先只利用Tensor和autograd来实现一个线性回归的训练,先感受一下不用框架的工作量。
体验一下早期研究者的生活。
3.2.1 生成数据集和可视化
我们先设定好真实的模型参数 以及服从 (0, 0.01) 正态分布的噪点
以及服从 (0, 0.01) 正态分布的噪点 (想到了CV中的高斯噪声),显然标签
(想到了CV中的高斯噪声),显然标签 满足一下公式
满足一下公式
# 生成数据集# 统一类型elem_type = torch.float32# 特征个数feature_size = 2# 样本数量example_size = 1000# 真实的模型参数 (w, b)true_w = torch.tensor([[2, -3.4]]).t()true_b = torch.tensor(4.2)print(true_w, true_b)# 输入特征features = torch.randn(example_size, feature_size, dtype=elem_type)# 标签, 需要加上正态分布的噪点labels = torch.mm(features, true_w) + true_blabels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()), dtype=elem_type)print(features[0], labels[0])# 可视化# 设置图片大小base.set_figsize((10, 10))plt.scatter(features[:, 0], labels, s=5)plt.show()
运行结果
tensor([[ 2.0000],[-3.4000]]) tensor(4.2000)tensor([ 0.5475, -2.4344]) tensor([13.5706])
自己动手计算一下,数据生成无误。
以下是取了 ,
, 作为横纵轴来,大致可以看出两者的线性关系
作为横纵轴来,大致可以看出两者的线性关系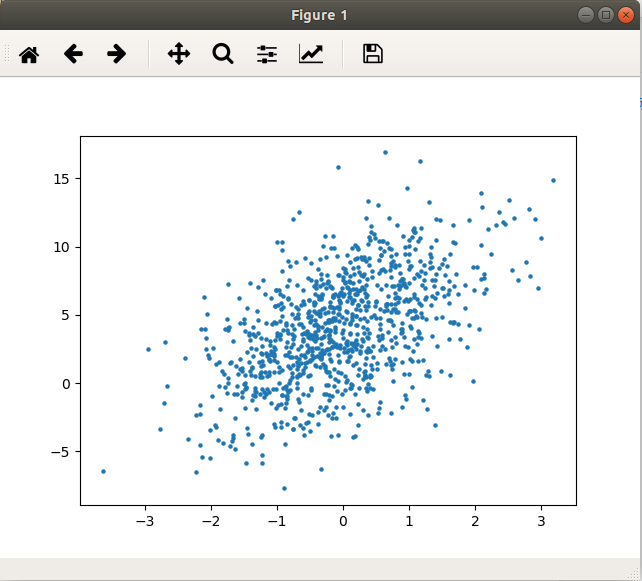
把作者提供的 d2lzh_pytorch模块放到可以搜寻到的路径下, 或者通过 sys.append() 来添加也可,这个包帮助我们实现了一些基础功能。
3.2.2 读取数据
用于小批量随机梯度下降算法中选取样本。
# 已在 d2lzh_pytorch 包中的 data_iter 实现def data_iter(batch_size, features, labels):"""从训练集中每次返回指定数量的随机序列样本.Args:batch_size: 返回的随机序列样本大小features: 训练集的输入特征labels: 训练集的标签Returns:随机序列样本, 大小为 batchSizeRaises:无"""example_size = len(features)indices = list(range(example_size))random.shuffle(indices)for i in range(0, example_size, batch_size):j = torch.LongTensor(indices[i:min(i + batch_size, example_size)]) # 防止溢出yield features.index_select(0, j), labels.index_select(0, j)batch_size = 10for x, y in data_iter(batch_size, features, labels):print(x, '\n', y)break
运行结果
tensor([[-0.0151, -0.3958],[-0.0945, -0.7227],[ 0.1960, -0.3565],[ 0.3286, 0.1862],[ 0.9063, -0.3101],[-1.1899, -0.4032],[-0.9397, -0.2831],[-0.0709, -0.6024],[-1.3366, -1.0776],[ 2.3408, 0.6169]])tensor([[5.5169],[6.4762],[5.7843],[4.2247],[7.0719],[3.1794],[3.2786],[6.0992],[5.1948],[6.7959]])
3.2.3 初始化模型参数
参数随机初始化, 不要取同样的值,这在已经之前的笔记中讲过了。
# 初始化模型参数w = torch.tensor(np.random.normal(0, 0.01, (feature_size, 1)), dtype=elem_type, requires_grad=True)b = torch.zeros(1, dtype=elem_type, requires_grad=True)print(w, '\n', b)
运行结果
tensor([[0.0054],[0.0009]], requires_grad=True)tensor([0.], requires_grad=True)
3.2.4 定义模型
# 定义模型# 已在 d2lzh_pytorch 包中的 linreg 实现def linear_regression(x, w, b):"""用矢量计算表达式描述线性回归的模型Args:x: 特征向量 xw: 模型参数权重 wb: 模型参数偏差 bReturns:预测的标签值Raises:无"""return torch.mm(x, w) + b
3.2.5 定义损失函数
这次我们用的是 平方误差 函数。
# 定义损失函数# 已在 d2lzh_pytorch 包中的 squared_loss 实现def lossfunc_square(y_predict, y):"""计算当前参数下, 损失函数的数值Args:y_predict: 预测的标签值y: 真是的标签值Returns:当前损失函数的值Raises:无"""return (y_predict-y.view(y_predict.size())) ** 2 / 2
3.2.6 定义优化算法
我们采用小批量随机梯度下降, 关于击中常见的梯度下降算法, 可以查看此处
# 定义优化算法# 已在 d2lzh_pytorch 包中的 sgd 实现def mbgd(params, lr, batch_size):"""采用小批量样本 + 随机梯度下降算法来优化模型Args:params: 模型的参数lr: 学习率batch_size: 样本批次的规模Returns:无Raises:无"""for param in params:param.data -= lr * param.grad / batch_size
3.2.7 训练模型
在一个 迭代周期 中,我们将完整遍历一遍data_iter函数,即对训练数据集中 所有样本 都使用一次(假设样本数能够被批量大小整除)。
这里的迭代次数 iterate_num 和学习率lr都是 超参数 ,在实践中,大多超参数都需要通过反复试错来不断调节,也就是我们常常说的 调参工作 。虽然迭代周期数设得越大模型可能越有效,但是训练时间可能过长。而有关学习率对模型的影响,后续会再讲,之间的笔记中也有一定涉及。
选好我们的模型、损失函数(代价函数),优化方法。当然现在我们也没得选,都是之前定义好的那些。框架的一大意义就在于它已经帮你将各种模型、损失函数、优化方法都已经帮你高效且正确地实现了,而你只需要根据实际问题需求选用。
每一次迭代后打印一下当前的损失值,查看一下训练效果,当然用 matplotlib可视化出来更好。
# 训练模型# 学习率lr = 0.03# 迭代次数iterate_num = 5# 选择学习模型, 损失函数, 优化方法net = linear_regressionlossfunc = lossfunc_squareoptimizer = mbgd# 开始迭代for i in range(iterate_num):# 每一次迭代中都要使用训练集中全部样本一次# x, y 分别是样本的特征和标签for x, y in data_iter(batch_size, features, labels):# 调用 sum(), 使结果用标量表示, 计算小批次样本的损失current_lose = lossfunc(net(x, w, b), y).sum()# 小批次样本的损失进行梯度反向传播current_lose.backward()# 优化模型参数optimizer([w, b], lr, batch_size)# 每次执行后梯度清零w.grad.data.zero_()b.grad.data.zero_()# 计算整个训练集的损失, 查看学习效果trainset_lose = lossfunc(net(features, w, b), labels).sum()print("第{0}次训练和的损失={1:.4f}".format(i + 1, trainset_lose))
运行结果
第1次训练和的损失=35.7206第2次训练和的损失=0.1288第3次训练和的损失=0.0461第4次训练和的损失=0.0461第5次训练和的损失=0.0460
最终结果
打印一下我们训练完的模型的参数。
print("训练完成, 最终模型参数为")print("w =", w)print("b =", b)
运行结果
w = tensor([[ 1.9997],[-3.4002]], requires_grad=True)b = tensor([4.1998], requires_grad=True)
可以看到和我们生成数据时用的参数已经基本一致了。
小结
仅仅使用Tensor和autograd 这些基础模块,我们已经能比较方便地实现一个简单的线性回归了。接下来我们将利用 PyTorch 中更多更加方便的功能来进一步提高效率。

若有收获,就点个赞吧
0 人点赞
