写于:2019-06-03 08:52:37 参考资料: Hystrix GitHub 官方文档 Hystrix Wiki 文档
一、Hystrix 停止开发问题
Hystrix is no longer in active development, and is currently in maintenance mode. Hystrix (at version 1.5.18) is stable enough to meet the needs of Netflix for our existing applications.
Hystrix 在 Github 上声明了 Hystrix 已经停止开发维护,最后一个稳定版本 1.5.18。市面上也出现了一些替代 Hystrix 的工具,但是对于中小企业应用来说 经历过市场认可的Hystrix组件,仍然是系统搭建,尤其是组合 Spring Cloud 架构不可获取的一个重要组件。
二、Introduce
In a distributed environment, inevitably some of the many service dependencies will fail. Hystrix is a library that helps you control the interactions between these distributed services by adding latency tolerance and fault tolerance logic. Hystrix does this by isolating points of access between the services, stopping cascading failures across them, and providing fallback options, all of which improve your system’s overall resiliency.
大意如下:在分布式环境中,服务间的调用链不可避免会出现某些中间服务出现问题。Hystrix 用来帮助我们控制分布式服务间的逻辑容错处理,可以有效的防止错误蔓延导致服务崩溃,并提供备用处理方案,提高系统的整体弹性。
三、Hystrix 解决的问题
[官方地址](https://github.com/Netflix/Hystrix/wiki)
首先抛出问题
在分布式系统中,在调用某个功能(如:下单),此时可能需要调用其他众多的依赖服务(如:用户服务、支付服务,订单服务等依赖的服务),如下图: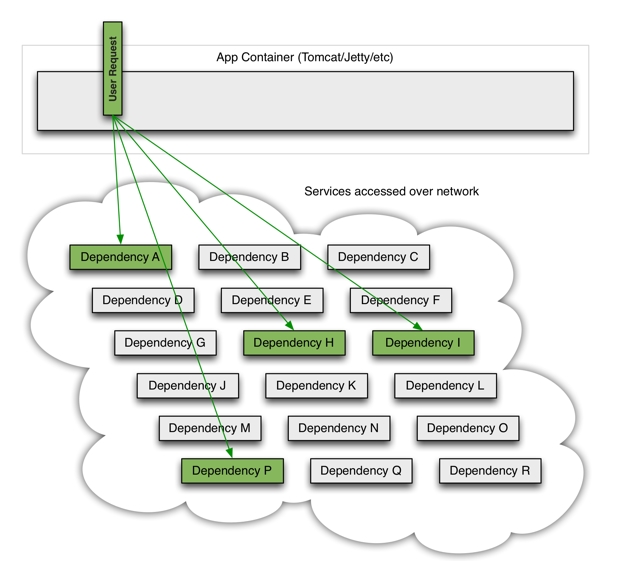
如果此时,某一个依赖服务挂了(假设:支付服务挂了)。如下图: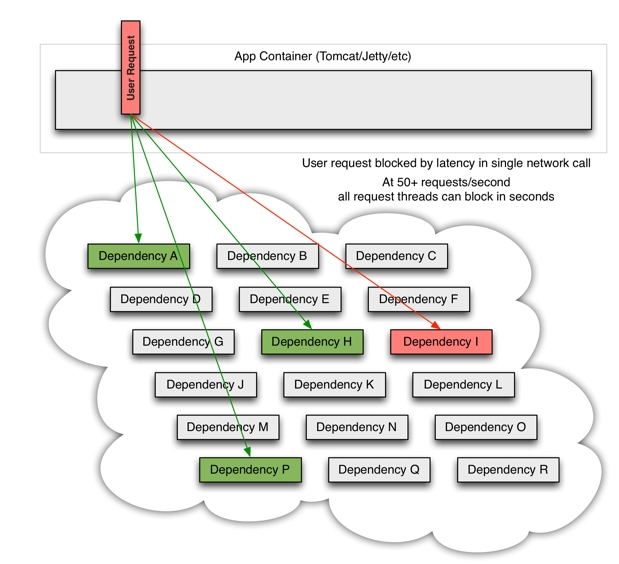
此时服务请求(如:下单请求)需要等待依赖服务(如:支付服务)请求超时,使得本次请求判定错误,并进行回滚,而如果设置有重试机制,则请求会进行多次尝试,每次尝试都会进行超时等待,如果此时涌进了大量相同的请求,则大量请求会等待在故障服务点。如下图
其中的请求无法得到响应,导致请求延迟响应,并且直接或者间接调用该故障点的服务也需要进行等待,导致故障蔓延。(故障蔓延:宕机的服务会出现请求堆积,响应延迟。而此时该服务被其他的服务调用,其他服务会跟着一起延迟,一起请求堆积。)
Hystrix 如何解决上述的问题。
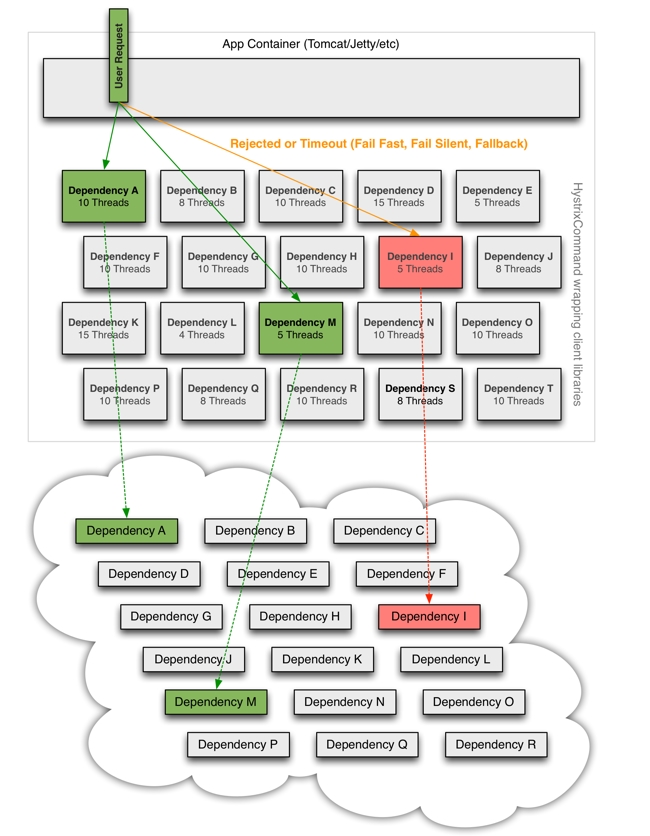
图中,Hystrix 包裹每个依赖请求,相当于每次请求和响应都需要经由 Hystrix,有点类似于 AOP 环绕通知的赶脚,Hystrix 通过在请求前后针对请求进行定制化处理,起到针对每个依赖请求的控制。如:当服务延迟响应触发 Hystrix 熔断规则(如:下单中的支付多次延迟响应),Hystrix 判定 支付服务宕机,并进行熔断,之后的每一次相关的调用支付服务的请求,直接返回调用失败,进行快速失败,防止服务故障导致的请求堆积,最后导致故障蔓延的问题。
四、官方对 Hystrix 提供的功能进行了总结
- 一、在调用其他依赖服务应用时( 跨网络调用 )提供保护、延时控制和保障。
- 二、在复杂的分布式系统中停止级联错误
- 三、故障快速回复
- 四、尽可能优雅的进行服务降级
- 五、实时监控、警报和操作控制。

若有收获,就点个赞吧
0 人点赞
