在解决过拟合问题时,虽然简化模型和增大数据集是有效的方法,但是实际中并不常用,简化模型意味着有些特征被丢弃,增大数据集面临数据获取难的问题。权重衰减(weight decay)是一种更为常用的方法。
权重衰减等价于 L2 范数正则化(regularization),教程中这样说,那么本节的内容可以参考吴恩达机器学习中关于正则化的部分。但是我不知道什么 L2 范数,先学一下这个新概念。
关于 L2 范数参考链接:https://www.jianshu.com/p/4bad38fe07e6
理论知识看教程复习即可。重点用代码实现看一下正则化的效果。
- 生成数据集
原始数据的函数关系为,p 表示特征向量的维数:
为了制造过拟合的现象,减少训练集的大小,增加特征的数量。
# 生成数据集elem_type = torch.floattrain_size = 20test_size = 100feature_size = 200true_w = torch.ones((feature_size, 1)) * 0.01true_b = 0.05features = torch.randn((train_size + test_size, feature_size))labels = torch.mm(features, true_w) + true_blabels += torch.normal(0, 0.01, labels.size(), dtype=elem_type)
- 训练模型
与前一节的函数类似,但是这次加上 wd 表示 L2 范数惩罚项的系数
def fit_and_plot(train_features, train_labels, test_features, test_labels, wd):"""训练模型并可视化训练结果和测试结果.Args:train_features: 训练集的特征train_labels: 训练集的标签test_features: 测试集的特征test_labels: 测试集的标签wd:Returns:无Raises:无"""# 训练准备iterate_num = 100loss_func = torch.nn.MSELoss()net = torch.nn.Linear(train_features.shape[-1], 1)nn.init.normal_(net.weight, mean=0, std=1)nn.init.normal_(net.bias, mean=0, std=1)# PyTorch 默认对权重和偏差同时衰减, 这里只让权重衰减optimizer_w = torch.optim.SGD(params=[net.weight], lr=0.01, weight_decay=wd)optimizer_b = torch.optim.SGD(params=[net.bias], lr=0.01)batch_size = min(10, train_labels.shape[0])train_set = torch_data.TensorDataset(train_features, train_labels)train_set_iter = torch_data.DataLoader(train_set, batch_size, shuffle=True)# 存放学习后的误差数据点train_lose_array, test_lose_array = [], []for i in range(iterate_num):for x, y in train_set_iter:y_output = net(x)current_lose = loss_func(y_output, y.view(y_output.size()))optimizer_w.zero_grad()optimizer_b.zero_grad()current_lose.backward()optimizer_w.step()optimizer_b.step()train_lose_array.append(loss_func(net(train_features), train_labels).mean().item())test_lose_array.append(loss_func(net(test_features), test_labels).mean().item())print("第{0}次迭代后, 训练误差={1:.4f}, 泛化误差={2:.4f}".format(i + 1, train_lose_array[-1], test_lose_array[-1]))print("矩阵范数={0}".format(net.weight.data.norm().item()))d2lzh_pytorch.semilogy(range(1, iterate_num + 1), train_lose_array, 'epochs', 'loss',range(1, iterate_num + 1), test_lose_array, ['train', 'test'])
- 效果展示
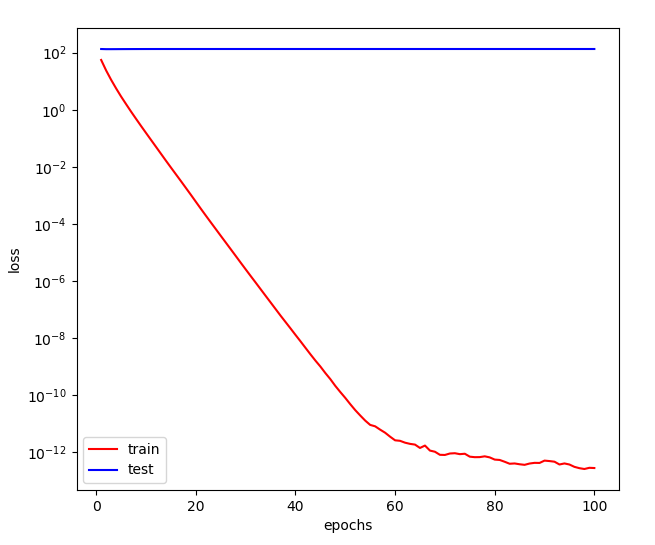
先看一下不加权重衰减的表现,即 惩罚项系数 wd=0
# 无权重衰减fit_and_plot(features[:train_size, :], labels[:train_size],features[train_size:, :], labels[train_size:],wd=0)
尽管训练误差近似为 0,但泛化误差高居不下。
第100次迭代后, 训练误差=0.0000, 泛化误差=134.0383矩阵范数=12.42329216003418
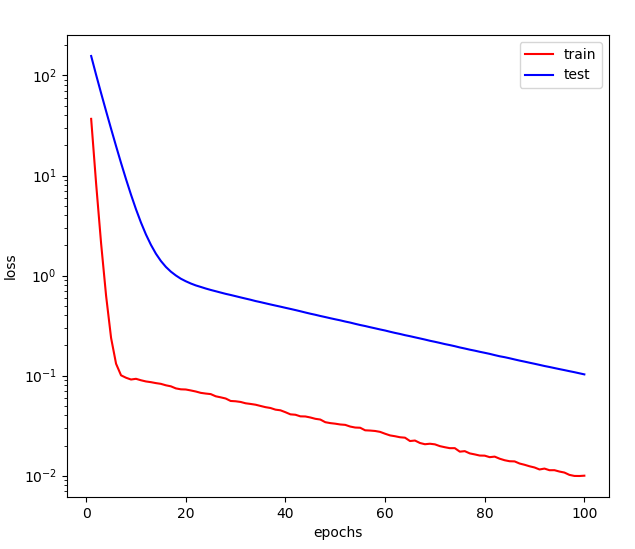
再来看一下加上权重衰减后的效果,
# 加上权重衰减fit_and_plot(features[:train_size, :], labels[:train_size],features[train_size:, :], labels[train_size:],wd=10)
可以看到,泛化误差已经大大降低了,最终得到的矩阵范数也比较小。
第100次迭代后, 训练误差=0.0100, 泛化误差=0.1028矩阵范数=0.07206203788518906

若有收获,就点个赞吧
0 人点赞
