且这些集群应用少则几百台,多则上千台,且横跨不同的数据中心。这时候就需要一些可以帮助理解系统行为、用于分析性能问题的工具—-分布式链路追踪系统。
二、Dapper 的分布式链路追踪

图中有5个服务系统
- A 服务
- B 服务
- C 服务
- D 服务
A 服务作为聚合服务接收 用户请求X,调用不同服务系统进行处理。
在获取请求响应数据的同时,收集指定链路的信息,并进行汇总,形成追踪链路信息。
2.1、链路信息收集方式
链路信息的收集方式有两种
- 黑盒(black-box)
- 标注(annotation-based)
黑盒(black-box)
没有任何代码的侵入,通过分析请求信息日志分析请求间的关联关系,生成链路追踪信息。
其优点很明显就是没有任何代码的侵入,但是缺点也很明显,就是需要大量的请求信息日志,且其链路信息准确定取决于数据是否足够。
标注(annotation-based)
通过代码侵入的方式进行埋点,针对一次请求明确的标注全局唯一 ID ,通过连接每条记录的全局唯一 ID 穿起链路追踪信息。
其缺点很明显就是需要对代码进行侵入埋点,不过通过组件的方式(直接埋点或者 Javassist 的方式)能够用最小的代价实现链路追踪。
其优点就是能够保证链路信息的准确性。
三、基于标注的链路追踪
基于标注的链路追踪是通过代码埋点的方式实现的,这时候需要对埋点的数据结构进行规范的定义,也就是抽象化
数据抽象:span
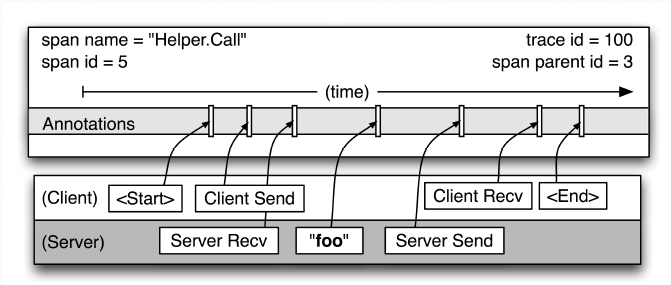
一个 span 描述了两个服务系统间的RPC调用信息。调用方称为 client,被调用方称为 server。
span 中保存了本次 RPC 调用的信息
- 调用开始时间和结束时间
- span 名称
- span id(当前span id)
- span 的父级 span id(如果为 root span 则没有父 span id)
- trace id (用于串联多个span 形成链路追踪信息的全局唯一ID)
一次请求的 span 链路
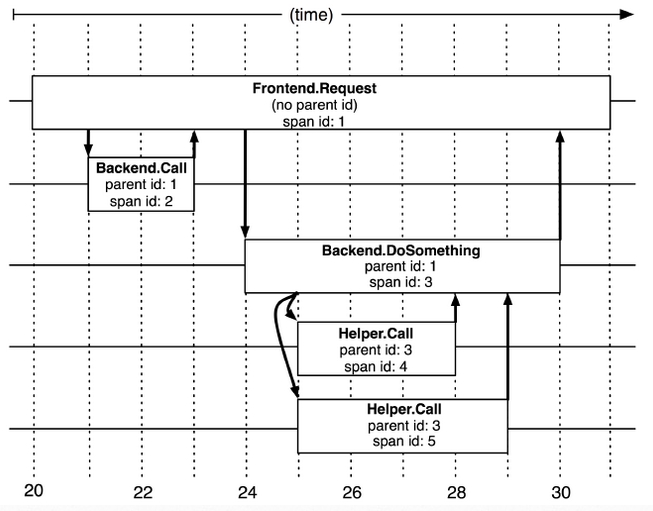
每次请求的追踪链路由一个或多个 span 组成,span 通过 trace id 进行成 span 集合,然后通过 span parent id 构建各个 span 间的关系,组合成一棵跟踪树。
四、基于标注的链路追踪信息的收集
在明确了追踪信息的数据结构和埋点方式后,剩下的就是对追踪信息的收集和汇总。
针对跟踪信息的收集方式通常有两种
- 1、直接打印日志,然后分析日志信息进行汇总分析。
- 2、直接将链路信息存储到中间存储系统中,进行信息汇总分析。
4.1、信息收集造成的额外消耗
跟踪系统的成本由两部分组成
- 正在被监控的系统再生成追踪和收集追踪数据的消耗导致系统性能下降
- 需要使用一部分资源来存储和分析跟踪数据
生成追踪的损耗
跟踪生成的消耗在于 span 的创建和销毁,以及记录到这些追踪信息造成的损耗。
追对生成追踪的损耗可以通过异步记录追踪信息的方式优化。
跟踪收集的损耗
针对已经生成的追踪信息进行收集整理,同样会对系统造成性能上的损耗。
系统通常会将收集到的追踪信息发送给另外一个系统进行分析处理,在传输过程中会占用部分的网络资源。不过可以忽略不计。
针4.2、对跟踪信息进行采样
在进行追踪信息的生成、收集时会造成系统部分性能的损耗,虽然这些损耗是值得的,但是为了尽可能的减少对系统带来的性能损耗,通过采样的方式减少采集的频率。
对于系统来说,只需要记录大量请求中的一部分数据,通过概率的方式就能够得出较为准确的数据结果。
针对不同的系统可以给出通过的采样率方案,对于一个请求量小,但是又需要较为精准的分析数据时,可以提高采样率。
当系统的请求量大,采样率高,可能会给系统性能带来更大的损耗,而这些损耗对比收集到的数据来说不那么值得,这时候就可以降低采样率,减少其带来的系统性能损耗,且在请求两大的时候采集得到的数据准确性也较高。

若有收获,就点个赞吧
0 人点赞
